الحفر التكيفي: اختبار رجعي بدقة متغيرة من الدقائق إلى الصفقات الخام
شموع الدقيقة هي الدقة القياسية للاختبارات الرجعية. لكن داخل شمعة دقيقة واحدة، يمكن أن يتحرك السعر بشكل مختلف: أحياناً بنسبة 0.01%، وأحياناً بنسبة 2%. عندما يقع كل من وقف الخسارة وجني الأرباح ضمن نطاق [low, high] لشمعة دقيقة واحدة، لا يعرف الاختبار الرجعي أيهما تم تفعيله أولاً. هذه هي مشكلة غموض التنفيذ (fill ambiguity problem).
الحل البسيط هو التحول إلى بيانات بالثانية للاختبار الرجعي بأكمله. لكن على مدار عامين، يعني ذلك حوالي 63 مليون شريط ثانية بدلاً من حوالي مليون شريط دقيقة. يزداد التخزين 60 ضعفاً، وتنخفض السرعة بشكل متناسب.
الحفر التكيفي يحل هذه المشكلة: استخدام الدقة العالية فقط حيث تكون مطلوبة فعلاً.
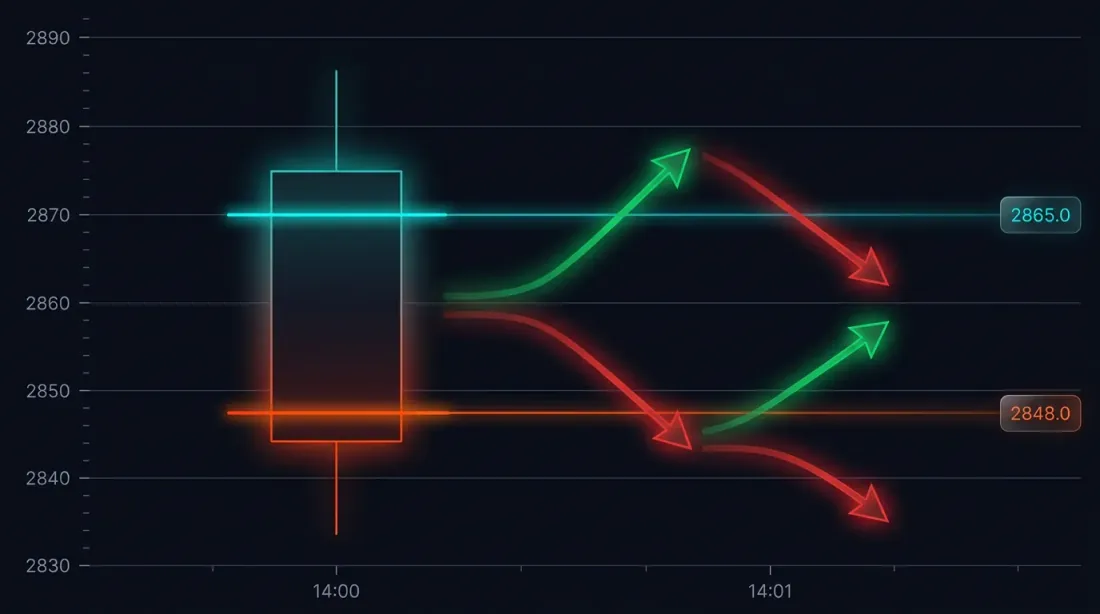
المشكلة: غموض التنفيذ في الشموع الكبيرة
لنتأمل حالة محددة. فتحت الاستراتيجية صفقة شراء عند 3000 USDT. وقف الخسارة: 2970 (-1%). جني الأرباح: 3060 (+2%).
شمعة الدقيقة عند 14:37:
- الافتتاح: 3010
- الأعلى: 3065
- الأدنى: 2965
- الإغلاق: 3050
كل من SL (2970) وTP (3060) يقعان ضمن النطاق [2965, 3065]. أيهما تم تفعيله أولاً؟
النتائج المحتملة:
- السعر انخفض أولاً -> تم تفعيل SL -> خسارة -1%
- السعر ارتفع أولاً -> تم تفعيل TP -> ربح +2%
الفرق في صفقة واحدة: 3 نقاط مئوية. مع رافعة مالية 10 أضعاف — 30%. لاختبار رجعي يحتوي على مئات الصفقات، يؤدي الحل الخاطئ لغموض التنفيذ إلى تشويه النتائج بشكل منهجي.
كيف تتعامل الأطر البرمجية مع هذا افتراضياً
تستخدم معظم محركات الاختبار الرجعي أحد أسلوبين استدلاليين:
- متفائل: يتم تفعيل TP أولاً -> نتائج مبالغ فيها
- متشائم: يتم تفعيل SL أولاً -> نتائج منقوصة
كلا النهجين مجرد تخمين. البيانات الحقيقية متاحة على مستوى الثانية أو حتى الميلي ثانية، ولا يوجد سبب للتخمين عندما يمكنك التحقق.
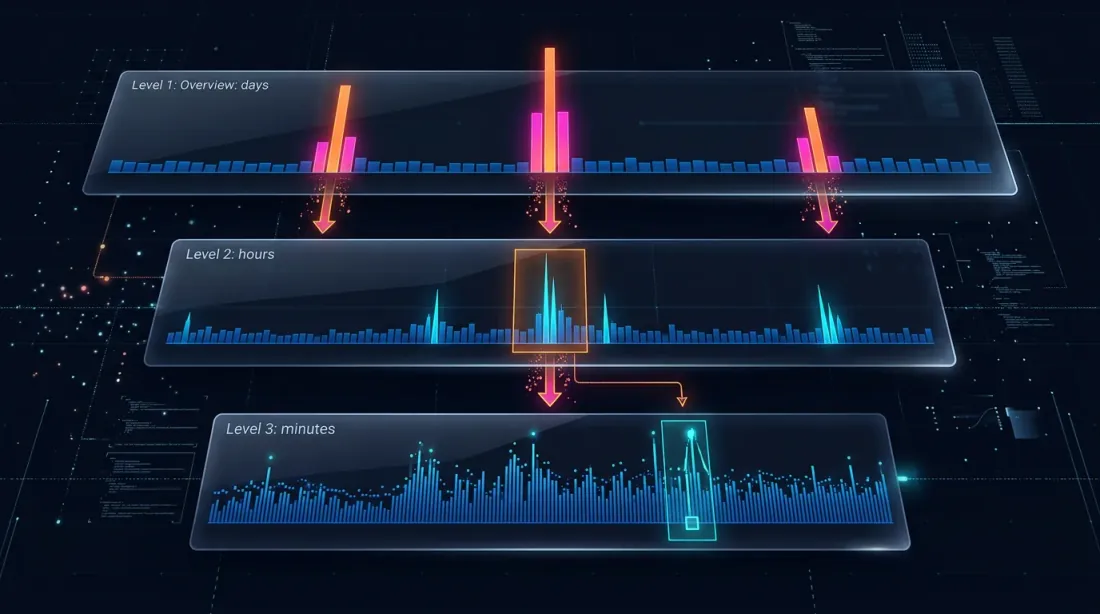
الحفر: استراتيجية من أربعة مستويات

فكرة الحفر: البدء من مستوى الدقيقة و"الحفر" إلى مستوى أدنى فقط عندما يكون هناك غموض — إما بسبب حركة السعر أو ارتفاعات الحجم.
Level 1: 1m (شموع الدقيقة)
-> إذا كان SL أو TP خارج نطاق [low, high] بوضوح — حل فوري
-> إذا كان كلاهما ضمن النطاق — حفر
Level 2: 1s (شموع الثانية)
-> تحميل 60 شريط ثانية لهذه الدقيقة
-> المرور ثانية بثانية: أيهما تم تفعيله أولاً؟
-> إذا كان شريط الثانية غامضاً، أو price_move >= min_pct، أو volume >= median_1s * vol_mult — حفر
Level 3: 100ms (شموع الميلي ثانية)
-> تحميل حتى 10 أشرطة من 100ms لهذه الثانية
-> المرور 100ms تلو 100ms
-> إذا كان شريط 100ms غامضاً، أو price_move >= min_pct، أو volume >= median_100ms * vol_mult — حفر
Level 4: الصفقات الخام
-> تحميل الصفقات الفردية لدلو 100ms هذا
-> حل التنفيذ على مستوى صفقة بصفقة — أقصى دقة ممكنة
متى لا يكون الحفر مطلوباً
في 95% من الحالات، لا يكون الحفر مطلوباً. السيناريوهات النموذجية:
SL واضح: أعلى الشمعة لا يصل إلى TP، وأدنى الشمعة يخترق SL -> تم تفعيل SL، لا حاجة للحفر.
TP واضح: الأدنى لا يصل إلى SL، والأعلى يخترق TP -> تم تفعيل TP، لا حاجة للحفر.
لم يتم تفعيل أي منهما: كلا المستويين خارج النطاق -> المركز يظل مفتوحاً.
كشف الفجوة: افتتاح الشمعة التالية يقفز عبر SL أو TP -> التنفيذ بسعر الافتتاح، لا حاجة للحفر.
الحفر مطلوب فقط لحوالي 5% من الأشرطة — عندما يقع كلا المستويين ضمن نطاق شمعة واحدة.
class AdaptiveFillSimulator:
"""
Four-level drill-down for determining fill order.
"""
def __init__(self, data_loader):
self.loader = data_loader
self.cache_1s = {} # Cache of second data by month
def check_fill(self, timestamp, candle_1m, sl_price, tp_price, side):
"""
Checks whether SL or TP triggered on the given minute candle.
Returns: ('sl', fill_price) | ('tp', fill_price) | None
"""
low, high = candle_1m['low'], candle_1m['high']
open_price = candle_1m['open']
if side == 'long':
if open_price <= sl_price:
return ('sl', open_price)
if open_price >= tp_price:
return ('tp', open_price)
else:
if open_price >= sl_price:
return ('sl', open_price)
if open_price <= tp_price:
return ('tp', open_price)
sl_hit = self._level_hit(sl_price, low, high, side, 'sl')
tp_hit = self._level_hit(tp_price, low, high, side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if not sl_hit and not tp_hit:
return None
return self._drill_down_1s(timestamp, sl_price, tp_price, side)
def _drill_down_1s(self, minute_ts, sl_price, tp_price, side):
"""Level 2: second-by-second pass."""
bars_1s = self.loader.load_1s_for_minute(minute_ts)
if bars_1s is None or len(bars_1s) == 0:
return self._pessimistic_fill(side, sl_price, tp_price)
for bar in bars_1s:
sl_hit = self._level_hit(sl_price, bar['low'], bar['high'], side, 'sl')
tp_hit = self._level_hit(tp_price, bar['low'], bar['high'], side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if sl_hit and tp_hit:
result = self._drill_down_100ms(bar['timestamp'], sl_price, tp_price, side)
if result:
return result
return self._pessimistic_fill(side, sl_price, tp_price)
def _pessimistic_fill(self, side, sl_price, tp_price):
"""Pessimistic assumption: SL for longs, TP for shorts."""
if side == 'long':
return ('sl', sl_price)
else:
return ('sl', sl_price)
الأداء
| الوضع | الوقت لكل فحص تنفيذ | متى يُستخدم |
|---|---|---|
| 1m (بدون حفر) | ~0ms | ~95% من الحالات |
| حفر 1s | ~5ms (أول وصول للشهر) | ~5% من الحالات |
| حفر 100ms | ~1ms | <0.5% من الحالات |
| حفر الصفقات الخام | ~0.5ms | <0.1% من الحالات |
في اختبار رجعي على مدار عامين مع حوالي 400 صفقة، يتم استدعاء الحفر لحوالي 20 شمعة. إجمالي الحمل الإضافي — أقل من ثانية واحدة للاختبار الرجعي بأكمله.
التخزين التكيفي للبيانات
يتطلب الحفر بيانات بالثانية والميلي ثانية. لكن تخزين كل شيء بأقصى دقة غير عملي:
| الدقة | عدد الأشرطة خلال عامين | حجم Parquet |
|---|---|---|
| 1m | ~1.05 مليون | ~15 ميغابايت |
| 1s | ~63 مليون | ~550 ميغابايت/شهر |
| 100ms | ~630 مليون | ~5 غيغابايت/شهر |
أرشيف 1s كامل على مدار عامين هو حوالي 13 غيغابايت. 100ms — أكثر من 100 غيغابايت. التخزين الكامل ممكن لكنه مُبذّر، بالنظر إلى أن الحفر يستخدم أقل من 1% من هذه البيانات.
كشف الثواني الساخنة
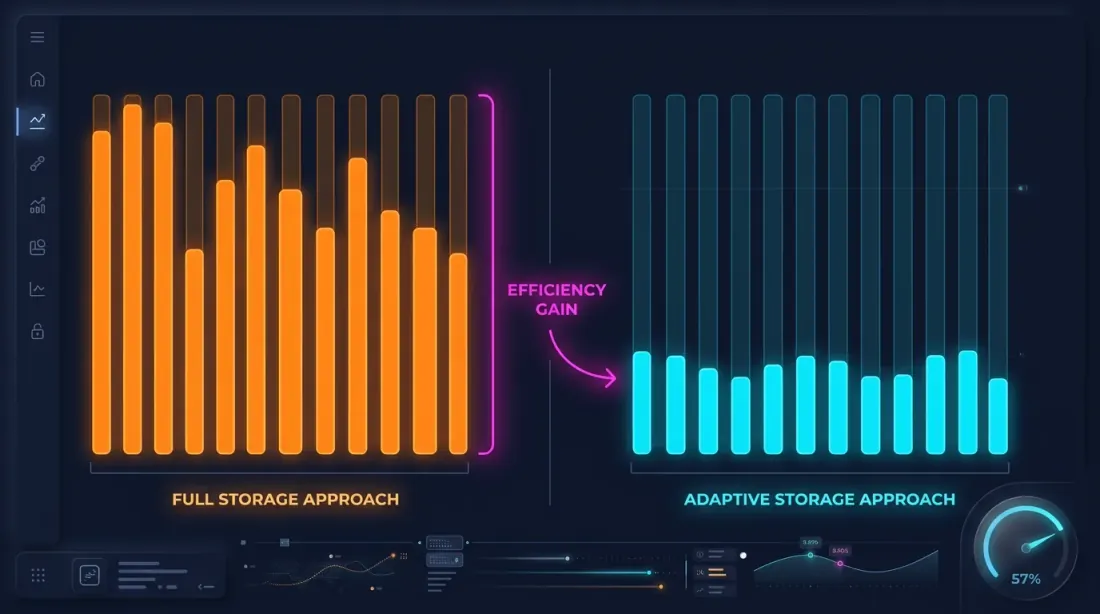
الملاحظة الأساسية: الثواني التي يتحرك فيها السعر بشكل كبير تمثل جزءاً صغيراً. إذا تغير السعر بأقل من 0.1% خلال ثانية واحدة — فلا فائدة من تخزين تفصيل 100ms لتلك الثانية.
كشف الثواني الساخنة: عند تنزيل البيانات ومعالجتها، نحلل كل ثانية وننشئ شموع 100ms فقط لـ"الثواني الساخنة" — تلك التي تجاوزت فيها حركة السعر العتبة.
def process_trades_adaptive(
trades: pd.DataFrame,
min_price_change_pct: float = 1.0,
) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Processes raw trades into an adaptive structure:
- 1s candles for all seconds
- 100ms candles only for "hot" seconds
Args:
trades: DataFrame with columns [timestamp, price, quantity]
min_price_change_pct: threshold for drill-down to 100ms
Returns:
(df_1s, df_100ms_hot) — second candles and 100ms for hot seconds
"""
trades['second'] = trades['timestamp'].dt.floor('1s')
df_1s = trades.groupby('second').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
df_1s['price_change_pct'] = (df_1s['high'] - df_1s['low']) / df_1s['open'] * 100
hot_seconds = df_1s[df_1s['price_change_pct'] >= min_price_change_pct].index
hot_trades = trades[trades['second'].isin(hot_seconds)]
hot_trades['bucket_100ms'] = hot_trades['timestamp'].dt.floor('100ms')
df_100ms = hot_trades.groupby('bucket_100ms').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
return df_1s, df_100ms
توفير التخزين
على سبيل المثال — ETHUSDT خلال شهر نموذجي:
| النهج | الحجم | الدقة |
|---|---|---|
| 1m فقط | ~1 ميغابايت | دقيقة واحدة |
| كل 1s | ~550 ميغابايت | ثانية واحدة |
| كل 100ms | ~5 غيغابايت | 100 مللي ثانية |
| تكيفي | ~600 ميغابايت | 1s + 100ms للثواني الساخنة فقط |
مع عتبة min_price_change_pct = 1.0%، تمثل الثواني الساخنة أقل من 1% من جميع الثواني. بيانات 100ms لها تضيف حوالي 50 ميغابايت إلى 550 ميغابايت من بيانات الثانية — حمل إضافي ضئيل.
إذا تم تخزين بيانات الثانية أيضاً بشكل تكيفي (فقط عندما تتجاوز الحركة خلال دقيقة 0.1%)، يمكن تقليل الحجم بمقدار 3-5 أضعاف إضافية.
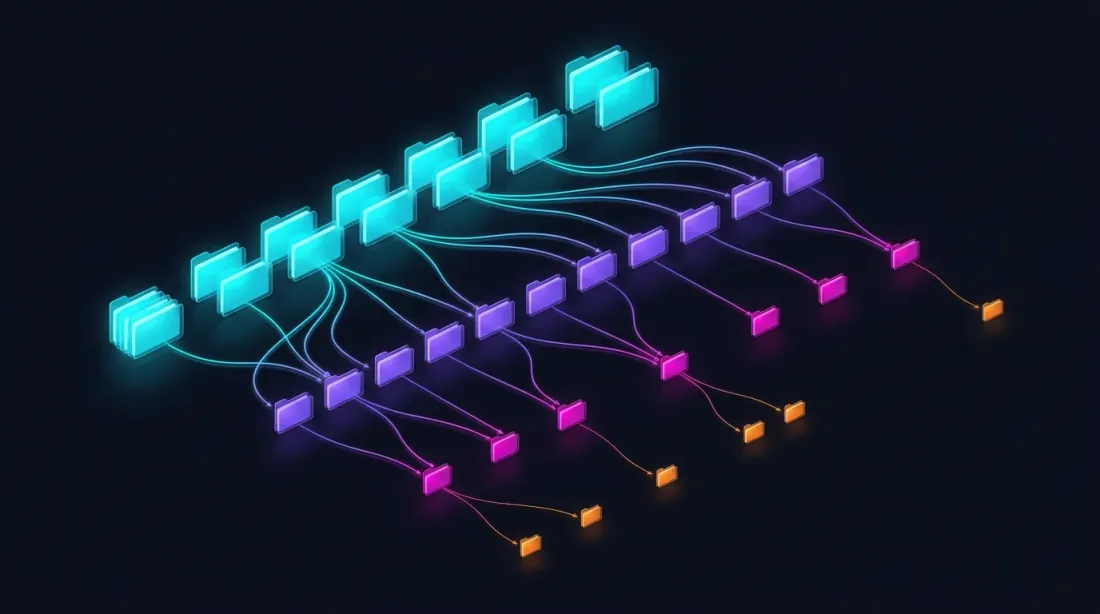
هيكل تخزين Parquet
data/{SYMBOL}/
├── source.json # Exchange source: {"exchange": "binance"} or {"exchange": "bybit"}
├── stats.json # Precomputed median volumes: {"median_volume_1s": ..., "median_volume_100ms": ...}
├── klines_1m/
│ ├── 2024-01.parquet # ~1 MB
│ ├── 2024-02.parquet
│ └── ...
├── klines_1s/
│ ├── 2024-01.parquet # ~550 MB
│ └── ...
├── klines_100ms_hot/
│ ├── 2024-01.parquet # ~50 MB (hot seconds only)
│ └── ...
├── trades_hot/
│ ├── 2024-01.parquet # Raw trades for hot 100ms buckets
│ └── ...
└── states_1m.parquet # Precomputed rolling state cache (~112 MB)
يغطي كل ملف شهراً واحداً من البيانات. يتم تحميل بيانات الثانية والميلي ثانية والصفقات بشكل كسول — فقط عندما يطلبها الحفر. يحتوي ملف stats.json على أحجام وسيطة محسوبة مسبقاً تُستخدم لمحفزات الحفر المبنية على الحجم.
تحسين Parquet للبيانات المالية
للبيانات المالية خصائص محددة: الطوابع الزمنية تنمو بشكل رتيب، والأسعار تتغير بسلاسة، والأحجام تتفاوت بشكل كبير. الإعدادات المثلى:
import pyarrow as pa
import pyarrow.parquet as pq
schema = pa.schema([
pa.field("timestamp", pa.int32()), # Seconds from epoch — int32 is sufficient
pa.field("open", pa.float32()),
pa.field("high", pa.float32()),
pa.field("low", pa.float32()),
pa.field("close", pa.float32()),
pa.field("volume", pa.float32()),
])
column_encodings = {
"timestamp": "DELTA_BINARY_PACKED", # Monotonic int -> delta compression
"open": "BYTE_STREAM_SPLIT", # Float -> byte-stream split
"high": "BYTE_STREAM_SPLIT",
"low": "BYTE_STREAM_SPLIT",
"close": "BYTE_STREAM_SPLIT",
"volume": "BYTE_STREAM_SPLIT",
}
def save_optimized_parquet(df, path):
table = pa.Table.from_pandas(df, schema=schema)
pq.write_table(
table, path,
compression="zstd",
compression_level=9,
use_dictionary=False,
write_statistics=False,
column_encoding=column_encodings,
)
لماذا هذه الإعدادات:
- DELTA_BINARY_PACKED للطوابع الزمنية: الفرق بين طوابع زمنية متتالية قيمة ثابتة (60 لـ 1m، 1 لـ 1s). ترميز الفروق يضغطها إلى ما يقرب من الصفر.
- BYTE_STREAM_SPLIT لـ float: يقسم بايتات float32 إلى تدفقات (جميع البايتات الأولى معاً، جميع البايتات الثانية معاً، إلخ). للأسعار المتغيرة بسلاسة، يحقق ضغطاً أفضل بمقدار 2-3 أضعاف من الترميز القياسي.
- ZSTD level 9: ضغط جيد مع سرعة فك ضغط مقبولة.
- float32 بدلاً من float64: كافٍ للأسعار والأحجام، يوفر 50% من الذاكرة.
التحميل الكسول مع التخزين المؤقت
يطلب الحفر بيانات الثانية لدقيقة محددة. تحميل ملف parquet لكل طلب بطيء. الحل — تحميل كسول مع ذاكرة تخزين مؤقت LRU حسب الشهر.
from functools import lru_cache
import pyarrow.parquet as pq
import pandas as pd
class AdaptiveDataLoader:
"""
Lazy loader with cache: loads second data by month,
keeps the last N months in memory.
"""
def __init__(self, symbol: str, data_dir: str = "data", cache_months: int = 2):
self.symbol = symbol
self.data_dir = data_dir
self.cache_months = cache_months
self._cache_1s: dict[str, pd.DataFrame] = {}
def load_1s_for_minute(self, minute_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Load 1s data for a specific minute."""
month_key = minute_ts.strftime("%Y-%m")
if month_key not in self._cache_1s:
self._load_month_1s(month_key)
if month_key not in self._cache_1s:
return None
df = self._cache_1s[month_key]
minute_start = minute_ts.floor('1min')
minute_end = minute_start + pd.Timedelta(minutes=1)
return df[(df.index >= minute_start) & (df.index < minute_end)]
def load_100ms_for_second(self, second_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Load 100ms data for a hot second."""
month_key = second_ts.strftime("%Y-%m")
path = f"{self.data_dir}/{self.symbol}/klines_100ms_hot/{month_key}.parquet"
try:
df = pd.read_parquet(path)
second_start = second_ts.floor('1s')
second_end = second_start + pd.Timedelta(seconds=1)
return df[(df.index >= second_start) & (df.index < second_end)]
except FileNotFoundError:
return None
def _load_month_1s(self, month_key: str):
"""Load a month of 1s data, evict old data from cache."""
path = f"{self.data_dir}/{self.symbol}/klines_1s/{month_key}.parquet"
try:
df = pd.read_parquet(path)
df.index = pd.to_datetime(df['timestamp'], unit='s')
if len(self._cache_1s) >= self.cache_months:
oldest = min(self._cache_1s.keys())
del self._cache_1s[oldest]
self._cache_1s[month_key] = df
except FileNotFoundError:
pass
تطبيق الحفر على الاختبار الرجعي
الدمج في حلقة الاختبار الرجعي:
def backtest_with_adaptive_fill(
states: pd.DataFrame,
strategy_params: dict,
data_loader: AdaptiveDataLoader,
) -> list:
"""
Backtest with adaptive drill-down for fill simulation.
"""
fill_sim = AdaptiveFillSimulator(data_loader)
trades = []
position = None
for i in range(len(states)):
row = states.iloc[i]
ts = states.index[i]
candle_1m = {
'open': row['open'], 'high': row['high'],
'low': row['low'], 'close': row['close'],
'timestamp': ts,
}
if position is not None:
fill = fill_sim.check_fill(
ts, candle_1m,
position['sl'], position['tp'],
position['side'],
)
if fill is not None:
fill_type, fill_price = fill
trades.append({
'entry_time': position['entry_time'],
'exit_time': ts,
'side': position['side'],
'entry_price': position['entry_price'],
'exit_price': fill_price,
'exit_type': fill_type,
'drill_down': fill_sim.last_drill_depth, # 0, 1, or 2
})
position = None
continue
signal = check_entry_signal(row, strategy_params)
if signal and position is None:
position = {
'side': signal['side'],
'entry_price': row['close'],
'entry_time': ts,
'sl': signal['sl'],
'tp': signal['tp'],
}
return trades
العلاقة مع ذاكرة التخزين المؤقت للحالة المتدحرجة
الحفر يُكمّل ذاكرة التخزين المؤقت المجمعة لـ Parquet — فهما يحلان مشكلات مختلفة:
| ذاكرة الحالة المتدحرجة | الحفر التكيفي | |
|---|---|---|
| الغرض | قيم مؤشرات الإطار الزمني الأعلى الصحيحة | ترتيب تنفيذ SL/TP الدقيق |
| يعمل على | كل شمعة 1m | فقط أثناء غموض التنفيذ (~5%) |
| البيانات | محسوبة مسبقاً، مخزنة بشكل دائم | تحميل كسول، ذاكرة مؤقتة للأشهر الأخيرة |
| يؤثر على | إشارات الدخول/الخروج | سعر ووقت التنفيذ |
كلا النهجين يزيلان أخطاء غير مرئية على مستوى الشمعة اليومية لكنها حاسمة للاختبار الرجعي الواقعي.
الملخص: مقارنة أساليب محاكاة التنفيذ
| النهج | الدقة | السرعة | التخزين |
|---|---|---|---|
| استدلال OHLC (متفائل/متشائم) | منخفضة | فورية | 1m فقط |
| اختبار رجعي كامل 1s | عالية | بطيء (x60) | ~550 ميغابايت/شهر |
| اختبار رجعي كامل 100ms | عالية جداً | بطيء جداً (x600) | ~5 غيغابايت/شهر |
| اختبار رجعي كامل للصفقات الخام | أقصى | بطيء للغاية | ~50 غيغابايت/شهر |
| الحفر التكيفي (4 مستويات) | أقصى | ~فوري | 1m + 1s + 100ms ساخن + صفقات ساخنة |
الحفر يوفر دقة الاختبار الرجعي الكامل بـ 1s بسرعة اختبار رجعي بـ 1m. الملاحظة الأساسية: الدقة العالية ليست مطلوبة في كل مكان — فقط عند نقاط اتخاذ القرار.
الحفر المبني على الحجم
الحفر الأصلي كان يُفعّل فقط بناءً على حركة السعر — عندما يكون نطاق [low, high] للشمعة واسعاً بما يكفي لخلق غموض تنفيذ. لكن السعر ليس الإشارة الوحيدة على حدوث شيء مثير داخل الشريط.
ارتفاعات الحجم هي محفز بنفس الأهمية. ثانية يكون فيها الحجم 500 ضعف الوسيط عادةً تتوافق مع أمر سوق كبير، أو سلسلة تصفية، أو انهيار مفاجئ. حتى لو بدا جسم الشمعة صغيراً، فإن مسار السعر الفعلي خلال تلك الثانية ربما كان عنيفاً — ملامساً لأطراف يخفيها تمثيل OHLC.
شرط الحفر أصبح الآن مبنياً على OR: إما حركة سعر كبيرة أو ارتفاع حجم غير طبيعي يُفعّل النزول إلى دقة أدق.
def is_hot(bar, median_volume, min_pct=0.1, vol_mult=500):
"""
Determines if a bar warrants drill-down to the next level.
Two independent triggers (OR logic):
- price moved >= min_pct within the bar
- volume exceeded median * vol_mult
"""
price_move = (bar['high'] - bar['low']) / bar['open'] * 100
return price_move >= min_pct or bar['volume'] >= median_volume * vol_mult
هذا يلتقط سيناريوهات غير مرئية لكشف السعر فقط: شريط بافتتاح=3000، إغلاق=3001 لكن بحجم 50,000 ضعف المعتاد ربما لامس 2950 و3050 لفترة وجيزة خلال ميلي ثوانٍ. بدون الحفر المبني على الحجم، لن يفحص الاختبار الرجعي هذه الثانية عن كثب.
الصفقات الخام: المستوى الرابع
التسلسل الهرمي الأصلي من ثلاثة مستويات (1m -> 1s -> 100ms) لا يزال يترك فجوة: داخل دلو 100ms واحد، يمكن تنفيذ صفقات متعددة بأسعار مختلفة. لدلو بأعلى=3060 وأدنى=2965، لا نزال لا نعرف التسلسل الدقيق.
الحل: الحفر إلى الصفقات الخام كمستوى رابع ونهائي.
شموع 1m (القاعدة)
└─> شموع 1s (عندما تُظهر 1s أن price_move >= min_pct أو volume >= median_1s * vol_mult)
└─> شموع 100ms (عند كشف ثانية ساخنة)
└─> الصفقات الخام (عندما تُظهر 100ms أن price_move >= min_pct أو volume >= median_100ms * vol_mult)
على مستوى الصفقات الخام، لا يوجد غموض — كل صفقة لها سعر وطابع زمني دقيق. يتم حل التنفيذ بشكل نهائي:
def resolve_from_trades(trades, sl_price, tp_price, side):
"""
Walk through individual trades in chronological order.
The first trade that crosses SL or TP determines the fill.
"""
for trade in trades:
price = trade['price']
if side == 'long':
if price <= sl_price:
return ('sl', price)
if price >= tp_price:
return ('tp', price)
else: # short
if price >= sl_price:
return ('sl', price)
if price <= tp_price:
return ('tp', price)
return None
مستوى الصفقات الخام يُستدعى نادراً للغاية — أقل من 0.1% من جميع الأشرطة — لكن عندما يُستدعى، يوفر الحقيقة المطلقة التي لا يمكن لأي تقريب مبني على الشموع مطابقتها.
عتبات منفصلة لكل انتقال
لانتقالات الدقة المختلفة خصائص مختلفة. حركة سعر بنسبة 0.1% خلال ثانية ذات مغزى؛ نفس 0.1% خلال دلو 100ms هي متطرفة. وبالمثل، تختلف توزيعات الحجم في كل مقياس زمني.
كل انتقال مستوى لديه الآن معاملات min_pct وvol_mult خاصة به:
1s → 100ms: --min-pct-1s 0.1 --vol-mult-1s 500
100ms → trades: --min-pct-100ms 0.1 --vol-mult-100ms 500
يتيح هذا ضبط حساسية كل انتقال بشكل مستقل. في الممارسة العملية، يمكن لانتقال 100ms إلى الصفقات استخدام عتبة أضيق لأن تكلفة تحميل الصفقات الخام لدلو 100ms واحد ضئيلة.
@dataclass
class DrillDownConfig:
min_pct_1s: float = 0.1
vol_mult_1s: float = 500
min_pct_100ms: float = 0.1
vol_mult_100ms: float = 500
إحصائيات الوسيط الدائمة
الحفر المبني على الحجم يتطلب معرفة حجم التداول الوسيط في كل مقياس زمني. حساب الأوساط أثناء التشغيل لكل اختبار رجعي سيلغي فوائد الأداء. الحل: حساب الأوساط مرة واحدة مسبقاً وتخزينها مؤقتاً.
لكل رمز، يتم حساب أحجام التداول الوسيطة بدقة 1s و100ms من البيانات التاريخية وتخزينها في ملف stats.json:
{
"ETHUSDT": {
"median_volume_1s": 12.5,
"median_volume_100ms": 1.8
},
"BTCUSDT": {
"median_volume_1s": 0.45,
"median_volume_100ms": 0.06
}
}
يتم حساب الإحصائيات مرة واحدة لكل رمز عند تنزيل البيانات لأول مرة وإعادة استخدامها في جميع الاختبارات الرجعية اللاحقة. إذا تم تحديث البيانات (تنزيل أشهر جديدة)، يتم إعادة حساب الإحصائيات بشكل تراكمي.
def compute_median_stats(symbol, data_dir):
"""Compute and cache median volume stats for a symbol."""
stats_path = f"{data_dir}/{symbol}/stats.json"
all_1s = load_all_months(f"{data_dir}/{symbol}/klines_1s/")
median_1s = all_1s['volume'].median()
all_100ms = load_all_months(f"{data_dir}/{symbol}/klines_100ms_hot/")
median_100ms = all_100ms['volume'].median()
stats = {
"median_volume_1s": float(median_1s),
"median_volume_100ms": float(median_100ms),
}
with open(stats_path, 'w') as f:
json.dump(stats, f, indent=2)
return stats

دعم البورصات المتعددة: Bybit
ليست جميع الرموز متاحة على Binance. لأصول مثل XAUTUSDT (الذهب)، يجب أن تأتي البيانات من بورصات أخرى. يدعم نظام الحفر الآن Bybit كمصدر بيانات بديل.
لرموز Bybit، يتم بناء جميع مستويات الشموع (1m، 1s، 100ms) والصفقات الخام من تدفق الصفقات الخام لـ Bybit. العملية هي نفسها — يتم تجميع الصفقات الخام في شموع على كل مقياس زمني — لكن مصدر البيانات يختلف.
data/{SYMBOL}/
├── source.json # {"exchange": "bybit"} or {"exchange": "binance"}
├── klines_1m/
│ └── ...
├── klines_1s/
│ └── ...
├── klines_100ms_hot/
│ └── ...
└── trades_hot/ # Raw trades for hot 100ms buckets
└── ...
يتحقق محمّل البيانات من source.json ويستخدم خط أنابيب التنزيل المناسب. من منظور محرك الاختبار الرجعي، يكون تنسيق البيانات متطابقاً بغض النظر عن البورصة المصدر — منطق الحفر لا يعتمد على البورصة.
هذا مهم بشكل خاص لاستراتيجيات البورصات المتعددة أو الرموز التي تتداول حصرياً في أماكن معينة.
الخلاصة
الحفر التكيفي هو تطبيق لمبدأ بسيط: إنفاق الموارد الحسابية والتخزين بما يتناسب مع أهمية البيانات.
أربعة مستويات دقة:
- 1m — المرور الأساسي لـ 95% من الأشرطة
- 1s — حفر أثناء غموض التنفيذ أو ارتفاعات الحجم
- 100ms — حفر للثواني الساخنة ذات الحركة الشديدة أو الحجم غير الطبيعي
- الصفقات الخام — حفر لدلاء 100ms الساخنة، حل التنفيذ على مستوى الصفقة الفردية
أربعة مستويات تخزين:
- كل 1m — أرشيف كامل، ~15 ميغابايت لعامين
- كل 1s — أرشيف كامل أو تكيفي، ~550 ميغابايت/شهر
- 100ms ساخن فقط — <1% من الثواني، ~50 ميغابايت/شهر
- صفقات ساخنة فقط — صفقات خام لأكثر دلاء 100ms تطرفاً
محفزا حفر (منطق OR):
- مبني على السعر: نطاق سعر الشريط يتجاوز
min_pct - مبني على الحجم: حجم الشريط يتجاوز
median * vol_mult
النتيجة: اختبار رجعي بدقة محاكي التكات بسرعة مستوى الدقيقة. تخزين ينمو خطياً وليس أسياً. ودعم لبورصات متعددة — Binance وBybit — مع منطق حفر لا يعتمد على البورصة.
لمزيد من المعلومات حول ذاكرة التخزين المؤقت المحسوبة مسبقاً لاستراتيجيات الإطارات الزمنية المتعددة، انظر مقال ذاكرة التخزين المؤقت المجمعة لـ Parquet. حول تأثير معدلات التمويل على النتائج مع الرافعة المالية العالية — معدلات التمويل تقتل رافعتك المالية.
روابط مفيدة
- Apache Parquet — data storage format
- Apache Arrow — BYTE_STREAM_SPLIT encoding
- Zstandard — compression algorithm
- Lopez de Prado — Advances in Financial Machine Learning
- Binance — Historical Market Data
Citation
@article{soloviov2026adaptivedrilldown,
author = {Soloviov, Eugen},
title = {Adaptive Drill-Down: Backtest with Variable Granularity from Minutes to Raw Trades},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/adaptive-resolution-drill-down-backtest},
description = {How adaptive data granularity speeds up backtests and saves storage: drill-down from 1m to 1s, 100ms, and raw trades only where price moved significantly or volume spiked.}
}
MarketMaker.cc Team
البحوث والاستراتيجيات الكمية
Read More

ذاكرة التخزين المؤقت المجمعة لـ Parquet: كيف تُسرّع الاختبارات الرجعية متعددة الأُطُر الزمنية بمئات المرات

تحسين المشي للأمام: الاختبار الصادق الوحيد للاستراتيجية
