Monte Carlo Bootstrap: How to Get Confidence Intervals for a Backtest in 10 Lines of Code
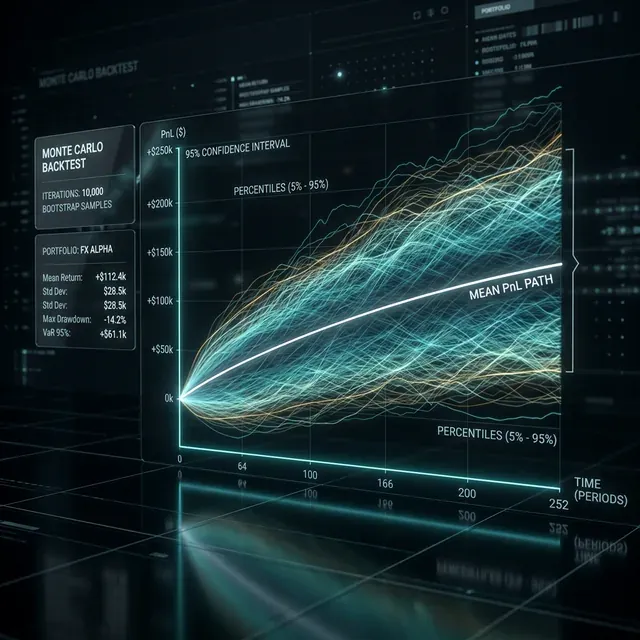
You ran a strategy through a backtest. You got PnL +42%, Sharpe 1.8, MaxDD -12%. The results look great. You launch the bot in production, and a month later you discover that the drawdown is already -28% and PnL is heading toward zero.
What went wrong? It is not a bug and not "a changed market." The issue is that you made a decision based on a single number — a single-point estimate. You learned that the strategy showed +42%, but you did not learn how much you can trust that number.
The Problem with Single-Point Estimates
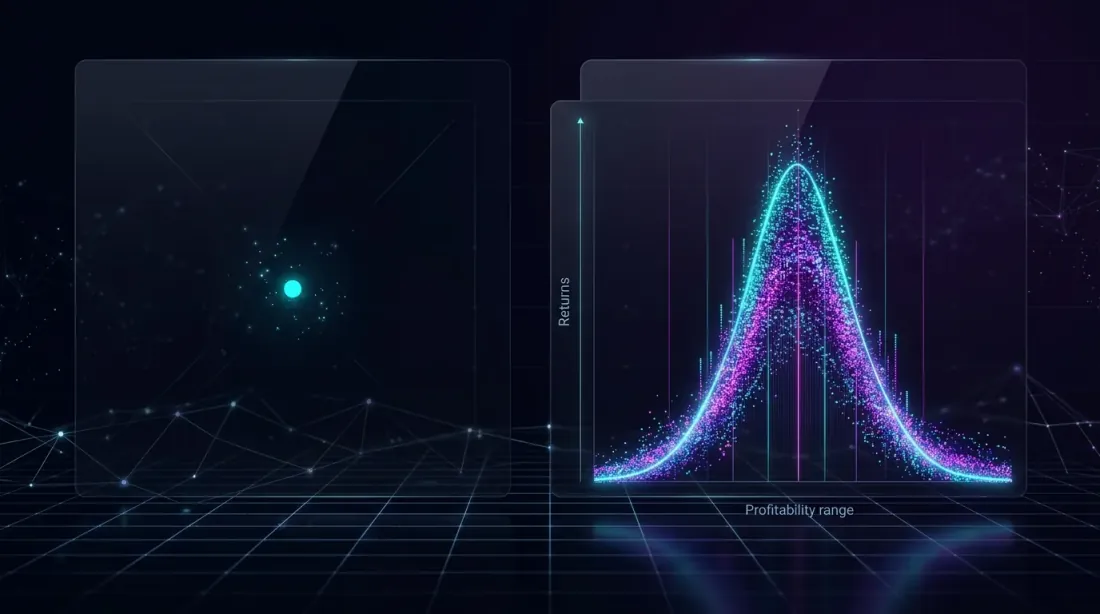 A single data point (left) gives a misleading picture, while the full distribution (right) reveals the true range of possible outcomes.
A single data point (left) gives a misleading picture, while the full distribution (right) reveals the true range of possible outcomes.
A backtest on historical data is one run through one specific sequence of market events. The result depends on the order of trades: the same strategy with the same trades, but in a different order, can show an entirely different maximum drawdown.
Imagine 491 trades. Each trade is a random event with a certain return distribution. The historical backtest shows only one realization of this process. It is like rolling a die once and concluding that the die always lands on four.
What we actually need:
- Not a point estimate, but an interval: "with 95% probability, the final PnL will be between X and Y"
- Not a single maximum drawdown, but a distribution: "in the 5% worst scenarios, the drawdown exceeds Z%"
- Not the mean, but the tails: what happens if luck is not on your side?
This is exactly what Monte Carlo bootstrap is for.
What Is Monte Carlo Bootstrap
 Bootstrap generates thousands of alternative equity trajectories by resampling trades with replacement from the original dataset.
Bootstrap generates thousands of alternative equity trajectories by resampling trades with replacement from the original dataset.
Bootstrap is a resampling method proposed by Bradley Efron in 1979. The idea is elegant: if we have a data sample, we can generate thousands of "new" samples by randomly selecting elements from the original with replacement.
In the context of a backtest, it works like this:
- You have an array of returns for each trade — for example, 491 values
- You randomly select 491 values from this array with replacement — some trades will appear twice, some will not appear at all
- You build an equity curve from this new sample
- You repeat 10,000 times
- You get a distribution of final metrics, not a single number
Each iteration is one "alternative scenario": what could have happened if the order and set of trades had been slightly different.
Implementation in 10 Lines
Here is a complete working implementation:
import numpy as np
def max_drawdown(equity_curve):
"""Calculate the maximum drawdown of an equity curve."""
peak = np.maximum.accumulate(equity_curve)
drawdown = (equity_curve - peak) / peak
return drawdown.min()
trade_returns = [...] # 491 values, e.g. [0.012, -0.005, 0.008, ...]
n_simulations = 10000
results = []
for _ in range(n_simulations):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
results.append({
"final_pnl": equity[-1] - 1,
"max_dd": max_drawdown(equity),
"sharpe": np.mean(sampled) / np.std(sampled) * np.sqrt(252)
})
Execution time: ~2 seconds on a regular laptop. 10,000 alternative histories of your strategy.
Extracting Confidence Intervals
 Confidence intervals for key strategy metrics: PnL, MaxDD, and Sharpe Ratio, showing the 5th (worst), 50th (median), and 95th (best) percentile bands.
Confidence intervals for key strategy metrics: PnL, MaxDD, and Sharpe Ratio, showing the 5th (worst), 50th (median), and 95th (best) percentile bands.
Now we have not one number, but a distribution. Here is how to extract useful information from it:
import pandas as pd
df = pd.DataFrame(results)
pnl_5 = np.percentile(df['final_pnl'], 5)
pnl_50 = np.percentile(df['final_pnl'], 50)
pnl_95 = np.percentile(df['final_pnl'], 95)
dd_5 = np.percentile(df['max_dd'], 5) # 5th — worst case
dd_50 = np.percentile(df['max_dd'], 50)
dd_95 = np.percentile(df['max_dd'], 95) # 95th — best case
print(f"PnL: {pnl_5:.1%} | {pnl_50:.1%} | {pnl_95:.1%}")
print(f"MaxDD: {dd_5:.1%} | {dd_50:.1%} | {dd_95:.1%}")
print(f"Sharpe: {np.percentile(df['sharpe'], 5):.2f} — {np.percentile(df['sharpe'], 95):.2f}")
Example output for a real strategy:
| Metric | 5th percentile (worst) | Median | 95th percentile (best) |
|---|---|---|---|
| PnL | +18.3% | +41.7% | +72.1% |
| MaxDD | -23.4% | -12.8% | -5.1% |
| Sharpe | 1.12 | 1.76 | 2.41 |
Now the difference is obvious:
- The backtest showed PnL +42% — but in the 5% worst scenarios, PnL is only +18.3%
- The backtest showed MaxDD -12% — but in the 5% worst scenarios, the drawdown is -23.4%
- Sharpe 1.8 — but the lower bound is 1.12
The 5th percentile is your "realistic worst case." If the strategy stops being profitable at the 5th percentile, launching it in production is risky.
Visualization: Fan Chart
Monte Carlo bootstrap is naturally visualized as a fan chart — a fan of equity curves:
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
ax = axes[0]
for i in range(min(500, n_simulations)):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
ax.plot(equity, alpha=0.02, color='#4FC3F7')
all_equities = []
for _ in range(n_simulations):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
all_equities.append(equity)
all_equities = np.array(all_equities)
p5 = np.percentile(all_equities, 5, axis=0)
p50 = np.percentile(all_equities, 50, axis=0)
p95 = np.percentile(all_equities, 95, axis=0)
ax.fill_between(range(len(p5)), p5, p95, alpha=0.3, color='#7C4DFF', label='90% CI')
ax.plot(p50, color='#E040FB', linewidth=2, label='Median')
ax.set_title('Monte Carlo Bootstrap: Equity Curves')
ax.legend()
ax = axes[1]
ax.hist(df['final_pnl'] * 100, bins=80, color='#4FC3F7', alpha=0.7, edgecolor='#1A237E')
ax.axvline(pnl_5 * 100, color='#FF5252', linestyle='--', label=f'5th: {pnl_5:.1%}')
ax.axvline(pnl_50 * 100, color='#E040FB', linestyle='--', label=f'Median: {pnl_50:.1%}')
ax.axvline(pnl_95 * 100, color='#69F0AE', linestyle='--', label=f'95th: {pnl_95:.1%}')
ax.set_title('Distribution of Final PnL')
ax.set_xlabel('PnL, %')
ax.legend()
plt.tight_layout()
plt.savefig('monte_carlo_fan_chart.png', dpi=150)
plt.show()
A fan chart provides an intuitive understanding of the spread of possible outcomes. A narrow fan means the strategy is stable. A wide fan means the result heavily depends on "luck" with the sequence of trades.
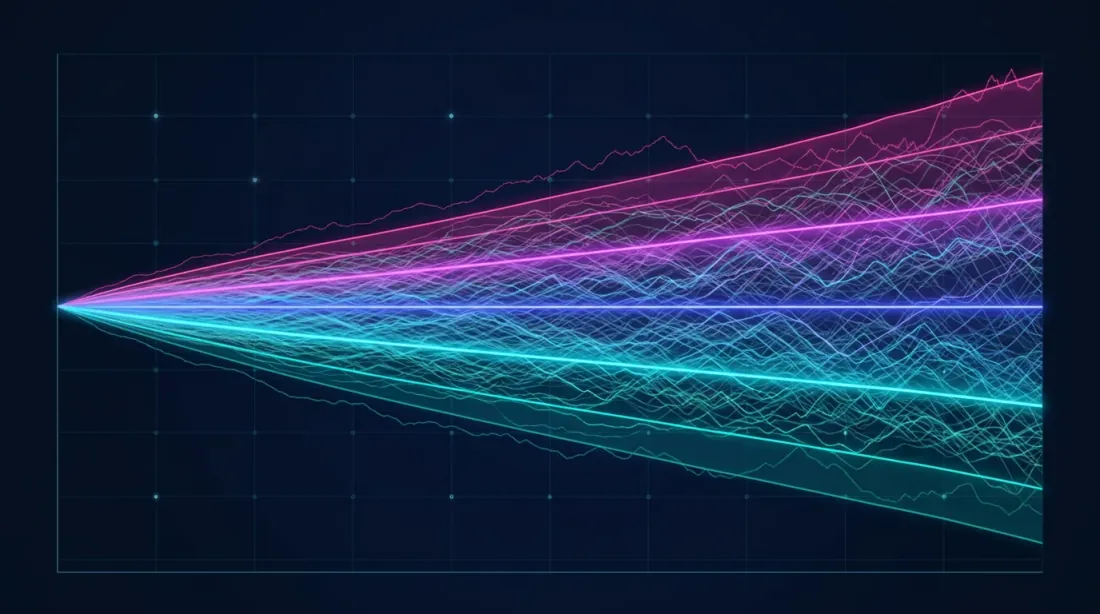 The fan chart (left) shows the spread of possible equity trajectories, and the histogram (right) shows the density distribution of final returns with highlighted confidence intervals (5%, 50%, 95%).
The fan chart (left) shows the spread of possible equity trajectories, and the histogram (right) shows the density distribution of final returns with highlighted confidence intervals (5%, 50%, 95%).
Advanced Analysis: Probability of Ruin
 Probability of ruin visualization: surviving equity paths (cyan) curve upward while ruined paths (red) drop below the zero-equity cliff edge.
Probability of ruin visualization: surviving equity paths (cyan) curve upward while ruined paths (red) drop below the zero-equity cliff edge.
Bootstrap allows you to answer a critical question: what is the probability that the strategy will lose X% of capital?
ruin_threshold = -0.20
prob_ruin = (df['max_dd'] < ruin_threshold).mean()
print(f"P(MaxDD < -20%) = {prob_ruin:.1%}")
prob_loss = (df['final_pnl'] < 0).mean()
print(f"P(PnL < 0) = {prob_loss:.1%}")
worst_5pct = df['final_pnl'].quantile(0.05)
cvar = df[df['final_pnl'] <= worst_5pct]['final_pnl'].mean()
print(f"CVaR(5%) = {cvar:.1%}")
These metrics are impossible to obtain from a single backtest run. Yet they are critical for making the decision to launch a strategy.
For more on why deep drawdowns are mathematically dangerous and how return asymmetry works, read our article Loss-Profit Asymmetry.
When Classical Bootstrap Does Not Work
The method has limitations that are important to know.
Autocorrelation of Returns
Classical bootstrap assumes that trades are independent. In reality, this is often not the case — a strategy can have winning and losing streaks. If autocorrelation is significant, use block bootstrap:
def block_bootstrap(returns, block_size=10, n_simulations=10000):
"""Bootstrap preserving local dependency structure."""
n = len(returns)
results = []
for _ in range(n_simulations):
starts = np.random.randint(0, n - block_size + 1, size=n // block_size + 1)
sampled = np.concatenate([returns[s:s+block_size] for s in starts])[:n]
equity = np.cumprod(1 + sampled)
results.append({
"final_pnl": equity[-1] - 1,
"max_dd": max_drawdown(equity),
})
return pd.DataFrame(results)
Block bootstrap preserves local dependencies between consecutive trades, providing more realistic confidence intervals for MaxDD.
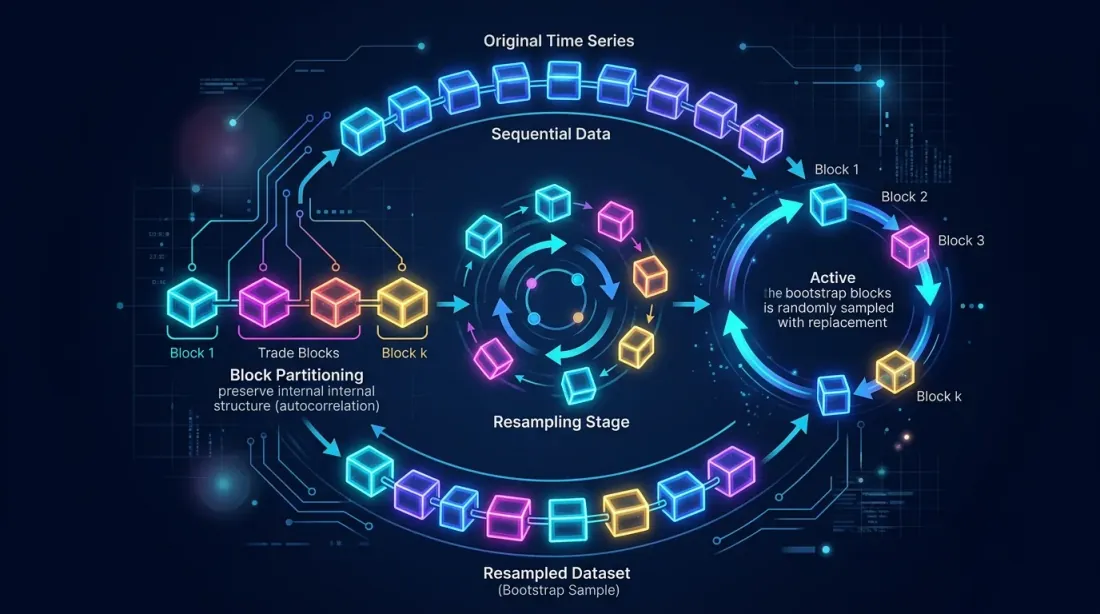 Block bootstrap preserves autocorrelation within blocks by partitioning the trade sequence into blocks and resampling them with replacement.
Block bootstrap preserves autocorrelation within blocks by partitioning the trade sequence into blocks and resampling them with replacement.
Market Non-Stationarity
Bootstrap works with the original trade distribution. If the market has structurally changed (e.g., volatility dropped or liquidity changed), historical trades may be unrepresentative. To account for this:
- Use a rolling window: bootstrap only on the last N trades
- Weight recent trades more heavily: weighted bootstrap
- Split data by market regimes and bootstrap separately
Small Number of Trades
Bootstrap is reliable when n > 30 trades. If you have 10 trades — no amount of resampling will help. 491 trades is an excellent sample; you can trust the results.
Comparison of Approaches to Backtest Robustness Assessment
| Method | What it provides | Complexity | Time | When to use |
|---|---|---|---|---|
| Single backtest | One point estimate | Minimal | Seconds | Never as a final result |
| Walk-forward | Out-of-sample metrics | Medium | Minutes | To check for overfitting |
| Monte Carlo bootstrap | Confidence intervals | Minimal | ~2 sec | Always before production |
| Monte Carlo path | New price paths | High | Minutes-hours | For stress testing |
| Cross-validation | Average metrics across folds | Medium | Minutes | For parameter tuning |
Monte Carlo bootstrap is the only method that in minimal time provides a complete picture of risks.
Checklist: Interpreting Results
Here is how we recommend interpreting Monte Carlo bootstrap results:
Launch in production if:
- PnL at the 5th percentile is positive
- MaxDD at the 5th percentile is acceptable for your risk appetite
- Probability of ruin < 1%
- Sharpe at the 5th percentile > 0.5
Needs work if:
- PnL at the 5th percentile is near zero
- MaxDD at the 5th percentile is significantly worse than at the 50th
- Wide fan chart spread — the strategy is unstable
Do not launch if:
- PnL at the 5th percentile is negative
- Probability of ruin > 5%
- Confidence interval for Sharpe includes 0
Our Experience at marketmaker.cc
At marketmaker.cc, we develop our own backtest engine, and Monte Carlo bootstrap is an integral part of our pipeline. Every strategy goes through bootstrap automatically before being approved for live trading.
We integrated bootstrap directly into the backtest engine: after a run, you get not just the final PnL, but a complete report with confidence intervals, fan chart, probability of ruin, and a comparison of block vs. standard bootstrap. This takes an additional 2-3 seconds — a negligible price for understanding real risks.
From our experience: approximately 30% of strategies that look attractive by single-point estimate are filtered out after Monte Carlo bootstrap. Their 5th percentile PnL goes negative or MaxDD turns out to be unacceptable. Without bootstrap, these strategies would have gone to production and would have very likely resulted in losses.
Conclusion
Monte Carlo bootstrap is ~10 lines of code and ~2 seconds of computation. It transforms a single number from a backtest into a full distribution with confidence intervals. This is perhaps the highest ROI of any quantitative analysis tool:
- Minimal cost: implementation in 30 minutes
- Maximum payoff: understanding of real strategy risks
- No dependencies: only NumPy
If you are not yet using bootstrap — add it to your pipeline today. It is the only way to know how much you can trust your backtest results.
References
- Efron, B. — Bootstrap Methods: Another Look at the Jackknife (1979)
- Davison, A.C., Hinkley, D.V. — Bootstrap Methods and their Application (Cambridge)
- Aronson, D.R. — Evidence-Based Technical Analysis: Monte Carlo permutation
- QuantStart — Monte Carlo Simulation for Backtest Analysis
- Marcos Lopez de Prado — Advances in Financial Machine Learning, Chapter 12: Backtesting
- Kevin Davey — Building Winning Algorithmic Trading Systems: Monte Carlo Analysis
- NumPy — numpy.random.choice
Citation
@software{soloviov2026montecarlobootstrap,
author = {Soloviov, Eugen},
title = {Monte Carlo Bootstrap: How to Get Confidence Intervals for a Backtest in 10 Lines of Code},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/monte-carlo-bootstrap-backtest},
version = {0.1.0},
description = {Why a single-point estimate from a backtest is a dangerous illusion. How Monte Carlo bootstrap in 2 seconds of computation gives you a 95\% confidence interval for PnL and MaxDD, and why this is a mandatory step before launching a strategy in production.}
}
MarketMaker.cc Team
Investigación Cuantitativa y Estrategia
Read More

PnL by Active Time: The Metric That Changes Strategy Rankings

Adaptive Drill-Down: Backtest with Variable Granularity from Minutes to Raw Trades
