Aggregated Parquet Cache: How to Speed Up Multi-Timeframe Backtests by Hundreds of Times

A multi-timeframe strategy uses several timeframes simultaneously: the daily determines trend direction, the hourly identifies entry points, and the 5-minute pinpoints execution timing. Each timeframe requires its own indicators: moving averages, oscillators, levels.
For a single backtest, everything is straightforward — recalculate timeframes from minute data, compute indicators, run the strategy. But during mass optimization — when you need to test thousands of parameter combinations — recalculating timeframes and indicators on every iteration becomes a bottleneck. A single pass through minute data over two years means processing over a million bars, and repeating this a thousand times is wasteful.
The solution: precompute everything once and cache it in a parquet file.
The Problem: Redundant Computations During Optimization
A typical multi-timeframe backtest pipeline looks like this:
for params in parameter_grid:
df_1m = load_candles("ETHUSDT", "1m", start, end)
df_5m = resample_ohlcv(df_1m, "5m")
df_1h = resample_ohlcv(df_1m, "1h")
df_4h = resample_ohlcv(df_1m, "4h")
df_1d = resample_ohlcv(df_1m, "D")
ma_1h = compute_ma(df_1h["close"], length=params["ma_1h_len"])
ma_4h = compute_ma(df_4h["close"], length=params["ma_4h_len"])
ma_1d = compute_ma(df_1d["close"], length=params["ma_1d_len"])
result = run_strategy(df_1m, ma_1h, ma_4h, ma_1d, params)
On every iteration, steps 1-3 are recomputed even though the data is the same. Only the strategy threshold parameters change (step 4). It's like rebuilding an entire house every time you just want to try a different wall color.
The Idea: Compute Once, Save, Reuse Many Times
The key observation: timeframes and indicators depend only on minute data and indicator parameters, not on strategy parameters. If we fix the set of required indicators, we can compute them once and save them.
The scheme:
Step 1 (once):
Minute candles -> Timeframe resampling -> Indicator computation -> Parquet file
Step 2 (many times):
Parquet file -> Strategy with different parameters -> Result
Emulating Timeframes from Minute Candles
We have a complete archive of minute candles. From it, we can accurately reproduce any higher timeframe. But there's a nuance: with a standard resample, we get one row per period (one row per hour, one per 4 hours, etc.). This doesn't work for minute-by-minute backtesting — we need to know the indicator value at every minute.
Therefore, we emulate higher timeframe values for each minute candle, modeling how the bot sees data in real time:
- The bot receives the next minute candle
- Updates the current (unclosed) bar of the higher timeframe — recalculates High, Low, Close, Volume
- Recomputes the indicator across all closed bars plus the current partial bar
- When the period ends — the bar is finalized and a new one begins
This approach guarantees that the backtest sees exactly the same data as the bot in real time. No looking into the future — each minute candle is processed strictly with the data that would have been available at that moment.
class RunningCandleBuffer:
"""
Emulates real-time updates of a higher timeframe bar
using 1-minute candles.
"""
def __init__(self, period_seconds: int):
self.period = period_seconds # 86400 for Daily, 3600 for 1h
self.closed_bars = []
self.current_bar = None
def update(self, timestamp, open_, high, low, close, volume):
bar_start = self._align_to_period(timestamp)
if self.current_bar is None or bar_start != self.current_bar['start']:
if self.current_bar is not None:
self.closed_bars.append(self.current_bar)
self.current_bar = {
'start': bar_start,
'open': open_, 'high': high,
'low': low, 'close': close,
'volume': volume,
}
else:
self.current_bar['high'] = max(self.current_bar['high'], high)
self.current_bar['low'] = min(self.current_bar['low'], low)
self.current_bar['close'] = close
self.current_bar['volume'] += volume
return self.closed_bars + [self.current_bar]
A separate RunningCandleBuffer is created for each higher timeframe. On every minute candle, all buffers are updated, giving us the current state of each timeframe — as if the bot were running in real time.
Parquet Cache Structure
The precomputation result is a single parquet file where each row corresponds to one minute candle, and columns contain:
timestamp — minute candle timestamp
open, high, low, — minute candle OHLCV
close, volume
close_5m — Close of the emulated 5m candle at this moment
close_1h — Close of the emulated 1h candle
close_4h — Close of the emulated 4h candle
close_1d — Close of the emulated daily candle
ma_20_1h — MA(20) on 1h, recalculated at this minute
ma_50_1h — MA(50) on 1h
ma_20_4h — MA(20) on 4h
ma_50_4h — MA(50) on 4h
ma_6_1d — MA(6) on Daily
ma_12_1d — MA(12) on Daily
cross_ma_1h — MA crossover signal on 1h ('buy'/'sell'/None)
cross_ma_4h — MA crossover signal on 4h
cross_ma_1d — MA crossover signal on Daily
separation_1h — MA divergence in % on 1h
separation_4h — MA divergence in % on 4h
separation_1d — MA divergence in % on Daily
Each value reflects the actual state of the indicator at the moment of the corresponding minute candle — accounting for unclosed bars of higher timeframes.
Precompute: Building the Cache
def precompute_cache(
df_1m: pd.DataFrame,
timeframes: dict[str, int], # {"5m": 300, "1h": 3600, "4h": 14400, "D": 86400}
indicators: dict, # {"ma_20": 20, "ma_50": 50}
) -> pd.DataFrame:
"""
Single pass through all minute candles.
Returns a DataFrame with emulated timeframes and indicators.
"""
buffers = {tf: RunningCandleBuffer(secs) for tf, secs in timeframes.items()}
n = len(df_1m)
result = {}
for tf_name, buf in buffers.items():
closes = np.zeros(n)
ma_values = {name: np.full(n, np.nan) for name in indicators}
for i in range(n):
row = df_1m.iloc[i]
bars = buf.update(
df_1m.index[i],
row['open'], row['high'], row['low'], row['close'], row['volume']
)
all_closes = [b['close'] for b in bars]
closes[i] = all_closes[-1]
for ind_name, length in indicators.items():
if len(all_closes) >= length:
ma_values[ind_name][i] = np.mean(all_closes[-length:])
result[f'close_{tf_name}'] = closes
for ind_name in indicators:
result[f'{ind_name}_{tf_name}'] = ma_values[ind_name]
cache_df = pd.DataFrame(result, index=df_1m.index)
cache_df = pd.concat([df_1m[['open', 'high', 'low', 'close', 'volume']], cache_df], axis=1)
return cache_df
cache = precompute_cache(
df_1m,
timeframes={"5m": 300, "1h": 3600, "4h": 14400, "D": 86400},
indicators={"ma_20": 20, "ma_50": 50, "ma_6": 6, "ma_12": 12},
)
cache.to_parquet("cache_ETHUSDT_2024_2026.parquet")
Using the Cache During Optimization
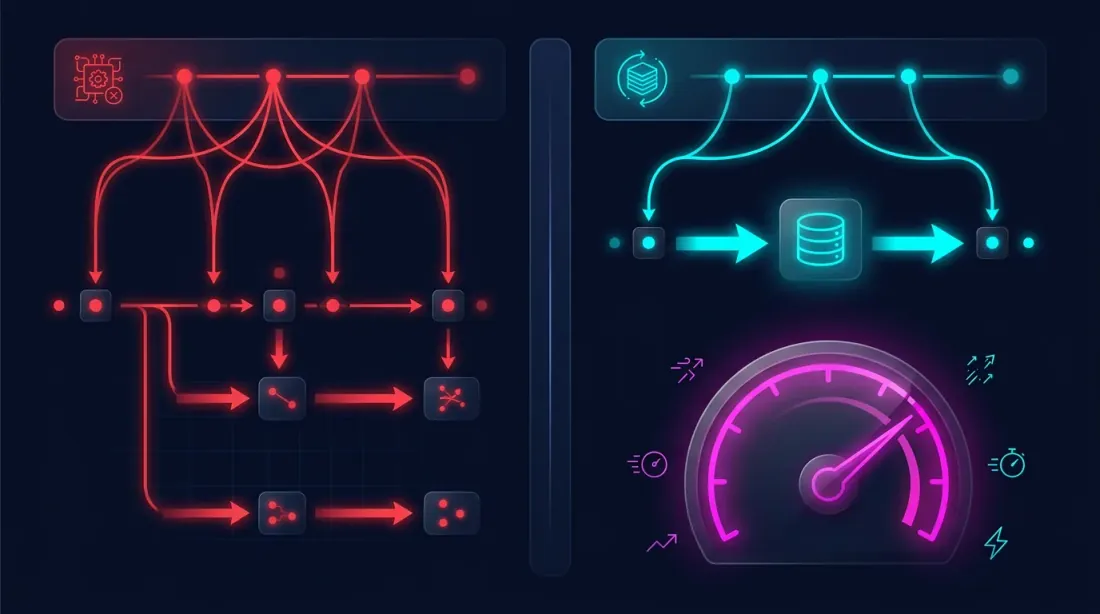
Now optimization looks like this:
cache = pd.read_parquet("cache_ETHUSDT_2024_2026.parquet")
for params in parameter_grid:
result = run_strategy(cache, params)
The strategy works with pre-built columns — no repeated passes through a million bars, no MA recalculations, no timeframe emulation. Just reading from a DataFrame and checking entry/exit conditions.
Why Parquet
Parquet is a columnar data storage format, optimal for this task:
- Compression. Parquet compresses numerical data 5-10x. A cache of 1.1 million rows with 30 columns takes ~50 MB instead of ~500 MB in CSV.
- Columnar reading. If the strategy only uses
ma_20_4handma_50_4h, parquet reads only those columns, skipping the rest. - Type preservation. Data types (float64, int64, string) are preserved losslessly — no need to parse strings on load.
- Read speed. Loading parquet into pandas takes tens of milliseconds, an order of magnitude faster than CSV.
Extending the Cache: Adding New Indicators
If the strategy requires a new indicator (RSI, MACD, Bollinger Bands), simply:
- Recompute only the new indicator from the same minute data
- Add the columns to the existing parquet file
- All previously computed columns remain untouched
cache = pd.read_parquet("cache_ETHUSDT_2024_2026.parquet")
rsi_cols = compute_rsi_for_timeframes(df_1m, timeframes, length=14)
cache = pd.concat([cache, rsi_cols], axis=1)
cache.to_parquet("cache_ETHUSDT_2024_2026.parquet")
Summary: Approach Comparison
| Naive Approach | Aggregated Cache | |
|---|---|---|
| Timeframe resampling | Every iteration | Once |
| Indicator computation | Every iteration | Once |
| Time per iteration | Minutes | Less than a second |
| 1000 iterations | Days | Minutes |
| Memory consumption | Load 1m + recompute | Single DataFrame |
| Backtest-live parity | Depends on implementation | Guaranteed (emulation = real-time) |
Conclusion
The aggregated parquet cache approach solves two problems simultaneously:
-
Correctness. Timeframe emulation from minute candles via RunningCandleBuffer guarantees that the backtest sees the same data as the bot in real time — no looking into the future and no artificial delays.
-
Speed. Precomputed timeframes and indicators allow testing thousands of parameter combinations in minutes instead of days.
The idea is simple: compute once — reuse many times. Minute candles are the source data. Everything else is derived and can be precomputed and cached. Parquet makes this cache compact, fast, and convenient.
For more on how to improve fill simulation accuracy with adaptive drill-down from minutes to seconds and milliseconds, see the article Adaptive drill-down: backtest with variable granularity.
Useful Links
- Apache Parquet — data storage format
- pandas — working with parquet
- Lopez de Prado — Advances in Financial Machine Learning
- Ernest Chan — Quantitative Trading
Citation
@article{soloviov2026parquetcache,
author = {Soloviov, Eugen},
title = {Aggregated Parquet Cache: How to Speed Up Multi-Timeframe Backtests by Hundreds of Times},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/parquet-cache-multitimeframe-backtest},
description = {How to precompute timeframes and indicators from minute candles, save them to parquet, and use them for mass strategy testing without redundant recalculations.}
}
MarketMaker.cc Team
Recherche quantitative et stratégie
Read More

Adaptive Drill-Down: Backtest with Variable Granularity from Minutes to Raw Trades

Walk-Forward Optimization: The Only Honest Strategy Test
