トレーディングボット保護のための異常検知:Z-ScoreからTransformerまで

暗号資産取引所でトレーディングボットを運用したことがある人なら、誰もがこの感覚を知っているだろう。ボットは1週間完璧に動作し、その後30秒で1週間分の利益を吹き飛ばす。ある取引所でのフラッシュクラッシュ。板の中の偽の壁。清算カスケード。あるいは、取引所が単にゴミデータを返しただけ。
これらの状況には共通点がある——すべて異常(アノマリー)だということだ。そしてボットがそれらを認識できなければ、遅かれ早かれその犠牲者になる。
暗号資産トレーディングにおける異常とは何か
異常を追いかける前に、何を探しているのかを合意する必要がある。機械学習では3種類を区別しており、そのすべてが暗号資産市場で日常的に発生している。
点異常(Point anomalies) ——正常値から急激に逸脱する孤立したイベント。平均の50倍の出来高を持つローソク足。BinanceのBTC/USDTスプレッドが0.5%に急騰。マーケットメイキングボットにとって、このようなイベントはそれぞれ潜在的な罠である:偽の価格でポジションに入るか、マージン全体を食い尽くすスリッページを被る。
集合異常(Collective anomalies) ——個々には正常に見えるが、集約すると問題を示すイベントの連続。典型的な例はスプーフィング:誰かが数分間にわたって大きな指値注文を出しては取り消す。個々の注文は普通だが、注文対約定比率が100:1の「発注-取消-発注-取消」パターンは相場操縦であり、板の厚みに依存するボットは存在しない流動性で取引することになる。
文脈異常(Contextual anomalies) ——間違った文脈における正常な値。ロンドンセッションに典型的なBitcoinの取引量が、日曜のUTC午前3時に観測された場合。文脈を考慮しなければ、このような異常は見えない——そしてこれらこそが基本的な検出器をすり抜けることが最も多いものだ。
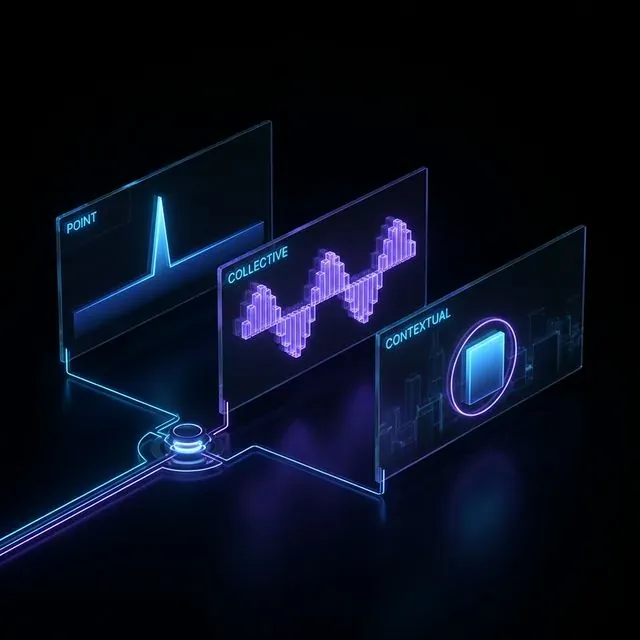 トレーディングデータにおける3つの主要な異常タイプの可視化:点的スパイク、集合的パターン、文脈的逸脱。
トレーディングデータにおける3つの主要な異常タイプの可視化:点的スパイク、集合的パターン、文脈的逸脱。
ノイズ vs 異常:文脈の問題
異常とは単なる「奇妙なデータ」ではない。それは情報を持つ逸脱である。以下を区別することが重要だ:
- ノイズ:正常な市場レジームの一部であるランダムな変動。
- ドリフト:市場状態の漸進的な変化(例:低ボラティリティの夜間から活発な朝への移行)。
- 異常:予想されるパターンの突然の違反。
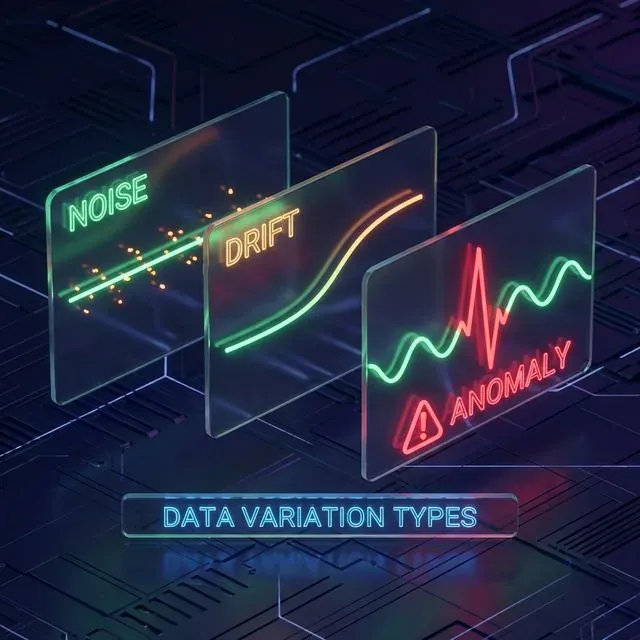 無害なノイズ、持続的なドリフト、危険な異常の違いを判断することは、あらゆる検出器にとっての重要な課題である。
無害なノイズ、持続的なドリフト、危険な異常の違いを判断することは、あらゆる検出器にとっての重要な課題である。
問題の80%を解決するシンプルな手法
すべてをニューラルネットワークで解決する必要はない。ほとんどのトレーディングボットには3つの基本的な検出器で十分だ。
Z-Score:高速な極値フィルター
Z-Scoreは、現在の値が移動平均からどれだけの標準偏差分逸脱しているかを示す。マイクロ秒で計算でき、あらゆるタイムフレームで機能する。
3つのタスクに使用する:異常出来高フィルタリング(Z-Score > 3 ——スプレッド拡大またはクォーティング一時停止のシグナル)、スプレッド監視(異常なbid-askの拡大は急激な動きの前兆であることが多い)、先物ファンディングレート(極端な値は清算カスケードの可能性を警告する)。
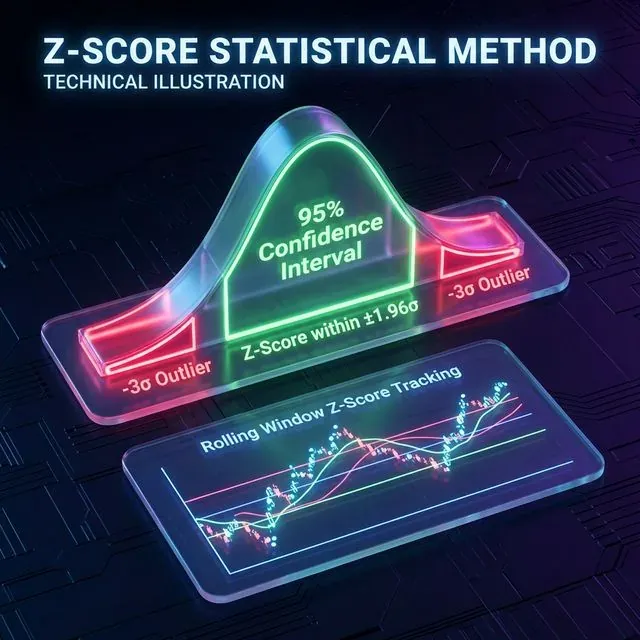 Z-Scoreは、ある点が平均からどれだけの標準偏差離れているかを測定することで極端なイベントを特定する。ほとんどのトレーディングシステムでは±3σを超える値が外れ値として扱われる。
Z-Scoreは、ある点が平均からどれだけの標準偏差離れているかを測定することで極端なイベントを特定する。ほとんどのトレーディングシステムでは±3σを超える値が外れ値として扱われる。
重要な制限:暗号資産市場はファットテール分布を持つ。正規分布では100万年に1度しか起きないはずのイベント(6σ)が、暗号資産では毎月起きる。したがってZ-Scoreは粗い異常フィルターであり、最終的な判断ではない。
レベルシフト検出器:市場がレジームを変えるとき
連続する2つのローリングウィンドウを取り、その平均を比較する。差が閾値を超えたら、レベルシフトが発生したということだ。マーケットメイキング戦略は安定した市場で利益を出し、急激な動きの時に損失を出す。出来高とボラティリティに対するレベルシフト検出器は、価格で明らかになる数分前にレジームチェンジを警告する。
複数の指標に同時に適用する:平均約定サイズ、板の最初の5段階の厚み、単位時間あたりの約定数。レベルシフトが少なくとも2つの指標でトリガーされたら、ボットは防御モードに切り替わる。
ボラティリティシフト検出器:嵐を感知する
同様のアプローチだが、平均の代わりに標準偏差を比較する。ボラティリティの急上昇はパラメータを再検討するシグナルだ。興味深いパターン:異常に低いボラティリティは爆発的な動きの前兆であることが多い。ボラティリティシフト検出器は圧縮と拡大の両方のケースを捉える。
 レベルシフトとボラティリティシフト検出器は、「レジームチェンジ」——異なるトレーディングパラメータを必要とする市場行動の突然の構造的変化——を特定するための鍵となる。
レベルシフトとボラティリティシフト検出器は、「レジームチェンジ」——異なるトレーディングパラメータを必要とする市場行動の突然の構造的変化——を特定するための鍵となる。
HBOS:高速な多次元分析
複雑なMLのコストなしに10以上の指標を同時に監視する必要がある場合、HBOS(Histogram-Based Outlier Selection) が最適な選択だ。特徴量の独立性を仮定し、各特徴量のヒストグラムを構築する。異常スコアは全ヒストグラムの逆密度の積となる。
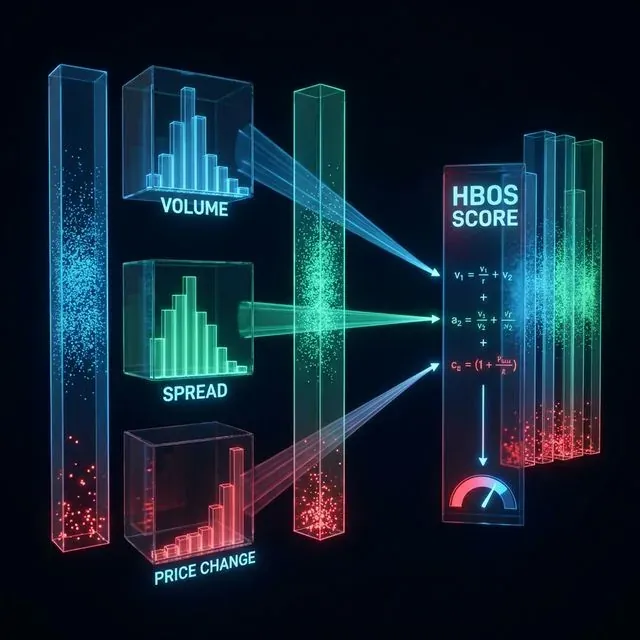 HBOSはLOFなどの距離ベースの手法よりも大幅に高速であり、多次元状態ベクトルの高頻度フィルタリングに適している。
HBOSはLOFなどの距離ベースの手法よりも大幅に高速であり、多次元状態ベクトルの高頻度フィルタリングに適している。
機械学習:統計では不十分な場合
基本的な手法は一度に1つの指標を扱う。しかし実際の異常は、指標の異常な組み合わせとして現れることが多い:出来高は正常、スプレッドは正常、しかし出来高+スプレッド+価格変化率+板の不均衡が合わさると異常となる。ここでMLが必要になる。
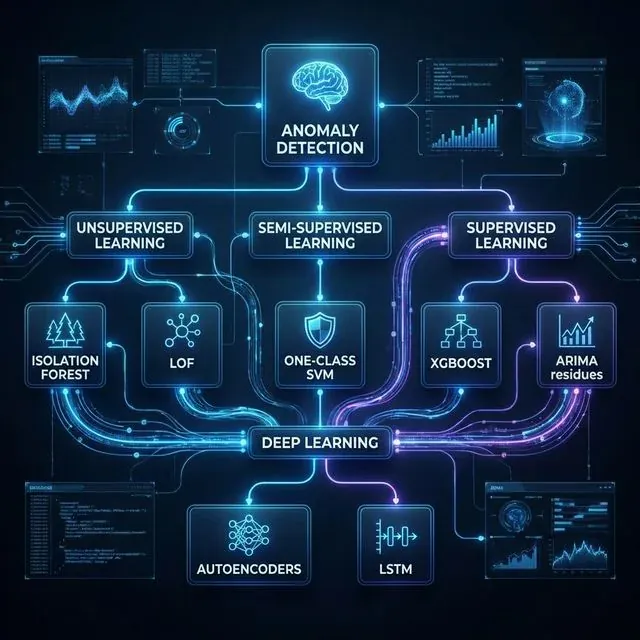 異常検知手法の体系的な全体像:古典的な教師なしアルゴリズムからディープラーニングアーキテクチャまで。
異常検知手法の体系的な全体像:古典的な教師なしアルゴリズムからディープラーニングアーキテクチャまで。
Isolation Forest:本番環境に最適なバランス
すべてのML異常検知手法の中で、Isolation Forestがトレーディングシステムに最も適している。このアルゴリズムは特徴空間をランダムに分割する決定木のアンサンブルを構築する。異常な点は「まれで異なる」ため、より少ない分割で孤立される。
なぜIsolation Forestなのか?ラベル付きデータが不要である——暗号資産市場での異常のラベリングは事実上不可能で、フラッシュクラッシュはそれぞれユニークだからだ。ミリ秒単位の高速推論により、ほぼリアルタイムでの使用が可能だ。そして本番環境にとって重要なのは、SHAP値で予測を説明できること——ある瞬間が異常であることを知るだけでなく、なぜ異常なのかを理解できる。
Bitcoinデータにおいて、Isolation Forestは2021年にTeslaがBTC決済を拒否した際のボラティリティスパイクのような明らかな異常だけでなく、微妙なもの——価格変動が出来高に裏付けられていない期間、つまり外部からの操縦を示すもの——も検出した。スプーフィングの分析では、SHAPは不均衡な板のクォートと異常に高いキャンセル活動が主要な指標であることを示している。
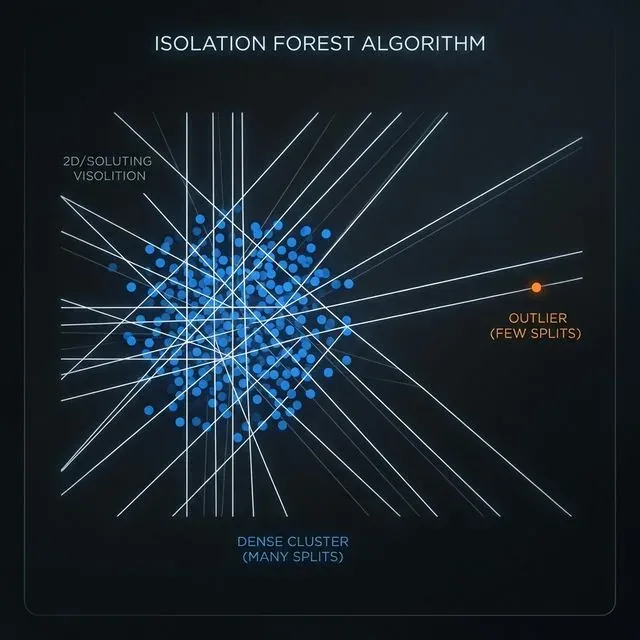 Isolation Forestアルゴリズムは空間をランダムに分割することで機能する:外れ値は密なクラスター内の点よりも大幅に少ない分割で孤立される。
Isolation Forestアルゴリズムは空間をランダムに分割することで機能する:外れ値は密なクラスター内の点よりも大幅に少ない分割で孤立される。
LOF:マルチ取引所監視に最適な選択
Local Outlier Factorは、あるポイントの局所密度をその近傍の密度と比較することで異常度を評価する。暗号資産データでLOF、Isolation Forest、One-Class SVMを比較した研究(Springer, 2024)では、LOFが最も効果的であることが判明した——最も少ない偽陽性で実際の異常を発見し、BitcoinとDogecoinの両方で安定したパフォーマンスを示した。
マルチ取引所インフラストラクチャにとってLOFが重要な理由は何か?異なる取引所のデータは異なる「密度」を持つ——Binanceは毎秒数千の約定があり、ニッチな取引所は数十だ。Z-Scoreのようなグローバルな手法はニッチな取引所で偽陽性を出すか、大きな取引所で異常を見逃す。LOFは局所的な文脈に適応する。
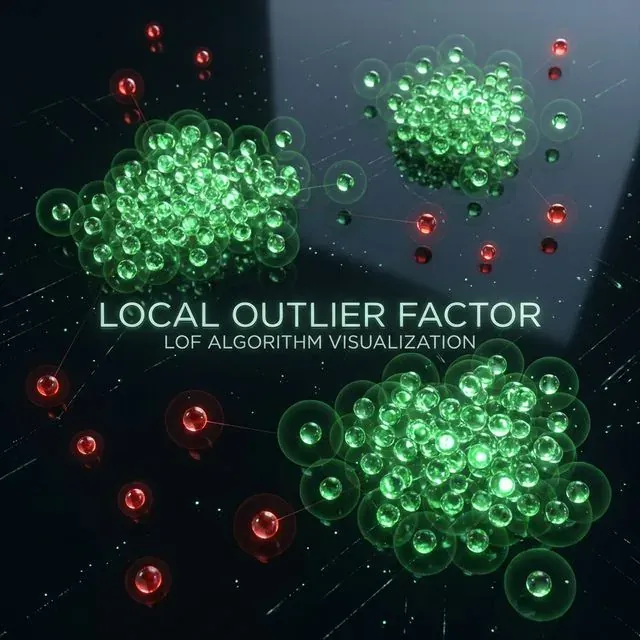 LOFはある点の局所密度をその近傍と比較する。これにより、グローバルなデータパターンと一致していても「局所的に」異常な外れ値を見つけることができる。
LOFはある点の局所密度をその近傍と比較する。これにより、グローバルなデータパターンと一致していても「局所的に」異常な外れ値を見つけることができる。
制限はポイント数に対する二次の計算量である。ティックレベルのリアルタイムデータには遅すぎるが、100以上の取引所の分足集計には理想的だ。
オートエンコーダ:板の深層分析
オートエンコーダは、データをコンパクトな表現に圧縮し再構成するニューラルネットワークだ。「正常な」データで訓練され、高い再構成誤差が異常を示す。
板の分析にはこれが最も強力なツールだ。20のbidレベルと20のaskレベルを持つ板は、毎秒数百回更新される40次元のベクトルだ。LSTMオートエンコーダは現在の状態だけでなく、ダイナミクス——過去Nティックで板がどう変化したか——も考慮する。「LSTMオートエンコーダ+One-Class SVM」のハイブリッドアプローチは関心事を分離する:ニューラルネットワークは特徴抽出を、古典的MLは意思決定を担当する。主な欠点は計算コスト:リアルタイム推論にはGPUが必要だ。
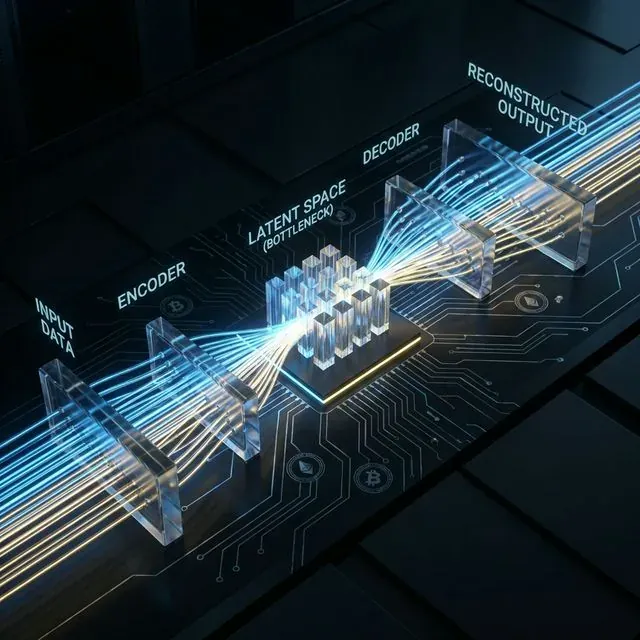 オートエンコーダは正常データの圧縮された「潜在」表現を学習する。異常は正確に再構成できず、検出に使用される高い誤差スコアとなる。
オートエンコーダは正常データの圧縮された「潜在」表現を学習する。異常は正確に再構成できず、検出に使用される高い誤差スコアとなる。
カスケードアーキテクチャ:すべてを統合する
単一の手法ですべての問題を解決することはできない。高速な手法は複雑な異常を見逃す。正確な手法はリアルタイムには遅すぎる。解決策は、各層が前の層が見逃したものを捉えるカスケードアーキテクチャだ。
 多層型異常検知アーキテクチャ:ミリ秒のハードリミットからバックグラウンドのディープラーニング分析まで。
多層型異常検知アーキテクチャ:ミリ秒のハードリミットからバックグラウンドのディープラーニング分析まで。
レイヤー1 ——ファストパス(1ms未満)。 出来高、スプレッド、価格変化に対するZ-Score。パーシステンスチェック。ハードリミット。トリガー時——即座に取引停止。このレイヤーはフラッシュクラッシュ、APIエラー、粗い操縦から保護する。外部依存なしでボットのメインループに実装される。
レイヤー2 ——ニアリアルタイム(1~100ms)。 複合特徴に対するIsolation Forest。レベルシフトおよびボラティリティシフト検出器。トリガー時——取引モードの切替、パラメータの調整。並列スレッドで実行。
レイヤー3 ——バックグラウンド分析(1~60秒)。 マルチ取引所データに対するLOF。板の状態に対するLSTMオートエンコーダ。季節分解の残差分析。トリガー時——アラート、戦略パラメータの調整。
レイヤー4 ——バッチ分析(毎時/毎日)。 ウォッシュトレーディング検出のためのDBSCAN。クロス取引所相関監視のためのPCA。完全なモデル再訓練。出力——レポート、モデル更新、前のレイヤーの閾値再キャリブレーション。
各レイヤーは独立して動作する。レイヤー3がダウンしても、レイヤー1と2がボットを保護し続ける。フォールトトレランスとグレースフルデグラデーションは、あらゆるトレーディングインフラストラクチャの必須特性だ。
実践的な推奨事項
本番環境からのいくつかの教訓。
シンプルから始める。 Z-Score+レベルシフト+ボラティリティシフトは1日で実装できる。これで異常な市場状況による損失シナリオの大部分をカバーできる。GPUクラスターは後からでよい。
Contaminationパラメータが最も重要なハイパーパラメータ。 Isolation Forestでは異常の予想割合を定義する。暗号資産市場ではペアと取引所に応じて0.01~0.05を使用する。低すぎると実際の異常を見逃す。高すぎると偽陽性がトレーディングを麻痺させる。
固定閾値の代わりに適応的閾値を。 暗号資産市場は非定常だ。1月に機能した閾値は3月に偽陽性を生成する。EWMAを使用して閾値を更新するか、ローリングウィンドウでモデルを定期的に再訓練する。
すべての異常をログに記録する。 自動的に対応しなくても——文脈とともにラベルを保存する。1ヶ月後には教師あり学習モデルの訓練や、どの異常が損失に先行したかの分析に使えるデータセットが手に入る。
実際のインシデントでテストする。 歴史的な異常のコレクションを構築する:2021年5月のフラッシュクラッシュ、FTXの清算カスケード、LUNAの崩壊。すべての新しい検出器をこれらのシナリオで実行する。既知のインシデントを検出できなければ——役に立たない。
今後の展望
注目すべき3つの方向性。
板データ向けTransformerベースモデル。 最近の研究では、Limit Order BookデータにおけるTransformerオートエンコーダ+OC-SVMが、スプーフィング検出における従来のすべてのアプローチを大幅に上回ることが示されている。高頻度EUR/USDデータ(3億1500万レコード)に対するStaged Sliding Window Transformerは、精度0.93、F1 0.91、AUC-ROC 0.95を達成——Random Forest、LSTM、CNNを大幅に上回った。
 マルチヘッドアテンションを備えたTransformerアーキテクチャは、高頻度のLimit Order Bookデータにおける複雑な時系列パターンの特定に卓越した能力を発揮している。
マルチヘッドアテンションを備えたTransformerアーキテクチャは、高頻度のLimit Order Bookデータにおける複雑な時系列パターンの特定に卓越した能力を発揮している。
合成異常生成のためのGAN。 主な課題の1つはラベル付きデータの不足だ。GANは教師あり学習モデルの訓練用にリアルな操縦シナリオを生成できる。レイテンシ3ms未満、スループット毎秒15万トランザクションで94.7%の精度を達成するアーキテクチャがすでに存在する。
 敵対的生成ネットワーク(GAN)は、リアルな合成異常を作成することでデータセットを拡張し、トレーディングにおける重要なラベル不足問題を解決できる。
敵対的生成ネットワーク(GAN)は、リアルな合成異常を作成することでデータセットを拡張し、トレーディングにおける重要なラベル不足問題を解決できる。
変化点検出(CPD)。 単に外れ値を探すのではなく、CPDは信号の統計的性質が変化した正確な瞬間を特定することに焦点を当てる。これはマーケットメイキングのレジーム切替(例:平均回帰からトレンドフォローへの移行)にとって重要だ。
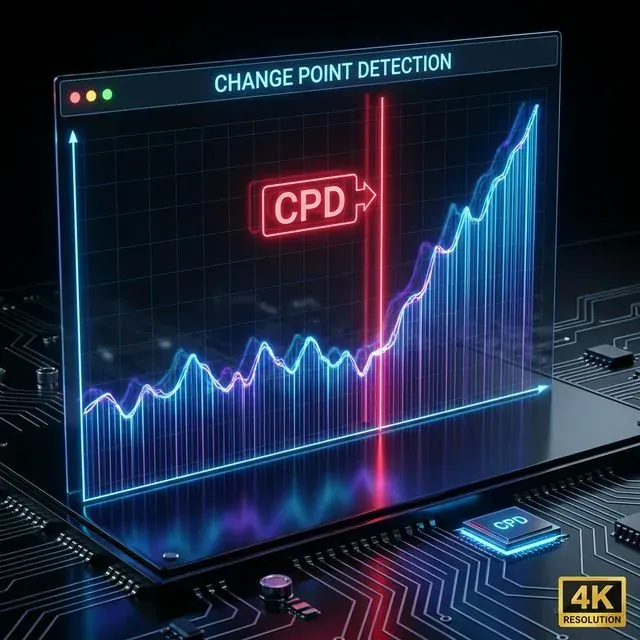 変化点検出は時系列データにおける構造的な変化を特定し、異なる市場レジーム間の境界を明確にする。
変化点検出は時系列データにおける構造的な変化を特定し、異なる市場レジーム間の境界を明確にする。
異常検知はオプション機能ではない。それはアルゴトレーディングをギャンブルにしないための基盤だ。そしてそれを早く構築すればするほど、市場があなたに教える高価な教訓は少なくなる。
参考文献
- Anomaly detection in cryptocurrency markets using Isolation Forest
- LOF: Identifying local outliers in high dimensional space
- Isolation Forest for Anomaly Detection (Sklearn Documentation)
- PyOD: A Comprehensive Python Toolbox for Outlier Detection
- Transformer-based models for Limit Order Book anomaly detection
- Ethical Issues and Market Manipulation in Cryptocurrency
引用
@software{soloviov2026anomalydetectionalgotrading,
author = {Soloviov, Eugen},
title = {Anomaly Detection for Trading Bot Protection: From Z-Score to Transformer},
year = {2026},
url = {https://marketmaker.cc/ja/blog/post/anomaly-detection-algotrading},
version = {0.1.0},
description = {Which anomaly detection methods actually work in crypto algo trading, how to build a cascading protection architecture, and why this is the foundation without which algo trading becomes gambling.}
}
MarketMaker.cc Team
クオンツ・リサーチ&戦略