アルゴリズム取引のためのQuestDB:オーダーブックから本番アーキテクチャまで

免責事項:本記事の情報は教育および情報提供のみを目的としており、金融、投資、または取引に関する助言を構成するものではありません。暗号資産の取引には重大な損失リスクが伴います。
QuestDBシリーズの最終回へようこそ。第1部ではストレージアーキテクチャを、第2部ではSQL拡張機能を解説しました。今回はそれらを統合します:リアルタイム分析のためのマテリアライズドビュー、2D配列によるネイティブなオーダーブック保存、そして本番アルゴリズム取引プラットフォームのリファレンスアーキテクチャです。
マテリアライズドビュー:ワイヤスピードで事前計算された分析
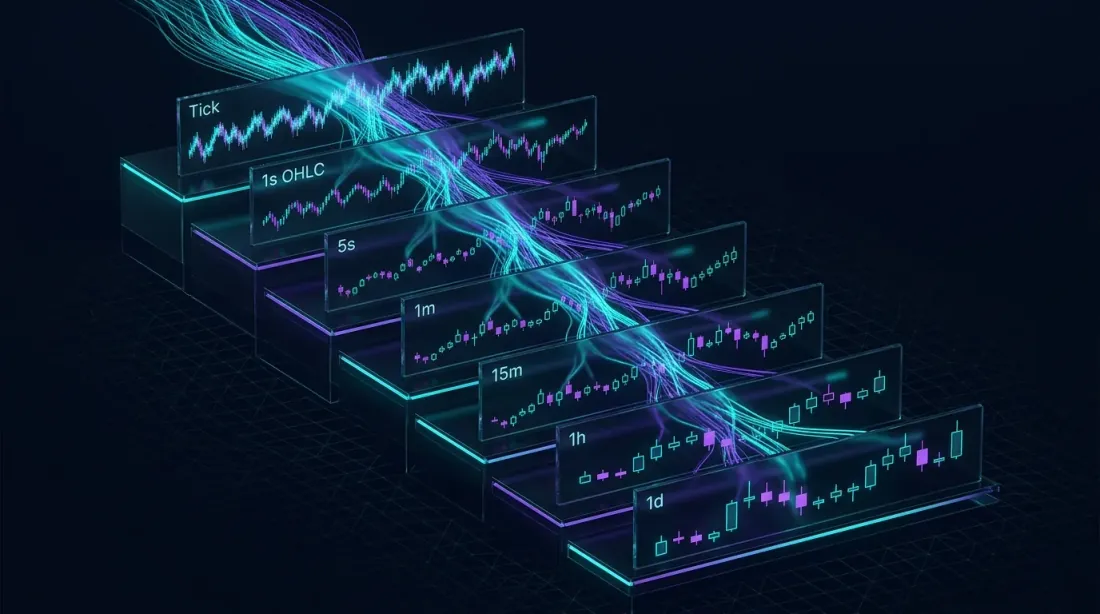 カスケードマテリアライズドビュー:生のティックデータがより粗い集約レイヤーを順次通過し、各レベルで劇的に小さなデータセットを処理する
カスケードマテリアライズドビュー:生のティックデータがより粗い集約レイヤーを順次通過し、各レベルで劇的に小さなデータセットを処理する
SAMPLE BYがQuestDBで最も使用されるクエリであるなら、マテリアライズドビューは最もインパクトのある最適化です。コンセプトはシンプルです:ダッシュボードの更新やAPIコールのたびにOHLCV集計を計算するのではなく、一度事前計算して結果を継続的に更新します。
基本的なOHLCマテリアライズドビュー
CREATE MATERIALIZED VIEW trades_OHLC_15m
WITH BASE 'trades'
REFRESH IMMEDIATE
AS
SELECT timestamp, symbol,
first(price) AS open,
max(price) AS high,
min(price) AS low,
last(price) AS close,
sum(quantity) AS volume
FROM trades
SAMPLE BY 15m;
これが定義のすべてです。tradesテーブルに新しい行が挿入されるたびに、QuestDBは自動的かつインクリメンタルにこのビューを更新します。完全な再計算ではなく、影響を受けたタイムバケットのみが更新されます。trades_OHLC_15mに対するクエリは、はるかに小さな事前集約済みデータセットに対する単純な検索になります。
パフォーマンスの差は劇的です。数十億行のテーブルで、ベーステーブルからOHLCデータをクエリすると200msかかることがあります。マテリアライズドビューは同じ結果を5ms未満で返します。複数のダッシュボードユーザーが同時にアクセスする場合、これは単なる最適化ではなく、レスポンシブなシステムとダウンしてしまうシステムの違いです。
カスケードビュー:単一ソースからのマルチタイムフレーム
マテリアライズドビューがアーキテクチャ的に美しくなるのはここです。ビューをチェーン化できます — 各ビューが次のビューにフィードし、単一の生データソースから集約レベルの階層を作成します:
-- 生の取引から1秒バー
CREATE MATERIALIZED VIEW ohlc_1s AS
SELECT timestamp, symbol,
first(price) AS open, max(price) AS high,
min(price) AS low, last(price) AS close,
sum(quantity) AS volume
FROM trades
SAMPLE BY 1s;
-- 1秒バーから5秒バー
CREATE MATERIALIZED VIEW ohlc_5s AS
SELECT timestamp, symbol,
first(open) AS open, max(high) AS high,
min(low) AS low, last(close) AS close,
sum(volume) AS volume
FROM ohlc_1s
SAMPLE BY 5s;
-- 5秒バーから1分バー
CREATE MATERIALIZED VIEW ohlc_1m AS
SELECT timestamp, symbol,
first(open) AS open, max(high) AS high,
min(low) AS low, last(close) AS close,
sum(volume) AS volume
FROM ohlc_5s
SAMPLE BY 1m;
各レベルは前のレベルよりも劇的に小さなデータセットを処理します。1分ビューは生の取引をスキャンしません — 事前集約済みの5秒バーのみを読み取ります。このカスケードパターンは任意の数のタイムフレームにスケーリングできます:1s → 5s → 1m → 5m → 15m → 1h → 4h → 1d。
100以上の取引所からデータを取り込む暗号資産データプラットフォームにとって、これはOHLC配信パイプライン全体のバックボーンです。
リフレッシュ戦略
QuestDBは3つのリフレッシュモードを提供しており、それぞれ異なるワークロードに適しています:
REFRESH IMMEDIATEは、ベーステーブルのトランザクションごとに非同期リフレッシュをトリガーします。サブ秒のレイテンシが重要なリアルタイムダッシュボードに最適です。
REFRESH EVERY 1h(タイマーベース)は、更新を定期的なリフレッシュにバッチ処理します。マイクロバッチごとにリフレッシュをトリガーするとオーバーヘッドが発生する高スループット取り込みに適しています。
REFRESH PERIOD (LENGTH 1d TIME ZONE 'Europe/London' DELAY 2h)は、カレンダーに整列した期間を定義します。「delay」は遅延到着データに対応します — 取引セッション終了後数時間経ってから訂正フィードを送信する可能性のある市場にとって重要です。
REFRESH MANUALは完全な制御を提供します。明示的にREFRESHコマンドを実行した場合のみビューが更新されます — 日次決済ワークフローに便利です。
LATEST ONアクセラレーションパターン
最も強力なパターンの1つは、マテリアライズドビューとLATEST ONを組み合わせて即時ポートフォリオスナップショットを実現するものです。13億行の生データから各シンボルの最新価格をスキャンするには数秒かかります。しかし、日次の事前集約ビューを使えば:
CREATE MATERIALIZED VIEW trades_latest_1d AS
SELECT timestamp, symbol, side,
last(price) AS price,
last(quantity) AS quantity,
last(timestamp) AS latest
FROM trades
SAMPLE BY 1d;
LATEST ONクエリは、数十億行ではなく約25,000行の事前集約データをスキャンします:
SELECT symbol, side, price, quantity, latest AS timestamp
FROM (
trades_latest_1d
LATEST ON timestamp PARTITION BY symbol, side
)
ORDER BY timestamp DESC;
数秒からミリ秒へ。これが、本番取引ダッシュボードが大規模データセット上でリアルタイムの応答性を実現する方法です。
TTL:自動データライフサイクル
マテリアライズドビューは自動データ期限のためのTTL(Time-To-Live)ポリシーをサポートしています:
CREATE MATERIALIZED VIEW ohlc_1h AS (
SELECT timestamp, symbol,
avg(price) AS avg_price
FROM trades
SAMPLE BY 1h
) PARTITION BY WEEK TTL 8 WEEKS;
これは8週間分の時間別データを保持し、古いパーティションを自動的に削除します。3層ストレージエンジンと組み合わせることで、自然なデータライフサイクルが得られます:生のティックはWAL → カラムナストレージ → オブジェクトストレージ上のParquetを通過し、マテリアライズドビューはアプリケーションが実際にクエリする事前集約済みサマリーを維持します。
2D配列:ネイティブなオーダーブック分析
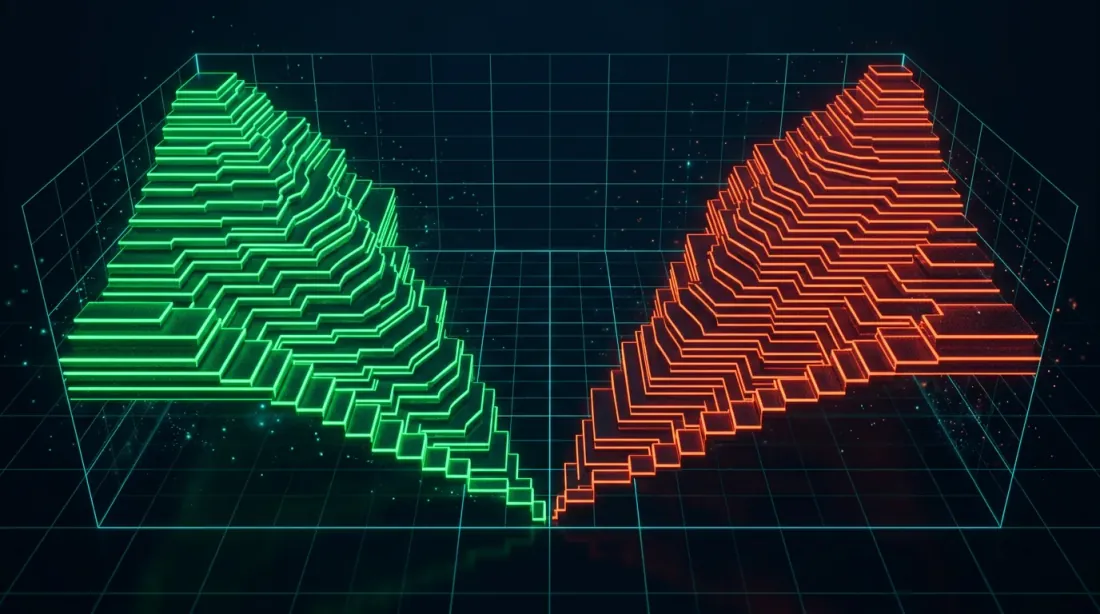 3Dオーダーブック深度:ビッドとアスクのレベルがネイティブ2D配列として保存され、SIMD最適化されたスプレッド計算と流動性分析が可能に
3Dオーダーブック深度:ビッドとアスクのレベルがネイティブ2D配列として保存され、SIMD最適化されたスプレッド計算と流動性分析が可能に
QuestDB 9.0はN次元配列を導入しました — NumPyライクな形状とストライドを持つ真の配列で、一般的な操作(スライシング、転置)をゼロコピーで処理します。取引における最強の応用はオーダーブックの保存です。
従来の問題
歴史的に、リレーショナルデータベースにオーダーブックのスナップショットを保存するのは困難でした。2つの選択肢がありました:価格レベルごとに1行(行数の爆発、深度クエリが高コスト)、またはbid1_price、bid1_size、bid2_price、bid2_sizeのような固定数のカラム(硬直的、無駄が多く、見苦しい)。
QuestDBの2D配列は両方の問題を解消します:
CREATE TABLE market_data (
timestamp TIMESTAMP,
symbol SYMBOL,
bids DOUBLE[][],
asks DOUBLE[][]
) TIMESTAMP(timestamp) PARTITION BY HOUR;
各bidsとasksカラムは、1行目に価格、2行目に各レベルの出来高を含む2D配列を保存します。20レベルのオーダーブックは1つのコンパクトな配列であり、40の個別カラムではありません。
SQLでのオーダーブック分析
スプレッド計算 — 最も基本的で最も頻繁に計算される指標:
SELECT timestamp,
spread(bids[1][1], asks[1][1]) AS spread
FROM market_data
WHERE symbol = 'EURUSD'
AND timestamp IN today();
spread()関数は、ベストアスクとベストビッドの差を計算する組み込み関数です。bids[1][1]はビッド配列の1行目(価格)の最初の要素(最良価格)にアクセスします。
より高度な分析 — 流動性の深さ、オーダーブックのインバランス、特定の価格レベルでの約定確率 — 配列スライシングとベクトル化された操作により、以前は複雑だったクエリが簡単になります:
-- ターゲット価格がヒットするレベルを見つけ、
-- そのレベルまでのすべてのボリュームを合計する
DECLARE @target := bids[1][1] * 1.01;
SELECT timestamp,
array_sum(asks[2][1:level_idx]) AS volume_to_fill
FROM market_data
WHERE symbol = 'EURUSD';
SIMD最適化された配列操作により、これらの計算は数百万のスナップショットに対してもハードウェアに近い速度で実行されます。
配列データの取り込み
QuestDBのクライアントライブラリはネイティブな配列取り込みをサポートしています。PythonクライアントはNumPy配列と直接統合します:
import numpy as np
from questdb.ingress import Sender
bids = np.array([[9.3, 9.2, 9.1], [100, 200, 150]]) # prices, volumes
asks = np.array([[9.5, 9.6, 9.7], [80, 160, 120]])
with Sender.from_conf("http::addr=localhost:9000;") as sender:
sender.row(
'market_data',
symbols={'symbol': 'EURUSD'},
columns={'bids': bids, 'asks': asks},
at=timestamp
)
Protocol Version 2は配列をバイナリ形式でエンコードし、テキストベースのプロトコルと比較して帯域幅とサーバー側の解析オーバーヘッドを劇的に削減します。高頻度のオーダーブック取り込み — シンボルあたり毎秒数千のスナップショットを受信する場合 — この効率性は重要です。
C/C++クライアントは形状記述子付きのフラットな行優先配列を使用し、既存の取引システムデータ構造からのゼロコピー取り込みを実現します。
すべてを統合する:リファレンスアーキテクチャ
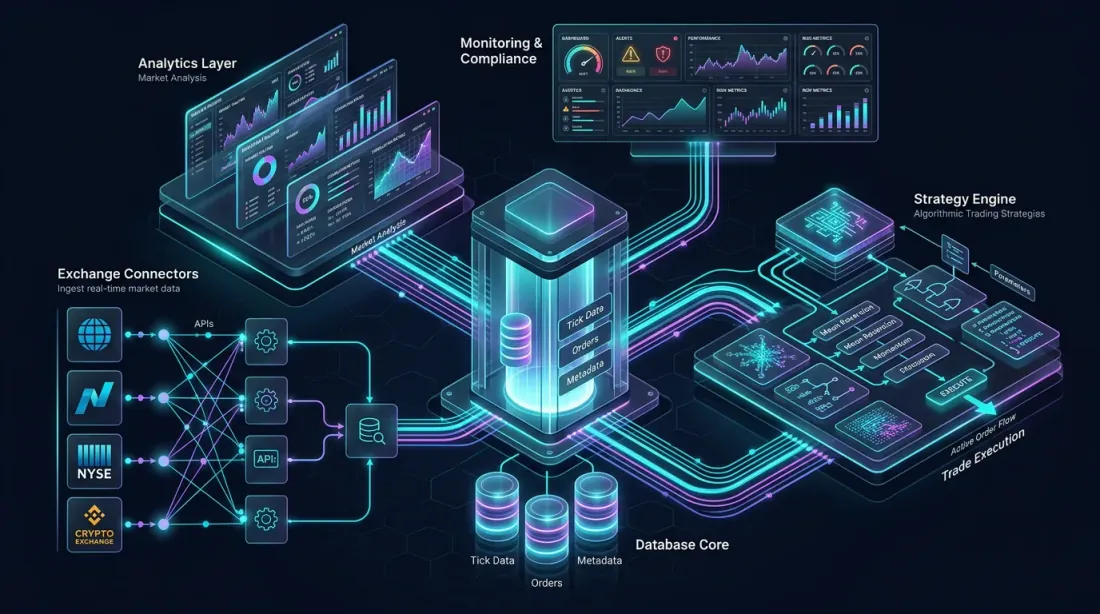 リファレンスアーキテクチャ:取引所コネクタ、カラムナデータベースコア、分析レイヤー、戦略エンジン、監視ダッシュボード — すべてが相互接続
リファレンスアーキテクチャ:取引所コネクタ、カラムナデータベースコア、分析レイヤー、戦略エンジン、監視ダッシュボード — すべてが相互接続
暗号資産市場向けの完全なQuestDBアルゴリズム取引プラットフォームを設計しましょう。このアーキテクチャは、複数の取引所からの取り込み、リアルタイム分析、バックテスト、戦略実行を処理します。
データ取り込みレイヤー
 データ取り込み:複数の取引所コネクタがWebSocketパイプラインを通じてリアルタイム市場データをILP経由でQuestDBに供給
データ取り込み:複数の取引所コネクタがWebSocketパイプラインを通じてリアルタイム市場データをILP経由でQuestDBに供給
取引所(Binance、Bybit、OKXなど)への複数のWebSocket接続が、ILP over HTTPを介して生の市場データをQuestDBに供給します。各取引所コネクタは個別のプロセスであり、分離性と耐障害性を提供します。
データストリームには以下が含まれます:取引(timestamp、symbol、side、price、quantity)、オーダーブックスナップショット(timestamp、symbol、bids[][]、asks[][])、および補助ストリームとしてのファンディングレートと清算。
取り込みスループット目標:すべての取引所を合わせて毎秒数百万行。QuestDBのWALはこれを快適に処理し、冗長な取引所接続からの不可避の重複を重複排除で捕捉します。
リアルタイム分析レイヤー
マテリアライズドビューが分析レイヤーのコアを形成します:
Raw trades → ohlc_1s → ohlc_5s → ohlc_1m → ohlc_5m → ohlc_15m → ohlc_1h → ohlc_1d
各レベルはインクリメンタルにリフレッシュされます。QuestDBのネイティブプラグインを介して接続されたGrafanaダッシュボードは、これらのビューをローソク足チャート用にクエリし、過去のデータ量に関係なく5ms未満の応答時間を実現します。
追加のマテリアライズドビューは以下を計算します:シンボルごと・日ごとのVWAP(出来高加重平均価格)、ローリングボラティリティ推定、クロス取引所スプレッドモニタリング。
事前集約ビューに対するLATEST ONクエリが、リアルタイムポートフォリオダッシュボードを駆動します — 現在のポジション、未実現損益、取引所ごとのエクスポージャーを表示します。
戦略エンジン
 戦略エンジン:リアルタイムインジケーター計算がアルゴリズム的な意思決定にフィードし、マテリアライズドビューによって最適化された売買実行パス
戦略エンジン:リアルタイムインジケーター計算がアルゴリズム的な意思決定にフィードし、マテリアライズドビューによって最適化された売買実行パス
取引戦略はQuestDBに現在の市場状態と過去のパターンをクエリします。QuestDBのPG wireプロトコルにより、PostgreSQLドライバーを持つ任意の言語が接続可能です:リサーチ戦略にはPython、レイテンシ重視の実行にはRustまたはC++。
戦略の主要クエリパターン:約定時の市場状況と執行フィルをマッチさせるASOF JOIN、各イベント周辺の短期間メトリクスを計算するWINDOW JOIN、リアルタイムインジケーター計算(RSI、ボリンジャーバンド、ATR)のためのウィンドウ関数。
レイテンシが重要な戦略では、事前計算されたマテリアライズドビューがクエリ時間を最小化します。50シンボルを監視するグリッドボットは、ティックごとに50個の個別移動平均を計算する必要はありません — マテリアライズドビューから読み取ります。
バックテストパイプライン
過去のデータはオブジェクトストレージ上のParquetに保存されます。QuestDBはこれを透過的にクエリしますが、重いバックテストワークロードの場合、データはPolars、Pandas、またはDuckDBで直接読み取ることもできます — データベースを完全にバイパスします。
このデュアルアクセスパターンは強力です:ライブ戦略はリアルタイム判断のためにQuestDBのSQLインターフェースを使用し、バックテストフレームワークはバッチ処理のためにParquet/Arrowを通じて同じデータを読み取ります。同じデータ、2つの最適化されたアクセスパス。
モニタリングとポストトレード分析
HORIZON JOINがポストトレード分析パイプラインを駆動します:
- スリッページ分析:約定価格を約定時の仲値と比較
- マークアウトカーブ:各約定後1秒、5秒、30秒、60秒の価格推移を追跡
- インプリメンテーションショートフォール:執行コストをスプレッド、一時的インパクト、恒久的インパクトに分解
- ベニュースコアリング:取引所間の約定品質を比較し、注文ルーティングを最適化
これらの分析はスケジュールクエリとして実行され、結果をモニタリングダッシュボードにフィードする専用テーブルに書き込みます。アラートルールは異常時にトリガーされます — 突然のスリッページスパイク、異常なマークアウトパターン、特定のベニューでの約定品質の劣化。
パフォーマンスに関する考慮事項
 本番パフォーマンスチューニング:レイテンシ、スループット、メモリモニタリングとホット・ウォーム・コールドデータライフサイクル
本番パフォーマンスチューニング:レイテンシ、スループット、メモリモニタリングとホット・ウォーム・コールドデータライフサイクル
本番デプロイメントからのいくつかの実践的な注意点:
パーティションサイジング:1日あたり数百万行の暗号資産ティックデータの場合、PARTITION BY HOURが一般的に最適です。個々のパーティションをストレージとクエリパフォーマンスの両方で管理可能なサイズに保ちます。
マテリアライズドビューのカスケード:中間レベルを作りすぎないでください。各レベルはリフレッシュレイテンシを追加します。ほとんどのユースケースでは、3-4レベル(1s → 1m → 15m → 1d)がクエリパフォーマンスとデータの鮮度のバランスが取れています。
重複排除のオーバーヘッド:冗長なデータソースを持つテーブルで重複排除を有効にしてください。ユニークタイムスタンプのデータではコストは最小ですが、カラムレベルの重複排除が必要な同一タイムスタンプの多数の行では増加します。
メモリ割り当て:QuestDBのゼロGCエンジンは効率的ですが、ホットパーティションと書き込みキャッシュに十分なメモリを割り当ててください。組み込みのメトリクスエンドポイントで監視します。
クライアントプロトコルの選択:取り込みにはILP over HTTPを使用します(自動リトライとヘルスチェック付き)。クエリにはPG wireを使用します。ILP Protocol Version 2(バイナリエンコーディング)は、配列データと高スループットのdouble値に対して大幅に効率的です。
QuestDB vs. 代替データベース
 競合状況:主要な機能軸でTimescaleDB、ClickHouse、InfluxDB、kdb+と比較したQuestDBのポジショニング
競合状況:主要な機能軸でTimescaleDB、ClickHouse、InfluxDB、kdb+と比較したQuestDBのポジショニング
取引で一般的に使用されるデータベースとの簡潔な位置づけ:
vs. TimescaleDB:TimescaleDBは時系列拡張機能付きのPostgreSQLです。PGの汎用性を継承しますが、オーバーヘッドも継承します。QuestDBのネイティブカラムナエンジンとSIMD実行は、時系列ワークロードで大幅に優れたクエリパフォーマンスを提供し、ASOF JOINのような機能にはTimescaleDBに直接的な等価物がありません。
vs. ClickHouse:ClickHouseは大規模データセットに対する分析クエリに優れています。しかし、時系列専用に設計されたわけではありません — ネイティブのASOF JOIN、FILLを伴うSAMPLE BY、オーダーブック用の2D配列がありません。OLAP + 時系列の混合ワークロードではClickHouseが有利かもしれませんが、純粋な取引データではQuestDBの方が使いやすいです。
vs. InfluxDB:InfluxDBにはマルチ取引所の暗号資産データで問題となる高カーディナリティの制限があります。そのクエリ言語(Flux、現在は非推奨、InfluxQL)は、QuestDBのSQL拡張機能の表現力に欠けます。大規模な過去のクエリのパフォーマンスは一般的に劣ります。
vs. kdb+/q:HFTのゴールドスタンダードです。kdb+は特定のシングルスレッドベクトル操作で高速であり、q言語は極めて簡潔です。しかし、プロプライエタリで高価であり、学習曲線が急です。QuestDBはコストの数分の一で80-90%の機能を提供し、標準SQLとオープンソースライセンスを備えています。
結論:取引を理解するデータベース
この3つの記事を通じて、QuestDBのアーキテクチャ(WAL、カラムナ、Parquetによる3層ストレージ)、SQL拡張機能(SAMPLE BY、ASOF JOIN、HORIZON JOIN、WINDOW JOIN、LATEST ON、TWAP)、そして実用的な応用(マテリアライズドビュー、オーダーブック配列、リファレンスアーキテクチャ)を解説しました。
一貫したテーマがあります:QuestDBはまさにアルゴリズム取引が生成するワークロードのために設計されました。データベースに合わせた回避策を強いることはありません — そのプリミティブが取引の概念に直接マッピングされます。OHLC集計は1行で済みます。取引と気配値の整列は単一のJOINです。ポストトレード分析はHORIZON JOINであり、複数ページのPL/SQLプロシージャではありません。
取引インフラを構築するチーム — 暗号資産市場データプラットフォーム、定量的リサーチ環境、完全なアルゴリズム取引エンジンのいずれであっても — QuestDBは真剣に評価する価値があります。オープンソース版はほとんどのユースケースをカバーし、Enterprise版は規制環境向けのギャップを埋めます。
金融データインフラの状況は急速に進化しています。市場の言語を話すデータベースが勝利するでしょう。QuestDBは流暢です。
良い取引を、そしてレイテンシが低いことを願います。
Citation
@software{soloviov2025questdb_algotrading_p3,
author = {Soloviov, Eugen},
title = {QuestDB for Algorithmic Trading: From Order Books to Production Architecture},
year = {2025},
url = {https://marketmaker.cc/en/blog/post/questdb-algotrading-production},
version = {0.1.0},
description = {Materialized views, 2D array order book analytics, and reference architecture for a QuestDB-powered algorithmic trading platform.}
}
MarketMaker.cc Team
クオンツ・リサーチ&戦略