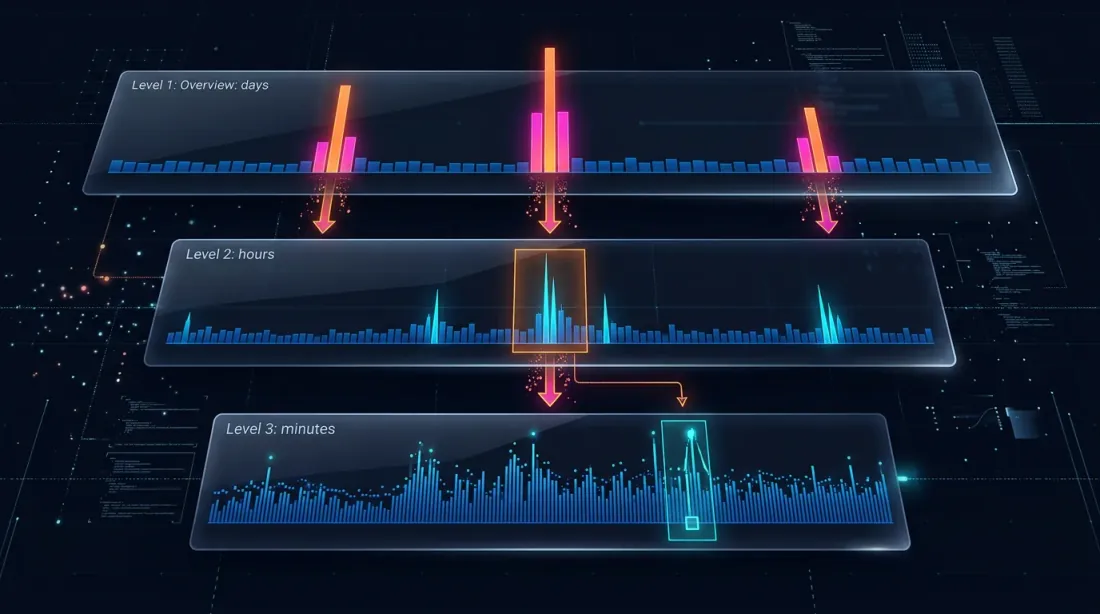
어댑티브 드릴다운: 분봉에서 원시 틱까지 가변 해상도 백테스트
분봉은 백테스트의 표준 해상도입니다. 하지만 하나의 분봉 안에서 가격은 다르게 움직일 수 있습니다: 때로는 0.01%, 때로는 2%. 스톱로스와 테이크프로핏 모두 하나의 분봉 [low, high] 범위 안에 있을 때, 백테스트는 어느 것이 먼저 트리거되었는지 알 수 없습니다. 이것이 체결 모호성 문제(fill ambiguity problem)입니다.
단순한 해결책은 백테스트 전체를 초 단위 데이터로 전환하는 것입니다. 하지만 2년에 걸쳐 약 100만 개의 분봉 대신 약 6,300만 개의 초봉이 필요합니다. 스토리지는 60배 증가하고 속도는 비례적으로 감소합니다.
어댑티브 드릴다운은 이 문제를 해결합니다: 실제로 필요한 곳에서만 세밀한 해상도를 사용합니다.
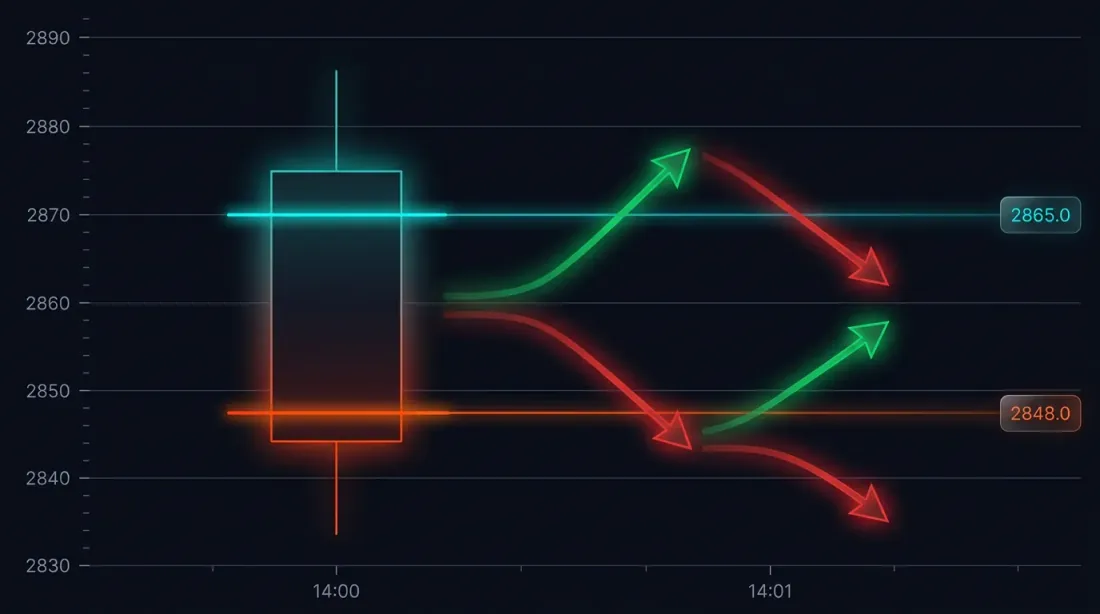
문제: 큰 캔들에서의 체결 모호성
구체적인 상황을 살펴봅시다. 전략이 3000 USDT에서 롱 포지션을 개시했습니다. 스톱로스: 2970 (-1%). 테이크프로핏: 3060 (+2%).
14:37 분봉:
- 시가: 3010
- 고가: 3065
- 저가: 2965
- 종가: 3050
SL (2970)과 TP (3060) 모두 범위 [2965, 3065] 안에 있습니다. 어느 것이 먼저 트리거되었을까요?
가능한 결과:
- 가격이 먼저 하락 -> SL 트리거 -> -1% 손실
- 가격이 먼저 상승 -> TP 트리거 -> +2% 수익
한 번의 거래에서의 차이: 3 퍼센트 포인트. 10배 레버리지로는 30%. 수백 건의 거래가 포함된 백테스트에서 잘못된 체결 모호성 해소는 결과를 체계적으로 왜곡합니다.
프레임워크의 기본 처리 방식
대부분의 백테스트 엔진은 두 가지 휴리스틱 중 하나를 사용합니다:
- 낙관적: TP가 먼저 트리거 -> 부풀려진 결과
- 비관적: SL이 먼저 트리거 -> 축소된 결과
두 접근 방식 모두 추측입니다. 초 단위 또는 밀리초 단위의 실제 데이터가 이용 가능하며, 확인할 수 있는데 추측할 이유가 없습니다.
드릴다운: 4단계 전략

드릴다운의 아이디어: 분 단위 레벨에서 시작하여 모호성이 있을 때만(가격 변동 또는 거래량 급증으로 인해) 하위 레벨로 "드릴다운"합니다.
Level 1: 1m (분봉)
-> SL 또는 TP가 명확하게 [low, high] 범위 밖에 있는 경우 — 즉시 해결
-> 둘 다 범위 안에 있는 경우 — 드릴다운
Level 2: 1s (초봉)
-> 해당 분의 60개 초봉 로드
-> 초 단위로 확인: 어느 것이 먼저 트리거되었는가?
-> 초봉이 모호하거나, price_move >= min_pct이거나, volume >= median_1s * vol_mult인 경우 — 드릴다운
Level 3: 100ms (밀리초봉)
-> 해당 초의 최대 10개 100ms 바 로드
-> 100ms 단위로 확인
-> 100ms 바가 모호하거나, price_move >= min_pct이거나, volume >= median_100ms * vol_mult인 경우 — 드릴다운
Level 4: 원시 틱
-> 해당 100ms 버킷의 개별 거래 로드
-> 틱 단위로 체결 해결 — 최대 정밀도
드릴다운이 필요하지 않은 경우
95%의 경우 드릴다운은 필요하지 않습니다. 일반적인 시나리오:
명확한 SL: 캔들 고가가 TP에 도달하지 않고 저가가 SL을 돌파 -> SL 트리거, 드릴다운 불필요.
명확한 TP: 저가가 SL에 도달하지 않고 고가가 TP를 돌파 -> TP 트리거, 드릴다운 불필요.
둘 다 트리거되지 않음: 두 레벨 모두 범위 밖 -> 포지션 유지.
갭 감지: 다음 캔들의 시가가 SL 또는 TP를 건너뜀 -> 시가에서 체결, 드릴다운 불필요.
드릴다운이 필요한 것은 약 5%의 바에 불과합니다 — 두 레벨 모두 하나의 캔들 범위 안에 있을 때.
class AdaptiveFillSimulator:
"""
Four-level drill-down for determining fill order.
"""
def __init__(self, data_loader):
self.loader = data_loader
self.cache_1s = {} # Cache of second data by month
def check_fill(self, timestamp, candle_1m, sl_price, tp_price, side):
"""
Checks whether SL or TP triggered on the given minute candle.
Returns: ('sl', fill_price) | ('tp', fill_price) | None
"""
low, high = candle_1m['low'], candle_1m['high']
open_price = candle_1m['open']
if side == 'long':
if open_price <= sl_price:
return ('sl', open_price)
if open_price >= tp_price:
return ('tp', open_price)
else:
if open_price >= sl_price:
return ('sl', open_price)
if open_price <= tp_price:
return ('tp', open_price)
sl_hit = self._level_hit(sl_price, low, high, side, 'sl')
tp_hit = self._level_hit(tp_price, low, high, side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if not sl_hit and not tp_hit:
return None
return self._drill_down_1s(timestamp, sl_price, tp_price, side)
def _drill_down_1s(self, minute_ts, sl_price, tp_price, side):
"""Level 2: second-by-second pass."""
bars_1s = self.loader.load_1s_for_minute(minute_ts)
if bars_1s is None or len(bars_1s) == 0:
return self._pessimistic_fill(side, sl_price, tp_price)
for bar in bars_1s:
sl_hit = self._level_hit(sl_price, bar['low'], bar['high'], side, 'sl')
tp_hit = self._level_hit(tp_price, bar['low'], bar['high'], side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if sl_hit and tp_hit:
result = self._drill_down_100ms(bar['timestamp'], sl_price, tp_price, side)
if result:
return result
return self._pessimistic_fill(side, sl_price, tp_price)
def _pessimistic_fill(self, side, sl_price, tp_price):
"""Pessimistic assumption: SL for longs, TP for shorts."""
if side == 'long':
return ('sl', sl_price)
else:
return ('sl', sl_price)
성능
| 모드 | 체결 확인당 시간 | 사용 시점 |
|---|---|---|
| 1m (드릴다운 없음) | ~0ms | ~95% 경우 |
| 1s 드릴다운 | ~5ms (월 첫 접근 시) | ~5% 경우 |
| 100ms 드릴다운 | ~1ms | <0.5% 경우 |
| 원시 틱 드릴다운 | ~0.5ms | <0.1% 경우 |
약 400건의 거래가 있는 2년 백테스트에서 드릴다운은 약 20개의 캔들에 대해 호출됩니다. 총 오버헤드 — 전체 백테스트에서 1초 미만.
어댑티브 데이터 스토리지
드릴다운에는 초 단위 및 밀리초 단위 데이터가 필요합니다. 하지만 모든 것을 최대 해상도로 저장하는 것은 비현실적입니다:
| 해상도 | 2년간 바 수 | Parquet 크기 |
|---|---|---|
| 1m | ~105만 | ~15 MB |
| 1s | ~6,300만 | ~550 MB/월 |
| 100ms | ~6.3억 | ~5 GB/월 |
2년간 완전한 1s 아카이브는 약 13 GB입니다. 100ms는 100 GB 이상. 모든 것을 저장하는 것은 가능하지만, 드릴다운이 이 데이터의 1% 미만만 사용한다는 점을 고려하면 낭비입니다.
핫 세컨드 감지
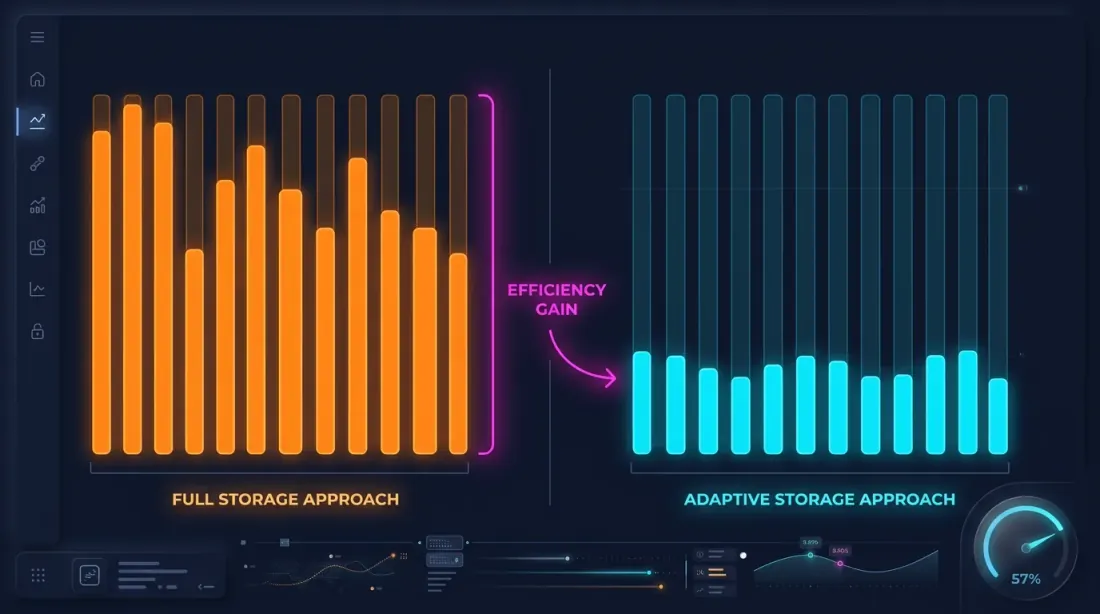
핵심 관찰: 가격이 크게 움직인 초는 전체의 극히 일부입니다. 1초 이내에 가격이 0.1% 미만으로 변동했다면 — 해당 초의 100ms 세분화를 저장할 의미가 없습니다.
핫 세컨드 감지: 데이터를 다운로드하고 처리할 때 각 초를 분석하고 "핫" 초 — 가격 변동이 임계값을 초과한 초에 대해서만 100ms 캔들을 생성합니다.
def process_trades_adaptive(
trades: pd.DataFrame,
min_price_change_pct: float = 1.0,
) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Processes raw trades into an adaptive structure:
- 1s candles for all seconds
- 100ms candles only for "hot" seconds
Args:
trades: DataFrame with columns [timestamp, price, quantity]
min_price_change_pct: threshold for drill-down to 100ms
Returns:
(df_1s, df_100ms_hot) — second candles and 100ms for hot seconds
"""
trades['second'] = trades['timestamp'].dt.floor('1s')
df_1s = trades.groupby('second').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
df_1s['price_change_pct'] = (df_1s['high'] - df_1s['low']) / df_1s['open'] * 100
hot_seconds = df_1s[df_1s['price_change_pct'] >= min_price_change_pct].index
hot_trades = trades[trades['second'].isin(hot_seconds)]
hot_trades['bucket_100ms'] = hot_trades['timestamp'].dt.floor('100ms')
df_100ms = hot_trades.groupby('bucket_100ms').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
return df_1s, df_100ms
스토리지 절약
예를 들어 — 일반적인 월의 ETHUSDT:
| 접근 방식 | 크기 | 해상도 |
|---|---|---|
| 1m만 | ~1 MB | 1분 |
| 전체 1s | ~550 MB | 1초 |
| 전체 100ms | ~5 GB | 100 ms |
| 어댑티브 | ~600 MB | 1s + 핫 세컨드만 100ms |
min_price_change_pct = 1.0% 임계값에서 핫 세컨드는 전체 초의 1% 미만을 차지합니다. 그에 대한 100ms 데이터는 550 MB의 초 데이터에 약 50 MB를 추가할 뿐 — 무시할 수 있는 오버헤드입니다.
초 데이터도 어댑티브하게 저장하는 경우(분봉 내 변동이 0.1%를 초과할 때만), 볼륨을 3-5배 더 줄일 수 있습니다.
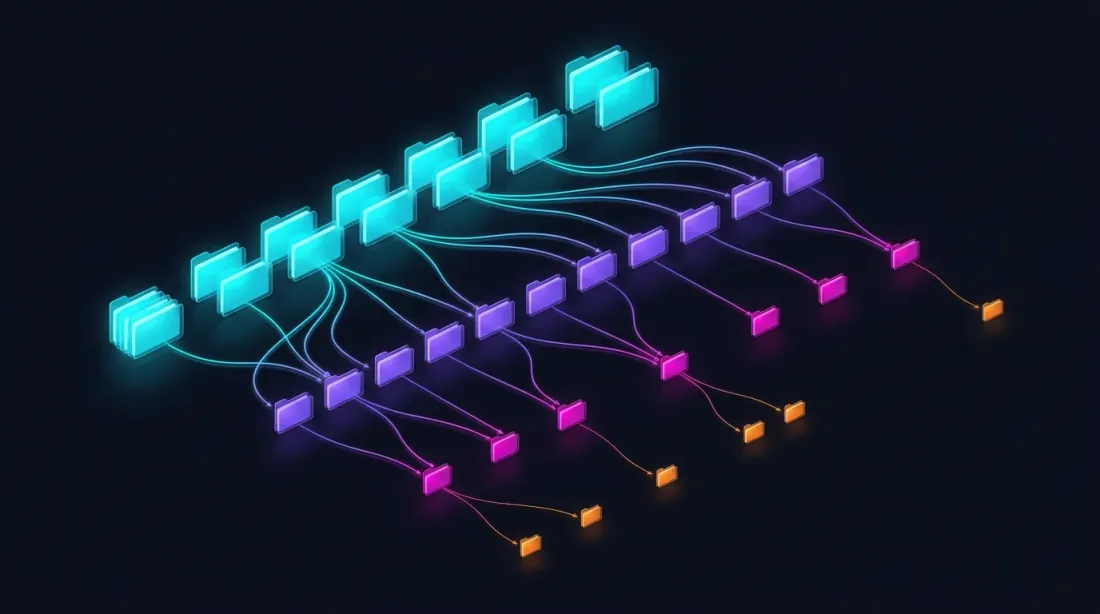
Parquet 스토리지 구조
data/{SYMBOL}/
├── source.json # 거래소 소스: {"exchange": "binance"} or {"exchange": "bybit"}
├── stats.json # 사전 계산된 중앙값 거래량: {"median_volume_1s": ..., "median_volume_100ms": ...}
├── klines_1m/
│ ├── 2024-01.parquet # ~1 MB
│ ├── 2024-02.parquet
│ └── ...
├── klines_1s/
│ ├── 2024-01.parquet # ~550 MB
│ └── ...
├── klines_100ms_hot/
│ ├── 2024-01.parquet # ~50 MB (hot seconds only)
│ └── ...
├── trades_hot/
│ ├── 2024-01.parquet # Raw trades for hot 100ms buckets
│ └── ...
└── states_1m.parquet # Precomputed rolling state cache (~112 MB)
각 파일은 한 달의 데이터를 포함합니다. 초, 밀리초, 거래 데이터는 지연 로딩되며 — 드릴다운이 요청할 때만 로드됩니다. stats.json 파일에는 거래량 기반 드릴다운 트리거에 사용되는 사전 계산된 중앙값 거래량이 포함되어 있습니다.
금융 데이터를 위한 Parquet 최적화
금융 데이터에는 특유의 특성이 있습니다: 타임스탬프는 단조 증가하고, 가격은 부드럽게 변하며, 거래량은 크게 변동합니다. 최적 설정:
import pyarrow as pa
import pyarrow.parquet as pq
schema = pa.schema([
pa.field("timestamp", pa.int32()), # Seconds from epoch — int32 is sufficient
pa.field("open", pa.float32()),
pa.field("high", pa.float32()),
pa.field("low", pa.float32()),
pa.field("close", pa.float32()),
pa.field("volume", pa.float32()),
])
column_encodings = {
"timestamp": "DELTA_BINARY_PACKED", # Monotonic int -> delta compression
"open": "BYTE_STREAM_SPLIT", # Float -> byte-stream split
"high": "BYTE_STREAM_SPLIT",
"low": "BYTE_STREAM_SPLIT",
"close": "BYTE_STREAM_SPLIT",
"volume": "BYTE_STREAM_SPLIT",
}
def save_optimized_parquet(df, path):
table = pa.Table.from_pandas(df, schema=schema)
pq.write_table(
table, path,
compression="zstd",
compression_level=9,
use_dictionary=False,
write_statistics=False,
column_encoding=column_encodings,
)
이러한 설정의 이유:
- DELTA_BINARY_PACKED (타임스탬프용): 연속 타임스탬프의 차이는 고정값입니다(1m은 60, 1s는 1). 델타 인코딩으로 거의 0에 가깝게 압축됩니다.
- BYTE_STREAM_SPLIT (float용): float32 바이트를 스트림으로 분할합니다(모든 첫 번째 바이트를 함께, 모든 두 번째 바이트를 함께 등). 부드럽게 변하는 가격에 대해 표준 인코딩보다 2-3배 더 나은 압축률을 달성합니다.
- ZSTD level 9: 허용 가능한 압축 해제 속도로 좋은 압축률.
- float32 (float64 대신): 가격과 거래량에 충분하며 메모리를 50% 절약합니다.
캐시를 활용한 지연 로딩
드릴다운은 특정 분의 초 단위 데이터를 요청합니다. 요청마다 parquet 파일을 로딩하는 것은 느립니다. 해결책 — 월별 LRU 캐시를 활용한 지연 로딩.
from functools import lru_cache
import pyarrow.parquet as pq
import pandas as pd
class AdaptiveDataLoader:
"""
Lazy loader with cache: loads second data by month,
keeps the last N months in memory.
"""
def __init__(self, symbol: str, data_dir: str = "data", cache_months: int = 2):
self.symbol = symbol
self.data_dir = data_dir
self.cache_months = cache_months
self._cache_1s: dict[str, pd.DataFrame] = {}
def load_1s_for_minute(self, minute_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Load 1s data for a specific minute."""
month_key = minute_ts.strftime("%Y-%m")
if month_key not in self._cache_1s:
self._load_month_1s(month_key)
if month_key not in self._cache_1s:
return None
df = self._cache_1s[month_key]
minute_start = minute_ts.floor('1min')
minute_end = minute_start + pd.Timedelta(minutes=1)
return df[(df.index >= minute_start) & (df.index < minute_end)]
def load_100ms_for_second(self, second_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Load 100ms data for a hot second."""
month_key = second_ts.strftime("%Y-%m")
path = f"{self.data_dir}/{self.symbol}/klines_100ms_hot/{month_key}.parquet"
try:
df = pd.read_parquet(path)
second_start = second_ts.floor('1s')
second_end = second_start + pd.Timedelta(seconds=1)
return df[(df.index >= second_start) & (df.index < second_end)]
except FileNotFoundError:
return None
def _load_month_1s(self, month_key: str):
"""Load a month of 1s data, evict old data from cache."""
path = f"{self.data_dir}/{self.symbol}/klines_1s/{month_key}.parquet"
try:
df = pd.read_parquet(path)
df.index = pd.to_datetime(df['timestamp'], unit='s')
if len(self._cache_1s) >= self.cache_months:
oldest = min(self._cache_1s.keys())
del self._cache_1s[oldest]
self._cache_1s[month_key] = df
except FileNotFoundError:
pass
백테스트에 드릴다운 적용
백테스트 루프에 통합:
def backtest_with_adaptive_fill(
states: pd.DataFrame,
strategy_params: dict,
data_loader: AdaptiveDataLoader,
) -> list:
"""
Backtest with adaptive drill-down for fill simulation.
"""
fill_sim = AdaptiveFillSimulator(data_loader)
trades = []
position = None
for i in range(len(states)):
row = states.iloc[i]
ts = states.index[i]
candle_1m = {
'open': row['open'], 'high': row['high'],
'low': row['low'], 'close': row['close'],
'timestamp': ts,
}
if position is not None:
fill = fill_sim.check_fill(
ts, candle_1m,
position['sl'], position['tp'],
position['side'],
)
if fill is not None:
fill_type, fill_price = fill
trades.append({
'entry_time': position['entry_time'],
'exit_time': ts,
'side': position['side'],
'entry_price': position['entry_price'],
'exit_price': fill_price,
'exit_type': fill_type,
'drill_down': fill_sim.last_drill_depth, # 0, 1, or 2
})
position = None
continue
signal = check_entry_signal(row, strategy_params)
if signal and position is None:
position = {
'side': signal['side'],
'entry_price': row['close'],
'entry_time': ts,
'sl': signal['sl'],
'tp': signal['tp'],
}
return trades
롤링 스테이트 캐시와의 관계
드릴다운은 집계 Parquet 캐시를 보완하며, 각각 다른 문제를 해결합니다:
| 롤링 스테이트 캐시 | 어댑티브 드릴다운 | |
|---|---|---|
| 목적 | 정확한 HTF 지표 값 | 정확한 SL/TP 체결 순서 |
| 대상 | 모든 1m 캔들 | 체결 모호성 시에만 (~5%) |
| 데이터 | 사전 계산, 영구 저장 | 지연 로드, 최근 월 캐시 |
| 영향 | 진입/청산 시그널 | 체결 가격 및 시간 |
두 접근 방식 모두 일봉 수준에서는 보이지 않지만 현실적인 백테스트에 중요한 오류를 제거합니다.
요약: 체결 시뮬레이션 접근 방식 비교
| 접근 방식 | 정확도 | 속도 | 스토리지 |
|---|---|---|---|
| OHLC 휴리스틱 (낙관/비관) | 낮음 | 즉시 | 1m만 |
| 전체 1s 백테스트 | 높음 | 느림 (x60) | ~550 MB/월 |
| 전체 100ms 백테스트 | 매우 높음 | 매우 느림 (x600) | ~5 GB/월 |
| 전체 원시 틱 백테스트 | 최대 | 극히 느림 | ~50 GB/월 |
| 어댑티브 드릴다운 (4단계) | 최대 | ~즉시 | 1m + 1s + 100ms 핫 + 틱 핫 |
드릴다운은 1m 백테스트 속도로 전체 1s 백테스트의 정확도를 제공합니다. 핵심 관찰: 높은 해상도는 모든 곳이 아닌 의사결정 지점에서만 필요합니다.
거래량 기반 드릴다운
원래 드릴다운은 가격 변동에만 트리거되었습니다 — 캔들의 [low, high] 범위가 체결 모호성을 발생시킬 만큼 넓을 때. 하지만 가격만이 바 안에서 흥미로운 일이 일어났다는 신호는 아닙니다.
거래량 급증은 동등하게 중요한 트리거입니다. 거래량이 중앙값의 500배인 초는 일반적으로 대형 시장가 주문, 청산 캐스케이드 또는 플래시 크래시에 해당합니다. 캔들 몸통이 작아 보이더라도 해당 초 내의 실제 가격 경로는 격렬했을 수 있으며 — OHLC 표현이 숨기는 극값에 도달했을 수 있습니다.
드릴다운 조건은 이제 OR 기반입니다: 상당한 가격 변동 또는 비정상적인 거래량 급증 중 하나가 더 세밀한 해상도로의 하강을 트리거합니다.
def is_hot(bar, median_volume, min_pct=0.1, vol_mult=500):
"""
Determines if a bar warrants drill-down to the next level.
Two independent triggers (OR logic):
- price moved >= min_pct within the bar
- volume exceeded median * vol_mult
"""
price_move = (bar['high'] - bar['low']) / bar['open'] * 100
return price_move >= min_pct or bar['volume'] >= median_volume * vol_mult
이는 가격만으로는 감지할 수 없는 시나리오를 포착합니다: 시가=3000, 종가=3001이지만 거래량이 정상의 50,000배인 바는 밀리초 이내에 2950과 3050에 일시적으로 도달했을 수 있습니다. 거래량 기반 드릴다운 없이는 백테스트가 이 초를 더 자세히 조사하지 않을 것입니다.
원시 틱: 네 번째 레벨
원래의 3단계 계층 (1m -> 1s -> 100ms)에는 여전히 간극이 있습니다: 단일 100ms 버킷 내에서 여러 거래가 다른 가격으로 체결될 수 있습니다. 고가=3060, 저가=2965인 버킷에서 정확한 순서는 여전히 알 수 없습니다.
해결책: 네 번째이자 최종 레벨로 원시 틱으로 드릴다운.
1m 캔들 (기본)
└─> 1s 캔들 (1s에서 price_move >= min_pct 또는 volume >= median_1s * vol_mult인 경우)
└─> 100ms 캔들 (핫 세컨드 감지 시)
└─> 원시 틱 (100ms에서 price_move >= min_pct 또는 volume >= median_100ms * vol_mult인 경우)
원시 틱 레벨에서는 모호성이 없습니다 — 각 거래는 정확한 가격과 타임스탬프를 가지고 있습니다. 체결은 결정적으로 해결됩니다:
def resolve_from_trades(trades, sl_price, tp_price, side):
"""
Walk through individual trades in chronological order.
The first trade that crosses SL or TP determines the fill.
"""
for trade in trades:
price = trade['price']
if side == 'long':
if price <= sl_price:
return ('sl', price)
if price >= tp_price:
return ('tp', price)
else: # short
if price >= sl_price:
return ('sl', price)
if price <= tp_price:
return ('tp', price)
return None
원시 틱 레벨은 극히 드물게 호출됩니다 — 전체 바의 0.1% 미만 — 하지만 호출될 때 캔들 기반 근사로는 얻을 수 없는 실제 데이터를 제공합니다.
전환별 개별 임계값
서로 다른 해상도 전환에는 서로 다른 특성이 있습니다. 1초 이내의 0.1% 가격 변동은 유의미하지만, 100ms 버킷 내의 같은 0.1%는 극단적입니다. 마찬가지로 거래량 분포는 각 타임스케일에서 다릅니다.
각 레벨 전환에는 이제 고유한 min_pct와 vol_mult 파라미터가 있습니다:
1s → 100ms: --min-pct-1s 0.1 --vol-mult-1s 500
100ms → trades: --min-pct-100ms 0.1 --vol-mult-100ms 500
이를 통해 각 전환의 민감도를 독립적으로 미세 조정할 수 있습니다. 실제로 100ms에서 틱으로의 전환은 단일 100ms 버킷의 원시 틱 로딩 비용이 최소이므로 더 엄격한 임계값을 사용할 수 있습니다.
@dataclass
class DrillDownConfig:
min_pct_1s: float = 0.1
vol_mult_1s: float = 500
min_pct_100ms: float = 0.1
vol_mult_100ms: float = 500
영구적 중앙값 통계
거래량 기반 드릴다운은 각 타임스케일에서 중앙값 거래량을 알아야 합니다. 매 백테스트마다 즉석에서 중앙값을 계산하면 성능 이점이 상쇄됩니다. 해결책: 중앙값을 한 번 사전 계산하고 캐시합니다.
각 심볼에 대해 1s 및 100ms 해상도의 중앙값 거래량이 이력 데이터에서 계산되고 stats.json 파일에 저장됩니다:
{
"ETHUSDT": {
"median_volume_1s": 12.5,
"median_volume_100ms": 1.8
},
"BTCUSDT": {
"median_volume_1s": 0.45,
"median_volume_100ms": 0.06
}
}
통계는 데이터가 처음 다운로드될 때 심볼당 한 번 계산되고 이후 모든 백테스트에서 재사용됩니다. 데이터가 업데이트되면(새로운 월이 다운로드되면) 통계가 점진적으로 재계산됩니다.
def compute_median_stats(symbol, data_dir):
"""Compute and cache median volume stats for a symbol."""
stats_path = f"{data_dir}/{symbol}/stats.json"
all_1s = load_all_months(f"{data_dir}/{symbol}/klines_1s/")
median_1s = all_1s['volume'].median()
all_100ms = load_all_months(f"{data_dir}/{symbol}/klines_100ms_hot/")
median_100ms = all_100ms['volume'].median()
stats = {
"median_volume_1s": float(median_1s),
"median_volume_100ms": float(median_100ms),
}
with open(stats_path, 'w') as f:
json.dump(stats, f, indent=2)
return stats

다중 거래소 지원: Bybit
모든 심볼이 Binance에서 이용 가능한 것은 아닙니다. XAUTUSDT(금)와 같은 자산의 경우 다른 거래소에서 데이터를 가져와야 합니다. 드릴다운 시스템은 이제 대안 데이터 소스로 Bybit를 지원합니다.
Bybit 심볼의 경우 모든 캔들 레벨(1m, 1s, 100ms)과 원시 틱은 Bybit의 원시 거래 스트림에서 구축됩니다. 프로세스는 동일합니다 — 원시 틱이 각 타임스케일의 캔들로 집계되지만 데이터 소스가 다릅니다.
data/{SYMBOL}/
├── source.json # {"exchange": "bybit"} or {"exchange": "binance"}
├── klines_1m/
│ └── ...
├── klines_1s/
│ └── ...
├── klines_100ms_hot/
│ └── ...
└── trades_hot/ # Raw trades for hot 100ms buckets
└── ...
데이터 로더는 source.json을 확인하고 적절한 다운로드 파이프라인을 사용합니다. 백테스트 엔진의 관점에서 소스 거래소와 관계없이 데이터 형식은 동일합니다 — 드릴다운 로직은 거래소에 구애받지 않습니다.
이는 교차 거래소 전략이나 특정 거래소에서만 거래되는 심볼에 특히 중요합니다.
결론
어댑티브 드릴다운은 단순한 원칙의 적용입니다: 데이터의 중요도에 비례하여 계산 자원과 스토리지를 사용합니다.
4가지 해상도 레벨:
- 1m — 95%의 바에 대한 기본 패스
- 1s — 체결 모호성 또는 거래량 급증 시 드릴다운
- 100ms — 극단적 변동 또는 비정상 거래량을 가진 핫 세컨드의 드릴다운
- 원시 틱 — 핫 100ms 버킷의 드릴다운, 개별 거래 수준에서 체결 해결
4가지 스토리지 레벨:
- 전체 1m — 완전한 아카이브, 2년간 ~15 MB
- 전체 1s — 완전한 또는 어댑티브 아카이브, ~550 MB/월
- 핫 100ms만 — 초의 <1%, ~50 MB/월
- 핫 틱만 — 가장 극단적인 100ms 버킷의 원시 틱
2가지 드릴다운 트리거 (OR 로직):
- 가격 기반: 바의 가격 범위가
min_pct를 초과 - 거래량 기반: 바의 거래량이
median * vol_mult를 초과
결과: 틱 시뮬레이터 정확도의 백테스트가 분봉 수준 속도로 실행됩니다. 스토리지는 기하급수적이 아니라 선형적으로 증가합니다. 그리고 여러 거래소 — Binance와 Bybit — 를 지원하며, 거래소에 구애받지 않는 드릴다운 로직을 갖추고 있습니다.
멀티 타임프레임 전략의 사전 계산 캐시에 대해서는 집계 Parquet 캐시 기사를 참조하세요. 높은 레버리지에서 펀딩 비율이 결과에 미치는 영향에 대해서는 펀딩 비율이 레버리지를 죽인다를 참조하세요.
참고 링크
- Apache Parquet — data storage format
- Apache Arrow — BYTE_STREAM_SPLIT encoding
- Zstandard — compression algorithm
- Lopez de Prado — Advances in Financial Machine Learning
- Binance — Historical Market Data
Citation
@article{soloviov2026adaptivedrilldown,
author = {Soloviov, Eugen},
title = {Adaptive Drill-Down: Backtest with Variable Granularity from Minutes to Raw Trades},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/adaptive-resolution-drill-down-backtest},
description = {How adaptive data granularity speeds up backtests and saves storage: drill-down from 1m to 1s, 100ms, and raw trades only where price moved significantly or volume spiked.}
}
MarketMaker.cc Team
퀀트 리서치 및 전략


