알고리즘 트레이딩을 위한 QuestDB: 오더북에서 프로덕션 아키텍처까지

면책 조항: 본 기사에 제공된 정보는 교육 및 정보 제공 목적으로만 작성되었으며, 금융, 투자 또는 거래 조언을 구성하지 않습니다. 암호화폐 거래에는 상당한 손실 위험이 수반됩니다.
QuestDB 시리즈의 마지막 파트에 오신 것을 환영합니다. 1부에서는 스토리지 아키텍처를, 2부에서는 SQL 확장 기능을 다루었습니다. 이제 모든 것을 통합합니다: 실시간 분석을 위한 머티리얼라이즈드 뷰, 2D 배열을 활용한 네이티브 오더북 저장, 그리고 프로덕션 알고리즘 트레이딩 플랫폼을 위한 레퍼런스 아키텍처입니다.
머티리얼라이즈드 뷰: 와이어 스피드의 사전 계산된 분석
 캐스케이드 머티리얼라이즈드 뷰: 원시 틱 데이터가 점점 더 거친 집계 레이어를 통과하며, 각 수준에서 극적으로 작은 데이터셋을 처리
캐스케이드 머티리얼라이즈드 뷰: 원시 틱 데이터가 점점 더 거친 집계 레이어를 통과하며, 각 수준에서 극적으로 작은 데이터셋을 처리
SAMPLE BY가 QuestDB에서 가장 많이 사용되는 쿼리라면, 머티리얼라이즈드 뷰는 가장 영향력 있는 최적화입니다. 개념은 단순합니다: 대시보드 갱신이나 API 호출마다 OHLCV 집계를 계산하는 대신, 한 번 사전 계산하고 결과를 지속적으로 업데이트합니다.
기본 OHLC 머티리얼라이즈드 뷰
CREATE MATERIALIZED VIEW trades_OHLC_15m
WITH BASE 'trades'
REFRESH IMMEDIATE
AS
SELECT timestamp, symbol,
first(price) AS open,
max(price) AS high,
min(price) AS low,
last(price) AS close,
sum(quantity) AS volume
FROM trades
SAMPLE BY 15m;
이것이 정의의 전부입니다. trades 테이블에 새로운 행이 삽입될 때마다, QuestDB는 자동으로 증분 방식으로 이 뷰를 갱신합니다. 전체 재계산이 아니라 영향을 받는 타임 버킷만 업데이트됩니다. trades_OHLC_15m에 대한 쿼리는 훨씬 작은 사전 집계된 데이터셋에 대한 단순한 조회가 됩니다.
성능 차이는 극적입니다. 수십억 행의 테이블에서 기본 테이블의 OHLC 데이터를 쿼리하면 200ms가 걸릴 수 있습니다. 머티리얼라이즈드 뷰는 동일한 결과를 5ms 미만으로 반환합니다. 여러 대시보드 사용자가 동시에 접속할 때, 이것은 단순한 최적화가 아니라 — 응답성 있는 시스템과 다운되는 시스템의 차이입니다.
캐스케이드 뷰: 단일 소스에서의 멀티 타임프레임
머티리얼라이즈드 뷰가 아키텍처적으로 우아해지는 지점입니다. 뷰를 체이닝할 수 있습니다 — 각 뷰가 다음 뷰에 데이터를 공급하여, 단일 원시 데이터 소스에서 집계 수준의 계층 구조를 생성합니다:
-- 원시 거래에서 1초 바
CREATE MATERIALIZED VIEW ohlc_1s AS
SELECT timestamp, symbol,
first(price) AS open, max(price) AS high,
min(price) AS low, last(price) AS close,
sum(quantity) AS volume
FROM trades
SAMPLE BY 1s;
-- 1초 바에서 5초 바
CREATE MATERIALIZED VIEW ohlc_5s AS
SELECT timestamp, symbol,
first(open) AS open, max(high) AS high,
min(low) AS low, last(close) AS close,
sum(volume) AS volume
FROM ohlc_1s
SAMPLE BY 5s;
-- 5초 바에서 1분 바
CREATE MATERIALIZED VIEW ohlc_1m AS
SELECT timestamp, symbol,
first(open) AS open, max(high) AS high,
min(low) AS low, last(close) AS close,
sum(volume) AS volume
FROM ohlc_5s
SAMPLE BY 1m;
각 수준은 이전 수준보다 극적으로 작은 데이터셋을 처리합니다. 1분 뷰는 원시 거래를 스캔하지 않습니다 — 사전 집계된 5초 바만 읽습니다. 이 캐스케이드 패턴은 임의의 타임프레임으로 확장됩니다: 1s → 5s → 1m → 5m → 15m → 1h → 4h → 1d.
100개 이상의 거래소에서 데이터를 수집하는 암호화폐 데이터 플랫폼에게, 이것은 전체 OHLC 전달 파이프라인의 백본입니다.
갱신 전략
QuestDB는 각기 다른 워크로드에 적합한 세 가지 갱신 모드를 제공합니다:
REFRESH IMMEDIATE는 기본 테이블 트랜잭션마다 비동기 갱신을 트리거합니다. 서브초 지연 시간이 중요한 실시간 대시보드에 최적입니다.
REFRESH EVERY 1h(타이머 기반)는 업데이트를 주기적 갱신으로 배치 처리합니다. 마이크로 배치마다 갱신을 트리거하면 오버헤드가 발생하는 고처리량 수집에 더 적합합니다.
REFRESH PERIOD (LENGTH 1d TIME ZONE 'Europe/London' DELAY 2h)는 캘린더에 정렬된 기간을 정의합니다. "delay"는 지연 도착 데이터를 처리합니다 — 거래 세션 종료 후 수 시간이 지나서 수정 피드를 보낼 수 있는 시장에 중요합니다.
REFRESH MANUAL은 완전한 제어를 제공합니다. 명시적으로 REFRESH 명령을 실행할 때만 뷰가 업데이트됩니다 — 일일 결산 워크플로에 유용합니다.
LATEST ON 가속 패턴
가장 강력한 패턴 중 하나는 머티리얼라이즈드 뷰와 LATEST ON을 결합하여 즉각적인 포트폴리오 스냅샷을 구현하는 것입니다. 13억 개의 원시 행에서 각 심볼의 최신 가격을 스캔하는 데 수 초가 걸립니다. 그러나 일일 사전 집계 뷰를 사용하면:
CREATE MATERIALIZED VIEW trades_latest_1d AS
SELECT timestamp, symbol, side,
last(price) AS price,
last(quantity) AS quantity,
last(timestamp) AS latest
FROM trades
SAMPLE BY 1d;
LATEST ON 쿼리는 수십억 행이 아닌 약 25,000개의 사전 집계 행만 스캔합니다:
SELECT symbol, side, price, quantity, latest AS timestamp
FROM (
trades_latest_1d
LATEST ON timestamp PARTITION BY symbol, side
)
ORDER BY timestamp DESC;
수 초에서 밀리초로. 이것이 프로덕션 트레이딩 대시보드가 대규모 데이터셋에서 실시간 응답성을 달성하는 방법입니다.
TTL: 자동 데이터 수명 주기
머티리얼라이즈드 뷰는 자동 데이터 만료를 위한 TTL(Time-To-Live) 정책을 지원합니다:
CREATE MATERIALIZED VIEW ohlc_1h AS (
SELECT timestamp, symbol,
avg(price) AS avg_price
FROM trades
SAMPLE BY 1h
) PARTITION BY WEEK TTL 8 WEEKS;
이렇게 하면 8주간의 시간별 데이터를 유지하고, 오래된 파티션을 자동으로 삭제합니다. 3계층 스토리지 엔진과 결합하면 자연스러운 데이터 수명 주기를 얻을 수 있습니다: 원시 틱은 WAL → 컬럼나 스토리지 → 오브젝트 스토리지의 Parquet를 통과하고, 머티리얼라이즈드 뷰는 애플리케이션이 실제로 쿼리하는 사전 집계된 요약을 유지합니다.
2D 배열: 네이티브 오더북 분석
 3D 오더북 깊이: 매수 및 매도 호가 수준이 네이티브 2D 배열로 저장되어, SIMD 최적화된 스프레드 계산과 유동성 분석 가능
3D 오더북 깊이: 매수 및 매도 호가 수준이 네이티브 2D 배열로 저장되어, SIMD 최적화된 스프레드 계산과 유동성 분석 가능
QuestDB 9.0은 N차원 배열을 도입했습니다 — 형상과 스트라이드를 갖춘 NumPy와 같은 진정한 배열로, 일반적인 연산(슬라이싱, 전치)을 제로 카피로 처리합니다. 트레이딩에서의 핵심 활용은 오더북 저장입니다.
기존의 문제
역사적으로 관계형 데이터베이스에 오더북 스냅샷을 저장하는 것은 고통스러웠습니다. 두 가지 선택지가 있었습니다: 가격 수준당 한 행(행 수의 폭증, 깊이 조회 비용이 높음), 또는 bid1_price, bid1_size, bid2_price, bid2_size 같은 고정된 수의 컬럼(경직적, 낭비적, 보기 흉함).
QuestDB의 2D 배열은 두 문제를 모두 해결합니다:
CREATE TABLE market_data (
timestamp TIMESTAMP,
symbol SYMBOL,
bids DOUBLE[][],
asks DOUBLE[][]
) TIMESTAMP(timestamp) PARTITION BY HOUR;
각 bids와 asks 컬럼은 첫 번째 행에 가격을, 두 번째 행에 각 수준의 거래량을 포함하는 2D 배열을 저장합니다. 20레벨 오더북은 하나의 컴팩트한 배열이며, 40개의 별도 컬럼이 아닙니다.
SQL에서의 오더북 분석
스프레드 계산 — 가장 기본적이면서 가장 자주 계산되는 지표:
SELECT timestamp,
spread(bids[1][1], asks[1][1]) AS spread
FROM market_data
WHERE symbol = 'EURUSD'
AND timestamp IN today();
spread() 함수는 최우선 매도 호가와 최우선 매수 호가의 차이를 계산하는 내장 함수입니다. bids[1][1]은 매수 배열의 첫 번째 행(가격)의 첫 번째 요소(최우선 가격)에 접근합니다.
더 정교한 분석 — 유동성 깊이, 오더북 불균형, 특정 가격 수준에서의 체결 확률 — 배열 슬라이싱과 벡터화된 연산이 이전에는 복잡했던 쿼리를 간단하게 만듭니다:
-- 목표 가격이 도달하는 수준을 찾고
-- 해당 수준까지의 모든 볼륨을 합산
DECLARE @target := bids[1][1] * 1.01;
SELECT timestamp,
array_sum(asks[2][1:level_idx]) AS volume_to_fill
FROM market_data
WHERE symbol = 'EURUSD';
SIMD 최적화된 배열 연산은 이러한 계산이 수백만 개의 스냅샷에 대해서도 하드웨어에 가까운 속도로 실행된다는 것을 의미합니다.
배열 데이터 수집
QuestDB의 클라이언트 라이브러리는 네이티브 배열 수집을 지원합니다. Python 클라이언트는 NumPy 배열과 직접 통합됩니다:
import numpy as np
from questdb.ingress import Sender
bids = np.array([[9.3, 9.2, 9.1], [100, 200, 150]]) # prices, volumes
asks = np.array([[9.5, 9.6, 9.7], [80, 160, 120]])
with Sender.from_conf("http::addr=localhost:9000;") as sender:
sender.row(
'market_data',
symbols={'symbol': 'EURUSD'},
columns={'bids': bids, 'asks': asks},
at=timestamp
)
Protocol Version 2는 배열을 바이너리 형식으로 인코딩하여, 텍스트 기반 프로토콜에 비해 대역폭과 서버 측 파싱 오버헤드를 극적으로 줄입니다. 고빈도 오더북 수집 — 심볼당 초당 수천 개의 스냅샷을 수신하는 경우 — 이러한 효율성이 중요합니다.
C/C++ 클라이언트는 형상 기술자가 포함된 플랫 행 우선 배열을 사용하여, 기존 트레이딩 시스템 데이터 구조에서 제로 카피 수집을 가능하게 합니다.
모든 것을 통합: 레퍼런스 아키텍처
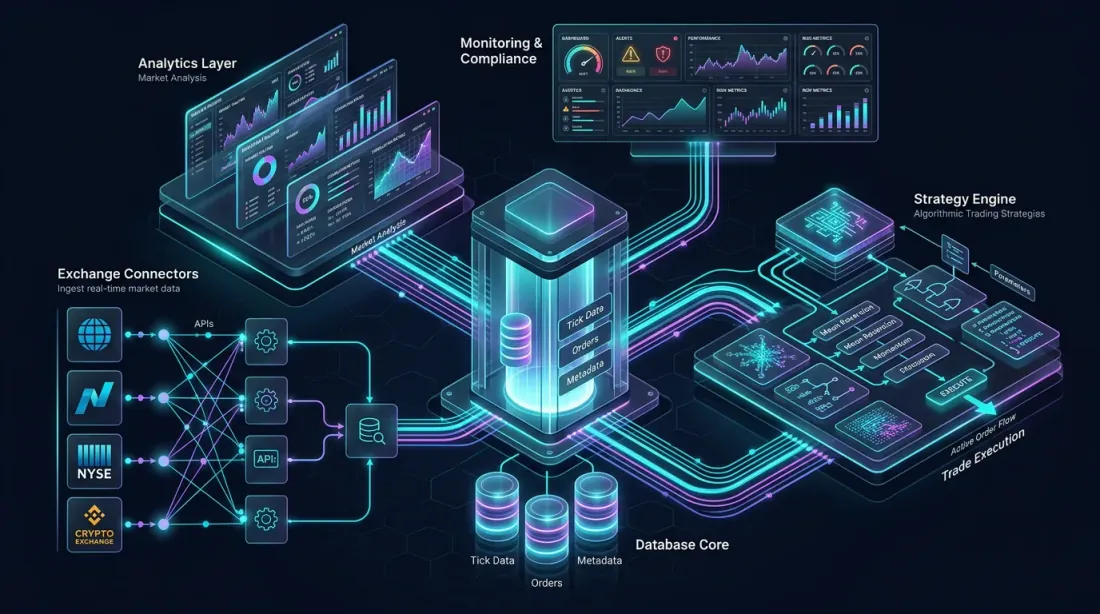 레퍼런스 아키텍처: 거래소 커넥터, 컬럼나 데이터베이스 코어, 분석 레이어, 전략 엔진, 모니터링 대시보드 — 모두 상호 연결
레퍼런스 아키텍처: 거래소 커넥터, 컬럼나 데이터베이스 코어, 분석 레이어, 전략 엔진, 모니터링 대시보드 — 모두 상호 연결
암호화폐 시장을 위한 완전한 QuestDB 알고리즘 트레이딩 플랫폼을 설계해 봅시다. 이 아키텍처는 여러 거래소에서의 수집, 실시간 분석, 백테스트, 전략 실행을 처리합니다.
데이터 수집 레이어
 데이터 수집: 여러 거래소 커넥터가 WebSocket 파이프라인을 통해 실시간 시장 데이터를 ILP를 통해 QuestDB에 공급
데이터 수집: 여러 거래소 커넥터가 WebSocket 파이프라인을 통해 실시간 시장 데이터를 ILP를 통해 QuestDB에 공급
거래소(Binance, Bybit, OKX 등)에 대한 다수의 WebSocket 연결이 ILP over HTTP를 통해 원시 시장 데이터를 QuestDB에 공급합니다. 각 거래소 커넥터는 별도의 프로세스로, 격리성과 내결함성을 제공합니다.
데이터 스트림은 다음을 포함합니다: 거래(timestamp, symbol, side, price, quantity), 오더북 스냅샷(timestamp, symbol, bids[][], asks[][]), 그리고 보조 스트림으로서의 펀딩 레이트 및 청산.
수집 처리량 목표: 모든 거래소를 합산하여 초당 수백만 행. QuestDB의 WAL은 이를 무리 없이 처리하며, 중복 거래소 연결에서 불가피하게 발생하는 중복을 중복 제거로 포착합니다.
실시간 분석 레이어
머티리얼라이즈드 뷰가 분석 레이어의 핵심을 형성합니다:
Raw trades → ohlc_1s → ohlc_5s → ohlc_1m → ohlc_5m → ohlc_15m → ohlc_1h → ohlc_1d
각 수준은 증분 방식으로 갱신됩니다. QuestDB의 네이티브 플러그인을 통해 연결된 Grafana 대시보드는 이 뷰들을 캔들스틱 차트용으로 쿼리하며, 과거 데이터 양에 관계없이 5ms 미만의 응답 시간을 달성합니다.
추가 머티리얼라이즈드 뷰는 다음을 계산합니다: 심볼당·일별 VWAP(거래량 가중 평균 가격), 롤링 변동성 추정, 교차 거래소 스프레드 모니터링.
사전 집계 뷰에 대한 LATEST ON 쿼리가 실시간 포트폴리오 대시보드를 구동합니다 — 현재 포지션, 미실현 손익, 거래소별 익스포저를 표시합니다.
전략 엔진
 전략 엔진: 실시간 인디케이터 계산이 알고리즘 의사결정에 데이터를 공급하며, 머티리얼라이즈드 뷰에 의해 최적화된 매수/매도 실행 경로
전략 엔진: 실시간 인디케이터 계산이 알고리즘 의사결정에 데이터를 공급하며, 머티리얼라이즈드 뷰에 의해 최적화된 매수/매도 실행 경로
트레이딩 전략은 QuestDB에 현재 시장 상태와 과거 패턴을 쿼리합니다. QuestDB의 PG wire 프로토콜은 PostgreSQL 드라이버를 가진 어떤 언어든 연결할 수 있음을 의미합니다: 리서치 전략에는 Python, 지연 시간에 민감한 실행에는 Rust 또는 C++.
전략의 핵심 쿼리 패턴: 체결 시점의 시장 상황과 실행 체결을 매칭하는 ASOF JOIN, 각 이벤트 주변의 단기 지표를 계산하는 WINDOW JOIN, 실시간 인디케이터 계산(RSI, 볼린저 밴드, ATR)을 위한 윈도우 함수.
지연 시간이 중요한 전략의 경우, 사전 계산된 머티리얼라이즈드 뷰가 쿼리 시간을 최소화합니다. 50개 심볼을 모니터링하는 그리드 봇은 매 틱마다 50개의 별도 이동 평균을 계산할 필요 없이 — 머티리얼라이즈드 뷰에서 읽습니다.
백테스트 파이프라인
과거 데이터는 오브젝트 스토리지의 Parquet에 저장됩니다. QuestDB는 이를 투명하게 쿼리하지만, 대규모 백테스트 워크로드의 경우 데이터를 Polars, Pandas 또는 DuckDB로 직접 읽을 수도 있습니다 — 데이터베이스를 완전히 우회합니다.
이 이중 접근 패턴은 강력합니다: 라이브 전략은 실시간 결정을 위해 QuestDB의 SQL 인터페이스를 사용하고, 백테스트 프레임워크는 배치 처리를 위해 Parquet/Arrow를 통해 동일한 데이터를 읽습니다. 같은 데이터, 두 개의 최적화된 접근 경로.
모니터링 및 포스트 트레이드 분석
HORIZON JOIN이 포스트 트레이드 분석 파이프라인을 구동합니다:
- 슬리피지 분석: 체결 가격을 체결 시점의 중간 가격과 비교
- 마크아웃 곡선: 각 체결 후 1초, 5초, 30초, 60초의 가격 변동 추적
- 구현 부족: 실행 비용을 스프레드, 일시적 영향, 영구적 영향으로 분해
- 거래소 평가: 거래소 간 체결 품질을 비교하여 주문 라우팅 최적화
이러한 분석은 스케줄 쿼리로 실행되어, 모니터링 대시보드에 데이터를 공급하는 전용 테이블에 결과를 기록합니다. 경보 규칙은 이상 징후 발생 시 트리거됩니다 — 갑작스러운 슬리피지 급증, 비정상적인 마크아웃 패턴, 특정 거래소의 체결 품질 저하.
성능 고려 사항
 프로덕션 성능 튜닝: 지연 시간, 처리량, 메모리 모니터링과 핫-웜-콜드 데이터 수명 주기
프로덕션 성능 튜닝: 지연 시간, 처리량, 메모리 모니터링과 핫-웜-콜드 데이터 수명 주기
프로덕션 배포에서의 실용적인 참고 사항:
파티션 크기 조정: 하루에 수백만 행의 암호화폐 틱 데이터의 경우, PARTITION BY HOUR가 일반적으로 최적입니다. 개별 파티션을 스토리지와 쿼리 성능 모두에서 관리 가능한 크기로 유지합니다.
머티리얼라이즈드 뷰 캐스케이딩: 너무 많은 중간 수준을 만들지 마십시오. 각 수준은 갱신 지연 시간을 추가합니다. 대부분의 사용 사례에서 3-4 수준(1s → 1m → 15m → 1d)이 쿼리 성능과 데이터 신선도 사이에서 좋은 균형을 제공합니다.
중복 제거 오버헤드: 중복 데이터 소스가 있는 테이블에서 중복 제거를 활성화하십시오. 고유 타임스탬프 데이터의 비용은 최소이지만, 컬럼 수준 중복 제거가 필요한 동일 타임스탬프의 많은 행에서는 증가합니다.
메모리 할당: QuestDB의 제로 GC 엔진은 효율적이지만, 핫 파티션과 쓰기 캐시에 충분한 메모리를 할당하십시오. 내장 메트릭스 엔드포인트를 통해 모니터링합니다.
클라이언트 프로토콜 선택: 수집에는 ILP over HTTP를 사용합니다(자동 재시도 및 헬스 체크 포함). 쿼리에는 PG wire를 사용합니다. ILP Protocol Version 2(바이너리 인코딩)는 배열 데이터와 고처리량 double 값에 대해 상당히 더 효율적입니다.
QuestDB vs. 대안 데이터베이스
 경쟁 환경: 주요 역량 차원에서 TimescaleDB, ClickHouse, InfluxDB, kdb+와 비교한 QuestDB의 포지셔닝
경쟁 환경: 주요 역량 차원에서 TimescaleDB, ClickHouse, InfluxDB, kdb+와 비교한 QuestDB의 포지셔닝
트레이딩에서 일반적으로 사용되는 데이터베이스와의 간략한 위치 비교:
vs. TimescaleDB: TimescaleDB는 시계열 확장이 포함된 PostgreSQL입니다. PG의 범용성을 계승하지만 오버헤드도 계승합니다. QuestDB의 네이티브 컬럼나 엔진과 SIMD 실행은 시계열 워크로드에서 훨씬 더 나은 쿼리 성능을 제공하며, ASOF JOIN 같은 기능은 TimescaleDB에 직접적인 등가 기능이 없습니다.
vs. ClickHouse: ClickHouse는 대규모 데이터셋에 대한 분석 쿼리에 탁월합니다. 그러나 시계열을 위해 특별히 설계되지는 않았습니다 — 네이티브 ASOF JOIN, FILL이 포함된 SAMPLE BY, 오더북용 2D 배열이 없습니다. OLAP + 시계열 혼합 워크로드에서는 ClickHouse가 유리할 수 있지만, 순수한 트레이딩 데이터에서는 QuestDB가 더 인체공학적입니다.
vs. InfluxDB: InfluxDB는 다중 거래소 암호화폐 데이터에서 문제가 되는 높은 카디널리티 제한이 있습니다. 그 쿼리 언어(Flux, 현재 지원 중단; InfluxQL)는 QuestDB의 SQL 확장의 표현력에 미치지 못합니다. 대규모 과거 쿼리의 성능은 일반적으로 더 나쁩니다.
vs. kdb+/q: HFT의 골드 스탠다드입니다. kdb+는 특정 싱글 스레드 벡터 연산에서 더 빠르며, q 언어는 매우 간결합니다. 그러나 독점적이고, 비용이 높으며, 학습 곡선이 가파릅니다. QuestDB는 비용의 일부로 80-90%의 기능을 제공하며, 표준 SQL과 오픈소스 라이선스를 갖추고 있습니다.
결론: 트레이딩을 이해하는 데이터베이스
이 세 편의 기사를 통해 QuestDB의 아키텍처(WAL, 컬럼나, Parquet을 활용한 3계층 스토리지), SQL 확장(SAMPLE BY, ASOF JOIN, HORIZON JOIN, WINDOW JOIN, LATEST ON, TWAP), 그리고 실용적 활용(머티리얼라이즈드 뷰, 오더북 배열, 레퍼런스 아키텍처)을 다루었습니다.
일관된 핵심이 있습니다: QuestDB는 바로 알고리즘 트레이딩이 생성하는 워크로드를 위해 설계되었습니다. 데이터베이스에 맞춘 우회 방법을 강요하지 않습니다 — 대신 그 프리미티브가 트레이딩 개념에 직접 매핑됩니다. OHLC 집계는 한 줄입니다. 거래 대 호가 정렬은 단일 JOIN입니다. 포스트 트레이드 분석은 HORIZON JOIN이며, 여러 페이지의 PL/SQL 프로시저가 아닙니다.
트레이딩 인프라를 구축하는 팀 — 암호화폐 시장 데이터 플랫폼, 퀀트 리서치 환경, 완전한 알고리즘 트레이딩 엔진 중 어느 것이든 — QuestDB는 진지하게 평가할 가치가 있습니다. 오픈소스 버전은 대부분의 사용 사례를 커버하며, Enterprise 에디션은 규제 환경의 공백을 채웁니다.
금융 데이터 인프라 환경은 급속히 진화하고 있습니다. 시장의 언어를 말하는 데이터베이스가 승리할 것입니다. QuestDB는 유창합니다.
즐거운 트레이딩을, 그리고 지연 시간이 낮기를 바랍니다.
Citation
@software{soloviov2025questdb_algotrading_p3,
author = {Soloviov, Eugen},
title = {QuestDB for Algorithmic Trading: From Order Books to Production Architecture},
year = {2025},
url = {https://marketmaker.cc/en/blog/post/questdb-algotrading-production},
version = {0.1.0},
description = {Materialized views, 2D array order book analytics, and reference architecture for a QuestDB-powered algorithmic trading platform.}
}
MarketMaker.cc Team
퀀트 리서치 및 전략