Monte Carlo Bootstrap: как получить confidence intervals для бэктеста за 10 строк кода
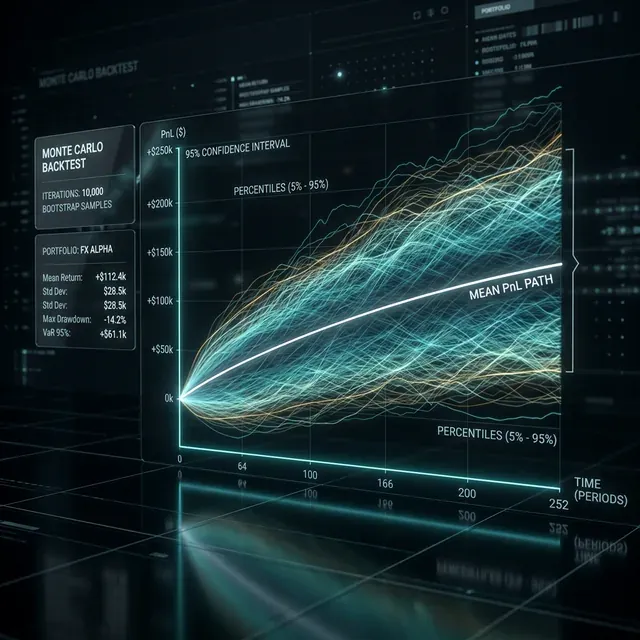
Вы прогнали стратегию через бэктест. Получили PnL +42%, Sharpe 1.8, MaxDD -12%. Результаты выглядят отлично. Вы запускаете бота в продакшен, и через месяц обнаруживаете, что просадка уже -28%, а PnL стремится к нулю.
Что пошло не так? Дело не в баге и не в «изменившемся рынке». Дело в том, что вы приняли решение на основе одного числа — single-point estimate. Вы узнали, что стратегия показала +42%, но не узнали, насколько вы можете доверять этому числу.
Проблема single-point estimate
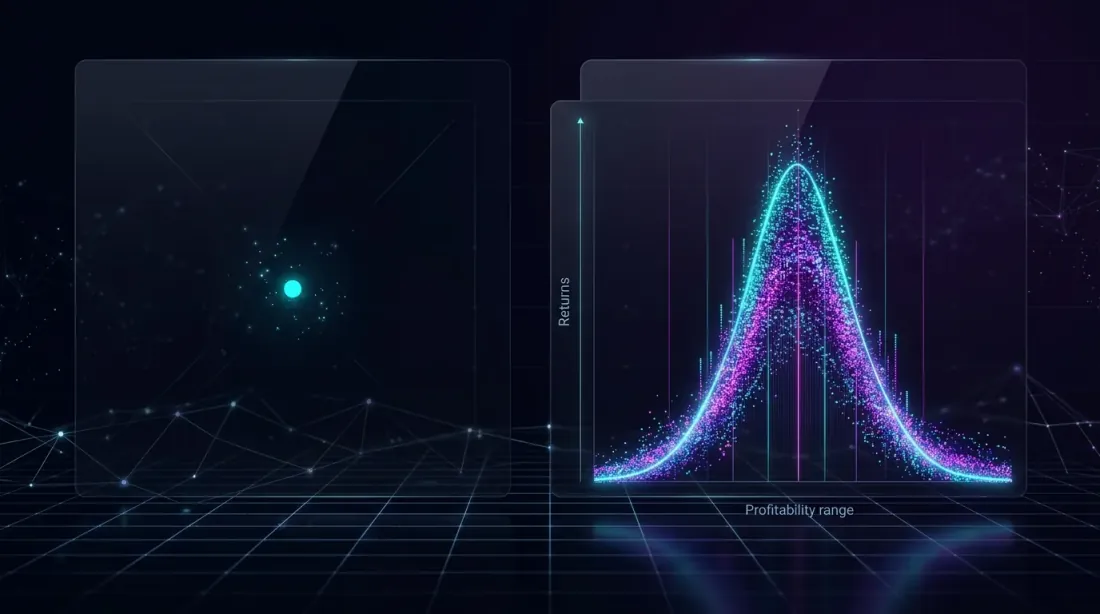 Одна точка данных (слева) даёт обманчивую картину, тогда как полное распределение (справа) раскрывает истинный диапазон возможных исходов.
Одна точка данных (слева) даёт обманчивую картину, тогда как полное распределение (справа) раскрывает истинный диапазон возможных исходов.
Бэктест на исторических данных — это один прогон по одной конкретной последовательности рыночных событий. Результат зависит от порядка сделок: та же стратегия с теми же сделками, но в другом порядке, может показать совершенно другую максимальную просадку.
Представьте 491 сделку. Каждая сделка — это случайное событие с определённым распределением доходности. Исторический бэктест показывает лишь одну реализацию этого процесса. Это как бросить кубик один раз и заключить, что кубик всегда выпадает четвёркой.
Что нам действительно нужно:
- Не точечную оценку, а интервал: «с вероятностью 95% итоговый PnL будет от X до Y»
- Не одну максимальную просадку, а распределение: «в 5% худших сценариев просадка превышает Z%»
- Не среднее, а хвосты: что произойдёт, если удача не на вашей стороне?
Именно для этого существует Monte Carlo bootstrap.
Что такое Monte Carlo bootstrap
 Bootstrap генерирует тысячи альтернативных траекторий эквити путём ресемплинга сделок с возвращением из исходного набора данных.
Bootstrap генерирует тысячи альтернативных траекторий эквити путём ресемплинга сделок с возвращением из исходного набора данных.
Bootstrap — это метод ресемплинга, предложенный Брэдли Эфроном в 1979 году. Идея элегантна: если у нас есть выборка данных, мы можем сгенерировать тысячи «новых» выборок, случайным образом выбирая элементы из исходной с возвращением (with replacement).
В контексте бэктеста это работает так:
- У вас есть массив доходностей по каждой сделке — например, 491 значение
- Вы случайным образом выбираете из этого массива 491 значение с возвращением — некоторые сделки попадут дважды, некоторые не попадут вовсе
- Строите equity curve из этой новой выборки
- Повторяете 10 000 раз
- Получаете распределение итоговых метрик, а не одно число
Каждая итерация — это один «альтернативный сценарий»: что могло бы случиться, если бы порядок и набор сделок были немного другими.
Реализация за 10 строк
Вот полная рабочая реализация:
import numpy as np
def max_drawdown(equity_curve):
"""Рассчитаем максимальную просадку equity curve."""
peak = np.maximum.accumulate(equity_curve)
drawdown = (equity_curve - peak) / peak
return drawdown.min()
trade_returns = [...] # 491 значение, например [0.012, -0.005, 0.008, ...]
n_simulations = 10000
results = []
for _ in range(n_simulations):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
results.append({
"final_pnl": equity[-1] - 1,
"max_dd": max_drawdown(equity),
"sharpe": np.mean(sampled) / np.std(sampled) * np.sqrt(252)
})
Время выполнения: ~2 секунды на обычном ноутбуке. 10 000 альтернативных историй вашей стратегии.
Извлекаем confidence intervals
 Доверительные интервалы для ключевых метрик стратегии: PnL, MaxDD и Sharpe Ratio — с полосами 5-го (худший), 50-го (медиана) и 95-го (лучший) перцентилей.
Доверительные интервалы для ключевых метрик стратегии: PnL, MaxDD и Sharpe Ratio — с полосами 5-го (худший), 50-го (медиана) и 95-го (лучший) перцентилей.
Теперь у нас есть не одно число, а распределение. Вот как извлечь из него полезную информацию:
import pandas as pd
df = pd.DataFrame(results)
pnl_5 = np.percentile(df['final_pnl'], 5)
pnl_50 = np.percentile(df['final_pnl'], 50)
pnl_95 = np.percentile(df['final_pnl'], 95)
dd_5 = np.percentile(df['max_dd'], 5) # 5th — worst case
dd_50 = np.percentile(df['max_dd'], 50)
dd_95 = np.percentile(df['max_dd'], 95) # 95th — best case
print(f"PnL: {pnl_5:.1%} | {pnl_50:.1%} | {pnl_95:.1%}")
print(f"MaxDD: {dd_5:.1%} | {dd_50:.1%} | {dd_95:.1%}")
print(f"Sharpe: {np.percentile(df['sharpe'], 5):.2f} — {np.percentile(df['sharpe'], 95):.2f}")
Пример вывода для реальной стратегии:
| Метрика | 5th percentile (worst) | Медиана | 95th percentile (best) |
|---|---|---|---|
| PnL | +18.3% | +41.7% | +72.1% |
| MaxDD | -23.4% | -12.8% | -5.1% |
| Sharpe | 1.12 | 1.76 | 2.41 |
Теперь разница очевидна:
- Бэктест показал PnL +42% — но в 5% худших сценариев PnL всего +18.3%
- Бэктест показал MaxDD -12% — но в 5% худших сценариев просадка -23.4%
- Sharpe 1.8 — но нижняя граница 1.12
5th percentile — это ваш «реалистичный худший случай». Если стратегия перестаёт быть прибыльной уже на 5-м перцентиле, запускать её в продакшен рискованно.
Визуализация: fan chart
Monte Carlo bootstrap естественно визуализируется как fan chart — веер эквити-кривых:
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
ax = axes[0]
for i in range(min(500, n_simulations)):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
ax.plot(equity, alpha=0.02, color='#4FC3F7')
all_equities = []
for _ in range(n_simulations):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
all_equities.append(equity)
all_equities = np.array(all_equities)
p5 = np.percentile(all_equities, 5, axis=0)
p50 = np.percentile(all_equities, 50, axis=0)
p95 = np.percentile(all_equities, 95, axis=0)
ax.fill_between(range(len(p5)), p5, p95, alpha=0.3, color='#7C4DFF', label='90% CI')
ax.plot(p50, color='#E040FB', linewidth=2, label='Медиана')
ax.set_title('Monte Carlo Bootstrap: Equity Curves')
ax.legend()
ax = axes[1]
ax.hist(df['final_pnl'] * 100, bins=80, color='#4FC3F7', alpha=0.7, edgecolor='#1A237E')
ax.axvline(pnl_5 * 100, color='#FF5252', linestyle='--', label=f'5th: {pnl_5:.1%}')
ax.axvline(pnl_50 * 100, color='#E040FB', linestyle='--', label=f'Median: {pnl_50:.1%}')
ax.axvline(pnl_95 * 100, color='#69F0AE', linestyle='--', label=f'95th: {pnl_95:.1%}')
ax.set_title('Распределение итогового PnL')
ax.set_xlabel('PnL, %')
ax.legend()
plt.tight_layout()
plt.savefig('monte_carlo_fan_chart.png', dpi=150)
plt.show()
Fan chart даёт интуитивное понимание разброса возможных исходов. Узкий веер — стратегия стабильна. Широкий — результат сильно зависит от «везения» с последовательностью сделок.
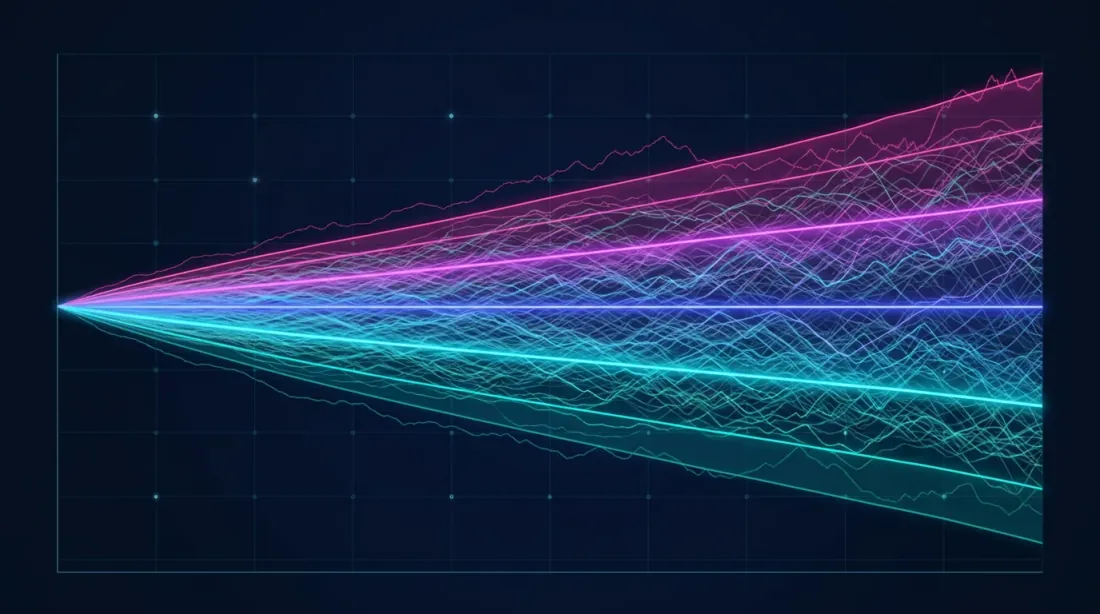 Fan chart (слева) показывает веер возможных траекторий эквити, а гистограмма (справа) — плотность распределения итоговой доходности с выделенными доверительными интервалами (5%, 50%, 95%).
Fan chart (слева) показывает веер возможных траекторий эквити, а гистограмма (справа) — плотность распределения итоговой доходности с выделенными доверительными интервалами (5%, 50%, 95%).
Продвинутый анализ: probability of ruin
 Визуализация вероятности разорения: выжившие траектории эквити (голубые) изгибаются вверх, а обречённые (красные) падают за обрыв нулевого капитала.
Визуализация вероятности разорения: выжившие траектории эквити (голубые) изгибаются вверх, а обречённые (красные) падают за обрыв нулевого капитала.
Bootstrap позволяет ответить на критический вопрос: какова вероятность, что стратегия потеряет X% капитала?
ruin_threshold = -0.20
prob_ruin = (df['max_dd'] < ruin_threshold).mean()
print(f"P(MaxDD < -20%) = {prob_ruin:.1%}")
prob_loss = (df['final_pnl'] < 0).mean()
print(f"P(PnL < 0) = {prob_loss:.1%}")
worst_5pct = df['final_pnl'].quantile(0.05)
cvar = df[df['final_pnl'] <= worst_5pct]['final_pnl'].mean()
print(f"CVaR(5%) = {cvar:.1%}")
Эти метрики невозможно получить из одного прогона бэктеста. А они критичны для принятия решения о запуске стратегии.
Подробнее о том, почему глубокие просадки математически опасны и как работает асимметрия доходностей, читайте в нашей статье Асимметрия убытков и прибылей.
Когда классический bootstrap не работает
У метода есть ограничения, о которых важно знать.
Автокорреляция доходностей
Классический bootstrap предполагает, что сделки независимы. В реальности это часто не так — стратегия может иметь серии выигрышных и проигрышных сделок (streaks). Если автокорреляция значима, используйте block bootstrap:
def block_bootstrap(returns, block_size=10, n_simulations=10000):
"""Bootstrap с сохранением локальной структуры зависимостей."""
n = len(returns)
results = []
for _ in range(n_simulations):
starts = np.random.randint(0, n - block_size + 1, size=n // block_size + 1)
sampled = np.concatenate([returns[s:s+block_size] for s in starts])[:n]
equity = np.cumprod(1 + sampled)
results.append({
"final_pnl": equity[-1] - 1,
"max_dd": max_drawdown(equity),
})
return pd.DataFrame(results)
Block bootstrap сохраняет локальные зависимости между последовательными сделками, давая более реалистичные confidence intervals для MaxDD.
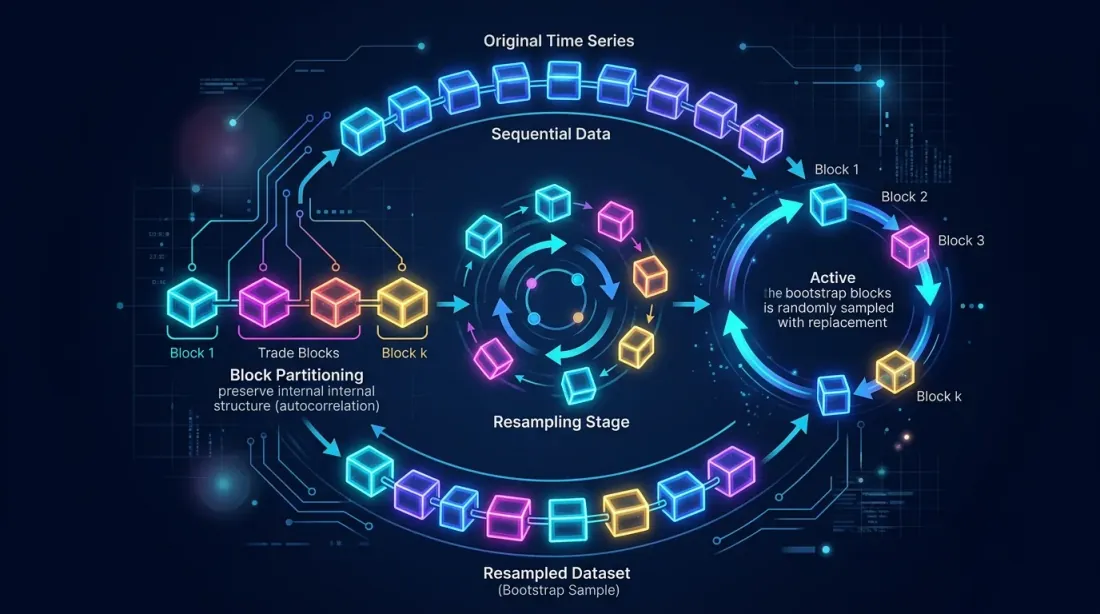 Block bootstrap сохраняет автокорреляцию внутри блоков, разбивая последовательность сделок на блоки и ресемплируя их с возвращением.
Block bootstrap сохраняет автокорреляцию внутри блоков, разбивая последовательность сделок на блоки и ресемплируя их с возвращением.
Нестационарность рынка
Bootstrap работает с исходным распределением сделок. Если рынок структурно изменился (например, упала волатильность или изменилась ликвидность), исторические сделки могут быть нерепрезентативны. Для учёта этого:
- Используйте скользящее окно: bootstrap только по последним N сделкам
- Взвешивайте недавние сделки сильнее: weighted bootstrap
- Разбивайте данные по рыночным режимам и делайте bootstrap отдельно
Малое количество сделок
Bootstrap надёжен при n > 30 сделок. Если у вас 10 сделок — никакой ресемплинг не спасёт. 491 сделка — отличная выборка, результатам можно доверять.
Сравнение подходов к оценке робастности бэктеста
| Метод | Что даёт | Сложность | Время | Когда использовать |
|---|---|---|---|---|
| Single backtest | Одну точечную оценку | Минимальная | Секунды | Никогда как финальный результат |
| Walk-forward | Out-of-sample метрики | Средняя | Минуты | Для проверки переобучения |
| Monte Carlo bootstrap | Confidence intervals | Минимальная | ~2 сек | Всегда перед продакшеном |
| Monte Carlo path | Новые ценовые пути | Высокая | Минуты–часы | Для стресс-тестирования |
| Cross-validation | Средние метрики по фолдам | Средняя | Минуты | Для подбора параметров |
Monte Carlo bootstrap — единственный метод, который за минимальное время даёт полную картину рисков.
Чек-лист: интерпретация результатов
Вот как мы рекомендуем интерпретировать результаты Monte Carlo bootstrap:
✅ Запускаем в продакшен, если:
- PnL на 5-м перцентиле положительный
- MaxDD на 5-м перцентиле приемлемый для вашего риск-аппетита
- Probability of ruin < 1%
- Sharpe на 5-м перцентиле > 0.5
⚠️ Дорабатываем, если:
- PnL на 5-м перцентиле около нуля
- MaxDD на 5-м перцентиле заметно больше, чем на 50-м
- Широкий разброс fan chart — стратегия нестабильна
🛑 Не запускаем, если:
- PnL на 5-м перцентиле отрицательный
- Probability of ruin > 5%
- Confidence interval для Sharpe включает 0
Наш опыт в marketmaker.cc
В marketmaker.cc мы разрабатываем собственный backtest-движок, и Monte Carlo bootstrap — неотъемлемая часть нашего пайплайна. Каждая стратегия проходит через bootstrap автоматически перед допуском к live-торговле.
Мы интегрировали bootstrap прямо в движок бэктеста: после прогона вы получаете не просто итоговый PnL, а полный отчёт с confidence intervals, fan chart, probability of ruin и сравнением block vs. standard bootstrap. Это занимает дополнительные 2-3 секунды — ничтожная цена за понимание реальных рисков.
Из нашего опыта: примерно 30% стратегий, которые выглядят привлекательно по single-point estimate, отсеиваются после Monte Carlo bootstrap. Их 5-й перцентиль PnL уходит в отрицательную зону или MaxDD оказывается неприемлемым. Без bootstrap эти стратегии попали бы в продакшен и с высокой вероятностью принесли бы убытки.
Заключение
Monte Carlo bootstrap — это ~10 строк кода и ~2 секунды вычислений. Он превращает одно число из бэктеста в полноценное распределение с confidence intervals. Это, пожалуй, самый высокий ROI из всех инструментов квантового анализа:
- Минимальные затраты: реализация за 30 минут
- Максимальная отдача: понимание реальных рисков стратегии
- Нет зависимостей: только NumPy
Если вы ещё не используете bootstrap — добавьте его в свой пайплайн сегодня. Это единственный способ узнать, насколько вы можете доверять результатам бэктеста.
Полезные ссылки
- Efron, B. — Bootstrap Methods: Another Look at the Jackknife (1979)
- Davison, A.C., Hinkley, D.V. — Bootstrap Methods and their Application (Cambridge)
- Aronson, D.R. — Evidence-Based Technical Analysis: Monte Carlo permutation
- QuantStart — Monte Carlo Simulation for Backtest Analysis
- Marcos López de Prado — Advances in Financial Machine Learning, Chapter 12: Backtesting
- Kevin Davey — Building Winning Algorithmic Trading Systems: Monte Carlo Analysis
- NumPy — numpy.random.choice
Цитирование
@software{soloviov2026montecarlobootstrap,
author = {Soloviov, Eugen},
title = {Monte Carlo Bootstrap: как получить confidence intervals для бэктеста за 10 строк кода},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/monte-carlo-bootstrap-backtest},
version = {0.1.0},
description = {Почему single-point estimate из бэктеста — опасная иллюзия. Как Monte Carlo bootstrap за 2 секунды вычислений даёт 95% confidence interval для PnL и MaxDD, и почему это обязательный шаг перед запуском стратегии в продакшен.}
}
Авторы

Инженер торговых систем
Разработка торговых ботов с 2017 года: межбиржевой арбитраж (подключал до 30 бирж), парный арбитраж на коинтеграции между спотом и фьючерсами, скальпинг, фронтраннинг, торговля по новостям, сентиментный анализ, трендовые алгоритмы, а также алгоритмы управления и балансировки портфелей. Делает выставление ордеров до 1 мс, warehouse для big data, бэктестинг-движки, AI-агентов и интерфейсы для ботов (в т.ч. open-source profitmaker.cc). Стек: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, архитектура.
Читайте также

PnL по активному времени: метрика, которая меняет ранжирование стратегий

Funding rates убивают ваш leverage: почему PnL×50x — фикция