QuestDB для алготрейдинга: от стаканов заявок до продакшн-архитектуры

Часть 3 из 3 — также доступно на EN · ZH
Дисклеймер: информация в этой статье предназначена исключительно для образовательных и информационных целей и не является финансовой, инвестиционной или торговой рекомендацией. Торговля криптовалютами сопряжена со значительным риском потерь.
Добро пожаловать в заключительную часть нашей серии о QuestDB. В Части 1 мы рассмотрели архитектуру хранения. В Части 2 — SQL-расширения. Теперь соберём всё воедино: материализованные представления для аналитики в реальном времени, нативное хранение стакана заявок с 2D-массивами и референсную архитектуру промышленной алготрейдинговой платформы.
Материализованные представления: предвычисленная аналитика на скорости сети
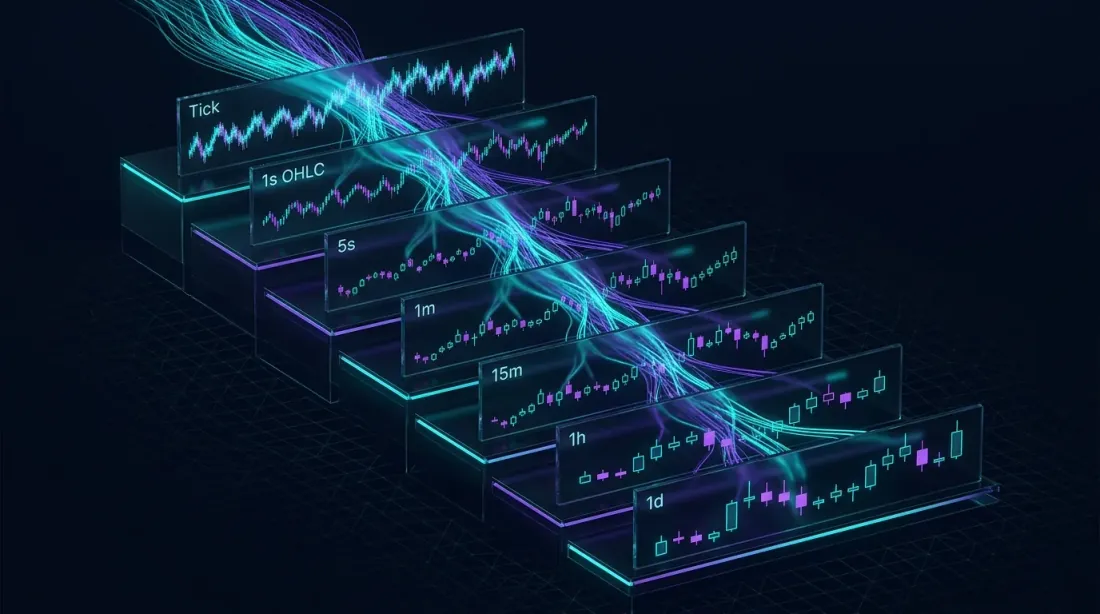 Каскадные материализованные представления: сырые тиковые данные проходят через последовательные уровни агрегации, каждый из которых обрабатывает значительно меньший объём данных
Каскадные материализованные представления: сырые тиковые данные проходят через последовательные уровни агрегации, каждый из которых обрабатывает значительно меньший объём данных
Если SAMPLE BY — наиболее используемый запрос QuestDB, то материализованные представления — его наиболее значимая оптимизация. Концепция проста: вместо того чтобы вычислять OHLCV-агрегации при каждом обновлении дашборда или API-вызове, вычислить их один раз и поддерживать результат в актуальном состоянии непрерывно.
Базовое материализованное представление OHLC
CREATE MATERIALIZED VIEW trades_OHLC_15m
WITH BASE 'trades'
REFRESH IMMEDIATE
AS
SELECT timestamp, symbol,
first(price) AS open,
max(price) AS high,
min(price) AS low,
last(price) AS close,
sum(quantity) AS volume
FROM trades
SAMPLE BY 15m;
Это всё определение. Каждый раз, когда в таблицу trades вставляются новые строки, QuestDB автоматически и инкрементально обновляет это представление. Не полное пересчитывание — обновляются только затронутые временны́е интервалы. Запросы к trades_OHLC_15m превращаются в простой поиск по значительно меньшему, предварительно агрегированному набору данных.
Разница в производительности разительна. На таблице с миллиардами строк запрос к базовой таблице для получения OHLC-данных может занять 200 мс. Материализованное представление возвращает тот же результат менее чем за 5 мс. При нескольких одновременных пользователях дашборда это не просто оптимизация — это разница между отзывчивой системой и той, которая падает под нагрузкой.
Каскадные представления: несколько таймфреймов из единого источника
Вот где материализованные представления приобретают архитектурную элегантность. Их можно выстраивать в цепочку — каждое представление питает следующее, создавая иерархию уровней агрегации из единого источника сырых данных:
-- 1-секундные бары из сырых сделок
CREATE MATERIALIZED VIEW ohlc_1s AS
SELECT timestamp, symbol,
first(price) AS open, max(price) AS high,
min(price) AS low, last(price) AS close,
sum(quantity) AS volume
FROM trades
SAMPLE BY 1s;
-- 5-секундные бары из 1-секундных баров
CREATE MATERIALIZED VIEW ohlc_5s AS
SELECT timestamp, symbol,
first(open) AS open, max(high) AS high,
min(low) AS low, last(close) AS close,
sum(volume) AS volume
FROM ohlc_1s
SAMPLE BY 5s;
-- 1-минутные бары из 5-секундных баров
CREATE MATERIALIZED VIEW ohlc_1m AS
SELECT timestamp, symbol,
first(open) AS open, max(high) AS high,
min(low) AS low, last(close) AS close,
sum(volume) AS volume
FROM ohlc_5s
SAMPLE BY 1m;
Каждый уровень обрабатывает кардинально меньший набор данных, чем предыдущий. Минутное представление не сканирует сырые сделки — оно читает только предварительно агрегированные 5-секундные бары. Этот каскадный паттерн масштабируется на любое число таймфреймов: 1s → 5s → 1m → 5m → 15m → 1h → 4h → 1d.
Для криптовалютной data-платформы, принимающей данные с 100+ бирж, это основа всего конвейера доставки OHLC.
Стратегии обновления
QuestDB предлагает три режима обновления, каждый из которых подходит для разных нагрузок:
REFRESH IMMEDIATE запускает асинхронное обновление после каждой транзакции в базовой таблице. Лучший выбор для дашбордов реального времени, где важна задержка менее секунды.
REFRESH EVERY 1h (по таймеру) объединяет обновления в периодические обновления. Лучше для высокопроизводительной записи, где запуск обновления при каждом микробатче создавал бы накладные расходы.
REFRESH PERIOD (LENGTH 1d TIME ZONE 'Europe/London' DELAY 2h) определяет периоды, выровненные по календарю. «Задержка» учитывает данные с опозданием — критически важно для рынков, которые могут присылать корректирующие фиды спустя часы после торговой сессии.
REFRESH MANUAL даёт полный контроль. Представление обновляется только при явном выполнении команды REFRESH — полезно для рабочих процессов сверки по окончании дня.
Паттерн ускорения с LATEST ON
Один из наиболее мощных паттернов объединяет материализованные представления с LATEST ON для мгновенных снимков портфеля. Сканирование 1,3 миллиарда сырых строк для получения последней цены каждого символа занимает секунды. Но с дневным предварительно агрегированным представлением:
CREATE MATERIALIZED VIEW trades_latest_1d AS
SELECT timestamp, symbol, side,
last(price) AS price,
last(quantity) AS quantity,
last(timestamp) AS latest
FROM trades
SAMPLE BY 1d;
Запрос LATEST ON сканирует примерно 25 000 предварительно агрегированных строк вместо миллиардов:
SELECT symbol, side, price, quantity, latest AS timestamp
FROM (
trades_latest_1d
LATEST ON timestamp PARTITION BY symbol, side
)
ORDER BY timestamp DESC;
От секунд до миллисекунд. Вот как промышленные торговые дашборды достигают отзывчивости реального времени на огромных наборах данных.
TTL: автоматический жизненный цикл данных
Материализованные представления поддерживают политики TTL (time-to-live) для автоматического истечения данных:
CREATE MATERIALIZED VIEW ohlc_1h AS (
SELECT timestamp, symbol,
avg(price) AS avg_price
FROM trades
SAMPLE BY 1h
) PARTITION BY WEEK TTL 8 WEEKS;
Это хранит 8 недель почасовых данных, автоматически удаляя более старые секции. В сочетании с трёхуровневым движком хранения вы получаете естественный жизненный цикл данных: сырые тики проходят через WAL → колоночное хранилище → Parquet в объектном хранилище, тогда как материализованные представления поддерживают предварительно агрегированные сводки, с которыми реально работают ваши приложения.
2D-массивы: нативная аналитика стакана заявок
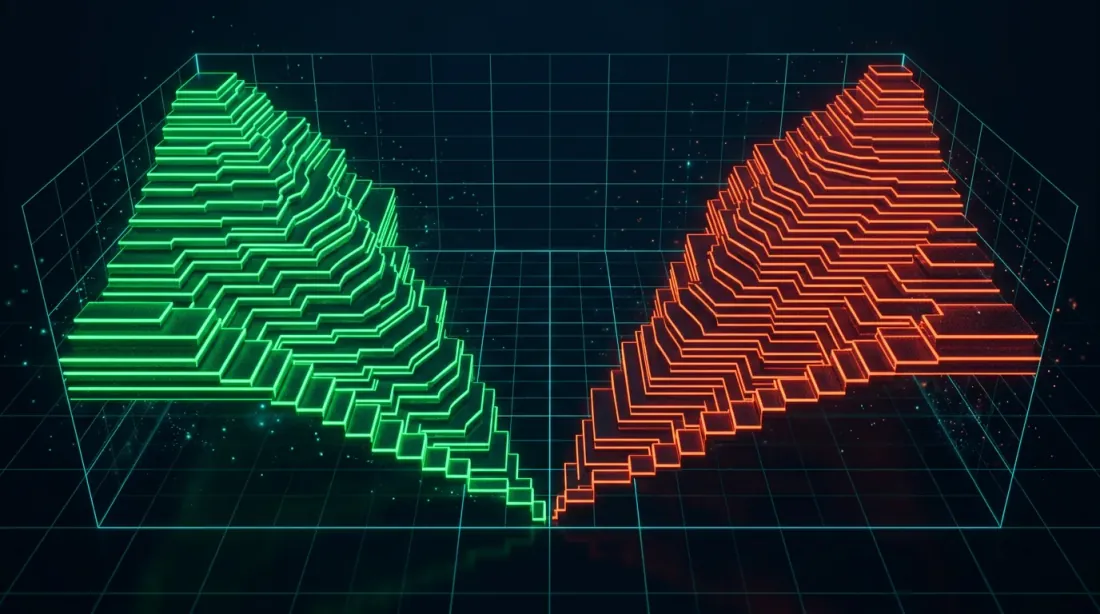 3D-визуализация стакана заявок: уровни bid и ask хранятся как нативные 2D-массивы, обеспечивая SIMD-оптимизированные расчёты спреда и анализ ликвидности
3D-визуализация стакана заявок: уровни bid и ask хранятся как нативные 2D-массивы, обеспечивая SIMD-оптимизированные расчёты спреда и анализ ликвидности
QuestDB 9.0 представил N-мерные массивы — настоящие массивы с формой и шагом, похожие на NumPy, обрабатывающие типичные операции (срезы, транспонирование) без копирования. Для трейдинга killer application — хранение стакана заявок.
Традиционная проблема
Исторически хранение снимков стакана заявок в реляционной базе данных было болезненным. Было два выбора: одна строка на ценовой уровень (взрыв строк, дорогой запрос глубины) или фиксированное число столбцов вроде bid1_price, bid1_size, bid2_price, bid2_size и т.д. (жёстко, расточительно и некрасиво).
2D-массивы QuestDB устраняют обе проблемы:
CREATE TABLE market_data (
timestamp TIMESTAMP,
symbol SYMBOL,
bids DOUBLE[][],
asks DOUBLE[][]
) TIMESTAMP(timestamp) PARTITION BY HOUR;
Каждый столбец bids и asks хранит 2D-массив, где первая строка содержит цены, а вторая — объёмы на каждом уровне. Стакан заявок из 20 уровней — это единственный компактный массив, а не 40 отдельных столбцов.
Аналитика стакана заявок в SQL
Расчёт спреда — наиболее базовая и наиболее часто вычисляемая метрика:
SELECT timestamp,
spread(bids[1][1], asks[1][1]) AS spread
FROM market_data
WHERE symbol = 'EURUSD'
AND timestamp IN today();
Функция spread() — встроенная, вычисляющая разность между лучшим ask и лучшим bid. bids[1][1] обращается к первому элементу (лучшей цене) первой строки (цен) в массиве bids.
Для более сложной аналитики — глубины ликвидности, дисбаланса стакана заявок, вероятности исполнения на заданном ценовом уровне — срезы массивов и векторизованные операции делают прежде сложные запросы простыми:
-- Найти уровень, на котором будет достигнута целевая цена,
-- и суммировать все объёмы до этого уровня
DECLARE @target := bids[1][1] * 1.01;
SELECT timestamp,
array_sum(asks[2][1:level_idx]) AS volume_to_fill
FROM market_data
WHERE symbol = 'EURUSD';
SIMD-оптимизированные операции над массивами означают, что эти вычисления выполняются на скорости, близкой к аппаратной, даже на миллионах снимков.
Приём данных массивов
Клиентские библиотеки QuestDB поддерживают нативный приём массивов. Python-клиент интегрируется напрямую с NumPy-массивами:
import numpy as np
from questdb.ingress import Sender
bids = np.array([[9.3, 9.2, 9.1], [100, 200, 150]]) # цены, объёмы
asks = np.array([[9.5, 9.6, 9.7], [80, 160, 120]])
with Sender.from_conf("http::addr=localhost:9000;") as sender:
sender.row(
'market_data',
symbols={'symbol': 'EURUSD'},
columns={'bids': bids, 'asks': asks},
at=timestamp
)
Protocol Version 2 кодирует массивы в бинарной форме, существенно снижая полосу пропускания и накладные расходы на серверный парсинг по сравнению с текстовыми протоколами. Для высокочастотного приёма стакана заявок — где вы можете получать тысячи снимков в секунду на символ — эта эффективность имеет значение.
Клиенты C/C++ используют плоские массивы в порядке строк с дескрипторами формы, обеспечивая приём без копирования из существующих структур данных торговых систем.
Всё вместе: референсная архитектура
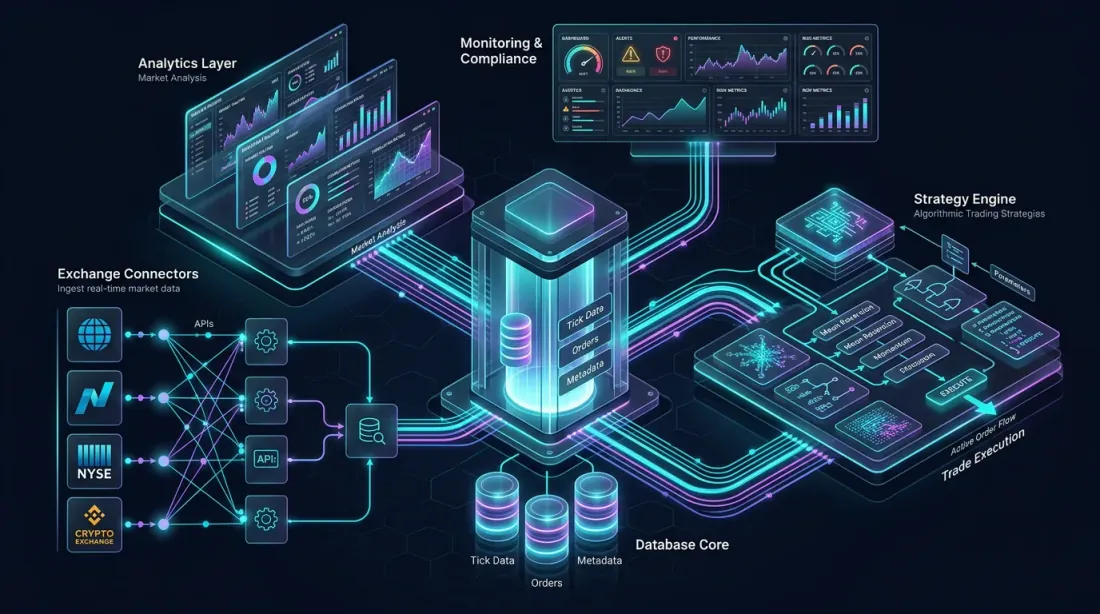 Референсная архитектура: биржевые коннекторы, ядро колоночной базы данных, аналитический слой, движок стратегий и мониторинговые дашборды — все взаимосвязаны
Референсная архитектура: биржевые коннекторы, ядро колоночной базы данных, аналитический слой, движок стратегий и мониторинговые дашборды — все взаимосвязаны
Спроектируем полноценную алготрейдинговую платформу на основе QuestDB для криптовалютных рынков. Эта архитектура обрабатывает приём данных с нескольких бирж, аналитику в реальном времени, бэктестирование и исполнение стратегий.
Слой приёма данных
 Приём данных: множество биржевых коннекторов подают рыночные данные в реальном времени через WebSocket-каналы в QuestDB по протоколу ILP
Приём данных: множество биржевых коннекторов подают рыночные данные в реальном времени через WebSocket-каналы в QuestDB по протоколу ILP
Несколько WebSocket-соединений с биржами (Binance, Bybit, OKX и др.) подают сырые рыночные данные в QuestDB через ILP по HTTP. Каждый биржевой коннектор — отдельный процесс, обеспечивающий изоляцию и отказоустойчивость.
Потоки данных включают: сделки (timestamp, symbol, side, price, quantity), снимки стакана заявок (timestamp, symbol, bids[][], asks[][]) и ставки финансирования/ликвидации как вспомогательные потоки.
Целевая пропускная способность приёма: миллионы строк в секунду по всем биржам. WAL QuestDB справляется с этим комфортно, а дедупликация отлавливает неизбежные дубликаты от дублирующих соединений с биржами.
Слой аналитики в реальном времени
Материализованные представления образуют ядро аналитического слоя:
Сырые сделки → ohlc_1s → ohlc_5s → ohlc_1m → ohlc_5m → ohlc_15m → ohlc_1h → ohlc_1d
Каждый уровень обновляется инкрементально. Дашборд Grafana, подключённый через нативный плагин QuestDB, запрашивает эти представления для свечных графиков с временем отклика менее 5 мс вне зависимости от объёма исторических данных.
Дополнительные материализованные представления вычисляют: VWAP (взвешенную по объёму среднюю цену) по символу за день, скользящие оценки волатильности и мониторинг спреда между биржами.
Запросы LATEST ON к предварительно агрегированным представлениям питают дашборд портфеля в реальном времени — отображая текущие позиции, нереализованный P&L и экспозицию по биржам.
Движок стратегий
 Движок стратегий: вычисление индикаторов в реальном времени питает алгоритмическое принятие решений, а пути исполнения buy/sell оптимизированы через материализованные представления
Движок стратегий: вычисление индикаторов в реальном времени питает алгоритмическое принятие решений, а пути исполнения buy/sell оптимизированы через материализованные представления
Торговые стратегии запрашивают QuestDB для получения текущего состояния рынка и исторических паттернов. Протокол PG wire QuestDB означает, что подключиться может любой язык с PostgreSQL-драйвером: Python для исследовательских стратегий, Rust или C++ для чувствительного к задержкам исполнения.
Ключевые паттерны запросов для стратегий: ASOF JOIN для сопоставления исполненных заявок с рыночными условиями на момент исполнения, WINDOW JOIN для вычисления краткосрочных метрик вокруг каждого события и оконные функции для вычисления индикаторов в реальном времени (RSI, полосы Боллинджера, ATR).
Для критичных к задержке стратегий предварительно вычисленные материализованные представления минимизируют время запроса. Грид-бот, следящий за 50 символами, не должен вычислять 50 отдельных скользящих средних на каждый тик — он читает их из материализованного представления.
Конвейер бэктестирования
Исторические данные живут в Parquet в объектном хранилище. QuestDB запрашивает их прозрачно, но для тяжёлых нагрузок бэктестирования данные также можно читать напрямую через Polars, Pandas или DuckDB — обходя базу данных полностью.
Этот паттерн двойного доступа мощен: живая стратегия использует SQL-интерфейс QuestDB для решений в реальном времени, тогда как фреймворк бэктестирования читает те же данные через Parquet/Arrow для пакетной обработки. Одни данные, два оптимизированных пути доступа.
Мониторинг и постторговый анализ
HORIZON JOIN питает конвейер постторгового анализа:
- Анализ проскальзывания: сравнение цены исполнения со средней ценой на момент заявки
- Кривые маркаута: отслеживание эволюции цены через 1с, 5с, 30с, 60с после каждого исполнения
- Implementation shortfall: декомпозиция издержек исполнения на спред, временное воздействие и постоянное воздействие
- Оценка площадок: сравнение качества исполнения по биржам для оптимизации маршрутизации ордеров
Эти анализы выполняются как запланированные запросы, записывая результаты в специальные таблицы, питающие мониторинговые дашборды. Правила оповещения срабатывают на аномалии — внезапные всплески проскальзывания, нетипичные паттерны маркаута или ухудшение качества исполнения на конкретных площадках.
Вопросы производительности
 Тюнинг производительности в продакшне: мониторинг задержки, пропускной способности и памяти наряду с жизненным циклом данных hot-warm-cold
Тюнинг производительности в продакшне: мониторинг задержки, пропускной способности и памяти наряду с жизненным циклом данных hot-warm-cold
Несколько практических замечаний из промышленных развёртываний:
Размер секций: для криптотиковых данных с миллионами строк в день PARTITION BY HOUR обычно оптимален. Это держит отдельные секции управляемыми как для хранения, так и для производительности запросов.
Каскадирование материализованных представлений: не создавайте слишком много промежуточных уровней. Каждый уровень добавляет задержку обновления. Для большинства случаев 3-4 уровня (1s → 1m → 15m → 1d) обеспечивают хороший баланс между производительностью запросов и свежестью данных.
Накладные расходы дедупликации: включайте дедупликацию на таблицах с дублирующими источниками данных. Стоимость минимальна для данных с уникальными временны́ми метками, но возрастает при большом числе строк с одинаковыми метками, требующих дедупликации на уровне столбцов.
Выделение памяти: zero-GC движок QuestDB эффективен, но выделяйте достаточно памяти для горячих секций и кэша записи. Контролируйте через встроенный endpoint метрик.
Выбор клиентского протокола: используйте ILP по HTTP для записи (с автоматическими повторными попытками и проверками работоспособности). Используйте PG wire для запросов. ILP Protocol Version 2 (бинарное кодирование) значительно эффективнее для данных массивов и высокопроизводительных значений с плавающей точкой.
QuestDB против альтернатив
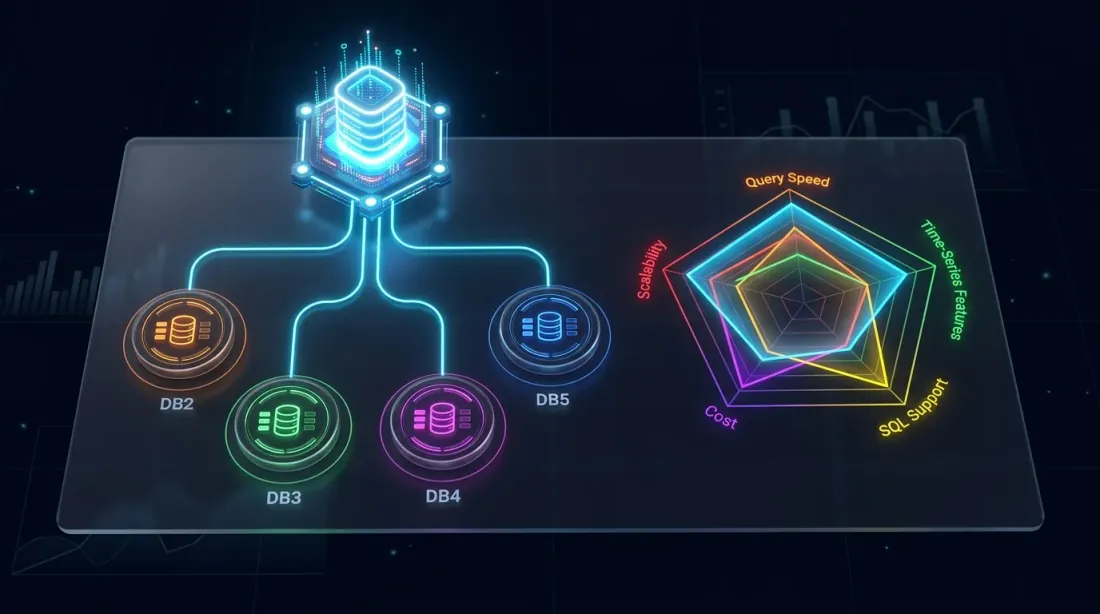 Конкурентный ландшафт: QuestDB в сравнении с TimescaleDB, ClickHouse, InfluxDB и kdb+ по ключевым параметрам
Конкурентный ландшафт: QuestDB в сравнении с TimescaleDB, ClickHouse, InfluxDB и kdb+ по ключевым параметрам
Краткое позиционирование относительно баз данных, обычно используемых в трейдинге:
vs. TimescaleDB: TimescaleDB — это PostgreSQL с расширениями для временны́х рядов. Он наследует общность PG, но и его накладные расходы. Нативный колоночный движок QuestDB и SIMD-исполнение обеспечивают значительно лучшую производительность запросов на нагрузках временны́х рядов, а такие возможности как ASOF JOIN не имеют прямого аналога в TimescaleDB.
vs. ClickHouse: ClickHouse превосходен в аналитических запросах на огромных наборах данных. Но он не проектировался специально для временны́х рядов — нет нативного ASOF JOIN, нет SAMPLE BY с FILL, нет 2D-массивов для стакана заявок. Для смешанных OLAP + time-series нагрузок ClickHouse может выиграть; для чисто торговых данных QuestDB более эргономичен.
vs. InfluxDB: InfluxDB имеет ограничения высокой кардинальности, болезненные для многобиржевых криптоданных. Его язык запросов (Flux, ныне устаревший; InfluxQL) уступает в выразительности SQL-расширениям QuestDB. Производительность на больших исторических запросах в целом хуже.
vs. kdb+/q: золотой стандарт для HFT. kdb+ быстрее для определённых однопоточных векторных операций, а язык q невероятно лаконичен. Но он проприетарный, дорогой и имеет высокий порог вхождения. QuestDB предлагает 80-90% возможностей за долю стоимости, со стандартным SQL и open-source лицензированием.
Заключение: база данных, понимающая трейдинг
В этих трёх статьях мы рассмотрели архитектуру QuestDB (трёхуровневое хранение с WAL, колоночным форматом и Parquet), его SQL-расширения (SAMPLE BY, ASOF JOIN, HORIZON JOIN, WINDOW JOIN, LATEST ON, TWAP) и его практические применения (материализованные представления, массивы стакана заявок, референсная архитектура).
Сквозная нить последовательна: QuestDB спроектирован именно для нагрузок, которые порождает алгоритмическая торговля. Он не заставляет вас обходить базу данных — напротив, его примитивы напрямую отображаются на торговые концепции. Агрегация OHLC — одна строка. Выравнивание сделок с котировками — один JOIN. Постторговый анализ — HORIZON JOIN, а не многостраничная PL/SQL-процедура.
Для команд, строящих торговую инфраструктуру — будь то криптовалютная платформа рыночных данных, среда количественных исследований или полноценный алготрейдинговый движок — QuestDB заслуживает серьёзной оценки. Open-source версия покрывает большинство случаев использования, а Enterprise-редакция закрывает пробелы для регулируемых сред.
Ландшафт финансовой инфраструктуры данных быстро меняется. Базы данных, говорящие на языке рынков, победят. QuestDB владеет этим языком в совершенстве.
Удачной торговли, и пусть ваши задержки будут минимальными.
Цитирование
@software{soloviov2025questdb_algotrading_p3,
author = {Soloviov, Eugen},
title = {QuestDB for Algorithmic Trading: From Order Books to Production Architecture},
year = {2025},
url = {https://marketmaker.cc/en/blog/post/questdb-algotrading-production},
version = {0.1.0},
description = {Materialized views, 2D array order book analytics, and reference architecture for a QuestDB-powered algorithmic trading platform.}
}
MarketMaker.cc Team
Количественные исследования и стратегии
Читайте также

QuestDB для алготрейдинга: SQL-расширения, меняющие правила игры

QuestDB для алготрейдинга: архитектура, говорящая на языке рынков
