分钟级K线是回测的标准粒度。但在一根分钟K线内,价格的波动幅度各不相同:有时仅为0.01%,有时却达到2%。当止损和止盈同时落在一根分钟K线的[最低价, 最高价]范围内时,回测无法知道哪个先被触发。这就是成交歧义(fill ambiguity)问题。
朴素的解决方案是对整个回测使用秒级数据。但两年的数据意味着约6300万根秒级K线,而非约100万根分钟K线。存储空间增加60倍,速度也按比例下降。
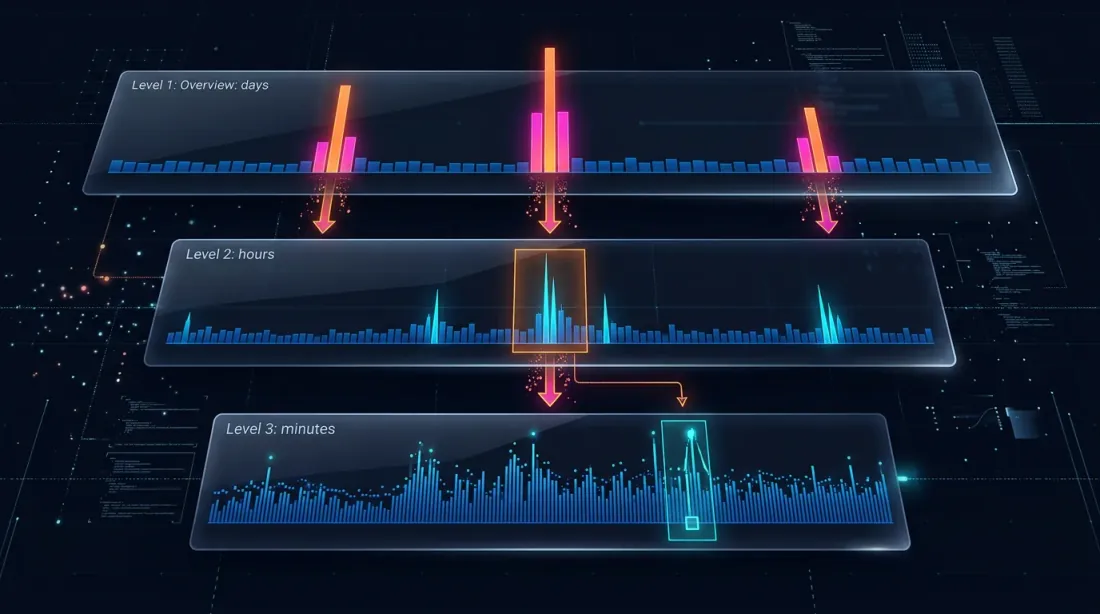
自适应下钻解决了这个问题:仅在真正需要的地方使用更细粒度。
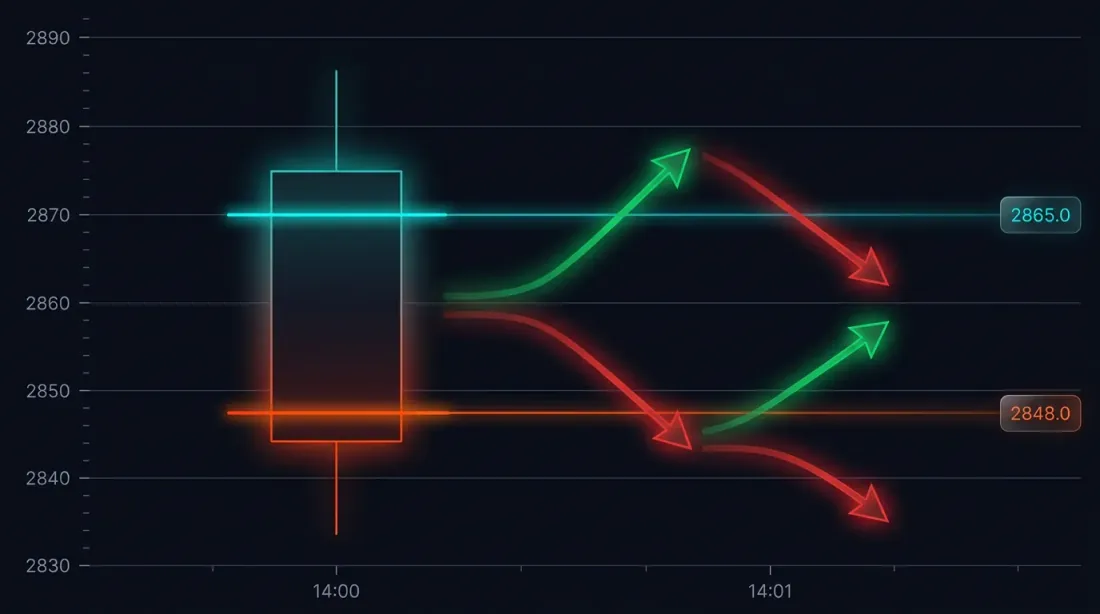
问题:大K线上的成交歧义
考虑一个具体场景。策略以3000 USDT开多。止损:2970(-1%)。止盈:3060(+2%)。
14:37的分钟K线:
- 开盘价:3010
- 最高价:3065
- 最低价:2965
- 收盘价:3050
止损(2970)和止盈(3060)都落在[2965, 3065]范围内。哪个先被触发?
可能的结果:
- 价格先下行 → 触发止损 → 亏损 -1%
- 价格先上行 → 触发止盈 → 盈利 +2%
单笔交易的差异:3个百分点。若使用10倍杠杆则为30%。对于包含数百笔交易的回测,错误的成交歧义解析会系统性地扭曲结果。
框架的默认处理方式
大多数回测引擎使用以下两种启发式方法之一:
- 乐观式: 止盈先触发 → 结果偏高
- 悲观式: 止损先触发 → 结果偏低
两种方法都是猜测。真实数据在秒级甚至毫秒级是可获取的,既然可以查看真实数据,就没有理由去猜测。
下钻:四级策略

下钻的思路:从分钟级开始,仅在存在歧义时"下钻"到更低级别——基于价格波动或成交量异常。
第1级:1m(分钟K线)
→ 如果止损或止盈明确在[最低价, 最高价]范围之外——当场解决
→ 如果两者都在范围内——下钻 ↓
第2级:1s(秒级K线)
→ 加载该分钟的60根秒级K线
→ 逐秒遍历:哪个先被触发?
→ 如果秒级K线有歧义,或 price_move >= min_pct,或 volume >= median_1s * vol_mult——下钻 ↓
第3级:100ms(毫秒级K线)
→ 加载该秒最多10根100ms的K线
→ 逐100ms遍历
→ 如果100ms K线有歧义,或 price_move >= min_pct,或 volume >= median_100ms * vol_mult——下钻 ↓
第4级:原始交易(raw trades)
→ 加载该100ms桶中的单笔交易
→ 逐笔解析成交——最大可能的精度
何时不需要下钻
95%的情况下不需要下钻。典型场景:
明确的止损: K线最高价未达到止盈,最低价击穿止损 → 止损触发,无需下钻。
明确的止盈: 最低价未达到止损,最高价突破止盈 → 止盈触发,无需下钻。
都未触发: 两个价位都在范围之外 → 持仓继续。
跳空检测: 下一根K线的开盘价跳过止损或止盈 → 按开盘价成交,无需下钻。
下钻仅在约5%的K线中需要——即两个价位都落在单根K线范围内时。
class AdaptiveFillSimulator:
"""
四级下钻,用于确定成交顺序。
"""
def __init__(self, data_loader):
self.loader = data_loader
self.cache_1s = {} # 按月缓存的秒级数据
def check_fill(self, timestamp, candle_1m, sl_price, tp_price, side):
"""
检查给定分钟K线上是否触发了止损或止盈。
Returns: ('sl', fill_price) | ('tp', fill_price) | None
"""
low, high = candle_1m['low'], candle_1m['high']
open_price = candle_1m['open']
if side == 'long':
if open_price <= sl_price:
return ('sl', open_price)
if open_price >= tp_price:
return ('tp', open_price)
else:
if open_price >= sl_price:
return ('sl', open_price)
if open_price <= tp_price:
return ('tp', open_price)
sl_hit = self._level_hit(sl_price, low, high, side, 'sl')
tp_hit = self._level_hit(tp_price, low, high, side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if not sl_hit and not tp_hit:
return None
return self._drill_down_1s(timestamp, sl_price, tp_price, side)
def _drill_down_1s(self, minute_ts, sl_price, tp_price, side):
"""第2级:逐秒遍历。"""
bars_1s = self.loader.load_1s_for_minute(minute_ts)
if bars_1s is None or len(bars_1s) == 0:
return self._pessimistic_fill(side, sl_price, tp_price)
for bar in bars_1s:
sl_hit = self._level_hit(sl_price, bar['low'], bar['high'], side, 'sl')
tp_hit = self._level_hit(tp_price, bar['low'], bar['high'], side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if sl_hit and tp_hit:
result = self._drill_down_100ms(bar['timestamp'], sl_price, tp_price, side)
if result:
return result
return self._pessimistic_fill(side, sl_price, tp_price)
def _pessimistic_fill(self, side, sl_price, tp_price):
"""悲观假设:多头触发止损,空头触发止损。"""
if side == 'long':
return ('sl', sl_price)
else:
return ('sl', sl_price)
性能
| 模式 | 单次成交检查时间 | 使用场景 |
|---|---|---|
| 1m(无下钻) | ~0ms | ~95%的情况 |
| 1s 下钻 | ~5ms(首次访问该月) | ~5%的情况 |
| 100ms 下钻 | ~1ms | <0.5%的情况 |
| 原始交易下钻 | ~0.5ms | <0.1%的情况 |
在两年约400笔交易的回测中,下钻大约被调用20次。总开销——整个回测不到1秒。
自适应数据存储
下钻需要秒级和毫秒级数据。但以最大粒度存储所有数据是不切实际的:
| 粒度 | 两年的K线数 | Parquet 大小 |
|---|---|---|
| 1m | ~105万 | ~15 MB |
| 1s | ~6300万 | ~550 MB/月 |
| 100ms | ~6.3亿 | ~5 GB/月 |
两年的完整1秒存档约13 GB。100毫秒超过100 GB。全部存储是可以的,但考虑到下钻使用的数据不到1%,这是浪费的。
热点秒检测
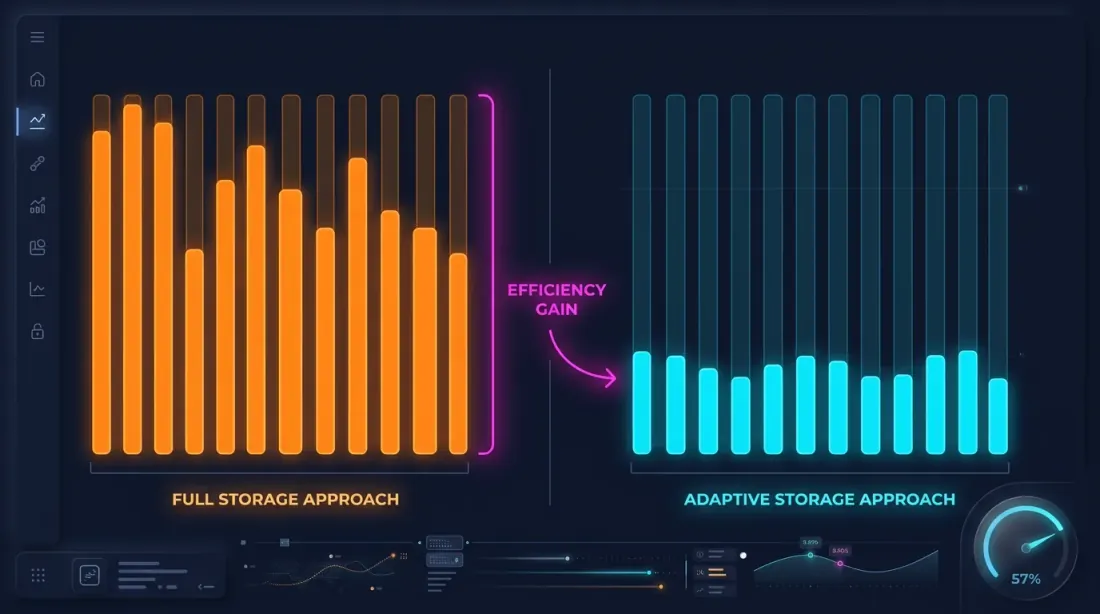
关键观察:价格显著波动的秒数只占很小的比例。如果某秒内价格变化不到0.1%——就没有必要存储该秒的100ms细分数据。
热点秒检测:在下载和处理数据时,分析每一秒并仅为"热点秒"生成100ms K线——即价格波动超过阈值的秒。
def process_trades_adaptive(
trades: pd.DataFrame,
min_price_change_pct: float = 1.0,
) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
将原始交易数据处理为自适应结构:
- 所有秒的1秒K线
- 仅"热点秒"的100ms K线
Args:
trades: 包含 [timestamp, price, quantity] 列的 DataFrame
min_price_change_pct: 下钻到100ms的阈值
Returns:
(df_1s, df_100ms_hot) — 秒级K线和热点秒的100ms K线
"""
trades['second'] = trades['timestamp'].dt.floor('1s')
df_1s = trades.groupby('second').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
df_1s['price_change_pct'] = (df_1s['high'] - df_1s['low']) / df_1s['open'] * 100
hot_seconds = df_1s[df_1s['price_change_pct'] >= min_price_change_pct].index
hot_trades = trades[trades['second'].isin(hot_seconds)]
hot_trades['bucket_100ms'] = hot_trades['timestamp'].dt.floor('100ms')
df_100ms = hot_trades.groupby('bucket_100ms').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
return df_1s, df_100ms
存储节省
以 ETHUSDT 典型月份为例:
| 方案 | 大小 | 粒度 |
|---|---|---|
| 仅1m | ~1 MB | 1分钟 |
| 全部1s | ~550 MB | 1秒 |
| 全部100ms | ~5 GB | 100毫秒 |
| 自适应 | ~600 MB | 1s + 仅热点秒的100ms |
当阈值 min_price_change_pct = 1.0% 时,热点秒占所有秒的不到1%。它们的100ms数据仅在550 MB秒级数据基础上增加约50 MB——几乎可以忽略不计。
如果秒级数据也采用自适应存储(仅当分钟内波动超过0.1%时),存储量还可再减少3-5倍。
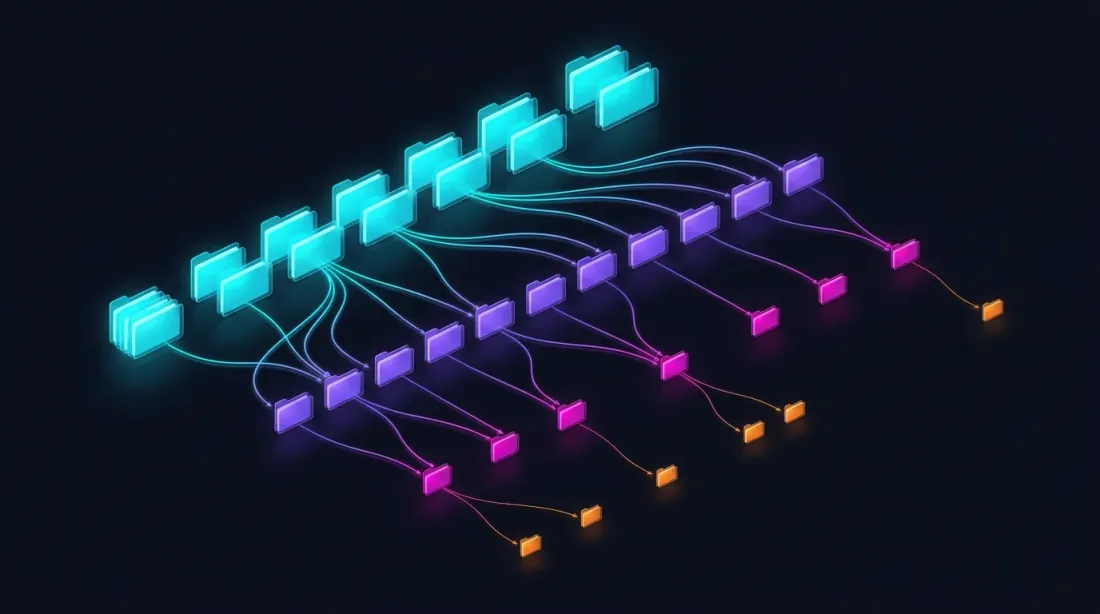
Parquet 存储结构
data/{SYMBOL}/
├── source.json # 数据来源:{"exchange": "binance"} 或 {"exchange": "bybit"}
├── stats.json # 预计算的成交量中位数:{"median_volume_1s": ..., "median_volume_100ms": ...}
├── klines_1m/
│ ├── 2024-01.parquet # ~1 MB
│ ├── 2024-02.parquet
│ └── ...
├── klines_1s/
│ ├── 2024-01.parquet # ~550 MB
│ └── ...
├── klines_100ms_hot/
│ ├── 2024-01.parquet # ~50 MB(仅热点秒)
│ └── ...
├── trades_hot/
│ ├── 2024-01.parquet # 热点100ms桶的原始交易
│ └── ...
└── states_1m.parquet # 预计算的滚动状态缓存(~112 MB)
每个文件包含一个月的数据。秒级、毫秒级数据和原始交易采用延迟加载——仅在下钻请求时才加载。stats.json 文件包含预计算的成交量中位数,用于基于成交量的下钻触发。
针对金融数据的 Parquet 优化
金融数据有其特殊性:时间戳单调递增,价格变化平滑,成交量波动较大。最优配置:
import pyarrow as pa
import pyarrow.parquet as pq
schema = pa.schema([
pa.field("timestamp", pa.int32()), # 从 epoch 起的秒数——int32 足够
pa.field("open", pa.float32()),
pa.field("high", pa.float32()),
pa.field("low", pa.float32()),
pa.field("close", pa.float32()),
pa.field("volume", pa.float32()),
])
column_encodings = {
"timestamp": "DELTA_BINARY_PACKED", # 单调整数 → 差分压缩
"open": "BYTE_STREAM_SPLIT", # 浮点数 → 字节流分割
"high": "BYTE_STREAM_SPLIT",
"low": "BYTE_STREAM_SPLIT",
"close": "BYTE_STREAM_SPLIT",
"volume": "BYTE_STREAM_SPLIT",
}
def save_optimized_parquet(df, path):
table = pa.Table.from_pandas(df, schema=schema)
pq.write_table(
table, path,
compression="zstd",
compression_level=9,
use_dictionary=False,
write_statistics=False,
column_encoding=column_encodings,
)
为什么使用这些配置:
- DELTA_BINARY_PACKED 用于时间戳:连续的时间戳之间差值固定(1m为60,1s为1)。差分编码将其压缩到接近零。
- BYTE_STREAM_SPLIT 用于浮点数:将 float32 的字节分流(所有第一字节在一起,所有第二字节在一起,依此类推)。对于平滑变化的价格,比标准编码压缩率高2-3倍。
- ZSTD level 9:在可接受的解压速度下实现良好的压缩。
- float32 代替 float64:对于价格和成交量足够,节省50%内存。
带缓存的延迟加载
下钻请求特定分钟的秒级数据。每次请求都加载一个 parquet 文件太慢。解决方案——按月进行 LRU 缓存的延迟加载。
from functools import lru_cache
import pyarrow.parquet as pq
import pandas as pd
class AdaptiveDataLoader:
"""
带缓存的延迟加载器:按月加载秒级数据,
在内存中保留最近 N 个月。
"""
def __init__(self, symbol: str, data_dir: str = "data", cache_months: int = 2):
self.symbol = symbol
self.data_dir = data_dir
self.cache_months = cache_months
self._cache_1s: dict[str, pd.DataFrame] = {}
def load_1s_for_minute(self, minute_ts: pd.Timestamp) -> pd.DataFrame | None:
"""加载特定分钟的1秒数据。"""
month_key = minute_ts.strftime("%Y-%m")
if month_key not in self._cache_1s:
self._load_month_1s(month_key)
if month_key not in self._cache_1s:
return None
df = self._cache_1s[month_key]
minute_start = minute_ts.floor('1min')
minute_end = minute_start + pd.Timedelta(minutes=1)
return df[(df.index >= minute_start) & (df.index < minute_end)]
def load_100ms_for_second(self, second_ts: pd.Timestamp) -> pd.DataFrame | None:
"""加载热点秒的100ms数据。"""
month_key = second_ts.strftime("%Y-%m")
path = f"{self.data_dir}/{self.symbol}/klines_100ms_hot/{month_key}.parquet"
try:
df = pd.read_parquet(path)
second_start = second_ts.floor('1s')
second_end = second_start + pd.Timedelta(seconds=1)
return df[(df.index >= second_start) & (df.index < second_end)]
except FileNotFoundError:
return None
def _load_month_1s(self, month_key: str):
"""加载一个月的1秒数据,从缓存中淘汰旧数据。"""
path = f"{self.data_dir}/{self.symbol}/klines_1s/{month_key}.parquet"
try:
df = pd.read_parquet(path)
df.index = pd.to_datetime(df['timestamp'], unit='s')
if len(self._cache_1s) >= self.cache_months:
oldest = min(self._cache_1s.keys())
del self._cache_1s[oldest]
self._cache_1s[month_key] = df
except FileNotFoundError:
pass
将下钻应用于回测
集成到回测循环中:
def backtest_with_adaptive_fill(
states: pd.DataFrame,
strategy_params: dict,
data_loader: AdaptiveDataLoader,
) -> list:
"""
使用自适应下钻进行成交模拟的回测。
"""
fill_sim = AdaptiveFillSimulator(data_loader)
trades = []
position = None
for i in range(len(states)):
row = states.iloc[i]
ts = states.index[i]
candle_1m = {
'open': row['open'], 'high': row['high'],
'low': row['low'], 'close': row['close'],
'timestamp': ts,
}
if position is not None:
fill = fill_sim.check_fill(
ts, candle_1m,
position['sl'], position['tp'],
position['side'],
)
if fill is not None:
fill_type, fill_price = fill
trades.append({
'entry_time': position['entry_time'],
'exit_time': ts,
'side': position['side'],
'entry_price': position['entry_price'],
'exit_price': fill_price,
'exit_type': fill_type,
'drill_down': fill_sim.last_drill_depth, # 0、1 或 2
})
position = None
continue
signal = check_entry_signal(row, strategy_params)
if signal and position is None:
position = {
'side': signal['side'],
'entry_price': row['close'],
'entry_time': ts,
'sl': signal['sl'],
'tp': signal['tp'],
}
return trades
与滚动状态缓存的关系
下钻与聚合 parquet 缓存互为补充——它们解决不同的问题:
| 滚动状态缓存 | 自适应下钻 | |
|---|---|---|
| 目标 | 正确的高时间框架指标值 | 精确的止损/止盈执行顺序 |
| 作用于 | 每根1分钟K线 | 仅在成交歧义时(~5%) |
| 数据 | 预计算,永久存储 | 延迟加载,缓存最近月份 |
| 影响 | 入场/出场信号 | 成交价格和时间 |
两种方法都消除了在日线级别不可见但对真实回测至关重要的错误。
总结:成交模拟方法对比
| 方法 | 精度 | 速度 | 存储 |
|---|---|---|---|
| OHLC 启发式(乐观/悲观) | 低 | 即时 | 仅1m |
| 完整1秒回测 | 高 | 慢(x60) | ~550 MB/月 |
| 完整100ms回测 | 很高 | 非常慢(x600) | ~5 GB/月 |
| 完整原始交易回测 | 最高 | 极慢 | ~50 GB/月 |
| 自适应下钻(4级) | 最高 | 接近即时 | 1m + 1s + 热点100ms + 热点交易 |
下钻以1分钟回测的速度提供了完整1秒回测的精度。关键观察:高粒度并非处处需要——只在决策点需要。
基于成交量的下钻
原始的下钻仅基于价格波动触发——当K线的[最低价, 最高价]范围足够宽以产生成交歧义时。但价格并不是某个K线内发生重要事件的唯一信号。
成交量飙升是同样重要的触发条件。当某秒的成交量达到中位数的500倍时,通常对应着大额市价单、连环爆仓或闪崩。即使K线实体看起来很小,该秒内的实际价格轨迹可能非常剧烈——触及OHLC表示法所隐藏的极值。
下钻条件现在基于或逻辑:显著的价格波动或异常的成交量飙升都会触发向更细粒度的下钻。
def is_hot(bar, median_volume, min_pct=0.1, vol_mult=500):
"""
判断一根K线是否需要下钻到下一级。
两个独立触发条件(或逻辑):
- K线内价格波动 >= min_pct
- 成交量超过 median * vol_mult
"""
price_move = (bar['high'] - bar['low']) / bar['open'] * 100
return price_move >= min_pct or bar['volume'] >= median_volume * vol_mult
这捕获了仅靠价格检测无法发现的场景:一根open=3000、close=3001但成交量是正常值50000倍的K线,可能在毫秒内曾触及2950和3050。没有基于成交量的下钻,回测永远不会更仔细地检查这一秒。
原始交易:第四级
原始的三级层次(1m → 1s → 100ms)仍然留有空白:在单个100ms桶内,多笔交易可能以不同价格成交。对于high=3060和low=2965的桶,我们仍然不知道确切的顺序。
解决方案:下钻到原始交易作为第四级也是最终级别。
1m K线(基础)
└─> 1s K线 (当 price_move >= min_pct 或 volume >= median_1s * vol_mult)
└─> 100ms K线 (当检测到热点秒)
└─> 原始交易 (当100ms显示 price_move >= min_pct 或 volume >= median_100ms * vol_mult)
在原始交易级别,没有歧义——每笔交易都有精确的价格和时间戳。成交被最终确定:
def resolve_from_trades(trades, sl_price, tp_price, side):
"""
按时间顺序遍历单笔交易。
第一笔穿越止损或止盈的交易决定成交。
"""
for trade in trades:
price = trade['price']
if side == 'long':
if price <= sl_price:
return ('sl', price)
if price >= tp_price:
return ('tp', price)
else: # short
if price >= sl_price:
return ('sl', price)
if price <= tp_price:
return ('tp', price)
return None
原始交易级别极少被调用——不到所有K线的0.1%——但当被调用时,它提供了任何K线近似都无法匹配的真实数据。
每个转换的独立阈值
不同分辨率之间的转换具有不同的特征。1秒内0.1%的价格波动是显著的;100ms桶内同样的0.1%则是极端的。同样,成交量分布在每个时间尺度上也不同。
每个级别转换现在有自己的 min_pct 和 vol_mult 参数:
1s → 100ms: --min-pct-1s 0.1 --vol-mult-1s 500
100ms → trades: --min-pct-100ms 0.1 --vol-mult-100ms 500
这允许独立地微调每个转换的灵敏度。实际上,100ms到交易的转换可以使用更严格的阈值,因为加载单个100ms桶的原始交易的成本很小。
@dataclass
class DrillDownConfig:
min_pct_1s: float = 0.1
vol_mult_1s: float = 500
min_pct_100ms: float = 0.1
vol_mult_100ms: float = 500
持久化中位数统计
基于成交量的下钻需要知道每个时间尺度的成交量中位数。为每次回测实时计算中位数会抵消性能优势。解决方案:预计算一次中位数并缓存。
对于每个交易对,1秒和100ms粒度的成交量中位数从历史数据中计算并存储在 stats.json 文件中:
{
"ETHUSDT": {
"median_volume_1s": 12.5,
"median_volume_100ms": 1.8
},
"BTCUSDT": {
"median_volume_1s": 0.45,
"median_volume_100ms": 0.06
}
}
统计数据在首次下载数据时为每个交易对计算一次,并在所有后续回测中复用。当数据更新(下载新月份)时,统计数据增量重新计算。
def compute_median_stats(symbol, data_dir):
"""为交易对计算并缓存成交量中位数统计。"""
stats_path = f"{data_dir}/{symbol}/stats.json"
all_1s = load_all_months(f"{data_dir}/{symbol}/klines_1s/")
median_1s = all_1s['volume'].median()
all_100ms = load_all_months(f"{data_dir}/{symbol}/klines_100ms_hot/")
median_100ms = all_100ms['volume'].median()
stats = {
"median_volume_1s": float(median_1s),
"median_volume_100ms": float(median_100ms),
}
with open(stats_path, 'w') as f:
json.dump(stats, f, indent=2)
return stats

多交易所支持:Bybit
并非所有交易对都在Binance上可用。对于XAUTUSDT(黄金)等资产,数据必须来自其他交易所。下钻系统现在支持 Bybit 作为替代数据源。
对于Bybit交易对,所有K线级别(1m、1s、100ms)和原始交易都从Bybit的原始交易流构建。过程相同——原始交易在每个时间尺度上聚合为K线——但数据源不同。
data/{SYMBOL}/
├── source.json # {"exchange": "bybit"} 或 {"exchange": "binance"}
├── klines_1m/
│ └── ...
├── klines_1s/
│ └── ...
├── klines_100ms_hot/
│ └── ...
└── trades_hot/ # 热点100ms桶的原始交易
└── ...
数据加载器检查 source.json 并使用相应的下载管道。从回测引擎的角度来看,无论数据来源是哪个交易所,数据格式都是相同的——下钻逻辑与交易所无关。
这对于跨交易所策略或仅在特定平台上交易的交易对尤为重要。
结论
自适应下钻是一个简单原则的应用:按数据重要性的比例投入计算资源和存储空间。
四个粒度级别:
- 1m — 95%K线的基础遍历
- 1s — 成交歧义或成交量飙升时的下钻
- 100ms — 极端波动或异常成交量热点秒的下钻
- 原始交易 — 热点100ms桶的下钻,在单笔交易级别解析成交
四个存储级别:
- 全部1m — 完整存档,两年约15 MB
- 全部1s — 完整或自适应存档,~550 MB/月
- 仅热点100ms — 不到1%的秒,~50 MB/月
- 仅热点交易 — 最极端100ms桶的原始交易
两个下钻触发条件(或逻辑):
- 基于价格:K线价格范围超过
min_pct - 基于成交量:K线成交量超过
median * vol_mult
结果:以分钟级速度获得逐笔模拟器的精度。存储空间线性增长而非指数增长。并且支持多个交易所——Binance和Bybit——下钻逻辑与交易所无关。
关于多时间框架策略的预计算缓存,请参阅文章 聚合 Parquet 缓存。关于资金费率在高杠杆下对结果的影响 — 资金费率正在摧毁你的杠杆。
参考链接
- Apache Parquet — 数据存储格式
- Apache Arrow — BYTE_STREAM_SPLIT 编码
- Zstandard — 压缩算法
- Lopez de Prado — Advances in Financial Machine Learning
- Binance — 历史市场数据
引用
@article{soloviov2026adaptivedrilldown,
author = {Soloviov, Eugen},
title = {Adaptive Drill-Down: Backtest with Variable Granularity from Minutes to Milliseconds},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/adaptive-resolution-drill-down-backtest},
description = {自适应数据粒度如何加速回测并节省存储空间:仅在价格显著波动或成交量异常的位置从1分钟下钻到1秒、100毫秒和原始交易。}
}
MarketMaker.cc Team
量化研究与策略


