算法交易系统中的数据通信:技术综述

在算法交易中,盈利与亏损之间的差距往往以微秒计。数据传输架构是决定交易系统效率的关键因素之一。在本文中,我们将解析各个层级的通信技术:从与交易所的交互到内部微服务通信、存储和数据分发。
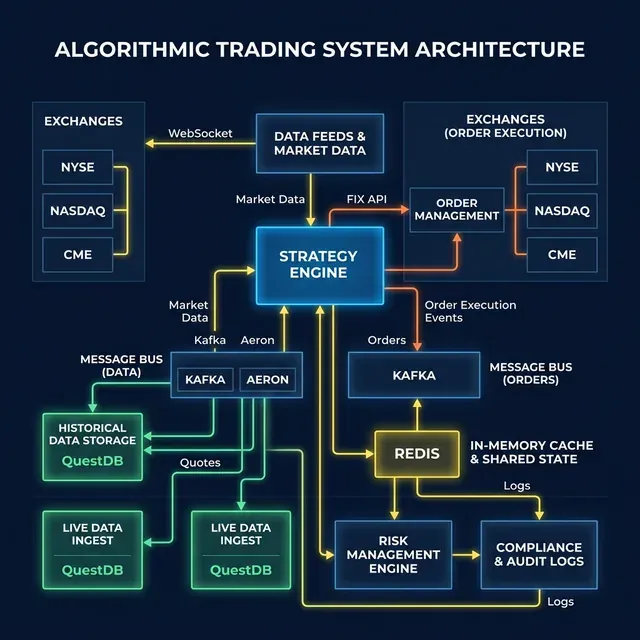
本文按层级组织——从“外部”(交易所通信协议)到“内部”(IPC、消息代理、存储),真实反映了算法交易平台的架构设计。
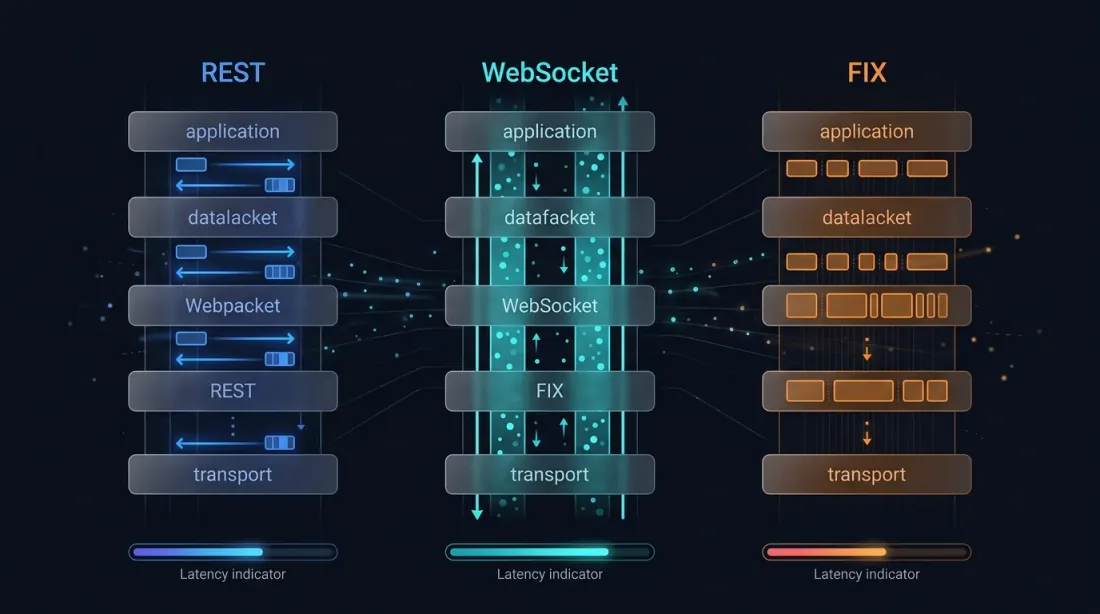
1. 交易所交互:REST, WebSocket, FIX
1.1 REST API
REST 是与交易所 API 交互最简单、最常见的方式。每个请求都是一个独立的 HTTP 连接:TCP 握手 → TLS 握手 → 发送请求 → 接收响应 → 关闭连接。
交易中的 REST 问题:
每个请求都会带来连接建立的开销。即使使用 HTTP keep-alive,“请求-响应”模型也意味着你接收数据的速度不可能快于发送请求的速度。这导致了轮询(polling)——即无限循环地询问“有新数据吗?”,这占用了交易所服务器高达 80% 的负载(据加密交易所开发人员估计)。交易所通常会引入频率限制(通常每分钟 10–1200 个请求),这使得 REST 不适用于高频策略。
适用场景: 获取历史数据(K线, OHLCV)、账户管理(余额, 仓位)、非实时操作(DCA 机器人、每小时调仓)。
1.2 WebSocket
WebSocket 建立一个持久的 TCP 连接,数据可以双向流动。它以带有 Upgrade 头的普通 HTTP 请求开始,然后切换到双向帧协议(payload 可以是文本 JSON 或二进制格式)。
交易优势:
最大的优势是无请求开销。连接一旦建立,服务器即可即时推送数据。通过 WebSocket 传输的行情数据延迟通常小于 50 毫秒(从交易所网关到客户端)。你可以在一个连接上同时订阅 50 多个交易对。
关键点:通过 WebSocket 下单。 许多交易者不知道某些交易所(如 Binance, HitBTC, Deribit, Bybit 等)允许通过 WebSocket 发送订单,而不仅仅是接收数据。这比 REST 根本上更快,因为:
- 每个订单无需 TCP/TLS 握手(连接已“预热”)
- 无 HTTP 开销(头信息、cookie 等)
- 异步模型:发送订单后通过同一个 WebSocket 接收确认,无需阻塞线程。
根据 Deribit 的数据,WebSocket 和 FIX 的执行速度多数情况下相当。REST 由于连接层的预处理而略慢。WebSocket 订单进入撮合引擎队列的方式与 FIX 订单相同。
混合上下文问题: 如果你通过 REST 发送订单,但通过 WebSocket 接收成交通知,会产生竞争条件(race condition):WebSocket 通知可能在 REST 请求完成之前到达。这会导致状态不一致。解决方案是完全转向异步模型,通过同一个 WebSocket 发送订单。
1.3 FIX 协议 (Financial Information eXchange)
FIX 是电子交易的行业标准,自 1992 年起(由 Fidelity Investments 和 Salomon Brothers 创建)一直存在。它是一种构建在 TCP 之上的二进制协议,专为交易操作设计。
FIX 架构:
- 会话层 (Session layer) — 管理连接、心跳、序列号、差错恢复。保证消息的交付和顺序。
- 应用层 (Application layer) — 业务逻辑:订单类型、执行报告、行情请求。
FIX 消息由“标签=值 (tag=value)”对组成,由 SOH 字符分隔。例如,以 150 美元买入 100 股 AAPL 的订单如下:
8=FIX.4.2|35=D|49=BUYER|56=SELLER|11=ORD1001|38=100|40=2|54=1|55=AAPL|44=150.00
为什么 FIX 比 WebSocket 快: FIX 是原生 TCP 协议,没有 HTTP 层。AWS 在其针对加密交易所的 tick-to-trade 优化指南中,明确建议优先使用 FIX 而非 REST 和 WebSocket,以最小化协议引起的延迟。FIX 在微秒级别运行,而 WebSocket 通常在毫秒级别。
FIX 的主导领域: 直接市场准入 (DMA) 连接撮合引擎、机构领域的高频交易 (HFT)、流动性聚合(主经纪商通过 FIX 连接数十家银行)。
FIX 的局限性: 集成复杂、消息格式陈旧(文本形式的标签值不如二进制格式高效)、准入门槛高。在加密行业中,支持 FIX 的交易所数量有限。
1.4 SBE (Simple Binary Encoding) — 进化的 FIX
SBE 是由 FIX Trading Community 内的高性能工作组创建的二进制序列化格式。其目标是用紧凑的二进制表示取代文本格式的 FIX,以实现超低延迟交易。
SBE 的核心原则:
- 零拷贝轻量级模式 (Zero-copy flyweight pattern) — 编码器和解码器像“模板”一样作用于缓冲区。值直接写入缓冲区,无需中间拷贝(不像 Protobuf 需要多次拷贝)。
- 传输格式 = 内存格式 (Wire format = memory format) — 线路上的数据与内存中的数据一致,最大限度减少转换开销。
- 固定字段在前,变量字段在后 — 虽然是设计限制,但与 Protocol Buffers 相比平衡了性能。
SBE + Aeron 是高性能交易系统的标准组合。Aeron 是来自 Real Logic 的开源消息系统(由原 LMAX Exchange CTO Martin Thompson 和原 29West CTO Todd Montgomery 创建)。它实际上是专为金融系统设计的传输层,运行在 UDP 和共享内存之上,延迟仅为几微秒。SBE 负责序列化,Aeron 负责传输。详见第 3.1 节。
1.5 交易所通信协议对比表

| 参数 | REST | WebSocket | FIX | FIX+SBE |
|---|---|---|---|---|
| 延迟 | 10–100+ ms | 1–50 ms | 10–500 μs | 1–100 μs |
| 模型 | 请求-响应 | 双向推送 | 双向会话 | 双向会话 |
| 订单 | 是 (同步) | 是 (异步, 部分) | 是 (原生) | 是 (原生) |
| 连接预热 | 每次请求 | 一次性 | 一次性 | 一次性 |
| 格式 | JSON/文本 | JSON/二进制 | 标签值文本 | 二进制 |
| 集成难度 | 低 | 中 | 高 | 极高 |
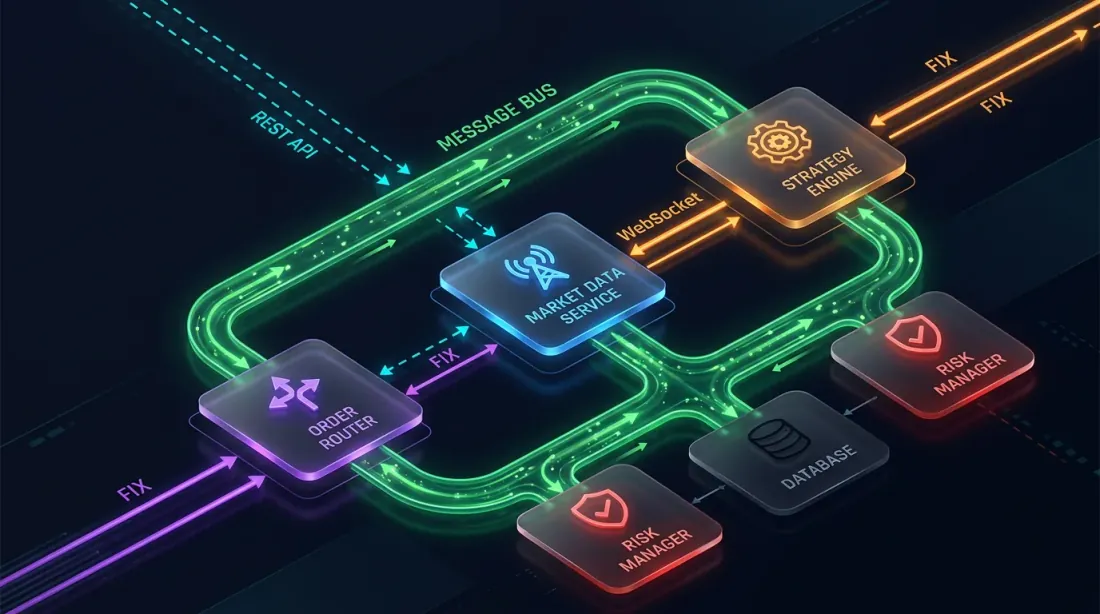
2. 内部微服务通信
行情数据从交易所进入系统后,开始内部处理:解析行情 → 策略计算 → 做出决策 → 发送订单。每个步骤都涉及服务间通信。
2.1 gRPC 双向流 (TCP)
gRPC 是 Google 开发的基于 HTTP/2 的框架,使用 Protocol Buffers 进行序列化。对于算交,双向流(bidirectional streaming)尤为重要——客户端和服务器通过一个连接同时发送消息流。
为什么 gRPC 适合交易系统:
- Protobuf 格式紧凑(比 JSON 小 3–10 倍)
- HTTP/2 多路复用 — 一个 TCP 连接支持多个流
- 强类型 .proto 定义 — 编译阶段捕捉错误
- 支持 Python, Rust, Go, C++, Java 等多语言
- 双向流可以实现“行情下发,订单上传”的统一通道模式。
根据 SmartDev 的数据,70% 部署 AI HFT 的金融机构使用 gRPC 或原生 TCP 来实现微秒级响应。
架构示例: 行情收集器 (Rust) → gRPC 流 → 策略引擎 (Python/Rust) → gRPC 调用 → 订单路由 (Rust) → WebSocket/FIX → 交易所。
2.2 Unix 域套接字上的 gRPC (UDS)
如果服务运行在同一台机器上(托管机房的典型场景),TCP 是多余的开销。Unix 域套接字 (UDS) 移除整个网络栈:无 TCP 握手、无路由、无校验。
基准测试显示显著差异:
- gRPC via UDS: ~102 μs/请求 (10万次请求)
- gRPC via TCP: ~127 μs/请求 (10万次请求)
- UDS 提升:小消息提升 ~20%,大消息 (100KB+) 提升高达 50%。
根据 F. Werner (MPI Heidelberg) 的测量,gRPC UDS 比原生 UDS I/O 增加了约 10 倍开销(~130 μs 对比 ~13 μs)。这是为了抽象方便(HTTP/2 帧、protobuf 序列化)付出的代价。
何时使用 gRPC+UDS: 同一服务器上的进程间通信,且开发便利性(Schema, 代码生成)比极致延迟更重要时。UDS 还具有安全性优势——Unix 文件权限可控制访问。
何时不使用: 如果需要延迟 <10 μs,建议使用共享内存或不带 gRPC 的原生 UDS。具体数值:原生 UDS 中位延迟 ~13 μs,gRPC UDS ~130 μs。共享内存 (Aeron IPC) 小于 1 μs,LMAX Disruptor 环形缓冲区约为 50–100 纳秒。也就是说 gRPC+UDS 比原生 UDS 慢 10 倍,比共享内存慢 100–1000 倍。但延迟每降低一个台阶,代码复杂度就会上升一个台阶。
自行验证: 本节中的延迟数据可通过开源基准测试 suenot/trading-ipc-bench 在您自己的硬件上复现——涵盖 TCP、UDS、ZeroMQ IPC/TCP、WebSocket、Redis Pub/Sub、共享内存和命名管道的 Python 实现,测量 p50/p95/p99/p99.9 延迟和吞吐量。
不带 gRPC 的原生 UDS — 如果 gRPC 开销过大,可以去掉它,只保留套接字。按性能从高到低的选项:
- AF_UNIX 套接字 + 自定义序列化 (SBE, FlatBuffers, MessagePack) — 中位延迟 ~13 μs,最高控制权,最高复杂度
- ZeroMQ IPC (
ipc://) — ~50–100 μs,提供现成模式(PUB/SUB, REQ/REP),底层使用 UDS - nanomsg/NNG IPC — 类似 ZeroMQ,小消息 (<64 KB) 延迟略优
- Cap'n Proto RPC over UDS — 零拷贝序列化 + RPC 抽象,比 gRPC 快,有 schema
2.3 共享内存 IPC
对于同主机的超低延迟,使用共享内存。两个进程映射同一块 RAM 区域,数据传递无需系统调用(初始设置除外)。
LMAX Disruptor 模式(共享内存中的环形缓冲区)可在单线程上每秒处理约 600 万个事件。这种方法是 LMAX 交易所及许多 HFT 系统的核心。
实现: Aeron IPC (Java/C++), Chronicle Queue (Java), 自定义 mmap 方案 (Rust/C++)。IronSBE (Rust 实现) 支持延迟约为 20 纳秒的共享内存 IPC。
3. 传输系统:消息代理与库
3.1 Aeron — 交易系统的行业标准
Aeron 是由 Real Logic 开发的开源高性能消息传输系统。创建者是 Martin Thompson(原 LMAX CTO)和 Todd Montgomery(原 29West CTO)。它诞生于 2014 年,最初由一家美国主要交易所委托开发。
实践中的 Aeron: 它不是像 Kafka 那样的代理(Broker),也不是像 ZeroMQ 那样的套接字库。Aeron 是专为可预测低延迟设计的传输层。它运行在 UDP(网络)和共享内存(IPC)之上,同时提供可靠交付、定序和流量控制——这些是原生 UDP 所不具备的。你可以将 Aeron 视为“具有 UDP 延迟的 TCP”。
Aeron 特性:
- 延迟:云端 <100 μs,物理硬件 <18 μs。
- 吞吐:微秒延迟下超过 100 万消息/秒。
- 峰值超过 2000 万消息/秒。
- 无代理模式 (Brokerless) — 无单点故障。
- 内置流量控制、拥塞控制和丢包检测。
Aeron Cluster — 用于容错状态机复制的扩展(Raft 共识),为交易系统提供一致性复制。
Aeron Archive — 以全速将消息持久化到磁盘,支持回放(Replay)。
Aeron Sequencer — 生态系统的最新组件,旨在协调大型组织内多个项目。基于 Aeron Transport 和 Aeron Cluster 构建。核心特性:
- 分布式日志 (Distributed log) — 将消息序列复制到多台机器以实现容错
- 多读取方 (Multiple readers) — 多个应用程序可同时从同一日志读取,用于不同任务
- 团队解耦 (Decoupled teams) — 各团队保持独立,同时在统一协调的系统中运作
- 目标场景:行情数据处理、经纪商平台、交易所撮合引擎
与 Kafka 对比: 两者都使用分布式日志,但 Aeron 优化延迟(微秒级),而 Kafka 优化耐久性和吞吐量(毫秒级)。Aeron 用于实时交易逻辑,Kafka 用于数据管道和分析。
3.2 Apache Kafka
Apache Kafka 是大规模事件流的事实标准。不适合交易决策的热路径(毫秒级延迟),但对于以下场景不可或缺:
- 行情聚合: 将 100 多个交易所的流汇集到统一管道。
- 事件溯源 (Event Sourcing): 记录系统的每个动作。
- CDC (变动数据捕捉): 将交易数据库的变化同步到分析系统。
- QuestDB 集成: Kafka → QuestDB 进行实时逐笔分析。
在合理配置下,Kafka 端到端延迟约为 2–15 毫秒。对于 HFT 不可接受,但对于决策周期 >1 秒的策略足够。
3.3 Redis Pub/Sub 与 Redis Streams
Redis 是内存数据库,也可作为轻量级消息代理。
Redis Pub/Sub — 阅后即焚,亚毫秒级延迟。非常适合实时通知:价格更新、策略信号、告警。
Redis Streams — 增加了持久化和消费者组(类似小型 Kafka)。可以读取历史数据并确认处理 (ACK)。
3.4 NATS
NATS 是 Go 编写的极轻量消息系统。亚微秒延迟。NATS JetStream 扩展支持持久化和”仅一次交付 (exactly-once delivery)”。
3.5 ZeroMQ 与 nanomsg
提供套接字抽象的无代理库,用于点对点通信。ZeroMQ 吞吐量可达 500 万+消息/秒,历史悠久。nanomsg (及 NNG) 是其继承者,在小消息 (<64KB) 上延迟更佳。
4. 客户端实时推送:Centrifugo
Centrifugo 是 Go 编写的自托管发布/订阅服务器,优化了广播场景:一条消息 → 数万/百万客户端。支持 WebSocket, SSE, gRPC 等。
为何算交使用 Centrifugo:
- 单机测试支持 100 万个 WebSocket 连接,每分钟投递 3000 万条消息。
- 支持 60Hz 频率的数据流。
- 采用增量压缩 (Delta compression) 算法最小化流量。
- 常用于向 Web 面板或移动端分发实时数据。
5. 实时访问数据存储
5.1 QuestDB — 专为交易设计的时序数据库
QuestDB 是开源时序数据库,由 Java (Zero-GC), C++ 和 Rust 编写。
- 查询: 通过 SIMD 指令实现亚毫秒级向量执行。
- ASOF JOIN: 时序数据对齐的关键功能(行情对齐)。
- WAL: 超低延迟的追加写入。
- 巴西 B3 证券交易所已在其交易业务中使用 QuestDB。
5.2 Redis 作为实时数据层
通常作为中间层:
- 热缓存 (Hot cache): O(1) 访问最新价格。
- 有序集合 (Sorted sets): 用于订单簿盘口。
- Lua 脚本: 用于保证原子操作。
5.3 细分方案:RayforceDB, AXL DB
极简主义的 C 语言向量数据库(二进制文件 <1MB),零依赖,SIMD 加速。专注于负载下的确定性延迟,这在高频交易中至关重要。
6. 序列化对比:Protobuf vs SBE vs JSON
| 格式 | 编解码速度 | 体积 | 零拷贝 | 适用场景 |
|---|---|---|---|---|
| JSON | 慢 | 大 | 否 | REST API, 调试, 日志 |
| Protobuf | 快 | 紧凑 | 否 | gRPC, 微服务通信 |
| SBE | 极快 | 极小 | 是 | HFT, 撮合引擎 |
| FlatBuffers | 非常快 | 紧凑 | 是 | 游戏开发, 中等延迟 |
SBE 通过固定字段位置实现了极速性能。对于交易消息(订单、成交报告)非常合适。
7. 参考架构
7.1 加密货币套利 (中频)
交易所 → Collector (Rust) → Redis (热缓存) → 策略引擎 (Python) → gRPC (UDS) → 订单路由 (Rust) → 交易所。
7.2 HFT 做市 (托管机房同机架)
交易所 Feed → 网卡 (内核旁路) → Aeron IPC (共享内存) → 策略 (C++, 单线程) → SBE 编码 → Aeron → FIX → 交易所。
8. 实践建议
- <10 μs (HFT): FPGA, 内核旁路, 共享内存, SBE, Aeron IPC。
- 10–100 μs (超低延迟): Aeron (UDP), gRPC+UDS, ZeroMQ。
- 100 μs – 1 ms (低延迟): gRPC (TCP), WebSocket, Protobuf。
- 1–10 ms (中频): WebSocket 到交易所, 内部 Kafka, Redis。
- >10 ms (低频 / 波段): REST API 即可满足需求。DCA、再平衡、投资组合管理。
不要过度优化非瓶颈。 如果你的策略决策需要 50 毫秒,那么为了节省 100 微秒而将 gRPC 换成 Aeron 是没有意义的。混合架构是常态:REST 用于配置,gRPC 用于核心通信,WS 用于行情下发。
基准测试仓库
本文中引用的所有延迟数据均可通过 suenot/trading-ipc-bench 复现——这是一个开源 Python 基准测试套件,涵盖本文讨论的所有主要 IPC 传输方式:TCP、UDS、命名管道、ZeroMQ IPC/TCP、WebSocket、Redis Pub/Sub 和共享内存。
git clone https://github.com/suenot/trading-ipc-bench
cd trading-ipc-bench
pip install -r requirements.txt
python run_all.py # 运行全部 8 种传输,结果保存至 results/
python report.py # 输出汇总表格和 ASCII 延迟图表
在您自己的硬件上运行——结果会因 CPU、操作系统和内核版本而异。这正是它的意义所在。
结论
不存在完美的通用通信技术。系统每个层级都有其需求:外部(兼容性)、内部热路径(极低延迟)、数据管道(可靠性)、客户端(灵活性)。有效架构的关键是理解每个组件的要求,并为特定任务选择合适的工具。
MarketMaker.cc Team
量化研究与策略