QuestDB 算法交易实战:从订单簿到生产架构

免责声明:本文内容仅供教育和参考目的,不构成任何财务、投资或交易建议。加密货币交易存在重大亏损风险。
欢迎来到 QuestDB 系列的最终篇。在第 1 篇中,我们介绍了存储架构。在第 2 篇中,我们探讨了 SQL 扩展。现在让我们将一切融合在一起:用于实时分析的物化视图、原生 2D 数组的订单簿存储,以及生产级算法交易平台的参考架构。
物化视图:以网络速度提供预计算分析
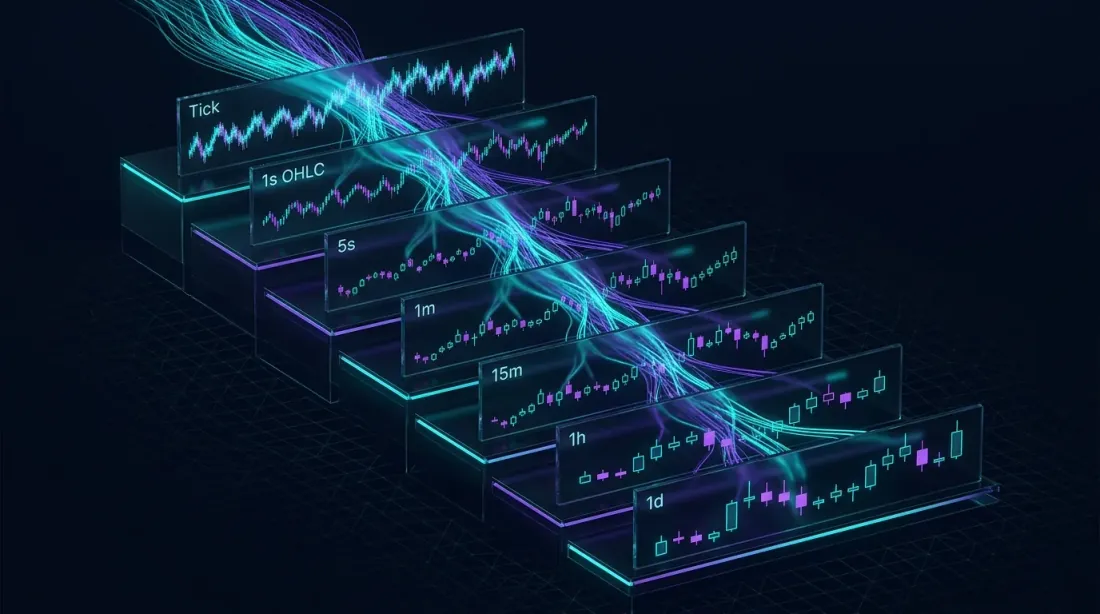 级联物化视图:原始 tick 数据流经逐级粗化的聚合层,每一层处理的数据量都大幅减少
级联物化视图:原始 tick 数据流经逐级粗化的聚合层,每一层处理的数据量都大幅减少
如果 SAMPLE BY 是 QuestDB 最常用的查询,那么物化视图就是其最有影响力的优化。概念很简单:不是在每次仪表板刷新或 API 调用时计算 OHLCV 聚合,而是预先计算一次,并保持结果持续更新。
基础 OHLC 物化视图
CREATE MATERIALIZED VIEW trades_OHLC_15m
WITH BASE 'trades'
REFRESH IMMEDIATE
AS
SELECT timestamp, symbol,
first(price) AS open,
max(price) AS high,
min(price) AS low,
last(price) AS close,
sum(quantity) AS volume
FROM trades
SAMPLE BY 15m;
这就是完整的定义。每当新行被插入 trades 表时,QuestDB 会自动对该视图进行增量刷新。不是完整重算——只有受影响的时间桶会被更新。针对 trades_OHLC_15m 的查询变成了对更小的预聚合数据集的简单查找。
性能差异是戏剧性的。在一张有数十亿行的表上,查询基础表获取 OHLC 数据可能需要 200 毫秒。物化视图在 5 毫秒以内返回相同结果。当多个仪表板用户并发访问时,这不仅仅是一种优化——而是响应系统与崩溃系统之间的差距。
级联视图:单一数据源支持多个时间周期
物化视图在架构上优雅之处在于此。你可以将它们链接起来——每个视图以下一个为基础,从单一原始数据源创建多层次的聚合层级:
-- 从原始成交数据生成 1 秒 K 线
CREATE MATERIALIZED VIEW ohlc_1s AS
SELECT timestamp, symbol,
first(price) AS open, max(price) AS high,
min(price) AS low, last(price) AS close,
sum(quantity) AS volume
FROM trades
SAMPLE BY 1s;
-- 从 1 秒 K 线生成 5 秒 K 线
CREATE MATERIALIZED VIEW ohlc_5s AS
SELECT timestamp, symbol,
first(open) AS open, max(high) AS high,
min(low) AS low, last(close) AS close,
sum(volume) AS volume
FROM ohlc_1s
SAMPLE BY 5s;
-- 从 5 秒 K 线生成 1 分钟 K 线
CREATE MATERIALIZED VIEW ohlc_1m AS
SELECT timestamp, symbol,
first(open) AS open, max(high) AS high,
min(low) AS low, last(close) AS close,
sum(volume) AS volume
FROM ohlc_5s
SAMPLE BY 1m;
每一层处理的数据集都比前一层小得多。1 分钟视图不扫描原始成交数据——它只读取预聚合的 5 秒 K 线。这种级联模式可以扩展到任意数量的时间周期:1s → 5s → 1m → 5m → 15m → 1h → 4h → 1d。
对于从 100 多家交易所写入数据的加密数据平台,这是整个 OHLC 分发管道的骨干。
刷新策略
QuestDB 提供三种刷新模式,各自适合不同的工作负载:
REFRESH IMMEDIATE 在每次基础表事务后触发异步刷新。最适合亚秒级延迟至关重要的实时仪表板。
REFRESH EVERY 1h(基于定时器)将更新批量合并到定期刷新中。对于高吞吐量写入场景更合适,因为在每个微批次后触发刷新会产生额外开销。
REFRESH PERIOD (LENGTH 1d TIME ZONE 'Europe/London' DELAY 2h) 定义日历对齐的周期。"延迟"考虑了迟到数据的情况——对于可能在交易时段结束后数小时才发送修正数据的市场,这一点至关重要。
REFRESH MANUAL 提供完全控制权。视图仅在你显式运行 REFRESH 命令时才会更新——对于日终对账工作流非常有用。
LATEST ON 加速模式
最强大的模式之一是将物化视图与 LATEST ON 结合,用于即时投资组合快照。扫描 13 亿行原始数据以获取每个交易对的最新价格需要数秒时间。但有了每日预聚合视图:
CREATE MATERIALIZED VIEW trades_latest_1d AS
SELECT timestamp, symbol, side,
last(price) AS price,
last(quantity) AS quantity,
last(timestamp) AS latest
FROM trades
SAMPLE BY 1d;
LATEST ON 查询扫描大约 25,000 行预聚合数据,而非数十亿行:
SELECT symbol, side, price, quantity, latest AS timestamp
FROM (
trades_latest_1d
LATEST ON timestamp PARTITION BY symbol, side
)
ORDER BY timestamp DESC;
从数秒降至毫秒级。这就是生产交易仪表板如何在海量数据集上实现实时响应的秘诀。
TTL:自动数据生命周期管理
物化视图支持 TTL(存活时间)策略用于自动数据过期:
CREATE MATERIALIZED VIEW ohlc_1h AS (
SELECT timestamp, symbol,
avg(price) AS avg_price
FROM trades
SAMPLE BY 1h
) PARTITION BY WEEK TTL 8 WEEKS;
这保留 8 周的小时数据,自动删除较旧的分区。结合三层存储引擎,你获得了自然的数据生命周期:原始 tick 数据流经 WAL → 列式存储 → 对象存储中的 Parquet,而物化视图维护着应用实际查询的预聚合摘要。
2D 数组:原生订单簿分析
 3D 订单簿深度:买卖盘以原生 2D 数组存储,支持 SIMD 优化的价差计算和流动性分析
3D 订单簿深度:买卖盘以原生 2D 数组存储,支持 SIMD 优化的价差计算和流动性分析
QuestDB 9.0 引入了 N 维数组——真正的具有形状和步长的类 NumPy 数组,以零拷贝方式处理常见操作(切片、转置)。对于交易而言,杀手级应用是订单簿存储。
传统方案的痛点
历史上,在关系型数据库中存储订单簿快照是件苦差事。你只有两种选择:每个价格档位一行(行数爆炸,查询深度代价高昂),或者固定数量的列,如 bid1_price、bid1_size、bid2_price、bid2_size 等(僵硬、浪费且难看)。
QuestDB 的 2D 数组彻底消除了这两个问题:
CREATE TABLE market_data (
timestamp TIMESTAMP,
symbol SYMBOL,
bids DOUBLE[][],
asks DOUBLE[][]
) TIMESTAMP(timestamp) PARTITION BY HOUR;
每个 bids 和 asks 列存储一个 2D 数组,其中第一行包含每个档位的价格,第二行包含每个档位的数量。一个 20 档订单簿是一个紧凑的单一数组,而非 40 个独立的列。
SQL 中的订单簿分析
价差计算——最基础也是最频繁计算的指标:
SELECT timestamp,
spread(bids[1][1], asks[1][1]) AS spread
FROM market_data
WHERE symbol = 'EURUSD'
AND timestamp IN today();
spread() 函数是内置函数,计算最优买价与最优卖价之差。bids[1][1] 访问买盘数组第一行(价格)的第一个元素(最优价格)。
对于更复杂的分析——流动性深度、订单簿不平衡、特定价格档位的成交概率——数组切片和向量化操作使原本复杂的查询变得直接:
-- 找到目标价格会被成交的档位
-- 并对该档位以上的所有数量求和
DECLARE @target := bids[1][1] * 1.01;
SELECT timestamp,
array_sum(asks[2][1:level_idx]) AS volume_to_fill
FROM market_data
WHERE symbol = 'EURUSD';
SIMD 优化的数组操作意味着这些计算以接近硬件的速度运行,即使面对数百万个快照也是如此。
数组数据的写入
QuestDB 的客户端库支持原生数组写入。Python 客户端直接与 NumPy 数组集成:
import numpy as np
from questdb.ingress import Sender
bids = np.array([[9.3, 9.2, 9.1], [100, 200, 150]]) # 价格, 数量
asks = np.array([[9.5, 9.6, 9.7], [80, 160, 120]])
with Sender.from_conf("http::addr=localhost:9000;") as sender:
sender.row(
'market_data',
symbols={'symbol': 'EURUSD'},
columns={'bids': bids, 'asks': asks},
at=timestamp
)
协议第 2 版以二进制形式对数组进行编码,与基于文本的协议相比显著降低了带宽和服务器端解析开销。对于高频订单簿写入——你可能每秒每个交易对接收数千个快照——这种效率至关重要。
C/C++ 客户端使用带形状描述符的平铺行主数组,支持从现有交易系统数据结构进行零拷贝写入。
融会贯通:参考架构
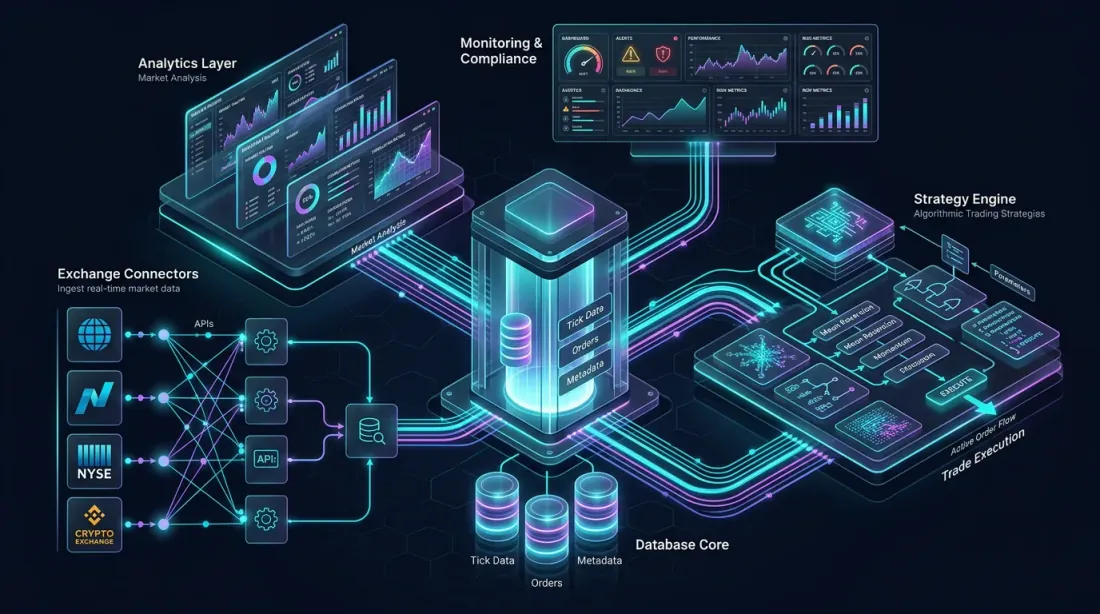 参考架构:交易所连接器、列式数据库核心、分析层、策略引擎和监控仪表板——全部互联互通
参考架构:交易所连接器、列式数据库核心、分析层、策略引擎和监控仪表板——全部互联互通
让我们为加密市场设计一个完整的基于 QuestDB 的算法交易平台。该架构处理来自多家交易所的数据写入、实时分析、回测和策略执行。
数据写入层
 数据写入:多个交易所连接器通过 WebSocket 管道将实时行情数据经 ILP 协议写入 QuestDB
数据写入:多个交易所连接器通过 WebSocket 管道将实时行情数据经 ILP 协议写入 QuestDB
通过 HTTP 上的 ILP,连接到各交易所(Binance、Bybit、OKX 等)的多个 WebSocket 连接将原始行情数据写入 QuestDB。每个交易所连接器是一个独立进程,提供隔离性和容错性。
数据流包括:成交数据(timestamp, symbol, side, price, quantity)、订单簿快照(timestamp, symbol, bids[][], asks[][]),以及作为辅助流的资金费率/强平数据。
写入吞吐量目标:所有交易所合计每秒数百万行。QuestDB 的 WAL 能够轻松应对,去重功能捕获来自冗余交易所连接的不可避免的重复数据。
实时分析层
物化视图构成分析层的核心:
原始成交 → ohlc_1s → ohlc_5s → ohlc_1m → ohlc_5m → ohlc_15m → ohlc_1h → ohlc_1d
每一层增量刷新。通过 QuestDB 原生插件连接的 Grafana 仪表板查询这些视图绘制 K 线图,无论历史数据量多大,响应时间都在 5 毫秒以内。
额外的物化视图计算:每日每交易对的 VWAP(成交量加权平均价格)、滚动波动率估算,以及跨交易所价差监控。
针对预聚合视图的 LATEST ON 查询支持实时投资组合仪表板——显示当前持仓、未实现盈亏和各交易所敞口。
策略引擎
 策略引擎:实时指标计算驱动算法决策,买卖执行路径通过物化视图优化
策略引擎:实时指标计算驱动算法决策,买卖执行路径通过物化视图优化
交易策略查询 QuestDB 以获取当前市场状态和历史模式。QuestDB 的 PG 协议意味着任何具有 PostgreSQL 驱动的语言都可以连接:Python 用于研究策略,Rust 或 C++ 用于延迟敏感的执行。
策略的关键查询模式:ASOF JOIN 用于将执行成交与成交时的市场状况匹配、WINDOW JOIN 用于计算每个事件周围的短周期指标,以及用于实时指标计算的窗口函数(RSI、布林带、ATR)。
对于延迟敏感的策略,预计算物化视图最大程度地减少了查询时间。监控 50 个交易对的网格机器人不需要在每个 tick 时计算 50 个独立的移动平均线——它从物化视图中读取。
回测管道
历史数据以 Parquet 格式存储在对象存储中。QuestDB 可以透明地查询它,但对于繁重的回测工作负载,数据也可以由 Polars、Pandas 或 DuckDB 直接读取——完全绕过数据库。
这种双访问模式非常强大:实时策略使用 QuestDB 的 SQL 接口进行实时决策,而回测框架通过 Parquet/Arrow 读取相同数据进行批处理。相同的数据,两条优化的访问路径。
监控与交易后分析
HORIZON JOIN 为交易后分析管道提供支持:
- 滑点分析:将执行价格与成交时的中间价进行比较
- 标记曲线:跟踪每笔成交后 1 秒、5 秒、30 秒、60 秒的价格演变
- 实施差异:将执行成本分解为价差成本、临时冲击和永久冲击
- 交易场所评分:比较各交易所的成交质量以优化订单路由
这些分析作为计划查询运行,将结果写入专用表,为监控仪表板提供数据。告警规则在异常情况下触发——突然的滑点峰值、异常的标记模式,或特定交易场所成交质量下降。
性能注意事项
 生产环境性能调优:延迟、吞吐量和内存监控,以及 hot-warm-cold 数据生命周期管理
生产环境性能调优:延迟、吞吐量和内存监控,以及 hot-warm-cold 数据生命周期管理
来自生产部署的一些实践说明:
分区大小:对于每天每个交易对有数百万行的加密 tick 数据,PARTITION BY HOUR 通常是最优选择。这使单个分区在存储和查询性能方面都保持可管理。
物化视图级联:不要创建太多中间层次。每一层都会增加刷新延迟。对于大多数用例,3-4 层(1s → 1m → 15m → 1d)在查询性能和数据新鲜度之间提供了良好平衡。
去重开销:对具有冗余数据源的表启用去重。对于时间戳唯一的数据成本很小,但当许多相同时间戳的行需要基于列级别去重时,开销会增加。
内存分配:QuestDB 的零 GC 引擎效率很高,但要为热分区和写入缓存分配足够的内存。通过内置指标端点进行监控。
客户端协议选择:使用 HTTP 上的 ILP 进行写入(具有自动重试和健康检查)。使用 PG 协议进行查询。ILP 协议第 2 版(二进制编码)对于数组数据和高吞吐量双精度浮点值显著更高效。
QuestDB 与竞争对手对比
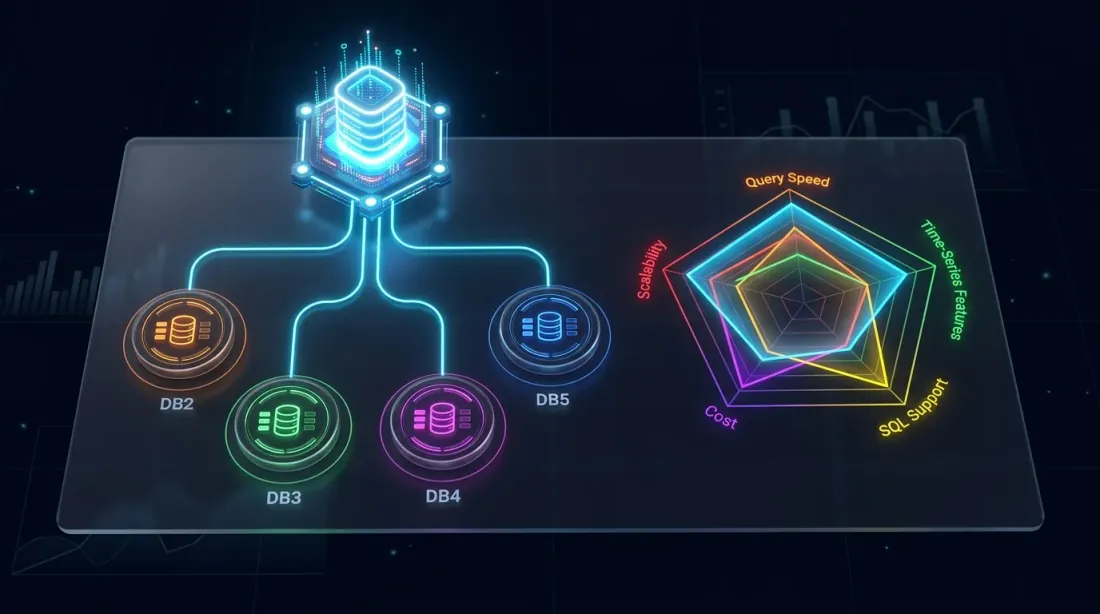 竞争格局:QuestDB 与 TimescaleDB、ClickHouse、InfluxDB 和 kdb+ 在关键能力维度的对比
竞争格局:QuestDB 与 TimescaleDB、ClickHouse、InfluxDB 和 kdb+ 在关键能力维度的对比
简要对比交易领域常用的数据库:
对比 TimescaleDB:TimescaleDB 是带时序扩展的 PostgreSQL。它继承了 PG 的通用性,但也继承了其开销。QuestDB 的原生列式引擎和 SIMD 执行在时序工作负载上提供了显著更好的查询性能,而 ASOF JOIN 等功能在 TimescaleDB 中没有直接对应项。
对比 ClickHouse:ClickHouse 擅长对海量数据集进行分析查询。但它并非专为时序设计——没有原生 ASOF JOIN,没有带 FILL 的 SAMPLE BY,没有用于订单簿的 2D 数组。对于混合 OLAP + 时序工作负载,ClickHouse 可能胜出;对于纯交易数据,QuestDB 使用体验更佳。
对比 InfluxDB:InfluxDB 存在高基数限制,对于多交易所加密数据非常棘手。其查询语言(Flux,现已废弃;InfluxQL)缺乏 QuestDB SQL 扩展的表达能力。大型历史查询的性能通常更差。
对比 kdb+/q:高频交易的黄金标准。kdb+ 在某些单线程向量运算上更快,其 q 语言极为简洁。但它是专有的、昂贵的,且学习曲线陡峭。QuestDB 以极低的成本提供了 80-90% 的能力,具备标准 SQL 和开源许可。
结论:真正懂交易的数据库
在这三篇文章中,我们介绍了 QuestDB 的架构(三层存储:WAL、列式存储和 Parquet)、其 SQL 扩展(SAMPLE BY、ASOF JOIN、HORIZON JOIN、WINDOW JOIN、LATEST ON、TWAP),以及实际应用(物化视图、订单簿数组、参考架构)。
贯穿始终的主线是一致的:QuestDB 正是为算法交易所产生的工作负载而设计的。它不会强迫你绕开数据库——相反,其原语直接映射到交易概念。OHLC 聚合是一行代码。成交-报价对齐是一个 JOIN。交易后分析是一个 HORIZON JOIN,而非多页 PL/SQL 过程。
对于构建交易基础设施的团队——无论是加密行情数据平台、量化研究环境,还是完整的算法交易引擎——QuestDB 值得认真评估。开源版本涵盖大多数用例,企业版填补了受监管环境的空白。
金融数据基础设施格局正在快速演变。能够读懂市场语言的数据库将会胜出。QuestDB 已经流利掌握了这门语言。
祝交易顺利,愿你的延迟永远低。
引用
@software{soloviov2025questdb_algotrading_p3,
author = {Soloviov, Eugen},
title = {QuestDB for Algorithmic Trading: From Order Books to Production Architecture},
year = {2025},
url = {https://marketmaker.cc/en/blog/post/questdb-algotrading-production},
version = {0.1.0},
description = {Materialized views, 2D array order book analytics, and reference architecture for a QuestDB-powered algorithmic trading platform.}
}
MarketMaker.cc Team
量化研究与策略


