引言:为什么聚合盘口在"说谎"
每一位看盘口交易的交易者都会看到同样的画面:左边是买盘(bid),右边是卖盘(ask),每个价格层级显示一个数字,代表限价单的总量。例如:
价格 10001 | 150 手
价格 10000 | 2,400 手 ← 挂单墙
价格 9999 | 80 手
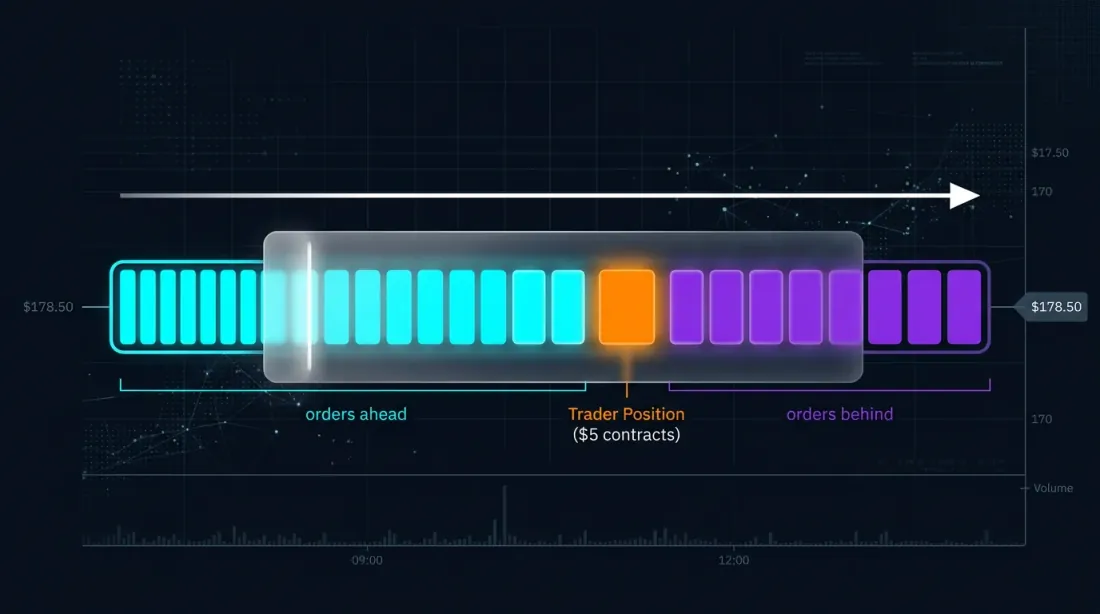
10000 价位上的 2,400 手就是一堵"墙"(wall、density,即密集挂单区)。这里出现了一个大多数交易者忽视的关键问题:我们的订单在这 2,400 手中到底排在哪个位置?
价格 10000 [ 我们前面 1,800 手 ][ 我们的订单 10 手 ][ 我们后面 590 手 ]
这不是学术上的好奇心。这是订单被执行与未被执行的区别。是盈利与亏损的区别。是回测中显示漂亮净值曲线与现实中策略失效的区别。
什么是 Queue Position(排队位置),为什么要计算它
 FIFO 队列可视化:交易者在价格层级中与其他订单的相对位置
FIFO 队列可视化:交易者在价格层级中与其他订单的相对位置
FIFO 与交易所的现实
绝大多数交易所——无论是传统交易所(CME、NASDAQ),还是加密货币交易所(Binance、Bybit、OKX)——都采用**价格-时间优先(FIFO)**规则。这意味着:在相同价格下,最先提交的订单最先被执行。
当一个市价卖单到达并"击中"我们的 bid 价格层级时,它会按照从队首到队尾的顺序依次执行限价单。如果该市价单不够大,无法到达我们在队列中的位置——我们的订单就不会被执行。
排队位置价值的两个组成部分
学术研究(Moallemi & Yuan,哥伦比亚商学院,2017)将排队位置的价值分为两个组成部分:
-
静态组成部分 —— 赚取价差与逆向选择之间的权衡。我们在队列中越靠后,被大型知情订单(而非噪音交易)执行的概率就越高。简单来说:如果你是队列中最后被执行的——价格很可能已经朝不利方向运动了。
-
动态组成部分 —— 随着时间推移,队列位置改善带来的期权价值。当排在我们前面的订单被取消或执行时,我们的位置会自动改善,无需任何主动操作。
实证数据表明,对于大 tick 品种,排队位置的价值可以与价差大小相当。这是一个巨大的数值。
如何评估自己的排队位置
评估问题
我们以价格 P 提交一笔大小为 S 的限价单。提交时该价格层级上已有 Q 手。我们的初始位置估计:
V̂(t₀) = Q(t₀) — 排在我们前面的手数
然后,我们跟踪该价格层级上所有的成交量变化。这是 Erik Rigtorp 描述并在 Trading Technologies (TT)、Bookmap 等产品中实现的核心算法。
更新算法
每当价格层级上的量减少 ΔQ 时,我们需要判断:减少的是排在我们前面的还是排在我们后面的订单?
如果我们能区分成交(fills)和撤单(cancellations):
- 成交(Fill): 确定性地减少前方队列 →
V̂ = max(V̂ + ΔQ, 0) - 撤单(Cancel): 不确定性——撤掉的订单可能在我们前面,也可能在后面
对于撤单,使用概率模型:
V̂(n+1) = max(V̂(n) + p(n) × ΔQ(n), 0)
其中 p(n) 是被撤订单排在我们前面的概率。一类模型为:
p(n) = f(V̂(n)) / (f(V̂(n)) + f(max(Q(n) - S - V̂(n), 0)))
其中 f(x) 是递增函数,例如 ln(1+x) 或恒等函数。直觉是:相对于后方量,前方量越大,撤单发生在前方的概率就越高。
数据层级与加密市场现实
评估质量直接取决于数据的精细度:
| 数据层级 | 可见内容 | PIQ 评估精度 |
|---|---|---|
| Level 1 (BBO) | 最优买卖价 + 量 | 无法评估 |
| Level 2 (价格聚合) | 每个价格层级的量 | 概率估计 |
| Level 3 (Market-by-Order, MBO) | 每笔独立订单及其 ID | 精确位置 |
加密市场的现状:
- Binance —— 提供 L2 depth stream,更新间隔 100ms。L3 (MBO) 数据不公开提供。
- Coinbase —— 少数提供 L3 流的中心化交易所之一,通过 WebSocket 提供完整的逐单数据。
- CME(BTC/ETH 期货)—— 通过 ITCH feed 提供完整的 MBO 数据。
大多数加密交易者使用 L2 数据,因此只能进行概率估计。但即使是概率估计,也远好于完全没有评估。
可视化:将墙看作内部盘口
我们建议将每个显著的密集挂单区(墙)可视化为盘口中的迷你盘口:
╔════════════════════════════════════════════════════════════════╗
║ 价格 10001 │ 150 手 ║
╠════════════════════════════════════════════════════════════════╣
║ 价格 10000 │ [████████████░░░▓▓░░░░░░░] 2,400 手 ║
║ │ ↑ 前方 1,800 ↑ 我们 ↑ 后方 590 ║
║ │ 消耗速度: ~120 手/秒 ║
║ │ 预计成交时间: ~15 秒 ║
╠════════════════════════════════════════════════════════════════╣
║ 价格 9999 │ 80 手 ║
╚════════════════════════════════════════════════════════════════╝
实时计算内容
-
我们订单前方的手数 —— 在轮到我们之前,需要被执行或撤销的量的估计值。
-
我们订单后方的手数 —— 排在我们后面的量。如果墙从尾部快速"膨胀"——意味着其他参与者认为该价位有吸引力。
-
队列消耗速度 —— 基于该价格层级实际成交(trades)计算。以手/秒表示。
-
预计成交时间(Estimated Time to Fill, ETF) —— 我们订单被执行的时间预测,计算公式为
前方手数 / 消耗速度。 -
同一密集区的多笔订单 —— 如果机器人在同一面墙内有多笔订单,可以看到每笔订单各自的位置。
在高频交易中的应用
 朴素回测与 Queue-aware 回测的对比:真实成交概率 vs 乐观估计
朴素回测与 Queue-aware 回测的对比:真实成交概率 vs 乐观估计
K线数据回测的问题
经典的 OHLCV K线回测逻辑是:如果价格触及我们的限价单——就算作成交。但这是一个严重的错误:
示例。 我们在 10000 价位有一笔买入限价单。分钟 K线的最低价 low = 10000。K线回测记录为成交。但实际上:
- 10000 价位有一面 5,000 手的挂单墙
- 我们的订单排在队尾(第 4,800 位)
- 这一分钟内该价位只成交了 2,000 手
- 实际上我们的订单不会被执行
Queue-aware 回测解决了这个问题:它模拟排队位置,根据逐笔数据统计该价位的成交量,判断成交量是否足以到达我们的位置。
一分钟内——不止一次成交
在活跃的高频交易中,一个订单可能在一分钟内被执行并重新提交多次。K线回测根本无法模拟这种情况。只有带队列模拟的逐笔分析才能:
- 确定每次成交的精确时间
- 判断我们是否来得及重新提交订单
- 评估策略在一个时间区间内实际会触发多少次
预测成交等待时间
了解自身排队位置和当前墙消耗速度的机器人可以:
- 计算预计成交时间(ETA) —— 大致的成交等待时间
- 将 ETA 与价格预测关联 —— 如果 ETA = 30 秒,但我们的模型预测 10 秒后价格反转,应该撤单
- 调整订单大小 —— 在按比例分配的交易所(CME)上,较大的订单更接近队首;但在 FIFO 交易所上,订单大小不影响排队位置
与平均值比较消耗速度
对高频交易者而言最有价值的指标:当前队列消耗速度 vs 过去 N 根 K线的平均速度。
- 速度高于平均 → 市价单攻击性高 → 墙可能被"击穿" → 我们的成交概率更大
- 速度低于平均 → 市场"冻结" → 墙将坚守 → 订单会挂住,价格可能离开
市场现有实现概览
Trading Technologies (TT) — Position In Queue (PIQ)
最成熟的实现。TT 在 Floating Order Book 列中为每笔交易者订单显示 PIQ。对于通过数据源直接提供排队位置信息的交易所(CME、ICE),显示精确值。其余交易所则为保守估计。
Bookmap Quant
Bookmap 专业版($499/月)包含订单排队位置可视化和事件导出功能。Bookmap Quant 使用 MBO 数据,其 L0 API 允许为任意数据源构建自定义适配器。
CQG — 排队位置估算
CQG 为期货市场提供排队位置估算功能。该平台基于 L2/L3 数据计算概率性 PIQ 估算值,并在 DOMTrader 界面中显示。
Rithmic — 排队数据提供商
Rithmic 是一家市场数据提供商,提供低延迟的排队位置评估数据。许多自营交易公司和算法交易者将其作为基础设施层,用于构建自己的 PIQ 模型。
Jigsaw Trading — 订单流可视化
Jigsaw Trading 专注于带排队位置估算的订单流可视化。其 Depth & Sales 和 Reconstructed Tape 工具帮助交易者看到价格层级上的真实执行情况。
学术模型
- Moallemi & Yuan (2017) —— 基于 NASDAQ ITCH 数据的排队位置价值正式模型
- Cont, Stoikov & Talreja (2010) —— 将限价订单簿建模为生灭过程系统
- Gould & Bonart (2015) —— 队列失衡作为中间价单 tick 预测指标
- 深度学习方法 —— RNN 模型(哥伦比亚大学,2022)用于评估成交概率和成交时间
市场上尚不存在的产品
目前没有任何现有产品为加密市场提供专门面向高频交易机器人的墙内部结构可视化。 这正是 Marketmaker.cc 可以填补的空白。
对抗操纵者策略
 识别虚假挂单墙:真实订单 vs 高撤单率的幌骗订单
识别虚假挂单墙:真实订单 vs 高撤单率的幌骗订单
理解墙的内部结构不仅仅是优化自身的执行质量。它是防范操纵的工具,如果运用得当,也是解读大户意图的工具。
幌骗(Spoofing):虚假挂单墙
幌骗是指提交大额订单并打算在执行前撤销。目的是制造虚假的供需印象。
PIQ 分析如何帮助识别:
- 墙体堆积速度。 真实的墙是逐步形成的。幌骗墙瞬间出现。
- 价格逼近时的行为。 真实的墙会留在原地。幌骗墙会"逃跑"。
- 撤单率。 幌骗者在执行前撤销订单。跟踪提交/撤销比率可以实时检测幌骗。
- 周期性。 幌骗常呈现重复模式:出现 → 消失 → 在新价位出现。
分层下单(Layering):多层级虚假挂单
Layering 是幌骗的高级形式,在多个价格层级上提交虚假订单。
PIQ 分析如何帮助识别:
- 关联撤单。 如果连续 5 个价格层级的订单同时被撤销——几乎可以确定是同一参与者的 layering。
- 盘口不对称。 真实的流动性通常分布相对均匀。
- 对成交的反应。 真实的订单会被执行而不会"逃跑"。
冰山订单(Iceberg Orders):隐藏的流动性
冰山订单是将大额订单拆分为小的可见部分。当一部分被执行后,下一部分自动出现。
PIQ 分析如何帮助识别:
- "不死"价位模式。 成交量持续被消耗,但总量不减少。
- 吸收分析(Absorption Analysis)。 价格冲击墙体,执行了可见量,但墙体恢复了。
- 吸收过程中的队列行为。 每当冰山的一部分被执行并重新排队到尾部时,我们的位置会"滑向"前方。
做市商作为墙内的"隐形"参与者
专业做市商使用多种策略:
- 报价轰炸(Quote Stuffing) —— 大量提交和撤销订单,"干扰"竞争对手的数据处理
- 一分抢先(Penny Jumping) —— 以比竞争对手好一个 tick 的价格下单以获取优先权
- 动态报价(Dynamic Quoting) —— 根据队列失衡实时调整订单
- 价位保护 —— 当价格逼近时增加流动性
实现:Queue Position Tracker 模块架构
输入数据
1. WebSocket 订单簿数据流(L2 depth):
- 最优买卖价更新
- 深度更新(每个价格层级的量)
2. WebSocket 成交数据流:
- 每笔成交: 价格、数量、方向(买/卖)、时间戳
3. 自有订单(来自交易机器人):
- order_id、价格、数量、提交时间戳
核心算法(Python 风格伪代码)
class QueuePositionTracker:
def __init__(self, order_price, order_size, initial_depth):
self.price = order_price
self.size = order_size
self.queue_ahead = initial_depth # V̂(t₀) = Q(t₀)
self.queue_behind = 0
self.fill_velocity = EMA(span=30) # 成交速度的指数移动平均
def on_trade(self, trade_price, trade_size):
"""每当我们的价格层级发生成交时调用"""
if trade_price == self.price:
self.queue_ahead = max(self.queue_ahead - trade_size, 0)
self.fill_velocity.update(trade_size)
def on_depth_change(self, new_depth, change_type):
"""每当我们的价格层级深度变化时调用"""
if change_type == 'cancel':
total = self.queue_ahead + self.size + self.queue_behind
p_ahead = log(1 + self.queue_ahead) / (
log(1 + self.queue_ahead) + log(1 + self.queue_behind)
)
cancelled = abs(new_depth - total)
self.queue_ahead = max(
self.queue_ahead - p_ahead * cancelled, 0
)
self.queue_behind = max(
self.queue_behind - (1 - p_ahead) * cancelled, 0
)
elif change_type == 'new_order':
added = new_depth - (self.queue_ahead + self.size + self.queue_behind)
self.queue_behind += added
@property
def estimated_time_to_fill(self):
"""预计成交时间(秒)"""
if self.fill_velocity.value <= 0:
return float('inf')
return self.queue_ahead / self.fill_velocity.value
@property
def fill_probability(self, horizon_sec=60):
"""在给定时间范围内的成交概率"""
expected_volume = self.fill_velocity.value * horizon_sec
return min(expected_volume / max(self.queue_ahead, 1), 1.0)
关键边界情况
- 墙被完全"吃穿" —— 如果
queue_ahead降为 0,下一笔市价单就会执行我们的订单 - 大规模撤单(wall pull) —— 墙突然消失,
queue_ahead跳跃式变化 - 我们的订单被移动 —— 撤销并重新提交后,我们排到队尾
- 同一面墙内有多笔订单 —— 每笔独立跟踪
仪表盘和回测指标
实时指标(高频交易终端)
| 指标 | 公式 | 颜色 |
|---|---|---|
| 排队位置 % | queue_ahead / total_depth × 100 |
绿色 < 30%,黄色 30-70%,红色 > 70% |
| 预计成交时间 | queue_ahead / fill_velocity |
秒 |
| 墙体健康度 | depth_now / depth_5sec_ago |
墙体稳定性 |
| 吸收率 | filled_volume / visible_depth |
是否存在隐藏流动性 |
| 幌骗评分 | cancel_rate × sudden_appear × distance_from_price |
0-100,虚假指标 |
回测指标(queue-aware 模拟)
- Queue-adjusted 成交率 —— 考虑排队位置后实际成交的订单比例
- 有效成交延迟 —— 从提交到执行的实际时间
- 每笔成交的逆向选择 —— 成交后价格对我们不利方向的平均移动幅度
- 队列速度相关性 —— 队列消耗速度与后续价格运动之间的相关性
社交盘口:墙内的团队订单
 三级可见性模型:个人订单、订阅者和团队持仓在墙内的展示
三级可见性模型:个人订单、订阅者和团队持仓在墙内的展示
第一层:交易所或交易平台
如果你是交易所或交易终端,你拥有关于每个用户每笔订单位置的绝对知识。平台可以向每位用户展示:在他的订单前后有多少"他人"的量,而不泄露其他参与者的身份。
第二层:Marketmaker.cc 平台 —— 个人订单 + 社交层
在 Marketmaker.cc 中,我们计划实现墙内订单的三级可见性模型:
个人订单 —— 基础层。每位交易者可以看到自己所有订单的独立指标。
订阅者订单(信号提供者) —— 通过订阅分享持仓的交易者。采用 Opt-in 机制:领导者自行决定是否展示持仓。
团队订单(交易团队/基金) —— 对专业团队最有价值的层级。解决的问题包括:订单冲突、流动性分配、团队风险监控、培训。
权限模型
┌─────────────────────────────────────────────────────────────┐
│ 交易者的订单 │
│ │
│ 可见性: │
│ ├── 交易者本人 → 始终可见 │
│ ├── 订阅者 → 如果交易者开启了该功能 │
│ │ ├── 显示延迟 → 可配置 (0s–60s) │
│ │ ├── 显示数量 → 是 / 隐藏 / 取整 │
│ │ └── 显示预计成交时间 → 是 / 否 │
│ └── 团队 → 如果加入了团队 │
│ ├── 延迟 → 可配置 (0s–5s) │
│ ├── 显示数量 → 是(用于风险管理) │
│ └── 角色可见性 → 交易员 / 经理 / 观察者 │
└─────────────────────────────────────────────────────────────┘
完全透明:DEX 与链上订单簿
在拥有链上订单簿的 DEX 上——尤其是 Hyperliquid——每笔订单都绑定到特定的钱包地址。我们不仅可以看到聚合后的墙,还可以看到每个参与者的每笔独立订单。
然而,要实时处理这些数据,需要搭建自己的 Hyperliquid 区块链节点。
自动识别操纵者的订单
第四层可视化——按参与者类型对订单进行算法标注:做市商、幌骗者、散户。分类算法在多个层面运作:幌骗检测、做市商分类、轧空场景检测、交易者数字指纹。
更多详情请参阅本系列下一篇文章:《交易者数字指纹:如何通过订单簿行为识别做市商》
结论
订单簿密集区内的挂单位置分析是从"看盘口"到"理解市场微观结构"的下一个进化步骤。这是多个领域的交叉地带:
- 排队论(queueing theory)—— 用于队列建模
- 随机订单流模型(Stochastic order flow models)—— 用于评估成交概率
- 机器学习 —— 用于幌骗检测和墙体行为预测
- 低延迟工程 —— 用于实时数据获取和处理
截至目前,加密市场上没有任何产品在统一界面中提供完整的"墙作为迷你盘口"可视化,包含用户订单位置、预计成交时间估算、幌骗检测和 queue-aware 回测。
我们在 Marketmaker.cc 致力于让每一位交易者——从个人高频交易者到专业自营团队——都能使用这些分析工具。
参考文献与延伸阅读
- Moallemi C.C., Yuan K. — "A Model for Queue Position Valuation in a Limit Order Book" (Columbia Business School, 2017)
- Cont R., Stoikov S., Talreja R. — "A Stochastic Model for Order Book Dynamics" (2010)
- Gould M.D., Bonart J. — "Queue Imbalance as a One-Tick-Ahead Price Predictor" (2015)
- Rigtorp E. — "Estimating Order Queue Position" (rigtorp.se)
- Do B.L., Putniņš T.J. — "Detecting Layering and Spoofing in Markets" (SSRN, 2023)
- Trading Technologies — PIQ Documentation
- Bookmap — Iceberg Orders Tracker Knowledge Base
MarketMaker.cc Team
量化研究与策略