النزول الإحداثي مقابل التحسين البايزي: أيهما يجد معاملات أفضل
هذه هي المقالة الخامسة في سلسلة "اختبارات رجعية بلا أوهام". في المقالات السابقة تناولنا عدم تماثل الخسارة والربح، ومحاكاة مونت كارلو بالتمهيد، وتأثير معدلات التمويل، وذاكرة التخزين المؤقت Parquet للاختبارات الرجعية متعددة الأطر الزمنية. والآن لنتحدث عن عملية إيجاد المعاملات المثلى للاستراتيجية — وهي مهمة يخفق فيها الحدس في أغلب الأحيان.
لديك استراتيجية بـ 12 معاملاً. كل معامل يأخذ حوالي 9 قيم. تريد إيجاد التركيبة التي تعظّم الربح والخسارة (PnL) مع تقييد التراجع. كيف تفعل ذلك؟
إذا كانت إجابتك "أجرب جميع التركيبات" — فلديك مشكلة. وإذا كانت إجابتك "أغيّر معاملاً واحداً في كل مرة" — فلديك مشكلة مختلفة. هذه المقالة عن المشاكل الكامنة وراء كل منهج وكيفية حلها.
لماذا البحث الشامل مستحيل

لعنة الأبعاد
البحث الشامل (grid search) يختبر كل تركيبة من القيم لكل معامل. لمعاملين بـ 9 قيم، هذا تشغيلة — ممكن تماماً. لثلاثة: — مقبول.
لكن لاستراتيجية حقيقية بـ 12 معاملاً:
مائتان واثنان وثمانون مليار تشغيلة. حتى لو استغرق اختبار رجعي واحد ثانية واحدة (وهو تقدير متفائل بالفعل)، فإن البحث الشامل سيستغرق:
هذا نمو أسي: كل معامل جديد يضرب فضاء البحث في 9. أضف المعامل الثالث عشر — وبدلاً من 9,000 سنة تحتاج 80,000.
import math
def grid_search_cost(n_params: int, values_per_param: int, seconds_per_trial: float) -> dict:
"""Estimate the cost of exhaustive search."""
total_trials = values_per_param ** n_params
total_seconds = total_trials * seconds_per_trial
return {
"total_trials": total_trials,
"total_hours": total_seconds / 3600,
"total_years": total_seconds / (3600 * 24 * 365),
}
cost = grid_search_cost(12, 9, 1.0)
print(f"Trials: {cost['total_trials']:,.0f}") # 282,429,536,481
print(f"Years: {cost['total_years']:,.0f}") # 8,950
حتى مع الحساب المسبق
في مقالة ذاكرة التخزين المؤقت Parquet أوضحنا كيف يسرّع الحساب المسبق للأطر الزمنية والمؤشرات اختباراً رجعياً واحداً إلى حوالي ثانية واحدة. لكن حتى عند 0.1 ثانية لكل تشغيلة، فإن البحث الشامل لـ 12 معاملاً سيستغرق 895 سنة. الحساب المسبق يساعد، لكنه لا يحل المشكلة الجوهرية للنمو الأسي.
نحتاج إلى أساليب تستكشف فضاء المعاملات بشكل أذكى من البحث الشامل.
النزول الإحداثي وOAT: سريع لكن أعمى
نوعان من نفس الفكرة
هناك منهجان متصلان — كلاهما يحسّن معاملاً واحداً في المرة، لكنهما يختلفان في عدد المرات:
مسح OAT (واحد في المرة) — مرور واحد عبر جميع المعاملات. تكرر قيم المعامل الأول، تثبّت الأفضل، تنتقل للثاني — وهكذا. مرة واحدة فقط. سريع ورخيص.
النزول الإحداثي — مرور متعدد. بعد تحسين المعامل الأخير، تعود للأول وتتحقق مما إذا كان الأمثل قد تغيّر (بما أن السياق تغيّر — قيم المعاملات الأخرى أصبحت مختلفة). تكرر الجولات حتى التقارب. أكثر كلفة، لكن أكثر دقة — كل جولة يمكن أن تحسّن الحل.
عملياً، في الاختبارات الرجعية يُستخدم OAT أكثر: مرور واحد عبر 12 معاملاً — 96 تشغيلة. النزول الإحداثي بـ 3-5 جولات — 300-500 تشغيلة، وهو بالفعل مماثل لـ Optuna، لكن بدون مزاياه.
لـ 12 معاملاً بحوالي 8 قيم لكل منها:
قارن مع للبحث الشامل. OAT خطي: بدلاً من . هذه ميزته الرئيسية ومشكلته الرئيسية في آن واحد.
def oat_sweep(
param_grid: dict[str, list],
run_backtest_fn,
initial_params: dict,
metric: str = "effective_score",
) -> dict:
"""
OAT sweep: single pass, optimizing one parameter at a time.
param_grid: {"htf_entry_sell": [0.0, 0.005, ..., 0.05], ...}
initial_params: starting values for all parameters
metric: metric to optimize (effective_score recommended —
PnL per active time extrapolated to a year)
"""
best_params = initial_params.copy()
best_score = run_backtest_fn(**best_params)[metric]
for param_name, values in param_grid.items():
param_best_val = best_params[param_name]
param_best_score = best_score
for val in values:
candidate = best_params.copy()
candidate[param_name] = val
result = run_backtest_fn(**candidate)
score = result[metric]
if score > param_best_score:
param_best_score = score
param_best_val = val
best_params[param_name] = param_best_val
best_score = param_best_score
print(f"{param_name}: best={param_best_val}, score={param_best_score:.4f}")
return best_params
أي مقياس تختار للتحسين؟ بدلاً من PnL الخام أو PnL@MaxLev، يُنصح باستخدام effective score — الربح والخسارة لكل وقت نشط مستقرَأً إلى سنة. يأخذ هذا المقياس في الاعتبار الوقت في المركز ويسمح بالمقارنة الصحيحة للاستراتيجيات ذات تكرارات التداول المختلفة.
النقطة العمياء: تفاعلات المعاملات
يفترض OAT أن تأثير كل معامل جمعي — أي أن القيمة المثلى لمعامل واحد لا تعتمد على قيم الآخرين. هذا الافتراض صحيح لبعض المعاملات، لكنه يفشل للمعاملات المترابطة.
المعاملات الجمعية مقابل المترابطة
قبل التحسين — من المفيد تصنيف المعاملات:
جمعية (مستقلة) — القيمة المثلى لأحدها لا تعتمد على الآخر. يمكن تحسينها فردياً بتكلفة منخفضة:
htf_entry_sellوhtf_entry_buy— عتبات الدخول لاتجاهين مختلفين (بيع/شراء) على نفس الإطار الزمني. عتبة البيع تصفي إشارات البيع القصير، وعتبة الشراء تصفي الشراء الطويل. تعمل على مجموعات فرعية غير متداخلة من الصفقات.tp_targetوbe_trigger— جني الأرباح ونقطة التعادل، إذا لم يخلقا شروط خروج متعارضة.
مترابطة (تفاعلية) — القيمة المثلى لأحدها تعتمد على الآخر. يلزم التحسين المشترك:
htf_entry_sellوmtf_entry_sell— عتبات لنفس الاتجاه (بيع) على أطر زمنية مختلفة. HTF يحدد أي إشارات تصل إلى MTF، وعتبة MTF تحدد فعالية التصفية. يتحول أمثل HTF عندما يتغير MTF.ltf_entry_sell،mtf_entry_sell،htf_entry_sell— سلسلة العتبات الكاملة لاتجاه واحد.partial_fracوtp_target— حجم الإغلاق الجزئي يعتمد على مستوى TP.
المنهج العملي: أولاً حسّن المعاملات الجمعية عبر OAT بتكلفة منخفضة. ثم حسّن المجموعات المترابطة عبر Optuna. هذا يقلل الميزانية: بدلاً من 12 معاملاً في Optuna، نرسل فقط 6-8 معاملات مترابطة، بينما الباقي مثبّت بالفعل.
مثال: كيف يفوّت OAT تفاعلاً
لنأخذ عتبتين مترابطتين:
htf_entry_sell— عتبة على الإطار الزمني الأعلى (اتجاه البيع)mtf_entry_sell— عتبة على الإطار الزمني الأوسط (اتجاه البيع)
يثبّت OAT mtf_entry_sell = 0.01 (القيمة الابتدائية) ويكرر عبر htf_entry_sell. يجد أفضل قيمة: htf_entry_sell = 0.02. يثبّتها وينتقل للمعامل التالي — ولا يعود أبداً.
إليك ما فاته OAT:
htf_entry_sell |
mtf_entry_sell |
PnL |
|---|---|---|
| 0.02 | 0.01 | +42% |
| 0.02 | 0.02 | +38% |
| 0.03 | 0.02 | +51% |
| 0.03 | 0.01 | +35% |
التركيبة (0.03, 0.02) تعطي PnL بنسبة +51%، لكن OAT لن يدرسها أبداً لأنه مع mtf_entry_sell = 0.01 المثبّت، القيمة htf_entry_sell = 0.03 تعطي +35% فقط. وقع OAT في الأمثل المحلي (0.02, 0.01) ولا يستطيع رؤية الأمثل الشامل (0.03, 0.02).
هذه مشكلة كلاسيكية: إذا كان سطح دالة الهدف يحتوي على حواف قطرية (عندما ينزاح أمثل معامل بتغيّر آخر)، فإن OAT يفوّتها.
صياغة المشكلة
ليكن دالة الهدف (PnL). يجد OAT نقطة حيث:
لكن هذا شرط ضروري، لا كافٍ للأمثل الشامل. إذا كانت مصفوفة هيسيان تحتوي على عناصر خارج القطر ذات دلالة — فإن OAT لا يأخذ في الاعتبار المشتقات المتقاطعة عندما .
للمعاملات المترابطة (عتبات نفس الاتجاه عبر أطر زمنية متعددة) — التفاعلات هي القاعدة لا الاستثناء. عتبة الدخول على الإطار الزمني الأعلى تحدد أي إشارات تصل إلى الأوسط، وعتبة الأوسط تحدد فعالية التصفية على الأدنى. للمعاملات الجمعية (اتجاهات مختلفة، مرشحات مستقلة) المشتقات المتقاطعة قريبة من الصفر — ويعمل OAT جيداً.
التحسين البايزي: بحث ذكي

الفكرة
بدلاً من التعداد الأعمى أو البحث الجشع، يبني التحسين البايزي نموذجاً بديلاً لدالة الهدف ويختار في كل خطوة النقطة التي يكون فيها التحسن المتوقع أقصى.
الخوارزمية:
- اختر عدة نقاط عشوائية، قيّم دالة الهدف
- ابنِ نموذجاً بديلاً (يقرّب من النقاط المرصودة)
- جد النقطة ذات أقصى تحسن متوقع (دالة الاستحواذ)
- قيّم دالة الهدف عند تلك النقطة
- حدّث النموذج البديل
- كرر الخطوات 3-5
الفرق الجوهري عن OAT: التحسين البايزي يأخذ في الاعتبار جميع المعاملات في وقت واحد ويمكنه استكشاف الحواف القطرية في فضاء المعاملات.
TPE (مقدّر Parzen ذو البنية الشجرية)

TPE هو العيّنة الافتراضية في Optuna. بدلاً من نمذجة مباشرة، ينمذج TPE توزيعين:
- — توزيع المعاملات حيث دالة الهدف أفضل من العتبة
- — توزيع المعاملات حيث دالة الهدف أسوأ من العتبة
دالة الاستحواذ في TPE هي النسبة:
يختار TPE النقاط حيث كبير (معاملات مشابهة لـ"الجيدة") و صغير (معاملات غير مشابهة لـ"السيئة").
لماذا TPE مناسب للاختبارات الرجعية:
- يتعامل مع التبعيات الشرطية بين المعاملات
- لا يتطلب استمرارية دالة الهدف
- فعّال مع ميزانيات معتدلة (100-1000 تكرار)
- يدعم المعاملات الفئوية والمنفصلة
العملية الغاوسية (GP)
بديل لـ TPE — العملية الغاوسية. تنمذج GP الدالة كعملية طبيعية متعددة المتغيرات وتوفر ليس فقط تنبؤاً بالقيمة، بل أيضاً عدم اليقين عند كل نقطة.
حيث هو المتوسط، و هي دالة التغاير (النواة).
تعمل GP جيداً عندما:
- يكون عدد المعاملات قليلاً (حتى 10-15)
- تكون دالة الهدف سلسة
- تكون كل تشغيلة مكلفة (دقائق، ساعات)
للاختبارات الرجعية مع ذاكرة التخزين المؤقت Parquet المحسوبة مسبقاً، حيث تستغرق التشغيلة الواحدة حوالي ثانية واحدة، يُفضّل TPE عادةً: يبني النموذج أسرع ويتوسع بشكل أفضل لـ 500+ تكرار.
التكامل العملي مع Optuna
مثال عملي كامل
import optuna
from optuna.samplers import TPESampler
import numpy as np
def run_backtest(htf_pre, mtf_pre, ltf_pre, **params) -> dict:
"""
Runs a backtest with given parameters.
Returns a dict with metrics: pnl, max_dd, n_trades, trading_time, sharpe.
Uses precomputed Parquet cache — ~1 second per run.
"""
pass
def objective(trial: optuna.Trial) -> float:
"""Objective function for Optuna."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
study = optuna.create_study(
sampler=TPESampler(seed=42),
study_name="strategy_optimization",
direction="minimize",
)
study.optimize(objective, n_trials=500, show_progress_bar=True)
print(f"Best PnL: {-study.best_value:.2f}%")
print(f"Best params: {study.best_params}")
print(f"Total trials: {len(study.trials)}")
عند حوالي ثانية واحدة لكل اختبار رجعي (مع ذاكرة التخزين المؤقت المحسوبة مسبقاً):
ثماني دقائق مقابل 8,950 سنة للبحث الشامل. ويجد TPE في 500 تكرار تركيبات يفوّتها OAT في 96، لأنه يستكشف فضاء المعاملات بشكل متزامن وليس محوراً واحداً في المرة.
حفظ واستئناف الدراسة
import optuna
study = optuna.create_study(
storage="sqlite:///optuna_study.db",
study_name="strategy_v2",
sampler=TPESampler(seed=42),
direction="minimize",
load_if_exists=True, # continue if study already exists
)
study.optimize(objective, n_trials=300)
study.optimize(objective, n_trials=200)
إضافة قيود
ليست كل تركيبات المعاملات صالحة. على سبيل المثال، عتبة الخروج يجب ألا تتجاوز عتبة الدخول:
def objective_with_constraints(trial: optuna.Trial) -> float:
htf_entry = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
htf_exit = trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005)
if htf_exit > htf_entry:
raise optuna.TrialPruned()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
مقارنة العيّنات
يدعم Optuna عدة عيّنات. لكل منها نقاط قوتها.
TPESampler (الافتراضي)
sampler = optuna.samplers.TPESampler(
n_startup_trials=20, # random trials before modeling begins
seed=42,
)
- المبدأ: Tree-structured Parzen Estimator
- نقاط القوة: جيد لأنواع المعاملات المختلطة، يتوسع لـ 1000+ تكرار
- نقاط الضعف: قد يكون أقل كفاءة مع تفاعلات قوية بين المعاملات
- متى تستخدمه: افتراضياً، إذا لم يكن هناك سبب لاختيار آخر
CmaEsSampler
sampler = optuna.samplers.CmaEsSampler(seed=42)
- المبدأ: Covariance Matrix Adaptation Evolution Strategy — خوارزمية تطورية تكيّف مصفوفة التغاير
- نقاط القوة: ممتاز في إيجاد التفاعلات بين المعاملات المستمرة، يأخذ الارتباطات في الاعتبار
- نقاط الضعف: لا يدعم المعاملات الفئوية، يتطلب تكرارات أكثر للتهيئة
- متى تستخدمه: إذا كانت جميع المعاملات مستمرة وتشك في وجود تفاعلات قوية
GPSampler
sampler = optuna.samplers.GPSampler(seed=42)
- المبدأ: العملية الغاوسية مع دالة استحواذ
- نقاط القوة: أفضل كفاءة عيّنة (تكرارات أقل لنتيجة جيدة)، يوفر تقديرات عدم اليقين
- نقاط الضعف: في عدد التكرارات — بطيء عندما
- متى تستخدمه: إذا كان الاختبار الرجعي الواحد مكلفاً (دقائق) والميزانية محدودة بـ 100-200 تكرار
RandomSampler (خط الأساس)
sampler = optuna.samplers.RandomSampler(seed=42)
- المبدأ: أخذ عيّنات عشوائية منتظمة
- نقاط القوة: لا يعلق في الأمثل المحلية، تغطية كاملة للفضاء
- نقاط الضعف: لا يستخدم النتائج السابقة
- متى تستخدمه: كخط أساس للمقارنة، أو للتحليل الاستكشافي
QMCSampler
sampler = optuna.samplers.QMCSampler(seed=42)
- المبدأ: Quasi-Monte Carlo (متتابعات Sobol/Halton) — يملأ الفضاء بشكل أكثر انتظاماً من العيّنة العشوائية
- نقاط القوة: تغطية أفضل للفضاء من RandomSampler، قابلية إعادة الإنتاج
- نقاط الضعف: لا يتكيف مع النتائج
- متى تستخدمه: لأول 50-100 تكرار قبل التحول إلى TPE
جدول ملخص
| العيّنة | النوع | التفاعلات | فئوي | أفضل ميزانية |
|---|---|---|---|---|
| TPE | Bayesian | جزئي | نعم | 100-1000 |
| CmaEs | تطوري | نعم | لا | 200-2000 |
| GP | Bayesian | نعم | محدود | 50-200 |
| Random | عشوائي | لا | نعم | أي (خط أساس) |
| QMC | شبه عشوائي | لا | لا | 50-500 |
معيار قياس عملي
import optuna
import time
def benchmark_sampler(sampler, n_trials=300):
"""Compare samplers on the same task."""
study = optuna.create_study(sampler=sampler, direction="minimize")
start = time.time()
study.optimize(objective, n_trials=n_trials, show_progress_bar=False)
elapsed = time.time() - start
return {
"best_value": -study.best_value,
"elapsed_sec": elapsed,
"best_trial": study.best_trial.number,
}
samplers = {
"TPE": optuna.samplers.TPESampler(seed=42),
"CmaEs": optuna.samplers.CmaEsSampler(seed=42),
"GP": optuna.samplers.GPSampler(seed=42),
"Random": optuna.samplers.RandomSampler(seed=42),
"QMC": optuna.samplers.QMCSampler(seed=42),
}
for name, sampler in samplers.items():
result = benchmark_sampler(sampler, n_trials=300)
print(f"{name:8s}: best PnL={result['best_value']:.2f}%, "
f"found at trial #{result['best_trial']}, "
f"time={result['elapsed_sec']:.1f}s")
نتائج نموذجية لاستراتيجية بـ 12 معاملاً:
| العيّنة | أفضل PnL | عُثر عليه في التكرار | حمل العيّنة الإضافي |
|---|---|---|---|
| TPE | ~51% | ~180 | منخفض |
| CmaEs | ~49% | ~250 | متوسط |
| GP | ~48% | ~90 | مرتفع عند |
| Random | ~42% | ~270 | أدنى |
| QMC | ~43% | ~200 | أدنى |
يتفوق TPE وCmaEs باستمرار على البحث العشوائي بنسبة 15-20% في PnL النهائي. يجد GP نتائج جيدة مبكراً لكنه يصطدم بسقف حسابي مع عدد كبير من التكرارات.
التحسين متعدد الأهداف: PnL مقابل MaxDD
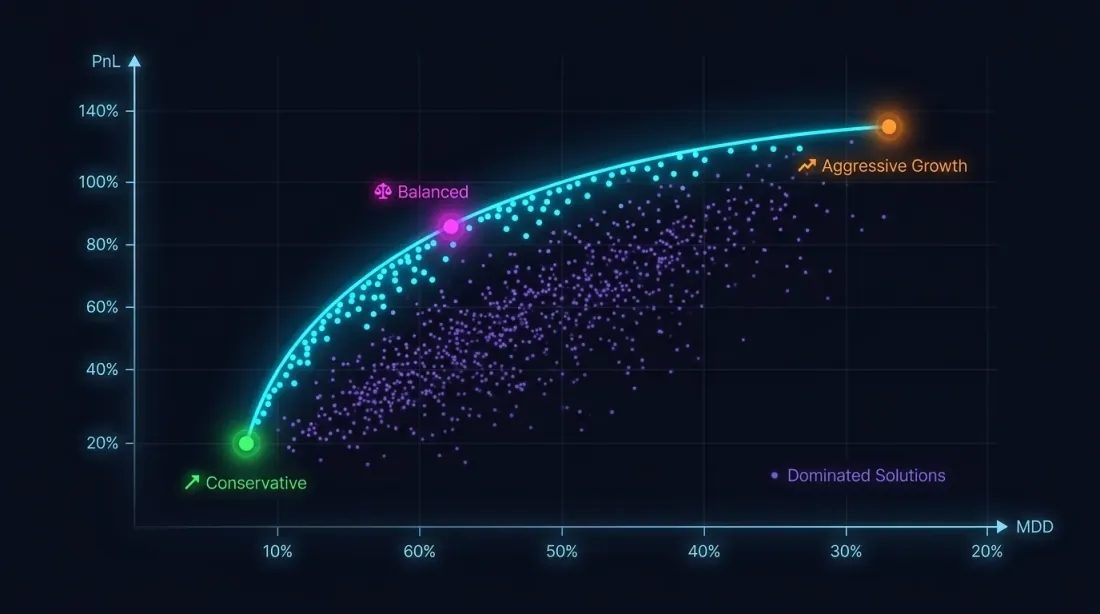
لماذا معيار واحد لا يكفي
تعظيم PnL بدون قيود على التراجع هو طريق نحو الكارثة. استراتيجية بـ PnL +80% وMaxDD -30% هي، بسبب عدم تماثل الخسارة والربح، أكثر خطورة بكثير من استراتيجية بـ PnL +50% وMaxDD -5%.
مسألة التحسين هي في الواقع متعددة الأهداف:
هذه الأهداف متعارضة: المعاملات العدوانية تزيد كلاً من PnL والتراجع. الحل ليس نقطة واحدة، بل جبهة Pareto: مجموعة من الحلول حيث لا يمكنك تحسين مقياس واحد دون إساءة الآخر.
NSGA-II / NSGA-III في Optuna
import optuna
def multi_objective(trial: optuna.Trial) -> tuple[float, float]:
"""Multi-objective function: (PnL, MaxDD)."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
pnl = result["pnl"] # maximize
max_dd = result["max_dd"] # minimize (already a negative number)
return pnl, max_dd # Optuna: both directions are set in create_study
study = optuna.create_study(
directions=["maximize", "minimize"],
sampler=optuna.samplers.NSGAIIISampler(seed=42),
study_name="multi_objective_strategy",
)
study.optimize(multi_objective, n_trials=500)
pareto_trials = study.best_trials
print(f"Pareto front: {len(pareto_trials)} solutions")
for t in pareto_trials[:5]:
print(f" PnL={t.values[0]:.2f}%, MaxDD={t.values[1]:.2f}%")
اختيار نقطة على جبهة Pareto
تقدم جبهة Pareto حلولاً متعددة. كيف تختار واحداً؟
def select_from_pareto(
pareto_trials: list,
max_dd_limit: float = -5.0,
min_pnl: float = 20.0,
) -> list:
"""
Filter the Pareto front by constraints.
max_dd_limit: maximum acceptable drawdown (e.g., -5%)
min_pnl: minimum acceptable PnL (%)
"""
filtered = []
for trial in pareto_trials:
pnl, max_dd = trial.values
if max_dd >= max_dd_limit and pnl >= min_pnl:
max_lev = min(50 / abs(max_dd), 100) if max_dd != 0 else 100
pnl_at_max_lev = pnl * max_lev
filtered.append({
"trial": trial,
"pnl": pnl,
"max_dd": max_dd,
"max_lev": max_lev,
"pnl_at_max_lev": pnl_at_max_lev,
})
filtered.sort(key=lambda x: x["pnl_at_max_lev"], reverse=True)
return filtered
ملاحظة: عند حساب PnL بأقصى رافعة مالية، يجب مراعاة معدلات التمويل، وإلا فإن الرافعة المالية العالية نظرياً ستتحول إلى خسارة في السوق الحقيقي. بالإضافة إلى ذلك، PnL النهائي هو تقدير نقطة واحدة، ولتقييم استقرار النتيجة تحتاج إلى محاكاة مونت كارلو بالتمهيد.
مثال: ثلاث استراتيجيات على جبهة Pareto
| الاستراتيجية | PnL | MaxDD | MaxLev | PnL@MaxLev | وقت التداول |
|---|---|---|---|---|---|
| الاستراتيجية أ | ~55% | ~0.9% | ~55x | ~3025% | ~15% |
| الاستراتيجية ب | ~25% | ~0.75% | ~66x | ~1650% | ~5% |
| الاستراتيجية ج | ~300% | ~17% | ~3x | ~900% | ~45% |
الاستراتيجية ج ذات PnL المثير للإعجاب بنسبة +300% تتبين أنها الأقل جاذبية بمقياس PnL@MaxLev بسبب التراجع العالي. الاستراتيجية أ تتصدر في صافي العائد بالرافعة، لكن عند مراعاة PnL لكل وقت نشط، قد تكون الاستراتيجية ب أفضل — 95% من الوقت الحر يمكن ملؤه باستراتيجيات أخرى.
رسوم الخطوط الكنتورية وأهمية المعاملات

تصوير المشهد
بعد التحسين — التصوير. يوفر Optuna أدوات مدمجة:
import optuna.visualization as vis
fig_contour = vis.plot_contour(
study,
params=["htf_entry_sell", "mtf_entry_sell"],
)
fig_contour.show()
fig_importance = vis.plot_param_importances(study)
fig_importance.show()
fig_history = vis.plot_optimization_history(study)
fig_history.show()
fig_parallel = vis.plot_parallel_coordinate(
study,
params=["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell"],
)
fig_parallel.show()
fig_slice = vis.plot_slice(study)
fig_slice.show()
رسم الخطوط الكنتورية: قراءة التفاعلات
يبني رسم الخطوط الكنتورية مقطعاً ثنائي الأبعاد لدالة الهدف لزوج من المعاملات. إذا كانت خطوط التساوي موازية لأحد المحاور — فالمعاملات لا تتفاعل، وكان OAT سيجد نفس الأمثل. إذا كانت خطوط التساوي قطرية — فهناك تفاعل، وسيفوّته OAT.
key_params = ["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell",
"htf_entry_buy", "mtf_entry_buy", "ltf_entry_buy"]
for i, p1 in enumerate(key_params):
for p2 in key_params[i+1:]:
fig = vis.plot_contour(study, params=[p1, p2])
fig.write_image(f"contour_{p1}_vs_{p2}.png")
إذا أظهر رسم الخطوط الكنتورية هضبة — منطقة تتغير فيها دالة الهدف قليلاً — فهذه علامة جيدة. الهضبة تعني أن النتيجة متينة تجاه الانحرافات الصغيرة في المعاملات. المزيد عن تحليل الهضبة وعلاقته بالإفراط في التخصيص — في المقالة القادمة تحليل الهضبة.
أهمية المعاملات
importance = optuna.importance.get_param_importances(study)
for param, imp in importance.items():
print(f"{param:20s}: {imp:.4f}")
ناتج نموذجي:
htf_entry_sell : 0.2841
mtf_entry_sell : 0.2103
ltf_entry_sell : 0.1567
trail_pct : 0.1204
htf_entry_buy : 0.0892
...
المعاملات ذات الأهمية أقل من 0.01 يمكن تثبيتها عند قيمتها الافتراضية — مما يقلل أبعاد المسألة ويسرّع التحسين. لكن كن حذراً: قد تعني الأهمية المنخفضة أيضاً أن المعامل مهم فقط في تفاعله مع الآخرين. تحقق عبر رسوم الخطوط الكنتورية.
ذاكرة التخزين المؤقت المحسوبة مسبقاً: لماذا ثانية واحدة لكل اختبار رجعي تغيّر كل شيء
سرعة الاختبار الرجعي الواحد تحدد أي طريقة تحسين يمكنك تحمّلها.
| وقت الاختبار الرجعي | 96 OAT | 500 TPE | 2000 CmaEs |
|---|---|---|---|
| 60 ثانية | 1.6 ساعة | 8.3 ساعات | 33 ساعة |
| 10 ثوانٍ | 16 دقيقة | 83 دقيقة | 5.5 ساعات |
| 1 ثانية | 1.5 دقيقة | 8 دقائق | 33 دقيقة |
| 0.1 ثانية | 10 ثوانٍ | 50 ثانية | 3.3 دقائق |
عند 60 ثانية لكل اختبار رجعي، 500 تكرار TPE تستغرق 8 ساعات. مقبول بالفعل، لكن التكرار (تغيير دالة الهدف، إعادة التشغيل) مكلف. عند ثانية واحدة — 8 دقائق، ويمكنك تشغيل عشرات التجارب يومياً.
هذا هو بالضبط السبب في أن الحساب المسبق في ذاكرة التخزين المؤقت Parquet ليس مجرد تسريع، بل توسيع لفضاء الأساليب المتاحة. بدون ذاكرة التخزين المؤقت أنت مقيد بـ OAT أو 100 تكرار GP. مع ذاكرة التخزين المؤقت — يمكنك تحمّل 2000 تكرار CmaEs أو NSGA-III متعدد الأهداف بالكامل.
import pyarrow.parquet as pq
import time
t0 = time.time()
htf_pre = pq.read_table("cache/htf_indicators.parquet").to_pandas()
mtf_pre = pq.read_table("cache/mtf_indicators.parquet").to_pandas()
ltf_pre = pq.read_table("cache/ltf_indicators.parquet").to_pandas()
print(f"Cache loaded in {time.time() - t0:.2f}s") # ~0.3s
t1 = time.time()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, htf_entry_sell=0.02, ...)
print(f"Backtest in {time.time() - t1:.2f}s") # ~1.0s
توصيات عملية
متى تستخدم OAT
يكون OAT مبرراً في الحالات التالية:
-
التحليل الاستكشافي. بدأت للتو في استكشاف استراتيجية وتريد فهم أي المعاملات تؤثر على النتيجة أصلاً. 96 تشغيلة في 1.5 دقيقة — نقطة انطلاق ممتازة.
-
المعاملات الجمعية. للمعاملات التي تعمل على مجموعات فرعية غير متداخلة من الصفقات (اتجاه البيع مقابل الشراء، أدوات مختلفة)، سيعطي OAT نتيجة صحيحة أسرع.
-
اختبار رجعي مكلف جداً. إذا استغرقت التشغيلة الواحدة أكثر من 10 دقائق ولا يمكن تسريعها، فإن OAT بـ 96 تشغيلة (16 ساعة) أفضل من 500 تكرار TPE (3.5 أيام).
متى تستخدم Optuna
Optuna مفضّل في معظم الحالات:
-
أكثر من 3 معاملات. التفاعلات مضمونة عملياً — وسيفوّت OAT الأمثل.
-
استراتيجيات متعددة الأطر الزمنية. عتبات الأطر الزمنية المختلفة مترابطة دائماً تقريباً.
-
التحسين النهائي. عندما تجتاز الاستراتيجية محاكاة مونت كارلو بالتمهيد وأنت واثق من متانتها — سيجد Optuna أفضل المعاملات.
-
المسائل متعددة الأهداف. PnL مقابل MaxDD مقابل وقت التداول — لا يستطيع OAT حل هذه المسألة من حيث المبدأ.
المنهج الهجين: OAT للجمعية + Optuna للمترابطة
لا يتعين عليك الاختيار بين OAT وOptuna — من الأفضل الجمع بينهما:
-
صنّف المعاملات. قسّمها إلى جمعية (مستقلة) ومترابطة (تفاعلية). مثال لـ 12 معامل فصل:
- جمعية:
htf_entry_sell<->htf_entry_buy،mtf_entry_sell<->mtf_entry_buy،ltf_entry_sell<->ltf_entry_buy(بيع/شراء — اتجاهات مختلفة، تعمل على صفقات غير متداخلة) - مجموعة مترابطة sell:
htf_entry_sell،mtf_entry_sell،ltf_entry_sell(سلسلة التصفية: HTF -> MTF -> LTF لإشارات البيع) - مجموعة مترابطة buy:
htf_entry_buy،mtf_entry_buy،ltf_entry_buy
- جمعية:
-
OAT للجمعية. حسّن مجموعتي البيع والشراء بشكل مستقل. إذا كانت معاملات البيع لا تؤثر على صفقات الشراء — سيعطي OAT نتيجة صحيحة في دقائق.
-
Optuna للمترابطة. داخل كل مجموعة (sell: 6 معاملات entry+exit) استخدم TPE. 6 معاملات بدلاً من 12 — الميزانية تنخفض إلى النصف.
sell_params = oat_sweep(sell_param_grid, run_backtest, initial_params)
def objective_sell(trial):
params = sell_params.copy()
params["htf_entry_sell"] = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
params["mtf_entry_sell"] = trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005)
params["ltf_entry_sell"] = trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005)
params["htf_exit_sell"] = trial.suggest_float("htf_exit_sell", 0.0, 0.02, step=0.001)
params["mtf_exit_sell"] = trial.suggest_float("mtf_exit_sell", 0.0, 0.02, step=0.001)
params["ltf_exit_sell"] = trial.suggest_float("ltf_exit_sell", 0.0, 0.02, step=0.001)
return -run_backtest(**params)["effective_score"]
study = optuna.create_study(sampler=optuna.samplers.TPESampler())
study.optimize(objective_sell, n_trials=300) # 6 parameters → 300 is enough
خط أنابيب التحسين الكامل
1. حساب مسبق لذاكرة التخزين المؤقت Parquet (مرة واحدة)
2. تصنيف المعاملات: جمعية مقابل مترابطة
3. OAT للجمعية (~50 تشغيلة، ~1 دقيقة) → تثبيت
4. Optuna TPE للمجموعات المترابطة (300 تكرار × مجموعتين، ~10 دقائق)
5. Optuna NSGA-III للمعاملات الفوقية (500 تكرار، ~8 دقائق) → جبهة Pareto
6. رسوم الخطوط الكنتورية → تصوير التفاعلات
7. محاكاة مونت كارلو بالتمهيد لأفضل النقاط → فترات الثقة
8. Walk-Forward → التحقق خارج العيّنة
الخطوة 8 — تحسين Walk-Forward — حاسمة للحماية من الإفراط في التخصيص. المزيد عن هذا في المقالة القادمة Walk-Forward.
مزالق التحسين
الإفراط في التخصيص. كلما زادت المعاملات وكان التحسين أكثر دقة — ارتفع خطر تكييف الاستراتيجية على البيانات التاريخية. 500 تكرار Optuna مع 12 معاملاً ستجد تركيبة تعمل بشكل مثالي على مجموعة التدريب، لكنها عديمة الفائدة على بيانات جديدة.
الحماية:
- قسّم البيانات إلى تدريب/اختبار (70/30)
- استخدم محاكاة مونت كارلو بالتمهيد لتقييم الاستقرار
- تحقق عبر Walk-Forward
- فضّل الحلول على الهضاب (المزيد في تحليل الهضبة)
مسألة المقارنات المتعددة. إذا اختبرت 500 تركيبة، تنمو احتمالية إيجاد نتيجة "جيدة" بالصدفة. يساعد تصحيح Bonferroni أو التحكم بـ FDR (معدل الاكتشاف الزائف)، لكن المنهج الأبسط هو التحقق خارج العيّنة.
ميزانية غير كافية. TPE بـ 50 تكراراً لـ 12 معاملاً قليل جداً. أول 20 تكراراً عشوائية (بدء التشغيل)، مما يترك 30 فقط للنمذجة. الحد الأدنى للميزانية: تكراراً لـ 12 معاملاً، والموصى به: .
Freqtrade: كيف يعمل في إطار عمل إنتاجي

Freqtrade — أحد أطر التداول الخوارزمي الشائعة — يستخدم Optuna تحت الغطاء من خلال وحدة Hyperopt. تجربته تؤكد توصياتنا:
- العيّنات: TPE (افتراضي)، GP، CmaEs، NSGA-II، QMC — جميعها متاحة عبر الإعدادات
- دوال الخسارة: 12 دالة خسارة مدمجة، بما فيها ShortTradeDurHyperOptLoss، SharpeHyperOptLoss، MaxDrawDownHyperOptLoss
- متعدد الأهداف: دعم NSGA-II وNSGA-III للتحسين المتزامن لمقاييس متعددة
- عيّنات مخصصة: إمكانية توصيل أي عيّنة متوافقة مع Optuna
درس رئيسي من منظومة Freqtrade: دوال الخسارة المدمجة تغطي السيناريوهات النموذجية، لكن للتحسين الجاد تحتاج إلى دالة هدف مخصصة تراعي خصوصيات استراتيجيتك — الوقت النشط، وتكاليف التمويل، والتعمق التكيفي من أجل محاكاة دقيقة للتنفيذ.
الخلاصة

النزول الإحداثي (OAT) طريقة سريعة وبديهية. لـ 12 معاملاً يتطلب 96 تشغيلة فقط وينتهي في دقيقة ونصف. لكنه أعمى تجاه تفاعلات المعاملات — وفي الاستراتيجيات متعددة الأطر الزمنية، التفاعلات موجودة دائماً تقريباً.
التحسين البايزي عبر Optuna (TPE، GP، CmaEs) يستكشف فضاء المعاملات ككل. 500 تكرار في 8 دقائق — مع ذاكرة التخزين المؤقت Parquet المحسوبة مسبقاً — يجد تركيبات غير مرئية لـ OAT.
التحسين متعدد الأهداف (NSGA-III) يحوّل مسألة "تعظيم PnL" إلى مسألة "بناء جبهة Pareto لـ PnL مقابل MaxDD" — ويوفر مجموعة حلول بمفاضلات مختلفة بين المخاطرة والعائد.
لكن التحسين ليس سوى جزء من خط الأنابيب. المعاملات التي تم إيجادها تحتاج إلى التحقق عبر محاكاة مونت كارلو بالتمهيد، وتصحيحها لـمعدلات التمويل، وإعادة حسابها مع مراعاة الوقت النشط، وتشغيلها عبر تحقق Walk-Forward. المزيد عن ذلك في المقالات القادمة من السلسلة.
روابط مفيدة
- Optuna: A Next-generation Hyperparameter Optimization Framework (Akiba et al., 2019)
- Algorithms for Hyper-Parameter Optimization (Bergstra et al., 2011) — the original TPE paper
- Optuna Documentation — Samplers
- Optuna Visualization Module
- Hansen, N. — The CMA Evolution Strategy: A Tutorial
- Deb, K. et al. — NSGA-II: A Fast and Elitist Multiobjective Genetic Algorithm (2002)
- Snoek, J. et al. — Practical Bayesian Optimization of Machine Learning Algorithms (2012)
- Freqtrade Documentation — Hyperopt
- Marcos Lopez de Prado — Advances in Financial Machine Learning, Chapter 12
- Bergstra, J. & Bengio, Y. — Random Search for Hyper-Parameter Optimization (2012)
Citation
@article{soloviov2026optuna,
author = {Soloviov, Eugen},
title = {Coordinate Descent vs Bayesian Optimization: Which Finds Better Parameters},
year = {2026},
url = {https://marketmaker.cc/en/blog/post/optuna-vs-coordinate-descent},
description = {Why exhaustive search is impossible for 12+ parameters, how coordinate descent misses interactions, and how Optuna with a TPE sampler finds in 500 iterations what OAT cannot find in 96.}
}
MarketMaker.cc Team
البحوث والاستراتيجيات الكمية
Read More

الحفر التكيفي: اختبار رجعي بدقة متغيرة من الدقائق إلى الصفقات الخام

ذاكرة التخزين المؤقت المجمعة لـ Parquet: كيف تُسرّع الاختبارات الرجعية متعددة الأُطُر الزمنية بمئات المرات
