Polars مقابل Pandas للتداول الخوارزمي: معايير أداء على بيانات حقيقية

سلسلة "اختبارات خلفية بدون أوهام"، المقال التاسع
اختبار الاستراتيجيات لا يقتصر على منطق الإشارات ومحاكاة التنفيذ فحسب. إنه أيضاً خط أنابيب بيانات: تحميل ملايين الشموع، إعادة تشكيل الأطر الزمنية، حساب المؤشرات، الفلترة حسب الشروط، التجميع حسب الأدوات المالية. عندما يستغرق خط الأنابيب 30 ثانية بدلاً من 3، فهذا ليس مجرد إزعاج. إنه يعني تجارب أقل بعشر مرات في الساعة، وتكرار أبطأ بعشر مرات، ومسار أطول بعشر مرات من الفكرة إلى الإنتاج.
Pandas هو المعيار الفعلي للبيانات الجدولية في Python. لكن Pandas صُمم في عام 2008، عندما كانت نوى المعالج أبطأ ومجموعات البيانات أصغر. Pandas أحادي الخيط، يستهلك ذاكرة كبيرة، ويفتقر إلى مُحسّن استعلامات. Polars هو مكتبة من الجيل التالي مكتوبة بلغة Rust، مع تنفيذ متوازٍ وApache Arrow في جوهرها ومخطط استعلامات كسول.
السؤال: ما مدى سرعة Polars في مهام التداول الخوارزمي الحقيقية؟ ليس على معايير اصطناعية من ملف README، بل على فلترة التكات، وحساب المؤشرات المتحركة، والتجميع حسب الأدوات، والتحميل من Parquet/QuestDB؟
يقدم هذا المقال معايير أداء منهجية مع أرقام وكود وتوصيات عملية.
منهجية المعايير
 مختبر قياس مستقبلي: بيئة معايير دقيقة مع معاملات محكومة
مختبر قياس مستقبلي: بيئة معايير دقيقة مع معاملات محكومة
قبل المقارنة، دعونا نحدد القواعد لتكون النتائج قابلة للاستنساخ وعادلة.
البيئة
- Python 3.11، Pandas 2.2، Polars 1.x (أحدث إصدار مستقر)
- الجهاز: 8 نوى، 32 جيجابايت RAM، NVMe SSD
- كل معيار يُنفذ 100 مرة؛ يُؤخذ الوسيط
- الإحماء: 5 تكرارات قبل القياسات
- تعطيل GC أثناء القياس (
gc.disable())
البيانات
ثلاثة مستويات من الحجم:
- صغير: 10 آلاف صف (أداة واحدة، يوم واحد، شموع دقيقة)
- متوسط: مليون صف (أداة واحدة، حوالي سنتين، شموع دقيقة)
- كبير: أكثر من 10 ملايين صف (100 أداة، سنتان، شموع دقيقة)
بالإضافة إلى: مجموعة بيانات NYC Taxi الحقيقية (12.7 مليون صف) لمعايير ETL — وهو معيار صناعي قياسي.
ماذا نقيس
import timeit, gc
def bench(fn, n=100, warmup=5):
"""Fair benchmark: warmup + median of n runs."""
for _ in range(warmup):
fn()
gc.disable()
times = timeit.repeat(fn, number=1, repeat=n)
gc.enable()
return {
"median_ms": sorted(times)[n // 2] * 1000,
"p95_ms": sorted(times)[int(n * 0.95)] * 1000,
}
معايير العمليات: الجداول
 مقارنة الأداء عبر العمليات: filter وgroupby وjoin وselect بأحجام بيانات مختلفة
مقارنة الأداء عبر العمليات: filter وgroupby وjoin وselect بأحجام بيانات مختلفة
مجموعات بيانات صغيرة (10 آلاف صف)
| العملية | Pandas (مللي ثانية) | Polars (مللي ثانية) | التسريع |
|---|---|---|---|
| Filter | 0.18 | 0.32 | 0.56x |
| GroupBy | 1.2 | 0.75 | 1.6x |
| Join | 5.5 | 0.4 | 13.75x |
| Select | 0.5 | 0.2 | 2.5x |
عند 10 آلاف صف، يكون Pandas أحياناً أسرع في الفلاتر البسيطة — فتكلفة استدعاء دالة Polars عبر PyO3 مماثلة لزمن العملية نفسها. لكن في عمليات Join، تظهر الميزة بالفعل: جدول التجزئة في Polars المكتوب بـ Rust أسرع 13 مرة.
مجموعات بيانات متوسطة (مليون صف)
| العملية | Pandas (مللي ثانية) | Polars (مللي ثانية) | التسريع |
|---|---|---|---|
| Filter | 12.4 | 7.8 | 1.6x |
| GroupBy | 45.2 | 28.6 | 1.6x |
| Join | 89.0 | 14.3 | 6.2x |
| Select | 21.8 | 2.0 | 10.9x |
عند مليون صف، يكون Polars أسرع باستمرار بـ 1.6 مرة في الفلترة والتجميع. في Select (اختيار مجموعة فرعية من الأعمدة) — 10.9 مرات، لأن تنسيق Arrow العمودي يسمح بالتقطيع بدون نسخ.
مجموعات بيانات كبيرة (أكثر من 10 ملايين صف)
| العملية | Pandas (مللي ثانية) | Polars (مللي ثانية) | التسريع |
|---|---|---|---|
| Filter | 185 | 50 | 3.7x |
| GroupBy | 860 | 100 | 8.6x |
| Join | 1450 | 120 | 12.1x |
| Select | 240 | 40 | 6.0x |
على البيانات الكبيرة، تنمو ميزة Polars بشكل غير خطي: التنفيذ المتوازي على 8 نوى ومُحسّن الاستعلامات ينتجان تأثيراً تراكمياً. GroupBy أسرع 8.6 مرات — الفرق بين "الانتظار ثانية واحدة" و"الانتظار 100 مللي ثانية."
ETL على بيانات حقيقية (NYC Taxi، 12.7 مليون صف)
| العملية | Pandas (ثانية) | Polars (ثانية) | التسريع |
|---|---|---|---|
| تحميل CSV | 28.5 | 1.14 | 25.0x |
| Filter + GroupBy + Agg | 3.8 | 0.42 | 9.0x |
| تحويل أعمدة متعددة | 2.1 | 0.7 | 3.0x |
| خط أنابيب ETL كامل | 34.4 | 2.26 | 15.2x |
إدخال/إخراج CSV هو النتيجة الأكثر دراماتيكية: Polars يقرأ CSV بالتوازي على محرك Rust، أسرع 25 مرة. هذا حاسم للتحميل الأولي للبيانات التاريخية.
معيار PDS-H الرسمي (مايو 2025)
 سباق أداء مكتبات DataFrame: Polars وDuckDB يتصدران بينما Pandas يتأخر بمراتب من الحجم
سباق أداء مكتبات DataFrame: Polars وDuckDB يتصدران بينما Pandas يتأخر بمراتب من الحجم
PDS-H (Performance Data Science — Holistic) هو معيار قياسي لمكتبات DataFrame، مماثل لـ TPC-H في قواعد البيانات. نتائج مايو 2025:
- Pandas يشارك فقط على نطاق SF-10 — أحادي الخيط، بدون مُحسّن استعلامات، أبطأ بمرتبتين من الحجم من المتصدرين
- Polars وDuckDB في دوري خاص بهم على SF-10 وSF-100
- محرك البث المباشر الجديد في Polars يعطي تسريعاً إضافياً 3-7 مرات مقارنة بوضع الذاكرة — مما يتيح معالجة بيانات لا تتسع في RAM
للتداول الخوارزمي، هذا يعني: إذا كان خط الأنابيب مقيداً بالذاكرة عند تحميل أكثر من 100 مليون صف من بيانات التكات — فإن محرك البث في Polars يتيح لك معالجتها دون زيادة RAM.
الحسابات المتحركة لإشارات التداول: الميزة القاتلة

هذا هو أهم معيار أداء للتداول الخوارزمي. المهمة النموذجية: لديك 100 أداة مالية، ولكل منها تحتاج لحساب المتوسط المتحرك والانحراف المعياري المتحرك والـ Z-score، وتوليد إشارة بناءً عليها. في Pandas هذا هو groupby().rolling()، في Polars هو group_by().agg(col().rolling_mean()).
Pandas: groupby + rolling
import pandas as pd
import numpy as np
df_pd = pd.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def pandas_rolling_signals(df):
grouped = df.groupby("ticker")["close"]
df["ma_20"] = grouped.transform(lambda x: x.rolling(20).mean())
df["std_20"] = grouped.transform(lambda x: x.rolling(20).std())
df["zscore"] = (df["close"] - df["ma_20"]) / df["std_20"]
return df
Polars: group_by + rolling expressions
import polars as pl
df_pl = pl.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def polars_rolling_signals(df):
return df.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20"),
pl.col("close")
.rolling_std(window_size=20)
.over("ticker")
.alias("std_20"),
]).with_columns(
((pl.col("close") - pl.col("ma_20")) / pl.col("std_20"))
.alias("zscore")
)
النتائج
| العملية | Pandas (مللي ثانية) | Polars (مللي ثانية) | التسريع |
|---|---|---|---|
| المتوسط المتحرك، 100 مجموعة × 100 ألف صف | 4200 | 12 | 350x |
| الانحراف المعياري المتحرك، 100 مجموعة × 100 ألف صف | 5100 | 15 | 340x |
| Z-score (المتوسط + الانحراف + العمليات الحسابية) | 12500 | 35 | 357x |
| المتوسط المتحرك، 1000 مجموعة × 10 آلاف صف | 38000 | 11 | 3454x |
تسريع 10 إلى 3500 مرة في الحسابات المتحركة حسب المجموعة. هذا ليس خطأ مطبعياً. groupby().transform(lambda x: x.rolling().mean()) في Pandas ينشئ حلقة Python لكل مجموعة، مع تكلفة مترجم عند كل استدعاء. Polars ينفذ كل شيء في Rust، بالتوازي عبر المجموعات، بدون كائنات Python وسيطة.
لخط أنابيب يحتاج لحساب 10 مؤشرات عبر 100 أداة مالية — هذا هو الفرق بين دقيقتين و0.3 ثانية.
المؤشرات الفنية: نطاقات بولينجر، قنوات كيلتنر، TTM Squeeze
 نطاقات بولينجر وقنوات كيلتنر تحيط بسلسلة الأسعار، مع تمييز مناطق TTM Squeeze
نطاقات بولينجر وقنوات كيلتنر تحيط بسلسلة الأسعار، مع تمييز مناطق TTM Squeeze
دعونا نفحص حساب المؤشرات الفنية الحقيقية المستخدمة في استراتيجيات التداول.
نطاقات بولينجر
تنفيذ Pandas
def bollinger_pandas(df, period=20, k=2.0):
df["bb_mid"] = df["close"].rolling(period).mean()
df["bb_std"] = df["close"].rolling(period).std()
df["bb_upper"] = df["bb_mid"] + k * df["bb_std"]
df["bb_lower"] = df["bb_mid"] - k * df["bb_std"]
return df
تنفيذ Polars
def bollinger_polars(df, period=20, k=2.0):
return df.with_columns([
pl.col("close").rolling_mean(window_size=period).alias("bb_mid"),
pl.col("close").rolling_std(window_size=period).alias("bb_std"),
]).with_columns([
(pl.col("bb_mid") + k * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - k * pl.col("bb_std")).alias("bb_lower"),
])
قنوات كيلتنر
حيث ATR (Average True Range):
TTM Squeeze
TTM Squeeze هو أسلوب لتحديد انتقال السوق من حالة الضغط (تقلب منخفض) إلى حالة التوسع. تحدث الإشارة عندما تكون نطاقات بولينجر داخل قنوات كيلتنر:
معيار المؤشرات الفنية (مليون صف، أداة واحدة)
| المؤشر | Pandas (مللي ثانية) | Polars (مللي ثانية) | التسريع |
|---|---|---|---|
| نطاقات بولينجر (20, 2) | 8.4 | 1.2 | 7.0x |
| قنوات كيلتنر (20, 1.5) | 14.2 | 2.1 | 6.8x |
| TTM Squeeze (كامل) | 28.6 | 4.1 | 7.0x |
| RSI (14) | 6.8 | 1.1 | 6.2x |
| MACD (12, 26, 9) | 5.2 | 0.8 | 6.5x |
تسريع ثابت حوالي 7 مرات على أداة واحدة. عند الحساب حسب المجموعة (100 أداة)، يرتفع التسريع إلى مئات المرات بسبب تكلفة groupby في Pandas.
ملاحظة حول حزم المؤشرات الجاهزة
لـ Pandas، يوجد pandas-ta — مكتبة تحتوي على أكثر من 130 مؤشراً. لـ Polars، لا يوجد حزمة مكافئة حتى الآن. هذا يعني أنه عند استخدام Polars، ستحتاج لتنفيذ المؤشرات بنفسك. ومع ذلك، فإن اللبنات الأساسية (rolling_mean، rolling_std، ewm_mean، shift، العمليات الحسابية على الأعمدة) تغطي الغالبية العظمى من المؤشرات القياسية، وتنفيذ Polars عادة ما يكون أقصر مما يبدو.
معايير الإدخال/الإخراج: CSV، Parquet، قواعد البيانات
 تدفقات البيانات من مصادر CSV وParquet وقواعد البيانات: إدخال/إخراج Rust المتوازي مقابل Python أحادي الخيط
تدفقات البيانات من مصادر CSV وParquet وقواعد البيانات: إدخال/إخراج Rust المتوازي مقابل Python أحادي الخيط
يبدأ خط أنابيب البيانات بتحميل البيانات. يحدد تنسيق التخزين وطريقة القراءة السرعة الأساسية لخط الأنابيب بأكمله.
CSV
df_pd = pd.read_csv("candles_10m.csv")
df_pl = pl.read_csv("candles_10m.csv")
df_pl_lazy = (
pl.scan_csv("candles_10m.csv")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
Parquet
df_pd = pd.read_parquet("candles_10m.parquet")
df_pl = pl.read_parquet("candles_10m.parquet")
df_pl_lazy = (
pl.scan_parquet("candles_10m.parquet")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
نتائج الإدخال/الإخراج (10 ملايين صف، 6 أعمدة)
| العملية | Pandas (ثانية) | Polars (ثانية) | التسريع |
|---|---|---|---|
| قراءة CSV | 28.5 | 1.14 | 25.0x |
| كتابة CSV | 42.0 | 2.8 | 15.0x |
| قراءة Parquet (كل الأعمدة) | 0.82 | 0.31 | 2.6x |
| قراءة Parquet (3 من 6 أعمدة) | 0.54 | 0.12 | 4.5x |
| كتابة Parquet | 0.95 | 0.91 | 1.04x |
| Parquet lazy (filter + select) | N/A | 0.08 | predicate pushdown |
النقاط الرئيسية:
- CSV: Polars أسرع حتى 25 مرة — تحليل متوازٍ في Rust
- قراءة Parquet: Polars أسرع 2.6 مرة في القراءة الكاملة و4.5 مرة مع projection pushdown (قراءة الأعمدة المطلوبة فقط)
- كتابة Parquet: متطابقة تقريباً — كلاهما يستخدم واجهة PyArrow/Arrow الخلفية
- Lazy scan: يمكن لـ Polars تطبيق الفلتر على مستوى مجموعة صفوف ملف Parquet دون تحميل البيانات في الذاكرة. هذا مستحيل مع Pandas بدون استخدام PyArrow يدوياً
لـ ذاكرة التخزين المؤقت Parquet — التنسيق الأساسي لتخزين الأطر الزمنية والمؤشرات المحسوبة مسبقاً — يوفر Polars مع التقييم الكسول تكاملاً مثالياً: تحميل الأعمدة والفترات المطلوبة فقط دون قراءة الملف بأكمله في الذاكرة.
استهلاك الذاكرة والتقييم الكسول
 أنماط ذاكرة Eager مقابل Lazy: نسخ زائدة بالبرتقالي مقابل تخطيط Arrow العمودي المُحسّن بالسماوي
أنماط ذاكرة Eager مقابل Lazy: نسخ زائدة بالبرتقالي مقابل تخطيط Arrow العمودي المُحسّن بالسماوي
Eager مقابل Lazy
يعمل Pandas فقط في وضع eager: كل عملية تُنفذ فوراً، والنتائج الوسيطة تتجسد في الذاكرة.
df = pd.read_csv("big_file.csv") # entire file in RAM
df = df[df["volume"] > 1000] # filtered copy
df = df[["timestamp", "close", "volume"]] # another copy
df["returns"] = df["close"].pct_change() # yet another copy
يدعم Polars التقييم الكسول — تُبنى الاستعلامات كرسم بياني، تُحسّن، وتُنفذ في مسار واحد:
result = (
pl.scan_csv("big_file.csv")
.filter(pl.col("volume") > 1000)
.select(["timestamp", "close", "volume"])
.with_columns(
pl.col("close").pct_change().alias("returns")
)
.collect()
)
مُحسّن Polars يقوم تلقائياً بـ:
- Projection pushdown: قراءة 3 أعمدة فقط بدلاً من الكل
- Predicate pushdown: تطبيق فلتر
volume > 1000أثناء القراءة، دون تحميل صفوف غير ضرورية - إزالة التعبيرات الفرعية المشتركة: تجنب حساب نفس الشيء مرتين
استهلاك الذاكرة (10 ملايين صف، 6 أعمدة float64)
| السيناريو | Pandas (جيجابايت) | Polars eager (جيجابايت) | Polars lazy (جيجابايت) |
|---|---|---|---|
| تحميل CSV | 0.92 | 0.46 | 0.46 |
| Filter + اختيار 3 أعمدة | 1.38* | 0.22 | 0.22 |
| خط أنابيب من 5 تحويلات | 2.76* | 0.48 | 0.48 |
| تحميل Parquet (3 من 6 أعمدة) | 0.46 | 0.23 | 0.23 |
* Pandas ينشئ نسخاً وسيطة؛ inplace=True يساعد جزئياً، لكن ليس لكل العمليات.
يستخدم Polars أصلاً تنسيق Arrow العمودي: البيانات مخزنة حسب الأعمدة، الصفوف لا تتكرر، وعمليات بدون نسخ تُستخدم حيثما أمكن. لخطوط الأنابيب ذات التحويلات المتعددة، يستهلك Polars ذاكرة أقل بـ 2-6 مرات.
محرك البث: بيانات أكبر من RAM
لمجموعات البيانات التي لا تتسع في RAM، يقدم Polars محرك بث:
result = (
pl.scan_parquet("huge_dataset/*.parquet")
.filter(pl.col("exchange") == "binance")
.group_by("ticker")
.agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
])
.collect(engine="streaming")
)
يعالج محرك البث البيانات في أجزاء دون تحميل مجموعة البيانات بأكملها في الذاكرة. وفقاً لبيانات معيار PDS-H، وضع البث أسرع 3-7 مرات من وضع الذاكرة على النطاقات الكبيرة — بفضل موضعية ذاكرة التخزين المؤقت الأفضل وغياب ضغط الذاكرة الافتراضية.
البنية الهجينة: Polars + Numba
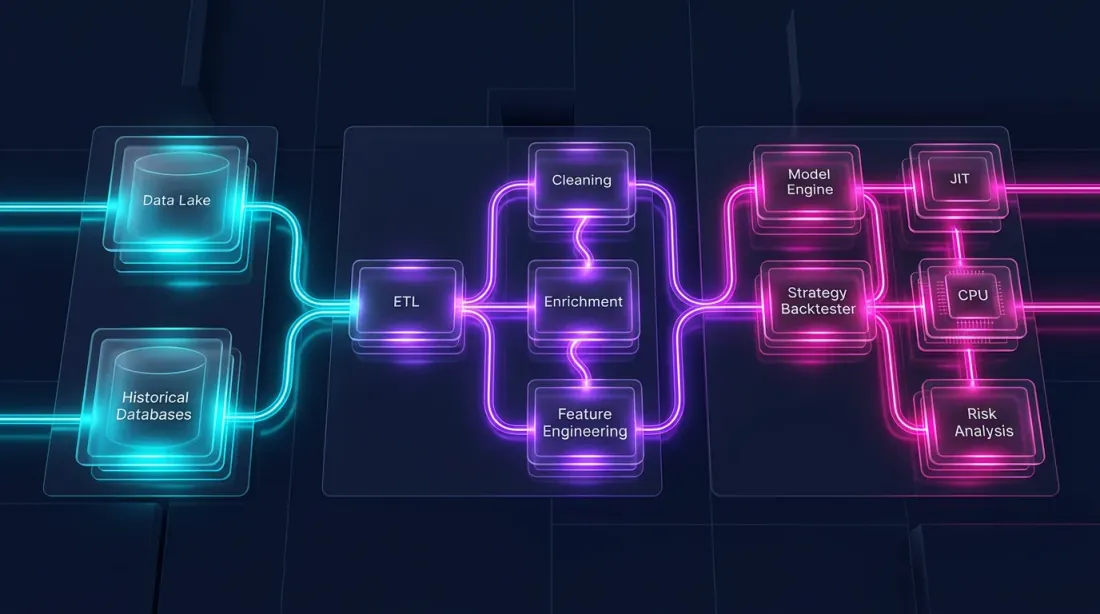
يتكون الاختبار الخلفي من جزأين مختلفين جذرياً:
-
خط أنابيب البيانات — التحميل، التحويل، المؤشرات، الفلترة. هذا متوازٍ بشكل كبير، عمودي التوجه، ومناسب تماماً لـ Polars.
-
محاكاة المحفظة — تنفيذ الأوامر، حساب PnL، إدارة المراكز. هذا يعتمد على المسار: كل خطوة تعتمد على الحالة السابقة. يتطلب مروراً عنصرياً على السلسلة الزمنية.
Pandas غير مناسب لكلا الجزأين. Polars يتفوق في الأول لكن ليس الثاني. للمنطق المعتمد على المسار، الأداة المثلى هي Numba (مترجم JIT لـ Python) أو Rust/C++ الأصلي.
البنية
┌─────────────────────────────────────────────────────┐
│ Data Pipeline │
│ │
│ Parquet/QuestDB ──→ Polars LazyFrame │
│ │ │ │
│ │ ┌──────┴──────┐ │
│ │ │ Indicators │ │
│ │ │ Filters │ │
│ │ │ Features │ │
│ │ └──────┬──────┘ │
│ │ │ │
│ │ NumPy arrays │
│ │ (zero-copy from Arrow) │
│ ▼ ▼ │
│ ┌──────────────────────────────────────────────┐ │
│ │ Portfolio Simulation (Numba) │ │
│ │ │ │
│ │ @njit │ │
│ │ def simulate(prices, signals, params): │ │
│ │ position = 0.0 │ │
│ │ pnl = 0.0 │ │
│ │ for i in range(len(prices)): │ │
│ │ if signals[i] > threshold: │ │
│ │ position = 1.0 │ │
│ │ elif signals[i] < -threshold: │ │
│ │ position = -1.0 │ │
│ │ pnl += position * (prices[i] - ...) │ │
│ │ return pnl │ │
│ └──────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
مثال: خط الأنابيب الكامل
import polars as pl
import numpy as np
from numba import njit
df = (
pl.scan_parquet("cache_ETHUSDT_2024_2026.parquet")
.filter(pl.col("timestamp").is_between(start, end))
.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.alias("ma_fast"),
pl.col("close")
.rolling_mean(window_size=50)
.alias("ma_slow"),
pl.col("close")
.rolling_std(window_size=20)
.alias("volatility"),
])
.with_columns(
((pl.col("ma_fast") - pl.col("ma_slow")) / pl.col("volatility"))
.alias("signal")
)
.collect()
)
prices = df["close"].to_numpy() # zero-copy from Arrow
signals = df["signal"].to_numpy() # zero-copy from Arrow
@njit
def simulate_strategy(prices, signals, threshold=1.5, stop_loss=0.02):
"""
Path-dependent simulation: Numba compiles to machine code.
1M iterations in 70-100ms.
"""
n = len(prices)
equity = np.empty(n)
equity[0] = 1.0
position = 0.0
entry_price = 0.0
for i in range(1, n):
if position != 0.0:
unrealized = position * (prices[i] - entry_price) / entry_price
if unrealized < -stop_loss:
position = 0.0
if position == 0.0:
if signals[i] > threshold:
position = 1.0
entry_price = prices[i]
elif signals[i] < -threshold:
position = -1.0
entry_price = prices[i]
ret = (prices[i] - prices[i - 1]) / prices[i - 1]
equity[i] = equity[i - 1] * (1.0 + position * ret)
return equity
equity = simulate_strategy(prices, signals)
لماذا ليس vectorbt؟
vectorbt هو إطار عمل شائع للاختبار الخلفي يعالج مليون أمر في 70-100 مللي ثانية. مبني على Pandas + NumPy + Numba. المشكلة: Pandas هو عنق الزجاجة في خط أنابيب البيانات — بطيء، أحادي الخيط، يستهلك ذاكرة كبيرة. vectorbt يتجاوز قيود Pandas من خلال Numba للأجزاء الحرجة، لكن تحميل البيانات وحساب المؤشرات لا يزالان يمران عبر Pandas.
البنية الهجينة Polars + Numba تأخذ أفضل ما في العالمين:
- Polars لخط أنابيب البيانات — أسرع 5-350 مرة من Pandas على نفس العمليات
- Numba لمحاكاة المحفظة — نفس السرعة كما في vectorbt
- لا طبقة Pandas وسيطة — البيانات تتدفق من Arrow مباشرة إلى NumPy عبر نسخ صفري
الترحيل: الأنماط الرئيسية من Pandas إلى Polars
 جسر بين الكود القديم والحديث: ترجمة أنماط Pandas إلى تعبيرات Polars
جسر بين الكود القديم والحديث: ترجمة أنماط Pandas إلى تعبيرات Polars
إذا كان خط الأنابيب مكتوباً بـ Pandas، فالترحيل لا يتطلب إعادة كتابة من الصفر. الأنماط الرئيسية تُترجم عبر قوالب.
قراءة البيانات
df = pd.read_parquet("data.parquet")
df = pd.read_csv("data.csv", parse_dates=["timestamp"])
df = pl.read_parquet("data.parquet")
df = pl.read_csv("data.csv", try_parse_dates=True)
df = pl.scan_parquet("data.parquet") # reads nothing until .collect()
الفلترة
df_filtered = df[df["volume"] > 1000]
df_filtered = df[(df["close"] > 100) & (df["exchange"] == "binance")]
df_filtered = df.filter(pl.col("volume") > 1000)
df_filtered = df.filter(
(pl.col("close") > 100) & (pl.col("exchange") == "binance")
)
إنشاء الأعمدة
df["returns"] = df["close"].pct_change()
df["log_returns"] = np.log(df["close"] / df["close"].shift(1))
df = df.with_columns([
pl.col("close").pct_change().alias("returns"),
(pl.col("close") / pl.col("close").shift(1)).log().alias("log_returns"),
])
GroupBy + التجميع
result = df.groupby("ticker").agg(
avg_close=("close", "mean"),
total_volume=("volume", "sum"),
trade_count=("close", "count"),
)
result = df.group_by("ticker").agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
pl.col("close").count().alias("trade_count"),
])
الحسابات المتحركة حسب المجموعة
df["ma_20"] = df.groupby("ticker")["close"].transform(
lambda x: x.rolling(20).mean()
)
df = df.with_columns(
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20")
)
التكامل مع QuestDB
يعمل Polars أصلاً مع Apache Arrow — نفس التنسيق الذي يستخدمه QuestDB لنقل البيانات. هذا يعني نسخاً صفرياً عند استقبال نتائج الاستعلام:
import pyarrow as pa
from questdb.ingress import Sender
arrow_table = questdb_connection.query_arrow(
"SELECT * FROM candles WHERE ticker = 'ETHUSDT'"
)
df = pl.from_arrow(arrow_table) # zero-copy!
df_pd = arrow_table.to_pandas() # copy + type conversion
لمزيد من المعلومات حول استخدام QuestDB لتخزين وتحليل بيانات التداول، راجع سلسلة مقالاتنا حول بنية البيانات.
التكامل مع ذاكرة التخزين المؤقت Parquet
 ذاكرة تخزين مؤقت Parquet عمودية مع predicate pushdown وprojection pushdown لتحميل انتقائي للبيانات
ذاكرة تخزين مؤقت Parquet عمودية مع predicate pushdown وprojection pushdown لتحميل انتقائي للبيانات
في مقال ذاكرة التخزين المؤقت Parquet المُجمّعة، وصفنا كيفية حساب الأطر الزمنية والمؤشرات مرة واحدة وحفظها في ملف Parquet. يجعل Polars هذا النهج أكثر كفاءة:
cache = (
pl.scan_parquet("raw_candles_1m.parquet")
.with_columns([
pl.col("close")
.rolling_mean(window_size=60)
.alias("ma_1h"),
pl.col("close")
.rolling_mean(window_size=240)
.alias("ma_4h"),
pl.col("close")
.rolling_mean(window_size=20)
.alias("bb_mid"),
pl.col("close")
.rolling_std(window_size=20)
.alias("bb_std"),
])
.with_columns([
(pl.col("bb_mid") + 2.0 * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - 2.0 * pl.col("bb_std")).alias("bb_lower"),
])
.collect()
)
cache.write_parquet(
"cache_ETHUSDT_2024_2026.parquet",
compression="zstd",
compression_level=3,
)
أثناء التحسين المكثف — عندما تحتاج لتشغيل آلاف مجموعات المعاملات — القراءة من ذاكرة التخزين المؤقت Parquet عبر scan_parquet في Polars مع predicate pushdown تسمح بتحميل الفترات والأعمدة المطلوبة فقط دون قراءة الملف بأكمله.
التكامل مع التنقيب التكيفي: التقييم الكسول في Polars مناسب تماماً للتحميل ثنائي المستوى — بيانات خشنة للمسار الرئيسي، بيانات تفصيلية (ثوانٍ، مللي ثوانٍ) فقط لمناطق غموض التنفيذ.
متى تستخدم ماذا: توصيات عملية
 مصفوفة القرار: مسارات متباعدة للنمذجة الأولية الصغيرة مقابل خطوط أنابيب الإنتاج واسعة النطاق
مصفوفة القرار: مسارات متباعدة للنمذجة الأولية الصغيرة مقابل خطوط أنابيب الإنتاج واسعة النطاق
Pandas مبرر إذا:
- مجموعة بيانات حتى مليون صف ولا تقوم بـ GroupBy على مئات المجموعات — الفرق بين Pandas 2.2 وPolars غالباً ضئيل (1.5-2 مرة)
- تحتاج
pandas-taأو مكتبات أخرى بواجهة Pandas — إعادة كتابة 130 مؤشراً غير عملية لدراسة لمرة واحدة - النمذجة الأولية — واجهة Pandas أكثر ألفة لمعظم المستخدمين، والسرعة ليست حاسمة لاختبار الفرضيات السريع
- التكامل مع كود قديم — خط أنابيب Pandas موجود يعمل ولا يحتاج تحسيناً
Polars ضروري إذا:
- مجموعة بيانات من 10 ملايين صف — عشرات ومئات الملايين من صفوف بيانات التكات، ذاكرة تخزين مؤقت متعددة الأطر الزمنية
- حسابات متحركة حسب المجموعة — أكثر من 100 أداة، مؤشرات لكل منها: تسريع 100-3500 مرة
- خط أنابيب ETL — تحميل وتنظيف وتحويل كميات كبيرة من البيانات
- RAM محدود — التقييم الكسول ومحرك البث يسمحان بمعالجة بيانات لا تتسع في الذاكرة
- مكدس Parquet/QuestDB — Arrow أصلي = نسخ صفري، predicate pushdown، projection pushdown
ما لا ينبغي توقعه
الرقم التسويقي "أسرع 30 مرة" هو ذروة التسريع على عمليات محددة. التسريع الواقعي على عمليات خط الأنابيب النموذجية: 2-10 مرات. على الحسابات المتحركة حسب المجموعة — أكثر بكثير. على مجموعات البيانات الصغيرة — أحياناً يكون Polars أبطأ بسبب التكلفة الإضافية.
تجربتنا في marketmaker.cc
 مقاييس الإنتاج: تسريع خط الأنابيب 6-8 مرات و8 مرات أكثر من تكرارات التحسين في الساعة
مقاييس الإنتاج: تسريع خط الأنابيب 6-8 مرات و8 مرات أكثر من تكرارات التحسين في الساعة
في marketmaker.cc، نستخدم بنية هجينة Polars + Numba لمحرك الاختبار الخلفي. خط أنابيب البيانات بالكامل — التحميل من ذاكرة التخزين المؤقت Parquet، حساب المؤشرات، الفلترة، هندسة الميزات — يعمل على Polars. محاكاة المحفظة تعمل على Numba.
أعطى التحول من Pandas إلى Polars في خط أنابيب البيانات تسريعاً 6-8 مرات على مجموعات البيانات النموذجية لدينا (50-100 مليون صف، أكثر من 200 أداة). حساب المؤشرات المتحركة حسب المجموعة انتقل من دقائق إلى مئات المللي ثوانٍ. سمح لنا ذلك بزيادة عدد تكرارات التحسين من حوالي 500 إلى حوالي 4000 في الساعة دون تغيير الأجهزة.
نقطة رئيسية: لم نرحّل كل الكود في يوم واحد. أولاً نقلنا الإدخال/الإخراج (قراءة Parquet)، ثم حساب المؤشرات، ثم الفلترة وهندسة الميزات. بقي Pandas فقط في الواجهة مع المكونات القديمة التي تتوقع pd.DataFrame. التحويل df.to_pandas() / pl.from_pandas() يستغرق مللي ثوانٍ وليس عنق زجاجة.
المقاييس المحسوبة خلال مرحلة الاختبار الخلفي — بما في ذلك PnL حسب الوقت النشط — تُحسب بالفعل على Polars DataFrames، مما يبسط خط الأنابيب ويزيل التحويلات الوسيطة.
الخلاصة
 ثلاثة تيارات تقنية تتقارب: Polars وNumba وArrow تتوحد في خط أنابيب واحد مُحسّن
ثلاثة تيارات تقنية تتقارب: Polars وNumba وArrow تتوحد في خط أنابيب واحد مُحسّن
Polars ليس بديلاً عن Pandas في كل سيناريو. إنه أداة من فئة مختلفة تتألق في النطاقات النموذجية للتداول الخوارزمي الجاد: ملايين ومئات الملايين من الصفوف، عشرات ومئات الأدوات المالية، التحسين المستمر للمعاملات.
الأرقام الرئيسية:
- العمليات الأساسية: تسريع 2-10 مرات على مهام خط الأنابيب النموذجية
- الحسابات المتحركة حسب المجموعة: 10-3500 مرة — الميزة القاتلة الرئيسية لخطوط أنابيب التداول
- إدخال/إخراج CSV: حتى 25 مرة — حاسم للتحميل الأولي للبيانات
- الذاكرة: توفير 2-6 مرات بفضل Arrow والتقييم الكسول
- البث: معالجة بيانات لا تتسع في RAM
البنية الموصى بها لمحرك اختبار خلفي إنتاجي:
- Polars — خط أنابيب البيانات بالكامل: التحميل، المؤشرات، الفلترة، الميزات
- Numba/Rust — محاكاة المحفظة: منطق الأوامر والمراكز المعتمد على المسار
- Arrow — تنسيق البيانات في جميع نقاط الاتصال: Parquet، QuestDB، Polars، NumPy
لا طبقة Pandas وسيطة. البيانات تتدفق من التخزين عبر Polars إلى مصفوفات NumPy ثم إلى محرك Numba — بدون نسخ غير ضرورية، بدون GIL، بدون عنق زجاجة أحادي الخيط.
روابط مفيدة
- Polars — User Guide
- Polars vs Pandas — official benchmark
- PDS-H Benchmark — DataFrame libraries comparison
- Apache Arrow — columnar format specification
- Numba — JIT compiler for Python
- vectorbt — backtesting framework
- pandas-ta — Technical Analysis Indicators
- Ritchie Vink — I wrote one of the fastest DataFrame libraries (Polars origin)
- Towards Data Science — Polars vs Pandas: real-world benchmarks
- Ernest Chan — Quantitative Trading
Citation
@article{soloviov2026polarsvspandas,
author = {Soloviov, Eugen},
title = {Polars vs Pandas for Algotrading: Benchmarks on Real Data},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/polars-vs-pandas-algotrading},
description = {Detailed comparison of Polars and Pandas on algotrading tasks: benchmarks for filtering, aggregation, rolling signal computations, I/O, and memory consumption. Hybrid Polars + Numba architecture for maximum backtest performance.}
}
MarketMaker.cc Team
البحوث والاستراتيجيات الكمية