Multi-Symbol Validation: Test Your Strategy on All Pairs

Article from the "Backtests Without Illusions" series
You optimized a strategy on ETHUSDT. 25 months of data, 12+ parameters. The backtest shows PnL +55%, 500 trades, MaxDD -0.9%, position open 15% of the time. The equity curve rises smoothly. Parameters passed plateau analysis — the optimum looks wide. Walk-forward yields WFER > 0.6. Monte Carlo bootstrap shows a positive 5th percentile.
Everything is perfect. Except for one thing: you tested the strategy on a single instrument.
You launch the same algorithm with the same parameters on BTCUSDT — PnL +8%. On SOLUSDT — PnL -12%. On DOGEUSDT — PnL -34%. The strategy that passed all checks on ETH turns out to be unprofitable on most other pairs.
This is not a bug. This is the single-symbol trap — one of the most common and insidious forms of overfitting in algotrading.
The Single Instrument Trap
Optimizing a strategy on a single symbol is essentially fitting it to the price dynamics of a specific asset. Even if you ran walk-forward, even if bootstrap shows wide confidence intervals — all these checks were performed within a single time series.
Walk-forward checks robustness across time: do parameters work on future data of the same instrument. Monte Carlo checks robustness across trade order: can the strategy withstand a different sequence. But none of these methods checks robustness across instruments: does the strategy work on other assets with different characteristics.
If a strategy is profitable only on ETHUSDT — it captured not a market inefficiency, but the specific structure of ETH's price series:
- Characteristic candlestick patterns unique to ETH
- Specific volatility levels to which thresholds are tuned
- The liquidity and microstructure specifics of this particular pair
- Correlation with BTC, characteristic of a particular period
None of this is edge. This is curve fitting at the instrument level.
Symbol Groups (Tiers) in the Crypto Market

Not all cryptocurrencies are equal. For meaningful multi-symbol validation, you need to understand that instruments are divided into groups with fundamentally different characteristics.
Tier 1: Blue Chips (BTC, ETH)
High liquidity, relatively low volatility, institutional flow. Correlation with macro (S&P 500, DXY, Fed rates). Deep order books, tight spreads, stable funding rates. Typical daily volatility: 2-4%.
Tier 2: Large Caps (SOL, BNB, ADA, XRP, AVAX)
Moderate liquidity, elevated volatility. Movements are often driven by sector dynamics (L1 vs L2, DeFi vs infra). Funding rates are more volatile. Spreads are wider. Typical daily volatility: 4-6%.
Tier 3: Mid Caps (DOGE, SHIB, PEPE, ARB, OP)
Meme coins and narrative tokens. High volatility, low correlation with fundamental factors. Movements are determined by social media, listings, narratives. Thin order books on some exchanges. Typical daily volatility: 6-10%.
Tier 4: Low Caps (New Listings)
Extreme volatility, thin order books, manipulation risk. Often insufficient history for a full backtest. Typical daily volatility: 10-20%+.
Summary Table of Characteristics
| Characteristic | Tier 1 | Tier 2 | Tier 3 | Tier 4 |
|---|---|---|---|---|
| Daily volatility | 2-4% | 4-6% | 6-10% | 10-20%+ |
| Average spread (perps) | 0.01-0.02% | 0.02-0.05% | 0.05-0.15% | 0.1-0.5%+ |
| Order book depth (top 5 bps) | $5-50M | $1-10M | $100K-2M | $10K-200K |
| Funding rate (average abs) | 0.005-0.01% | 0.01-0.03% | 0.02-0.08% | 0.05-0.2%+ |
| Correlation with BTC | 0.85-0.95 | 0.6-0.85 | 0.3-0.7 | 0.1-0.5 |
| Minimum history | 5+ years | 2-5 years | 6 mo - 3 years | < 6 mo |
Each tier is a separate "world" with its own microstructure. A strategy tuned for Tier 1 enters a foreign environment when moving to Tier 3.
Multi-Symbol Validation Methodology
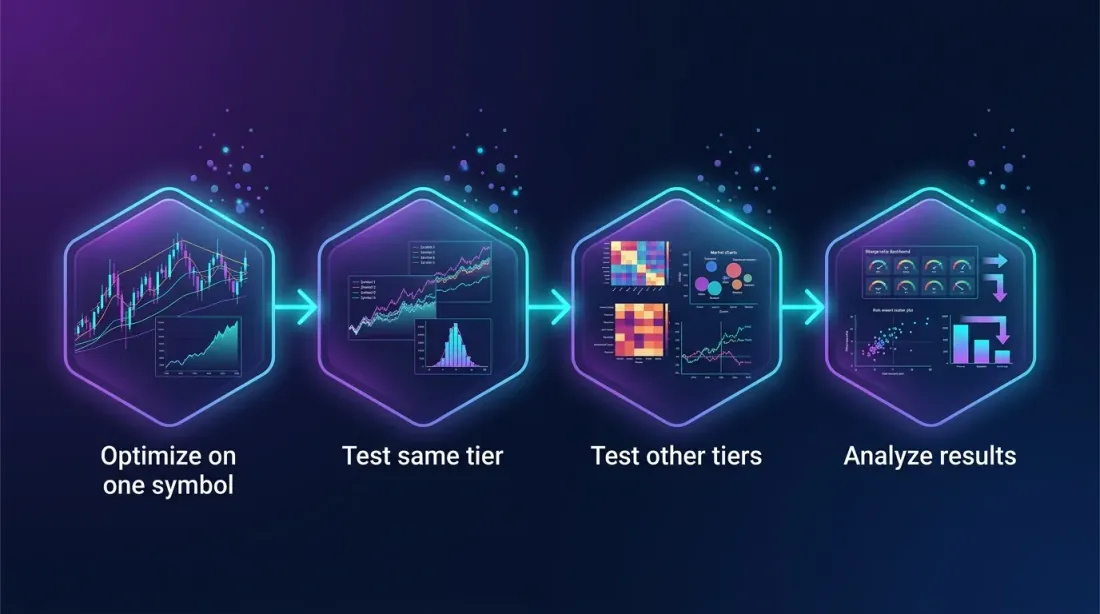
Step 1: Optimize on a Single Symbol
Choose a symbol for optimization — for example, ETHUSDT. Run the full pipeline: Optuna optimization, plateau analysis, walk-forward. Fix the parameters.
Step 2: Test on Symbols from the Same Tier
Run the strategy with the same parameters on 5-10 symbols from the same tier. For Tier 1 this is limited (BTC + ETH), but for Tier 2 and Tier 3 there are enough symbols.
Step 3: Test on Symbols from Other Tiers
Run the strategy on 3-5 symbols from each other tier. This is the toughest test: if the strategy works on ETHUSDT (Tier 1) and on DOGEUSDT (Tier 3), the probability of curve fitting is minimal.
Step 4: Analyze Results by Group
Aggregate metrics by tier and assess cross-symbol robustness.
Metrics for Each Symbol
For each symbol, record:
- PnL — total return
- MaxDD — maximum drawdown
- N trades — number of trades
- Win rate — fraction of profitable trades
- PnL/active day — return per unit of active time (more details in PnL by active time)
Pass Criteria
A strategy passes multi-symbol validation if:
- Profitable on >= 60% of symbols in the same tier
- Average PnL across the group is positive
- MaxDD does not increase dramatically (no more than 2-3x relative to the optimization symbol)
- If the strategy is profitable ONLY on the optimization symbol — reject
Example: Three Strategies, Three Outcomes
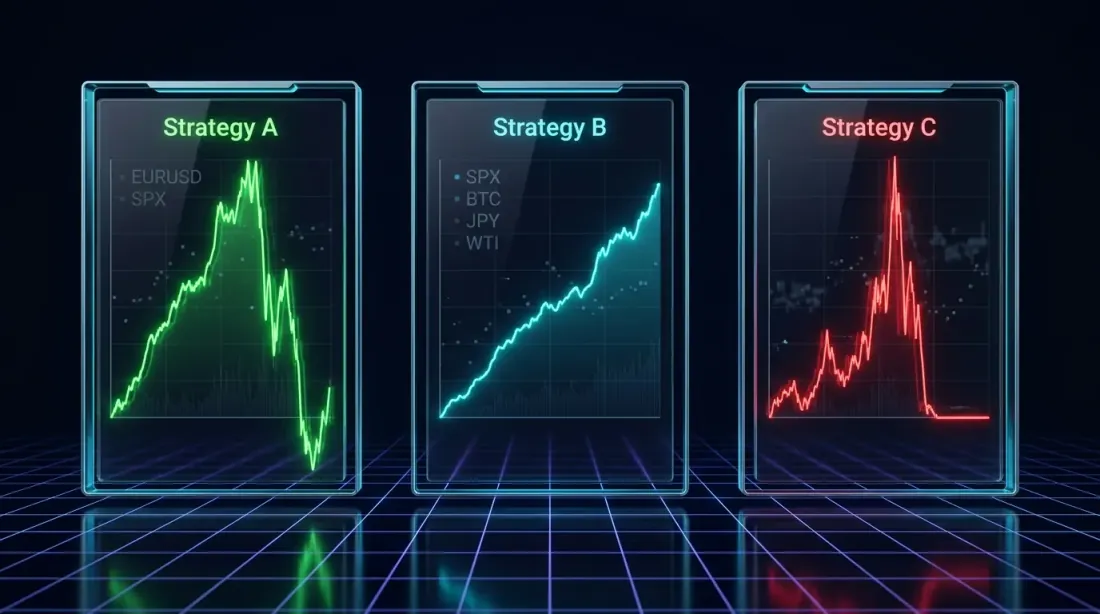
Let's consider a concrete example. Three strategies (Strategy A, Strategy B, Strategy C), optimized on ETHUSDT, tested on 12 symbols across four tiers.
Strategy A (Optimized on ETHUSDT)
Parameters: PnL +55%, ~500 trades, ~15% active time, MaxDD ~0.9%.
| Symbol | Tier | PnL | MaxDD | N trades | Win rate | PnL/active day |
|---|---|---|---|---|---|---|
| ETHUSDT* | 1 | +55.2% | -0.9% | 491 | 52.1% | 0.48% |
| BTCUSDT | 1 | +31.4% | -1.8% | 478 | 50.8% | 0.27% |
| SOLUSDT | 2 | +22.7% | -3.1% | 512 | 49.2% | 0.18% |
| BNBUSDT | 2 | +18.3% | -2.7% | 467 | 48.9% | 0.16% |
| AVAXUSDT | 2 | +8.1% | -4.5% | 498 | 47.6% | 0.07% |
| ADAUSDT | 2 | -3.2% | -6.1% | 445 | 46.1% | -0.03% |
| DOGEUSDT | 3 | -12.8% | -9.4% | 531 | 44.3% | -0.10% |
| SHIBUSDT | 3 | -18.7% | -12.1% | 487 | 43.1% | -0.16% |
| PEPEUSDT | 3 | -24.3% | -14.8% | 556 | 42.7% | -0.18% |
| ARBUSDT | 3 | -7.4% | -7.2% | 419 | 45.8% | -0.07% |
| OPUSDT | 3 | -5.1% | -6.8% | 402 | 46.2% | -0.05% |
* — optimization symbol
Results by tier:
| Tier | Symbols | Profitable | Average PnL | Average MaxDD |
|---|---|---|---|---|
| Tier 1 | 2 | 2 (100%) | +43.3% | -1.4% |
| Tier 2 | 4 | 3 (75%) | +11.5% | -4.1% |
| Tier 3 | 5 | 0 (0%) | -13.7% | -10.1% |
Verdict: Strategy A works on Tier 1-2 but completely fails on Tier 3. This is a typical strategy tuned for a low-volatility environment. For a portfolio of blue chips and large caps — acceptable. For universal use — no.
Strategy B (Optimized on ETHUSDT)
Parameters: PnL +25%, ~40 trades, ~5% active time.
| Symbol | Tier | PnL | MaxDD | N trades | Win rate |
|---|---|---|---|---|---|
| ETHUSDT* | 1 | +25.1% | -2.3% | 38 | 57.9% |
| BTCUSDT | 1 | +21.8% | -2.8% | 41 | 56.1% |
| SOLUSDT | 2 | +19.4% | -3.5% | 44 | 54.5% |
| BNBUSDT | 2 | +16.7% | -3.1% | 37 | 54.1% |
| AVAXUSDT | 2 | +12.3% | -4.2% | 42 | 52.4% |
| ADAUSDT | 2 | +8.9% | -4.8% | 39 | 51.3% |
| DOGEUSDT | 3 | +4.2% | -6.7% | 48 | 47.9% |
| SHIBUSDT | 3 | -1.3% | -8.4% | 45 | 46.7% |
| PEPEUSDT | 3 | -3.8% | -9.1% | 52 | 46.2% |
| ARBUSDT | 3 | +6.1% | -5.8% | 40 | 50.0% |
| OPUSDT | 3 | +3.7% | -6.2% | 38 | 50.0% |
Results by tier:
| Tier | Symbols | Profitable | Average PnL | Average MaxDD |
|---|---|---|---|---|
| Tier 1 | 2 | 2 (100%) | +23.5% | -2.6% |
| Tier 2 | 4 | 4 (100%) | +14.3% | -3.9% |
| Tier 3 | 5 | 3 (60%) | +1.8% | -7.2% |
Verdict: Strategy B is profitable on 9 out of 11 symbols (82%). Average PnL is positive across all tiers. MaxDD grows predictably with tier. This is a robust strategy with a real market edge. Despite the more modest PnL on the optimization symbol (+25% vs +55%), Strategy B is significantly more reliable than Strategy A.
Strategy C (Optimized on ETHUSDT)
Parameters: PnL +300%, ~400 trades, ~45% active time, MaxDD ~17%.
| Symbol | Tier | PnL | MaxDD | N trades | Win rate |
|---|---|---|---|---|---|
| ETHUSDT* | 1 | +301.2% | -17.1% | 418 | 53.8% |
| BTCUSDT | 1 | +42.7% | -28.4% | 395 | 48.6% |
| SOLUSDT | 2 | -18.3% | -41.2% | 456 | 44.1% |
| BNBUSDT | 2 | +12.1% | -33.7% | 387 | 46.8% |
| AVAXUSDT | 2 | -31.4% | -52.8% | 471 | 42.3% |
| ADAUSDT | 2 | -44.7% | -58.1% | 412 | 40.5% |
| DOGEUSDT | 3 | -67.2% | -74.3% | 528 | 38.1% |
| PEPEUSDT | 3 | -72.1% | -81.6% | 574 | 37.4% |
Verdict: Strategy C is classic overfitting. +301% on ETHUSDT, but catastrophic losses on most other pairs. MaxDD on Tier 3 exceeds 70% — this is capital destruction. The strategy captured unique patterns of ETH, not a market inefficiency. Reject.
Why Strategies Break on Other Symbols
1. Volatility Mismatch
The most common reason. Strategy parameters are tuned to a specific volatility level. If the strategy uses a 2% entry threshold — for ETH with 3% daily volatility, this is a reasonable filter. For DOGE with 8% daily volatility — this threshold triggers too often, generating a mass of false signals.
Similarly, a 1% stop loss is adequate for ETH, but for PEPE it's normal "noise," and the stop gets hit dozens of times a day.
2. Liquidity Differences
The strategy assumes instant order execution at the current price. On BTCUSDT with 200K depth — your $10K order will move the price, and actual execution will be worse by 0.05-0.2%. Over 500 trades, that's 25-100% lost to slippage alone.
3. Market Microstructure
Each instrument has its own microstructure:
- Funding rates: on BTC, funding is consistently positive in a bull market (+0.01% every 8 hours). On meme coins, funding can jump from -0.3% to +0.5%. More details — in Funding rates kill your leverage.
- Spread: on Tier 1 the spread is 0.01%, on Tier 4 — 0.5%. A strategy with small take-profits cannot be profitable when the spread exceeds the take size.
- Manipulation patterns: wicks, spoofing, wash trading — manifest differently on each tier.
4. Regime Sensitivity
Altcoins behave differently in different market phases:
- In a bull trend, altcoins outperform BTC (beta > 1)
- In a bear trend, altcoins fall harder than BTC
- In a sideways market, altcoins may correlate with BTC or move on their own narratives
A strategy optimized in one phase on one symbol may be optimally tuned to the lag/lead of specifically that symbol relative to BTC — and this lag/lead will change when the regime shifts.
Adaptive Parameter Scaling

Running a strategy with identical parameters on all symbols is incorrect. But full re-optimization on each symbol defeats the very purpose of multi-symbol validation (parameters become "native" to each symbol).
The compromise is parameter normalization by volatility:
import numpy as np
def scale_params_by_volatility(
base_params: dict,
optimization_symbol_vol: float,
target_symbol_vol: float,
vol_sensitive_params: list[str],
) -> dict:
"""
Scale strategy parameters by target symbol volatility.
Args:
base_params: parameters optimized on the original symbol
optimization_symbol_vol: daily volatility of the optimization symbol
target_symbol_vol: daily volatility of the target symbol
vol_sensitive_params: list of volatility-sensitive parameters
"""
vol_ratio = target_symbol_vol / optimization_symbol_vol
adjusted = base_params.copy()
for param in vol_sensitive_params:
if param in adjusted:
adjusted[param] = adjusted[param] * vol_ratio
return adjusted
base_params = {
"entry_threshold": 0.02, # 2% — entry threshold
"stop_loss": 0.01, # 1% — stop loss
"take_profit": 0.03, # 3% — take profit
"trailing_stop": 0.008, # 0.8% — trailing stop
"atr_multiplier": 2.5, # ATR multiplier (not scaled)
"rsi_period": 14, # RSI period (not scaled)
"ma_fast": 10, # fast MA (not scaled)
"ma_slow": 50, # slow MA (not scaled)
}
vol_sensitive = ["entry_threshold", "stop_loss", "take_profit", "trailing_stop"]
eth_vol = 0.032 # 3.2%
doge_vol = 0.081 # 8.1%
doge_params = scale_params_by_volatility(
base_params, eth_vol, doge_vol, vol_sensitive
)
print("ETH params:", {k: f"{v:.4f}" for k, v in base_params.items() if k in vol_sensitive})
print("DOGE params:", {k: f"{v:.4f}" for k, v in doge_params.items() if k in vol_sensitive})
Output:
ETH params: {'entry_threshold': '0.0200', 'stop_loss': '0.0100', 'take_profit': '0.0300', 'trailing_stop': '0.0080'}
DOGE params: {'entry_threshold': '0.0506', 'stop_loss': '0.0253', 'take_profit': '0.0759', 'trailing_stop': '0.0203'}
The stop loss increased from 1% to 2.53% — appropriate for DOGE's 8.1% daily volatility. Without scaling, a 1% stop would be hit by "noise" dozens of times.
Important: scale only price thresholds (entries, stops, takes). Indicator periods (RSI, MA) and multipliers (ATR multiplier) are usually not scaled — they are already normalized by volatility through the indicator itself.
Two Validation Modes
-
Strict mode (without scaling): run with identical parameters. A test of absolute robustness. If the strategy is profitable — the edge is strong.
-
Adaptive mode (with scaling): run with normalized parameters. A test of strategy logic robustness, with the allowance that volatility levels differ.
We recommend running both tests. Strict mode — to assess the "strength" of the edge. Adaptive mode — for practical application.
Cross-Symbol Robustness Score

For quantitative assessment of multi-symbol robustness, we introduce a composite metric — Cross-Symbol Robustness Score (CSRS).
Formula
where:
- — fraction of profitable symbols:
- — normalized liquidity-weighted average PnL:
where is the liquidity of symbol (average daily volume).
- — bonus for cross-tier consistency:
- — penalty for high PnL variance between symbols:
Default Weights
| Component | Weight | Rationale |
|---|---|---|
| (profitable fraction) | 0.35 | Most important: strategy must work on the majority |
| (average PnL) | 0.25 | Absolute returns |
| (cross-tier) | 0.25 | Bonus for universality |
| (variance penalty) | 0.15 | Penalty for instability |
CSRS Interpretation
| CSRS | Interpretation |
|---|---|
| > 0.7 | Excellent robustness. Strategy works on most instruments. |
| 0.5 — 0.7 | Good robustness. Strategy works in its tier and partially in others. |
| 0.3 — 0.5 | Borderline. Strategy works on a narrow set of symbols. |
| < 0.3 | Low robustness. Instrument-level curve fitting is likely. |
Full Implementation: Multi-Symbol Validation Pipeline

import numpy as np
import pandas as pd
from dataclasses import dataclass, field
from typing import Callable, Optional
@dataclass
class SymbolResult:
"""Strategy result on a single symbol."""
symbol: str
tier: int
pnl: float
max_dd: float
n_trades: int
win_rate: float
pnl_per_active_day: float
avg_daily_volume: float # liquidity
@dataclass
class TierResult:
"""Aggregated result by tier."""
tier: int
symbols: list[SymbolResult]
n_symbols: int
n_profitable: int
profit_ratio: float
avg_pnl: float
avg_max_dd: float
pnl_std: float
@dataclass
class MultiSymbolResult:
"""Full multi-symbol validation result."""
symbol_results: list[SymbolResult]
tier_results: list[TierResult]
csrs: float
passed: bool
optimization_symbol: str
report: str
SYMBOL_TIERS = {
1: ["BTCUSDT", "ETHUSDT"],
2: ["SOLUSDT", "BNBUSDT", "ADAUSDT", "XRPUSDT", "AVAXUSDT"],
3: ["DOGEUSDT", "SHIBUSDT", "PEPEUSDT", "ARBUSDT", "OPUSDT"],
}
SYMBOL_VOLATILITY = {
"BTCUSDT": 0.028, "ETHUSDT": 0.032,
"SOLUSDT": 0.052, "BNBUSDT": 0.038, "ADAUSDT": 0.048,
"XRPUSDT": 0.045, "AVAXUSDT": 0.055,
"DOGEUSDT": 0.081, "SHIBUSDT": 0.092, "PEPEUSDT": 0.105,
"ARBUSDT": 0.068, "OPUSDT": 0.063,
}
SYMBOL_VOLUME = {
"BTCUSDT": 15e9, "ETHUSDT": 8e9,
"SOLUSDT": 2e9, "BNBUSDT": 1.5e9, "ADAUSDT": 800e6,
"XRPUSDT": 1.2e9, "AVAXUSDT": 500e6,
"DOGEUSDT": 1e9, "SHIBUSDT": 400e6, "PEPEUSDT": 600e6,
"ARBUSDT": 300e6, "OPUSDT": 250e6,
}
def run_multi_symbol_validation(
strategy_fn: Callable,
base_params: dict,
optimization_symbol: str,
data_loader: Callable,
vol_sensitive_params: list[str],
adaptive: bool = True,
csrs_weights: tuple = (0.35, 0.25, 0.25, 0.15),
min_profit_ratio: float = 0.6,
) -> MultiSymbolResult:
"""
Full multi-symbol validation pipeline.
Args:
strategy_fn: strategy function (data, params) -> (pnl, max_dd, n_trades, win_rate, returns)
base_params: parameters optimized on optimization_symbol
optimization_symbol: optimization symbol
data_loader: data loading function (symbol) -> np.ndarray
vol_sensitive_params: parameters to scale by volatility
adaptive: use volatility scaling
csrs_weights: weights (w1, w2, w3, w4) for CSRS
min_profit_ratio: minimum fraction of profitable symbols in a tier
"""
w1, w2, w3, w4 = csrs_weights
opt_vol = SYMBOL_VOLATILITY.get(optimization_symbol, 0.03)
symbol_results = []
for tier, symbols in SYMBOL_TIERS.items():
for symbol in symbols:
data = data_loader(symbol)
if data is None or len(data) < 100:
continue
if adaptive and symbol != optimization_symbol:
sym_vol = SYMBOL_VOLATILITY.get(symbol, 0.05)
params = scale_params_by_volatility(
base_params, opt_vol, sym_vol, vol_sensitive_params
)
else:
params = base_params.copy()
pnl, max_dd, n_trades, win_rate, returns = strategy_fn(data, params)
active_days = max(n_trades * 0.5, 1) # rough estimate
pnl_per_day = pnl / active_days
symbol_results.append(SymbolResult(
symbol=symbol,
tier=tier,
pnl=pnl,
max_dd=max_dd,
n_trades=n_trades,
win_rate=win_rate,
pnl_per_active_day=pnl_per_day,
avg_daily_volume=SYMBOL_VOLUME.get(symbol, 1e6),
))
tier_results = []
tiers_present = sorted(set(r.tier for r in symbol_results))
for tier in tiers_present:
tier_symbols = [r for r in symbol_results if r.tier == tier]
n_profitable = sum(1 for r in tier_symbols if r.pnl > 0)
pnls = [r.pnl for r in tier_symbols]
tier_results.append(TierResult(
tier=tier,
symbols=tier_symbols,
n_symbols=len(tier_symbols),
n_profitable=n_profitable,
profit_ratio=n_profitable / len(tier_symbols) if tier_symbols else 0,
avg_pnl=np.mean(pnls),
avg_max_dd=np.mean([r.max_dd for r in tier_symbols]),
pnl_std=np.std(pnls),
))
all_pnls = [r.pnl for r in symbol_results]
all_volumes = [r.avg_daily_volume for r in symbol_results]
n_total = len(symbol_results)
n_profitable = sum(1 for r in symbol_results if r.pnl > 0)
r_profit = n_profitable / n_total if n_total > 0 else 0
total_vol = sum(all_volumes)
r_pnl_raw = sum(r.pnl * r.avg_daily_volume for r in symbol_results) / total_vol
r_pnl = 1 / (1 + np.exp(-r_pnl_raw * 5))
profitable_tiers = sum(1 for tr in tier_results if tr.avg_pnl > 0)
p_consistency = profitable_tiers / len(tier_results) if tier_results else 0
pnl_std = np.std(all_pnls) if len(all_pnls) > 1 else 0
pnl_mean = np.mean(all_pnls) if all_pnls else 0.01
p_variance = pnl_std / max(abs(pnl_mean), 0.01)
p_variance = min(p_variance, 5.0) # cap the penalty
csrs = w1 * r_profit + w2 * r_pnl + w3 * p_consistency - w4 * (p_variance / 5.0)
csrs = max(0, min(1, csrs)) # clamp to [0, 1]
opt_tier = None
for tier, symbols in SYMBOL_TIERS.items():
if optimization_symbol in symbols:
opt_tier = tier
break
same_tier_result = next((tr for tr in tier_results if tr.tier == opt_tier), None)
passed = (
csrs >= 0.5
and (same_tier_result is None or same_tier_result.profit_ratio >= min_profit_ratio)
and np.mean(all_pnls) > 0
)
report = _generate_report(
symbol_results, tier_results, csrs, passed,
optimization_symbol, adaptive
)
return MultiSymbolResult(
symbol_results=symbol_results,
tier_results=tier_results,
csrs=csrs,
passed=passed,
optimization_symbol=optimization_symbol,
report=report,
)
def _generate_report(
symbol_results, tier_results, csrs, passed,
opt_symbol, adaptive
) -> str:
"""Generate text report."""
lines = []
lines.append("=" * 60)
lines.append("MULTI-SYMBOL VALIDATION REPORT")
lines.append(f"Optimization symbol: {opt_symbol}")
lines.append(f"Mode: {'adaptive' if adaptive else 'strict'}")
lines.append(f"CSRS: {csrs:.3f}")
lines.append(f"Passed: {'YES' if passed else 'NO'}")
lines.append("=" * 60)
for tr in tier_results:
lines.append(f"\n--- Tier {tr.tier} ---")
lines.append(f" Symbols: {tr.n_symbols}, Profitable: {tr.n_profitable} "
f"({tr.profit_ratio:.0%})")
lines.append(f" Avg PnL: {tr.avg_pnl:.2%}, Avg MaxDD: {tr.avg_max_dd:.2%}")
lines.append(f" PnL StdDev: {tr.pnl_std:.2%}")
for sr in tr.symbols:
marker = "*" if sr.symbol == opt_symbol else " "
status = "+" if sr.pnl > 0 else "-"
lines.append(
f" {marker} [{status}] {sr.symbol:12s} "
f"PnL={sr.pnl:+.2%} MaxDD={sr.max_dd:.2%} "
f"Trades={sr.n_trades:4d} WR={sr.win_rate:.1%}"
)
lines.append("\n" + "=" * 60)
return "\n".join(lines)
Pipeline Usage Example
def my_strategy(data, params):
"""Your strategy. Returns (pnl, max_dd, n_trades, win_rate, returns)."""
pass
def load_ohlcv(symbol):
"""Load OHLCV data for a symbol."""
pass
base_params = {
"entry_threshold": 0.02,
"stop_loss": 0.01,
"take_profit": 0.03,
"trailing_stop": 0.008,
"atr_multiplier": 2.5,
"rsi_period": 14,
"ma_fast": 10,
"ma_slow": 50,
}
result = run_multi_symbol_validation(
strategy_fn=my_strategy,
base_params=base_params,
optimization_symbol="ETHUSDT",
data_loader=load_ohlcv,
vol_sensitive_params=["entry_threshold", "stop_loss", "take_profit", "trailing_stop"],
adaptive=True,
)
print(result.report)
print(f"\nCSRS: {result.csrs:.3f}")
print(f"Passed: {result.passed}")
When Single-Symbol Validation Is Acceptable
Not every strategy must work across multiple instruments. There are legitimate cases where single-symbol is a normal approach:
Market Making on a Specific Order Book
A market-making strategy (e.g., using the Avellaneda-Stoikov model) is by definition tied to a specific order book. Parameters depend on the specific microstructure: depth, spread, queue position, fill rate. Testing on another symbol is meaningless — it's a different order book.
Arbitrage Between Specific Pairs
Funding rate arbitrage or cross-exchange arbitrage is by definition tied to specific instrument pairs. Validation here is on other exchanges with the same pairs, not on different symbols.
Strategies Explicitly Using Unique Asset Properties
If a strategy is based on a specific property of one asset (e.g., BTC's correlation with hashrate or ETH's correlation with gas fees), multi-symbol validation is not applicable. But such strategies are rare.
In all other cases — if the strategy is based on "generic" signals (MA crossover, RSI, momentum, mean reversion) — multi-symbol validation is mandatory. If a generic strategy works only on one symbol, it's not edge — it's overfitting.
Relationship with Other Validation Methods
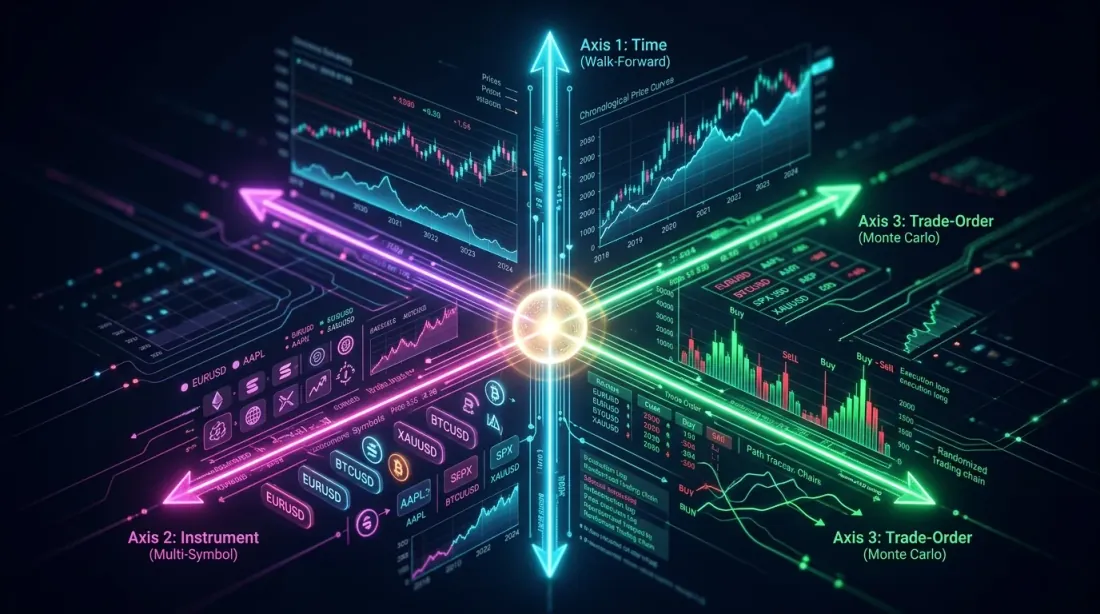
Multi-symbol validation is one of three orthogonal methods of out-of-sample testing:
| Method | Validation Axis | What It Reveals |
|---|---|---|
| Walk-Forward | Time | Overfitting to a specific period |
| Multi-symbol | Instrument | Overfitting to a specific asset |
| Monte Carlo Bootstrap | Trade order | Dependence on a specific sequence |
Each method checks robustness along its own axis. A strategy can pass walk-forward but fail multi-symbol (curve fitted to the instrument). It can pass multi-symbol but fail Monte Carlo (depends on a lucky trade order).
Maximum overfitting protection: use all three methods.
Full validation pipeline:
- Optimization of parameters on a single symbol
- Plateau analysis — optimum stability check
- Walk-forward — time-axis validation (WFER > 0.5)
- Multi-symbol — instrument-axis validation (CSRS > 0.5)
- Monte Carlo bootstrap — confidence intervals (5th percentile > 0)
- Account for funding rates and loss asymmetry
A strategy that passes all six checks has minimal probability of being an overfitting artifact.
Extensions: Symbol Correlation and Cascade Strategies

Multi-symbol validation reveals yet another aspect: correlations between symbols. If a strategy is profitable on BTC and ETH but unprofitable on all altcoins — this is information that the edge is tied to the high BTC-ETH correlation. Detailed analysis of correlation structures — in the article Signal correlation and pairs trading.
For strategy portfolios, multi-symbol results determine on which instruments a strategy should be launched. Strategy A from the example above — only Tier 1-2. Strategy B — Tier 1-3. This is input data for cascade orchestration, where different strategies are launched on different instruments depending on their robustness profile.
Conclusion
Multi-symbol validation is not optional — it is a mandatory step for any strategy claiming a generalized market edge. Key takeaways:
-
A strategy that works on only one symbol is most likely overfit to that symbol's specifics. Exceptions: market making, arbitrage, strategies based on unique asset properties.
-
Tier grouping is mandatory. You cannot compare results on BTC (Tier 1) with results on PEPE (Tier 3) without understanding the differences in volatility, liquidity, and microstructure.
-
Adaptive parameter scaling — threshold normalization by volatility — significantly improves the realism of multi-symbol testing.
-
CSRS > 0.5 — a reasonable minimum threshold. The strategy should be profitable on >= 60% of symbols in the same tier, and the average PnL across all symbols should be positive.
-
Walk-forward + Multi-symbol + Monte Carlo — three orthogonal validation axes. Each method catches what the others miss. Use all three.
A strategy with PnL +25% and CSRS 0.72 is more reliable than a strategy with PnL +300% and CSRS 0.18. The former earns from market inefficiency. The latter earns from memorizing a single price series.
Useful Links
- Lopez de Prado, M. — Advances in Financial Machine Learning (Wiley)
- Pardo, R. — The Evaluation and Optimization of Trading Strategies (Wiley)
- Bailey, D.H. et al. — The Probability of Backtest Overfitting
- Aronson, D.R. — Evidence-Based Technical Analysis
- Kevin Davey — Building Winning Algorithmic Trading Systems (Wiley)
- Harvey, C.R. & Liu, Y. — Backtesting (2015)
- Chan, E. — Algorithmic Trading: Winning Strategies and Their Rationale (Wiley)
- Binance Research — Cryptocurrency Correlation Analysis
- NumPy — numpy.random.choice
- Pandas — DataFrame
Citation
@article{soloviov2026multisymbolvalidation,
author = {Soloviov, Eugen},
title = {Multi-Symbol Validation: Test Your Strategy on All Pairs},
year = {2026},
url = {https://marketmaker.cc/en/blog/post/multi-symbol-validation},
version = {0.1.0},
description = {Why a strategy optimized on ETHUSDT may fail on altcoins. How to properly test across pair groups (blue chips, large caps, shitcoins) and what cross-symbol robustness score to consider sufficient.}
}
MarketMaker.cc Team
क्वांटिटेटिव रिसर्च और स्ट्रैटेजी