Monte Carlo Bootstrap: Come Ottenere Intervalli di Confidenza per un Backtest in 10 Righe di Codice
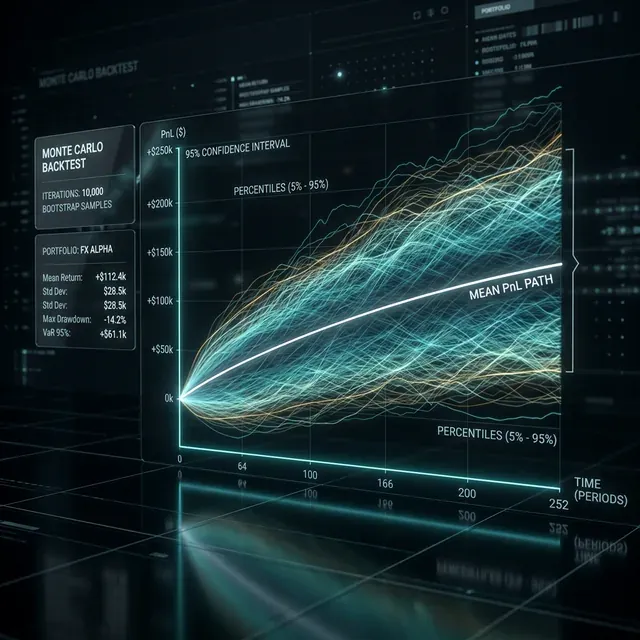
Hai eseguito una strategia in un backtest. Hai ottenuto PnL +42%, Sharpe 1.8, MaxDD -12%. I risultati sembrano ottimi. Avvii il bot in produzione e un mese dopo scopri che il drawdown è già -28% e il PnL si avvicina allo zero.
Cosa è andato storto? Non è un bug e nemmeno "un mercato cambiato." Il problema è che hai preso una decisione basandoti su un singolo numero — una stima puntuale. Hai scoperto che la strategia ha mostrato +42%, ma non hai scoperto quanto puoi fidarti di quel numero.
Il Problema delle Stime Puntuali
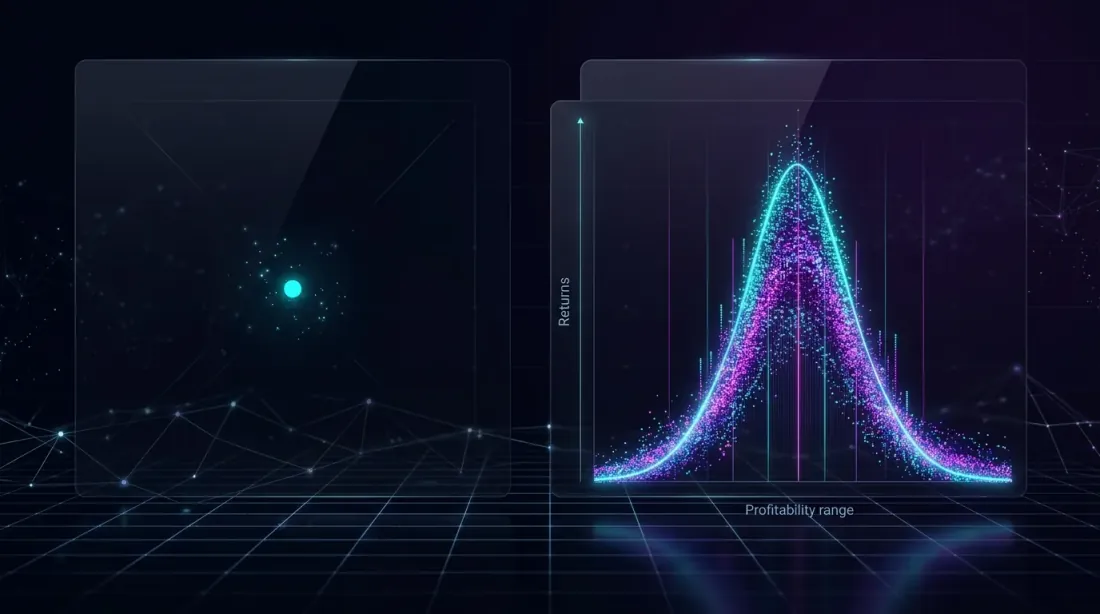 Un singolo punto dati (sinistra) dà un'immagine fuorviante, mentre la distribuzione completa (destra) rivela il vero range dei possibili risultati.
Un singolo punto dati (sinistra) dà un'immagine fuorviante, mentre la distribuzione completa (destra) rivela il vero range dei possibili risultati.
Un backtest sui dati storici è un'unica esecuzione attraverso una sequenza specifica di eventi di mercato. Il risultato dipende dall'ordine dei trade: la stessa strategia con gli stessi trade, ma in un ordine diverso, può mostrare un massimo drawdown completamente diverso.
Immagina 491 trade. Ogni trade è un evento casuale con una certa distribuzione dei rendimenti. Il backtest storico mostra soltanto una realizzazione di questo processo. È come tirare un dado una volta e concludere che il dado cade sempre sul quattro.
Ciò di cui abbiamo effettivamente bisogno:
- Non una stima puntuale, ma un intervallo: "con il 95% di probabilità, il PnL finale sarà compreso tra X e Y"
- Non un singolo massimo drawdown, ma una distribuzione: "nel 5% degli scenari peggiori, il drawdown supera Z%"
- Non la media, ma le code: cosa succede se la fortuna non è dalla tua parte?
Ecco esattamente a cosa serve il Monte Carlo bootstrap.
Cos'è il Monte Carlo Bootstrap
 Il bootstrap genera migliaia di traiettorie equity alternative ricampionando i trade con sostituzione dal dataset originale.
Il bootstrap genera migliaia di traiettorie equity alternative ricampionando i trade con sostituzione dal dataset originale.
Il bootstrap è un metodo di ricampionamento proposto da Bradley Efron nel 1979. L'idea è elegante: se abbiamo un campione di dati, possiamo generare migliaia di "nuovi" campioni selezionando casualmente elementi dall'originale con sostituzione.
Nel contesto di un backtest, funziona così:
- Hai un array di rendimenti per ogni trade — per esempio, 491 valori
- Selezioni casualmente 491 valori da questo array con sostituzione — alcuni trade appariranno due volte, altri non appariranno affatto
- Costruisci una curva equity da questo nuovo campione
- Ripeti 10.000 volte
- Ottieni una distribuzione delle metriche finali, non un singolo numero
Ogni iterazione è uno "scenario alternativo": ciò che avrebbe potuto accadere se l'ordine e l'insieme dei trade fosse stato leggermente diverso.
Implementazione in 10 Righe
Ecco un'implementazione completa e funzionante:
import numpy as np
def max_drawdown(equity_curve):
"""Calculate the maximum drawdown of an equity curve."""
peak = np.maximum.accumulate(equity_curve)
drawdown = (equity_curve - peak) / peak
return drawdown.min()
trade_returns = [...] # 491 values, e.g. [0.012, -0.005, 0.008, ...]
n_simulations = 10000
results = []
for _ in range(n_simulations):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
results.append({
"final_pnl": equity[-1] - 1,
"max_dd": max_drawdown(equity),
"sharpe": np.mean(sampled) / np.std(sampled) * np.sqrt(252)
})
Tempo di esecuzione: ~2 secondi su un laptop normale. 10.000 storie alternative della tua strategia.
Estrazione degli Intervalli di Confidenza
 Intervalli di confidenza per le metriche chiave della strategia: PnL, MaxDD e Sharpe Ratio, che mostrano le fasce del 5° (peggiore), 50° (mediano) e 95° (migliore) percentile.
Intervalli di confidenza per le metriche chiave della strategia: PnL, MaxDD e Sharpe Ratio, che mostrano le fasce del 5° (peggiore), 50° (mediano) e 95° (migliore) percentile.
Ora abbiamo non un numero, ma una distribuzione. Ecco come estrarre informazioni utili:
import pandas as pd
df = pd.DataFrame(results)
pnl_5 = np.percentile(df['final_pnl'], 5)
pnl_50 = np.percentile(df['final_pnl'], 50)
pnl_95 = np.percentile(df['final_pnl'], 95)
dd_5 = np.percentile(df['max_dd'], 5) # 5th — worst case
dd_50 = np.percentile(df['max_dd'], 50)
dd_95 = np.percentile(df['max_dd'], 95) # 95th — best case
print(f"PnL: {pnl_5:.1%} | {pnl_50:.1%} | {pnl_95:.1%}")
print(f"MaxDD: {dd_5:.1%} | {dd_50:.1%} | {dd_95:.1%}")
print(f"Sharpe: {np.percentile(df['sharpe'], 5):.2f} — {np.percentile(df['sharpe'], 95):.2f}")
Esempio di output per una strategia reale:
| Metrica | 5° percentile (peggiore) | Mediana | 95° percentile (migliore) |
|---|---|---|---|
| PnL | +18,3% | +41,7% | +72,1% |
| MaxDD | -23,4% | -12,8% | -5,1% |
| Sharpe | 1,12 | 1,76 | 2,41 |
Ora la differenza è evidente:
- Il backtest ha mostrato PnL +42% — ma nel 5% degli scenari peggiori, il PnL è solo +18,3%
- Il backtest ha mostrato MaxDD -12% — ma nel 5% degli scenari peggiori, il drawdown è -23,4%
- Sharpe 1,8 — ma il limite inferiore è 1,12
Il 5° percentile è il tuo "caso peggiore realistico." Se la strategia smette di essere redditizia al 5° percentile, avviarla in produzione è rischioso.
Visualizzazione: Fan Chart
Il Monte Carlo bootstrap si visualizza naturalmente come un fan chart — un ventaglio di curve equity:
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
ax = axes[0]
for i in range(min(500, n_simulations)):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
ax.plot(equity, alpha=0.02, color='#4FC3F7')
all_equities = []
for _ in range(n_simulations):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
all_equities.append(equity)
all_equities = np.array(all_equities)
p5 = np.percentile(all_equities, 5, axis=0)
p50 = np.percentile(all_equities, 50, axis=0)
p95 = np.percentile(all_equities, 95, axis=0)
ax.fill_between(range(len(p5)), p5, p95, alpha=0.3, color='#7C4DFF', label='90% CI')
ax.plot(p50, color='#E040FB', linewidth=2, label='Median')
ax.set_title('Monte Carlo Bootstrap: Equity Curves')
ax.legend()
ax = axes[1]
ax.hist(df['final_pnl'] * 100, bins=80, color='#4FC3F7', alpha=0.7, edgecolor='#1A237E')
ax.axvline(pnl_5 * 100, color='#FF5252', linestyle='--', label=f'5th: {pnl_5:.1%}')
ax.axvline(pnl_50 * 100, color='#E040FB', linestyle='--', label=f'Median: {pnl_50:.1%}')
ax.axvline(pnl_95 * 100, color='#69F0AE', linestyle='--', label=f'95th: {pnl_95:.1%}')
ax.set_title('Distribution of Final PnL')
ax.set_xlabel('PnL, %')
ax.legend()
plt.tight_layout()
plt.savefig('monte_carlo_fan_chart.png', dpi=150)
plt.show()
Un fan chart fornisce una comprensione intuitiva della dispersione dei possibili risultati. Un ventaglio stretto significa che la strategia è stabile. Un ventaglio ampio significa che il risultato dipende molto dalla "fortuna" con la sequenza dei trade.
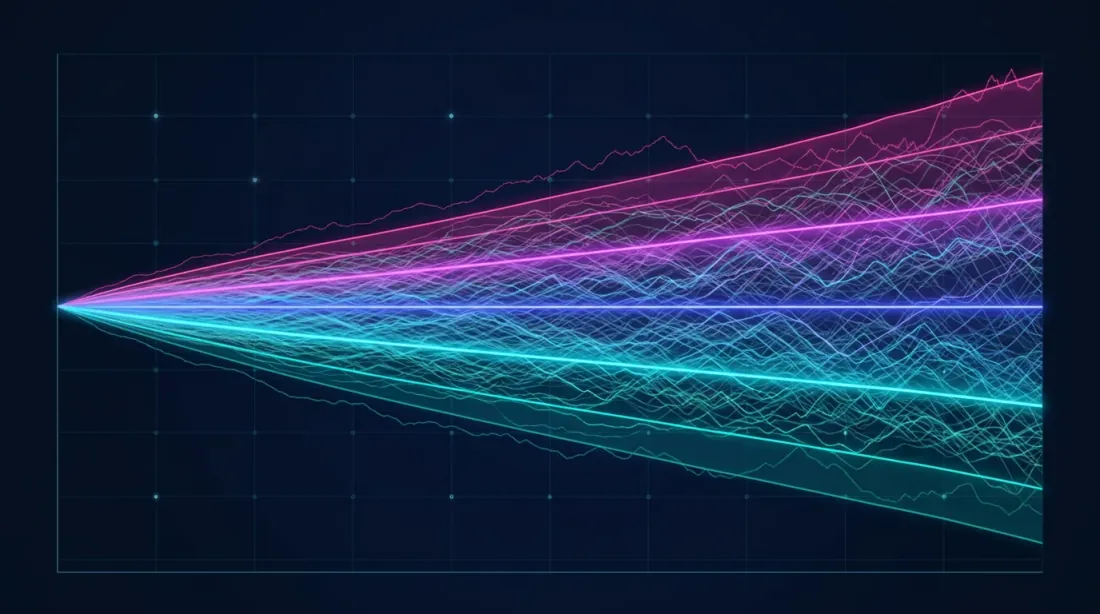 Il fan chart (sinistra) mostra la dispersione delle possibili traiettorie equity, e l'istogramma (destra) mostra la distribuzione della densità dei rendimenti finali con intervalli di confidenza evidenziati (5%, 50%, 95%).
Il fan chart (sinistra) mostra la dispersione delle possibili traiettorie equity, e l'istogramma (destra) mostra la distribuzione della densità dei rendimenti finali con intervalli di confidenza evidenziati (5%, 50%, 95%).
Analisi Avanzata: Probabilità di Rovina
 Visualizzazione della probabilità di rovina: i percorsi equity sopravvissuti (ciano) si curvano verso l'alto mentre i percorsi rovinati (rosso) scendono sotto il bordo della scogliera a equity zero.
Visualizzazione della probabilità di rovina: i percorsi equity sopravvissuti (ciano) si curvano verso l'alto mentre i percorsi rovinati (rosso) scendono sotto il bordo della scogliera a equity zero.
Il bootstrap ti permette di rispondere a una domanda critica: qual è la probabilità che la strategia perda X% del capitale?
ruin_threshold = -0.20
prob_ruin = (df['max_dd'] < ruin_threshold).mean()
print(f"P(MaxDD < -20%) = {prob_ruin:.1%}")
prob_loss = (df['final_pnl'] < 0).mean()
print(f"P(PnL < 0) = {prob_loss:.1%}")
worst_5pct = df['final_pnl'].quantile(0.05)
cvar = df[df['final_pnl'] <= worst_5pct]['final_pnl'].mean()
print(f"CVaR(5%) = {cvar:.1%}")
Queste metriche sono impossibili da ottenere da una singola esecuzione del backtest. Eppure sono critiche per prendere la decisione di avviare una strategia.
Per ulteriori informazioni sul perché i drawdown profondi sono matematicamente pericolosi e su come funziona l'asimmetria dei rendimenti, leggi il nostro articolo Asimmetria Perdita-Profitto.
Quando il Bootstrap Classico Non Funziona
Il metodo ha limitazioni importanti da conoscere.
Autocorrelazione dei Rendimenti
Il bootstrap classico assume che i trade siano indipendenti. In realtà, spesso non è così — una strategia può avere serie vincenti e perdenti. Se l'autocorrelazione è significativa, usa il block bootstrap:
def block_bootstrap(returns, block_size=10, n_simulations=10000):
"""Bootstrap preserving local dependency structure."""
n = len(returns)
results = []
for _ in range(n_simulations):
starts = np.random.randint(0, n - block_size + 1, size=n // block_size + 1)
sampled = np.concatenate([returns[s:s+block_size] for s in starts])[:n]
equity = np.cumprod(1 + sampled)
results.append({
"final_pnl": equity[-1] - 1,
"max_dd": max_drawdown(equity),
})
return pd.DataFrame(results)
Il block bootstrap preserva le dipendenze locali tra trade consecutivi, fornendo intervalli di confidenza più realistici per il MaxDD.
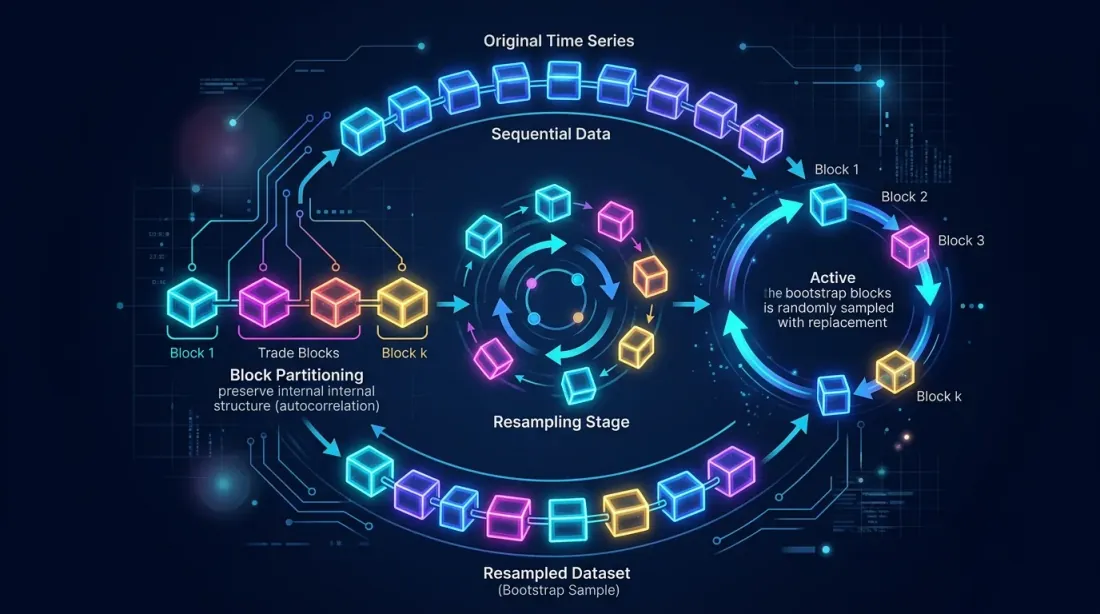 Il block bootstrap preserva l'autocorrelazione all'interno dei blocchi suddividendo la sequenza dei trade in blocchi e ricampionandoli con sostituzione.
Il block bootstrap preserva l'autocorrelazione all'interno dei blocchi suddividendo la sequenza dei trade in blocchi e ricampionandoli con sostituzione.
Non-Stazionarietà del Mercato
Il bootstrap lavora con la distribuzione originale dei trade. Se il mercato è cambiato strutturalmente (ad es., la volatilità è diminuita o la liquidità è cambiata), i trade storici potrebbero non essere rappresentativi. Per tenerne conto:
- Usa una finestra scorrevole: bootstrap solo sugli ultimi N trade
- Pesa i trade recenti più pesantemente: bootstrap ponderato
- Dividi i dati per regimi di mercato e fai bootstrap separatamente
Numero Ridotto di Trade
Il bootstrap è affidabile quando si hanno n > 30 trade. Se hai 10 trade — nessun ricampionamento potrà aiutare. 491 trade è un campione eccellente; puoi fidarti dei risultati.
Confronto degli Approcci per la Valutazione della Robustezza del Backtest
| Metodo | Cosa fornisce | Complessità | Tempo | Quando usarlo |
|---|---|---|---|---|
| Singolo backtest | Una stima puntuale | Minima | Secondi | Mai come risultato finale |
| Walk-forward | Metriche out-of-sample | Media | Minuti | Per verificare l'overfitting |
| Monte Carlo bootstrap | Intervalli di confidenza | Minima | ~2 sec | Sempre prima della produzione |
| Monte Carlo path | Nuovi percorsi di prezzo | Alta | Minuti-ore | Per lo stress testing |
| Cross-validation | Metriche medie per fold | Media | Minuti | Per la messa a punto dei parametri |
Il Monte Carlo bootstrap è l'unico metodo che nel minimo tempo fornisce un quadro completo dei rischi.
Checklist: Interpretazione dei Risultati
Ecco come consigliamo di interpretare i risultati del Monte Carlo bootstrap:
Avvia in produzione se:
- PnL al 5° percentile è positivo
- MaxDD al 5° percentile è accettabile per la tua propensione al rischio
- Probabilità di rovina < 1%
- Sharpe al 5° percentile > 0,5
Necessita di lavoro se:
- PnL al 5° percentile è vicino allo zero
- MaxDD al 5° percentile è significativamente peggiore che al 50°
- Ampia dispersione del fan chart — la strategia è instabile
Non avviare se:
- PnL al 5° percentile è negativo
- Probabilità di rovina > 5%
- L'intervallo di confidenza per lo Sharpe include 0
La Nostra Esperienza su marketmaker.cc
Su marketmaker.cc, sviluppiamo il nostro motore di backtest, e il Monte Carlo bootstrap è parte integrante della nostra pipeline. Ogni strategia passa attraverso il bootstrap automaticamente prima di essere approvata per il trading live.
Abbiamo integrato il bootstrap direttamente nel motore di backtest: dopo un'esecuzione, ottieni non solo il PnL finale, ma un report completo con intervalli di confidenza, fan chart, probabilità di rovina e un confronto tra block bootstrap e bootstrap standard. Questo richiede ulteriori 2-3 secondi — un prezzo trascurabile per comprendere i rischi reali.
Dalla nostra esperienza: circa il 30% delle strategie che sembrano attraenti per stima puntuale vengono filtrate dopo il Monte Carlo bootstrap. Il loro PnL al 5° percentile diventa negativo o il MaxDD risulta inaccettabile. Senza bootstrap, queste strategie sarebbero andate in produzione e molto probabilmente avrebbero generato perdite.
Conclusione
Il Monte Carlo bootstrap è ~10 righe di codice e ~2 secondi di calcolo. Trasforma un singolo numero da un backtest in una distribuzione completa con intervalli di confidenza. Questo è forse il ROI più alto di qualsiasi strumento di analisi quantitativa:
- Costo minimo: implementazione in 30 minuti
- Massima resa: comprensione dei rischi reali della strategia
- Nessuna dipendenza: solo NumPy
Se non stai ancora usando il bootstrap — aggiungilo alla tua pipeline oggi. È l'unico modo per sapere quanto puoi fidarti dei risultati del tuo backtest.
Riferimenti
- Efron, B. — Bootstrap Methods: Another Look at the Jackknife (1979)
- Davison, A.C., Hinkley, D.V. — Bootstrap Methods and their Application (Cambridge)
- Aronson, D.R. — Evidence-Based Technical Analysis: Monte Carlo permutation
- QuantStart — Monte Carlo Simulation for Backtest Analysis
- Marcos Lopez de Prado — Advances in Financial Machine Learning, Chapter 12: Backtesting
- Kevin Davey — Building Winning Algorithmic Trading Systems: Monte Carlo Analysis
- NumPy — numpy.random.choice
Citazione
@software{soloviov2026montecarlobootstrap,
author = {Soloviov, Eugen},
title = {Monte Carlo Bootstrap: Come Ottenere Intervalli di Confidenza per un Backtest in 10 Righe di Codice},
year = {2026},
url = {https://marketmaker.cc/it/blog/post/monte-carlo-bootstrap-backtest},
version = {0.1.0},
description = {Perché una stima puntuale da un backtest è un'illusione pericolosa. Come il bootstrap Monte Carlo in 2 secondi di calcolo fornisce un intervallo di confidenza al 95\% per PnL e MaxDD, e perché questo è un passaggio obbligatorio prima di avviare una strategia in produzione.}
}
Autori

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Leggi di Più

PnL per Tempo Attivo: La Metrica che Cambia il Ranking delle Strategie

Drill-Down Adattivo: Backtest con Granularità Variabile dai Minuti ai Trade Grezzi
