Drill-Down Adattivo: Backtest con Granularità Variabile dai Minuti ai Trade Grezzi
Le candele al minuto sono la granularità standard per i backtest. Ma all'interno di una singola candela al minuto, il prezzo può muoversi in modo diverso: a volte dello 0,01%, altre volte del 2%. Quando sia lo stop-loss che il take-profit ricadono nell'intervallo [low, high] di una singola candela al minuto, il backtest non sa quale sia scattato per primo. Questo è il problema dell'ambiguità di esecuzione (fill ambiguity).
La soluzione ingenua è passare ai dati al secondo per l'intero backtest. Ma in due anni, ciò equivale a ~63 milioni di barre al secondo invece di ~1 milione di barre al minuto. L'archiviazione aumenta di 60 volte, la velocità cala proporzionalmente.
Il drill-down adattivo risolve questo problema: usa la granularità fine solo dove è davvero necessaria.
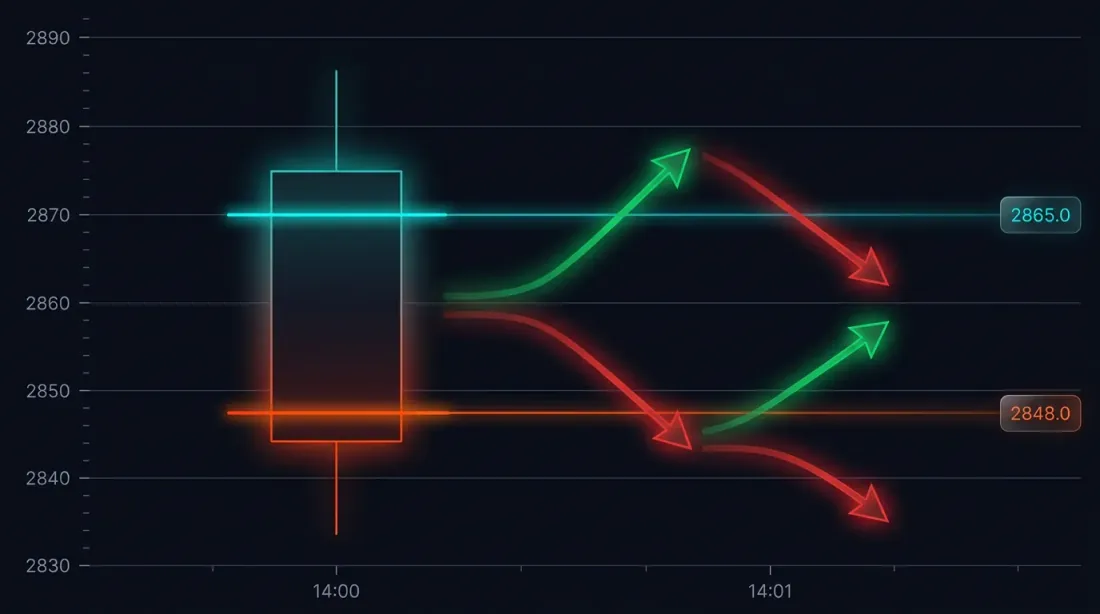
Il Problema: Ambiguità di Esecuzione sulle Candele Grandi
Consideriamo una situazione specifica. La strategia ha aperto una posizione long a 3000 USDT. Stop-loss: 2970 (-1%). Take-profit: 3060 (+2%).
La candela al minuto alle 14:37:
- Open: 3010
- High: 3065
- Low: 2965
- Close: 3050
Sia SL (2970) che TP (3060) ricadono nell'intervallo [2965, 3065]. Quale è scattato per primo?
Possibili esiti:
- Il prezzo è sceso prima -> SL scattato -> perdita del -1%
- Il prezzo è salito prima -> TP scattato -> profitto del +2%
La differenza in un singolo trade: 3 punti percentuali. Con leva 10x — 30%. Per un backtest con centinaia di trade, la risoluzione errata dell'ambiguità di esecuzione distorce sistematicamente i risultati.
Come i Framework Gestiscono Questo per Impostazione Predefinita
La maggior parte dei motori di backtest utilizza una di due euristiche:
- Ottimistica: il TP scatta per primo -> risultati gonfiati
- Pessimistica: lo SL scatta per primo -> risultati deflazionati
Entrambi gli approcci sono ipotetico. I dati reali sono disponibili a livello di secondo o persino di millisecondo, e non c'è motivo di indovinare quando si può guardare.
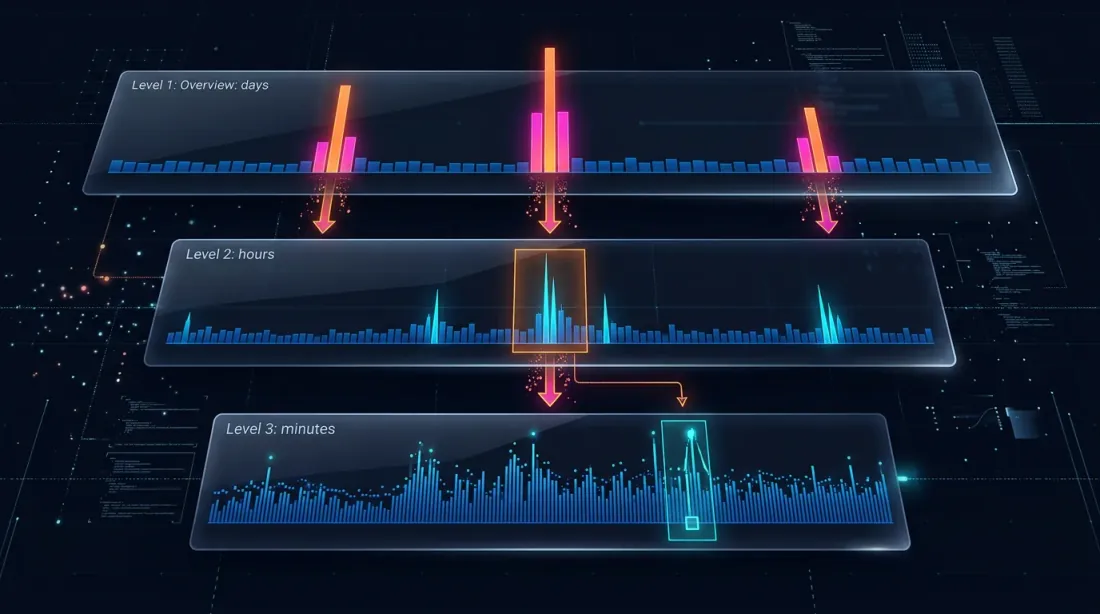
Drill-Down: Strategia a Quattro Livelli

L'idea del drill-down: iniziare al livello del minuto e "scendere" a un livello inferiore solo in presenza di ambiguità — a causa di movimenti di prezzo o picchi di volume.
Livello 1: 1m (candele al minuto)
-> Se SL o TP è inequivocabilmente al di fuori dell'intervallo [low, high] — risolvi sul posto
-> Se entrambi sono nell'intervallo — drill-down
Livello 2: 1s (candele al secondo)
-> Carica 60 barre al secondo per questo minuto
-> Passa secondo per secondo: quale è scattato per primo?
-> Se una barra al secondo è ambigua, O price_move >= min_pct, O volume >= median_1s * vol_mult — drill-down
Livello 3: 100ms (candele ai millisecondi)
-> Carica fino a 10 barre di 100ms per questo secondo
-> Passa 100ms per 100ms
-> Se una barra di 100ms è ambigua, O price_move >= min_pct, O volume >= median_100ms * vol_mult — drill-down
Livello 4: Trade grezzi
-> Carica i trade individuali per questo bucket di 100ms
-> Risolvi l'esecuzione a livello di singolo trade — massima precisione possibile
Quando il Drill-Down Non È Necessario
Nel 95% dei casi, il drill-down non è necessario. Scenari tipici:
SL inequivocabile: il high della candela non raggiunge il TP, il low rompe lo SL -> SL scattato, nessun drill-down necessario.
TP inequivocabile: il low non raggiunge lo SL, il high rompe il TP -> TP scattato, nessun drill-down necessario.
Nessuno scattato: entrambi i livelli sono al di fuori dell'intervallo -> la posizione rimane aperta.
Rilevamento del gap: l'open della candela successiva salta oltre SL o TP -> esecuzione al prezzo di open, nessun drill-down.
Il drill-down è necessario solo per circa il 5% delle barre — quando entrambi i livelli ricadono nell'intervallo di una singola candela.
class AdaptiveFillSimulator:
"""
Drill-down a quattro livelli per determinare l'ordine di esecuzione.
"""
def __init__(self, data_loader):
self.loader = data_loader
self.cache_1s = {} # Cache dei dati al secondo per mese
def check_fill(self, timestamp, candle_1m, sl_price, tp_price, side):
"""
Controlla se SL o TP è scattato sulla candela al minuto data.
Restituisce: ('sl', fill_price) | ('tp', fill_price) | None
"""
low, high = candle_1m['low'], candle_1m['high']
open_price = candle_1m['open']
if side == 'long':
if open_price <= sl_price:
return ('sl', open_price)
if open_price >= tp_price:
return ('tp', open_price)
else:
if open_price >= sl_price:
return ('sl', open_price)
if open_price <= tp_price:
return ('tp', open_price)
sl_hit = self._level_hit(sl_price, low, high, side, 'sl')
tp_hit = self._level_hit(tp_price, low, high, side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if not sl_hit and not tp_hit:
return None
return self._drill_down_1s(timestamp, sl_price, tp_price, side)
def _drill_down_1s(self, minute_ts, sl_price, tp_price, side):
"""Livello 2: passaggio secondo per secondo."""
bars_1s = self.loader.load_1s_for_minute(minute_ts)
if bars_1s is None or len(bars_1s) == 0:
return self._pessimistic_fill(side, sl_price, tp_price)
for bar in bars_1s:
sl_hit = self._level_hit(sl_price, bar['low'], bar['high'], side, 'sl')
tp_hit = self._level_hit(tp_price, bar['low'], bar['high'], side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if sl_hit and tp_hit:
result = self._drill_down_100ms(bar['timestamp'], sl_price, tp_price, side)
if result:
return result
return self._pessimistic_fill(side, sl_price, tp_price)
def _pessimistic_fill(self, side, sl_price, tp_price):
"""Ipotesi pessimistica: SL per long, TP per short."""
if side == 'long':
return ('sl', sl_price)
else:
return ('sl', sl_price)
Prestazioni
| Modalità | Tempo per controllo di esecuzione | Quando viene usata |
|---|---|---|
| 1m (nessun drill-down) | ~0ms | ~95% dei casi |
| Drill-down 1s | ~5ms (primo accesso al mese) | ~5% dei casi |
| Drill-down 100ms | ~1ms | <0,5% dei casi |
| Drill-down trade grezzi | ~0,5ms | <0,1% dei casi |
Su un backtest di 2 anni con ~400 trade, il drill-down viene invocato per circa 20 candele. L'overhead totale — meno di 1 secondo per l'intero backtest.
Archiviazione Adattiva dei Dati
Il drill-down richiede dati al secondo e al millisecondo. Ma archiviare tutto alla massima granularità è impraticabile:
| Granularità | Barre in 2 anni | Dimensione Parquet |
|---|---|---|
| 1m | ~1,05M | ~15 MB |
| 1s | ~63M | ~550 MB/mese |
| 100ms | ~630M | ~5 GB/mese |
Un archivio completo a 1s su 2 anni è circa 13 GB. 100ms — oltre 100 GB. Archiviare tutto è possibile ma dispendioso, considerando che il drill-down utilizza meno dell'1% di questi dati.
Rilevamento dei Secondi Caldi
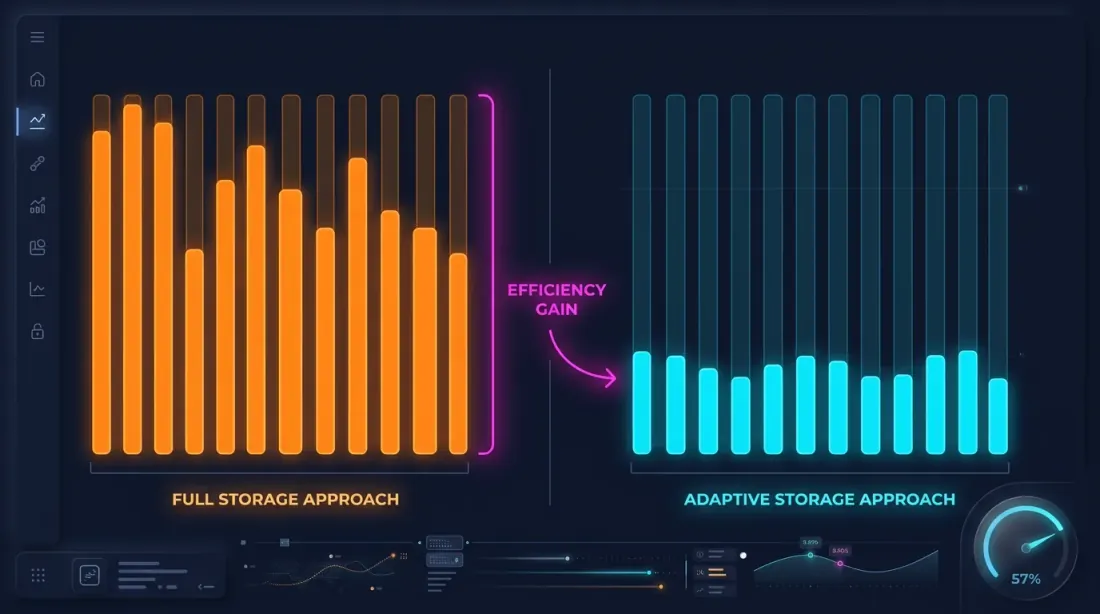
L'osservazione chiave: i secondi in cui il prezzo si muove significativamente rappresentano una piccola frazione. Se il prezzo è cambiato di meno dello 0,1% all'interno di un secondo — non ha senso memorizzare la scomposizione a 100ms per quel secondo.
Rilevamento dei secondi caldi: durante il download e l'elaborazione dei dati, analizziamo ogni secondo e generiamo candele a 100ms solo per i secondi "caldi" — quelli in cui il movimento di prezzo ha superato la soglia.
def process_trades_adaptive(
trades: pd.DataFrame,
min_price_change_pct: float = 1.0,
) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Elabora i trade grezzi in una struttura adattiva:
- Candele 1s per tutti i secondi
- Candele 100ms solo per i secondi "caldi"
Args:
trades: DataFrame con colonne [timestamp, price, quantity]
min_price_change_pct: soglia per il drill-down a 100ms
Returns:
(df_1s, df_100ms_hot) — candele al secondo e 100ms per i secondi caldi
"""
trades['second'] = trades['timestamp'].dt.floor('1s')
df_1s = trades.groupby('second').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
df_1s['price_change_pct'] = (df_1s['high'] - df_1s['low']) / df_1s['open'] * 100
hot_seconds = df_1s[df_1s['price_change_pct'] >= min_price_change_pct].index
hot_trades = trades[trades['second'].isin(hot_seconds)]
hot_trades['bucket_100ms'] = hot_trades['timestamp'].dt.floor('100ms')
df_100ms = hot_trades.groupby('bucket_100ms').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
return df_1s, df_100ms
Risparmio nell'Archiviazione
Ad esempio — ETHUSDT in un mese tipico:
| Approccio | Dimensione | Granularità |
|---|---|---|
| Solo 1m | ~1 MB | 1 minuto |
| Tutto 1s | ~550 MB | 1 secondo |
| Tutto 100ms | ~5 GB | 100 ms |
| Adattivo | ~600 MB | 1s + 100ms solo per i secondi caldi |
Con una soglia di min_price_change_pct = 1,0%, i secondi caldi rappresentano meno dell'1% di tutti i secondi. I dati a 100ms per essi aggiungono ~50 MB ai 550 MB di dati al secondo — un overhead trascurabile.
Se anche i dati al secondo vengono archiviati adattativamente (solo quando il movimento all'interno di un minuto supera lo 0,1%), il volume può essere ridotto di un ulteriore 3-5x.
Struttura dell'Archiviazione Parquet
data/{SYMBOL}/
├── source.json # Sorgente exchange: {"exchange": "binance"} o {"exchange": "bybit"}
├── stats.json # Volumi mediani precomputed: {"median_volume_1s": ..., "median_volume_100ms": ...}
├── klines_1m/
│ ├── 2024-01.parquet # ~1 MB
│ ├── 2024-02.parquet
│ └── ...
├── klines_1s/
│ ├── 2024-01.parquet # ~550 MB
│ └── ...
├── klines_100ms_hot/
│ ├── 2024-01.parquet # ~50 MB (solo secondi caldi)
│ └── ...
├── trades_hot/
│ ├── 2024-01.parquet # Trade grezzi per i bucket 100ms caldi
│ └── ...
└── states_1m.parquet # Cache dello stato rolling precomputed (~112 MB)
Ogni file copre un mese di dati. I dati al secondo, al millisecondo e i trade vengono caricati in modo lazy — solo quando il drill-down li richiede. Il file stats.json contiene i volumi mediani precomputed utilizzati per i trigger di drill-down basati sul volume.
Ottimizzazione Parquet per Dati Finanziari
I dati finanziari hanno caratteristiche specifiche: i timestamp crescono monotonicamente, i prezzi cambiano in modo graduale, i volumi variano significativamente. Impostazioni ottimali:
import pyarrow as pa
import pyarrow.parquet as pq
schema = pa.schema([
pa.field("timestamp", pa.int32()), # Secondi dall'epoch — int32 è sufficiente
pa.field("open", pa.float32()),
pa.field("high", pa.float32()),
pa.field("low", pa.float32()),
pa.field("close", pa.float32()),
pa.field("volume", pa.float32()),
])
column_encodings = {
"timestamp": "DELTA_BINARY_PACKED", # Int monotono -> compressione delta
"open": "BYTE_STREAM_SPLIT", # Float -> byte-stream split
"high": "BYTE_STREAM_SPLIT",
"low": "BYTE_STREAM_SPLIT",
"close": "BYTE_STREAM_SPLIT",
"volume": "BYTE_STREAM_SPLIT",
}
def save_optimized_parquet(df, path):
table = pa.Table.from_pandas(df, schema=schema)
pq.write_table(
table, path,
compression="zstd",
compression_level=9,
use_dictionary=False,
write_statistics=False,
column_encoding=column_encodings,
)
Perché queste impostazioni:
- DELTA_BINARY_PACKED per i timestamp: i timestamp consecutivi differiscono di un valore fisso (60 per 1m, 1 per 1s). La codifica delta li comprime a quasi zero.
- BYTE_STREAM_SPLIT per i float: divide i byte di float32 in stream (tutti i primi byte insieme, tutti i secondi byte insieme, ecc.). Per prezzi che cambiano gradualmente, si ottiene una compressione 2-3x migliore rispetto alla codifica standard.
- ZSTD livello 9: buona compressione con velocità di decompressione accettabile.
- float32 invece di float64: sufficiente per prezzi e volumi, risparmia il 50% di memoria.
Caricamento Lazy con Caching
Il drill-down richiede dati al secondo per un minuto specifico. Caricare un file parquet per ogni richiesta è lento. La soluzione — caricamento lazy con cache LRU per mese.
from functools import lru_cache
import pyarrow.parquet as pq
import pandas as pd
class AdaptiveDataLoader:
"""
Loader lazy con cache: carica i dati al secondo per mese,
mantiene gli ultimi N mesi in memoria.
"""
def __init__(self, symbol: str, data_dir: str = "data", cache_months: int = 2):
self.symbol = symbol
self.data_dir = data_dir
self.cache_months = cache_months
self._cache_1s: dict[str, pd.DataFrame] = {}
def load_1s_for_minute(self, minute_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Carica i dati 1s per un minuto specifico."""
month_key = minute_ts.strftime("%Y-%m")
if month_key not in self._cache_1s:
self._load_month_1s(month_key)
if month_key not in self._cache_1s:
return None
df = self._cache_1s[month_key]
minute_start = minute_ts.floor('1min')
minute_end = minute_start + pd.Timedelta(minutes=1)
return df[(df.index >= minute_start) & (df.index < minute_end)]
def load_100ms_for_second(self, second_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Carica i dati 100ms per un secondo caldo."""
month_key = second_ts.strftime("%Y-%m")
path = f"{self.data_dir}/{self.symbol}/klines_100ms_hot/{month_key}.parquet"
try:
df = pd.read_parquet(path)
second_start = second_ts.floor('1s')
second_end = second_start + pd.Timedelta(seconds=1)
return df[(df.index >= second_start) & (df.index < second_end)]
except FileNotFoundError:
return None
def _load_month_1s(self, month_key: str):
"""Carica un mese di dati 1s, espelle i vecchi dati dalla cache."""
path = f"{self.data_dir}/{self.symbol}/klines_1s/{month_key}.parquet"
try:
df = pd.read_parquet(path)
df.index = pd.to_datetime(df['timestamp'], unit='s')
if len(self._cache_1s) >= self.cache_months:
oldest = min(self._cache_1s.keys())
del self._cache_1s[oldest]
self._cache_1s[month_key] = df
except FileNotFoundError:
pass
Applicazione del Drill-Down al Backtesting
Integrazione nel loop del backtest:
def backtest_with_adaptive_fill(
states: pd.DataFrame,
strategy_params: dict,
data_loader: AdaptiveDataLoader,
) -> list:
"""
Backtest con drill-down adattivo per la simulazione dell'esecuzione.
"""
fill_sim = AdaptiveFillSimulator(data_loader)
trades = []
position = None
for i in range(len(states)):
row = states.iloc[i]
ts = states.index[i]
candle_1m = {
'open': row['open'], 'high': row['high'],
'low': row['low'], 'close': row['close'],
'timestamp': ts,
}
if position is not None:
fill = fill_sim.check_fill(
ts, candle_1m,
position['sl'], position['tp'],
position['side'],
)
if fill is not None:
fill_type, fill_price = fill
trades.append({
'entry_time': position['entry_time'],
'exit_time': ts,
'side': position['side'],
'entry_price': position['entry_price'],
'exit_price': fill_price,
'exit_type': fill_type,
'drill_down': fill_sim.last_drill_depth, # 0, 1, o 2
})
position = None
continue
signal = check_entry_signal(row, strategy_params)
if signal and position is None:
position = {
'side': signal['side'],
'entry_price': row['close'],
'entry_time': ts,
'sl': signal['sl'],
'tp': signal['tp'],
}
return trades
Relazione con la Cache dello Stato Rolling
Il drill-down complementa la cache parquet aggregata — risolvono problemi diversi:
| Cache stato rolling | Drill-down adattivo | |
|---|---|---|
| Scopo | Valori corretti degli indicatori HTF | Ordine preciso di esecuzione SL/TP |
| Opera su | Ogni candela 1m | Solo durante l'ambiguità di esecuzione (~5%) |
| Dati | Precomputed, archiviati in modo permanente | Caricati lazy, cache dei mesi recenti |
| Influisce su | Segnali di entrata/uscita | Prezzo e ora di esecuzione |
Entrambi gli approcci eliminano gli errori invisibili a livello di candela giornaliera ma critici per un backtesting realistico.
Riepilogo: Confronto degli Approcci di Simulazione dell'Esecuzione
| Approccio | Precisione | Velocità | Archiviazione |
|---|---|---|---|
| Euristica OHLC (ottimista/pessimista) | Bassa | Istantanea | Solo 1m |
| Backtest completo 1s | Alta | Lento (x60) | ~550 MB/mese |
| Backtest completo 100ms | Molto alta | Molto lento (x600) | ~5 GB/mese |
| Backtest completo trade grezzi | Massima | Estremamente lento | ~50 GB/mese |
| Drill-down adattivo (4 livelli) | Massima | ~Istantanea | 1m + 1s + 100ms caldo + trade caldi |
Il drill-down fornisce la precisione di un backtest completo a 1s alla velocità di un backtest a 1m. L'osservazione chiave: la granularità alta non è necessaria ovunque — solo nei punti di decisione.
Drill-Down Basato sul Volume
Il drill-down originale si attiva solo sul movimento di prezzo — quando l'intervallo [low, high] di una candela è abbastanza ampio da creare ambiguità di esecuzione. Ma il prezzo non è l'unico segnale che qualcosa di interessante è successo all'interno di una barra.
I picchi di volume sono un trigger altrettanto importante. Un secondo in cui il volume è 500 volte la mediana corrisponde tipicamente a un ordine di mercato di grandi dimensioni, una cascata di liquidazioni o un flash crash. Anche se il corpo della candela appare piccolo, il percorso effettivo del prezzo all'interno di quel secondo potrebbe essere stato selvaggio — toccando estremi che la rappresentazione OHLC nasconde.
La condizione di drill-down è ora basata sull'OR: sia un movimento significativo del prezzo SIA un picco di volume anomalo innesca la discesa a una granularità più fine.
def is_hot(bar, median_volume, min_pct=0.1, vol_mult=500):
"""
Determina se una barra richiede il drill-down al livello successivo.
Due trigger indipendenti (logica OR):
- il prezzo si è mosso >= min_pct all'interno della barra
- il volume ha superato median * vol_mult
"""
price_move = (bar['high'] - bar['low']) / bar['open'] * 100
return price_move >= min_pct or bar['volume'] >= median_volume * vol_mult
Questo cattura scenari invisibili al rilevamento solo basato sul prezzo: una barra con open=3000, close=3001 ma volume 50.000 volte la norma potrebbe aver toccato brevemente 2950 e 3050 in pochi millisecondi. Senza drill-down basato sul volume, il backtest non esaminerebbe mai questo secondo più da vicino.
Trade Grezzi: Il Quarto Livello
La gerarchia originale a tre livelli (1m -> 1s -> 100ms) lascia ancora una lacuna: all'interno di un singolo bucket di 100ms, possono essere eseguiti più trade a prezzi diversi. Per un bucket con high=3060 e low=2965, non conosciamo ancora la sequenza esatta.
La soluzione: drill-down ai trade grezzi come quarto e ultimo livello.
Candele 1m (base)
└─> Candele 1s (quando 1s mostra price_move >= min_pct OPPURE volume >= median_1s * vol_mult)
└─> Candele 100ms (quando viene rilevato un secondo caldo)
└─> Trade grezzi (quando 100ms mostra price_move >= min_pct OPPURE volume >= median_100ms * vol_mult)
Al livello dei trade grezzi, non c'è ambiguità — ogni trade ha un prezzo e un timestamp esatti. L'esecuzione viene risolta in modo definitivo:
def resolve_from_trades(trades, sl_price, tp_price, side):
"""
Scorre i trade individuali in ordine cronologico.
Il primo trade che attraversa SL o TP determina l'esecuzione.
"""
for trade in trades:
price = trade['price']
if side == 'long':
if price <= sl_price:
return ('sl', price)
if price >= tp_price:
return ('tp', price)
else: # short
if price >= sl_price:
return ('sl', price)
if price <= tp_price:
return ('tp', price)
return None
Il livello dei trade grezzi viene invocato estremamente raramente — meno dello 0,1% di tutte le barre — ma quando lo è, fornisce la ground truth che nessuna approssimazione basata su candele può eguagliare.
Soglie Separate per Transizione
Diverse transizioni di risoluzione hanno caratteristiche diverse. Un movimento di prezzo dello 0,1% all'interno di un secondo è significativo; lo stesso 0,1% all'interno di un bucket di 100ms è estremo. Analogamente, le distribuzioni di volume differiscono a ogni scala temporale.
Ogni transizione di livello ora ha i propri parametri min_pct e vol_mult:
1s → 100ms: --min-pct-1s 0.1 --vol-mult-1s 500
100ms → trades: --min-pct-100ms 0.1 --vol-mult-100ms 500
Questo consente di regolare finemente la sensibilità di ogni transizione in modo indipendente. In pratica, la transizione da 100ms a trade può usare una soglia più stretta perché il costo del caricamento dei trade grezzi per un singolo bucket di 100ms è minimo.
@dataclass
class DrillDownConfig:
min_pct_1s: float = 0.1
vol_mult_1s: float = 500
min_pct_100ms: float = 0.1
vol_mult_100ms: float = 500
Statistiche Mediane Persistenti
Il drill-down basato sul volume richiede la conoscenza del volume mediano a ogni scala temporale. Calcolare le mediane al volo per ogni backtest negherebbe i benefici di prestazione. La soluzione: precomputed le mediane una volta e metterle in cache.
Per ogni simbolo, i volumi mediani a granularità 1s e 100ms vengono calcolati dai dati storici e archiviati in un file stats.json:
{
"ETHUSDT": {
"median_volume_1s": 12.5,
"median_volume_100ms": 1.8
},
"BTCUSDT": {
"median_volume_1s": 0.45,
"median_volume_100ms": 0.06
}
}
Le statistiche vengono calcolate una volta per simbolo quando i dati vengono scaricati per la prima volta e riutilizzate in tutti i backtest successivi. Se i dati vengono aggiornati (nuovi mesi scaricati), le statistiche vengono ricalcolate in modo incrementale.
def compute_median_stats(symbol, data_dir):
"""Calcola e mette in cache le statistiche di volume mediano per un simbolo."""
stats_path = f"{data_dir}/{symbol}/stats.json"
all_1s = load_all_months(f"{data_dir}/{symbol}/klines_1s/")
median_1s = all_1s['volume'].median()
all_100ms = load_all_months(f"{data_dir}/{symbol}/klines_100ms_hot/")
median_100ms = all_100ms['volume'].median()
stats = {
"median_volume_1s": float(median_1s),
"median_volume_100ms": float(median_100ms),
}
with open(stats_path, 'w') as f:
json.dump(stats, f, indent=2)
return stats

Supporto Multi-Exchange: Bybit
Non tutti i simboli sono disponibili su Binance. Per asset come XAUTUSDT (oro), i dati devono provenire da altri exchange. Il sistema di drill-down ora supporta Bybit come sorgente di dati alternativa.
Per i simboli Bybit, tutti i livelli di candele (1m, 1s, 100ms) e i trade grezzi vengono costruiti dal flusso di trade grezzi di Bybit. Il processo è lo stesso — i trade grezzi vengono aggregati in candele a ogni scala temporale — ma la sorgente dati è diversa.
data/{SYMBOL}/
├── source.json # {"exchange": "bybit"} o {"exchange": "binance"}
├── klines_1m/
│ └── ...
├── klines_1s/
│ └── ...
├── klines_100ms_hot/
│ └── ...
└── trades_hot/ # Trade grezzi per i bucket 100ms caldi
└── ...
Il data loader controlla source.json e utilizza la pipeline di download appropriata. Dal punto di vista del motore di backtest, il formato dei dati è identico indipendentemente dall'exchange sorgente — la logica di drill-down è agnostica rispetto all'exchange.
Questo è particolarmente importante per le strategie cross-exchange o per i simboli che vengono scambiati esclusivamente su determinati venue.
Conclusione
Il drill-down adattivo è l'applicazione di un principio semplice: spendi risorse computazionali e di archiviazione in modo proporzionale all'importanza dei dati.
Quattro livelli di granularità:
- 1m — passaggio base per il 95% delle barre
- 1s — drill-down durante l'ambiguità di esecuzione o i picchi di volume
- 100ms — drill-down per i secondi caldi con movimento estremo o volume anomalo
- Trade grezzi — drill-down per i bucket 100ms caldi, risoluzione delle esecuzioni a livello di singolo trade
Quattro livelli di archiviazione:
- Tutti 1m — archivio completo, ~15 MB per 2 anni
- Tutti 1s — archivio completo o adattivo, ~550 MB/mese
- Solo 100ms caldi — <1% dei secondi, ~50 MB/mese
- Solo trade caldi — trade grezzi per i bucket 100ms più estremi
Due trigger di drill-down (logica OR):
- Basato sul prezzo: l'intervallo di prezzo della barra supera
min_pct - Basato sul volume: il volume della barra supera
median * vol_mult
Il risultato: un backtest con la precisione di un simulatore tick alla velocità del livello al minuto. Archiviazione che cresce linearmente, non esponenzialmente. E supporto per più exchange — Binance e Bybit — con logica di drill-down agnostica rispetto all'exchange.
Per ulteriori informazioni sulla cache precomputed per strategie multi-timeframe, vedere l'articolo Cache Parquet Aggregata. Sull'impatto dei funding rate sui risultati con leva alta — I funding rate distruggono la tua leva.
Link Utili
- Apache Parquet — formato di archiviazione dati
- Apache Arrow — codifica BYTE_STREAM_SPLIT
- Zstandard — algoritmo di compressione
- Lopez de Prado — Advances in Financial Machine Learning
- Binance — Historical Market Data
Citazione
@article{soloviov2026adaptivedrilldown,
author = {Soloviov, Eugen},
title = {Adaptive Drill-Down: Backtest with Variable Granularity from Minutes to Raw Trades},
year = {2026},
url = {https://marketmaker.cc/it/blog/post/adaptive-resolution-drill-down-backtest},
description = {Come la granularità adattiva dei dati accelera i backtest e risparmia spazio di archiviazione: drill-down da 1m a 1s, 100ms e trade grezzi solo dove il prezzo si è mosso significativamente o il volume è aumentato.}
}
Autori

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Leggi di Più

Cache Parquet Aggregata: Come Accelerare i Backtest Multi-Timeframe di Centinaia di Volte

Walk-Forward Optimization: L'Unico Test Onesto per una Strategia
