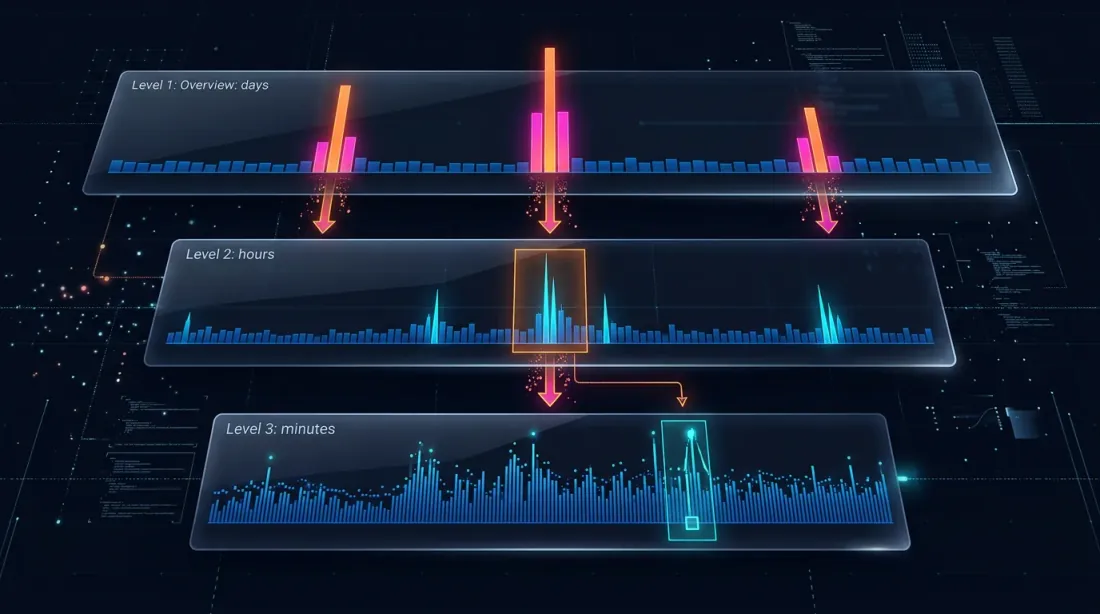
アダプティブ・ドリルダウン:分足から生ティックまでの可変粒度バックテスト
分足はバックテストの標準的な粒度です。しかし、1本の分足の中で価格の動き方は異なります:0.01%しか動かないこともあれば、2%動くこともあります。ストップロスとテイクプロフィットの両方が1本の分足の[low, high]レンジ内にある場合、バックテストはどちらが先にトリガーされたかを判定できません。これが約定曖昧性問題(fill ambiguity problem)です。
単純な解決策は、バックテスト全体を秒足データに切り替えることです。しかし2年間では、約100万本の分足の代わりに約6,300万本の秒足が必要になります。ストレージは60倍に増加し、速度も比例して低下します。
アダプティブ・ドリルダウンはこの問題を解決します:実際に必要な箇所だけ高粒度を使用する。
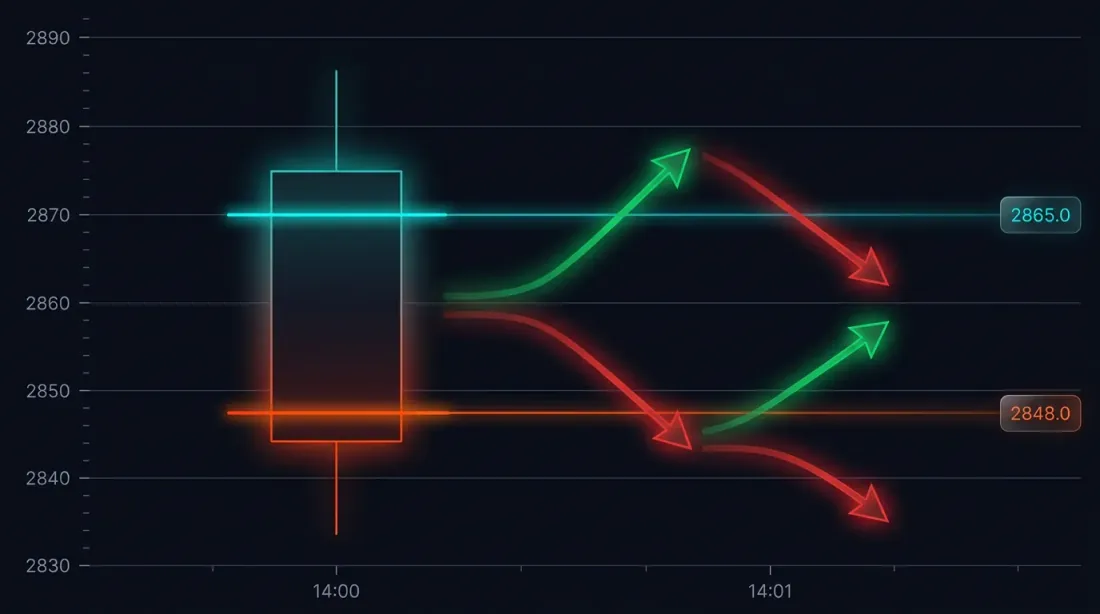
問題:大きなローソク足での約定曖昧性
具体的な状況を考えてみましょう。戦略が3000 USDTでロングをオープンしました。ストップロス:2970(-1%)。テイクプロフィット:3060(+2%)。
14:37の分足:
- 始値:3010
- 高値:3065
- 安値:2965
- 終値:3050
SL(2970)とTP(3060)の両方がレンジ[2965, 3065]内にあります。どちらが先にトリガーされたのでしょうか?
考えられる結果:
- 価格が先に下落 -> SLがトリガー -> -1%の損失
- 価格が先に上昇 -> TPがトリガー -> +2%の利益
1回の取引での差:3パーセントポイント。10倍レバレッジなら30%です。数百の取引を含むバックテストでは、約定曖昧性の誤った解決が結果を体系的に歪めます。
フレームワークのデフォルト処理方法
ほとんどのバックテストエンジンは2つのヒューリスティックのいずれかを使用します:
- 楽観的: TPが先にトリガー -> 結果が膨張
- 悲観的: SLが先にトリガー -> 結果が縮小
どちらのアプローチも推測です。秒単位やミリ秒単位のリアルデータが利用可能であり、確認できるのに推測する理由はありません。
ドリルダウン:4段階戦略

ドリルダウンのアイデア:分足レベルから開始し、曖昧性がある場合のみ(価格変動またはボリュームスパイクにより)下位レベルに「ドリルダウン」します。
Level 1: 1m(分足)
-> SLまたはTPが明確に[low, high]レンジ外にある場合 — その場で解決
-> 両方がレンジ内にある場合 — ドリルダウン
Level 2: 1s(秒足)
-> この分の60本の秒足をロード
-> 秒ごとに確認:どちらが先にトリガーされたか?
-> 秒足が曖昧、またはprice_move >= min_pct、またはvolume >= median_1s * vol_mult の場合 — ドリルダウン
Level 3: 100ms(ミリ秒足)
-> この秒の最大10本の100msバーをロード
-> 100msごとに確認
-> 100msバーが曖昧、またはprice_move >= min_pct、またはvolume >= median_100ms * vol_mult の場合 — ドリルダウン
Level 4: 生ティック
-> この100msバケットの個別取引をロード
-> ティック単位で約定を解決 — 最大精度
ドリルダウンが不要な場合
95%のケースでドリルダウンは不要です。典型的なシナリオ:
明確なSL: ローソク足の高値がTPに到達せず、安値がSLを突破 -> SLがトリガー、ドリルダウン不要。
明確なTP: 安値がSLに到達せず、高値がTPを突破 -> TPがトリガー、ドリルダウン不要。
どちらもトリガーされない: 両方のレベルがレンジ外 -> ポジション維持。
ギャップ検出: 次のローソク足の始値がSLまたはTPをジャンプ -> 始値で約定、ドリルダウン不要。
ドリルダウンが必要なのは約5%のバーのみ — 両方のレベルが1本のローソク足のレンジ内にある場合です。
class AdaptiveFillSimulator:
"""
Four-level drill-down for determining fill order.
"""
def __init__(self, data_loader):
self.loader = data_loader
self.cache_1s = {} # Cache of second data by month
def check_fill(self, timestamp, candle_1m, sl_price, tp_price, side):
"""
Checks whether SL or TP triggered on the given minute candle.
Returns: ('sl', fill_price) | ('tp', fill_price) | None
"""
low, high = candle_1m['low'], candle_1m['high']
open_price = candle_1m['open']
if side == 'long':
if open_price <= sl_price:
return ('sl', open_price)
if open_price >= tp_price:
return ('tp', open_price)
else:
if open_price >= sl_price:
return ('sl', open_price)
if open_price <= tp_price:
return ('tp', open_price)
sl_hit = self._level_hit(sl_price, low, high, side, 'sl')
tp_hit = self._level_hit(tp_price, low, high, side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if not sl_hit and not tp_hit:
return None
return self._drill_down_1s(timestamp, sl_price, tp_price, side)
def _drill_down_1s(self, minute_ts, sl_price, tp_price, side):
"""Level 2: second-by-second pass."""
bars_1s = self.loader.load_1s_for_minute(minute_ts)
if bars_1s is None or len(bars_1s) == 0:
return self._pessimistic_fill(side, sl_price, tp_price)
for bar in bars_1s:
sl_hit = self._level_hit(sl_price, bar['low'], bar['high'], side, 'sl')
tp_hit = self._level_hit(tp_price, bar['low'], bar['high'], side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if sl_hit and tp_hit:
result = self._drill_down_100ms(bar['timestamp'], sl_price, tp_price, side)
if result:
return result
return self._pessimistic_fill(side, sl_price, tp_price)
def _pessimistic_fill(self, side, sl_price, tp_price):
"""Pessimistic assumption: SL for longs, TP for shorts."""
if side == 'long':
return ('sl', sl_price)
else:
return ('sl', sl_price)
パフォーマンス
| モード | 約定チェックあたりの時間 | 使用場面 |
|---|---|---|
| 1m(ドリルダウンなし) | 約0ms | 約95%のケース |
| 1sドリルダウン | 約5ms(月の最初のアクセス時) | 約5%のケース |
| 100msドリルダウン | 約1ms | <0.5%のケース |
| 生ティックドリルダウン | 約0.5ms | <0.1%のケース |
2年間のバックテストで約400回の取引がある場合、ドリルダウンは約20本のローソク足に対して呼び出されます。合計オーバーヘッドはバックテスト全体で1秒未満です。
アダプティブ・データストレージ
ドリルダウンには秒足やミリ秒足のデータが必要です。しかし、すべてを最大粒度で保存するのは非現実的です:
| 粒度 | 2年間のバー数 | Parquetサイズ |
|---|---|---|
| 1m | 約105万 | 約15 MB |
| 1s | 約6,300万 | 約550 MB/月 |
| 100ms | 約6億3,000万 | 約5 GB/月 |
2年間の完全な1sアーカイブは約13 GBです。100msは100 GB以上。すべてを保存することは可能ですが、ドリルダウンがこのデータの1%未満しか使用しないことを考えると無駄です。
ホットセカンド検出
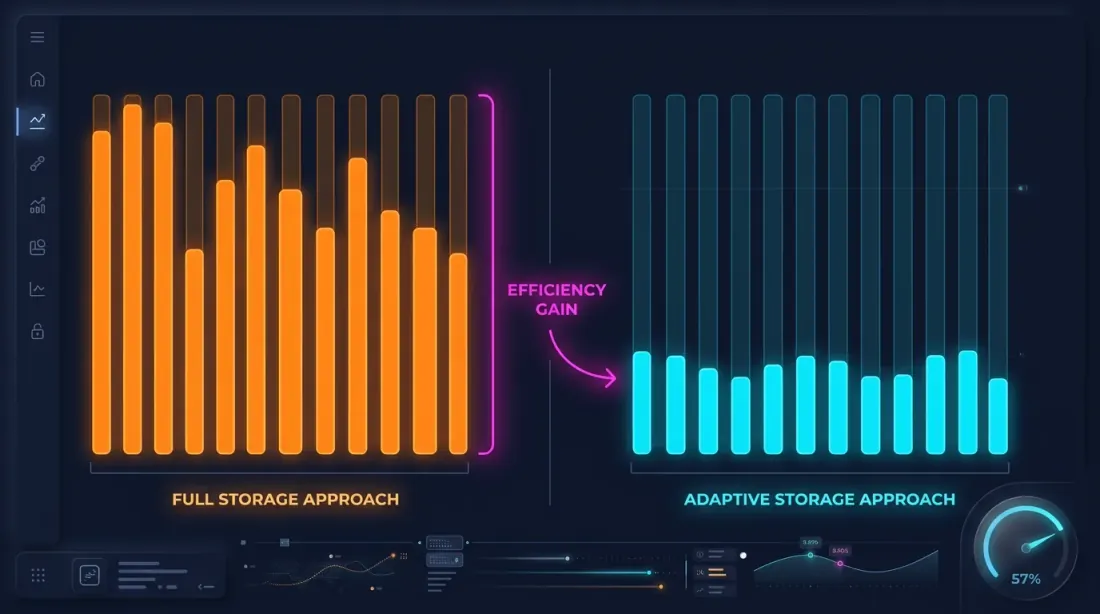
重要な観察:価格が大きく動く秒は全体のごく一部です。1秒以内に価格が0.1%未満しか変動しなければ、その秒の100ms内訳を保存する意味はありません。
ホットセカンド検出:データをダウンロード・処理する際に、各秒を分析し、「ホット」な秒 — 価格変動がしきい値を超えた秒のみ100msローソク足を生成します。
def process_trades_adaptive(
trades: pd.DataFrame,
min_price_change_pct: float = 1.0,
) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Processes raw trades into an adaptive structure:
- 1s candles for all seconds
- 100ms candles only for "hot" seconds
Args:
trades: DataFrame with columns [timestamp, price, quantity]
min_price_change_pct: threshold for drill-down to 100ms
Returns:
(df_1s, df_100ms_hot) — second candles and 100ms for hot seconds
"""
trades['second'] = trades['timestamp'].dt.floor('1s')
df_1s = trades.groupby('second').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
df_1s['price_change_pct'] = (df_1s['high'] - df_1s['low']) / df_1s['open'] * 100
hot_seconds = df_1s[df_1s['price_change_pct'] >= min_price_change_pct].index
hot_trades = trades[trades['second'].isin(hot_seconds)]
hot_trades['bucket_100ms'] = hot_trades['timestamp'].dt.floor('100ms')
df_100ms = hot_trades.groupby('bucket_100ms').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
return df_1s, df_100ms
ストレージの節約
例として — 典型的な月のETHUSDT:
| アプローチ | サイズ | 粒度 |
|---|---|---|
| 1mのみ | 約1 MB | 1分 |
| 全1s | 約550 MB | 1秒 |
| 全100ms | 約5 GB | 100 ms |
| アダプティブ | 約600 MB | 1s + ホットセカンドのみ100ms |
min_price_change_pct = 1.0%のしきい値では、ホットセカンドは全秒の1%未満です。それらの100msデータは550 MBの秒データに約50 MBを追加するだけで、無視できるオーバーヘッドです。
秒データもアダプティブに保存する場合(分足内の変動が0.1%を超える場合のみ)、データ量をさらに3-5倍削減できます。
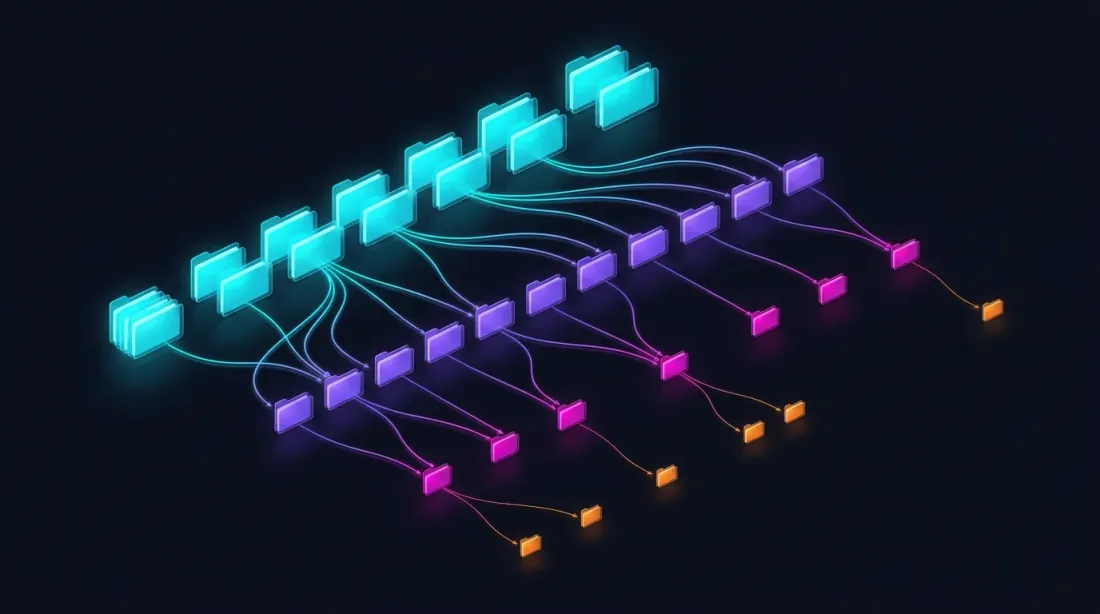
Parquetストレージ構造
data/{SYMBOL}/
├── source.json # 取引所ソース: {"exchange": "binance"} or {"exchange": "bybit"}
├── stats.json # 事前計算された中央値ボリューム: {"median_volume_1s": ..., "median_volume_100ms": ...}
├── klines_1m/
│ ├── 2024-01.parquet # ~1 MB
│ ├── 2024-02.parquet
│ └── ...
├── klines_1s/
│ ├── 2024-01.parquet # ~550 MB
│ └── ...
├── klines_100ms_hot/
│ ├── 2024-01.parquet # ~50 MB (hot seconds only)
│ └── ...
├── trades_hot/
│ ├── 2024-01.parquet # Raw trades for hot 100ms buckets
│ └── ...
└── states_1m.parquet # Precomputed rolling state cache (~112 MB)
各ファイルは1ヶ月のデータをカバーしています。秒、ミリ秒、取引データはレイジーロードされ、ドリルダウンが要求した場合のみロードされます。stats.jsonファイルには、ボリュームベースのドリルダウントリガーに使用される事前計算された中央値ボリュームが含まれています。
金融データ向けParquet最適化
金融データには特有の特性があります:タイムスタンプは単調増加し、価格は滑らかに変化し、ボリュームは大きく変動します。最適な設定:
import pyarrow as pa
import pyarrow.parquet as pq
schema = pa.schema([
pa.field("timestamp", pa.int32()), # Seconds from epoch — int32 is sufficient
pa.field("open", pa.float32()),
pa.field("high", pa.float32()),
pa.field("low", pa.float32()),
pa.field("close", pa.float32()),
pa.field("volume", pa.float32()),
])
column_encodings = {
"timestamp": "DELTA_BINARY_PACKED", # Monotonic int -> delta compression
"open": "BYTE_STREAM_SPLIT", # Float -> byte-stream split
"high": "BYTE_STREAM_SPLIT",
"low": "BYTE_STREAM_SPLIT",
"close": "BYTE_STREAM_SPLIT",
"volume": "BYTE_STREAM_SPLIT",
}
def save_optimized_parquet(df, path):
table = pa.Table.from_pandas(df, schema=schema)
pq.write_table(
table, path,
compression="zstd",
compression_level=9,
use_dictionary=False,
write_statistics=False,
column_encoding=column_encodings,
)
これらの設定の理由:
- DELTA_BINARY_PACKED(タイムスタンプ向け):連続するタイムスタンプの差は固定値です(1mなら60、1sなら1)。デルタエンコーディングによりほぼゼロに圧縮されます。
- BYTE_STREAM_SPLIT(float向け):float32のバイトをストリームに分割します(すべての第1バイトをまとめ、すべての第2バイトをまとめるなど)。滑らかに変化する価格に対して、標準エンコーディングより2-3倍良い圧縮率を実現します。
- ZSTD level 9:許容可能な展開速度で良好な圧縮率。
- float32(float64の代わり):価格とボリュームには十分で、メモリを50%節約します。
キャッシュ付きレイジーロード
ドリルダウンは特定の分の秒データを要求します。リクエストごとにparquetファイルをロードするのは遅いです。解決策 — 月単位のLRUキャッシュによるレイジーロード。
from functools import lru_cache
import pyarrow.parquet as pq
import pandas as pd
class AdaptiveDataLoader:
"""
Lazy loader with cache: loads second data by month,
keeps the last N months in memory.
"""
def __init__(self, symbol: str, data_dir: str = "data", cache_months: int = 2):
self.symbol = symbol
self.data_dir = data_dir
self.cache_months = cache_months
self._cache_1s: dict[str, pd.DataFrame] = {}
def load_1s_for_minute(self, minute_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Load 1s data for a specific minute."""
month_key = minute_ts.strftime("%Y-%m")
if month_key not in self._cache_1s:
self._load_month_1s(month_key)
if month_key not in self._cache_1s:
return None
df = self._cache_1s[month_key]
minute_start = minute_ts.floor('1min')
minute_end = minute_start + pd.Timedelta(minutes=1)
return df[(df.index >= minute_start) & (df.index < minute_end)]
def load_100ms_for_second(self, second_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Load 100ms data for a hot second."""
month_key = second_ts.strftime("%Y-%m")
path = f"{self.data_dir}/{self.symbol}/klines_100ms_hot/{month_key}.parquet"
try:
df = pd.read_parquet(path)
second_start = second_ts.floor('1s')
second_end = second_start + pd.Timedelta(seconds=1)
return df[(df.index >= second_start) & (df.index < second_end)]
except FileNotFoundError:
return None
def _load_month_1s(self, month_key: str):
"""Load a month of 1s data, evict old data from cache."""
path = f"{self.data_dir}/{self.symbol}/klines_1s/{month_key}.parquet"
try:
df = pd.read_parquet(path)
df.index = pd.to_datetime(df['timestamp'], unit='s')
if len(self._cache_1s) >= self.cache_months:
oldest = min(self._cache_1s.keys())
del self._cache_1s[oldest]
self._cache_1s[month_key] = df
except FileNotFoundError:
pass
バックテストへのドリルダウンの適用
バックテストループへの統合:
def backtest_with_adaptive_fill(
states: pd.DataFrame,
strategy_params: dict,
data_loader: AdaptiveDataLoader,
) -> list:
"""
Backtest with adaptive drill-down for fill simulation.
"""
fill_sim = AdaptiveFillSimulator(data_loader)
trades = []
position = None
for i in range(len(states)):
row = states.iloc[i]
ts = states.index[i]
candle_1m = {
'open': row['open'], 'high': row['high'],
'low': row['low'], 'close': row['close'],
'timestamp': ts,
}
if position is not None:
fill = fill_sim.check_fill(
ts, candle_1m,
position['sl'], position['tp'],
position['side'],
)
if fill is not None:
fill_type, fill_price = fill
trades.append({
'entry_time': position['entry_time'],
'exit_time': ts,
'side': position['side'],
'entry_price': position['entry_price'],
'exit_price': fill_price,
'exit_type': fill_type,
'drill_down': fill_sim.last_drill_depth, # 0, 1, or 2
})
position = None
continue
signal = check_entry_signal(row, strategy_params)
if signal and position is None:
position = {
'side': signal['side'],
'entry_price': row['close'],
'entry_time': ts,
'sl': signal['sl'],
'tp': signal['tp'],
}
return trades
ローリングステートキャッシュとの関係
ドリルダウンは集約Parquetキャッシュを補完するもので、それぞれ異なる問題を解決します:
| ローリングステートキャッシュ | アダプティブ・ドリルダウン | |
|---|---|---|
| 目的 | 正確なHTFインジケーター値 | 正確なSL/TP約定順序 |
| 対象 | 全1m足 | 約定曖昧性時のみ(約5%) |
| データ | 事前計算、永続保存 | レイジーロード、直近月のキャッシュ |
| 影響 | エントリー/イグジットシグナル | 約定価格と時間 |
どちらのアプローチも、日足レベルでは見えないがリアルなバックテストには不可欠なエラーを排除します。
まとめ:約定シミュレーション・アプローチの比較
| アプローチ | 精度 | 速度 | ストレージ |
|---|---|---|---|
| OHLCヒューリスティック(楽観/悲観) | 低 | 即時 | 1mのみ |
| 全1sバックテスト | 高 | 低速(x60) | 約550 MB/月 |
| 全100msバックテスト | 非常に高い | 非常に低速(x600) | 約5 GB/月 |
| 全生ティックバックテスト | 最大 | 極めて低速 | 約50 GB/月 |
| アダプティブ・ドリルダウン(4段階) | 最大 | ほぼ即時 | 1m + 1s + 100msホット + ティックホット |
ドリルダウンは1mバックテストの速度で全1sバックテストの精度を提供します。重要な観察:高粒度はすべての場所で必要なのではなく、意思決定ポイントでのみ必要です。
ボリュームベースのドリルダウン
当初のドリルダウンは価格変動のみをトリガーとしていました — ローソク足の[low, high]レンジが約定曖昧性を生じさせるほど広い場合です。しかし、価格だけがバー内で何か興味深いことが起きたシグナルではありません。
ボリュームスパイクも同様に重要なトリガーです。ボリュームが中央値の500倍ある秒は、通常、大口成行注文、ロスカットカスケード、またはフラッシュクラッシュに対応しています。ローソク足の実体が小さく見えても、その秒内の実際の価格パスは激しいものだった可能性があり、OHLC表現では隠される極値に触れていたかもしれません。
ドリルダウン条件はOR条件になりました:大きな価格変動または異常なボリュームスパイクのいずれかが、より細かい粒度への降下をトリガーします。
def is_hot(bar, median_volume, min_pct=0.1, vol_mult=500):
"""
Determines if a bar warrants drill-down to the next level.
Two independent triggers (OR logic):
- price moved >= min_pct within the bar
- volume exceeded median * vol_mult
"""
price_move = (bar['high'] - bar['low']) / bar['open'] * 100
return price_move >= min_pct or bar['volume'] >= median_volume * vol_mult
これにより、価格のみの検出では見えないシナリオを捉えます:始値=3000、終値=3001で通常の50,000倍のボリュームのバーは、ミリ秒以内に2950と3050に一時的に達していた可能性があります。ボリュームベースのドリルダウンがなければ、バックテストはこの秒をより詳しく調べることはありません。
生ティック:第4レベル
元の3段階階層(1m -> 1s -> 100ms)にはまだギャップがあります:1つの100msバケット内で、複数の取引が異なる価格で約定する可能性があります。高値=3060、安値=2965のバケットでは、正確なシーケンスはまだわかりません。
解決策:第4かつ最終レベルとして生ティックへのドリルダウン。
1m足(ベース)
└─> 1s足 (1sがprice_move >= min_pctまたはvolume >= median_1s * vol_multを示す場合)
└─> 100ms足 (ホットセカンド検出時)
└─> 生ティック (100msがprice_move >= min_pctまたはvolume >= median_100ms * vol_multを示す場合)
生ティックレベルでは曖昧性はありません — 各取引は正確な価格とタイムスタンプを持っています。約定は決定的に解決されます:
def resolve_from_trades(trades, sl_price, tp_price, side):
"""
Walk through individual trades in chronological order.
The first trade that crosses SL or TP determines the fill.
"""
for trade in trades:
price = trade['price']
if side == 'long':
if price <= sl_price:
return ('sl', price)
if price >= tp_price:
return ('tp', price)
else: # short
if price >= sl_price:
return ('sl', price)
if price <= tp_price:
return ('tp', price)
return None
生ティックレベルは非常にまれにしか呼び出されません — 全バーの0.1%未満 — しかし、呼び出された場合、ローソク足ベースの近似では得られないグラウンドトゥルースを提供します。
遷移ごとの個別しきい値
異なる解像度遷移には異なる特性があります。1秒以内の0.1%の価格変動は大きいですが、100msバケット内の同じ0.1%は極端です。同様に、ボリューム分布は各タイムスケールで異なります。
各レベル遷移に独自のmin_pctとvol_multパラメータが設定されています:
1s → 100ms: --min-pct-1s 0.1 --vol-mult-1s 500
100ms → trades: --min-pct-100ms 0.1 --vol-mult-100ms 500
これにより、各遷移の感度を個別に微調整できます。実際には、100msからティックへの遷移は、単一の100msバケットの生ティックをロードするコストが最小限であるため、より厳密なしきい値を使用できます。
@dataclass
class DrillDownConfig:
min_pct_1s: float = 0.1
vol_mult_1s: float = 500
min_pct_100ms: float = 0.1
vol_mult_100ms: float = 500
永続的な中央値統計
ボリュームベースのドリルダウンには、各タイムスケールでの中央値ボリュームを知る必要があります。毎回のバックテストでオンザフライで中央値を計算すると、パフォーマンスの利点が相殺されます。解決策:中央値を一度事前計算してキャッシュする。
各シンボルについて、1sおよび100ms粒度の中央値ボリュームが履歴データから計算され、stats.jsonファイルに保存されます:
{
"ETHUSDT": {
"median_volume_1s": 12.5,
"median_volume_100ms": 1.8
},
"BTCUSDT": {
"median_volume_1s": 0.45,
"median_volume_100ms": 0.06
}
}
統計はデータが最初にダウンロードされた時にシンボルごとに一度計算され、その後のすべてのバックテストで再利用されます。データが更新された場合(新しい月がダウンロードされた場合)、統計はインクリメンタルに再計算されます。
def compute_median_stats(symbol, data_dir):
"""Compute and cache median volume stats for a symbol."""
stats_path = f"{data_dir}/{symbol}/stats.json"
all_1s = load_all_months(f"{data_dir}/{symbol}/klines_1s/")
median_1s = all_1s['volume'].median()
all_100ms = load_all_months(f"{data_dir}/{symbol}/klines_100ms_hot/")
median_100ms = all_100ms['volume'].median()
stats = {
"median_volume_1s": float(median_1s),
"median_volume_100ms": float(median_100ms),
}
with open(stats_path, 'w') as f:
json.dump(stats, f, indent=2)
return stats

マルチ取引所サポート:Bybit
すべてのシンボルがBinanceで利用可能なわけではありません。XAUTUSDT(金)などのアセットについては、他の取引所からデータを取得する必要があります。ドリルダウンシステムは、代替データソースとしてBybitをサポートするようになりました。
Bybitシンボルの場合、すべてのローソク足レベル(1m、1s、100ms)と生ティックは、Bybitの生取引ストリームから構築されます。プロセスは同じで、生ティックが各タイムスケールのローソク足に集約されますが、データソースが異なります。
data/{SYMBOL}/
├── source.json # {"exchange": "bybit"} or {"exchange": "binance"}
├── klines_1m/
│ └── ...
├── klines_1s/
│ └── ...
├── klines_100ms_hot/
│ └── ...
└── trades_hot/ # Raw trades for hot 100ms buckets
└── ...
データローダーはsource.jsonをチェックし、適切なダウンロードパイプラインを使用します。バックテストエンジンの観点からは、ソース取引所に関係なくデータフォーマットは同一です — ドリルダウンロジックは取引所に依存しません。
これはクロス取引所戦略や特定の取引所でのみ取引されるシンボルにとって特に重要です。
結論
アダプティブ・ドリルダウンはシンプルな原則の適用です:計算リソースとストレージをデータの重要性に比例して使用する。
4つの粒度レベル:
- 1m — 95%のバーのベースパス
- 1s — 約定曖昧性またはボリュームスパイク時のドリルダウン
- 100ms — 極端な変動または異常なボリュームを持つホットセカンドのドリルダウン
- 生ティック — ホット100msバケットのドリルダウン、個別取引レベルでの約定解決
4つのストレージレベル:
- 全1m — 完全なアーカイブ、2年間で約15 MB
- 全1s — 完全またはアダプティブアーカイブ、約550 MB/月
- ホット100msのみ — 秒の<1%、約50 MB/月
- ホットティックのみ — 最も極端な100msバケットの生ティック
2つのドリルダウントリガー(OR論理):
- 価格ベース:バーの価格レンジが
min_pctを超える - ボリュームベース:バーのボリュームが
median * vol_multを超える
結果:ティックシミュレーター精度を持つバックテストが分足レベルの速度で実行されます。ストレージは指数関数的ではなく線形に増加します。そして複数の取引所 — BinanceとBybit — をサポートし、取引所に依存しないドリルダウンロジックを持ちます。
マルチタイムフレーム戦略の事前計算キャッシュについては、集約Parquetキャッシュの記事をご覧ください。高レバレッジ時のファンディングレートの結果への影響については、ファンディングレートがレバレッジを殺すをご覧ください。
参考リンク
- Apache Parquet — data storage format
- Apache Arrow — BYTE_STREAM_SPLIT encoding
- Zstandard — compression algorithm
- Lopez de Prado — Advances in Financial Machine Learning
- Binance — Historical Market Data
Citation
@article{soloviov2026adaptivedrilldown,
author = {Soloviov, Eugen},
title = {Adaptive Drill-Down: Backtest with Variable Granularity from Minutes to Raw Trades},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/adaptive-resolution-drill-down-backtest},
description = {How adaptive data granularity speeds up backtests and saves storage: drill-down from 1m to 1s, 100ms, and raw trades only where price moved significantly or volume spiked.}
}
MarketMaker.cc Team
クオンツ・リサーチ&戦略


