좌표 하강법 vs 베이지안 최적화: 어느 쪽이 더 좋은 파라미터를 찾는가
이 글은 "환상 없는 백테스트" 시리즈의 다섯 번째 기사입니다. 이전 기사에서는 손익 비대칭성, 몬테카를로 부트스트랩, 펀딩 비율의 영향, 멀티타임프레임 백테스트를 위한 Parquet 캐시를 다루었습니다. 이번에는 최적의 전략 파라미터를 찾는 과정에 대해 이야기하겠습니다 — 직관이 가장 자주 실패하는 작업입니다.
12개의 파라미터를 가진 전략이 있습니다. 각 파라미터는 약 9개의 값을 취합니다. 드로다운을 제한하면서 PnL을 최대화하는 조합을 찾고 싶습니다. 어떻게 하시겠습니까?
"모든 조합을 시도한다"가 답이라면 — 문제가 있습니다. "한 번에 하나의 파라미터를 변경한다"가 답이라면 — 다른 문제가 있습니다. 이 기사는 각 접근 방식에 숨겨진 문제와 해결 방법에 대한 것입니다.
전수 탐색이 불가능한 이유

차원의 저주
전수 탐색(그리드 서치)은 모든 파라미터의 모든 값 조합을 테스트합니다. 9개의 값을 가진 2개의 파라미터의 경우 회 실행으로 충분히 가능합니다. 3개의 경우: 회로 허용 가능합니다.
하지만 12개의 파라미터를 가진 실제 전략에서는:
2,820억 회의 실행입니다. 단일 백테스트가 1초(이미 낙관적인 추정)가 걸린다 해도, 전수 탐색에는:
이것은 지수적 성장입니다: 새로운 파라미터가 하나 추가될 때마다 탐색 공간이 9배 증가합니다. 13번째 파라미터를 추가하면 9,000년 대신 80,000년이 필요합니다.
import math
def grid_search_cost(n_params: int, values_per_param: int, seconds_per_trial: float) -> dict:
"""Estimate the cost of exhaustive search."""
total_trials = values_per_param ** n_params
total_seconds = total_trials * seconds_per_trial
return {
"total_trials": total_trials,
"total_hours": total_seconds / 3600,
"total_years": total_seconds / (3600 * 24 * 365),
}
cost = grid_search_cost(12, 9, 1.0)
print(f"Trials: {cost['total_trials']:,.0f}") # 282,429,536,481
print(f"Years: {cost['total_years']:,.0f}") # 8,950
사전 계산을 사용해도
Parquet 캐시 기사에서 타임프레임과 지표의 사전 계산으로 단일 백테스트를 약 1초로 가속하는 방법을 보여주었습니다. 하지만 실행당 0.1초라 해도 12개 파라미터의 전수 탐색에는 895년이 필요합니다. 사전 계산은 도움이 되지만, 지수적 증가의 근본적인 문제를 해결하지는 못합니다.
전수 탐색보다 더 똑똑하게 파라미터 공간을 탐색하는 방법이 필요합니다.
좌표 하강법과 OAT: 빠르지만 맹목적
같은 아이디어의 두 가지 변형
두 가지 관련 접근 방식이 있습니다 — 둘 다 한 번에 하나의 파라미터를 최적화하지만 패스 횟수가 다릅니다:
OAT(One-at-a-Time) 스윕 — 모든 파라미터를 한 번만 통과합니다. 첫 번째 파라미터의 값을 순회하고, 최적값을 고정한 뒤, 두 번째로 이동합니다 — 이렇게 계속합니다. 한 번만. 빠르고 저렴합니다.
좌표 하강법 — 다중 패스. 마지막 파라미터 최적화 후, 첫 번째로 돌아가 최적값이 변했는지 확인합니다(맥락이 변했으므로 — 다른 파라미터 값이 이제 다릅니다). 수렴할 때까지 라운드를 반복합니다. 더 비용이 들지만 더 정밀합니다 — 각 라운드에서 솔루션을 개선할 수 있습니다.
실제로 백테스트에서는 OAT가 더 자주 사용됩니다: 12개 파라미터의 단일 패스 — 96회 실행. 좌표 하강법은 3-5 라운드로 300-500회 실행이며, 이미 Optuna와 비슷하지만 그 장점은 없습니다.
각 파라미터가 약 8개의 값을 가진 12개 파라미터의 경우:
그리드 서치의 와 비교하세요. OAT는 선형입니다: 대신 . 이것이 가장 큰 장점이자 동시에 가장 큰 문제입니다.
def oat_sweep(
param_grid: dict[str, list],
run_backtest_fn,
initial_params: dict,
metric: str = "effective_score",
) -> dict:
"""
OAT sweep: single pass, optimizing one parameter at a time.
param_grid: {"htf_entry_sell": [0.0, 0.005, ..., 0.05], ...}
initial_params: starting values for all parameters
metric: metric to optimize (effective_score recommended —
PnL per active time extrapolated to a year)
"""
best_params = initial_params.copy()
best_score = run_backtest_fn(**best_params)[metric]
for param_name, values in param_grid.items():
param_best_val = best_params[param_name]
param_best_score = best_score
for val in values:
candidate = best_params.copy()
candidate[param_name] = val
result = run_backtest_fn(**candidate)
score = result[metric]
if score > param_best_score:
param_best_score = score
param_best_val = val
best_params[param_name] = param_best_val
best_score = param_best_score
print(f"{param_name}: best={param_best_val}, score={param_best_score:.4f}")
return best_params
최적화에 어떤 지표를 선택해야 하는가? 원시 PnL이나 PnL@MaxLev 대신, 연간으로 환산한 effective score — 활성 시간당 PnL을 사용하는 것을 권장합니다. 이 지표는 포지션 보유 시간을 고려하여 서로 다른 거래 빈도의 전략을 올바르게 비교할 수 있게 합니다.
맹점: 파라미터 상호작용
OAT는 각 파라미터의 효과가 가법적이라고 가정합니다 — 즉, 하나의 파라미터의 최적값이 다른 파라미터의 값에 의존하지 않는다는 것입니다. 이 가정은 일부 파라미터에서는 성립하지만, 결합된 파라미터에서는 무너집니다.
가법적 파라미터 vs 결합 파라미터
최적화 전에 파라미터를 분류하는 것이 유용합니다:
가법적(독립) — 하나의 최적값이 다른 것에 의존하지 않습니다. 개별적으로 저렴하게 최적화할 수 있습니다:
htf_entry_sell과htf_entry_buy— 같은 타임프레임에서 다른 방향(매도/매수)의 진입 임계값. 매도 임계값은 숏 시그널을 필터링하고, 매수 임계값은 롱을 필터링합니다. 겹치지 않는 트레이드 하위 집합에서 작동합니다.tp_target과be_trigger— 테이크프로핏과 손익분기점(상충하는 청산 조건을 만들지 않는 경우).
결합(상호작용) — 하나의 최적값이 다른 것에 의존합니다. 공동 최적화가 필요합니다:
htf_entry_sell과mtf_entry_sell— 서로 다른 타임프레임에서 같은 방향(매도)의 임계값. HTF는 어떤 시그널이 MTF에 도달하는지 결정하고, MTF 임계값은 필터링 효과를 결정합니다. MTF가 변하면 HTF 최적값이 이동합니다.ltf_entry_sell,mtf_entry_sell,htf_entry_sell— 한 방향의 전체 임계값 체인.partial_frac과tp_target— 부분 청산 크기는 TP 수준에 의존합니다.
실용적 접근: 먼저 가법적 파라미터를 OAT로 저렴하게 최적화합니다. 그런 다음 결합 그룹을 Optuna로 최적화합니다. 이렇게 하면 예산이 줄어듭니다: Optuna에 12개 파라미터 전부 대신 결합된 6-8개만 보내고, 나머지는 이미 고정됩니다.
예시: OAT가 상호작용을 놓치는 경우
두 개의 결합된 임계값을 고려합니다:
htf_entry_sell— 상위 타임프레임 임계값(매도 방향)mtf_entry_sell— 중간 타임프레임 임계값(매도 방향)
OAT는 mtf_entry_sell = 0.01(초기값)을 고정하고 htf_entry_sell의 값을 순회합니다. 최적값 발견: htf_entry_sell = 0.02. 이를 고정하고 다음 파라미터로 이동하며, 다시는 돌아오지 않습니다.
OAT가 놓친 것은 다음과 같습니다:
htf_entry_sell |
mtf_entry_sell |
PnL |
|---|---|---|
| 0.02 | 0.01 | +42% |
| 0.02 | 0.02 | +38% |
| 0.03 | 0.02 | +51% |
| 0.03 | 0.01 | +35% |
조합 (0.03, 0.02)는 PnL +51%를 산출하지만, 고정된 mtf_entry_sell = 0.01에서 htf_entry_sell = 0.03은 +35%만 산출하므로 OAT는 이 조합을 결코 고려하지 않습니다. OAT는 국소 최적점 (0.02, 0.01)에 "갇혀" 전역 최적점 (0.03, 0.02)를 볼 수 없습니다.
이것은 전형적인 문제입니다: 목적 함수 지형에 대각 능선이 포함되어 있으면(한 파라미터가 변할 때 다른 파라미터의 최적값이 이동하면), OAT는 이를 놓칩니다.
문제의 형식화
를 목적 함수(PnL)라 합시다. OAT는 다음 조건을 만족하는 점을 찾습니다:
하지만 이것은 전역 최적의 필요 조건이지 충분 조건이 아닙니다. 헤시안 행렬 에 유의미한 비대각 요소가 있다면, OAT는 일 때 교차 미분 을 고려하지 않습니다.
결합된 파라미터(여러 타임프레임에 걸친 같은 방향의 임계값)의 경우, 상호작용은 예외가 아니라 규칙입니다. 상위 타임프레임의 진입 임계값은 어떤 시그널이 중간으로 도달하는지 결정하고, 중간의 임계값은 하위에서의 필터링 효과를 결정합니다. 가법적 파라미터(다른 방향, 독립 필터)의 경우 교차 미분은 0에 가깝고 OAT는 잘 작동합니다.
베이지안 최적화: 스마트 탐색

아이디어
맹목적 열거나 탐욕적 탐색 대신, 베이지안 최적화는 목적 함수의 대리 모델을 구축하고 각 단계에서 기대 개선이 최대인 지점을 선택합니다.
알고리즘:
- 몇 개의 랜덤 포인트를 선택하고 목적 함수를 평가
- 대리 모델 구축 (관측 포인트에서 를 근사)
- 기대 개선이 최대인 포인트 찾기 (획득 함수)
- 해당 포인트에서 목적 함수 평가
- 대리 모델 업데이트
- 3-5단계 반복
OAT와의 핵심 차이: 베이지안 최적화는 모든 파라미터를 동시에 고려하며 파라미터 공간의 대각 능선을 탐색할 수 있습니다.
TPE (Tree-structured Parzen Estimator)

TPE는 Optuna의 기본 샘플러입니다. 를 직접 모델링하는 대신, TPE는 두 개의 분포를 모델링합니다:
- — 목적 함수가 임계값 보다 좋은 파라미터의 분포
- — 목적 함수가 임계값 보다 나쁜 파라미터의 분포
TPE의 획득 함수는 다음 비율입니다:
TPE는 이 크고("좋은" 파라미터와 유사) 가 작은("나쁜" 파라미터와 유사하지 않은) 포인트를 선택합니다.
TPE가 백테스트에 적합한 이유:
- 파라미터 간 조건부 의존성 처리 가능
- 목적 함수의 연속성 불필요
- 중간 규모 예산(100-1000회 반복)에서 효율적
- 범주형 및 이산 파라미터 지원
Gaussian Process (GP)
TPE의 대안인 Gaussian Process입니다. GP는 를 다변량 정규 프로세스로 모델링하며, 각 포인트에서 값 예측뿐만 아니라 불확실성도 제공합니다.
여기서 는 평균, 은 공분산 함수(커널)입니다.
GP는 다음 경우에 잘 작동합니다:
- 파라미터가 적은 경우(10-15개까지)
- 목적 함수가 부드러운 경우
- 각 실행이 비용이 높은 경우(분, 시간 단위)
사전 계산된 Parquet 캐시로 단일 실행이 약 1초인 백테스트에서는 보통 TPE가 선호됩니다. 모델 구축이 더 빠르고 500회 이상의 반복에도 잘 확장됩니다.
Optuna와의 실용적 통합
완전한 작동 예제
import optuna
from optuna.samplers import TPESampler
import numpy as np
def run_backtest(htf_pre, mtf_pre, ltf_pre, **params) -> dict:
"""
Runs a backtest with given parameters.
Returns a dict with metrics: pnl, max_dd, n_trades, trading_time, sharpe.
Uses precomputed Parquet cache — ~1 second per run.
"""
pass
def objective(trial: optuna.Trial) -> float:
"""Objective function for Optuna."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
study = optuna.create_study(
sampler=TPESampler(seed=42),
study_name="strategy_optimization",
direction="minimize",
)
study.optimize(objective, n_trials=500, show_progress_bar=True)
print(f"Best PnL: {-study.best_value:.2f}%")
print(f"Best params: {study.best_params}")
print(f"Total trials: {len(study.trials)}")
사전 계산 캐시로 백테스트당 약 1초일 때:
전수 탐색의 8,950년 대 8분입니다. 그리고 TPE는 500회 반복으로 OAT가 96회에서 놓치는 조합을 찾아냅니다. 파라미터 공간을 한 축씩이 아닌 동시에 탐색하기 때문입니다.
Study 저장 및 재개
import optuna
study = optuna.create_study(
storage="sqlite:///optuna_study.db",
study_name="strategy_v2",
sampler=TPESampler(seed=42),
direction="minimize",
load_if_exists=True, # continue if study already exists
)
study.optimize(objective, n_trials=300)
study.optimize(objective, n_trials=200)
제약 조건 추가
모든 파라미터 조합이 유효한 것은 아닙니다. 예를 들어, 청산 임계값은 진입 임계값을 초과해서는 안 됩니다:
def objective_with_constraints(trial: optuna.Trial) -> float:
htf_entry = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
htf_exit = trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005)
if htf_exit > htf_entry:
raise optuna.TrialPruned()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
샘플러 비교
Optuna는 여러 샘플러를 지원합니다. 각각 고유한 강점이 있습니다.
TPESampler (기본)
sampler = optuna.samplers.TPESampler(
n_startup_trials=20, # random trials before modeling begins
seed=42,
)
- 원리: Tree-structured Parzen Estimator
- 강점: 혼합 파라미터 유형에 적합, 1000회 이상 반복으로 확장 가능
- 약점: 강한 파라미터 상호작용이 있을 때 효율이 떨어질 수 있음
- 사용 시기: 다른 것을 선택할 이유가 없는 경우 기본값
CmaEsSampler
sampler = optuna.samplers.CmaEsSampler(seed=42)
- 원리: Covariance Matrix Adaptation Evolution Strategy — 공분산 행렬을 적응시키는 진화 알고리즘
- 강점: 연속 파라미터 간 상호작용 발견에 탁월, 상관관계 고려
- 약점: 범주형 파라미터 미지원, 초기화에 더 많은 반복 필요
- 사용 시기: 모든 파라미터가 연속이고 강한 상호작용이 의심되는 경우
GPSampler
sampler = optuna.samplers.GPSampler(seed=42)
- 원리: 획득 함수를 가진 Gaussian Process
- 강점: 최고의 샘플 효율성(적은 반복으로 좋은 결과), 불확실성 추정 제공
- 약점: 반복 횟수에 대해 — 일 때 느림
- 사용 시기: 단일 백테스트가 비용이 높고(분 단위) 예산이 100-200회 반복으로 제한된 경우
RandomSampler (베이스라인)
sampler = optuna.samplers.RandomSampler(seed=42)
- 원리: 균일 무작위 샘플링
- 강점: 국소 최적에 빠지지 않음, 전체 공간 커버리지
- 약점: 이전 결과를 활용하지 않음
- 사용 시기: 비교를 위한 베이스라인 또는 탐색적 분석
QMCSampler
sampler = optuna.samplers.QMCSampler(seed=42)
- 원리: Quasi-Monte Carlo (Sobol/Halton 수열) — 무작위 샘플러보다 더 균일하게 공간을 채움
- 강점: RandomSampler보다 나은 공간 커버리지, 재현성
- 약점: 결과에 적응하지 않음
- 사용 시기: TPE로 전환하기 전 첫 50-100회 반복
요약 테이블
| 샘플러 | 유형 | 상호작용 | 범주형 | 최적 예산 |
|---|---|---|---|---|
| TPE | Bayesian | 부분적 | 예 | 100-1000 |
| CmaEs | 진화적 | 예 | 아니오 | 200-2000 |
| GP | Bayesian | 예 | 제한적 | 50-200 |
| Random | 무작위 | 아니오 | 예 | 모든 (베이스라인) |
| QMC | 준무작위 | 아니오 | 아니오 | 50-500 |
실용적 벤치마크
import optuna
import time
def benchmark_sampler(sampler, n_trials=300):
"""Compare samplers on the same task."""
study = optuna.create_study(sampler=sampler, direction="minimize")
start = time.time()
study.optimize(objective, n_trials=n_trials, show_progress_bar=False)
elapsed = time.time() - start
return {
"best_value": -study.best_value,
"elapsed_sec": elapsed,
"best_trial": study.best_trial.number,
}
samplers = {
"TPE": optuna.samplers.TPESampler(seed=42),
"CmaEs": optuna.samplers.CmaEsSampler(seed=42),
"GP": optuna.samplers.GPSampler(seed=42),
"Random": optuna.samplers.RandomSampler(seed=42),
"QMC": optuna.samplers.QMCSampler(seed=42),
}
for name, sampler in samplers.items():
result = benchmark_sampler(sampler, n_trials=300)
print(f"{name:8s}: best PnL={result['best_value']:.2f}%, "
f"found at trial #{result['best_trial']}, "
f"time={result['elapsed_sec']:.1f}s")
12개 파라미터를 가진 전략의 전형적인 결과:
| 샘플러 | 최고 PnL | 발견 반복 | 샘플러 오버헤드 |
|---|---|---|---|
| TPE | ~51% | ~180 | 낮음 |
| CmaEs | ~49% | ~250 | 중간 |
| GP | ~48% | ~90 | 에서 높음 |
| Random | ~42% | ~270 | 최소 |
| QMC | ~43% | ~200 | 최소 |
TPE와 CmaEs는 최종 PnL에서 무작위 탐색을 일관되게 15-20% 능가합니다. GP는 더 일찍 좋은 결과를 찾지만 반복 횟수가 많아지면 계산 한계에 도달합니다.
다목적 최적화: PnL vs MaxDD
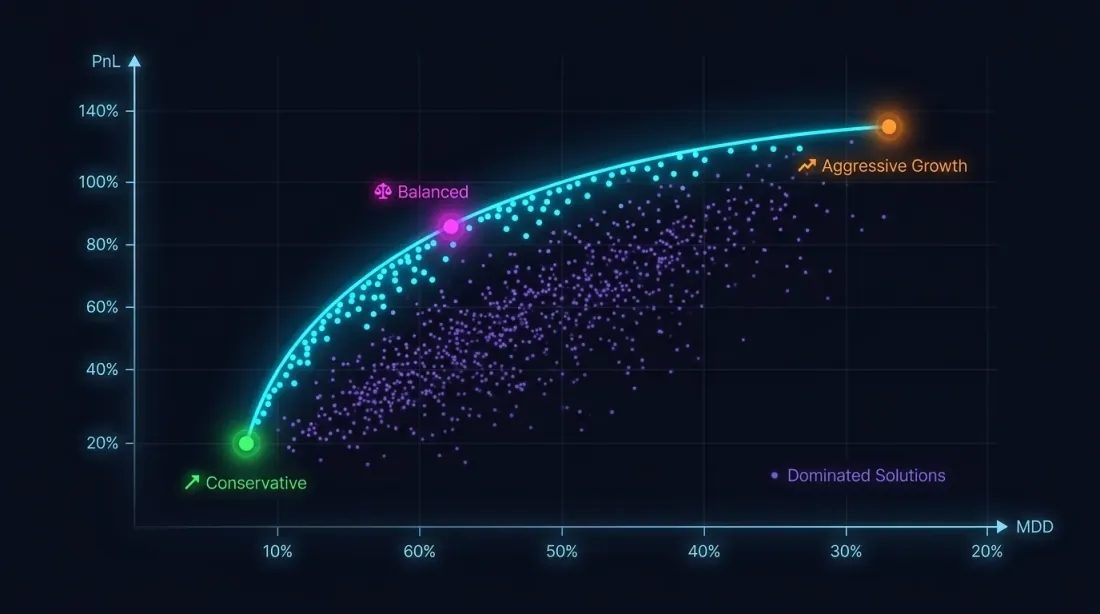
단일 기준이 충분하지 않은 이유
드로다운 제약 없이 PnL을 최대화하는 것은 재앙으로 가는 길입니다. PnL +80%에 MaxDD -30%인 전략은, 손익 비대칭성으로 인해, PnL +50%에 MaxDD -5%인 전략보다 훨씬 더 위험합니다.
최적화 문제는 실제로 다목적입니다:
이 목표들은 상충합니다: 공격적인 파라미터는 PnL과 드로다운을 모두 증가시킵니다. 해답은 단일 점이 아닌 Pareto 프론트입니다: 다른 하나를 악화시키지 않고는 하나의 지표를 개선할 수 없는 솔루션의 집합입니다.
Optuna에서의 NSGA-II / NSGA-III
import optuna
def multi_objective(trial: optuna.Trial) -> tuple[float, float]:
"""Multi-objective function: (PnL, MaxDD)."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
pnl = result["pnl"] # maximize
max_dd = result["max_dd"] # minimize (already a negative number)
return pnl, max_dd # Optuna: both directions are set in create_study
study = optuna.create_study(
directions=["maximize", "minimize"],
sampler=optuna.samplers.NSGAIIISampler(seed=42),
study_name="multi_objective_strategy",
)
study.optimize(multi_objective, n_trials=500)
pareto_trials = study.best_trials
print(f"Pareto front: {len(pareto_trials)} solutions")
for t in pareto_trials[:5]:
print(f" PnL={t.values[0]:.2f}%, MaxDD={t.values[1]:.2f}%")
Pareto 프론트에서 포인트 선택
Pareto 프론트는 여러 솔루션을 제공합니다. 하나를 어떻게 선택할까요?
def select_from_pareto(
pareto_trials: list,
max_dd_limit: float = -5.0,
min_pnl: float = 20.0,
) -> list:
"""
Filter the Pareto front by constraints.
max_dd_limit: maximum acceptable drawdown (e.g., -5%)
min_pnl: minimum acceptable PnL (%)
"""
filtered = []
for trial in pareto_trials:
pnl, max_dd = trial.values
if max_dd >= max_dd_limit and pnl >= min_pnl:
max_lev = min(50 / abs(max_dd), 100) if max_dd != 0 else 100
pnl_at_max_lev = pnl * max_lev
filtered.append({
"trial": trial,
"pnl": pnl,
"max_dd": max_dd,
"max_lev": max_lev,
"pnl_at_max_lev": pnl_at_max_lev,
})
filtered.sort(key=lambda x: x["pnl_at_max_lev"], reverse=True)
return filtered
참고: 최대 레버리지에서 PnL을 계산할 때 펀딩 비율을 고려해야 합니다. 그렇지 않으면 이론적으로 높은 레버리지가 실제 시장에서 손실로 전환됩니다. 또한 최종 PnL은 단일 점 추정치이며, 결과 안정성을 평가하려면 몬테카를로 부트스트랩이 필요합니다.
예시: Pareto 프론트 위의 세 가지 전략
| 전략 | PnL | MaxDD | MaxLev | PnL@MaxLev | 거래 시간 |
|---|---|---|---|---|---|
| 전략 A | ~55% | ~0.9% | ~55x | ~3025% | ~15% |
| 전략 B | ~25% | ~0.75% | ~66x | ~1650% | ~5% |
| 전략 C | ~300% | ~17% | ~3x | ~900% | ~45% |
인상적인 PnL +300%의 전략 C는 높은 드로다운으로 인해 PnL@MaxLev에서 가장 매력이 떨어집니다. 전략 A는 순 레버리지 수익률에서 선두이지만, 활성 시간당 PnL을 고려하면 전략 B가 더 선호될 수 있습니다 — 95%의 여유 시간을 다른 전략으로 채울 수 있습니다.
등고선 플롯과 파라미터 중요도

경관 시각화
최적화 후에는 시각화입니다. Optuna는 내장 도구를 제공합니다:
import optuna.visualization as vis
fig_contour = vis.plot_contour(
study,
params=["htf_entry_sell", "mtf_entry_sell"],
)
fig_contour.show()
fig_importance = vis.plot_param_importances(study)
fig_importance.show()
fig_history = vis.plot_optimization_history(study)
fig_history.show()
fig_parallel = vis.plot_parallel_coordinate(
study,
params=["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell"],
)
fig_parallel.show()
fig_slice = vis.plot_slice(study)
fig_slice.show()
등고선 플롯: 상호작용 읽기
등고선 플롯은 파라미터 쌍에 대한 목적 함수의 2차원 단면을 구축합니다. 등고선이 축 중 하나에 평행하면 파라미터가 상호작용하지 않으며, OAT도 같은 최적값을 찾았을 것입니다. 등고선이 대각선이면 상호작용이 있으며, OAT는 놓칩니다.
key_params = ["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell",
"htf_entry_buy", "mtf_entry_buy", "ltf_entry_buy"]
for i, p1 in enumerate(key_params):
for p2 in key_params[i+1:]:
fig = vis.plot_contour(study, params=[p1, p2])
fig.write_image(f"contour_{p1}_vs_{p2}.png")
등고선 플롯에 플래토(목적 함수가 거의 변하지 않는 영역)가 표시되면 이는 좋은 징조입니다. 플래토는 결과가 작은 파라미터 편차에 대해 견고하다는 의미입니다. 플래토 분석과 과적합과의 관계에 대한 자세한 내용은 향후 기사 플래토 분석을 참조하세요.
파라미터 중요도
importance = optuna.importance.get_param_importances(study)
for param, imp in importance.items():
print(f"{param:20s}: {imp:.4f}")
전형적인 출력:
htf_entry_sell : 0.2841
mtf_entry_sell : 0.2103
ltf_entry_sell : 0.1567
trail_pct : 0.1204
htf_entry_buy : 0.0892
...
중요도가 0.01 미만인 파라미터는 기본값으로 고정할 수 있습니다 — 이를 통해 문제의 차원이 줄어들고 최적화가 빨라집니다. 하지만 주의하세요: 낮은 중요도는 해당 파라미터가 다른 것과의 상호작용에서만 중요하다는 의미일 수도 있습니다. 등고선 플롯으로 확인하세요.
사전 계산 캐시: 백테스트당 1초가 모든 것을 바꾸는 이유
단일 백테스트의 속도가 어떤 최적화 방법을 사용할 수 있는지를 결정합니다.
| 백테스트 시간 | 96회 OAT | 500회 TPE | 2000회 CmaEs |
|---|---|---|---|
| 60초 | 1.6시간 | 8.3시간 | 33시간 |
| 10초 | 16분 | 83분 | 5.5시간 |
| 1초 | 1.5분 | 8분 | 33분 |
| 0.1초 | 10초 | 50초 | 3.3분 |
백테스트당 60초일 때 500회 TPE 반복은 8시간이 걸립니다. 이미 허용 가능하지만, 반복(목적 함수 변경, 재시작)은 비용이 높습니다. 1초일 때 — 8분이고, 하루에 수십 개의 실험을 실행할 수 있습니다.
바로 이것이 Parquet 캐시로의 사전 계산이 단순한 속도 최적화가 아니라 사용 가능한 방법 공간의 확장인 이유입니다. 캐시 없이는 OAT 또는 100회 GP 반복으로 제한됩니다. 캐시가 있으면 2000회 CmaEs 반복이나 완전한 다목적 NSGA-III를 실행할 여유가 있습니다.
import pyarrow.parquet as pq
import time
t0 = time.time()
htf_pre = pq.read_table("cache/htf_indicators.parquet").to_pandas()
mtf_pre = pq.read_table("cache/mtf_indicators.parquet").to_pandas()
ltf_pre = pq.read_table("cache/ltf_indicators.parquet").to_pandas()
print(f"Cache loaded in {time.time() - t0:.2f}s") # ~0.3s
t1 = time.time()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, htf_entry_sell=0.02, ...)
print(f"Backtest in {time.time() - t1:.2f}s") # ~1.0s
실용적 권장사항
OAT를 사용해야 할 때
다음 경우에 OAT가 정당화됩니다:
-
탐색적 분석. 전략 탐색을 막 시작했으며 어떤 파라미터가 결과에 영향을 미치는지 이해하고 싶은 경우. 96회 실행을 1.5분에 — 훌륭한 출발점입니다.
-
가법적 파라미터. 겹치지 않는 트레이드 하위 집합에서 작동하는 파라미터(매도 vs 매수 방향, 다른 금융 상품)의 경우, OAT가 더 빠르게 올바른 결과를 줍니다.
-
매우 비용이 높은 백테스트. 단일 실행이 10분 이상 걸리고 가속할 수 없는 경우, 96회 OAT(16시간)가 500회 TPE 반복(3.5일)보다 바람직합니다.
Optuna를 사용해야 할 때
대부분의 경우 Optuna가 바람직합니다:
-
3개 이상의 파라미터. 상호작용은 거의 확실히 존재하며, OAT는 최적값을 놓칩니다.
-
멀티타임프레임 전략. 서로 다른 타임프레임의 임계값은 거의 항상 상호 연결되어 있습니다.
-
최종 최적화. 전략이 몬테카를로 부트스트랩을 통과하고 견고성에 확신이 있는 경우 — Optuna가 최적의 파라미터를 찾습니다.
-
다목적 문제. PnL vs MaxDD vs 거래 시간 — OAT는 원칙적으로 이 문제를 해결할 수 없습니다.
하이브리드 접근: 가법적에는 OAT + 결합에는 Optuna
OAT와 Optuna 중 선택할 필요 없이 결합하는 것이 좋습니다:
-
파라미터 분류. 가법적(독립)과 결합(상호작용)으로 나눕니다. 12개 분리 파라미터의 예:
- 가법적:
htf_entry_sell<->htf_entry_buy,mtf_entry_sell<->mtf_entry_buy,ltf_entry_sell<->ltf_entry_buy(매도/매수 — 다른 방향, 겹치지 않는 트레이드에서 작동) - 결합 그룹 sell:
htf_entry_sell,mtf_entry_sell,ltf_entry_sell(필터링 체인: HTF -> MTF -> LTF 매도 시그널용) - 결합 그룹 buy:
htf_entry_buy,mtf_entry_buy,ltf_entry_buy
- 가법적:
-
가법적에는 OAT. 매도와 매수 그룹을 독립적으로 최적화합니다. 매도 파라미터가 매수 트레이드에 영향을 미치지 않는다면 OAT가 몇 분 만에 올바른 결과를 줍니다.
-
결합에는 Optuna. 각 그룹 내(sell: 6개 파라미터 entry+exit)에서 TPE를 사용합니다. 12개 대신 6개 파라미터 — 예산이 절반으로 줄어듭니다.
sell_params = oat_sweep(sell_param_grid, run_backtest, initial_params)
def objective_sell(trial):
params = sell_params.copy()
params["htf_entry_sell"] = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
params["mtf_entry_sell"] = trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005)
params["ltf_entry_sell"] = trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005)
params["htf_exit_sell"] = trial.suggest_float("htf_exit_sell", 0.0, 0.02, step=0.001)
params["mtf_exit_sell"] = trial.suggest_float("mtf_exit_sell", 0.0, 0.02, step=0.001)
params["ltf_exit_sell"] = trial.suggest_float("ltf_exit_sell", 0.0, 0.02, step=0.001)
return -run_backtest(**params)["effective_score"]
study = optuna.create_study(sampler=optuna.samplers.TPESampler())
study.optimize(objective_sell, n_trials=300) # 6 parameters → 300 is enough
완전한 최적화 파이프라인
1. Parquet 캐시 사전 계산 (1회)
2. 파라미터 분류: 가법적 vs 결합
3. 가법적에 OAT (~50회, ~1분) → 고정
4. 결합 그룹에 Optuna TPE (300회 반복 x 2 그룹, ~10분)
5. 메타 파라미터에 Optuna NSGA-III (500회 반복, ~8분) → Pareto 프론트
6. 등고선 플롯 → 상호작용 시각화
7. 최적 포인트의 몬테카를로 부트스트랩 → 신뢰 구간
8. Walk-Forward → 표본 외 검증
8단계의 Walk-Forward 최적화는 과적합 방지를 위해 매우 중요합니다. 이에 대한 자세한 내용은 향후 기사 Walk-Forward를 참조하세요.
최적화의 함정
과적합. 파라미터가 많고 최적화가 정밀할수록, 전략을 과거 데이터에 피팅할 위험이 높아집니다. 12개 파라미터로 500회 Optuna 반복은 훈련 세트에서 완벽하게 작동하는 조합을 찾지만, 새로운 데이터에서는 쓸모가 없습니다.
대책:
- 데이터를 train/test (70/30)로 분할
- 몬테카를로 부트스트랩으로 안정성 평가
- Walk-Forward로 검증
- 플래토 위의 솔루션 선호 (자세한 내용은 플래토 분석 참조)
다중 비교 문제. 500개의 조합을 테스트하면 우연히 "좋은" 결과를 찾을 확률이 증가합니다. Bonferroni 보정이나 FDR(위양성 발견율) 제어가 도움이 되지만, 더 간단한 접근 방식은 표본 외 검증입니다.
불충분한 예산. 12개 파라미터에 대한 TPE 50회 반복은 너무 적습니다. 처음 20회 반복은 랜덤(스타트업)이므로 모델링에 사용할 수 있는 것은 30회뿐입니다. 최소 예산: 12개 파라미터의 경우 회 반복, 권장: .
Freqtrade: 프로덕션 프레임워크에서의 동작

Freqtrade는 인기 있는 알고트레이딩 프레임워크 중 하나로, Hyperopt 모듈을 통해 내부적으로 Optuna를 사용합니다. 그 경험은 우리의 권장 사항을 확인해 줍니다:
- 샘플러: TPE(기본), GP, CmaEs, NSGA-II, QMC — 모두 설정을 통해 사용 가능
- 손실 함수: ShortTradeDurHyperOptLoss, SharpeHyperOptLoss, MaxDrawDownHyperOptLoss를 포함한 12개의 내장 손실 함수
- 다목적: 여러 지표의 동시 최적화를 위한 NSGA-II 및 NSGA-III 지원
- 커스텀 샘플러: Optuna 호환 샘플러를 플러그인 가능
Freqtrade 생태계의 핵심 교훈: 내장 손실 함수는 전형적인 시나리오를 다루지만, 진지한 최적화에는 전략의 특성을 고려한 커스텀 목적 함수가 필요합니다 — 활성 시간, 펀딩 비용, 정확한 체결 시뮬레이션을 위한 적응형 드릴다운.
결론

좌표 하강법(OAT)은 빠르고 직관적인 방법입니다. 12개 파라미터에 대해 단 96회 실행으로 1분 반 만에 완료됩니다. 하지만 파라미터 상호작용에 대해 맹목적이며, 멀티타임프레임 전략에서는 상호작용이 거의 항상 존재합니다.
Optuna를 통한 베이지안 최적화(TPE, GP, CmaEs)는 파라미터 공간을 전체적으로 탐색합니다. 사전 계산된 Parquet 캐시로 8분간 500회 반복하면 OAT에게는 보이지 않는 조합을 찾아냅니다.
다목적 최적화(NSGA-III)는 "PnL을 최대화하라"는 문제를 "PnL vs MaxDD의 Pareto 프론트를 구축하라"는 문제로 변환하고, 서로 다른 위험-수익 트레이드오프를 가진 솔루션 집합을 제공합니다.
그러나 최적화는 파이프라인의 일부에 불과합니다. 찾은 파라미터는 몬테카를로 부트스트랩으로 검증하고, 펀딩 비율을 보정하고, 활성 시간을 고려하여 재계산하고, Walk-Forward 검증을 수행해야 합니다. 이에 대한 자세한 내용은 시리즈의 향후 기사를 참조하세요.
유용한 링크
- Optuna: A Next-generation Hyperparameter Optimization Framework (Akiba et al., 2019)
- Algorithms for Hyper-Parameter Optimization (Bergstra et al., 2011) — the original TPE paper
- Optuna Documentation — Samplers
- Optuna Visualization Module
- Hansen, N. — The CMA Evolution Strategy: A Tutorial
- Deb, K. et al. — NSGA-II: A Fast and Elitist Multiobjective Genetic Algorithm (2002)
- Snoek, J. et al. — Practical Bayesian Optimization of Machine Learning Algorithms (2012)
- Freqtrade Documentation — Hyperopt
- Marcos Lopez de Prado — Advances in Financial Machine Learning, Chapter 12
- Bergstra, J. & Bengio, Y. — Random Search for Hyper-Parameter Optimization (2012)
Citation
@article{soloviov2026optuna,
author = {Soloviov, Eugen},
title = {Coordinate Descent vs Bayesian Optimization: Which Finds Better Parameters},
year = {2026},
url = {https://marketmaker.cc/en/blog/post/optuna-vs-coordinate-descent},
description = {Why exhaustive search is impossible for 12+ parameters, how coordinate descent misses interactions, and how Optuna with a TPE sampler finds in 500 iterations what OAT cannot find in 96.}
}
MarketMaker.cc Team
퀀트 리서치 및 전략


