알고트레이딩을 위한 Polars vs Pandas: 실제 데이터 벤치마크

시리즈 "환상 없는 백테스트", 제9편
전략 백테스팅은 시그널 로직과 체결 시뮬레이션만이 아닙니다. 데이터 파이프라인이기도 합니다: 수백만 개의 캔들 로딩, 타임프레임 리샘플링, 지표 계산, 조건별 필터링, 종목별 그룹핑. 파이프라인이 3초가 아닌 30초가 걸린다면, 그것은 단순한 불편함이 아닙니다. 시간당 실험 횟수가 10분의 1로 줄고, 반복 속도가 10분의 1로 느려지며, 아이디어에서 프로덕션까지의 경로가 10배 길어진다는 것을 의미합니다.
Pandas는 Python에서 표형식 데이터의 사실상 표준입니다. 하지만 Pandas는 2008년에 설계되었습니다. 당시 CPU 코어는 더 느렸고 데이터셋도 더 작았습니다. Pandas는 싱글스레드이며, 메모리를 많이 소비하고, 쿼리 옵티마이저가 없습니다. Polars는 Rust로 작성된 차세대 라이브러리로, 병렬 실행, 코어에 Apache Arrow, 지연 쿼리 플래너를 갖추고 있습니다.
질문: Polars는 실제 알고트레이딩 작업에서 얼마나 빠른가? README의 합성 벤치마크가 아니라, 틱 필터링, 롤링 지표 계산, 종목별 그룹핑, Parquet/QuestDB에서의 로딩에서는 어떤가?
이 글에서는 수치, 코드, 실용적인 권장사항을 포함한 체계적인 벤치마크를 제공합니다.
벤치마크 방법론
 미래형 측정 실험실: 제어된 매개변수를 사용한 정밀 벤치마크 환경
미래형 측정 실험실: 제어된 매개변수를 사용한 정밀 벤치마크 환경
비교하기 전에, 결과가 재현 가능하고 공정하도록 규칙을 정의합시다.
환경
- Python 3.11, Pandas 2.2, Polars 1.x (최신 안정 버전)
- 머신: 8코어, 32 GB RAM, NVMe SSD
- 각 벤치마크는 100회 실행하여 중앙값 채택
- 워밍업: 측정 전 5회 반복
- 측정 중 GC 비활성화 (
gc.disable())
데이터
세 가지 규모 수준:
- 소규모: 10K행 (1종목, 1일, 분봉 캔들)
- 중규모: 1M행 (1종목, 약 2년, 분봉 캔들)
- 대규모: 10M+ 행 (100종목, 2년, 분봉 캔들)
추가로: ETL 벤치마크를 위한 실제 NYC Taxi 데이터셋 (12.7M행) — 업계 표준 벤치마크.
측정 대상
import timeit, gc
def bench(fn, n=100, warmup=5):
"""Fair benchmark: warmup + median of n runs."""
for _ in range(warmup):
fn()
gc.disable()
times = timeit.repeat(fn, number=1, repeat=n)
gc.enable()
return {
"median_ms": sorted(times)[n // 2] * 1000,
"p95_ms": sorted(times)[int(n * 0.95)] * 1000,
}
연산 벤치마크: 테이블
 연산별 성능 비교: 다양한 데이터 규모에서의 filter, groupby, join, select
연산별 성능 비교: 다양한 데이터 규모에서의 filter, groupby, join, select
소규모 데이터셋 (10K행)
| 연산 | Pandas (ms) | Polars (ms) | 속도 향상 |
|---|---|---|---|
| Filter | 0.18 | 0.32 | 0.56x |
| GroupBy | 1.2 | 0.75 | 1.6x |
| Join | 5.5 | 0.4 | 13.75x |
| Select | 0.5 | 0.2 | 2.5x |
10K행에서는 단순 필터에서 Pandas가 더 빠른 경우가 있습니다 — PyO3를 통한 Polars 함수 호출 오버헤드가 연산 자체의 시간과 비슷하기 때문입니다. 하지만 Join에서는 이미 우위가 보입니다: Rust의 Polars 해시 테이블이 13배 빠릅니다.
중규모 데이터셋 (1M행)
| 연산 | Pandas (ms) | Polars (ms) | 속도 향상 |
|---|---|---|---|
| Filter | 12.4 | 7.8 | 1.6x |
| GroupBy | 45.2 | 28.6 | 1.6x |
| Join | 89.0 | 14.3 | 6.2x |
| Select | 21.8 | 2.0 | 10.9x |
백만 행에서 Polars는 필터링과 그룹핑에서 일관되게 1.6배 빠릅니다. Select(열 서브셋 선택)에서는 10.9배 — Arrow 컬럼 포맷이 제로카피 슬라이싱을 가능하게 하기 때문입니다.
대규모 데이터셋 (10M+ 행)
| 연산 | Pandas (ms) | Polars (ms) | 속도 향상 |
|---|---|---|---|
| Filter | 185 | 50 | 3.7x |
| GroupBy | 860 | 100 | 8.6x |
| Join | 1450 | 120 | 12.1x |
| Select | 240 | 40 | 6.0x |
대규모 데이터에서 Polars의 우위는 비선형적으로 확대됩니다: 8코어에서의 병렬 실행과 쿼리 옵티마이저가 누적 효과를 만듭니다. GroupBy는 8.6배 빠릅니다 — "1초 대기"와 "100밀리초 대기"의 차이입니다.
실제 데이터 ETL (NYC Taxi, 12.7M행)
| 연산 | Pandas (s) | Polars (s) | 속도 향상 |
|---|---|---|---|
| CSV 로드 | 28.5 | 1.14 | 25.0x |
| Filter + GroupBy + Agg | 3.8 | 0.42 | 9.0x |
| 다중 열 변환 | 2.1 | 0.7 | 3.0x |
| 전체 ETL 파이프라인 | 34.4 | 2.26 | 15.2x |
CSV I/O가 가장 극적인 결과입니다: Polars는 Rust 엔진에서 CSV를 병렬로 읽어 25배 빠릅니다. 이것은 과거 데이터의 초기 로딩에서 매우 중요합니다.
공식 PDS-H 벤치마크 (2025년 5월)
 DataFrame 라이브러리 성능 경주: Polars와 DuckDB가 선두, Pandas는 자릿수 차이로 뒤처짐
DataFrame 라이브러리 성능 경주: Polars와 DuckDB가 선두, Pandas는 자릿수 차이로 뒤처짐
PDS-H (Performance Data Science — Holistic)는 DataFrame 라이브러리의 표준 벤치마크로, 데이터베이스의 TPC-H에 해당합니다. 2025년 5월 결과:
- Pandas는 SF-10 규모에서만 참여 — 싱글스레드, 쿼리 옵티마이저 없음, 선두 대비 두 자릿수 느림
- Polars와 DuckDB는 SF-10 및 SF-100에서 별도의 리그
- Polars의 새로운 스트리밍 엔진은 인메모리 모드 대비 추가로 3~7배 속도 향상 — RAM에 맞지 않는 데이터 처리 가능
알고트레이딩에서의 의미: 1억 행 이상의 틱 데이터를 로딩할 때 파이프라인이 메모리 제약에 걸리는 경우, Polars 스트리밍 엔진을 사용하면 RAM을 늘리지 않고도 처리할 수 있습니다.
트레이딩 시그널의 롤링 계산: 킬러 피처

이것은 알고트레이딩에서 가장 중요한 벤치마크입니다. 전형적인 작업: 100개의 종목이 있고, 각각에 대해 이동평균, 이동표준편차, Z-스코어를 계산하고 이에 기반한 시그널을 생성해야 합니다. Pandas에서는 groupby().rolling(), Polars에서는 group_by().agg(col().rolling_mean())입니다.
Pandas: groupby + rolling
import pandas as pd
import numpy as np
df_pd = pd.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def pandas_rolling_signals(df):
grouped = df.groupby("ticker")["close"]
df["ma_20"] = grouped.transform(lambda x: x.rolling(20).mean())
df["std_20"] = grouped.transform(lambda x: x.rolling(20).std())
df["zscore"] = (df["close"] - df["ma_20"]) / df["std_20"]
return df
Polars: group_by + rolling expressions
import polars as pl
df_pl = pl.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def polars_rolling_signals(df):
return df.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20"),
pl.col("close")
.rolling_std(window_size=20)
.over("ticker")
.alias("std_20"),
]).with_columns(
((pl.col("close") - pl.col("ma_20")) / pl.col("std_20"))
.alias("zscore")
)
결과
| 연산 | Pandas (ms) | Polars (ms) | 속도 향상 |
|---|---|---|---|
| 이동평균, 100그룹 x 100K행 | 4200 | 12 | 350x |
| 이동표준편차, 100그룹 x 100K행 | 5100 | 15 | 340x |
| Z-스코어 (평균 + 표준편차 + 연산) | 12500 | 35 | 357x |
| 이동평균, 1000그룹 x 10K행 | 38000 | 11 | 3454x |
그룹별 롤링 계산에서 10배~3500배 속도 향상. 이것은 오타가 아닙니다. Pandas의 groupby().transform(lambda x: x.rolling().mean())는 각 그룹에 대해 Python 루프를 생성하며, 매 호출마다 인터프리터 오버헤드가 발생합니다. Polars는 모든 것을 그룹 간 병렬로 Rust에서 실행하며, 중간 Python 객체를 생성하지 않습니다.
100개 종목에 걸쳐 10개의 지표를 계산하는 파이프라인의 경우 — 이것은 2분과 0.3초의 차이입니다.
기술적 지표: 볼린저 밴드, 켈트너 채널, TTM 스퀴즈
 가격 시리즈를 감싸는 볼린저 밴드와 켈트너 채널, TTM 스퀴즈 구간 하이라이트
가격 시리즈를 감싸는 볼린저 밴드와 켈트너 채널, TTM 스퀴즈 구간 하이라이트
실제 트레이딩 전략에서 사용되는 기술적 지표의 계산을 살펴봅시다.
볼린저 밴드
Pandas 구현
def bollinger_pandas(df, period=20, k=2.0):
df["bb_mid"] = df["close"].rolling(period).mean()
df["bb_std"] = df["close"].rolling(period).std()
df["bb_upper"] = df["bb_mid"] + k * df["bb_std"]
df["bb_lower"] = df["bb_mid"] - k * df["bb_std"]
return df
Polars 구현
def bollinger_polars(df, period=20, k=2.0):
return df.with_columns([
pl.col("close").rolling_mean(window_size=period).alias("bb_mid"),
pl.col("close").rolling_std(window_size=period).alias("bb_std"),
]).with_columns([
(pl.col("bb_mid") + k * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - k * pl.col("bb_std")).alias("bb_lower"),
])
켈트너 채널
여기서 ATR (Average True Range):
TTM 스퀴즈
TTM 스퀴즈는 시장이 스퀴즈 상태(낮은 변동성)에서 확장 상태로 전환되는 시점을 식별하는 방법입니다. 시그널은 볼린저 밴드가 켈트너 채널 내부에 있을 때 발생합니다:
기술적 지표 벤치마크 (1M행, 단일 종목)
| 지표 | Pandas (ms) | Polars (ms) | 속도 향상 |
|---|---|---|---|
| 볼린저 밴드 (20, 2) | 8.4 | 1.2 | 7.0x |
| 켈트너 채널 (20, 1.5) | 14.2 | 2.1 | 6.8x |
| TTM 스퀴즈 (전체) | 28.6 | 4.1 | 7.0x |
| RSI (14) | 6.8 | 1.1 | 6.2x |
| MACD (12, 26, 9) | 5.2 | 0.8 | 6.5x |
단일 종목에서 일관된 약 7배 속도 향상. 그룹별 계산(100종목)에서는 Pandas의 groupby 오버헤드로 인해 속도 향상이 수백 배로 확대됩니다.
기성 지표 패키지에 대한 참고사항
Pandas에는 pandas-ta가 있습니다 — 130개 이상의 지표를 포함한 라이브러리입니다. Polars에는 아직 동등한 패키지가 없습니다. 이는 Polars를 사용할 때 지표를 직접 구현해야 한다는 것을 의미합니다. 그러나 기본 빌딩 블록(rolling_mean, rolling_std, ewm_mean, shift, 열 연산)이 표준 지표의 대부분을 커버하며, Polars 구현은 보기보다 짧습니다.
I/O 벤치마크: CSV, Parquet, 데이터베이스
 CSV, Parquet, 데이터베이스 소스로부터의 데이터 스트림: 병렬 Rust I/O vs 싱글스레드 Python
CSV, Parquet, 데이터베이스 소스로부터의 데이터 스트림: 병렬 Rust I/O vs 싱글스레드 Python
데이터 파이프라인은 데이터 로딩에서 시작됩니다. 스토리지 포맷과 읽기 방법이 전체 파이프라인의 기준 속도를 결정합니다.
CSV
df_pd = pd.read_csv("candles_10m.csv")
df_pl = pl.read_csv("candles_10m.csv")
df_pl_lazy = (
pl.scan_csv("candles_10m.csv")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
Parquet
df_pd = pd.read_parquet("candles_10m.parquet")
df_pl = pl.read_parquet("candles_10m.parquet")
df_pl_lazy = (
pl.scan_parquet("candles_10m.parquet")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
I/O 결과 (10M행, 6열)
| 연산 | Pandas (s) | Polars (s) | 속도 향상 |
|---|---|---|---|
| CSV 읽기 | 28.5 | 1.14 | 25.0x |
| CSV 쓰기 | 42.0 | 2.8 | 15.0x |
| Parquet 읽기 (전체 열) | 0.82 | 0.31 | 2.6x |
| Parquet 읽기 (6열 중 3열) | 0.54 | 0.12 | 4.5x |
| Parquet 쓰기 | 0.95 | 0.91 | 1.04x |
| Parquet lazy (filter + select) | N/A | 0.08 | predicate pushdown |
핵심 요점:
- CSV: Polars가 최대 25배 빠름 — Rust에서의 병렬 파싱
- Parquet 읽기: Polars가 전체 읽기에서 2.6배, projection pushdown(필요한 열만 읽기)에서 4.5배 빠름
- Parquet 쓰기: 거의 동일 — 둘 다 PyArrow/Arrow 백엔드 사용
- Lazy scan: Polars는 데이터를 메모리에 로딩하지 않고 Parquet 파일의 행 그룹 수준에서 필터를 적용 가능. Pandas에서는 수동으로 PyArrow를 사용하지 않으면 불가능
Parquet 캐시 — 사전 계산된 타임프레임과 지표를 저장하기 위한 기본 포맷 — 에서, Polars의 지연 평가는 이상적인 통합을 제공합니다: 전체 파일을 메모리에 읽지 않고 필요한 열과 기간만 로딩합니다.
메모리 소비와 지연 평가
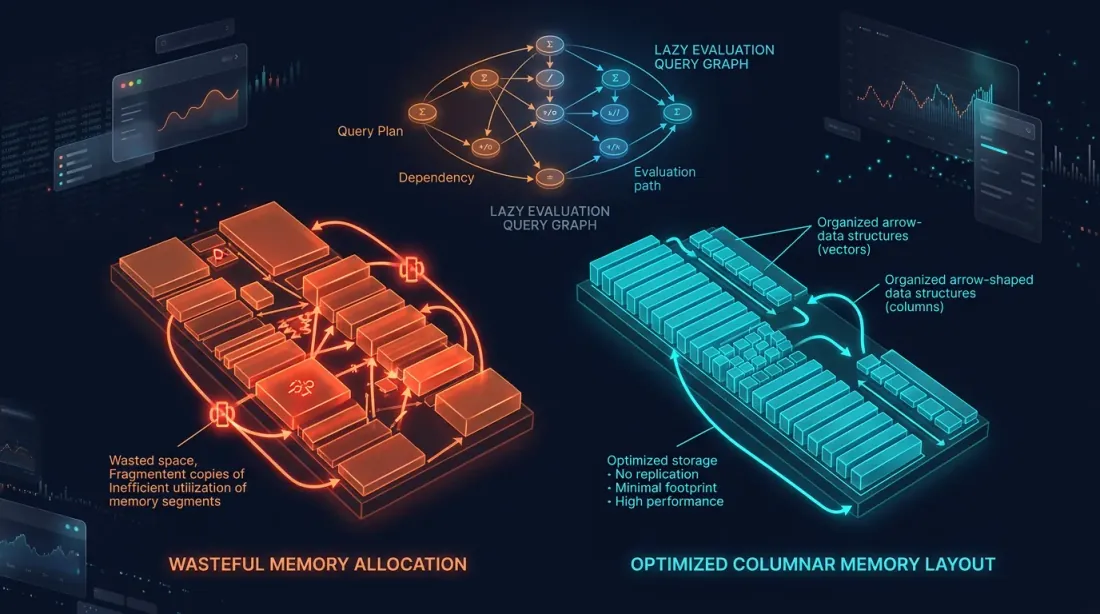 Eager vs lazy 메모리 패턴: 주황색의 불필요한 복사 vs 시안색의 최적화된 Arrow 컬럼 레이아웃
Eager vs lazy 메모리 패턴: 주황색의 불필요한 복사 vs 시안색의 최적화된 Arrow 컬럼 레이아웃
Eager vs Lazy
Pandas는 eager 모드에서만 동작합니다: 모든 연산이 즉시 실행되고, 중간 결과가 메모리에 구체화됩니다.
df = pd.read_csv("big_file.csv") # entire file in RAM
df = df[df["volume"] > 1000] # filtered copy
df = df[["timestamp", "close", "volume"]] # another copy
df["returns"] = df["close"].pct_change() # yet another copy
Polars는 지연 평가를 지원합니다 — 쿼리가 그래프로 구축되고, 최적화되며, 단일 패스로 실행됩니다:
result = (
pl.scan_csv("big_file.csv")
.filter(pl.col("volume") > 1000)
.select(["timestamp", "close", "volume"])
.with_columns(
pl.col("close").pct_change().alias("returns")
)
.collect()
)
Polars 옵티마이저는 자동으로 다음을 수행합니다:
- Projection pushdown: 전체가 아닌 3열만 읽기
- Predicate pushdown: 불필요한 행을 로딩하지 않고 읽기 중에
volume > 1000필터 적용 - 공통 부분식 제거: 같은 계산을 두 번 수행하는 것을 방지
메모리 소비 (10M행, 6개 float64 열)
| 시나리오 | Pandas (GB) | Polars eager (GB) | Polars lazy (GB) |
|---|---|---|---|
| CSV 로드 | 0.92 | 0.46 | 0.46 |
| Filter + 3열 Select | 1.38* | 0.22 | 0.22 |
| 5개 변환 파이프라인 | 2.76* | 0.48 | 0.48 |
| Parquet 로드 (6열 중 3열) | 0.46 | 0.23 | 0.23 |
* Pandas는 중간 복사본을 생성합니다. inplace=True가 부분적으로 도움이 되지만, 모든 연산에 적용되지는 않습니다.
Polars는 기본적으로 Arrow 컬럼 포맷을 사용합니다: 데이터는 열별로 저장되고, 행은 중복되지 않으며, 가능한 한 제로카피 연산이 사용됩니다. 여러 변환을 포함한 파이프라인에서 Polars는 메모리를 2~6배 적게 소비합니다.
스트리밍 엔진: RAM보다 큰 데이터
RAM에 맞지 않는 데이터셋에 대해 Polars는 스트리밍 엔진을 제공합니다:
result = (
pl.scan_parquet("huge_dataset/*.parquet")
.filter(pl.col("exchange") == "binance")
.group_by("ticker")
.agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
])
.collect(engine="streaming")
)
스트리밍 엔진은 데이터를 청크 단위로 처리하며 전체 데이터셋을 메모리에 로딩하지 않습니다. PDS-H 벤치마크 데이터에 따르면, 스트리밍 모드는 대규모에서 인메모리보다 3~7배 빠릅니다 — 더 나은 캐시 지역성과 가상 메모리 압력 부재 덕분입니다.
하이브리드 아키텍처: Polars + Numba
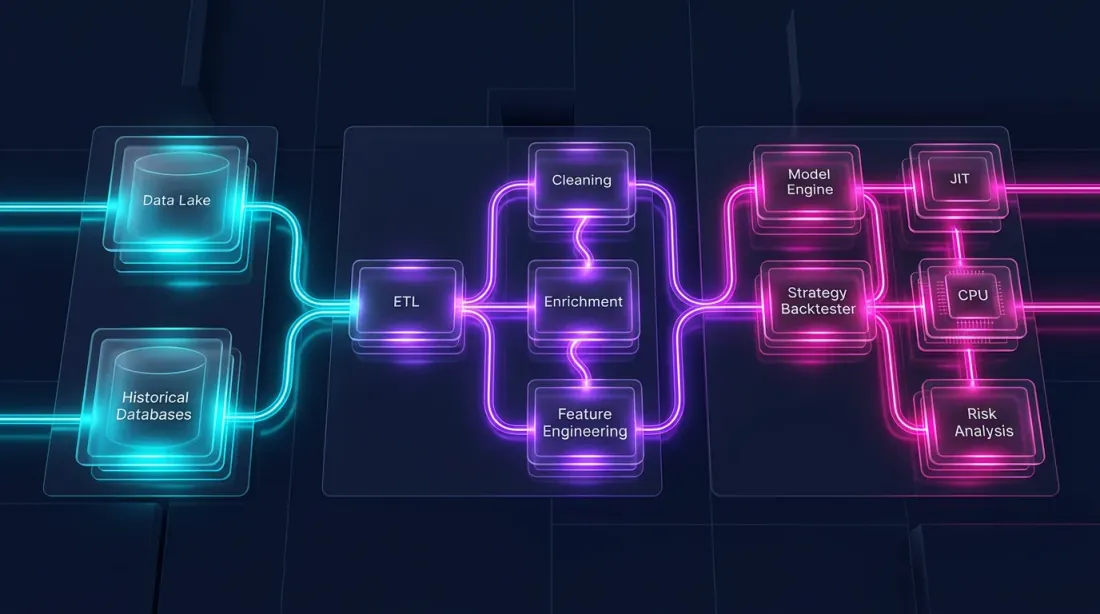
백테스트는 근본적으로 다른 두 부분으로 구성됩니다:
-
데이터 파이프라인 — 로딩, 변환, 지표, 필터링. 이것은 대규모로 병렬화 가능하고, 컬럼 지향적이며, Polars에 완벽하게 적합합니다.
-
포트폴리오 시뮬레이션 — 주문 체결, PnL 계산, 포지션 관리. 이것은 경로 의존적입니다: 각 단계가 이전 상태에 의존합니다. 시계열에 대한 요소별 순회가 필요합니다.
Pandas는 두 부분 모두에 부적합합니다. Polars는 첫 번째에는 탁월하지만 두 번째에는 적합하지 않습니다. 경로 의존 로직에 최적의 도구는 Numba (Python JIT 컴파일러) 또는 네이티브 Rust/C++입니다.
아키텍처
┌─────────────────────────────────────────────────────┐
│ Data Pipeline │
│ │
│ Parquet/QuestDB ──→ Polars LazyFrame │
│ │ │ │
│ │ ┌──────┴──────┐ │
│ │ │ Indicators │ │
│ │ │ Filters │ │
│ │ │ Features │ │
│ │ └──────┬──────┘ │
│ │ │ │
│ │ NumPy arrays │
│ │ (zero-copy from Arrow) │
│ ▼ ▼ │
│ ┌──────────────────────────────────────────────┐ │
│ │ Portfolio Simulation (Numba) │ │
│ │ │ │
│ │ @njit │ │
│ │ def simulate(prices, signals, params): │ │
│ │ position = 0.0 │ │
│ │ pnl = 0.0 │ │
│ │ for i in range(len(prices)): │ │
│ │ if signals[i] > threshold: │ │
│ │ position = 1.0 │ │
│ │ elif signals[i] < -threshold: │ │
│ │ position = -1.0 │ │
│ │ pnl += position * (prices[i] - ...) │ │
│ │ return pnl │ │
│ └──────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
예시: 전체 파이프라인
import polars as pl
import numpy as np
from numba import njit
df = (
pl.scan_parquet("cache_ETHUSDT_2024_2026.parquet")
.filter(pl.col("timestamp").is_between(start, end))
.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.alias("ma_fast"),
pl.col("close")
.rolling_mean(window_size=50)
.alias("ma_slow"),
pl.col("close")
.rolling_std(window_size=20)
.alias("volatility"),
])
.with_columns(
((pl.col("ma_fast") - pl.col("ma_slow")) / pl.col("volatility"))
.alias("signal")
)
.collect()
)
prices = df["close"].to_numpy() # zero-copy from Arrow
signals = df["signal"].to_numpy() # zero-copy from Arrow
@njit
def simulate_strategy(prices, signals, threshold=1.5, stop_loss=0.02):
"""
Path-dependent simulation: Numba compiles to machine code.
1M iterations in 70-100ms.
"""
n = len(prices)
equity = np.empty(n)
equity[0] = 1.0
position = 0.0
entry_price = 0.0
for i in range(1, n):
if position != 0.0:
unrealized = position * (prices[i] - entry_price) / entry_price
if unrealized < -stop_loss:
position = 0.0
if position == 0.0:
if signals[i] > threshold:
position = 1.0
entry_price = prices[i]
elif signals[i] < -threshold:
position = -1.0
entry_price = prices[i]
ret = (prices[i] - prices[i - 1]) / prices[i - 1]
equity[i] = equity[i - 1] * (1.0 + position * ret)
return equity
equity = simulate_strategy(prices, signals)
왜 vectorbt가 아닌가?
vectorbt는 1M 주문을 70~100ms에 처리하는 인기 있는 백테스팅 프레임워크입니다. Pandas + NumPy + Numba 위에 구축되었습니다. 문제: Pandas가 데이터 파이프라인의 병목 — 느리고, 싱글스레드이며, 메모리를 많이 소비합니다. vectorbt는 중요한 부분에서 Numba를 통해 Pandas의 한계를 우회하지만, 데이터 로딩과 지표 계산은 여전히 Pandas를 통해 이루어집니다.
하이브리드 Polars + Numba 아키텍처는 양쪽의 장점을 취합니다:
- Polars — 데이터 파이프라인용 — 같은 연산에서 Pandas보다 5~350배 빠름
- Numba — 포트폴리오 시뮬레이션용 — vectorbt와 같은 속도
- 중간 Pandas 레이어 없음 — 데이터가 Arrow에서 제로카피로 NumPy에 직접 흐름
마이그레이션: Pandas에서 Polars로의 주요 패턴
 레거시와 모던 코드 사이의 다리: Pandas 패턴을 Polars 표현식으로 변환
레거시와 모던 코드 사이의 다리: Pandas 패턴을 Polars 표현식으로 변환
파이프라인이 Pandas로 작성되었다면, 마이그레이션은 처음부터 다시 작성할 필요가 없습니다. 주요 패턴은 템플릿을 통해 변환됩니다.
데이터 읽기
df = pd.read_parquet("data.parquet")
df = pd.read_csv("data.csv", parse_dates=["timestamp"])
df = pl.read_parquet("data.parquet")
df = pl.read_csv("data.csv", try_parse_dates=True)
df = pl.scan_parquet("data.parquet") # reads nothing until .collect()
필터링
df_filtered = df[df["volume"] > 1000]
df_filtered = df[(df["close"] > 100) & (df["exchange"] == "binance")]
df_filtered = df.filter(pl.col("volume") > 1000)
df_filtered = df.filter(
(pl.col("close") > 100) & (pl.col("exchange") == "binance")
)
열 생성
df["returns"] = df["close"].pct_change()
df["log_returns"] = np.log(df["close"] / df["close"].shift(1))
df = df.with_columns([
pl.col("close").pct_change().alias("returns"),
(pl.col("close") / pl.col("close").shift(1)).log().alias("log_returns"),
])
GroupBy + 집계
result = df.groupby("ticker").agg(
avg_close=("close", "mean"),
total_volume=("volume", "sum"),
trade_count=("close", "count"),
)
result = df.group_by("ticker").agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
pl.col("close").count().alias("trade_count"),
])
그룹별 롤링
df["ma_20"] = df.groupby("ticker")["close"].transform(
lambda x: x.rolling(20).mean()
)
df = df.with_columns(
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20")
)
QuestDB와의 통합
Polars는 Apache Arrow와 네이티브하게 작동합니다 — QuestDB가 데이터 전송에 사용하는 것과 같은 포맷입니다. 즉, 쿼리 결과 수신 시 제로카피가 가능합니다:
import pyarrow as pa
from questdb.ingress import Sender
arrow_table = questdb_connection.query_arrow(
"SELECT * FROM candles WHERE ticker = 'ETHUSDT'"
)
df = pl.from_arrow(arrow_table) # zero-copy!
df_pd = arrow_table.to_pandas() # copy + type conversion
트레이딩 데이터 저장 및 분석을 위한 QuestDB 활용에 대해서는 데이터 아키텍처에 관한 일련의 기사를 참조하세요.
Parquet 캐시와의 통합
 predicate pushdown과 projection pushdown을 통한 선택적 데이터 로딩이 가능한 컬럼형 Parquet 캐시
predicate pushdown과 projection pushdown을 통한 선택적 데이터 로딩이 가능한 컬럼형 Parquet 캐시
집계 Parquet 캐시 기사에서, 타임프레임과 지표를 한 번 계산하여 Parquet 파일에 저장하는 방법을 설명했습니다. Polars는 이 접근 방식을 더욱 효율적으로 만듭니다:
cache = (
pl.scan_parquet("raw_candles_1m.parquet")
.with_columns([
pl.col("close")
.rolling_mean(window_size=60)
.alias("ma_1h"),
pl.col("close")
.rolling_mean(window_size=240)
.alias("ma_4h"),
pl.col("close")
.rolling_mean(window_size=20)
.alias("bb_mid"),
pl.col("close")
.rolling_std(window_size=20)
.alias("bb_std"),
])
.with_columns([
(pl.col("bb_mid") + 2.0 * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - 2.0 * pl.col("bb_std")).alias("bb_lower"),
])
.collect()
)
cache.write_parquet(
"cache_ETHUSDT_2024_2026.parquet",
compression="zstd",
compression_level=3,
)
대량 최적화 시 — 수천 개의 파라미터 조합을 실행해야 할 때 — Polars의 scan_parquet와 predicate pushdown을 사용하여 Parquet 캐시에서 읽으면 전체 파일을 읽지 않고 필요한 기간과 열만 로딩할 수 있습니다.
적응형 드릴다운과의 통합: Polars의 지연 평가는 2단계 로딩에 완벽하게 적합합니다 — 메인 패스를 위한 대략적인 데이터와, 체결 모호 구간을 위한 상세 데이터(초, 밀리초).
언제 무엇을 사용할 것인가: 실용적 권장사항
 의사결정 매트릭스: 소규모 프로토타이핑 vs 대규모 프로덕션 파이프라인의 갈림길
의사결정 매트릭스: 소규모 프로토타이핑 vs 대규모 프로덕션 파이프라인의 갈림길
Pandas가 적절한 경우:
- 데이터셋이 1M행 이하이고 수백 그룹에 대한 GroupBy를 하지 않는 경우 — Pandas 2.2와 Polars의 차이는 무시할 만한 수준(1.5~2배)인 경우가 많음
pandas-ta가 필요하거나 Pandas API를 가진 다른 라이브러리가 필요한 경우 — 일회성 연구를 위해 130개의 지표를 다시 작성하는 것은 비현실적- 프로토타이핑 — Pandas API가 대부분의 사용자에게 더 익숙하고, 빠른 가설 검증에서는 속도가 중요하지 않음
- 레거시 코드와의 통합 — 작동하고 최적화가 필요 없는 기존 Pandas 파이프라인
Polars가 필요한 경우:
- 1000만 행 이상의 데이터셋 — 수천만, 수억 행의 틱 데이터, 멀티타임프레임 캐시
- 그룹별 롤링 — 100개 이상의 종목, 각각의 지표: 100~3500배 속도 향상
- ETL 파이프라인 — 대량 데이터의 로딩, 클렌징, 변환
- RAM 제한 — 지연 평가와 스트리밍 엔진으로 메모리에 맞지 않는 데이터 처리 가능
- Parquet/QuestDB 스택 — 네이티브 Arrow = 제로카피, predicate pushdown, projection pushdown
과도한 기대는 금물
"30배 빠름"이라는 마케팅 수치는 특정 연산에서의 피크 속도 향상입니다. 일반적인 파이프라인 연산에서의 현실적인 속도 향상: 2~10배. 그룹별 롤링에서는 훨씬 더 큽니다. 소규모 데이터셋에서는 오버헤드로 인해 Polars가 더 느린 경우도 있습니다.
marketmaker.cc에서의 경험
 프로덕션 메트릭: 파이프라인 6~8배 속도 향상과 시간당 8배 더 많은 최적화 반복
프로덕션 메트릭: 파이프라인 6~8배 속도 향상과 시간당 8배 더 많은 최적화 반복
marketmaker.cc에서는 백테스트 엔진에 하이브리드 Polars + Numba 아키텍처를 사용합니다. 전체 데이터 파이프라인 — Parquet 캐시에서의 로딩, 지표 계산, 필터링, 피처 엔지니어링 — 은 Polars로 실행됩니다. 포트폴리오 시뮬레이션은 Numba로 실행됩니다.
데이터 파이프라인에서 Pandas에서 Polars로 전환한 결과, 일반적인 데이터셋(50100M행, 200개 이상 종목)에서 68배 속도 향상을 달성했습니다. 그룹별 롤링 지표 계산이 수분에서 수백 밀리초로 단축되었습니다. 이를 통해 하드웨어 변경 없이 시간당 최적화 반복 횟수를 약 500에서 약 4000으로 늘릴 수 있었습니다.
핵심 포인트: 하루 만에 모든 코드를 마이그레이션한 것은 아닙니다. 먼저 I/O(Parquet 읽기)를 옮기고, 다음으로 지표 계산, 그리고 필터링과 피처 엔지니어링을 옮겼습니다. Pandas는 pd.DataFrame을 기대하는 레거시 컴포넌트와의 인터페이스에만 남아있습니다. df.to_pandas() / pl.from_pandas() 변환은 밀리초 단위로 완료되며 병목이 되지 않습니다.
백테스트 단계에서 계산되는 메트릭 — 활성 시간별 PnL 포함 — 은 이미 Polars DataFrame에서 계산되어 파이프라인을 단순화하고 중간 변환을 제거합니다.
결론
 세 가지 기술 흐름의 수렴: Polars, Numba, Arrow가 하나의 최적화된 파이프라인으로 통합
세 가지 기술 흐름의 수렴: Polars, Numba, Arrow가 하나의 최적화된 파이프라인으로 통합
Polars는 모든 시나리오에서 Pandas의 대체재가 아닙니다. 본격적인 알고트레이딩에 전형적인 규모 — 수백만, 수억 행, 수십, 수백 종목, 지속적인 파라미터 최적화 — 에서 빛을 발하는 다른 등급의 도구입니다.
핵심 수치:
- 기본 연산: 일반적인 파이프라인 작업에서 2~10배 속도 향상
- 그룹별 롤링: 10~3500배 — 트레이딩 파이프라인의 주요 킬러 피처
- CSV I/O: 최대 25배 — 초기 데이터 로딩에 매우 중요
- 메모리: Arrow와 지연 평가를 통한 2~6배 절약
- 스트리밍: RAM에 맞지 않는 데이터 처리
프로덕션 백테스트 엔진을 위한 권장 아키텍처:
- Polars — 전체 데이터 파이프라인: 로딩, 지표, 필터링, 피처
- Numba/Rust — 포트폴리오 시뮬레이션: 경로 의존적 주문 및 포지션 로직
- Arrow — 모든 접합부에서의 데이터 포맷: Parquet, QuestDB, Polars, NumPy
중간 Pandas 레이어 없이. 데이터는 스토리지에서 Polars를 통해 NumPy 배열로, 그리고 Numba 엔진으로 흐릅니다 — 불필요한 복사 없이, GIL 없이, 싱글스레드 병목 없이.
유용한 링크
- Polars — User Guide
- Polars vs Pandas — official benchmark
- PDS-H Benchmark — DataFrame libraries comparison
- Apache Arrow — columnar format specification
- Numba — JIT compiler for Python
- vectorbt — backtesting framework
- pandas-ta — Technical Analysis Indicators
- Ritchie Vink — I wrote one of the fastest DataFrame libraries (Polars origin)
- Towards Data Science — Polars vs Pandas: real-world benchmarks
- Ernest Chan — Quantitative Trading
Citation
@article{soloviov2026polarsvspandas,
author = {Soloviov, Eugen},
title = {Polars vs Pandas for Algotrading: Benchmarks on Real Data},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/polars-vs-pandas-algotrading},
description = {Detailed comparison of Polars and Pandas on algotrading tasks: benchmarks for filtering, aggregation, rolling signal computations, I/O, and memory consumption. Hybrid Polars + Numba architecture for maximum backtest performance.}
}
MarketMaker.cc Team
퀀트 리서치 및 전략