시그널 상관관계: 몇 개의 페어를 모니터링해야 하는가
10개의 암호화폐 페어에서 전략을 실행합니다: BTC/USDT, ETH/USDT, SOL/USDT, AVAX/USDT 그리고 6개의 알트코인. 논리는 완벽해 보입니다: 전략이 하나의 페어에서 5%의 시간 동안 활성화된다면, 10개 페어에서는 적어도 하나가 활성화될 확률이 입니다. 활용률이 4배 증가하는 셈입니다.
실제로는 활용률이 40%가 아닌 15-16%입니다. 10개의 페어가 3개처럼 행동합니다. 자본은 유휴 상태에 놓이고, fill_efficiency는 떨어지며, 실효 포트폴리오 수익률은 예측의 3분의 1에 그칩니다.
원인은 시그널 상관관계입니다. 그리고 암호화폐에서는 이것이 치명적으로 높습니다.
암호화폐의 분산 환상
전통 금융에서는 Apple 주식과 원유 ETF가 서로 다른 요인에 반응하기 때문에 분산이 효과적입니다. 암호화폐 시장에서는 모든 것이 다릅니다.
BTC가 지배적인 요인입니다. 비트코인이 5% 하락하면, ETH는 6-8% 하락하고, SOL은 8-12% 하락하며, 알트코인은 10-20% 하락합니다. 암호화폐 시장의 일일 수익률 상관관계는 지속적으로 0.6을 넘으며, 패닉 시에는 1.0에 접근합니다.
하지만 알고 트레이더인 우리에게 중요한 것은 가격 상관관계가 아니라 시그널 상관관계입니다. 전략이 모멘텀에 기반하고 BTC가 진입 시그널을 트리거하면, ETH와 SOL도 같은 분 내에 유사한 시그널을 트리거할 확률이 높습니다. 모든 페어가 동시에 롱에 진입하고, 동시에 청산합니다. 10개의 포지션 — 하지만 본질적으로 하나의 베팅입니다.
왜 10개 페어 ≠ 10배 분산인가
형식적 정의
개 페어 각각에서 전략이 시간의 비율만큼 활성화된다고 가정합니다. 시그널이 완전히 독립적이라면, 적어도 하나의 페어가 활성화될 확률:
전략 B (, )의 경우:
하지만 시그널은 독립적이지 않습니다. 암호화폐는 동기화되어 움직이며 — 시그널이 클러스터로 발생하고 소멸합니다.
상관관계가 10개 페어를 3개로 변환한다
직관은 이렇습니다: 10개 페어가 상관되어 있다면, 10개의 독립적인 소스가 아니라 3-4개의 소스에서 정보를 담고 있습니다. 이를 effective_N으로 형식화합니다:
여기서 는 correlation factor로, 평균 쌍별 시그널 상관관계를 반영합니다. 이면 페어가 완전히 독립적이고, 이면 동일합니다.
암호화폐 페어의 경우, 일반적인 . 그러면:
40%가 아닌 15.6%. 2.5배의 차이입니다. Fill efficiency도 그에 따라 떨어지고, 전체 포트폴리오의 실효 수익률도 떨어집니다(PnL per Active Time 참조).
암호화폐 시장의 상관관계
지배적 요인으로서의 BTC
암호화폐 시장은 뚜렷한 팩터 구조를 가지고 있습니다. BTC는 대부분의 알트코인 일일 수익률 분산의 60-80%를 설명합니다. 이는 PCA(주성분 분석)를 통해 명확히 볼 수 있습니다:
import numpy as np
from sklearn.decomposition import PCA
def analyze_crypto_factor_structure(returns_matrix: np.ndarray, pair_names: list) -> dict:
"""
PCA analysis of the factor structure of crypto returns.
Args:
returns_matrix: returns matrix [n_days x n_pairs]
pair_names: list of pair names
"""
pca = PCA()
pca.fit(returns_matrix)
explained = pca.explained_variance_ratio_
cumulative = np.cumsum(explained)
print("Factor structure:")
for i, (var, cum) in enumerate(zip(explained[:5], cumulative[:5])):
print(f" PC{i+1}: {var:.1%} variance (cumulative: {cum:.1%})")
loadings = pca.components_[0]
print("\nPC1 loadings (BTC factor):")
for name, load in sorted(zip(pair_names, loadings), key=lambda x: -abs(x[1])):
print(f" {name}: {load:.3f}")
return {
"explained_variance": explained,
"n_effective_factors": int(np.searchsorted(cumulative, 0.90)) + 1,
"pc1_loadings": dict(zip(pair_names, loadings)),
}
10개 암호화폐 페어 포트폴리오의 일반적인 결과:
| 컴포넌트 | 설명 분산 | 누적 |
|---|---|---|
| PC1 (BTC) | 65% | 65% |
| PC2 | 12% | 77% |
| PC3 | 8% | 85% |
| PC4 | 5% | 90% |
| PC5-PC10 | 10% | 100% |
4개의 팩터가 분산의 90%를 설명합니다. 10개 페어 중 "독립적인" 것은 최대 4개입니다.
시그널 상관관계 vs. 가격 상관관계
여기에 중요한 뉘앙스가 있습니다. 가격 상관관계와 시그널 상관관계는 다른 것입니다. BTC와 ETH의 가격 상관관계는 0.85이지만, 특정 전략의 시그널 상관관계는 진입 로직에 따라 0.95가 될 수도 있고 0.50이 될 수도 있습니다.
예시: RSI 과매수/과매도 전략. BTC의 RSI가 30을 하회(과매도) — 롱 진입. ETH도 같은 순간에 과매도 상태일 수 있습니다(시그널 상관관계 ~0.90). 혹은 ETH가 더 천천히 하락하고 있었다면 그렇지 않을 수 있습니다(시그널 상관관계 ~0.40).
올바른 접근법은 가격 시계열이 아닌 시그널 자체의 상관관계를 측정하는 것입니다:
import numpy as np
from itertools import combinations
def signal_correlation_matrix(
signals: dict, # {pair: np.array of 0/1 per minute}
method: str = "pearson",
) -> np.ndarray:
"""
Calculate the signal correlation matrix (binary: 0 = flat, 1 = in position).
Args:
signals: dictionary {pair_name: binary_signal_array}
method: correlation method ("pearson", "jaccard")
"""
pairs = sorted(signals.keys())
n = len(pairs)
corr_matrix = np.ones((n, n))
for i, j in combinations(range(n), 2):
s_i = signals[pairs[i]]
s_j = signals[pairs[j]]
if method == "pearson":
corr = np.corrcoef(s_i, s_j)[0, 1]
elif method == "jaccard":
intersection = np.sum(s_i & s_j)
union = np.sum(s_i | s_j)
corr = intersection / union if union > 0 else 0
else:
raise ValueError(f"Unknown method: {method}")
corr_matrix[i, j] = corr
corr_matrix[j, i] = corr
return corr_matrix, pairs
def estimate_correlation_factor(corr_matrix: np.ndarray) -> float:
"""
Estimate correlation_factor from the signal correlation matrix.
correlation_factor = 1 + (N-1) * mean_pairwise_correlation
When correlation is 0 → C_f = 1 (all independent).
When correlation is 1 → C_f = N (all identical).
"""
n = corr_matrix.shape[0]
upper_triangle = corr_matrix[np.triu_indices(n, k=1)]
mean_corr = np.mean(upper_triangle)
correlation_factor = 1 + (n - 1) * mean_corr
return correlation_factor
시간적 상관관계: 평온기 vs. 패닉
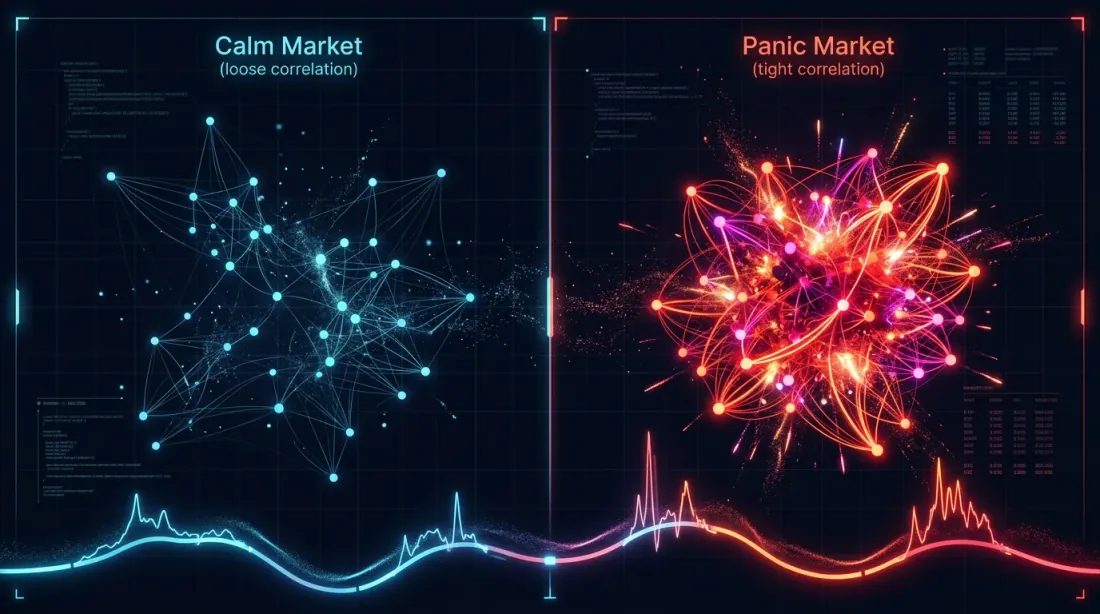
상관관계는 정적이지 않습니다. 평온한 기간에는 BTC와 알트코인이 분리될 수 있습니다 — ETH는 이더리움 뉴스로 상승하고, SOL은 솔라나 뉴스로 상승합니다. 위기 시에는 모든 것이 하나의 팩터로 붕괴합니다: 리스크온/리스크오프.
def rolling_correlation_factor(
signals: dict,
window_days: int = 30,
step_days: int = 7,
) -> list:
"""
Rolling correlation_factor to detect regime changes.
"""
pairs = sorted(signals.keys())
minutes_per_day = 1440
window = window_days * minutes_per_day
step = step_days * minutes_per_day
total_minutes = len(signals[pairs[0]])
results = []
for start in range(0, total_minutes - window, step):
end = start + window
window_signals = {p: signals[p][start:end] for p in pairs}
corr_matrix, _ = signal_correlation_matrix(window_signals)
cf = estimate_correlation_factor(corr_matrix)
results.append({
"start_minute": start,
"end_minute": end,
"correlation_factor": cf,
"effective_n": len(pairs) / cf,
})
return results
10개 암호화폐 페어의 일반적인 양상:
| 시장 레짐 | 평균 시그널 상관관계 | ||
|---|---|---|---|
| 횡보장 (낮은 변동성) | 0.15-0.25 | 2.4-3.3 | 3.0-4.2 |
| 상승 추세 | 0.25-0.40 | 3.3-4.6 | 2.2-3.0 |
| 하락 추세 | 0.30-0.50 | 3.7-5.5 | 1.8-2.7 |
| 패닉 (폭락) | 0.60-0.90 | 6.4-9.1 | 1.1-1.6 |
패닉 시에는 10개 페어가 1-2개의 유효 페어로 압축됩니다. 분산이 가장 필요한 바로 그 순간에 분산이 사라집니다. 이것은 고전적인 "위기 시 상관관계가 1로 수렴한다"의 암호화폐 버전입니다.
effective_N: 핵심 개념

공식과 유도
effective_N의 개념은 통계학에서 차용한 것으로, 유효 표본 크기가 관측값의 자기상관을 고려하는 것입니다. 우리의 목적에서는:
여기서 는 평균 쌍별 시그널 상관관계입니다. 간략 표기:
성질:
- 일 때: , — 완전 독립
- 일 때: , — 모든 페어가 동일
- 이고 일 때: ,
데이터에서 correlation_factor 추정 방법
실전에서는 세 가지 접근법이 있습니다:
1. 시그널 상관관계 행렬에서 (정확).
모든 페어에서 전략을 실행하고, 바이너리 시그널(각 분마다 0/1)을 얻고, 상관관계 행렬을 구축하고, 위 공식으로 를 계산합니다.
2. 가격 수익률의 PCA에서 (근사).
시그널이 가격 역학(모멘텀, 평균 회귀)에 강하게 의존하는 경우, 를 분산의 90%를 설명하는 PCA 컴포넌트 수로 추정할 수 있습니다.
3. 자산 클래스 경험적 추정에서 (대략적).
| 자산 클래스 | 일반적인 |
|---|---|
| 암호화폐 (상위 10) | 2.5-4.0 |
| 암호화폐 (DeFi/밈코인 포함) | 2.0-3.0 |
| 외환 (메이저) | 1.5-2.5 |
| 주식 (단일 섹터) | 2.0-3.5 |
| 주식 (크로스 섹터) | 1.2-1.8 |
BTC, ETH, SOL, AVAX, MATIC, DOGE, DOT, LINK, UNI, ATOM으로 구성된 암호화폐 포트폴리오의 경우, 안전한 추정치는 입니다.
슬롯 활용률 모델링

공식
상관관계를 고려한 기본 공식:
다양한 전략과 페어 수에 대한 표 ():
| 전략 | (거래 시간) | 5 페어 () | 10 페어 () | 20 페어 () | 50 페어 () |
|---|---|---|---|---|---|
| 전략 B | 5% | 8.2% | 15.6% | 29.1% | 58.0% |
| 전략 A | 15% | 23.6% | 41.8% | 65.9% | 92.8% |
| 전략 C | 45% | 67.1% | 89.0% | 98.8% | ~100% |
5% 활동의 전략 B의 경우, 적어도 하나의 활성 포지션이 절반의 시간에 존재하려면 50개 페어가 필요합니다. 그것도 50개의 암호화폐 페어가 10개보다 더 강하게 상관되어 있다는 사실을 고려하지 않은 것입니다.
멀티슬롯 오케스트레이터
실제 오케스트레이터는 여러 슬롯을 동시에 관리합니다. 5개 슬롯과 10개 페어가 있다면, 활용률 계산이 달라집니다:
def estimate_fill_efficiency(
trading_time_pct: float,
n_pairs: int,
correlation_factor: float = 3.0,
max_slots: int = 1,
) -> dict:
"""
Analytical estimate of fill efficiency for a multi-slot orchestrator.
Args:
trading_time_pct: fraction of active time for one strategy on one pair
n_pairs: number of trading pairs
correlation_factor: signal correlation coefficient
max_slots: maximum number of simultaneous positions
Returns:
dict with utilization metrics
"""
effective_n = n_pairs / correlation_factor
p_at_least_one = 1 - (1 - trading_time_pct) ** effective_n
expected_active = effective_n * trading_time_pct
utilization = min(expected_active, max_slots) / max_slots
fill_efficiency = min(p_at_least_one, utilization)
return {
"effective_n": effective_n,
"p_at_least_one": p_at_least_one,
"expected_active": expected_active,
"utilization": utilization,
"fill_efficiency": fill_efficiency,
}
configs = [
("Strategy B, 10 pairs, 1 slot", 0.05, 10, 3.0, 1),
("Strategy B, 10 pairs, 3 slots", 0.05, 10, 3.0, 3),
("Strategy B, 30 pairs, 1 slot", 0.05, 30, 3.0, 1),
("Strategy A, 10 pairs, 1 slot", 0.15, 10, 3.0, 1),
("Strategy C, 10 pairs, 1 slot", 0.45, 10, 3.0, 1),
("Strategy C, 10 pairs, 5 slots", 0.45, 10, 3.0, 5),
]
for name, p, n, cf, slots in configs:
result = estimate_fill_efficiency(p, n, cf, slots)
print(f"{name}:")
print(f" N_eff = {result['effective_n']:.1f}")
print(f" P(≥1 active) = {result['p_at_least_one']:.1%}")
print(f" E[active] = {result['expected_active']:.2f}")
print(f" fill_efficiency = {result['fill_efficiency']:.1%}")
print()
예상 출력:
Strategy B, 10 pairs, 1 slot:
N_eff = 3.3
P(≥1 active) = 15.6%
E[active] = 0.17
fill_efficiency = 15.6%
Strategy B, 10 pairs, 3 slots:
N_eff = 3.3
P(≥1 active) = 15.6%
E[active] = 0.17
fill_efficiency = 5.6%
Strategy B, 30 pairs, 1 slot:
N_eff = 10.0
P(≥1 active) = 40.1%
E[active] = 0.50
fill_efficiency = 40.1%
Strategy A, 10 pairs, 1 slot:
N_eff = 3.3
P(≥1 active) = 41.8%
E[active] = 0.50
fill_efficiency = 41.8%
Strategy C, 10 pairs, 1 slot:
N_eff = 3.3
P(≥1 active) = 89.0%
E[active] = 1.50
fill_efficiency = 89.0%
Strategy C, 10 pairs, 5 slots:
N_eff = 3.3
P(≥1 active) = 89.0%
E[active] = 1.50
fill_efficiency = 30.0%
참고: 전략 B의 3슬롯, 10페어에서 fill_efficiency는 5.6%입니다. 예상 활성 페어 수가 0.17에 불과할 때 3개 슬롯은 무의미합니다. 슬롯은 예상 부하에 비례하여 할당해야 합니다.
실제 데이터 시뮬레이션
분석 모델은 근사치입니다. 정확한 추정을 위해서는 실제 시그널로 시뮬레이션이 필요합니다:
import numpy as np
def simulate_fill_efficiency(
all_signals: dict, # {(strategy, pair): [(entry_min, exit_min), ...]}
max_slots: int = 10,
test_period_minutes: int = 750 * 24 * 60, # 750 days
priority_fn=None, # priority function for position selection
) -> dict:
"""
Simulate real slot load of the orchestrator.
For each minute: count how many pairs want to enter a position,
and how many slots are actually occupied (accounting for the limit).
Args:
all_signals: signals by pairs and strategies
max_slots: maximum number of simultaneous positions
test_period_minutes: length of the test period in minutes
priority_fn: if None — FIFO; otherwise — ranking function
"""
demand_timeline = np.zeros(test_period_minutes, dtype=np.int32)
capped_timeline = np.zeros(test_period_minutes, dtype=np.int32)
for signals in all_signals.values():
for entry_min, exit_min in signals:
if entry_min < test_period_minutes:
end = min(exit_min, test_period_minutes)
demand_timeline[entry_min:end] += 1
capped_timeline = np.minimum(demand_timeline, max_slots)
total_demand = np.sum(demand_timeline)
total_filled = np.sum(capped_timeline)
time_with_any_active = np.sum(demand_timeline > 0)
fill_efficiency = np.mean(capped_timeline) / max_slots
demand_fill_ratio = total_filled / total_demand if total_demand > 0 else 0
time_utilization = time_with_any_active / test_period_minutes
slot_distribution = {}
for s in range(max_slots + 1):
slot_distribution[s] = np.mean(capped_timeline == s)
return {
"fill_efficiency": fill_efficiency,
"demand_fill_ratio": demand_fill_ratio,
"time_utilization": time_utilization,
"avg_demand": np.mean(demand_timeline),
"avg_filled": np.mean(capped_timeline),
"slot_distribution": slot_distribution,
"overflow_pct": np.mean(demand_timeline > max_slots),
}
실제 데이터 시뮬레이션은 분석적 추정보다 더 낮은 활용률을 보여주는 경우가 많습니다. 이는 시그널의 시간적 클러스터링을 고려하기 때문입니다: 모든 페어가 클러스터에서 동시에 진입하여 오버플로를 만들고, 이후 모두 침묵하여 공백을 만듭니다.
몇 개의 페어를 모니터링해야 하는가? 수확 체감 분석
핵심 질문: 어떤 에서 하나의 페어를 더 추가해도 fill_efficiency가 눈에 띄게 증가하지 않는가?
import numpy as np
def diminishing_returns_analysis(
trading_time_pct: float,
correlation_factor: float = 3.0,
max_pairs: int = 100,
target_utilization: float = 0.80,
) -> dict:
"""
Diminishing returns analysis from adding new pairs.
"""
results = []
target_n = None
for n in range(1, max_pairs + 1):
n_eff = n / correlation_factor
p_active = 1 - (1 - trading_time_pct) ** n_eff
marginal = 0
if n > 1:
prev_eff = (n - 1) / correlation_factor
prev_p = 1 - (1 - trading_time_pct) ** prev_eff
marginal = p_active - prev_p
results.append({
"n_pairs": n,
"n_effective": n_eff,
"p_at_least_one": p_active,
"marginal_gain": marginal,
})
if target_n is None and p_active >= target_utilization:
target_n = n
return {
"results": results,
"target_n_for_utilization": target_n,
}
analysis_b = diminishing_returns_analysis(0.05, correlation_factor=3.0, target_utilization=0.80)
print(f"Strategy B: need {analysis_b['target_n_for_utilization']} pairs for 80% P(≥1)")
for r in analysis_b["results"]:
if r["n_pairs"] in [1, 3, 5, 10, 20, 30, 50, 80]:
print(f" N={r['n_pairs']:3d}: N_eff={r['n_effective']:.1f}, "
f"P(≥1)={r['p_at_least_one']:.1%}, "
f"marginal={r['marginal_gain']:.2%}")
전략 B (, ) 결과:
| 페어 | 한계 이득 | ||
|---|---|---|---|
| 1 | 0.3 | 1.7% | — |
| 3 | 1.0 | 5.0% | +1.7% |
| 5 | 1.7 | 8.2% | +1.6% |
| 10 | 3.3 | 15.6% | +1.4% |
| 20 | 6.7 | 29.1% | +1.1% |
| 30 | 10.0 | 40.1% | +0.9% |
| 50 | 16.7 | 58.0% | +0.6% |
| 80 | 26.7 | 74.5% | +0.4% |
전략 B의 경우, 100개 페어로도 80% 단일 슬롯 활용률에 도달하는 것은 불가능합니다(~96개 페어가 필요). 이것은 근본적인 한계입니다: 거래 시간 5%의 전략은 단일 슬롯 운용에 적합하지 않습니다 — 복수 전략을 결합한 포트폴리오 접근이 필요합니다.
전략 A (, )의 경우:
| 페어 | 한계 이득 | ||
|---|---|---|---|
| 5 | 1.7 | 23.6% | — |
| 10 | 3.3 | 41.8% | +3.3% |
| 20 | 6.7 | 65.9% | +2.1% |
| 30 | 10.0 | 80.3% | +1.2% |
전략 A는 ~30개 페어에서 80% 활용률에 도달합니다. 30번째 페어의 한계 이득은 겨우 +1.2%입니다.
전략 C (, )의 경우:
| 페어 | ||
|---|---|---|
| 3 | 1.0 | 45.0% |
| 5 | 1.7 | 67.1% |
| 10 | 3.3 | 89.0% |
| 15 | 5.0 | 95.0% |
거래 시간 45%의 전략 C는 단 10개 페어에서 90% 활용률에 도달합니다. 더 추가하는 것은 무의미합니다.
페어 간 엣지 저하
페어 수를 제한하는 또 다른 요인이 있습니다: 엣지 저하. BTC/USDT에서 개발하고 최적화한 전략은 유동성이 낮은 알트코인에서 성능이 떨어질 수 있습니다.
저하의 원인:
- 유동성: DOGE/USDT의 슬리피지는 BTC/USDT의 몇 배
- 스프레드: 유동성이 낮은 페어는 매수-매도 스프레드가 넓음
- 미시구조: 오더북 패턴이 페어마다 다름
- 조작: 저유동성 알트코인은 펌프 앤 덤프에 취약
def edge_decay_analysis(
strategy_results: dict, # {pair: {"pnl_per_day": float, "n_trades": int}}
min_trades: int = 30,
) -> list:
"""
Rank pairs by edge accounting for degradation.
"""
ranked = []
for pair, metrics in strategy_results.items():
if metrics["n_trades"] < min_trades:
continue
ranked.append({
"pair": pair,
"pnl_per_day": metrics["pnl_per_day"],
"n_trades": metrics["n_trades"],
"sharpe": metrics.get("sharpe", 0),
})
ranked.sort(key=lambda x: x["pnl_per_day"], reverse=True)
cumulative_pnl = []
running_sum = 0
for i, r in enumerate(ranked):
running_sum += r["pnl_per_day"]
avg = running_sum / (i + 1)
cumulative_pnl.append({
"n_pairs": i + 1,
"last_added": r["pair"],
"last_pnl_per_day": r["pnl_per_day"],
"avg_pnl_per_day": avg,
})
return cumulative_pnl
일반적인 양상:
| 페어 수 | 마지막 추가 | 마지막 PnL/일 | 평균 PnL/일 |
|---|---|---|---|
| 1 | BTC/USDT | 0.89% | 0.89% |
| 2 | ETH/USDT | 0.82% | 0.86% |
| 3 | SOL/USDT | 0.71% | 0.81% |
| 5 | AVAX/USDT | 0.55% | 0.73% |
| 8 | DOT/USDT | 0.31% | 0.61% |
| 10 | DOGE/USDT | 0.12% | 0.53% |
10번째 페어를 추가하면 포트폴리오의 평균 PnL/일이 하락합니다. 8번째 페어 시점에서 엣지는 이미 최고의 절반입니다. fill_efficiency(페어 수와 함께 증가)와 평균 엣지(하락) 간의 균형이 필요합니다.
최적 페어 수: 통합 모델

fill_efficiency와 엣지 저하를 하나의 지표 — 예상 포트폴리오 PnL/일 — 로 통합합니다:
def optimal_pairs_count(
pair_edges: list, # PnL/day in descending order: [0.89, 0.82, 0.71, ...]
trading_time_pct: float,
correlation_factor: float = 3.0,
max_slots: int = 1,
) -> dict:
"""
Find the optimal number of pairs that maximizes portfolio PnL.
"""
best_n = 0
best_score = 0
results = []
for n in range(1, len(pair_edges) + 1):
avg_edge = np.mean(pair_edges[:n])
n_eff = n / correlation_factor
p_active = 1 - (1 - trading_time_pct) ** n_eff
expected_active = n_eff * trading_time_pct
utilization = min(expected_active, max_slots) / max_slots
fill_eff = min(p_active, utilization)
portfolio_score = avg_edge * fill_eff * 365
results.append({
"n_pairs": n,
"avg_edge": avg_edge,
"fill_efficiency": fill_eff,
"portfolio_annualized": portfolio_score,
})
if portfolio_score > best_score:
best_score = portfolio_score
best_n = n
return {
"optimal_n": best_n,
"optimal_score": best_score,
"results": results,
}
edges = [0.89, 0.82, 0.71, 0.65, 0.55, 0.48, 0.40, 0.31, 0.22, 0.12,
0.08, 0.05, 0.02, -0.01, -0.05]
opt = optimal_pairs_count(edges, trading_time_pct=0.15, correlation_factor=3.0)
print(f"Optimal number of pairs: {opt['optimal_n']}")
print(f"Portfolio annualized: {opt['optimal_score']:.1f}%")
for r in opt["results"]:
print(f" N={r['n_pairs']:2d}: avg_edge={r['avg_edge']:.2f}%, "
f"fill_eff={r['fill_efficiency']:.1%}, "
f"portfolio={r['portfolio_annualized']:.1f}%")
최적점은 보통 페어 추가로 인한 한계 fill_efficiency가 평균 엣지 하락을 더 이상 보상하지 못하는 지점에 있습니다. 일반적인 암호화폐 포트폴리오의 경우:
- 전략 B (5% 시간): 최적 8-12개 페어
- 전략 A (15% 시간): 최적 6-10개 페어
- 전략 C (45% 시간): 최적 4-6개 페어
역설: 거래 시간이 가장 짧은 전략이 가장 많은 페어에서 혜택을 받지만, fill_efficiency는 여전히 낮습니다. 해결책은 더 많은 페어가 아니라 다른 전략과의 결합입니다(콤보 전략 참조).
크로스 페어 분산: 상관관계 감소 전략

페어 수를 무한정 늘릴 수 없다면, 를 줄일 수 있습니다 — 즉 시그널 다양성을 높이는 것입니다.
전략 1: 유동성 높은 토큰과 DeFi 토큰의 혼합
BTC, ETH, BNB는 매우 강하게 상관되어 있습니다. 하지만 UNI(DEX), AAVE(렌딩), CRV(스테이블코인)는 독자적인 요인을 가질 수 있습니다. DeFi 토큰을 추가하면 평균 가 0.35에서 0.20-0.25로 낮아집니다:
전략 2: 같은 페어에 다른 전략
하나의 전략으로 10개 페어 대신 — 두 가지 다른 전략으로 5개 페어. 전략이 서로 다른 원리에 기반한다면(모멘텀 vs. 평균 회귀), 시그널이 역상관될 수 있습니다:
- 모멘텀은 가격 상승 시 롱 진입
- 평균 회귀는 가격 하락 시 롱 진입
이것이 을 달성하는 유일한 방법입니다 — 음의 시그널 상관관계를 가진 전략을 사용하는 것입니다.
전략 3: 현물 vs. 선물
펀딩 레이트 차익거래와 현물 거래는 다른 상관관계 구조를 가집니다. 차익거래 전략을 포트폴리오에 추가하면 전체 가 크게 감소합니다. 차익거래는 정의상 수렴이 아닌 발산을 활용하기 때문입니다.
전략 유형별 실전 권장사항
고빈도 저시간 전략 (거래 시간 < 10%)
대표적인 예: 전략 B (5% 시간, 750일간 38번 거래).
- 페어 수: 10-15 (엣지/활용 균형의 최적점)
- 문제: 15개 페어로도 fill_efficiency가 낮음 (~20-25%)
- 해결책: 오케스트레이터에서 다른 전략과의 결합이 필수
- 암호화폐 : 2.5-3.5
- 모니터링: 롤링 로 시장 레짐에 따른 페어 수 조정
중간 시간 전략 (거래 시간 10-30%)
대표적인 예: 전략 A (15% 시간, 750일간 418번 거래).
- 페어 수: 6-10
- 10개 페어에서의 Fill_efficiency: ~40%
- 해결책: 이런 전략 2-3개를 결합하면 80% 이상의 시간을 채울 수 있음
- 암호화폐 : 2.5-3.5
- 핵심: 최대 엣지의 페어를 선택하고, 수량을 쫓지 말 것
고시간 전략 (거래 시간 > 30%)
대표적인 예: 전략 C (45% 시간).
- 페어 수: 4-6
- 6개 페어에서의 Fill_efficiency: ~80%
- 문제: 오버플로 — 여러 페어가 동시에 활성이지만 슬롯이 부족
- 해결책: max_slots 증가 또는 페어 우선순위 부여 추가
- 암호화폐 : 2.5-4.0 (롱 포지션이 위기와 겹치므로 높음)
요약 표
| 매개변수 | 전략 B (5%) | 전략 A (15%) | 전략 C (45%) |
|---|---|---|---|
| 권장 | 10-15 | 6-10 | 4-6 |
| 에서 | 3.3-5.0 | 2.0-3.3 | 1.3-2.0 |
| Fill eff. (1 슬롯) | 15-23% | 32-42% | 77-89% |
| 결합 필요? | 필수 | 바람직 | 불필요 |
| 병목 | 시그널 부족 | 균형 | 오버플로 |
시리즈의 다른 지표와의 연결
이 글은 "환상 없는 백테스트" 시리즈의 11번째 글입니다. 시그널 상관관계는 이전 글의 지표에 직접적으로 영향을 미칩니다:
-
PnL per Active Time: fill_efficiency는 실효 수익률 공식의 핵심 승수입니다. 상관관계를 무시하여 fill_efficiency를 과대평가하면, 포트폴리오 PnL 예측이 지나치게 낙관적이 됩니다.
-
펀딩 레이트: 높은 상관관계에서는 포지션이 동시에 열리고, 펀딩 비용은 슬롯 수에 비례하여 증가합니다. 오버플로 + 펀딩 = 자본의 가속적 소진.
-
펀딩 레이트 차익거래: 차익거래 전략은 포트폴리오의 를 낮추는 자연적인 분산 요소입니다. 그 시그널은 모멘텀이나 평균 회귀 전략과의 상관관계가 약합니다.
-
콤보 전략 (다음 글): 서로 다른 와 를 가진 전략의 포트폴리오를 구성하여 90% 이상의 활용률을 달성하는 방법. 캐스케이드 오케스트레이션은 우선순위를 할당할 때 시그널 상관관계를 고려합니다.
결론
암호화폐에서의 분산은 페어 수의 문제가 아닙니다. 10개의 상관된 페어는 3-4개의 독립적인 페어의 효과만 냅니다. 패닉 시에는 더 적어집니다.
네 가지 핵심:
-
N이 아닌 effective_N을 계산하라. 암호화폐 페어의 . 10개 페어는 ~3.3개의 유효 페어입니다. fill_efficiency는 이 아닌 에 기반하여 계획하십시오.
-
가격 상관관계가 아닌 시그널 상관관계를 측정하라. 가격 상관관계는 대리 지표이지 대체물이 아닙니다. 모든 페어에서 전략을 실행하고 바이너리 시그널 상관관계 행렬을 계산하십시오.
-
엣지 저하를 고려하라. 페어가 많아지면 평균 PnL/일이 낮아집니다. 최적점은 새 페어에서의 한계 fill_efficiency가 엣지 하락을 보상할 수 있는 지점입니다.
-
을 늘리지 말고 를 줄여라. 같은 페어에 서로 다른 전략을 결합하는 것이 하나의 전략을 더 많은 페어에 적용하는 것보다 효과적입니다. 크로스 전략 분산은 을 달성할 수 있습니다.
Correlation factor는 활용률과 수익률 예측이 얼마나 현실적인지를 결정하는 숨겨진 변수입니다. 이를 무시하는 것은 환상 위에 포트폴리오를 구축하는 것을 의미합니다.
참고 링크
- Markowitz, H. — Portfolio Selection (1952)
- López de Prado — Advances in Financial Machine Learning: Denoising and Detoning
- Ledoit, O. & Wolf, M. — Honey, I Shrunk the Sample Covariance Matrix (2004)
- Laloux, L. et al. — Noise Dressing of Financial Correlation Matrices (1999)
- Cont, R. — Empirical Properties of Asset Returns: Stylized Facts and Statistical Issues
- Ernest Chan — Algorithmic Trading: Portfolio Construction and Risk Management
- Rebonato, R. & Jäckel, P. — The Most General Methodology for Creating a Valid Correlation Matrix
Citation
@article{soloviov2026signalcorrelation,
author = {Soloviov, Eugen},
title = {Signal Correlation: How Many Pairs to Monitor},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/signal-correlation-pairs},
version = {0.1.0},
description = {Why 10 crypto pairs don't provide 10x diversification, how to calculate effective\_N via correlation\_factor, and how many pairs you really need to monitor for 80-90\% orchestrator slot utilization.}
}
MarketMaker.cc Team
퀀트 리서치 및 전략


