캐스케이드 전략: 우선순위 실행과 폴백 보완

'환상 없는 백테스트' 시리즈의 최종편. N개의 전략을 M개의 페어에서 운용하는 오케스트레이터를 구축하는 방법, 우선순위와 폴백 실행을 통한 캐스케이드 모드 구현, dual_size 선택, 그리고 전략 포트폴리오의 PnL을 단순 합산으로 백테스트할 수 없는 이유를 설명합니다.
전략 포트폴리오가 필요한 이유
 여러 전략이 제한된 자본을 놓고 경쟁하며, 임의의 시점에 실제로 거래하는 전략은 소수에 불과하고 나머지는 대기 상태
여러 전략이 제한된 자본을 놓고 경쟁하며, 임의의 시점에 실제로 거래하는 전략은 소수에 불과하고 나머지는 대기 상태
전략이 전체 파이프라인을 통과했습니다. 몬테카를로 부트스트랩에서 허용 가능한 5번째 백분위를 보여주었습니다. 워크포워드에서 아웃오브샘플 수익률을 확인했습니다. 펀딩 레이트는 반영 완료, 플래토 분석도 통과했습니다. 전략은 확실히 작동합니다.
하지만 거래 시간은 15%에 불과합니다. 나머지 85%의 시간 동안 자본은 유휴 상태입니다.
두 번째 전략을 실행할까? 세 번째? 열 번째? 아이디어는 명확합니다. 구현은 그렇지 않습니다. 전략 포트폴리오는 단일 봇에서는 존재하지 않는 문제를 만들어냅니다:
- 충돌: 두 전략이 같은 페어에서 반대 포지션을 열려고 합니다.
- 제약: 거래소/리스크 관리가 동시 포지션을 개 이하로 제한합니다.
- 배분: 각 전략에 자본의 어떤 비율을 배분할 것인가?
- 상관관계: 상관성이 높은 암호화폐 페어에서 10개 전략을 실행하는 것은 10배의 분산이 아닙니다.
캐스케이드 전략은 이러한 문제를 해결하는 아키텍처 패턴입니다: 프라이머리 전략이 전체 포지션 크기를 확보하고, 폴백 전략이 포지션을 줄여 유휴 시간을 채웁니다.
캐스케이드 개념: 프라이머리 + 폴백

고확신 전략 (프라이머리)
프라이머리는 엄격한 진입 기준을 가진 전략입니다. 예를 들어, 세 가지 확인 레벨을 가진 트리플 타임프레임: 일봉 + 4시간봉 + 1시간봉 시그널, 변동성과 거래량 필터링 포함.
특성:
- 적은 거래 횟수 (백테스트 기간 동안 수십 건)
- 거래당 높은 PnL
- 낮은 포지션 보유 시간 (5-15%)
- 각 진입에 대한 높은 확신도
폴백 전략
폴백은 완화된 기준을 가진 전략입니다. 듀얼 타임프레임, 적은 필터, 넓은 허용 범위. 더 자주 거래하지만 거래당 에지는 낮습니다.
특성:
- 많은 거래 횟수 (기간 동안 수백 건)
- 거래당 중간 수준의 PnL
- 높은 포지션 보유 시간 (30-50%)
- 중간 수준의 확신도 — 포지션 크기 축소로 보상
캐스케이드 모드
timeline: ──────────────────────────────────────────────────
primary: ___████___________________████████____███________
fallback: ███____███████████████████________████___████████
capital: [dual][ full ][ dual_size ][ full ][ dual ]
프라이머리가 포지션을 열면 폴백은 중단(또는 청산)됩니다. 프라이머리가 대기 중일 때 폴백은 축소된 포지션(dual_size)으로 거래합니다. 우선순위는 무조건적입니다: 프라이머리는 항상 폴백을 대체합니다.
예제에 사용된 전략
시리즈 전체에서 세 가지 전략을 사용했습니다. 750일 기간의 파라미터는 다음과 같습니다:
| 파라미터 | 전략 A | 전략 B | 전략 C |
|---|---|---|---|
| PnL | +55% | +27% | +300% |
| 거래 수 | ~500 | ~40 | ~400 |
| 거래 시간 | ~15% | ~5% | ~45% |
| MaxDD | ~0.9% | ~0.75% | ~17% |
| PnL/활성일 | 0.49%/일 | 0.72%/일 | 0.89%/일 |
| 성격 | 중간 활동 | 저빈도, 높은 확신 | 고빈도, 공격적 |
활성 시간당 PnL에서 보여주었듯이, 원시 PnL 순위와 PnL/활성일 순위는 다른 결과를 만들어냅니다. 캐스케이드 오케스트레이션에서는 후자의 지표가 중요합니다.
최적 dual_size
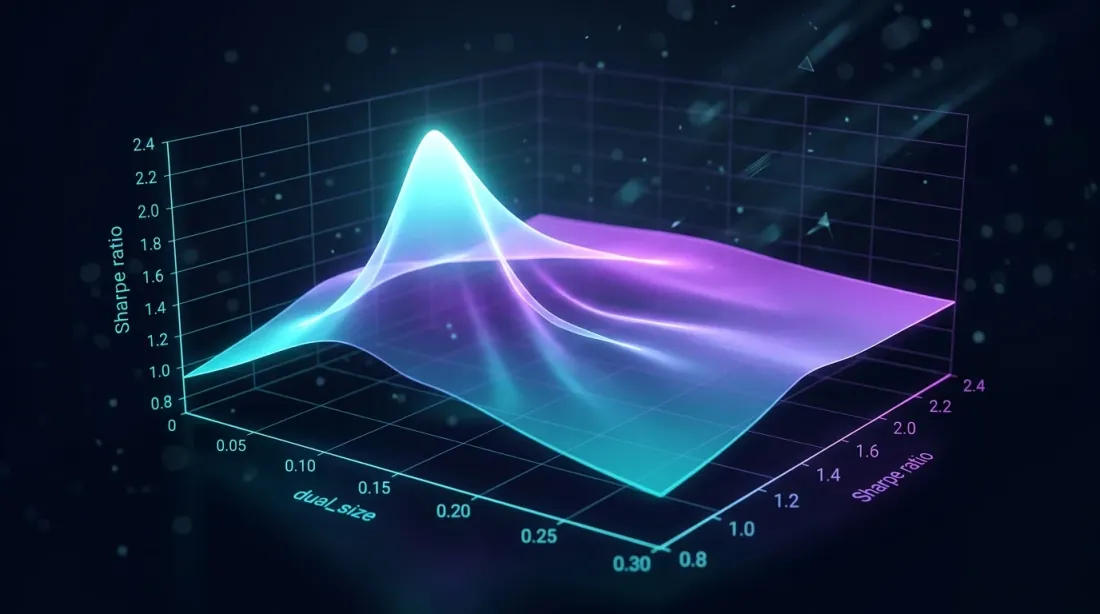 dual_size 그리드 서치로 샤프 비율 피크가 드러남 — 너무 크면 드로다운이 증가하고, 너무 작으면 유휴 시간을 낭비
dual_size 그리드 서치로 샤프 비율 피크가 드러남 — 너무 크면 드로다운이 증가하고, 너무 작으면 유휴 시간을 낭비
선택의 문제
dual_size는 폴백 전략이 받는 전체 포지션의 비율입니다. 이것이 캐스케이드의 핵심 파라미터입니다:
-
너무 큰 경우 (예: 0.5 = 50%): 프라이머리와 폴백이 동시에 활성화되면 총 노출 = 목표의 150%. 드로다운이 두 배가 됩니다. 손실-수익 비대칭성으로 인해 이는 불균형적으로 높은 비용이 됩니다.
-
너무 작은 경우 (예: 0.01 = 1%): 폴백이 유휴 시간의 85%를 채우지만 수익은 미미합니다. 자본은 사실상 유휴 상태입니다.
-
최적값: 폴백이 프라이머리와의 동시 운용 중 드로다운을 치명적으로 증가시키지 않으면서 의미 있는 PnL을 기여하는 값.
정식화
다음을 정의합니다:
- — 단위 시간당 프라이머리 PnL
- — 단위 시간당 폴백 PnL
- — 포지션 보유 시간 비율 (프라이머리)
- — 포지션 보유 시간 비율 (폴백)
- — dual_size (0..1)
- — 양쪽 모두 포지션을 보유하는 시간 비율
캐스케이드 총 PnL:
총 MaxDD (최악의 경우 — 완전 상관):
총 드로다운을 으로 제약할 경우:
그리드 서치
실무에서는 최적 dual_size를 캐스케이드 백테스트의 그리드 서치로 찾습니다:
import numpy as np
from dataclasses import dataclass
@dataclass
class CascadeResult:
dual_size: float
total_pnl: float
max_dd: float
sharpe: float
pnl_per_active_day: float
def grid_search_dual_size(
primary_equity: np.ndarray, # equity curve primary (minute bars)
fallback_equity: np.ndarray, # equity curve fallback (minute bars)
primary_positions: np.ndarray, # 1 = in position, 0 = flat
fallback_positions: np.ndarray,
grid: np.ndarray = np.arange(0.01, 0.30, 0.005),
) -> list[CascadeResult]:
"""
Grid search for dual_size.
primary_equity and fallback_equity are log-returns, minute bars.
"""
results = []
for d in grid:
fallback_active = fallback_positions & ~primary_positions
cascade_returns = (
primary_equity * primary_positions
+ d * fallback_equity * fallback_active
)
equity_curve = np.cumprod(1 + cascade_returns)
peak = np.maximum.accumulate(equity_curve)
drawdown = (equity_curve - peak) / peak
max_dd = drawdown.min()
total_pnl = equity_curve[-1] - 1
sharpe = (
np.mean(cascade_returns) / np.std(cascade_returns)
* np.sqrt(525_600) # minutes per year
) if np.std(cascade_returns) > 0 else 0
active_minutes = np.sum(primary_positions | fallback_active)
active_days = active_minutes / (24 * 60)
pnl_per_day = total_pnl / active_days if active_days > 0 else 0
results.append(CascadeResult(
dual_size=d,
total_pnl=total_pnl,
max_dd=max_dd,
sharpe=sharpe,
pnl_per_active_day=pnl_per_day,
))
return sorted(results, key=lambda r: r.sharpe, reverse=True)
암호화폐 전략의 일반적인 최적값: dual_size는 0.05-0.10 (전체 포지션의 5-10%) 범위. 전략 B를 프라이머리(MaxDD 0.75%), 전략 A를 폴백(MaxDD 0.9%)으로 할 경우:
드로다운 제약은 바인딩되지 않습니다 — 최적값은 캐스케이드 샤프 비율에 의해 결정됩니다. 실무에서 그리드 서치는 일반적으로 (6.8%)을 산출합니다.
스코어 기반 배분
 복합 스코어로 전략을 순위화 — 신뢰도 조정이 작은 표본에 페널티를 부여하고, 펀딩 비용이 순 에지를 감소시킴
복합 스코어로 전략을 순위화 — 신뢰도 조정이 작은 표본에 페널티를 부여하고, 펀딩 비용이 순 에지를 감소시킴
두 개 이상의 전략이 있을 때 캐스케이드는 스코어 기반 배분으로 일반화됩니다.
활성 시간당 PnL에 의한 순위
활성 시간당 PnL에서 자세히 설명한 바와 같이, 전략 스코어는 다음을 고려하여 계산됩니다:
- 활성일당 PnL — 자본 활용 효율성
- 신뢰도 조정 — 작은 표본에 대한 페널티 (t-분포)
- 펀딩 비용 — 레버리지의 실제 비용 (펀딩 레이트)
- MaxLev — 드로다운을 고려한 스케일링 (손실-수익 비대칭성)
저빈도 전략의 신뢰도 조정
40건의 거래를 가진 전략 B에는 심각한 페널티가 필요합니다. 신뢰 구간의 하한을 사용합니다:
import scipy.stats as st
import numpy as np
def confidence_factor(trade_returns: np.ndarray, confidence: float = 0.95) -> float:
"""Confidence factor: 0..1, penalty for small samples."""
n = len(trade_returns)
if n < 10:
return 0.0
mean_r = np.mean(trade_returns)
if mean_r <= 0:
return 0.0
se = np.std(trade_returns, ddof=1) / np.sqrt(n)
t_crit = st.t.ppf(1 - (1 - confidence) / 2, df=n - 1)
ci_lower = mean_r - t_crit * se
return max(0.0, ci_lower / mean_r)
cf_b = confidence_factor(np.random.normal(0.0067, 0.028, 40))
cf_a = confidence_factor(np.random.normal(0.0011, 0.008, 500))
펀딩 비용 통합
무기한 선물에서 펀딩은 8시간마다 지불됩니다. 레버리지 과 평균 레이트 의 경우:
MaxLev = 55x인 전략 A에서 평균 펀딩 레이트 0.01%인 경우:
PnL/활성일 = 0.49%에서 순 PnL은 마이너스가 됩니다: /일. 전략은 최대 레버리지에서 수익이 나지 않습니다. 자세한 분석은 펀딩 레이트가 레버리지를 죽인다를 참조하십시오.
멀티 전략 오케스트레이터
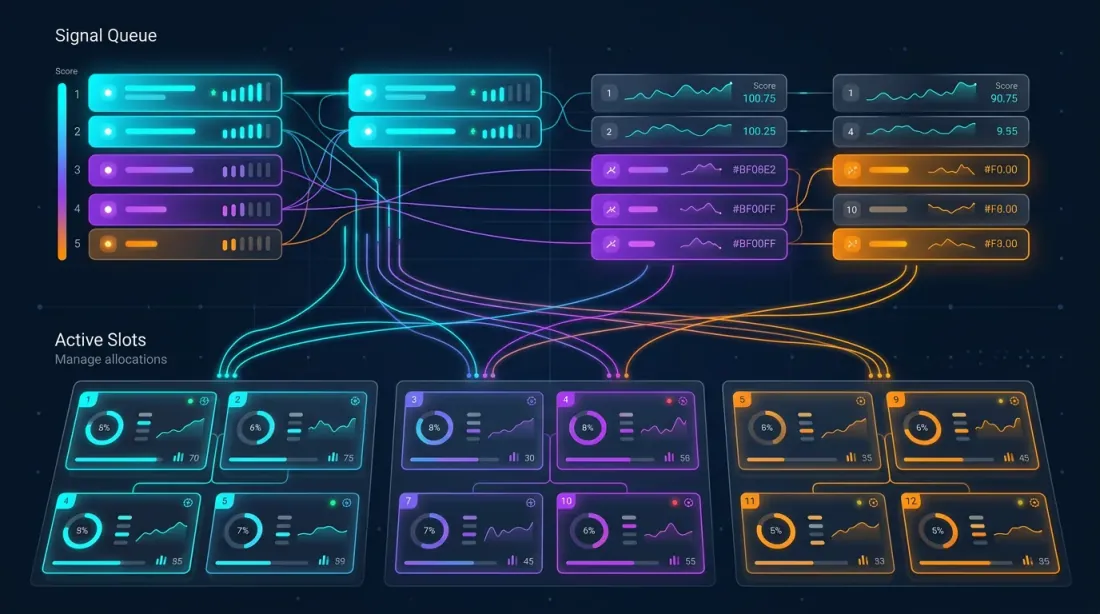
아키텍처
오케스트레이터는 개의 거래 페어에서 개의 전략을 관리합니다. 잠재적 포지션의 총 수: . 하지만 자본은 제한되어 있어 동시 포지션(슬롯)은 개 이하로 허용됩니다.
┌─────────────────────────────────────────────┐
│ ORCHESTRATOR │
│ │
│ Signal Queue (sorted by score): │
│ ┌──────────────────────────────────────┐ │
│ │ 1. Strategy C × ETHUSDT score=223 │ │
│ │ 2. Strategy B × BTCUSDT score=142 │ │
│ │ 3. Strategy A × SOLUSDT score=100 │ │
│ │ 4. Strategy C × BTCUSDT score=89 │ │
│ │ 5. Strategy A × ETHUSDT score=76 │ │
│ └──────────────────────────────────────┘ │
│ │
│ Active Slots (max_parallel = 3): │
│ ┌──────────────────────────────────────┐ │
│ │ Slot 1: Strategy C × ETHUSDT [FULL] │ │
│ │ Slot 2: Strategy B × BTCUSDT [FULL] │ │
│ │ Slot 3: Strategy A × SOLUSDT [DUAL] │ │
│ └──────────────────────────────────────┘ │
│ │
│ Conflict Rules: │
│ - One position per pair │
│ - Primary displaces fallback on same pair │
│ - Higher score wins for cross-pair slots │
└─────────────────────────────────────────────┘
슬롯 관리
from dataclasses import dataclass, field
from enum import Enum
from typing import Optional
import heapq
import time
class SlotType(Enum):
FULL = "full" # primary strategy, 100% position
DUAL = "dual" # fallback strategy, dual_size position
@dataclass
class Signal:
strategy_id: str
pair: str
direction: str # "long" | "short"
score: float
is_primary: bool # primary or fallback
timestamp: float
@dataclass(order=True)
class Slot:
"""A single orchestrator slot."""
priority: float = field(compare=True) # negative score for min-heap
strategy_id: str = field(compare=False)
pair: str = field(compare=False)
slot_type: SlotType = field(compare=False)
entry_time: float = field(compare=False)
class Orchestrator:
"""
Multi-strategy orchestrator with cascade mode.
Manages N strategies x M pairs within max_parallel_positions slots.
Primary strategies have unconditional priority over fallback.
"""
def __init__(
self,
max_parallel_positions: int = 10,
dual_size: float = 0.068,
min_score: float = 0,
):
self.max_parallel = max_parallel_positions
self.dual_size = dual_size
self.min_score = min_score
self.active_slots: dict[str, Slot] = {} # pair -> Slot
self.pending_signals: list[Signal] = []
def on_signal(self, signal: Signal) -> Optional[dict]:
"""
Process a new signal. Returns an action or None.
Actions:
- {"action": "open", "pair": ..., "size": ..., "slot_type": ...}
- {"action": "replace", "pair": ..., "close_strategy": ..., "open_strategy": ...}
- None (signal rejected)
"""
if signal.score < self.min_score:
return None
pair = signal.pair
if pair in self.active_slots:
existing = self.active_slots[pair]
if signal.is_primary and existing.slot_type == SlotType.DUAL:
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=SlotType.FULL,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": 1.0,
}
if signal.score > -existing.priority:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # existing has higher priority
if len(self.active_slots) < self.max_parallel:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "open",
"pair": pair,
"strategy": signal.strategy_id,
"size": size,
"slot_type": slot_type,
}
worst_pair = min(
self.active_slots,
key=lambda p: -self.active_slots[p].priority,
)
worst_slot = self.active_slots[worst_pair]
if signal.score > -worst_slot.priority:
del self.active_slots[worst_pair]
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": worst_slot.strategy_id,
"close_pair": worst_pair,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # all active slots have higher scores
def on_exit(self, pair: str) -> None:
"""Strategy closed a position."""
if pair in self.active_slots:
del self.active_slots[pair]
def utilization(self) -> float:
"""Current slot utilization."""
return len(self.active_slots) / self.max_parallel
def fill_efficiency_snapshot(self) -> float:
"""Weighted utilization: FULL=1.0, DUAL=dual_size."""
total = sum(
1.0 if s.slot_type == SlotType.FULL else self.dual_size
for s in self.active_slots.values()
)
return total / self.max_parallel
충돌 해결
세 가지 수준의 충돌이 있습니다:
레벨 1 — 같은 페어, 같은 방향. 스코어가 높은 전략이 이깁니다. 둘 다 프라이머리인 경우 스코어가 승자를 결정합니다. 하나가 프라이머리이고 다른 하나가 폴백인 경우 프라이머리가 무조건 이깁니다.
레벨 2 — 같은 페어, 반대 방향. 금지: 같은 페어에서 동시에 롱과 숏을 보유할 수 없습니다. 스코어가 가장 높은 전략이 이깁니다.
레벨 3 — 크로스 페어 경쟁. 모든 슬롯이 점유된 경우, 새 시그널이 가장 낮은 스코어의 슬롯을 축출합니다. 이는 우선순위 큐로 작동합니다.
캐스케이드 백테스트: 방법론
 공동 시뮬레이션: 프라이머리와 폴백 에퀴티 커브에 오버랩 존과 결합된 캐스케이드 결과 표시
공동 시뮬레이션: 프라이머리와 폴백 에퀴티 커브에 오버랩 존과 결합된 캐스케이드 결과 표시
PnL을 단순 합산할 수 없는 이유
순진한 접근법: 각 전략을 개별적으로 백테스트하고 PnL을 합산합니다. 이는 세 가지 이유로 부풀려진 결과를 만듭니다:
-
시간 오버랩. 프라이머리와 폴백이 동시에 활성화되면 폴백은 거래하지 않아야 합니다(또는 dual_size로 거래). 단순 합산은 이 오버랩을 무시합니다.
-
자본 제약. 총 포지션은 제한됩니다. 5개 전략이 동시에 진입하려 하지만 3개 슬롯만 있다면 2개 전략은 진입할 수 없습니다. 그 PnL은 계산할 수 없습니다.
-
거래 비용. 캐스케이드 전환(폴백 청산, 프라이머리 진입)은 개별 백테스트에 없는 추가 수수료를 발생시킵니다.
공동 시뮬레이션
올바른 캐스케이드 백테스트는 공유 타임라인에서 모든 전략의 공동 시뮬레이션입니다:
import numpy as np
from typing import NamedTuple
class Trade(NamedTuple):
strategy: str
pair: str
entry_time: int # minute index
exit_time: int # minute index
pnl_per_minute: float # log-return per minute
is_primary: bool
score: float
def backtest_cascade(
all_trades: list[Trade],
total_minutes: int,
max_slots: int = 10,
dual_size: float = 0.068,
switch_cost: float = 0.0006, # 0.06% round-trip
) -> dict:
"""
Joint simulation of cascade portfolio.
Walk through each minute, apply orchestrator rules,
calculate PnL accounting for overlap and slot constraints.
"""
entries = {}
exits = {}
active_trades = {} # trade_id -> Trade
for i, trade in enumerate(all_trades):
entries.setdefault(trade.entry_time, []).append((i, trade))
exits.setdefault(trade.exit_time, []).append((i, trade))
active_slots = {} # pair -> (trade_id, SlotType)
equity = np.ones(total_minutes)
switch_costs_total = 0.0
for t in range(1, total_minutes):
for trade_id, trade in exits.get(t, []):
if trade.pair in active_slots:
slot_id, _ = active_slots[trade.pair]
if slot_id == trade_id:
del active_slots[trade.pair]
new_signals = sorted(
entries.get(t, []),
key=lambda x: x[1].score,
reverse=True,
)
for trade_id, trade in new_signals:
pair = trade.pair
if pair in active_slots:
existing_id, existing_type = active_slots[pair]
existing_trade = all_trades[existing_id]
if trade.is_primary and existing_type == SlotType.DUAL:
active_slots[pair] = (trade_id, SlotType.FULL)
switch_costs_total += switch_cost
continue
if trade.score > existing_trade.score:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
switch_costs_total += switch_cost
elif len(active_slots) < max_slots:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
minute_return = 0.0
for pair, (trade_id, slot_type) in active_slots.items():
trade = all_trades[trade_id]
size = 1.0 if slot_type == SlotType.FULL else dual_size
minute_return += trade.pnl_per_minute * size
equity[t] = equity[t - 1] * (1 + minute_return)
peak = np.maximum.accumulate(equity)
max_dd = ((equity - peak) / peak).min()
total_pnl = equity[-1] - 1 - switch_costs_total
return {
"total_pnl": total_pnl,
"max_dd": max_dd,
"switch_costs": switch_costs_total,
"equity_curve": equity,
}
전환 시 거래 비용
각 캐스케이드 전환(폴백 -> 프라이머리)에는 다음이 필요합니다:
- 폴백 포지션 청산: 테이커 수수료 (Binance 선물 0.04%)
- 프라이머리 포지션 진입: 테이커 수수료 (0.04%)
- 스프레드: ~0.01-0.02%
총 전환 비용: 전환당 ~0.06-0.10%. 기간 동안 100회 전환이 있을 경우:
이는 상당한 금액입니다. 빈번한 전환이 있는 캐스케이드는 거래 비용으로 인해 단일 전략보다 성과가 나빠질 수 있습니다.
멀티 페어 확장: M개 페어에서 N개 전략
 N개 전략이 M개 거래 페어에 연결된 네트워크 — 상관관계의 강도가 실효적 분산을 결정
N개 전략이 M개 거래 페어에 연결된 네트워크 — 상관관계의 강도가 실효적 분산을 결정
조합 공간
10개 페어에서 3개 전략 = 30개 잠재적 시그널. max_slots = 5인 경우, 오케스트레이터는 스코어 상위 5개를 선택합니다. 이는 조합 문제입니다: 각 순간에 가지 가능한 포트폴리오.
실무에서 탐욕 알고리즘(스코어 정렬 후 위에서부터 채움)은 로 거의 최적의 결과를 생성합니다.
페어 간 상관관계
암호화폐 페어는 강하게 상관되어 있습니다. BTC가 하락하면 ETH, SOL, AVAX도 함께 하락합니다. 이는 5개의 다른 페어에서의 5개 롱 포지션이 사실상 "암호화폐 시장"에 대한 하나의 큰 포지션임을 의미합니다.
시그널 상관관계에서 자세히 분석한 바와 같이, 독립 포지션의 실효 수는:
여기서 는 페어 간 평균 상관관계입니다.
, 인 경우:
상관된 페어에서의 5개 포지션은 1.3개의 독립 포지션에 해당합니다. 분산은 사실상 존재하지 않습니다.
캐스케이드에 대한 실용적 시사점
def effective_diversification(
positions: list[dict], # [{"pair": "BTCUSDT", "direction": "long"}, ...]
correlation_matrix: np.ndarray,
pair_index: dict[str, int],
) -> float:
"""
Calculate effective diversification of open positions.
Returns:
N_eff / N — diversification coefficient (0..1)
"""
n = len(positions)
if n <= 1:
return 1.0
total_corr = 0.0
pairs_count = 0
for i in range(n):
for j in range(i + 1, n):
idx_i = pair_index[positions[i]["pair"]]
idx_j = pair_index[positions[j]["pair"]]
rho = correlation_matrix[idx_i, idx_j]
if positions[i]["direction"] != positions[j]["direction"]:
rho = -rho
total_corr += rho
pairs_count += 1
avg_rho = total_corr / pairs_count if pairs_count > 0 else 0
n_eff = n / (1 + (n - 1) * max(0, avg_rho))
return n_eff / n
오케스트레이터는 슬롯을 채울 때 상관관계를 고려해야 합니다. 두 가지 옵션이 있습니다:
- 분산 보너스: 순위 매기기 시 비상관 페어의 전략 스코어에 보너스를 추가.
- 상관관계 캡: 상관된 페어에서 같은 방향 포지션 수를 제한.
캐스케이드 최적화 파이프라인
 데이터 준비에서 검증, 라이브 오케스트레이션까지 8개의 연결된 단계 — 각 단계가 이전 단계 위에 구축됨
데이터 준비에서 검증, 라이브 오케스트레이션까지 8개의 연결된 단계 — 각 단계가 이전 단계 위에 구축됨
데이터에서 프로덕션까지의 전체 파이프라인은 8단계로 구성됩니다:
스테이지 0: 데이터 준비
히스토리컬 데이터를 로드하고 멀티 타임프레임 접근을 위한 Parquet 캐시를 구축합니다. 효율적인 캐싱 없이는 후속 단계가 수용할 수 없을 정도로 느려집니다.
스테이지 1: TF + Length (Hill-Climbing 그리드)
기본 타임프레임과 인디케이터 윈도우 길이를 선택합니다. 거친 그리드: TF는 {1m, 5m, 15m, 1h, 4h}, Length는 {10, 20, 50, 100, 200}. 최적 그리드 포인트에서 Hill-Climbing.
스테이지 2: Separation (좌표 하강법, 12개 파라미터)
Separation 파라미터(진입/이탈)를 최적화합니다. 12개 파라미터에 대한 좌표 하강법 — 인디케이터 임계값, 필터, 스톱로스, 테이크프로핏. 고차원 결정론적 목적 함수에서는 좌표 하강법이 Optuna보다 비용 효율적입니다.
스테이지 3: 메타 파라미터 (좌표 하강법)
메타 파라미터: 최대 보유 시간, 이탈을 위한 최소 PnL, 트레일링 스톱 설정. 다시 좌표 하강법. 플래토 분석으로 강건성을 확인 — 최적값이 점상이면 전략이 과최적화되었습니다.
스테이지 4: 콤보 최적화
페어(프라이머리, 폴백)에 대한 그리드 서치. 각 조합에 대해: dual_size를 선택하고 공동 시뮬레이션으로 캐스케이드 PnL을 계산합니다.
스테이지 5: 검증
다층 검증:
- 멀티 심볼: 최적화 페어뿐만 아니라 10개 이상의 페어에서 전략 테스트
- 워크포워드: 슬라이딩 IS/OOS 윈도우
- 파라미터 안정성: 각 단계에서의 플래토 분석
- 몬테카를로 부트스트랩: 캐스케이드 PnL의 신뢰 구간
- 백테스트-라이브 패리티: 백테스트와 페이퍼 트레이딩 비교
스테이지 6: 순위 및 선택
캐스케이드 조합을 스코어로 순위를 매깁니다. 상위 K개 조합이 스테이지 7로 진출합니다. 스코어는 신뢰도 조정, 펀딩 비용, fill_efficiency를 고려합니다.
스테이지 7: 오케스트레이션
최종 단계: 개 전략과 개 페어에서 캐스케이드 모드로 오케스트레이터를 시작합니다. 슬롯 관리, 우선순위 큐, 충돌 해결 — 위에서 설명한 모든 것이 여기에 집약됩니다.
성과 분석: 캐스케이드 vs. 개별
 나란히 비교: 캐스케이드 포트폴리오가 유휴 시간 활용을 통해 개별 전략을 상회
나란히 비교: 캐스케이드 포트폴리오가 유휴 시간 활용을 통해 개별 전략을 상회
캐스케이드의 이론적 이점
프라이머리가 의 시간 동안 PnL/일 = 0.49%로 거래한다고 가정합니다. 폴백은 에서 PnL/일 = 0.89%. 오버랩 = (독립성 가정).
프라이머리 단독 (전략 A):
캐스케이드 (A 프라이머리 + C 폴백):
캐스케이드 효과: 폴백으로부터 PnL +31% 증가, 드로다운 증가는 최소 (MaxDD에 추가).
캐스케이드가 효과적이지 않은 경우
캐스케이드가 비효율적인 경우:
- 프라이머리 활성 시간이 80% 초과. 유휴 시간이 적어 폴백이 들어갈 여지가 없음.
- 전략의 상관관계가 높음. 프라이머리와 폴백이 동시에 시그널을 생성 — 오버랩이 높고, 폴백은 프라이머리도 대기 중일 때 정확히 대기.
- 전환 비용이 폴백 PnL을 초과. 빈번한 전환 시 캐스케이드 수수료가 폴백 수익을 잠식.
- dual_size가 너무 작음. 에서 폴백은 잠재력의 1%만 벌어들임 — 수수료 이하.
비교표
| 구성 | 연간 PnL | MaxDD | 샤프 | 전환 비용 |
|---|---|---|---|---|
| 전략 A 단독 | 26.8% | 0.9% | 1.42 | 0 |
| 전략 C 단독 | 146.1% | 17% | 1.15 | 0 |
| 캐스케이드 A+C (d=0.068) | 35.2% | 2.06% | 1.58 | ~1.2% |
| 캐스케이드 B+A (d=0.068) | 19.4% | 1.36% | 1.71 | ~0.3% |
| 3전략 오케스트레이터 | 48.7% | 3.1% | 1.63 | ~2.1% |
캐스케이드 A+C: 프라이머리 A가 폴백 C로부터 +8.4%를 획득. 유휴 시간 활용으로 샤프 상승. MaxDD는 완만하게 증가 ().
오케스트레이션: 실무에서의 fill_efficiency
 Fill efficiency ~78%: 히트맵이 전략과 페어 간 시간 활용률을 보여주며, 밝은 셀이 활성 거래를 나타냄
Fill efficiency ~78%: 히트맵이 전략과 페어 간 시간 활용률을 보여주며, 밝은 셀이 활성 거래를 나타냄
fill_efficiency 파라미터는 오케스트레이터가 실제로 유휴 시간을 얼마나 활용하는지를 결정합니다. 활성 시간당 PnL에서 보여준 것처럼, 세 가지 방법으로 추정할 수 있습니다:
- 고정 상수 (0.80) — 거칠지만 범용적
- 분석적 추정 를 통해 — 상관관계를 고려
- 데이터로부터의 시뮬레이션 — 가장 정확
3전략 10페어 캐스케이드의 경우:
def cascade_fill_efficiency(
strategies: list[dict], # [{"trading_time": 0.15, "is_primary": True}, ...]
n_pairs: int = 10,
correlation_factor: float = 3.0,
) -> float:
"""Estimate fill_efficiency for a cascade portfolio."""
n_eff = n_pairs / correlation_factor
primary_times = [s["trading_time"] for s in strategies if s["is_primary"]]
p_primary = 1 - np.prod([(1 - t) ** n_eff for t in primary_times])
fallback_times = [s["trading_time"] for s in strategies if not s["is_primary"]]
p_fallback = 1 - np.prod([(1 - t) ** n_eff for t in fallback_times])
fill = p_primary + (1 - p_primary) * p_fallback
return min(fill, 1.0)
strategies = [
{"trading_time": 0.05, "is_primary": True}, # Strategy B
{"trading_time": 0.15, "is_primary": True}, # Strategy A
{"trading_time": 0.45, "is_primary": False}, # Strategy C as fallback
]
eff = cascade_fill_efficiency(strategies, n_pairs=10, correlation_factor=3.0)
실용적 권장사항
 캐스케이드 배포를 위한 6가지 핵심 권장사항 — 작은 시작부터 적응적 재보정까지
캐스케이드 배포를 위한 6가지 핵심 권장사항 — 작은 시작부터 적응적 재보정까지
1. 두 개의 전략으로 시작하기
20개 페어에서 10개 전략을 바로 시작하지 마십시오. 하나의 프라이머리 + 하나의 폴백을 3-5개 페어에서 시작합니다. 공동 시뮬레이션이 실제 동작과 일치하는지 확인하십시오. 백테스트-라이브 패리티가 중요합니다: 캐스케이드 백테스트가 라이브와 5-10%만 벌어져도 오케스트레이터 로직에 오류가 있습니다.
2. dual_size는 그리드 서치로, 직감이 아닌
최적 dual_size는 전략의 특정 조합에 따라 달라집니다. 6.8%는 가이드라인이지 보편적 상수가 아닙니다. 1%에서 30%까지 0.5% 단위로 그리드 서치를 실행하고 샤프 최대값을 선택하십시오.
3. 슬롯 제한이 아키텍처를 결정한다
max_slots = 1이면 캐스케이드는 단순한 전략 전환으로 퇴화합니다. max_slots = 50이면 제약이 바인딩되지 않고 문제는 독립적인 포트폴리오로 귀결됩니다. 흥미로운 영역: max_slots = 3-10, 슬롯 관리가 결과에 실질적으로 영향을 미치는 범위.
4. 지연 시간을 고려하기
라이브 거래에서 캐스케이드 전환은 순간적이지 않습니다. 폴백 포지션 청산 + 프라이머리 진입 = 2번의 API 호출 + 네트워크 지연 + 거래소 매칭. 변동성이 높은 시장에서는 200-500ms 안에 가격이 움직일 수 있습니다. 슬리피지 예산을 반영하십시오.
5. fill_efficiency 모니터링
프로덕션에서의 실제 fill_efficiency를 추적하십시오. 백테스트보다 현저히 낮다면 오케스트레이터가 기대한 대로 유휴 시간을 활용하지 못하고 있습니다. 원인: API 지연, 주문 거부, 마진 제약.
6. 적응적 최적화 사용
캐스케이드 파라미터(dual_size, 스코어 가중치, 슬롯 제한)는 정적이어서는 안 됩니다. 새 데이터로 주기적인 재보정을 위해 적응적 드릴다운을 사용하십시오. 시장이 변하면 캐스케이드 파라미터도 따라가야 합니다.
'환상 없는 백테스트' 시리즈: 요약
 완전한 시스템 아키텍처: 수학에서 검증, 라이브 오케스트레이션까지 13개의 상호 연결된 모듈
완전한 시스템 아키텍처: 수학에서 검증, 라이브 오케스트레이션까지 13개의 상호 연결된 모듈
이 기사는 13개 이상의 기사로 구성된 시리즈의 최종편입니다. 각 기사는 백테스트에서 프로덕션으로 가는 길에 있는 하나의 구체적인 문제를 다루었습니다. 이들이 어떻게 연결되는지 보여줍니다:
기초: 수익률의 수학
손실-수익 비대칭성 — 수익률의 곱셈적 특성, 변동성 드래그, 켈리 기준. 이것이 모든 후속 내용의 수학적 기초입니다: 왜 MaxDD가 레버리지를 결정하는지, 왜 샤프가 원시 PnL보다 중요한지, 왜 대칭적 R:R에서 50% 승률은 비수익적인지.
검증: 신뢰 구간과 강건성
몬테카를로 부트스트랩 — 단일 점 추정치를 신뢰 구간이 있는 분포로 변환. 모든 지표(PnL, MaxDD, 샤프)는 신뢰 구간이 있어야만 의미가 있습니다.
워크포워드 최적화 — 아웃오브샘플 검증. 히스토리컬 데이터에 대한 백테스트는 IS 결과입니다; WFO는 전략이 새로운 데이터에서 어떻게 수행되는지 보여줍니다.
플래토 분석 — 파라미터 강건성 확인. 최적값이 점상이면 전략이 과최적화되었습니다.
백테스트-라이브 패리티 — 백테스트와 실제 결과의 비교. 스케일링 전 최종 점검.
현실적 비용: 펀딩과 레버리지
펀딩 레이트가 레버리지를 죽인다 — 무기한 선물에서의 레버리지 숨은 비용. 펀딩을 고려하지 않으면 아름다운 백테스트가 손실로 변합니다.
펀딩 레이트 차익거래 — 크로스 거래소 전략을 통해 펀딩을 비용에서 수익원으로 전환하는 방법.
지표와 순위
활성 시간당 PnL — 포트폴리오 내 전략 순위 지표. 원시 PnL은 스케일링되지 않습니다; PnL/활성일은 스케일링됩니다.
시그널 상관관계 — 상관된 페어 포트폴리오에서의 실효적 분산.
인프라와 최적화
멀티 타임프레임 백테스트를 위한 Parquet 캐시 — 빠른 반복을 위한 데이터 인프라.
적응적 드릴다운 — 적응적 최적화: 거친 그리드 -> 유망한 영역에서 미세 조정.
Optuna vs. 좌표 하강법 — 옵티마이저 선택: 노이즈가 있는 목적 함수의 저차원에는 Optuna, 매끄러운 목적 함수의 고차원에는 좌표 하강법.
Polars vs Pandas — 백테스팅을 위한 DataFrame 연산 성능.
오케스트레이션 (본 기사)
캐스케이드 전략 — 이전의 모든 구성요소를 작동하는 시스템으로 통합. 스코어 기반 배분은 PnL/활성 시간, 신뢰도 조정, 펀딩 비용을 사용. 캐스케이드 모드가 유휴 시간을 채움. 공동 시뮬레이션이 포트폴리오를 검증. 몬테카를로 부트스트랩이 캐스케이드 PnL의 신뢰 구간을 제공.
각 기사는 독립된 모듈입니다. 이들이 모여 데이터 로딩에서 전략 포트폴리오의 라이브 오케스트레이션까지의 완전한 파이프라인을 형성합니다.
결론
캐스케이드는 전략 포트폴리오에 대한 유일한 접근법이 아닙니다. 그러나 가장 간단하고 실용적인 접근법 중 하나입니다: 프라이머리 전략이 전체 용량으로 거래하고, 폴백이 축소된 포지션으로 유휴 시간을 채웁니다. 두 가지 핵심 파라미터(dual_size와 max_slots)가 대부분의 구성에 충분한 유연성을 제공합니다.
세 가지 요점:
-
캐스케이드는 공동 시뮬레이션으로만 백테스트해야 합니다. 개별 PnL의 합산은 결과를 부풀립니다. 전환 비용, 오버랩, 슬롯 제약 — 이 모든 것은 공동 시뮬레이션에서만 포착됩니다.
-
dual_size가 PnL 대 드로다운 트레이드오프를 결정합니다. 전형적인 최적값은 5-10%. 샤프에 대한 그리드 서치가 신뢰할 수 있는 선택 방법입니다.
-
오케스트레이터는 스코어 기반 우선순위 큐입니다. 모든 것은 각 시그널에 대한 단일 숫자(스코어)로 귀결됩니다. 스코어 = f(PnL/활성일, MaxLev, 신뢰도, 펀딩). 최고 스코어를 가진 전략이 슬롯을 차지합니다. 나머지는 대기합니다.
'환상 없는 백테스트' 시리즈는 한 가지를 입증합니다: 아름다운 백테스트와 실제 수익 사이에는 수십 개의 함정이 있습니다. 각 기사가 그 중 하나를 제거합니다. 캐스케이드 오케스트레이션은 마지막 단계입니다: 검증된 전략 세트를 작동하는 포트폴리오로 전환하는 것.
참고 링크
- López de Prado — Advances in Financial Machine Learning: Portfolio Construction
- Pardo, R. — The Evaluation and Optimization of Trading Strategies
- Ernest Chan — Algorithmic Trading: Winning Strategies and Their Rationale
- Perry Kaufman — Trading Systems and Methods, Chapter on Portfolio Allocation
- Tomasini, Jaekle — Trading Systems: A New Approach to System Development and Portfolio Optimisation
- Bailey, D.H. & López de Prado — The Deflated Sharpe Ratio
- Markowitz, H. — Portfolio Selection (1952)
- Kelly, J.L. — A New Interpretation of Information Rate (1956)
Citation
@article{soloviov2026cascadestrategies,
author = {Soloviov, Eugen},
title = {Cascade Strategies: Priority Execution with Fallback Filling},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/cascade-strategies-orchestration},
version = {0.1.0},
description = {Finale of the "Backtests Without Illusions" series. How to build an orchestrator from N strategies x M pairs, implement cascade mode with priority and fallback filling, choose dual\_size, and why strategy portfolios cannot be backtested by summing PnL.}
}
MarketMaker.cc Team
퀀트 리서치 및 전략