Adaptive drill-down: бэктест с переменной гранулярностью от минут до сырых сделок
Минутные свечи — стандартная гранулярность для бэктестов. Но внутри одной минутной свечи цена может двигаться по-разному: иногда на 0.01%, а иногда на 2%. Когда стоп-лосс и тейк-профит оба попадают в диапазон [low, high] одной минутной свечи — бэктест не знает, что сработало первым. Это проблема fill ambiguity.
Наивное решение — перейти на секундные данные для всего бэктеста. Но за два года это ~63 миллиона секундных баров вместо ~1 миллиона минутных. Хранилище увеличивается в 60 раз, скорость падает пропорционально.
Адаптивный drill-down решает эту проблему: использовать мелкую гранулярность только там, где она действительно нужна.
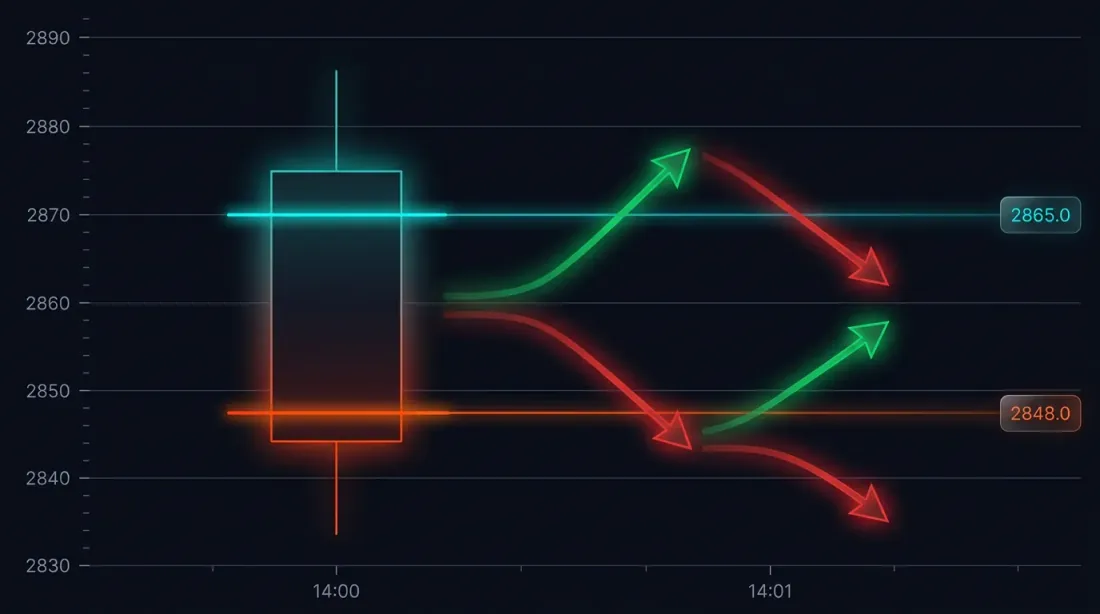
Проблема: fill ambiguity на крупных свечах
Рассмотрим конкретную ситуацию. Стратегия открыла лонг по 3000 USDT. Стоп-лосс: 2970 (-1%). Тейк-профит: 3060 (+2%).
Минутная свеча в 14:37:
- Open: 3010
- High: 3065
- Low: 2965
- Close: 3050
И SL (2970), и TP (3060) попали в диапазон [2965, 3065]. Что сработало первым?
Возможные исходы:
- Цена сначала пошла вниз → сработал SL → убыток -1%
- Цена сначала пошла вверх → сработал TP → прибыль +2%
Разница в одной сделке: 3 процентных пункта. При leverage 10× — 30%. Для бэктеста с сотнями сделок неправильное разрешение fill ambiguity систематически искажает результаты.
Как фреймворки решают это по умолчанию
Большинство бэктест-движков используют одну из двух эвристик:
- Оптимистичная: TP срабатывает первым → завышенные результаты
- Пессимистичная: SL срабатывает первым → заниженные результаты
Оба подхода — гадание. Реальные данные доступны на секундном или даже миллисекундном уровне, и нет причины гадать, когда можно посмотреть.
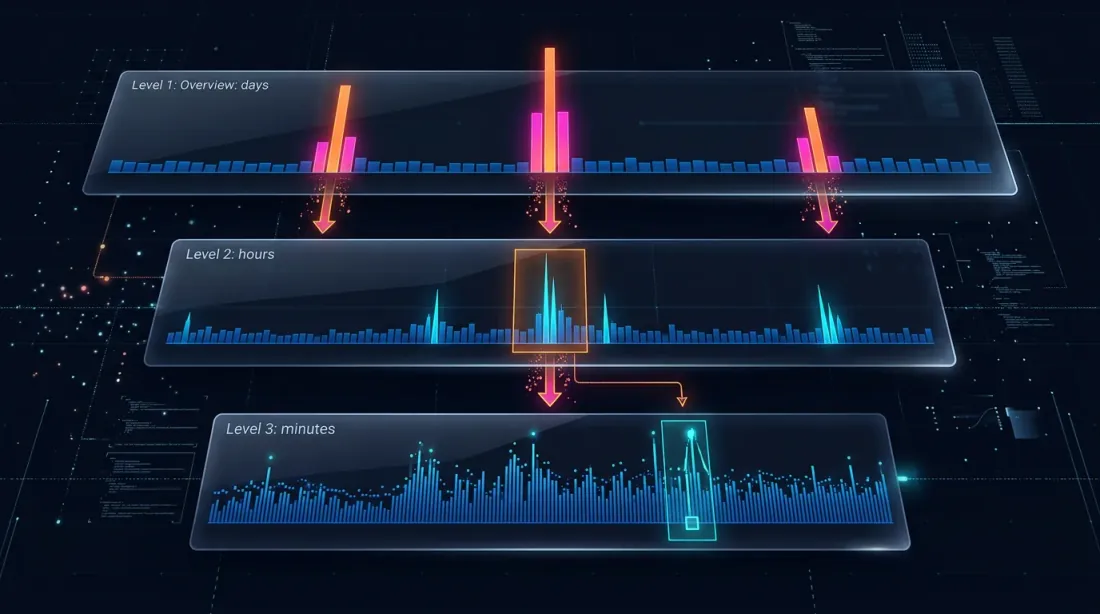
Drill-down: четырёхуровневая стратегия

Идея drill-down: начинаем на минутном уровне и «проваливаемся» на уровень ниже только при неоднозначности — по цене или по объёму.
Уровень 1: 1m (минутные свечи)
→ Если SL или TP однозначно вне диапазона [low, high] — решаем на месте
→ Если оба внутри диапазона — drill down ↓
Уровень 2: 1s (секундные свечи)
→ Загружаем 60 секундных баров для этой минуты
→ Проходим посекундно: кто сработал первым?
→ Если секундный бар неоднозначен, ИЛИ price_move >= min_pct, ИЛИ volume >= median_1s * vol_mult — drill down ↓
Уровень 3: 100ms (миллисекундные свечи)
→ Загружаем до 10 баров по 100ms для этой секунды
→ Проходим по 100ms: кто сработал первым?
→ Если 100ms бар неоднозначен, ИЛИ price_move >= min_pct, ИЛИ volume >= median_100ms * vol_mult — drill down ↓
Уровень 4: Сырые сделки (raw trades)
→ Загружаем отдельные сделки для этого 100ms бакета
→ Разрешаем fill на уровне каждой сделки — максимальная точность
Когда drill-down не нужен
В 95% случаев drill-down не требуется. Типичные сценарии:
Однозначный SL: high свечи не достигает TP, low пробивает SL → SL сработал, drill-down не нужен.
Однозначный TP: low не достигает SL, high пробивает TP → TP сработал, drill-down не нужен.
Ни один не сработал: оба уровня вне диапазона → позиция остаётся открытой.
Gap detection: open следующей свечи прыгает через SL или TP → исполнение по цене открытия, без drill-down.
Drill-down нужен только в ~5% баров — когда оба уровня попадают в диапазон одной свечи.
class AdaptiveFillSimulator:
"""
Четырёхуровневый drill-down для определения fill order.
"""
def __init__(self, data_loader):
self.loader = data_loader
self.cache_1s = {} # Кэш секундных данных по месяцам
def check_fill(self, timestamp, candle_1m, sl_price, tp_price, side):
"""
Проверяет, сработал ли SL или TP на данной минутной свече.
Returns: ('sl', fill_price) | ('tp', fill_price) | None
"""
low, high = candle_1m['low'], candle_1m['high']
open_price = candle_1m['open']
if side == 'long':
if open_price <= sl_price:
return ('sl', open_price)
if open_price >= tp_price:
return ('tp', open_price)
else:
if open_price >= sl_price:
return ('sl', open_price)
if open_price <= tp_price:
return ('tp', open_price)
sl_hit = self._level_hit(sl_price, low, high, side, 'sl')
tp_hit = self._level_hit(tp_price, low, high, side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if not sl_hit and not tp_hit:
return None
return self._drill_down_1s(timestamp, sl_price, tp_price, side)
def _drill_down_1s(self, minute_ts, sl_price, tp_price, side):
"""Уровень 2: посекундный проход."""
bars_1s = self.loader.load_1s_for_minute(minute_ts)
if bars_1s is None or len(bars_1s) == 0:
return self._pessimistic_fill(side, sl_price, tp_price)
for bar in bars_1s:
sl_hit = self._level_hit(sl_price, bar['low'], bar['high'], side, 'sl')
tp_hit = self._level_hit(tp_price, bar['low'], bar['high'], side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if sl_hit and tp_hit:
result = self._drill_down_100ms(bar['timestamp'], sl_price, tp_price, side)
if result:
return result
return self._pessimistic_fill(side, sl_price, tp_price)
def _pessimistic_fill(self, side, sl_price, tp_price):
"""Пессимистичное предположение: SL для лонгов, TP для шортов."""
if side == 'long':
return ('sl', sl_price)
else:
return ('sl', sl_price)
Производительность
| Режим | Время на 1 fill check | Когда используется |
|---|---|---|
| 1m (без drill-down) | ~0ms | ~95% случаев |
| 1s drill-down | ~5ms (первый доступ к месяцу) | ~5% случаев |
| 100ms drill-down | ~1ms | <0.5% случаев |
| Raw trades drill-down | ~0.5ms | <0.1% случаев |
За 2 года бэктеста с ~400 сделками drill-down вызывается примерно для 20 свечей. Общие накладные расходы — менее 1 секунды на весь бэктест.
Адаптивное хранение данных
Drill-down требует секундных и миллисекундных данных. Но хранить всё на максимальной гранулярности — непрактично:
| Гранулярность | Баров за 2 года | Размер parquet |
|---|---|---|
| 1m | ~1.05M | ~15 MB |
| 1s | ~63M | ~550 MB/мес |
| 100ms | ~630M | ~5 GB/мес |
Полный архив 1s данных за 2 года — около 13 GB. 100ms — более 100 GB. Хранить всё — можно, но расточительно, учитывая что drill-down использует менее 1% этих данных.
Hot-second detection
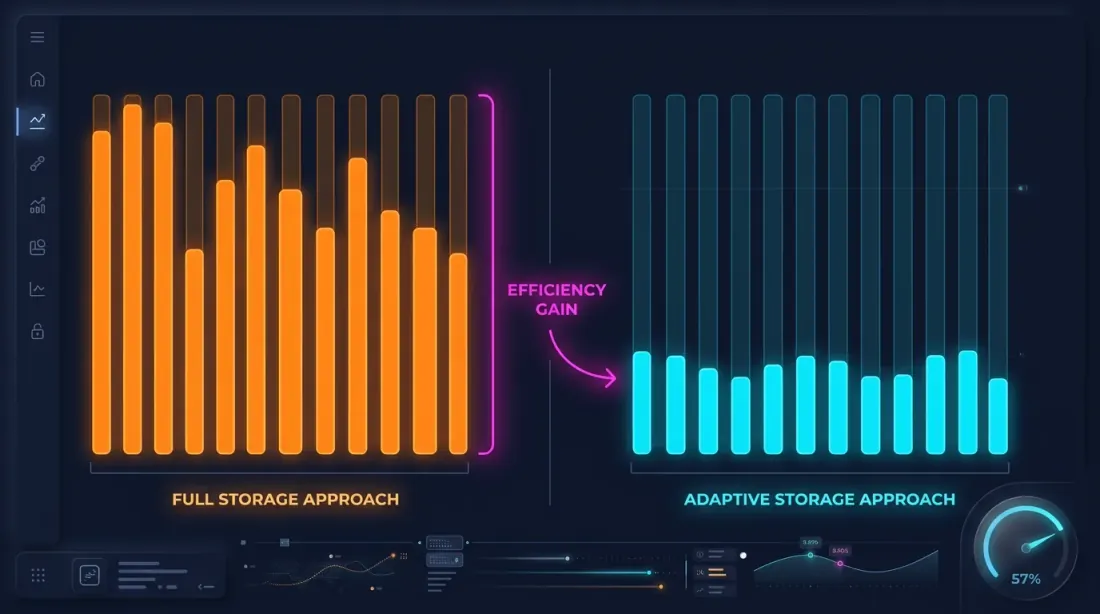
Ключевое наблюдение: секунды, в которых цена значительно двигается, составляют малую долю. Если за секунду цена изменилась менее чем на 0.1% — нет смысла хранить 100ms breakdown для этой секунды.
Hot-second detection: при скачивании и обработке данных анализируем каждую секунду и генерируем 100ms свечи только для «горячих» секунд — тех, где ценовое движение превысило пороговое значение.
def process_trades_adaptive(
trades: pd.DataFrame,
min_price_change_pct: float = 1.0,
) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Обрабатывает сырые trades в адаптивную структуру:
- 1s свечи для всех секунд
- 100ms свечи только для "горячих" секунд
Args:
trades: DataFrame с колонками [timestamp, price, quantity]
min_price_change_pct: порог для drill-down в 100ms
Returns:
(df_1s, df_100ms_hot) — секундные свечи и 100ms для горячих секунд
"""
trades['second'] = trades['timestamp'].dt.floor('1s')
df_1s = trades.groupby('second').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
df_1s['price_change_pct'] = (df_1s['high'] - df_1s['low']) / df_1s['open'] * 100
hot_seconds = df_1s[df_1s['price_change_pct'] >= min_price_change_pct].index
hot_trades = trades[trades['second'].isin(hot_seconds)]
hot_trades['bucket_100ms'] = hot_trades['timestamp'].dt.floor('100ms')
df_100ms = hot_trades.groupby('bucket_100ms').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
return df_1s, df_100ms
Экономия хранилища
Для примера — ETHUSDT за типичный месяц:
| Подход | Размер | Гранулярность |
|---|---|---|
| Только 1m | ~1 MB | 1 минута |
| Все 1s | ~550 MB | 1 секунда |
| Все 100ms | ~5 GB | 100 мс |
| Адаптивный | ~600 MB | 1s + 100ms только для горячих |
При пороге min_price_change_pct = 1.0% горячие секунды составляют менее 1% от всех секунд. 100ms данные для них добавляют ~50 MB к 550 MB секундных данных — пренебрежимая надбавка.
Если при этом хранить секундные данные тоже адаптивно (только когда движение внутри минуты > 0.1%), объём можно сократить ещё в 3–5 раз.
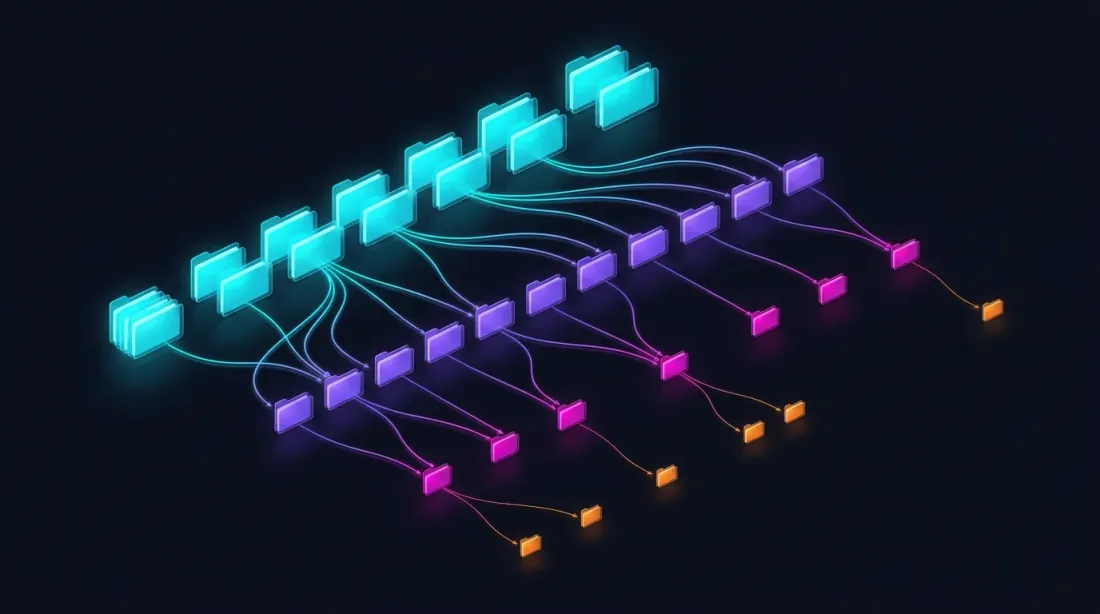
Структура parquet-хранилища
data/{SYMBOL}/
├── source.json # Источник данных: {"exchange": "binance"} или {"exchange": "bybit"}
├── stats.json # Предвычисленные медианы объёмов: {"median_volume_1s": ..., "median_volume_100ms": ...}
├── klines_1m/
│ ├── 2024-01.parquet # ~1 MB
│ ├── 2024-02.parquet
│ └── ...
├── klines_1s/
│ ├── 2024-01.parquet # ~550 MB
│ └── ...
├── klines_100ms_hot/
│ ├── 2024-01.parquet # ~50 MB (только горячие секунды)
│ └── ...
├── trades_hot/
│ ├── 2024-01.parquet # Сырые сделки для горячих 100ms бакетов
│ └── ...
└── states_1m.parquet # Precomputed rolling state cache (~112 MB)
Каждый файл — месяц данных. Секундные, миллисекундные данные и сырые сделки загружаются lazily — только когда drill-down их запрашивает. Файл stats.json содержит предвычисленные медианы объёмов для volume-based триггеров drill-down.
Оптимизация parquet для финансовых данных
Финансовые данные имеют специфику: timestamps монотонно растут, цены меняются плавно, объёмы сильно варьируются. Оптимальные настройки:
import pyarrow as pa
import pyarrow.parquet as pq
schema = pa.schema([
pa.field("timestamp", pa.int32()), # Секунды с epoch — int32 достаточно
pa.field("open", pa.float32()),
pa.field("high", pa.float32()),
pa.field("low", pa.float32()),
pa.field("close", pa.float32()),
pa.field("volume", pa.float32()),
])
column_encodings = {
"timestamp": "DELTA_BINARY_PACKED", # Монотонные int → delta-сжатие
"open": "BYTE_STREAM_SPLIT", # Float → byte-stream split
"high": "BYTE_STREAM_SPLIT",
"low": "BYTE_STREAM_SPLIT",
"close": "BYTE_STREAM_SPLIT",
"volume": "BYTE_STREAM_SPLIT",
}
def save_optimized_parquet(df, path):
table = pa.Table.from_pandas(df, schema=schema)
pq.write_table(
table, path,
compression="zstd",
compression_level=9,
use_dictionary=False,
write_statistics=False,
column_encoding=column_encodings,
)
Почему эти настройки:
- DELTA_BINARY_PACKED для timestamps: последовательные timestamps отличаются на фиксированное значение (60 для 1m, 1 для 1s). Delta-кодирование сжимает их почти до нуля.
- BYTE_STREAM_SPLIT для float: разделяет байты float32 по потокам (все первые байты вместе, все вторые и т.д.). Для плавно меняющихся цен это даёт сжатие в 2–3 раза лучше, чем стандартное.
- ZSTD level 9: хорошее сжатие при приемлемой скорости распаковки.
- float32 вместо float64: достаточно для цен и объёмов, экономит 50% памяти.
Lazy loading с кэшированием
Drill-down запрашивает секундные данные для конкретной минуты. Загружать parquet-файл для каждого запроса — медленно. Решение — lazy loading с LRU-кэшем по месяцам.
from functools import lru_cache
import pyarrow.parquet as pq
import pandas as pd
class AdaptiveDataLoader:
"""
Lazy loader с кэшем: загружает секундные данные по месяцам,
хранит в памяти последние N месяцев.
"""
def __init__(self, symbol: str, data_dir: str = "data", cache_months: int = 2):
self.symbol = symbol
self.data_dir = data_dir
self.cache_months = cache_months
self._cache_1s: dict[str, pd.DataFrame] = {}
def load_1s_for_minute(self, minute_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Загрузить 1s данные для конкретной минуты."""
month_key = minute_ts.strftime("%Y-%m")
if month_key not in self._cache_1s:
self._load_month_1s(month_key)
if month_key not in self._cache_1s:
return None
df = self._cache_1s[month_key]
minute_start = minute_ts.floor('1min')
minute_end = minute_start + pd.Timedelta(minutes=1)
return df[(df.index >= minute_start) & (df.index < minute_end)]
def load_100ms_for_second(self, second_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Загрузить 100ms данные для горячей секунды."""
month_key = second_ts.strftime("%Y-%m")
path = f"{self.data_dir}/{self.symbol}/klines_100ms_hot/{month_key}.parquet"
try:
df = pd.read_parquet(path)
second_start = second_ts.floor('1s')
second_end = second_start + pd.Timedelta(seconds=1)
return df[(df.index >= second_start) & (df.index < second_end)]
except FileNotFoundError:
return None
def _load_month_1s(self, month_key: str):
"""Загрузить месяц 1s данных, вытеснить старый из кэша."""
path = f"{self.data_dir}/{self.symbol}/klines_1s/{month_key}.parquet"
try:
df = pd.read_parquet(path)
df.index = pd.to_datetime(df['timestamp'], unit='s')
if len(self._cache_1s) >= self.cache_months:
oldest = min(self._cache_1s.keys())
del self._cache_1s[oldest]
self._cache_1s[month_key] = df
except FileNotFoundError:
pass
Применение drill-down для бэктеста
Интеграция в бэктест-цикл:
def backtest_with_adaptive_fill(
states: pd.DataFrame,
strategy_params: dict,
data_loader: AdaptiveDataLoader,
) -> list:
"""
Бэктест с адаптивным drill-down для fill simulation.
"""
fill_sim = AdaptiveFillSimulator(data_loader)
trades = []
position = None
for i in range(len(states)):
row = states.iloc[i]
ts = states.index[i]
candle_1m = {
'open': row['open'], 'high': row['high'],
'low': row['low'], 'close': row['close'],
'timestamp': ts,
}
if position is not None:
fill = fill_sim.check_fill(
ts, candle_1m,
position['sl'], position['tp'],
position['side'],
)
if fill is not None:
fill_type, fill_price = fill
trades.append({
'entry_time': position['entry_time'],
'exit_time': ts,
'side': position['side'],
'entry_price': position['entry_price'],
'exit_price': fill_price,
'exit_type': fill_type,
'drill_down': fill_sim.last_drill_depth, # 0, 1, or 2
})
position = None
continue
signal = check_entry_signal(row, strategy_params)
if signal and position is None:
position = {
'side': signal['side'],
'entry_price': row['close'],
'entry_time': ts,
'sl': signal['sl'],
'tp': signal['tp'],
}
return trades
Связь с rolling state cache
Drill-down дополняет агрегированный parquet-кэш — они решают разные задачи:
| Rolling state cache | Adaptive drill-down | |
|---|---|---|
| Задача | Корректные значения индикаторов HTF | Точный порядок исполнения SL/TP |
| Работает на | Каждой 1m свече | Только при fill ambiguity (~5%) |
| Данные | Precomputed, хранятся постоянно | Lazy loaded, кэш последних месяцев |
| Влияет на | Сигналы входа/выхода | Цену и время исполнения |
Оба подхода устраняют ошибки, невидимые на уровне дневных свечей, но критичные для реалистичного бэктеста.
Итого: сравнение подходов к fill simulation
| Подход | Точность | Скорость | Хранилище |
|---|---|---|---|
| OHLC эвристика (оптимист/пессимист) | Низкая | Мгновенно | Только 1m |
| Полный 1s бэктест | Высокая | Медленно (×60) | ~550 MB/мес |
| Полный 100ms бэктест | Очень высокая | Очень медленно (×600) | ~5 GB/мес |
| Полный raw trades бэктест | Максимальная | Крайне медленно | ~50 GB/мес |
| Adaptive drill-down (4 уровня) | Максимальная | ~Мгновенно | 1m + 1s + 100ms hot + trades hot |
Drill-down даёт точность полного 1s бэктеста при скорости 1m бэктеста. Ключевое наблюдение: высокая гранулярность нужна не везде — только в точках принятия решений.
Volume-based drill-down
Оригинальный drill-down срабатывает только по движению цены — когда диапазон [low, high] свечи достаточно широк для fill ambiguity. Но цена — не единственный сигнал того, что внутри бара произошло что-то важное.
Всплески объёма — не менее важный триггер. Секунда, в которой объём в 500 раз превышает медиану, обычно соответствует крупному рыночному ордеру, каскаду ликвидаций или flash crash. Даже если тело свечи выглядит маленьким, реальная траектория цены внутри этой секунды могла быть экстремальной — касаясь значений, которые OHLC-представление скрывает.
Условие drill-down теперь на основе ИЛИ: значительное ценовое движение ИЛИ аномальный всплеск объёма запускают спуск к более мелкой гранулярности.
def is_hot(bar, median_volume, min_pct=0.1, vol_mult=500):
"""
Определяет, требует ли бар drill-down на следующий уровень.
Два независимых триггера (логика ИЛИ):
- цена двинулась >= min_pct внутри бара
- объём превысил median * vol_mult
"""
price_move = (bar['high'] - bar['low']) / bar['open'] * 100
return price_move >= min_pct or bar['volume'] >= median_volume * vol_mult
Это ловит сценарии, невидимые для детекции только по цене: бар с open=3000, close=3001, но объёмом в 50 000 раз выше нормы, мог за миллисекунды коснуться 2950 и 3050. Без volume-based drill-down бэктест никогда не стал бы рассматривать эту секунду подробнее.
Сырые сделки: четвёртый уровень
Оригинальная трёхуровневая иерархия (1m → 1s → 100ms) оставляет пробел: внутри одного 100ms бакета может исполниться несколько сделок по разным ценам. Для бакета с high=3060 и low=2965 мы по-прежнему не знаем точную последовательность.
Решение: drill-down до сырых сделок как четвёртый и финальный уровень.
1m свечи (базовый)
└─> 1s свечи (когда price_move >= min_pct ИЛИ volume >= median_1s * vol_mult)
└─> 100ms свечи (когда обнаружена горячая секунда)
└─> Сырые сделки (когда 100ms показывает price_move >= min_pct ИЛИ volume >= median_100ms * vol_mult)
На уровне сырых сделок нет неоднозначности — каждая сделка имеет точную цену и timestamp. Fill разрешается окончательно:
def resolve_from_trades(trades, sl_price, tp_price, side):
"""
Проходим по отдельным сделкам в хронологическом порядке.
Первая сделка, пересекающая SL или TP, определяет fill.
"""
for trade in trades:
price = trade['price']
if side == 'long':
if price <= sl_price:
return ('sl', price)
if price >= tp_price:
return ('tp', price)
else: # short
if price >= sl_price:
return ('sl', price)
if price <= tp_price:
return ('tp', price)
return None
Уровень сырых сделок вызывается крайне редко — менее 0.1% от всех баров — но когда вызывается, он даёт ground truth, недоступную никакой свечной аппроксимации.
Раздельные пороги для каждого перехода
Разные переходы между разрешениями имеют разные характеристики. Движение цены на 0.1% в пределах секунды — значимое; те же 0.1% в пределах 100ms бакета — экстремальные. Аналогично, распределения объёмов различаются на каждом таймскейле.
Каждый переход теперь имеет свои параметры min_pct и vol_mult:
1s → 100ms: --min-pct-1s 0.1 --vol-mult-1s 500
100ms → trades: --min-pct-100ms 0.1 --vol-mult-100ms 500
Это позволяет тонко настраивать чувствительность каждого перехода независимо. На практике переход 100ms→trades может использовать более жёсткий порог, так как стоимость загрузки сырых сделок для одного 100ms бакета минимальна.
@dataclass
class DrillDownConfig:
min_pct_1s: float = 0.1
vol_mult_1s: float = 500
min_pct_100ms: float = 0.1
vol_mult_100ms: float = 500
Персистентные медианные статистики
Volume-based drill-down требует знания медианного объёма на каждом таймскейле. Вычислять медианы на лету для каждого бэктеста — это нивелирует преимущества в производительности. Решение: предвычислить медианы один раз и закэшировать.
Для каждого символа медианные объёмы на гранулярности 1s и 100ms вычисляются из исторических данных и сохраняются в файл stats.json:
{
"ETHUSDT": {
"median_volume_1s": 12.5,
"median_volume_100ms": 1.8
},
"BTCUSDT": {
"median_volume_1s": 0.45,
"median_volume_100ms": 0.06
}
}
Статистики вычисляются один раз для каждого символа при первой загрузке данных и переиспользуются во всех последующих бэктестах. При обновлении данных (загрузка новых месяцев) статистики пересчитываются инкрементально.
def compute_median_stats(symbol, data_dir):
"""Вычислить и закэшировать медианные статистики объёмов для символа."""
stats_path = f"{data_dir}/{symbol}/stats.json"
all_1s = load_all_months(f"{data_dir}/{symbol}/klines_1s/")
median_1s = all_1s['volume'].median()
all_100ms = load_all_months(f"{data_dir}/{symbol}/klines_100ms_hot/")
median_100ms = all_100ms['volume'].median()
stats = {
"median_volume_1s": float(median_1s),
"median_volume_100ms": float(median_100ms),
}
with open(stats_path, 'w') as f:
json.dump(stats, f, indent=2)
return stats

Мультибиржевая поддержка: Bybit
Не все символы доступны на Binance. Для активов вроде XAUTUSDT (золото) данные необходимо получать с других бирж. Система drill-down теперь поддерживает Bybit как альтернативный источник данных.
Для символов Bybit все уровни свечей (1m, 1s, 100ms) и сырые сделки строятся из потока сырых сделок Bybit. Процесс тот же — сырые сделки агрегируются в свечи на каждом таймскейле — но источник данных другой.
data/{SYMBOL}/
├── source.json # {"exchange": "bybit"} или {"exchange": "binance"}
├── klines_1m/
│ └── ...
├── klines_1s/
│ └── ...
├── klines_100ms_hot/
│ └── ...
└── trades_hot/ # Сырые сделки для горячих 100ms бакетов
└── ...
Data loader проверяет source.json и использует соответствующий pipeline загрузки. С точки зрения бэктест-движка формат данных идентичен вне зависимости от биржи-источника — логика drill-down не зависит от биржи.
Это особенно важно для кросс-биржевых стратегий или символов, которые торгуются исключительно на определённых площадках.
Заключение
Адаптивный drill-down — это применение простого принципа: тратить вычислительные ресурсы и место пропорционально важности данных.
Четыре уровня гранулярности:
- 1m — базовый проход для 95% баров
- 1s — drill-down при fill ambiguity или всплесках объёма
- 100ms — drill-down для горячих секунд с экстремальным движением или аномальным объёмом
- Сырые сделки — drill-down для горячих 100ms бакетов, разрешение fill на уровне каждой сделки
Четыре уровня хранения:
- Все 1m — полный архив, ~15 MB за 2 года
- Все 1s — полный архив или адаптивный, ~550 MB/мес
- Только горячие 100ms — <1% секунд, ~50 MB/мес
- Только горячие trades — сырые сделки для самых экстремальных 100ms бакетов
Два триггера drill-down (логика ИЛИ):
- По цене: диапазон бара превышает
min_pct - По объёму: объём бара превышает
median * vol_mult
Результат: бэктест с точностью тикового симулятора при скорости минутного. Хранилище, которое растёт линейно, а не экспоненциально. И поддержка нескольких бирж — Binance и Bybit — с биржа-агностичной логикой drill-down.
Подробнее о precomputed cache для мультитаймфрейм-стратегий — в статье Агрегированный Parquet-кэш. О влиянии funding rates на результаты при высоком leverage — Funding rates убивают ваш leverage.
Полезные ссылки
- Apache Parquet — формат хранения данных
- Apache Arrow — BYTE_STREAM_SPLIT encoding
- Zstandard — алгоритм сжатия
- López de Prado — Advances in Financial Machine Learning
- Binance — Historical Market Data
Цитирование
@article{soloviov2026adaptivedrilldown,
author = {Soloviov, Eugen},
title = {Adaptive drill-down: бэктест с переменной гранулярностью от минут до сырых сделок},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/adaptive-resolution-drill-down-backtest},
description = {Как адаптивная гранулярность данных ускоряет бэктесты и экономит хранилище: drill-down от 1m к 1s, 100ms и сырым сделкам только там, где цена двигалась значительно или объём аномально вырос.}
}
MarketMaker.cc Team
Количественные исследования и стратегии
Читайте также

Агрегированный Parquet-кэш: как ускорить мультитаймфрейм-бэктест в сотни раз

Walk-Forward Optimization: единственный честный тест стратегии
