Агрегированный Parquet-кэш: как ускорить мультитаймфрейм-бэктест в сотни раз

Мультитаймфрейм-стратегия использует несколько таймфреймов одновременно: дневной определяет направление тренда, часовой — точку входа, 5-минутный — момент исполнения. Для каждого таймфрейма нужны свои индикаторы: скользящие средние, осцилляторы, уровни.
При одиночном бэктесте всё просто — пересчитали таймфреймы из минутных данных, посчитали индикаторы, прогнали стратегию. Но при массовой оптимизации — когда нужно протестировать тысячи комбинаций параметров — пересчёт таймфреймов и индикаторов на каждой итерации становится узким местом. Один проход по минутным данным за два года — это обработка более миллиона баров, и повторять это тысячу раз — расточительно.
Решение: предвычислить всё один раз и закэшировать в parquet-файл.
Проблема: повторные вычисления при оптимизации
Типичный пайплайн мультитаймфрейм-бэктеста выглядит так:
for params in parameter_grid:
df_1m = load_candles("ETHUSDT", "1m", start, end)
df_5m = resample_ohlcv(df_1m, "5m")
df_1h = resample_ohlcv(df_1m, "1h")
df_4h = resample_ohlcv(df_1m, "4h")
df_1d = resample_ohlcv(df_1m, "D")
ma_1h = compute_ma(df_1h["close"], length=params["ma_1h_len"])
ma_4h = compute_ma(df_4h["close"], length=params["ma_4h_len"])
ma_1d = compute_ma(df_1d["close"], length=params["ma_1d_len"])
result = run_strategy(df_1m, ma_1h, ma_4h, ma_1d, params)
На каждой итерации шаги 1–3 считаются заново, хотя данные одни и те же. Меняются только пороговые параметры стратегии (шаг 4). Это всё равно что каждый раз заново строить дом, когда хочешь просто попробовать другой цвет стен.
Идея: один раз посчитать, сохранить, использовать многократно
Ключевое наблюдение: таймфреймы и индикаторы зависят только от минутных данных и параметров индикатора, но не от параметров стратегии. Если мы зафиксируем набор нужных индикаторов, можно посчитать их один раз и сохранить.
Схема:
Шаг 1 (однократно):
Минутные свечи → Пересчёт таймфреймов → Расчёт индикаторов → Parquet-файл
Шаг 2 (многократно):
Parquet-файл → Стратегия с разными параметрами → Результат
Эмуляция таймфреймов из минутных свечей
У нас есть полный архив минутных свечей. Из него можно точно воспроизвести любой старший таймфрейм. Но есть нюанс: при обычном resample мы получаем одну строку на каждый период (одна строка на каждый час, одна на каждые 4 часа и т.д.). Это не подходит для поминутного бэктеста — нам нужно знать значение индикатора на каждую минуту.
Поэтому мы эмулируем значения старших таймфреймов для каждой минутной свечи, моделируя то, как бот в реальном времени видит данные:
- Бот получает очередную минутную свечу
- Обновляет текущий (незакрытый) бар старшего таймфрейма — пересчитывает High, Low, Close, Volume
- Пересчитывает индикатор по всем закрытым барам плюс текущий частичный бар
- Когда период завершается — бар финализируется и начинается новый
Этот подход гарантирует, что бэктест видит ровно те же данные, что и бот в реальном времени. Никакого заглядывания в будущее — каждая минутная свеча обрабатывается строго с теми данными, которые были бы доступны в этот момент.
class RunningCandleBuffer:
"""
Эмулирует реалтайм-обновление бара старшего таймфрейма
по 1-минутным свечам.
"""
def __init__(self, period_seconds: int):
self.period = period_seconds # 86400 для Daily, 3600 для 1h
self.closed_bars = []
self.current_bar = None
def update(self, timestamp, open_, high, low, close, volume):
bar_start = self._align_to_period(timestamp)
if self.current_bar is None or bar_start != self.current_bar['start']:
if self.current_bar is not None:
self.closed_bars.append(self.current_bar)
self.current_bar = {
'start': bar_start,
'open': open_, 'high': high,
'low': low, 'close': close,
'volume': volume,
}
else:
self.current_bar['high'] = max(self.current_bar['high'], high)
self.current_bar['low'] = min(self.current_bar['low'], low)
self.current_bar['close'] = close
self.current_bar['volume'] += volume
return self.closed_bars + [self.current_bar]
Для каждого старшего таймфрейма создаётся свой RunningCandleBuffer. На каждой минутной свече все буферы обновляются, и мы получаем актуальное состояние каждого таймфрейма — как если бы бот работал в реальном времени.
Структура Parquet-кэша
Результат предвычисления — один parquet-файл, где каждая строка соответствует одной минутной свече, а колонки содержат:
timestamp — метка времени минутной свечи
open, high, low, — OHLCV минутной свечи
close, volume
close_5m — Close эмулированной 5m свечи на этот момент
close_1h — Close эмулированной 1h свечи
close_4h — Close эмулированной 4h свечи
close_1d — Close эмулированной дневной свечи
ma_20_1h — MA(20) по 1h, пересчитанный на эту минуту
ma_50_1h — MA(50) по 1h
ma_20_4h — MA(20) по 4h
ma_50_4h — MA(50) по 4h
ma_6_1d — MA(6) по Daily
ma_12_1d — MA(12) по Daily
cross_ma_1h — сигнал кроссовера MA на 1h ('buy'/'sell'/None)
cross_ma_4h — сигнал кроссовера MA на 4h
cross_ma_1d — сигнал кроссовера MA на Daily
separation_1h — расхождение MA в % на 1h
separation_4h — расхождение MA в % на 4h
separation_1d — расхождение MA в % на Daily
Каждое значение отражает реальное состояние индикатора на момент соответствующей минутной свечи — с учётом незакрытых баров старших таймфреймов.
Precompute: формирование кэша
def precompute_cache(
df_1m: pd.DataFrame,
timeframes: dict[str, int], # {"5m": 300, "1h": 3600, "4h": 14400, "D": 86400}
indicators: dict, # {"ma_20": 20, "ma_50": 50}
) -> pd.DataFrame:
"""
Один проход по всем минутным свечам.
Возвращает DataFrame с эмулированными таймфреймами и индикаторами.
"""
buffers = {tf: RunningCandleBuffer(secs) for tf, secs in timeframes.items()}
n = len(df_1m)
result = {}
for tf_name, buf in buffers.items():
closes = np.zeros(n)
ma_values = {name: np.full(n, np.nan) for name in indicators}
for i in range(n):
row = df_1m.iloc[i]
bars = buf.update(
df_1m.index[i],
row['open'], row['high'], row['low'], row['close'], row['volume']
)
all_closes = [b['close'] for b in bars]
closes[i] = all_closes[-1]
for ind_name, length in indicators.items():
if len(all_closes) >= length:
ma_values[ind_name][i] = np.mean(all_closes[-length:])
result[f'close_{tf_name}'] = closes
for ind_name in indicators:
result[f'{ind_name}_{tf_name}'] = ma_values[ind_name]
cache_df = pd.DataFrame(result, index=df_1m.index)
cache_df = pd.concat([df_1m[['open', 'high', 'low', 'close', 'volume']], cache_df], axis=1)
return cache_df
cache = precompute_cache(
df_1m,
timeframes={"5m": 300, "1h": 3600, "4h": 14400, "D": 86400},
indicators={"ma_20": 20, "ma_50": 50, "ma_6": 6, "ma_12": 12},
)
cache.to_parquet("cache_ETHUSDT_2024_2026.parquet")
Использование кэша при оптимизации
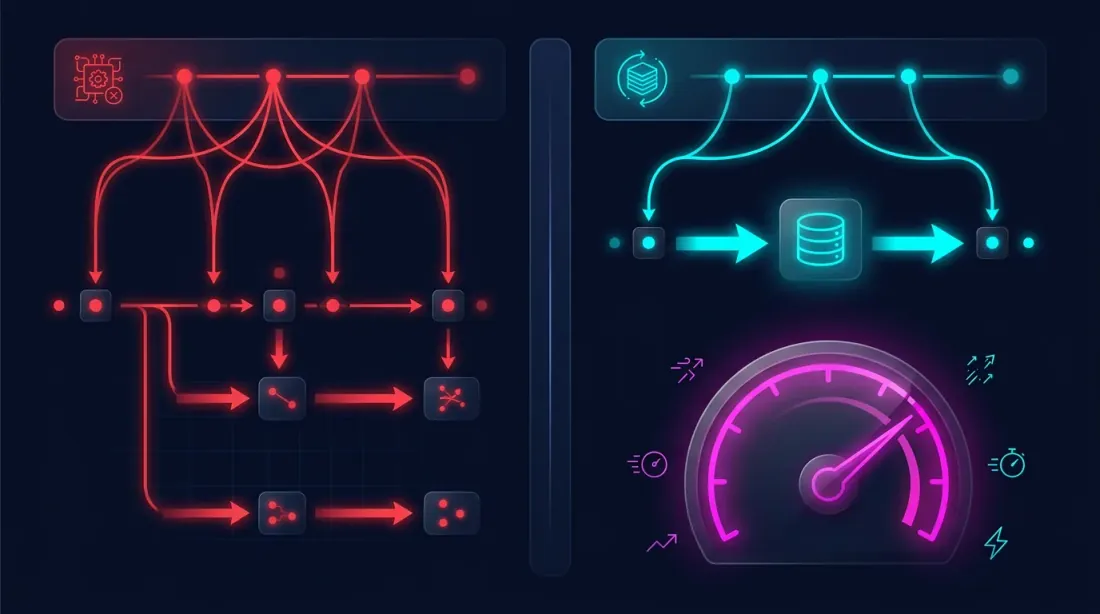
Теперь оптимизация выглядит так:
cache = pd.read_parquet("cache_ETHUSDT_2024_2026.parquet")
for params in parameter_grid:
result = run_strategy(cache, params)
Стратегия работает с готовыми колонками — без повторного прохода по миллиону баров, без пересчёта MA, без эмуляции таймфреймов. Только чтение из DataFrame и проверка условий входа/выхода.
Почему parquet
Parquet — колоночный формат хранения данных, оптимальный для этой задачи:
- Сжатие. Parquet сжимает числовые данные в 5–10 раз. Кэш на 1.1 миллиона строк с 30 колонками занимает ~50 МБ вместо ~500 МБ в CSV.
- Колоночное чтение. Если стратегия использует только
ma_20_4hиma_50_4h, parquet читает только эти колонки, пропуская остальные. - Типизация. Типы данных (float64, int64, string) сохраняются без потерь — не нужно парсить строки при загрузке.
- Скорость чтения. Загрузка parquet в pandas — десятки миллисекунд, что на порядок быстрее CSV.
Расширение кэша: добавление новых индикаторов
Если стратегия требует новый индикатор (RSI, MACD, Bollinger Bands), достаточно:
- Пересчитать только новый индикатор из тех же минутных данных
- Добавить колонки в существующий parquet-файл
- Все ранее вычисленные колонки остаются нетронутыми
cache = pd.read_parquet("cache_ETHUSDT_2024_2026.parquet")
rsi_cols = compute_rsi_for_timeframes(df_1m, timeframes, length=14)
cache = pd.concat([cache, rsi_cols], axis=1)
cache.to_parquet("cache_ETHUSDT_2024_2026.parquet")
Итого: сравнение подходов
| Наивный подход | Агрегированный кэш | |
|---|---|---|
| Пересчёт таймфреймов | На каждой итерации | Один раз |
| Пересчёт индикаторов | На каждой итерации | Один раз |
| Время одной итерации | Минуты | Менее секунды |
| 1000 итераций | Дни | Минуты |
| Потребление памяти | Загрузка 1m + пересчёт | Один DataFrame |
| Backtest-live parity | Зависит от реализации | Гарантировано (эмуляция = реалтайм) |
Заключение
Подход с агрегированным parquet-кэшем решает две задачи одновременно:
-
Корректность. Эмуляция таймфреймов из минутных свечей через RunningCandleBuffer гарантирует, что бэктест видит те же данные, что и бот в реальном времени — без заглядывания в будущее и без искусственных задержек.
-
Скорость. Предвычисленные таймфреймы и индикаторы позволяют тестировать тысячи комбинаций параметров за минуты вместо дней.
Идея проста: считай один раз — используй многократно. Минутные свечи — это исходные данные. Всё остальное — производные, которые можно посчитать заранее и закэшировать. Parquet делает этот кэш компактным, быстрым и удобным.
О том, как повысить точность fill simulation с помощью адаптивного drill-down от минут к секундам и миллисекундам — в статье Adaptive drill-down: бэктест с переменной гранулярностью.
Полезные ссылки
- Apache Parquet — формат хранения данных
- pandas — работа с parquet
- López de Prado — Advances in Financial Machine Learning
- Ernest Chan — Quantitative Trading
Цитирование
@article{soloviov2026parquetcache,
author = {Soloviov, Eugen},
title = {Агрегированный Parquet-кэш: как ускорить мультитаймфрейм-бэктест в сотни раз},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/parquet-cache-multitimeframe-backtest},
description = {Как предвычислить таймфреймы и индикаторы из минутных свечей, сохранить в parquet и использовать при массовом тестировании стратегий без повторных пересчётов.}
}
MarketMaker.cc Team
Количественные исследования и стратегии
Читайте также

Adaptive drill-down: бэктест с переменной гранулярностью от минут до сырых сделок

Walk-Forward Optimization: единственный честный тест стратегии
