座標降下法 vs ベイズ最適化:どちらがより良いパラメータを見つけるか
本記事は「幻想なきバックテスト」シリーズの第5回です。前回までの記事では、損益の非対称性、モンテカルロ・ブートストラップ、ファンディングレートの影響、マルチタイムフレーム・バックテストのためのParquetキャッシュを取り上げました。今回は、最適な戦略パラメータの探索プロセスについて語ります。これは直感が最も裏切られるタスクです。
あなたの戦略には12個のパラメータがあります。各パラメータは約9個の値を取ります。ドローダウンを制限しながらPnLを最大化する組み合わせを見つけたい。どうしますか?
もし「すべての組み合わせを試す」と答えるなら、問題があります。「一度に1つのパラメータを変える」と答えるなら、別の問題があります。本記事では、それぞれのアプローチに潜む問題とその解決方法を解説します。
網羅的探索が不可能な理由

次元の呪い
網羅的探索(グリッドサーチ)は、すべてのパラメータのすべての値の組み合わせをテストします。9個の値を持つ2つのパラメータの場合、回の実行で十分に実現可能です。3つの場合:回で許容範囲です。
しかし、12個のパラメータを持つ実際の戦略では:
2,820億回の実行です。1回のバックテストが1秒(これでも楽観的な見積もり)だとしても、網羅的探索には:
これは指数関数的増大です。新しいパラメータが1つ増えるごとに探索空間は9倍になります。13番目のパラメータを追加すると、9,000年の代わりに80,000年が必要になります。
import math
def grid_search_cost(n_params: int, values_per_param: int, seconds_per_trial: float) -> dict:
"""Estimate the cost of exhaustive search."""
total_trials = values_per_param ** n_params
total_seconds = total_trials * seconds_per_trial
return {
"total_trials": total_trials,
"total_hours": total_seconds / 3600,
"total_years": total_seconds / (3600 * 24 * 365),
}
cost = grid_search_cost(12, 9, 1.0)
print(f"Trials: {cost['total_trials']:,.0f}") # 282,429,536,481
print(f"Years: {cost['total_years']:,.0f}") # 8,950
事前計算を使っても
Parquetキャッシュに関する記事で、タイムフレームとインジケーターの事前計算により1回のバックテストを約1秒に高速化できることを示しました。しかし、1回0.1秒でも、12パラメータの網羅的探索には895年かかります。事前計算は役立ちますが、指数関数的増大の根本的な問題を解決しません。
網羅的探索よりも賢くパラメータ空間を探索する方法が必要です。
座標降下法とOAT:高速だが盲目的
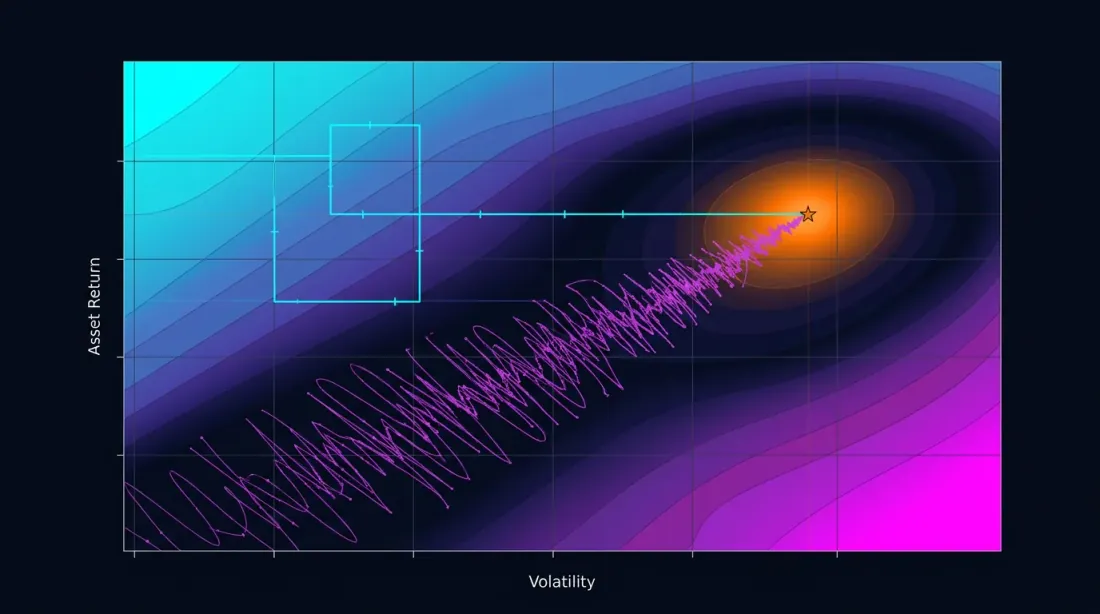
同じアイデアの2つのバリエーション
2つの関連するアプローチがあります。どちらも一度に1つのパラメータを最適化しますが、パスの回数が異なります。
OAT(One-at-a-Time)スイープ — すべてのパラメータを1回だけ通過します。最初のパラメータの値を順に試し、最良のものを固定し、2番目に移り、以下同様です。1回だけ。高速で低コストです。
座標降下法 — 複数回パス。最後のパラメータの最適化後、最初に戻り、最適値が変わっていないか確認します(コンテキストが変わった — 他のパラメータの値が異なる)。収束するまでラウンドを繰り返します。よりコストがかかりますが、より精密です。各ラウンドで解を改善できます。
実際には、バックテストではOATがより多く使われます:12パラメータの1回パスで96回の実行。座標降下法では3〜5ラウンドで300〜500回の実行となり、すでにOptunaと同等ですが、その利点はありません。
各パラメータが約8個の値を持つ12パラメータの場合:
グリッドサーチのと比較してください。OATは線形です:ではなく。これが最大の利点であり、同時に最大の問題でもあります。
def oat_sweep(
param_grid: dict[str, list],
run_backtest_fn,
initial_params: dict,
metric: str = "effective_score",
) -> dict:
"""
OAT sweep: single pass, optimizing one parameter at a time.
param_grid: {"htf_entry_sell": [0.0, 0.005, ..., 0.05], ...}
initial_params: starting values for all parameters
metric: metric to optimize (effective_score recommended —
PnL per active time extrapolated to a year)
"""
best_params = initial_params.copy()
best_score = run_backtest_fn(**best_params)[metric]
for param_name, values in param_grid.items():
param_best_val = best_params[param_name]
param_best_score = best_score
for val in values:
candidate = best_params.copy()
candidate[param_name] = val
result = run_backtest_fn(**candidate)
score = result[metric]
if score > param_best_score:
param_best_score = score
param_best_val = val
best_params[param_name] = param_best_val
best_score = param_best_score
print(f"{param_name}: best={param_best_val}, score={param_best_score:.4f}")
return best_params
最適化にどの指標を選ぶべきか? 生のPnLやPnL@MaxLevの代わりに、effective score — アクティブ時間あたりのPnLを年換算で使用することをお勧めします。この指標はポジション保有時間を考慮し、異なる取引頻度の戦略を正しく比較できます。
盲点:パラメータ間の相互作用
OATは各パラメータの効果が加法的であると仮定します。つまり、あるパラメータの最適値は他のパラメータの値に依存しないということです。一部のパラメータではこの仮定は成り立ちますが、連動するパラメータでは破綻します。
加法的パラメータ vs 連動パラメータ
最適化の前に、パラメータを分類すると便利です。
加法的(独立) — 一方の最適値が他方に依存しない。個別に安価に最適化できます:
htf_entry_sellとhtf_entry_buy— 同じタイムフレームでの異なる方向(売り/買い)のエントリー閾値。売り閾値はショートシグナルをフィルタし、買い閾値はロングをフィルタします。重複しないトレードのサブセットで動作します。tp_targetとbe_trigger— テイクプロフィットとブレイクイーブン(矛盾する決済条件を生み出さない場合)。
連動(相互作用あり) — 一方の最適値が他方に依存する。共同最適化が必要です:
htf_entry_sellとmtf_entry_sell— 異なるタイムフレームでの同じ方向(売り)の閾値。HTFはどのシグナルがMTFに到達するかを決定し、MTFの閾値はフィルタリングの有効性を決定します。MTFが変わるとHTFの最適値がシフトします。ltf_entry_sell、mtf_entry_sell、htf_entry_sell— 1つの方向の閾値チェーン全体。partial_fracとtp_target— 部分決済のサイズはTPレベルに依存します。
実践的アプローチ: まず加法的パラメータをOATで安価に最適化します。次に連動グループをOptunaで最適化します。これによりバジェットが削減されます:Optunaに12パラメータすべてを送る代わりに、連動する6〜8個だけを送り、残りはすでに固定されています。
例:OATが相互作用を見逃すケース
2つの連動閾値を考えます:
htf_entry_sell— 上位タイムフレームの閾値(売り方向)mtf_entry_sell— 中位タイムフレームの閾値(売り方向)
OATはmtf_entry_sell = 0.01(初期値)を固定し、htf_entry_sellの値を順に試します。最良値を発見:htf_entry_sell = 0.02。これを固定し、次のパラメータに移動し、二度と戻りません。
OATが見逃したものは以下の通りです:
htf_entry_sell |
mtf_entry_sell |
PnL |
|---|---|---|
| 0.02 | 0.01 | +42% |
| 0.02 | 0.02 | +38% |
| 0.03 | 0.02 | +51% |
| 0.03 | 0.01 | +35% |
組み合わせ(0.03, 0.02)はPnL +51%をもたらしますが、固定されたmtf_entry_sell = 0.01ではhtf_entry_sell = 0.03は+35%しか得られないため、OATはこの組み合わせを検討しません。OATは局所最適(0.02, 0.01)に「はまり」、大域最適(0.03, 0.02)を見ることができません。
これは典型的な問題です:目的関数の地形に斜めの稜線が含まれる場合(あるパラメータの変化に伴い別のパラメータの最適値がシフトする場合)、OATはそれを見逃します。
問題の形式化
を目的関数(PnL)とします。OATは以下の条件を満たす点を見つけます:
しかしこれは大域最適の必要条件であり、十分条件ではありません。ヘッセ行列に有意な非対角要素がある場合、OATはのときの交差微分を考慮しません。
連動パラメータ(複数のタイムフレームにわたる同じ方向の閾値)の場合、相互作用は例外ではなく法則です。上位タイムフレームのエントリー閾値はどのシグナルが中位に到達するかを決定し、中位の閾値は下位でのフィルタリングの有効性を決定します。加法的パラメータ(異なる方向、独立したフィルター)の場合、交差微分はゼロに近く、OATはうまく機能します。
ベイズ最適化:賢い探索

アイデア
盲目的な列挙や貪欲な探索の代わりに、ベイズ最適化は目的関数のサロゲートモデルを構築し、各ステップで期待される改善が最大となる点を選択します。
アルゴリズム:
- いくつかのランダムな点を選び、目的関数を評価する
- サロゲートモデルを構築する(観測点からを近似)
- 期待される改善が最大の点を見つける(獲得関数)
- その点で目的関数を評価する
- サロゲートモデルを更新する
- ステップ3〜5を繰り返す
OATとの主な違い:ベイズ最適化はすべてのパラメータを同時に考慮し、パラメータ空間の斜めの稜線を探索できます。
TPE(Tree-structured Parzen Estimator)

TPEはOptunaのデフォルトサンプラーです。を直接モデル化する代わりに、TPEは2つの分布をモデル化します:
- — 目的関数が閾値より良いパラメータの分布
- — 目的関数が閾値より悪いパラメータの分布
TPEの獲得関数は以下の比率です:
TPEはが大きく(「良い」パラメータに類似)、が小さい(「悪い」パラメータに類似しない)点を選択します。
TPEがバックテストに適している理由:
- パラメータ間の条件付き依存関係を処理できる
- 目的関数の連続性を必要としない
- 中程度のバジェット(100〜1000回の反復)で効率的
- カテゴリカルおよび離散パラメータをサポート
Gaussian Process(GP)
TPEの代替としてGaussian Processがあります。GPはを多変量正規過程としてモデル化し、各点での値の予測だけでなく不確実性も提供します。
ここでは平均、は共分散関数(カーネル)です。
GPは以下の場合にうまく機能します:
- パラメータが少ない(10〜15個まで)
- 目的関数が滑らかである
- 各実行がコスト高い(分単位、時間単位)
Parquetキャッシュで事前計算されたバックテストでは、1回の実行が約1秒であるため、通常TPEが好まれます。モデルの構築が速く、500回以上の反復にも適切にスケールします。
Optunaとの実践的統合
完全な動作例
import optuna
from optuna.samplers import TPESampler
import numpy as np
def run_backtest(htf_pre, mtf_pre, ltf_pre, **params) -> dict:
"""
Runs a backtest with given parameters.
Returns a dict with metrics: pnl, max_dd, n_trades, trading_time, sharpe.
Uses precomputed Parquet cache — ~1 second per run.
"""
pass
def objective(trial: optuna.Trial) -> float:
"""Objective function for Optuna."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
study = optuna.create_study(
sampler=TPESampler(seed=42),
study_name="strategy_optimization",
direction="minimize",
)
study.optimize(objective, n_trials=500, show_progress_bar=True)
print(f"Best PnL: {-study.best_value:.2f}%")
print(f"Best params: {study.best_params}")
print(f"Total trials: {len(study.trials)}")
事前計算済みキャッシュで1回のバックテストが約1秒の場合:
網羅的探索の8,950年に対して8分。そしてTPEは500回の反復で、OATが96回では見逃す組み合わせを発見します。なぜなら、パラメータ空間を1軸ずつではなく同時に探索するからです。
Studyの保存と再開
import optuna
study = optuna.create_study(
storage="sqlite:///optuna_study.db",
study_name="strategy_v2",
sampler=TPESampler(seed=42),
direction="minimize",
load_if_exists=True, # continue if study already exists
)
study.optimize(objective, n_trials=300)
study.optimize(objective, n_trials=200)
制約条件の追加
すべてのパラメータの組み合わせが有効とは限りません。例えば、決済閾値はエントリー閾値を超えるべきではありません:
def objective_with_constraints(trial: optuna.Trial) -> float:
htf_entry = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
htf_exit = trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005)
if htf_exit > htf_entry:
raise optuna.TrialPruned()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
サンプラー比較
Optunaは複数のサンプラーをサポートしています。それぞれに強みがあります。
TPESampler(デフォルト)
sampler = optuna.samplers.TPESampler(
n_startup_trials=20, # random trials before modeling begins
seed=42,
)
- 原理: Tree-structured Parzen Estimator
- 強み: 混合パラメータ型に適し、1000回以上の反復にスケール可能
- 弱み: パラメータ間の強い相互作用がある場合、効率が落ちる可能性
- 使用場面: 他を選ぶ理由がない場合のデフォルト
CmaEsSampler
sampler = optuna.samplers.CmaEsSampler(seed=42)
- 原理: Covariance Matrix Adaptation Evolution Strategy — 共分散行列を適応させる進化的アルゴリズム
- 強み: 連続パラメータ間の相互作用の検出に優れ、相関を考慮
- 弱み: カテゴリカルパラメータをサポートせず、初期化により多くの反復が必要
- 使用場面: すべてのパラメータが連続で、強い相互作用が疑われる場合
GPSampler
sampler = optuna.samplers.GPSampler(seed=42)
- 原理: 獲得関数を持つGaussian Process
- 強み: 最高のサンプル効率(少ない反復で良い結果)、不確実性の推定を提供
- 弱み: 反復回数に対してで、のとき遅い
- 使用場面: 1回のバックテストが高コスト(分単位)でバジェットが100〜200回の反復に限られる場合
RandomSampler(ベースライン)
sampler = optuna.samplers.RandomSampler(seed=42)
- 原理: 一様ランダムサンプリング
- 強み: 局所最適に陥らず、空間全体をカバー
- 弱み: 過去の結果を利用しない
- 使用場面: 比較のためのベースライン、または探索的分析
QMCSampler
sampler = optuna.samplers.QMCSampler(seed=42)
- 原理: Quasi-Monte Carlo(Sobol/Halton列) — ランダムサンプラーよりも均一に空間を充填
- 強み: RandomSamplerよりも良い空間カバレッジ、再現性
- 弱み: 結果に適応しない
- 使用場面: TPEに切り替える前の最初の50〜100回の反復
サマリーテーブル
| サンプラー | タイプ | 相互作用 | カテゴリカル | 最適バジェット |
|---|---|---|---|---|
| TPE | Bayesian | 部分的 | はい | 100-1000 |
| CmaEs | 進化的 | はい | いいえ | 200-2000 |
| GP | Bayesian | はい | 限定的 | 50-200 |
| Random | ランダム | いいえ | はい | 任意(ベースライン) |
| QMC | 準ランダム | いいえ | いいえ | 50-500 |
実践的ベンチマーク
import optuna
import time
def benchmark_sampler(sampler, n_trials=300):
"""Compare samplers on the same task."""
study = optuna.create_study(sampler=sampler, direction="minimize")
start = time.time()
study.optimize(objective, n_trials=n_trials, show_progress_bar=False)
elapsed = time.time() - start
return {
"best_value": -study.best_value,
"elapsed_sec": elapsed,
"best_trial": study.best_trial.number,
}
samplers = {
"TPE": optuna.samplers.TPESampler(seed=42),
"CmaEs": optuna.samplers.CmaEsSampler(seed=42),
"GP": optuna.samplers.GPSampler(seed=42),
"Random": optuna.samplers.RandomSampler(seed=42),
"QMC": optuna.samplers.QMCSampler(seed=42),
}
for name, sampler in samplers.items():
result = benchmark_sampler(sampler, n_trials=300)
print(f"{name:8s}: best PnL={result['best_value']:.2f}%, "
f"found at trial #{result['best_trial']}, "
f"time={result['elapsed_sec']:.1f}s")
12パラメータの戦略に対する典型的な結果:
| サンプラー | 最良PnL | 発見反復回数 | サンプラーのオーバーヘッド |
|---|---|---|---|
| TPE | 約51% | 約180 | 低い |
| CmaEs | 約49% | 約250 | 中程度 |
| GP | 約48% | 約90 | で高い |
| Random | 約42% | 約270 | 最小 |
| QMC | 約43% | 約200 | 最小 |
TPEとCmaEsは、最終PnLにおいてランダム探索を一貫して15〜20%上回ります。GPは早期に良い結果を見つけますが、反復回数が多い場合に計算の上限に達します。
多目的最適化:PnL vs MaxDD
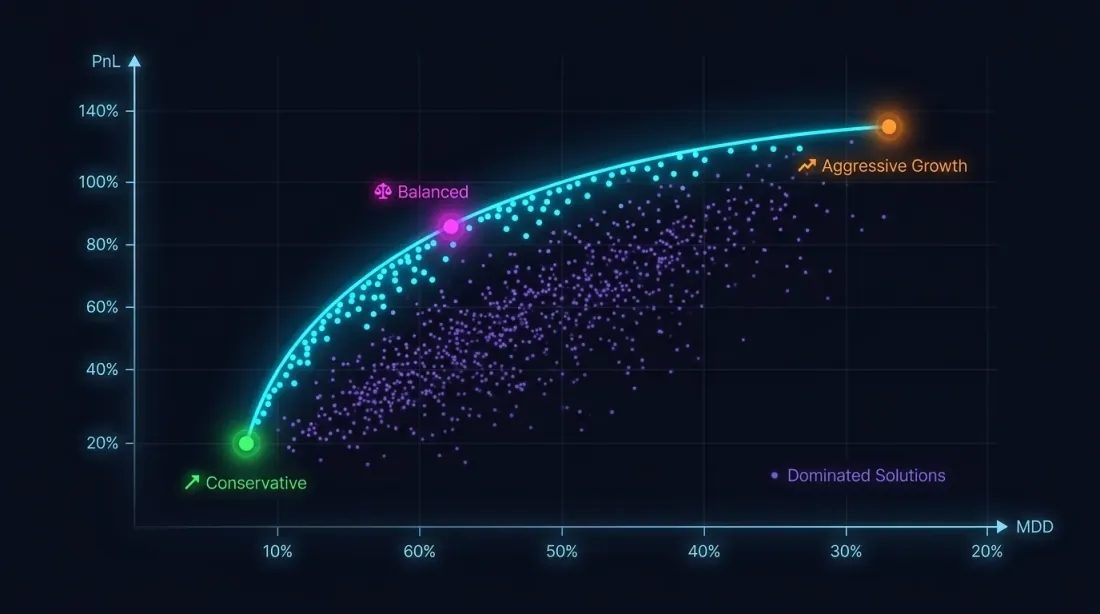
単一基準では不十分な理由
ドローダウン制約なしでPnLを最大化するのは災難への道です。PnL +80%でMaxDD -30%の戦略は、損益の非対称性により、PnL +50%でMaxDD -5%の戦略よりも大幅にリスクが高くなります。
最適化問題は実際には多目的です:
これらの目標は相反します。アグレッシブなパラメータはPnLとドローダウンの両方を増加させます。解は単一の点ではなく、Paretoフロントです。これは、一方の指標を悪化させずに他方を改善できない解の集合です。
OptunaにおけるNSGA-II / NSGA-III
import optuna
def multi_objective(trial: optuna.Trial) -> tuple[float, float]:
"""Multi-objective function: (PnL, MaxDD)."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
pnl = result["pnl"] # maximize
max_dd = result["max_dd"] # minimize (already a negative number)
return pnl, max_dd # Optuna: both directions are set in create_study
study = optuna.create_study(
directions=["maximize", "minimize"],
sampler=optuna.samplers.NSGAIIISampler(seed=42),
study_name="multi_objective_strategy",
)
study.optimize(multi_objective, n_trials=500)
pareto_trials = study.best_trials
print(f"Pareto front: {len(pareto_trials)} solutions")
for t in pareto_trials[:5]:
print(f" PnL={t.values[0]:.2f}%, MaxDD={t.values[1]:.2f}%")
Paretoフロントからの点の選択
Paretoフロントは複数の解を提供します。1つを選ぶにはどうすればよいでしょうか?
def select_from_pareto(
pareto_trials: list,
max_dd_limit: float = -5.0,
min_pnl: float = 20.0,
) -> list:
"""
Filter the Pareto front by constraints.
max_dd_limit: maximum acceptable drawdown (e.g., -5%)
min_pnl: minimum acceptable PnL (%)
"""
filtered = []
for trial in pareto_trials:
pnl, max_dd = trial.values
if max_dd >= max_dd_limit and pnl >= min_pnl:
max_lev = min(50 / abs(max_dd), 100) if max_dd != 0 else 100
pnl_at_max_lev = pnl * max_lev
filtered.append({
"trial": trial,
"pnl": pnl,
"max_dd": max_dd,
"max_lev": max_lev,
"pnl_at_max_lev": pnl_at_max_lev,
})
filtered.sort(key=lambda x: x["pnl_at_max_lev"], reverse=True)
return filtered
注:最大レバレッジでのPnL計算時には、ファンディングレートを考慮する必要があります。そうしないと、理論上高いレバレッジが実際の市場では損失に転じます。さらに、最終PnLは単一点の推定値であり、結果の安定性を評価するにはモンテカルロ・ブートストラップが必要です。
例:Paretoフロント上の3つの戦略
| 戦略 | PnL | MaxDD | MaxLev | PnL@MaxLev | 取引時間 |
|---|---|---|---|---|---|
| 戦略A | 約55% | 約0.9% | 約55x | 約3025% | 約15% |
| 戦略B | 約25% | 約0.75% | 約66x | 約1650% | 約5% |
| 戦略C | 約300% | 約17% | 約3x | 約900% | 約45% |
印象的なPnL +300%の戦略Cは、高いドローダウンのためPnL@MaxLevでは最も魅力が低くなります。戦略Aはネットレバレッジリターンでリードしますが、アクティブ時間あたりのPnLを考慮すると、戦略Bの方が好ましい場合があります — 95%の空き時間を他の戦略で埋められます。
等高線プロットとパラメータの重要度

ランドスケープの可視化
最適化の後は可視化です。Optunaには組み込みツールがあります:
import optuna.visualization as vis
fig_contour = vis.plot_contour(
study,
params=["htf_entry_sell", "mtf_entry_sell"],
)
fig_contour.show()
fig_importance = vis.plot_param_importances(study)
fig_importance.show()
fig_history = vis.plot_optimization_history(study)
fig_history.show()
fig_parallel = vis.plot_parallel_coordinate(
study,
params=["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell"],
)
fig_parallel.show()
fig_slice = vis.plot_slice(study)
fig_slice.show()
等高線プロット:相互作用の読み取り
等高線プロットは、パラメータのペアに対する目的関数の二次元断面を構築します。等高線が軸の1つに平行な場合、パラメータは相互作用せず、OATでも同じ最適値を見つけられたでしょう。等高線が対角的な場合、相互作用があり、OATは見逃します。
key_params = ["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell",
"htf_entry_buy", "mtf_entry_buy", "ltf_entry_buy"]
for i, p1 in enumerate(key_params):
for p2 in key_params[i+1:]:
fig = vis.plot_contour(study, params=[p1, p2])
fig.write_image(f"contour_{p1}_vs_{p2}.png")
等高線プロットにプラトー(目的関数の変化が小さい領域)が表示される場合、これは良い兆候です。プラトーは、小さなパラメータ偏差に対して結果が頑健であることを意味します。プラトー分析とオーバーフィッティングとの関係についての詳細は、今後の記事プラトー分析をご覧ください。
パラメータの重要度
importance = optuna.importance.get_param_importances(study)
for param, imp in importance.items():
print(f"{param:20s}: {imp:.4f}")
典型的な出力:
htf_entry_sell : 0.2841
mtf_entry_sell : 0.2103
ltf_entry_sell : 0.1567
trail_pct : 0.1204
htf_entry_buy : 0.0892
...
重要度が0.01未満のパラメータはデフォルト値で固定できます。これにより問題の次元が削減され、最適化が高速化されます。ただし注意が必要です:低い重要度は、そのパラメータが他との相互作用でのみ重要であることを意味する場合もあります。等高線プロットで検証してください。
事前計算済みキャッシュ:1回1秒のバックテストがすべてを変える理由
1回のバックテストの速度が、どの最適化手法を利用できるかを決定します。
| バックテスト時間 | 96回OAT | 500回TPE | 2000回CmaEs |
|---|---|---|---|
| 60秒 | 1.6時間 | 8.3時間 | 33時間 |
| 10秒 | 16分 | 83分 | 5.5時間 |
| 1秒 | 1.5分 | 8分 | 33分 |
| 0.1秒 | 10秒 | 50秒 | 3.3分 |
1回のバックテストが60秒の場合、500回のTPE反復に8時間かかります。許容範囲内ですが、反復(目的関数の変更、再起動)は高コストです。1秒なら8分で、1日に数十の実験を実行できます。
まさにこれが、Parquetキャッシュへの事前計算が単なる速度最適化ではなく、利用可能な手法の空間の拡大である理由です。キャッシュなしではOATまたは100回のGP反復に制限されます。キャッシュがあれば、2000回のCmaEs反復や完全な多目的NSGA-IIIを実行する余裕があります。
import pyarrow.parquet as pq
import time
t0 = time.time()
htf_pre = pq.read_table("cache/htf_indicators.parquet").to_pandas()
mtf_pre = pq.read_table("cache/mtf_indicators.parquet").to_pandas()
ltf_pre = pq.read_table("cache/ltf_indicators.parquet").to_pandas()
print(f"Cache loaded in {time.time() - t0:.2f}s") # ~0.3s
t1 = time.time()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, htf_entry_sell=0.02, ...)
print(f"Backtest in {time.time() - t1:.2f}s") # ~1.0s
実践的な推奨事項
OATを使うべき場合
以下の場合にOATは正当化されます:
-
探索的分析。 戦略の調査を始めたばかりで、どのパラメータが結果に影響するかを理解したい場合。96回の実行を1.5分で — 優れた出発点です。
-
加法的パラメータ。 重複しないトレードのサブセットで動作するパラメータ(売り vs 買い方向、異なる金融商品)の場合、OATはより速く正しい結果を出します。
-
非常に高コストなバックテスト。 1回の実行に10分以上かかり、高速化できない場合、96回のOAT(16時間)の方が500回のTPE反復(3.5日)よりも好ましいです。
Optunaを使うべき場合
ほとんどの場合、Optunaが好ましいです:
-
3つ以上のパラメータ。 相互作用はほぼ確実に存在し、OATは最適値を見逃します。
-
マルチタイムフレーム戦略。 異なるタイムフレームの閾値はほぼ常に相互に関連しています。
-
最終最適化。 戦略がモンテカルロ・ブートストラップを通過し、その頑健性に確信がある場合、Optunaが最良のパラメータを見つけます。
-
多目的問題。 PnL vs MaxDD vs 取引時間 — OATは原理的にこの問題を解決できません。
ハイブリッドアプローチ:加法的にはOAT + 連動にはOptuna
OATとOptunaの間で選ぶ必要はありません — 組み合わせる方が良いです:
-
パラメータを分類する。 加法的(独立)と連動(相互作用あり)に分けます。12個の分離パラメータの例:
- 加法的:
htf_entry_sell<->htf_entry_buy、mtf_entry_sell<->mtf_entry_buy、ltf_entry_sell<->ltf_entry_buy(売り/買い — 異なる方向、重複しないトレードで動作) - 連動グループsell:
htf_entry_sell、mtf_entry_sell、ltf_entry_sell(フィルタリングチェーン:HTF -> MTF -> LTF 売りシグナル用) - 連動グループbuy:
htf_entry_buy、mtf_entry_buy、ltf_entry_buy
- 加法的:
-
加法的にはOAT。 売りグループと買いグループを独立に最適化します。売りパラメータが買いトレードに影響しない場合、OATは数分で正しい結果を出します。
-
連動にはOptuna。 各グループ内(sell:6パラメータ entry+exit)でTPEを使用します。12個の代わりに6個のパラメータ — バジェットが半分に削減されます。
sell_params = oat_sweep(sell_param_grid, run_backtest, initial_params)
def objective_sell(trial):
params = sell_params.copy()
params["htf_entry_sell"] = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
params["mtf_entry_sell"] = trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005)
params["ltf_entry_sell"] = trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005)
params["htf_exit_sell"] = trial.suggest_float("htf_exit_sell", 0.0, 0.02, step=0.001)
params["mtf_exit_sell"] = trial.suggest_float("mtf_exit_sell", 0.0, 0.02, step=0.001)
params["ltf_exit_sell"] = trial.suggest_float("ltf_exit_sell", 0.0, 0.02, step=0.001)
return -run_backtest(**params)["effective_score"]
study = optuna.create_study(sampler=optuna.samplers.TPESampler())
study.optimize(objective_sell, n_trials=300) # 6 parameters → 300 is enough
完全な最適化パイプライン
1. Parquetキャッシュを事前計算(1回のみ)
2. パラメータを分類:加法的 vs 連動
3. 加法的にOAT(約50回、約1分)→ 固定
4. 連動グループにOptuna TPE(300反復 x 2グループ、約10分)
5. メタパラメータにOptuna NSGA-III(500反復、約8分)→ Paretoフロント
6. 等高線プロット → 相互作用の可視化
7. 最良点のモンテカルロ・ブートストラップ → 信頼区間
8. Walk-Forward → アウトオブサンプル検証
ステップ8のWalk-Forward最適化は、オーバーフィッティング防止のために極めて重要です。詳細は今後の記事Walk-Forwardをご覧ください。
最適化の落とし穴
オーバーフィッティング。 パラメータが多く最適化が精密なほど、戦略を過去データにフィットさせるリスクが高まります。12パラメータで500回のOptuna反復は、訓練セットで完璧に機能する組み合わせを見つけますが、新しいデータでは役に立ちません。
対策:
- データをtrain/test(70/30)に分割
- モンテカルロ・ブートストラップで安定性を評価
- Walk-Forwardで検証
- プラトー上の解を優先(詳細はプラトー分析を参照)
多重比較問題。 500個の組み合わせをテストすると、偶然「良い」結果が見つかる確率が増大します。Bonferroni補正やFDR(偽発見率)制御が役立ちますが、より簡単なアプローチはアウトオブサンプル検証です。
バジェット不足。 12パラメータに対するTPE 50回の反復は少なすぎます。最初の20回はランダム(スタートアップ)なので、モデリングに使えるのは30回だけです。最小バジェット:回の反復(12パラメータの場合)、推奨:。
Freqtrade:本番フレームワークでの動作

Freqtradeは人気のアルゴトレーディングフレームワークの1つで、HyperoptモジュールによりOptunaを内部で使用しています。その経験は私たちの推奨事項を裏付けています:
- サンプラー: TPE(デフォルト)、GP、CmaEs、NSGA-II、QMC — すべて設定を通じて利用可能
- 損失関数: 12個の組み込み損失関数。ShortTradeDurHyperOptLoss、SharpeHyperOptLoss、MaxDrawDownHyperOptLossなど
- 多目的: 複数の指標の同時最適化のためのNSGA-IIおよびNSGA-IIIのサポート
- カスタムサンプラー: Optuna互換の任意のサンプラーをプラグイン可能
Freqtradeエコシステムからの重要な教訓:組み込みの損失関数は典型的なシナリオをカバーしますが、本格的な最適化にはあなたの戦略の特性を考慮したカスタム目的関数が必要です — アクティブ時間、ファンディングコスト、正確な約定シミュレーションのための適応的ドリルダウン。
まとめ

座標降下法(OAT)は高速で直感的な手法です。12パラメータに対してわずか96回の実行で、1分半で完了します。しかし、パラメータの相互作用に対して盲目的であり、マルチタイムフレーム戦略では相互作用がほぼ常に存在します。
Optunaを通じたベイズ最適化(TPE、GP、CmaEs)は、パラメータ空間を全体として探索します。事前計算済みのParquetキャッシュを使えば、8分間の500回の反復で、OATには見えない組み合わせを発見します。
多目的最適化(NSGA-III)は「PnLを最大化する」問題を「PnL vs MaxDDのParetoフロントを構築する」問題に変換し、異なるリスク・リターンのトレードオフを持つ解の集合を提供します。
ただし、最適化はパイプラインの一部に過ぎません。見つかったパラメータはモンテカルロ・ブートストラップで検証し、ファンディングレートを補正し、アクティブ時間を考慮して再計算し、Walk-Forward検証を実行する必要があります。詳細はシリーズの今後の記事をご覧ください。
参考リンク
- Optuna: A Next-generation Hyperparameter Optimization Framework (Akiba et al., 2019)
- Algorithms for Hyper-Parameter Optimization (Bergstra et al., 2011) — the original TPE paper
- Optuna Documentation — Samplers
- Optuna Visualization Module
- Hansen, N. — The CMA Evolution Strategy: A Tutorial
- Deb, K. et al. — NSGA-II: A Fast and Elitist Multiobjective Genetic Algorithm (2002)
- Snoek, J. et al. — Practical Bayesian Optimization of Machine Learning Algorithms (2012)
- Freqtrade Documentation — Hyperopt
- Marcos Lopez de Prado — Advances in Financial Machine Learning, Chapter 12
- Bergstra, J. & Bengio, Y. — Random Search for Hyper-Parameter Optimization (2012)
Citation
@article{soloviov2026optuna,
author = {Soloviov, Eugen},
title = {Coordinate Descent vs Bayesian Optimization: Which Finds Better Parameters},
year = {2026},
url = {https://marketmaker.cc/en/blog/post/optuna-vs-coordinate-descent},
description = {Why exhaustive search is impossible for 12+ parameters, how coordinate descent misses interactions, and how Optuna with a TPE sampler finds in 500 iterations what OAT cannot find in 96.}
}
MarketMaker.cc Team
クオンツ・リサーチ&戦略


