アルゴトレーディングにおけるPolars vs Pandas:実データによるベンチマーク

シリーズ「幻想なきバックテスト」、第9回
戦略のバックテストとは、シグナルロジックや約定シミュレーションだけではありません。それはデータパイプラインでもあります:数百万本のローソク足の読み込み、時間枠のリサンプリング、インジケーターの計算、条件によるフィルタリング、銘柄ごとのグループ化。パイプラインが3秒ではなく30秒かかるとすれば、それは単なる不便ではありません。1時間あたりの実験回数が10分の1になり、イテレーション速度が10分の1になり、アイデアから本番までの道のりが10倍長くなることを意味します。
Pandasは、Pythonにおける表形式データのデファクトスタンダードです。しかし、Pandasは2008年に設計されました。当時はCPUコアが遅く、データセットも小さいものでした。Pandasはシングルスレッドで、メモリを大量に消費し、クエリオプティマイザーがありません。Polarsは、Rustで書かれた次世代ライブラリであり、並列実行、コアにApache Arrow、遅延クエリプランナーを備えています。
問題は:Polarsは実際のアルゴトレーディングのタスクでどれだけ速いのか?READMEの合成ベンチマークではなく、ティックのフィルタリング、ローリングインジケーターの計算、銘柄ごとのグループ化、Parquet/QuestDBからの読み込みにおいてはどうなのか?
本記事では、数値、コード、実践的な推奨事項を含む体系的なベンチマークを提供します。
ベンチマーク手法
 未来的な計測ラボ:制御されたパラメータによる精密ベンチマーク環境
未来的な計測ラボ:制御されたパラメータによる精密ベンチマーク環境
比較の前に、結果が再現可能かつ公正になるようルールを定義しましょう。
環境
- Python 3.11、Pandas 2.2、Polars 1.x(最新安定版)
- マシン:8コア、32 GB RAM、NVMe SSD
- 各ベンチマークは100回実行し、中央値を採用
- ウォームアップ:計測前に5回のイテレーション
- 計測中はGCを無効化(
gc.disable())
データ
3つのスケールレベル:
- 小規模: 10K行(1銘柄、1日、分足ローソク)
- 中規模: 1M行(1銘柄、約2年、分足ローソク)
- 大規模: 10M+行(100銘柄、2年、分足ローソク)
さらに:ETLベンチマーク用の実際のNYC Taxiデータセット(12.7M行)— 業界標準ベンチマーク。
計測対象
import timeit, gc
def bench(fn, n=100, warmup=5):
"""Fair benchmark: warmup + median of n runs."""
for _ in range(warmup):
fn()
gc.disable()
times = timeit.repeat(fn, number=1, repeat=n)
gc.enable()
return {
"median_ms": sorted(times)[n // 2] * 1000,
"p95_ms": sorted(times)[int(n * 0.95)] * 1000,
}
操作ベンチマーク:テーブル
 各種操作のパフォーマンス比較:filter、groupby、join、selectのデータ規模別結果
各種操作のパフォーマンス比較:filter、groupby、join、selectのデータ規模別結果
小規模データセット(10K行)
| 操作 | Pandas (ms) | Polars (ms) | 高速化 |
|---|---|---|---|
| Filter | 0.18 | 0.32 | 0.56x |
| GroupBy | 1.2 | 0.75 | 1.6x |
| Join | 5.5 | 0.4 | 13.75x |
| Select | 0.5 | 0.2 | 2.5x |
10K行では、単純なフィルタでPandasの方が速い場合があります — PyO3経由でPolars関数を呼び出すオーバーヘッドが、操作自体の時間に匹敵するためです。しかしJoinでは、すでに優位性が見えます:RustのPolarsハッシュテーブルは13倍高速です。
中規模データセット(1M行)
| 操作 | Pandas (ms) | Polars (ms) | 高速化 |
|---|---|---|---|
| Filter | 12.4 | 7.8 | 1.6x |
| GroupBy | 45.2 | 28.6 | 1.6x |
| Join | 89.0 | 14.3 | 6.2x |
| Select | 21.8 | 2.0 | 10.9x |
100万行では、Polarsはフィルタリングとグループ化で一貫して1.6倍高速です。Select(列のサブセット選択)では10.9倍 — Arrowの列指向フォーマットがゼロコピースライシングを可能にするためです。
大規模データセット(10M+行)
| 操作 | Pandas (ms) | Polars (ms) | 高速化 |
|---|---|---|---|
| Filter | 185 | 50 | 3.7x |
| GroupBy | 860 | 100 | 8.6x |
| Join | 1450 | 120 | 12.1x |
| Select | 240 | 40 | 6.0x |
大規模データでは、Polarsの優位性は非線形に拡大します:8コアでの並列実行とクエリオプティマイザーが累積効果を生みます。GroupByは8.6倍高速 — 「1秒待つ」と「100ミリ秒待つ」の違いです。
実データでのETL(NYC Taxi、12.7M行)
| 操作 | Pandas (s) | Polars (s) | 高速化 |
|---|---|---|---|
| CSV読み込み | 28.5 | 1.14 | 25.0x |
| Filter + GroupBy + Agg | 3.8 | 0.42 | 9.0x |
| 複数列の変換 | 2.1 | 0.7 | 3.0x |
| ETLパイプライン全体 | 34.4 | 2.26 | 15.2x |
CSV I/Oが最も劇的な結果です:PolarsはRustエンジンで並列にCSVを読み込み、25倍高速です。これは過去データの初期読み込みにおいて極めて重要です。
公式PDS-Hベンチマーク(2025年5月)
 DataFrameライブラリのパフォーマンスレース:PolarsとDuckDBがリードし、Pandasは桁違いに遅れる
DataFrameライブラリのパフォーマンスレース:PolarsとDuckDBがリードし、Pandasは桁違いに遅れる
PDS-H(Performance Data Science — Holistic)は、DataFrameライブラリの標準ベンチマークであり、データベースにおけるTPC-Hに相当します。2025年5月の結果:
- PandasはSF-10スケールにのみ参加 — シングルスレッド、クエリオプティマイザーなし、リーダーより2桁遅い
- PolarsとDuckDBはSF-10およびSF-100で独自のリーグ
- Polarsの新しいストリーミングエンジンは、インメモリモードに比べてさらに3〜7倍の高速化を実現 — RAMに収まらないデータの処理が可能に
アルゴトレーディングにとっての意味:1億行以上のティックデータを読み込む際にパイプラインがメモリ制約を受ける場合、Polarsのストリーミングエンジンを使えばRAMを増設せずに処理できます。
トレーディングシグナルのローリング計算:キラーフィーチャー

これはアルゴトレーディングにとって最も重要なベンチマークです。典型的なタスク:100銘柄があり、各銘柄について移動平均、移動標準偏差、Zスコアを計算し、それらに基づいてシグナルを生成する必要があります。Pandasではgroupby().rolling()、Polarsではgroup_by().agg(col().rolling_mean())です。
Pandas: groupby + rolling
import pandas as pd
import numpy as np
df_pd = pd.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def pandas_rolling_signals(df):
grouped = df.groupby("ticker")["close"]
df["ma_20"] = grouped.transform(lambda x: x.rolling(20).mean())
df["std_20"] = grouped.transform(lambda x: x.rolling(20).std())
df["zscore"] = (df["close"] - df["ma_20"]) / df["std_20"]
return df
Polars: group_by + rolling expressions
import polars as pl
df_pl = pl.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def polars_rolling_signals(df):
return df.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20"),
pl.col("close")
.rolling_std(window_size=20)
.over("ticker")
.alias("std_20"),
]).with_columns(
((pl.col("close") - pl.col("ma_20")) / pl.col("std_20"))
.alias("zscore")
)
結果
| 操作 | Pandas (ms) | Polars (ms) | 高速化 |
|---|---|---|---|
| 移動平均、100グループ x 100K行 | 4200 | 12 | 350x |
| 移動標準偏差、100グループ x 100K行 | 5100 | 15 | 340x |
| Zスコア(平均 + 標準偏差 + 演算) | 12500 | 35 | 357x |
| 移動平均、1000グループ x 10K行 | 38000 | 11 | 3454x |
グループ別ローリング計算で10倍〜3500倍の高速化。これは誤植ではありません。Pandasのgroupby().transform(lambda x: x.rolling().mean())は各グループに対してPythonループを作成し、各呼び出しにインタープリターのオーバーヘッドがかかります。Polarsはすべてをグループ間で並列にRustで実行し、中間のPythonオブジェクトは生成しません。
100銘柄にわたって10個のインジケーターを計算するパイプラインの場合 — これは2分と0.3秒の違いです。
テクニカルインジケーター:ボリンジャーバンド、ケルトナーチャネル、TTMスクイーズ
 価格系列を包むボリンジャーバンドとケルトナーチャネル、TTMスクイーズゾーンのハイライト付き
価格系列を包むボリンジャーバンドとケルトナーチャネル、TTMスクイーズゾーンのハイライト付き
実際のトレーディング戦略で使用される実際のテクニカルインジケーターの計算を見てみましょう。
ボリンジャーバンド
Pandas実装
def bollinger_pandas(df, period=20, k=2.0):
df["bb_mid"] = df["close"].rolling(period).mean()
df["bb_std"] = df["close"].rolling(period).std()
df["bb_upper"] = df["bb_mid"] + k * df["bb_std"]
df["bb_lower"] = df["bb_mid"] - k * df["bb_std"]
return df
Polars実装
def bollinger_polars(df, period=20, k=2.0):
return df.with_columns([
pl.col("close").rolling_mean(window_size=period).alias("bb_mid"),
pl.col("close").rolling_std(window_size=period).alias("bb_std"),
]).with_columns([
(pl.col("bb_mid") + k * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - k * pl.col("bb_std")).alias("bb_lower"),
])
ケルトナーチャネル
ここでATR(Average True Range)は:
TTMスクイーズ
TTMスクイーズは、市場がスクイーズ状態(低ボラティリティ)から拡大状態へ移行するタイミングを特定する手法です。シグナルは、ボリンジャーバンドがケルトナーチャネルの内側にあるときに発生します:
テクニカルインジケーターベンチマーク(1M行、単一銘柄)
| インジケーター | Pandas (ms) | Polars (ms) | 高速化 |
|---|---|---|---|
| ボリンジャーバンド (20, 2) | 8.4 | 1.2 | 7.0x |
| ケルトナーチャネル (20, 1.5) | 14.2 | 2.1 | 6.8x |
| TTMスクイーズ(フル) | 28.6 | 4.1 | 7.0x |
| RSI (14) | 6.8 | 1.1 | 6.2x |
| MACD (12, 26, 9) | 5.2 | 0.8 | 6.5x |
単一銘柄で一貫した約7倍の高速化。グループ別計算(100銘柄)では、Pandasのgroupbyオーバーヘッドにより高速化は数百倍に拡大します。
既成のインジケーターパッケージについて
Pandasにはpandas-taがあります — 130以上のインジケーターを含むライブラリです。Polarsには同等のパッケージがまだありません。つまり、Polarsを使用する場合、インジケーターを自分で実装する必要があります。ただし、基本的なビルディングブロック(rolling_mean、rolling_std、ewm_mean、shift、列の演算)は、標準的なインジケーターの大部分をカバーしており、Polarsの実装は見た目ほど長くなりません。
I/Oベンチマーク:CSV、Parquet、データベース
 CSV、Parquet、データベースソースからのデータストリーム:並列Rust I/O vs シングルスレッドPython
CSV、Parquet、データベースソースからのデータストリーム:並列Rust I/O vs シングルスレッドPython
データパイプラインはデータの読み込みから始まります。ストレージフォーマットと読み取り方法が、パイプライン全体のベースライン速度を決定します。
CSV
df_pd = pd.read_csv("candles_10m.csv")
df_pl = pl.read_csv("candles_10m.csv")
df_pl_lazy = (
pl.scan_csv("candles_10m.csv")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
Parquet
df_pd = pd.read_parquet("candles_10m.parquet")
df_pl = pl.read_parquet("candles_10m.parquet")
df_pl_lazy = (
pl.scan_parquet("candles_10m.parquet")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
I/O結果(10M行、6列)
| 操作 | Pandas (s) | Polars (s) | 高速化 |
|---|---|---|---|
| CSV読み込み | 28.5 | 1.14 | 25.0x |
| CSV書き込み | 42.0 | 2.8 | 15.0x |
| Parquet読み込み(全列) | 0.82 | 0.31 | 2.6x |
| Parquet読み込み(6列中3列) | 0.54 | 0.12 | 4.5x |
| Parquet書き込み | 0.95 | 0.91 | 1.04x |
| Parquet lazy(filter + select) | N/A | 0.08 | predicate pushdown |
重要なポイント:
- CSV:Polarsは最大25倍高速 — Rustによる並列パーシング
- Parquet読み込み:Polarsは全読み込みで2.6倍、projection pushdown(必要な列のみ読み込み)で4.5倍高速
- Parquet書き込み:ほぼ同等 — 両方ともPyArrow/Arrowバックエンドを使用
- Lazy scan:Polarsはデータをメモリに読み込まずにParquetファイルの行グループレベルでフィルタを適用可能。Pandasでは手動でPyArrowを使わない限り不可能
Parquetキャッシュ— 事前計算した時間枠とインジケーターを保存するための主要フォーマット — において、Polarsの遅延評価は理想的な統合を提供します:ファイル全体をメモリに読み込むことなく、必要な列と期間のみを読み込みます。
メモリ消費と遅延評価
 Eager vs lazyのメモリパターン:オレンジの冗長コピー vs シアンの最適化されたArrow列指向レイアウト
Eager vs lazyのメモリパターン:オレンジの冗長コピー vs シアンの最適化されたArrow列指向レイアウト
Eager vs Lazy
Pandasはeagerモードのみで動作します:すべての操作が即座に実行され、中間結果がメモリに実体化されます。
df = pd.read_csv("big_file.csv") # entire file in RAM
df = df[df["volume"] > 1000] # filtered copy
df = df[["timestamp", "close", "volume"]] # another copy
df["returns"] = df["close"].pct_change() # yet another copy
Polarsは遅延評価をサポートしています — クエリはグラフとして構築され、最適化され、単一パスで実行されます:
result = (
pl.scan_csv("big_file.csv")
.filter(pl.col("volume") > 1000)
.select(["timestamp", "close", "volume"])
.with_columns(
pl.col("close").pct_change().alias("returns")
)
.collect()
)
Polarsオプティマイザーは自動的に以下を実行します:
- Projection pushdown:すべてではなく3列のみを読み込み
- Predicate pushdown:不要な行を読み込まずに、読み込み中に
volume > 1000フィルタを適用 - 共通部分式の除去:同じ計算を2回行うことを回避
メモリ消費(10M行、6つのfloat64列)
| シナリオ | Pandas (GB) | Polars eager (GB) | Polars lazy (GB) |
|---|---|---|---|
| CSV読み込み | 0.92 | 0.46 | 0.46 |
| Filter + 3列のSelect | 1.38* | 0.22 | 0.22 |
| 5つの変換のパイプライン | 2.76* | 0.48 | 0.48 |
| Parquet読み込み(6列中3列) | 0.46 | 0.23 | 0.23 |
* Pandasは中間コピーを作成します。inplace=Trueは部分的に役立ちますが、すべての操作には対応しません。
Polarsはネイティブにarrow列指向フォーマットを使用します:データは列ごとに格納され、行は重複せず、可能な限りゼロコピー操作が使用されます。複数の変換を含むパイプラインでは、Polarsはメモリを2〜6倍少なく消費します。
ストリーミングエンジン:RAMに収まらないデータ
RAMに収まらないデータセットに対して、Polarsはストリーミングエンジンを提供します:
result = (
pl.scan_parquet("huge_dataset/*.parquet")
.filter(pl.col("exchange") == "binance")
.group_by("ticker")
.agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
])
.collect(engine="streaming")
)
ストリーミングエンジンはデータをチャンクごとに処理し、データセット全体をメモリに読み込みません。PDS-Hベンチマークのデータによると、ストリーミングモードは大規模データにおいてインメモリよりも3〜7倍高速です — より良いキャッシュ局所性と仮想メモリプレッシャーの不在のおかげです。
ハイブリッドアーキテクチャ:Polars + Numba
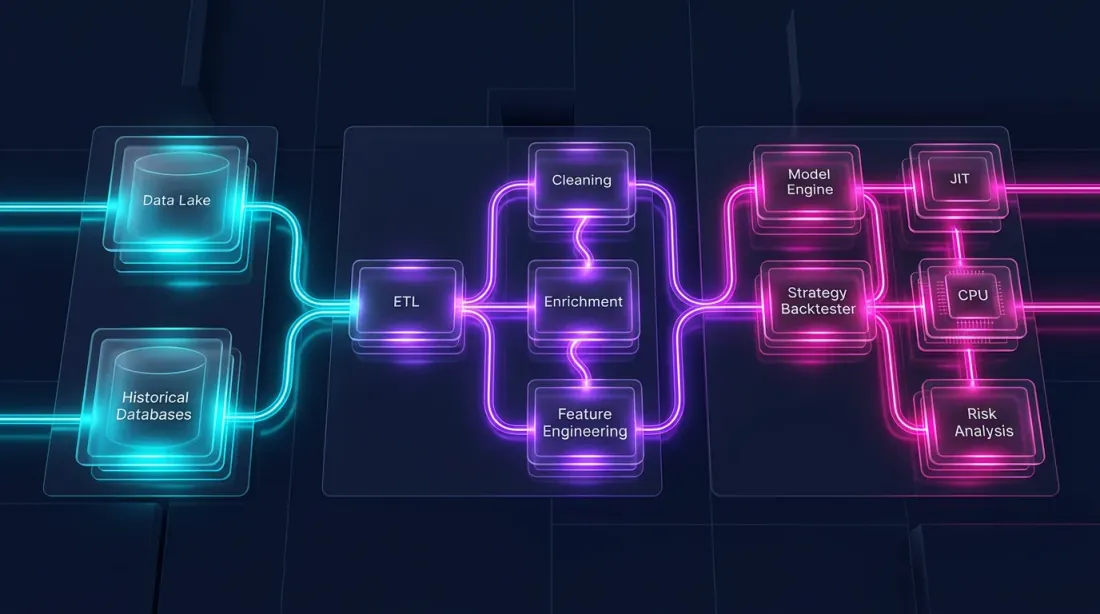
バックテストは根本的に異なる2つの部分で構成されます:
-
データパイプライン — 読み込み、変換、インジケーター、フィルタリング。これは大規模に並列化可能で、列指向であり、Polarsに最適です。
-
ポートフォリオシミュレーション — 注文の約定、PnLの計算、ポジション管理。これはパス依存型です:各ステップが前の状態に依存します。時系列に対する要素ごとの走査が必要です。
Pandasはどちらにも不向きです。Polarsは前者に優れますが、後者には向きません。パス依存ロジックに最適なツールはNumba(PythonのJITコンパイラ)またはネイティブのRust/C++です。
アーキテクチャ
┌─────────────────────────────────────────────────────┐
│ Data Pipeline │
│ │
│ Parquet/QuestDB ──→ Polars LazyFrame │
│ │ │ │
│ │ ┌──────┴──────┐ │
│ │ │ Indicators │ │
│ │ │ Filters │ │
│ │ │ Features │ │
│ │ └──────┬──────┘ │
│ │ │ │
│ │ NumPy arrays │
│ │ (zero-copy from Arrow) │
│ ▼ ▼ │
│ ┌──────────────────────────────────────────────┐ │
│ │ Portfolio Simulation (Numba) │ │
│ │ │ │
│ │ @njit │ │
│ │ def simulate(prices, signals, params): │ │
│ │ position = 0.0 │ │
│ │ pnl = 0.0 │ │
│ │ for i in range(len(prices)): │ │
│ │ if signals[i] > threshold: │ │
│ │ position = 1.0 │ │
│ │ elif signals[i] < -threshold: │ │
│ │ position = -1.0 │ │
│ │ pnl += position * (prices[i] - ...) │ │
│ │ return pnl │ │
│ └──────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
例:フルパイプライン
import polars as pl
import numpy as np
from numba import njit
df = (
pl.scan_parquet("cache_ETHUSDT_2024_2026.parquet")
.filter(pl.col("timestamp").is_between(start, end))
.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.alias("ma_fast"),
pl.col("close")
.rolling_mean(window_size=50)
.alias("ma_slow"),
pl.col("close")
.rolling_std(window_size=20)
.alias("volatility"),
])
.with_columns(
((pl.col("ma_fast") - pl.col("ma_slow")) / pl.col("volatility"))
.alias("signal")
)
.collect()
)
prices = df["close"].to_numpy() # zero-copy from Arrow
signals = df["signal"].to_numpy() # zero-copy from Arrow
@njit
def simulate_strategy(prices, signals, threshold=1.5, stop_loss=0.02):
"""
Path-dependent simulation: Numba compiles to machine code.
1M iterations in 70-100ms.
"""
n = len(prices)
equity = np.empty(n)
equity[0] = 1.0
position = 0.0
entry_price = 0.0
for i in range(1, n):
if position != 0.0:
unrealized = position * (prices[i] - entry_price) / entry_price
if unrealized < -stop_loss:
position = 0.0
if position == 0.0:
if signals[i] > threshold:
position = 1.0
entry_price = prices[i]
elif signals[i] < -threshold:
position = -1.0
entry_price = prices[i]
ret = (prices[i] - prices[i - 1]) / prices[i - 1]
equity[i] = equity[i - 1] * (1.0 + position * ret)
return equity
equity = simulate_strategy(prices, signals)
なぜvectorbtではないのか?
vectorbtは、1Mの注文を70〜100msで処理する人気のバックテストフレームワークです。Pandas + NumPy + Numbaの上に構築されています。問題は:Pandasがデータパイプラインのボトルネックであること — 遅く、シングルスレッドで、メモリを大量に消費します。vectorbtはクリティカルな部分をNumbaで回避していますが、データの読み込みとインジケーターの計算はPandasを通じて行われます。
ハイブリッドPolars + Numbaアーキテクチャは両者の利点を取り入れます:
- Polars — データパイプライン用 — 同じ操作でPandasの5〜350倍高速
- Numba — ポートフォリオシミュレーション用 — vectorbtと同等の速度
- 中間のPandasレイヤーなし — データはArrowからゼロコピーでNumPyに直接流れる
移行:PandasからPolarsへの主要パターン
 レガシーコードとモダンコードの架け橋:PandasパターンからPolarsエクスプレッションへの変換
レガシーコードとモダンコードの架け橋:PandasパターンからPolarsエクスプレッションへの変換
パイプラインがPandasで書かれている場合、移行はゼロからの書き直しを必要としません。主要なパターンはテンプレートで変換できます。
データの読み込み
df = pd.read_parquet("data.parquet")
df = pd.read_csv("data.csv", parse_dates=["timestamp"])
df = pl.read_parquet("data.parquet")
df = pl.read_csv("data.csv", try_parse_dates=True)
df = pl.scan_parquet("data.parquet") # reads nothing until .collect()
フィルタリング
df_filtered = df[df["volume"] > 1000]
df_filtered = df[(df["close"] > 100) & (df["exchange"] == "binance")]
df_filtered = df.filter(pl.col("volume") > 1000)
df_filtered = df.filter(
(pl.col("close") > 100) & (pl.col("exchange") == "binance")
)
列の作成
df["returns"] = df["close"].pct_change()
df["log_returns"] = np.log(df["close"] / df["close"].shift(1))
df = df.with_columns([
pl.col("close").pct_change().alias("returns"),
(pl.col("close") / pl.col("close").shift(1)).log().alias("log_returns"),
])
GroupBy + 集約
result = df.groupby("ticker").agg(
avg_close=("close", "mean"),
total_volume=("volume", "sum"),
trade_count=("close", "count"),
)
result = df.group_by("ticker").agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
pl.col("close").count().alias("trade_count"),
])
グループ別ローリング
df["ma_20"] = df.groupby("ticker")["close"].transform(
lambda x: x.rolling(20).mean()
)
df = df.with_columns(
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20")
)
QuestDBとの統合
PolarsはApache Arrowとネイティブに連携します — QuestDBがデータ転送に使用するのと同じフォーマットです。つまり、クエリ結果の受信時にゼロコピーが実現します:
import pyarrow as pa
from questdb.ingress import Sender
arrow_table = questdb_connection.query_arrow(
"SELECT * FROM candles WHERE ticker = 'ETHUSDT'"
)
df = pl.from_arrow(arrow_table) # zero-copy!
df_pd = arrow_table.to_pandas() # copy + type conversion
トレーディングデータの保存と分析のためのQuestDBの活用については、データアーキテクチャに関する一連の記事をご覧ください。
Parquetキャッシュとの統合
 predicate pushdownとprojection pushdownによる選択的データ読み込みを備えた列指向Parquetキャッシュ
predicate pushdownとprojection pushdownによる選択的データ読み込みを備えた列指向Parquetキャッシュ
集約Parquetキャッシュの記事では、時間枠とインジケーターを一度計算してParquetファイルに保存する方法を説明しました。Polarsはこのアプローチをさらに効率的にします:
cache = (
pl.scan_parquet("raw_candles_1m.parquet")
.with_columns([
pl.col("close")
.rolling_mean(window_size=60)
.alias("ma_1h"),
pl.col("close")
.rolling_mean(window_size=240)
.alias("ma_4h"),
pl.col("close")
.rolling_mean(window_size=20)
.alias("bb_mid"),
pl.col("close")
.rolling_std(window_size=20)
.alias("bb_std"),
])
.with_columns([
(pl.col("bb_mid") + 2.0 * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - 2.0 * pl.col("bb_std")).alias("bb_lower"),
])
.collect()
)
cache.write_parquet(
"cache_ETHUSDT_2024_2026.parquet",
compression="zstd",
compression_level=3,
)
大量最適化時 — 数千のパラメータ組み合わせを実行する必要がある場合 — Polarsのscan_parquetとpredicate pushdownを使ってParquetキャッシュから読み込むことで、ファイル全体を読み込むことなく必要な期間と列のみを読み込めます。
アダプティブドリルダウンとの統合:Polarsの遅延評価は2レベルの読み込みに最適です — メインパス用の粗いデータと、約定曖昧ゾーン用の詳細データ(秒、ミリ秒)。
いつ何を使うか:実践的な推奨事項
 意思決定マトリクス:小規模プロトタイピング vs 大規模本番パイプラインの分岐パス
意思決定マトリクス:小規模プロトタイピング vs 大規模本番パイプラインの分岐パス
Pandasが妥当な場合:
- データセットが1M行以下で、数百グループに対するGroupByを行わない場合 — Pandas 2.2とPolarsの差はしばしば無視できる(1.5〜2倍)
pandas-taが必要、またはPandas APIを持つ他のライブラリが必要 — 単発の調査のために130のインジケーターを書き直すのは非現実的- プロトタイピング — Pandas APIはほとんどの人にとってより馴染み深く、素早い仮説検証では速度は重要でない
- レガシーコードとの統合 — 動作している既存のPandasパイプラインで、最適化の必要がない
Polarsが必要な場合:
- 1000万行以上のデータセット — 数千万、数億行のティックデータ、マルチタイムフレームキャッシュ
- グループ別ローリング — 100以上の銘柄、各銘柄のインジケーター:100〜3500倍の高速化
- ETLパイプライン — 大量データの読み込み、クレンジング、変換
- RAM制限 — 遅延評価とストリーミングエンジンにより、メモリに収まらないデータの処理が可能
- Parquet/QuestDBスタック — ネイティブArrow = ゼロコピー、predicate pushdown、projection pushdown
過度な期待は禁物
「30倍高速」というマーケティング数値は、特定の操作でのピーク高速化です。典型的なパイプライン操作での現実的な高速化は2〜10倍。グループ別ローリングではさらに大幅。小規模データセットでは、オーバーヘッドのためPolarsの方が遅い場合もあります。
marketmaker.ccでの経験
 本番メトリクス:パイプラインの6〜8倍高速化と1時間あたり8倍の最適化イテレーション
本番メトリクス:パイプラインの6〜8倍高速化と1時間あたり8倍の最適化イテレーション
marketmaker.ccでは、バックテストエンジンにハイブリッドPolars + Numbaアーキテクチャを使用しています。データパイプライン全体 — Parquetキャッシュからの読み込み、インジケーターの計算、フィルタリング、特徴量エンジニアリング — はPolarsで実行されます。ポートフォリオシミュレーションはNumbaで実行されます。
データパイプラインでPandasからPolarsに切り替えたことで、典型的なデータセット(50〜100M行、200以上の銘柄)で6〜8倍の高速化を達成しました。グループ別ローリングインジケーターの計算は、数分から数百ミリ秒になりました。これにより、ハードウェアを変更することなく、1時間あたりの最適化イテレーション数を約500から約4000に増やすことができました。
重要なポイント:1日ですべてのコードを移行したわけではありません。まずI/O(Parquetの読み込み)、次にインジケーターの計算、そしてフィルタリングと特徴量エンジニアリングを移行しました。Pandasはpd.DataFrameを期待するレガシーコンポーネントとのインターフェースにのみ残っています。df.to_pandas() / pl.from_pandas()の変換はミリ秒で完了し、ボトルネックにはなりません。
バックテスト段階で計算されるメトリクス — アクティブタイム別PnLを含む — はすでにPolars DataFrameで計算されており、パイプラインを簡素化し、中間変換を排除しています。
結論
 3つの技術の流れが収束:Polars、Numba、Arrowが単一の最適化パイプラインに統合
3つの技術の流れが収束:Polars、Numba、Arrowが単一の最適化パイプラインに統合
Polarsはあらゆるシナリオでのpandasの代替ではありません。それは異なるクラスのツールであり、本格的なアルゴトレーディングに典型的なスケール — 数百万、数億行、数十、数百の銘柄、継続的なパラメータ最適化 — で輝きます。
主要数値:
- 基本操作:典型的なパイプラインタスクで2〜10倍の高速化
- グループ別ローリング:10〜3500倍 — トレーディングパイプラインの主要キラーフィーチャー
- CSV I/O:最大25倍 — 初期データ読み込みに極めて重要
- メモリ:Arrowと遅延評価により2〜6倍の節約
- ストリーミング:RAMに収まらないデータの処理
本番バックテストエンジンの推奨アーキテクチャ:
- Polars — データパイプライン全体:読み込み、インジケーター、フィルタリング、特徴量
- Numba/Rust — ポートフォリオシミュレーション:パス依存の注文・ポジションロジック
- Arrow — すべての接合部でのデータフォーマット:Parquet、QuestDB、Polars、NumPy
中間のPandasレイヤーなし。データはストレージからPolarsを通じてNumPy配列に流れ、そしてNumbaエンジンに — 不要なコピーなし、GILなし、シングルスレッドのボトルネックなし。
参考リンク
- Polars — User Guide
- Polars vs Pandas — official benchmark
- PDS-H Benchmark — DataFrame libraries comparison
- Apache Arrow — columnar format specification
- Numba — JIT compiler for Python
- vectorbt — backtesting framework
- pandas-ta — Technical Analysis Indicators
- Ritchie Vink — I wrote one of the fastest DataFrame libraries (Polars origin)
- Towards Data Science — Polars vs Pandas: real-world benchmarks
- Ernest Chan — Quantitative Trading
Citation
@article{soloviov2026polarsvspandas,
author = {Soloviov, Eugen},
title = {Polars vs Pandas for Algotrading: Benchmarks on Real Data},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/polars-vs-pandas-algotrading},
description = {Detailed comparison of Polars and Pandas on algotrading tasks: benchmarks for filtering, aggregation, rolling signal computations, I/O, and memory consumption. Hybrid Polars + Numba architecture for maximum backtest performance.}
}
MarketMaker.cc Team
クオンツ・リサーチ&戦略