Walk-Forward Optimization: единственный честный тест стратегии

Вы оптимизировали стратегию. 12 параметров разделения, 9 мета-параметров — итого 21. Бэктест на 25 месяцах одной пары показывает PnL +3342% при MaxLev. Equity curve растёт почти без просадок. Sharpe выше 3. Всё выглядит идеально.
Вы запускаете бота. Через две недели стратегия сливает 18% капитала. Через месяц — 34%. Параметры, которые «работали» на исторических данных, оказались подогнаны под конкретную последовательность рыночных событий. Вы не нашли закономерность — вы запомнили шум.
Это классический overfitting. И единственный системный способ его обнаружить до запуска в продакшен — Walk-Forward Optimization (WFO).
Ловушка single train/test split

Стандартный подход: разбиваем данные на 70% train и 30% test. Оптимизируем на train, проверяем на test. Если результат положительный — запускаем.
Проблема: это один тест на одном разбиении. Результат зависит от того, где проведена граница. Сдвиньте границу на месяц — и out-of-sample PnL может измениться с +40% до -15%.
Данные: |===== Train (70%) =====|== Test (30%) ==|
Split 1: |===2024-01..2025-09====|==2025-10..26-01==| → OOS PnL: +38%
Split 2: |===2024-01..2025-06====|==2025-07..26-01==| → OOS PnL: -12%
Split 3: |===2024-04..2025-12====|==2026-01..26-04==| → OOS PnL: +7%
Три разных разбиения — три разных вывода. Какому верить? Ни одному. Один train/test split — это тот же single-point estimate, о проблемах которого мы писали в Monte Carlo Bootstrap. Вам нужна не одна проверка, а систематическая серия проверок на последовательных участках данных.
Именно для этого существует Walk-Forward Optimization.
Что такое Walk-Forward Optimization

WFO — это процедура последовательной оптимизации и проверки стратегии на скользящих (или расширяющихся) окнах данных. Идея: имитировать реальный процесс торговли, при котором вы периодически переоптимизируете параметры на доступных данных и затем торгуете до следующей переоптимизации.
Каждое «окно» состоит из двух частей:
- In-Sample (IS) — период, на котором оптимизируются параметры
- Out-of-Sample (OOS) — период, на котором проверяются найденные параметры без подгонки
Ключевое свойство: OOS-периоды не пересекаются и в совокупности покрывают значительную часть данных. Итоговая equity curve строится только из OOS-участков — это и есть честная оценка стратегии.
Anchored WFO (расширяющееся окно)

В anchored WFO начало train-периода фиксировано, а его конец расширяется с каждым окном:
Window 1: Train [2024-01] → Test [2024-04]
Window 2: Train [2024-01..04] → Test [2024-07] (growing train)
Window 3: Train [2024-01..07] → Test [2024-10]
Window 4: Train [2024-01..10] → Test [2025-01]
Window 5: Train [2024-01..2025-01] → Test [2025-04]
Преимущества:
- Каждый последующий train-период содержит больше данных — оптимизация стабильнее
- Ранние паттерны не теряются — они всегда в обучающей выборке
- Проще реализовать
Недостатки:
- Старые данные могут «разбавлять» актуальные паттерны
- Если рынок структурно изменился — старые данные вредят
- Train-период растёт неограниченно, увеличивая время оптимизации
Rolling WFO (скользящее окно)
В rolling WFO train-период фиксированной длины «скользит» по данным:
Window 1: Train [2024-01..06] → Test [2024-07..09]
Window 2: Train [2024-04..09] → Test [2024-10..12]
Window 3: Train [2024-07..12] → Test [2025-01..03]
Window 4: Train [2024-10..2025-03] → Test [2025-04..06]
Window 5: Train [2025-01..06] → Test [2025-07..09]
Преимущества:
- Адаптация к текущему рыночному режиму
- Постоянное время оптимизации
- Старые, нерелевантные данные не влияют
Недостатки:
- Меньше данных для обучения — выше дисперсия оптимальных параметров
- Чувствителен к выбору длины окна
- Может «забывать» редкие, но важные события (flash crashes)
Combinatorial Purged Cross-Validation (CPCV)

Продвинутый метод, предложенный Marcos Lopez de Prado. Данные разбиваются на групп, из которых выбираются для test. Ключевое отличие от обычной cross-validation — purging (удаление данных на границе train/test) и embargo (дополнительный зазор для предотвращения data leakage):
При : 45 комбинаций train/test. Каждая комбинация даёт OOS-результат, и финальная оценка — среднее по всем комбинациям.
from itertools import combinations
import numpy as np
def cpcv_splits(n_groups: int, k_test: int, purge_pct: float = 0.01):
"""
Генерация CPCV splits с purging.
Args:
n_groups: число групп
k_test: число test-групп в каждом split
purge_pct: доля данных для purging (на границе train/test)
"""
groups = list(range(n_groups))
splits = []
for test_groups in combinations(groups, k_test):
train_groups = [g for g in groups if g not in test_groups]
splits.append({
"train": train_groups,
"test": list(test_groups),
"purge_groups": _get_purge_groups(train_groups, test_groups),
})
return splits
def _get_purge_groups(train, test):
"""Группы на границе train/test для purging."""
purge = set()
for t in test:
if t - 1 in train:
purge.add(t - 1)
if t + 1 in train:
purge.add(t + 1)
return list(purge)
CPCV лучше rolling WFO при малом количестве данных, но вычислительно дороже. Для стратегии с 21 параметром и 25 месяцами данных рекомендуем начать с rolling WFO, а CPCV использовать как дополнительную проверку.
Ключевые параметры WFO

Длина train-периода
Слишком короткий train — недостаточно данных для надёжной оптимизации. Слишком длинный — старые данные размывают текущие паттерны.
Эмпирическое правило: train должен содержать минимум 200-300 сделок. Если стратегия делает 2 сделки в день:
Для крипты с её режимными переключениями рекомендуем не более 6-12 месяцев rolling window.
Длина test-периода
Test-период должен быть достаточным для статистически значимой оценки, но не слишком длинным — иначе параметры успевают деградировать.
Правило: test = 20-33% от train. Если train = 6 месяцев, test = 1.5-2 месяца.
Overlap (перекрытие)
В rolling WFO окна могут перекрываться. Overlap увеличивает число OOS-точек, но вносит корреляцию между оценками:
Без overlap:
Train [01..06] → Test [07..09]
Train [07..12] → Test [01..03]
С overlap 50%:
Train [01..06] → Test [07..09]
Train [04..09] → Test [10..12]
Train [07..12] → Test [01..03]
Рекомендация: overlap 50% по train-периоду — хороший баланс между количеством окон и независимостью оценок.
Частота реоптимизации
Определяет, как часто вы пересчитываете параметры. На крипторынке оптимальная частота — каждые 1-3 месяца. Более частая реоптимизация увеличивает риск overfitting на шум; более редкая — риск устаревания параметров.
Walk-Forward Efficiency Ratio и Degradation Rate
Walk-Forward Efficiency Ratio (WFER)
Ключевая метрика WFO — отношение OOS-доходности к IS-доходности:
Интерпретация:
| WFER | Интерпретация |
|---|---|
| > 0.8 | Отличная робастность. Параметры переносятся на новые данные. |
| 0.5 — 0.8 | Приемлемая робастность. Стратегия работает, но с деградацией. |
| 0.3 — 0.5 | Пограничный случай. Вероятен частичный overfitting. |
| < 0.3 | Overfitting. Параметры подогнаны под IS-данные. |
| < 0 | Стратегия убыточна OOS. Полный overfitting или ошибка в логике. |
Если WFER < 0.5 — скорее всего, стратегия переобучена. Это наш основной фильтр.
Degradation Rate
Показывает, как быстро оптимальные параметры теряют эффективность во времени:
Практически: разделите test-период на подинтервалы и отследите динамику PnL:
def degradation_rate(oos_returns: np.ndarray, n_subperiods: int = 4) -> float:
"""
Оценка скорости деградации параметров.
Разбивает OOS-период на подинтервалы и считает наклон линейной регрессии
PnL по номеру подинтервала.
Returns:
slope: отрицательный = деградация, положительный = улучшение
"""
chunk_size = len(oos_returns) // n_subperiods
subperiod_pnls = []
for i in range(n_subperiods):
start = i * chunk_size
end = start + chunk_size
sub_pnl = np.sum(oos_returns[start:end])
subperiod_pnls.append(sub_pnl)
x = np.arange(n_subperiods)
slope = np.polyfit(x, subperiod_pnls, 1)[0]
return slope
Если degradation rate сильно отрицательный — параметры быстро устаревают, и вам нужна более частая реоптимизация или более короткий train-период.
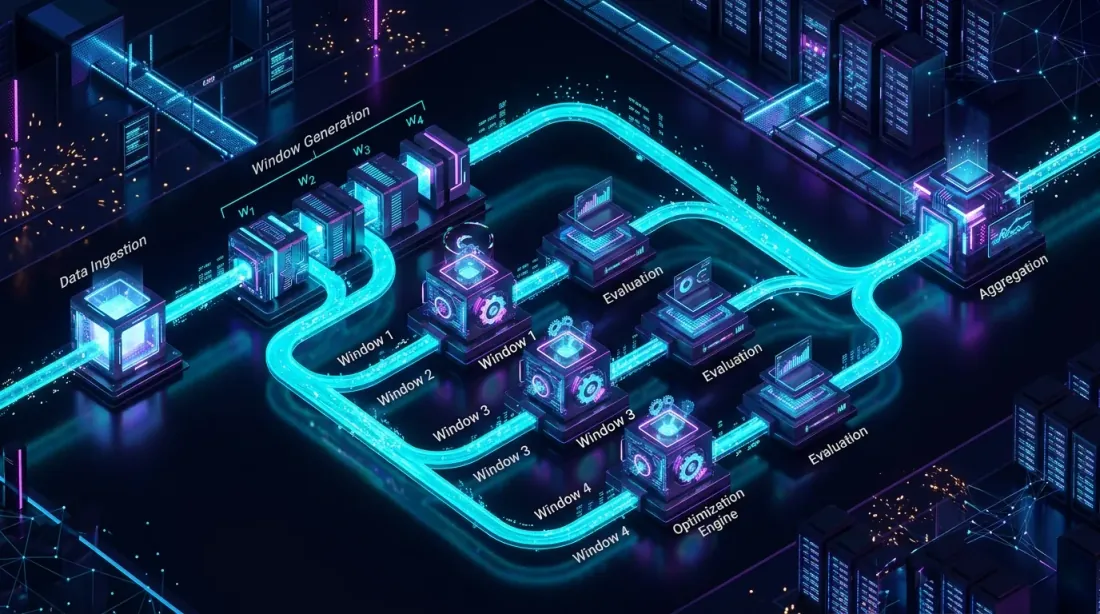
Полная реализация WFO pipeline на Python
import numpy as np
import pandas as pd
from dataclasses import dataclass, field
from typing import Callable, List, Optional
import warnings
@dataclass
class WFOWindow:
"""Одно окно walk-forward."""
window_id: int
train_start: int # индекс начала train
train_end: int # индекс конца train (exclusive)
test_start: int # индекс начала test
test_end: int # индекс конца test (exclusive)
best_params: dict = field(default_factory=dict)
is_pnl: float = 0.0 # in-sample PnL
oos_pnl: float = 0.0 # out-of-sample PnL
oos_returns: np.ndarray = field(default_factory=lambda: np.array([]))
wfer: float = 0.0 # walk-forward efficiency ratio
@dataclass
class WFOResult:
"""Результат всего WFO."""
windows: List[WFOWindow]
aggregate_oos_pnl: float
aggregate_is_pnl: float
wfer: float
degradation_rate: float
oos_equity: np.ndarray
oos_sharpe: float
oos_max_dd: float
n_windows: int
passed: bool # прошла ли стратегия фильтр
class WalkForwardOptimizer:
"""
Walk-Forward Optimization pipeline.
Поддерживает anchored (expanding) и rolling (sliding) режимы.
"""
def __init__(
self,
data: np.ndarray,
optimize_fn: Callable,
evaluate_fn: Callable,
mode: str = "rolling", # "rolling" или "anchored"
train_size: int = 180, # дней
test_size: int = 60, # дней
step_size: int = 60, # шаг сдвига окна, дней
min_trades: int = 30, # мин. число сделок в OOS
wfer_threshold: float = 0.5, # порог WFER для accept/reject
):
self.data = data
self.optimize_fn = optimize_fn
self.evaluate_fn = evaluate_fn
self.mode = mode
self.train_size = train_size
self.test_size = test_size
self.step_size = step_size
self.min_trades = min_trades
self.wfer_threshold = wfer_threshold
def generate_windows(self) -> List[WFOWindow]:
"""Генерация окон walk-forward."""
n = len(self.data)
windows = []
window_id = 0
if self.mode == "rolling":
start = 0
while start + self.train_size + self.test_size <= n:
w = WFOWindow(
window_id=window_id,
train_start=start,
train_end=start + self.train_size,
test_start=start + self.train_size,
test_end=min(start + self.train_size + self.test_size, n),
)
windows.append(w)
start += self.step_size
window_id += 1
elif self.mode == "anchored":
train_end = self.train_size
while train_end + self.test_size <= n:
w = WFOWindow(
window_id=window_id,
train_start=0,
train_end=train_end,
test_start=train_end,
test_end=min(train_end + self.test_size, n),
)
windows.append(w)
train_end += self.step_size
window_id += 1
return windows
def run(self) -> WFOResult:
"""Запуск полного WFO pipeline."""
windows = self.generate_windows()
all_oos_returns = []
for w in windows:
train_data = self.data[w.train_start:w.train_end]
test_data = self.data[w.test_start:w.test_end]
best_params, is_pnl = self.optimize_fn(train_data)
w.best_params = best_params
w.is_pnl = is_pnl
oos_pnl, oos_returns = self.evaluate_fn(test_data, best_params)
w.oos_pnl = oos_pnl
w.oos_returns = oos_returns
if is_pnl != 0:
w.wfer = oos_pnl / is_pnl
else:
w.wfer = 0.0
all_oos_returns.extend(oos_returns)
all_oos = np.array(all_oos_returns)
oos_equity = np.cumprod(1 + all_oos)
peak = np.maximum.accumulate(oos_equity)
max_dd = ((oos_equity - peak) / peak).min()
aggregate_is = sum(w.is_pnl for w in windows)
aggregate_oos = sum(w.oos_pnl for w in windows)
wfer = aggregate_oos / aggregate_is if aggregate_is != 0 else 0
if np.std(all_oos) > 0:
oos_sharpe = np.mean(all_oos) / np.std(all_oos) * np.sqrt(252)
else:
oos_sharpe = 0
deg_rate = self._degradation_rate(windows)
passed = wfer >= self.wfer_threshold and aggregate_oos > 0
return WFOResult(
windows=windows,
aggregate_oos_pnl=aggregate_oos,
aggregate_is_pnl=aggregate_is,
wfer=wfer,
degradation_rate=deg_rate,
oos_equity=oos_equity,
oos_sharpe=oos_sharpe,
oos_max_dd=max_dd,
n_windows=len(windows),
passed=passed,
)
def _degradation_rate(self, windows: List[WFOWindow]) -> float:
"""Наклон OOS PnL по номеру окна."""
if len(windows) < 3:
return 0.0
pnls = [w.oos_pnl for w in windows]
x = np.arange(len(pnls))
slope = np.polyfit(x, pnls, 1)[0]
return slope
Пример использования
import numpy as np
np.random.seed(42)
prices = 100 * np.cumprod(1 + np.random.normal(0.0002, 0.02, 750))
def my_optimize(train_data):
"""
Оптимизация стратегии на train-данных.
Возвращает (best_params, is_pnl).
"""
best_pnl = -np.inf
best_params = {}
for fast in range(5, 30, 5):
for slow in range(20, 100, 10):
if fast >= slow:
continue
pnl, _ = _run_strategy(train_data, fast, slow)
if pnl > best_pnl:
best_pnl = pnl
best_params = {"fast": fast, "slow": slow}
return best_params, best_pnl
def my_evaluate(test_data, params):
"""
Оценка стратегии на test-данных с фиксированными параметрами.
Возвращает (oos_pnl, oos_returns).
"""
pnl, returns = _run_strategy(test_data, params["fast"], params["slow"])
return pnl, returns
def _run_strategy(data, fast_period, slow_period):
"""Простая MA crossover стратегия."""
fast_ma = pd.Series(data).rolling(fast_period).mean().values
slow_ma = pd.Series(data).rolling(slow_period).mean().values
position = 0
returns = []
for i in range(slow_period, len(data) - 1):
if fast_ma[i] > slow_ma[i] and position <= 0:
position = 1
elif fast_ma[i] < slow_ma[i] and position >= 0:
position = -1
daily_ret = (data[i + 1] - data[i]) / data[i]
returns.append(position * daily_ret)
total_pnl = np.sum(returns)
return total_pnl, np.array(returns)
wfo = WalkForwardOptimizer(
data=prices,
optimize_fn=my_optimize,
evaluate_fn=my_evaluate,
mode="rolling",
train_size=180, # 6 месяцев
test_size=60, # 2 месяца
step_size=60, # шаг = test
)
result = wfo.run()
print(f"Windows: {result.n_windows}")
print(f"OOS PnL: {result.aggregate_oos_pnl:.4f}")
print(f"IS PnL: {result.aggregate_is_pnl:.4f}")
print(f"WFER: {result.wfer:.3f}")
print(f"OOS Sharpe: {result.oos_sharpe:.2f}")
print(f"OOS MaxDD: {result.oos_max_dd:.2%}")
print(f"Degradation: {result.degradation_rate:.5f}")
print(f"Passed: {result.passed}")
for w in result.windows:
print(f" Window {w.window_id}: IS={w.is_pnl:.4f} OOS={w.oos_pnl:.4f} "
f"WFER={w.wfer:.2f} params={w.best_params}")
Интерпретация результатов: когда доверять, когда отвергать
Стратегия прошла WFO
Если WFER >= 0.5 по всем окнам, OOS PnL положительный и стабильный:
Window 0: IS=0.0812 OOS=0.0531 WFER=0.65 params={'fast': 10, 'slow': 50}
Window 1: IS=0.0744 OOS=0.0489 WFER=0.66 params={'fast': 10, 'slow': 50}
Window 2: IS=0.0698 OOS=0.0401 WFER=0.57 params={'fast': 15, 'slow': 50}
Window 3: IS=0.0823 OOS=0.0512 WFER=0.62 params={'fast': 10, 'slow': 60}
Window 4: IS=0.0756 OOS=0.0478 WFER=0.63 params={'fast': 10, 'slow': 50}
→ Aggregate WFER: 0.63, все окна > 0.5, параметры стабильны
Хорошие признаки:
- WFER стабилен по окнам (нет резких скачков)
- Параметры похожи между окнами (fast = 10-15, slow = 50-60)
- OOS PnL положительный в большинстве окон
- Degradation rate близок к нулю
Стратегия провалила WFO
Window 0: IS=0.2341 OOS=-0.0312 WFER=-0.13 params={'fast': 5, 'slow': 95}
Window 1: IS=0.1987 OOS=0.0089 WFER=0.04 params={'fast': 25, 'slow': 30}
Window 2: IS=0.2156 OOS=-0.0567 WFER=-0.26 params={'fast': 10, 'slow': 90}
Window 3: IS=0.1834 OOS=0.0234 WFER=0.13 params={'fast': 20, 'slow': 40}
→ Aggregate WFER: -0.07, IS высокий, OOS около нуля → overfitting
Признаки overfitting:
- Высокий IS PnL, низкий/отрицательный OOS PnL — классический overfitting
- Параметры сильно различаются между окнами — нет стабильного оптимума
- WFER < 0.3 в большинстве окон — параметры не переносятся
- Degradation rate сильно отрицательный — быстрая деградация
Подробнее о анализе устойчивости параметров — в статье Plateau analysis. Если оптимум «острый» (резко падает при малом изменении параметров) — это дополнительный сигнал overfitting.
Особенности WFO для криптовалют
Криптовалюты создают уникальные проблемы для WFO, которых нет на традиционных рынках.
Режимные переключения
Крипторынок переключается между радикально разными режимами: бычий тренд, медвежий тренд, боковик с высокой/низкой волатильностью. Параметры, оптимальные в одном режиме, могут быть убыточными в другом.
Решение: используйте rolling WFO (не anchored) с окном 4-6 месяцев. Это позволяет «забывать» старые режимы. Дополнительно — кластеризуйте данные по волатильности и проводите WFO отдельно по каждому кластеру.
Короткая история
Большинство альткоинов имеют менее 3 лет торговой истории. При train = 6 месяцев и test = 2 месяца вы получите всего 4-5 окон — статистически слабая оценка.
Решение: используйте CPCV вместо или в дополнение к rolling WFO. CPCV генерирует больше комбинаций из тех же данных. Для 10 групп и k=2: 45 комбинаций вместо 4-5 окон.
Структурные изменения ликвидности
Ликвидность криптопар нестационарна: пара может быть ликвидной 6 месяцев, затем объёмы падают в 10 раз. Параметры, оптимизированные на ликвидном рынке, не работают на неликвидном.
Решение: добавьте фильтр ликвидности в WFO pipeline. Исключайте окна, где средний дневной объём ниже порога. Проверяйте, что ликвидность в test-периоде сопоставима с train-периодом.
Влияние funding rates
Для фьючерсных стратегий с плечом funding rates могут кардинально изменить OOS-результат. Стратегия показывает +5% OOS за 2 месяца, но при 10x плече funding съедает 3.6%.
Подробный анализ влияния funding — в нашей статье Funding rates убивают ваш leverage. Обязательно учитывайте funding costs при оценке OOS PnL в WFO.
Многопараметрические стратегии: почему WFO критичен при 12+ параметрах

Стратегия с 21 параметром (12 separation + 9 meta) на 25 месяцах одной пары — это модель с колоссальным пространством поиска.
Проклятие размерности
Число комбинаций параметров растёт экспоненциально с числом параметров:
Если каждый из 21 параметра принимает хотя бы 10 значений:
Даже при Bayesian-оптимизации (подробнее в Координатный спуск vs Bayesian) вы исследуете ничтожную долю пространства. Вероятность того, что найденный оптимум — артефакт шума, а не реальная закономерность, растёт с числом параметров.
Формула Бонферрони для множественных сравнений
Если вы проверяете комбинаций параметров, вероятность ложного «открытия» (найти хороший результат случайно):
При и испробованных комбинаций:
Гарантированно найдёте «работающие» параметры — которые на самом деле подогнаны под шум. Без WFO у вас нет способа отличить реальный edge от статистического артефакта.
Правило: число OOS-точек vs число параметров
Эмпирическое правило для доверия к WFO-результатам:
Для 21 параметра нужно минимум 210 OOS-сделок. Если ваш WFO генерирует меньше — результату нельзя доверять.
Стратегия с +3342% PnL@ML: 21 параметр, 25 месяцев данных. Допустим, 5 OOS-окон по 60 дней, 2 сделки/день — итого OOS-сделок. Соотношение — приемлемо, но только если WFER > 0.5.
Интеграция WFO с Optuna

В каждом окне WFO нужно оптимизировать параметры. Для 21 параметра grid search невозможен, координатный спуск неэффективен. Оптимальный выбор — Bayesian optimization через Optuna.
import optuna
from optuna.samplers import TPESampler
def optuna_optimize(train_data: np.ndarray, n_trials: int = 500) -> tuple:
"""
Оптимизация параметров стратегии с помощью Optuna.
Используется внутри каждого окна WFO.
"""
def objective(trial):
fast = trial.suggest_int("fast_period", 3, 50)
slow = trial.suggest_int("slow_period", 20, 200)
atr_period = trial.suggest_int("atr_period", 5, 50)
atr_mult = trial.suggest_float("atr_multiplier", 0.5, 4.0)
rsi_period = trial.suggest_int("rsi_period", 5, 30)
rsi_upper = trial.suggest_int("rsi_upper", 60, 85)
rsi_lower = trial.suggest_int("rsi_lower", 15, 40)
vol_window = trial.suggest_int("vol_window", 10, 100)
position_size = trial.suggest_float("position_size", 0.1, 1.0)
take_profit = trial.suggest_float("take_profit", 0.005, 0.05)
stop_loss = trial.suggest_float("stop_loss", 0.003, 0.03)
trailing_pct = trial.suggest_float("trailing_pct", 0.002, 0.02)
if fast >= slow:
return -1e6 # невалидная комбинация
params = {
"fast_period": fast, "slow_period": slow,
"atr_period": atr_period, "atr_multiplier": atr_mult,
"rsi_period": rsi_period, "rsi_upper": rsi_upper,
"rsi_lower": rsi_lower, "vol_window": vol_window,
"position_size": position_size,
"take_profit": take_profit, "stop_loss": stop_loss,
"trailing_pct": trailing_pct,
}
pnl, _ = run_strategy(train_data, params)
_, returns = run_strategy(train_data, params)
if len(returns) < 30 or np.std(returns) == 0:
return -1e6
sharpe = np.mean(returns) / np.std(returns) * np.sqrt(252)
return sharpe
optuna.logging.set_verbosity(optuna.logging.WARNING)
study = optuna.create_study(
direction="maximize",
sampler=TPESampler(seed=42),
)
study.optimize(objective, n_trials=n_trials, show_progress_bar=False)
best_params = study.best_params
best_pnl, _ = run_strategy(train_data, best_params)
return best_params, best_pnl
wfo = WalkForwardOptimizer(
data=prices,
optimize_fn=optuna_optimize, # Optuna вместо grid search
evaluate_fn=my_evaluate,
mode="rolling",
train_size=180,
test_size=60,
step_size=60,
)
result = wfo.run()
Важно: внутри WFO оптимизируйте Sharpe, а не PnL. Оптимизация по PnL находит параметры, которые максимизируют profit на конкретной последовательности сделок. Оптимизация по Sharpe находит параметры с лучшим соотношением доходности к риску — они робастнее OOS.
Подробное сравнение Optuna TPE с координатным спуском — в статье Координатный спуск vs Bayesian.
Визуализация результатов WFO
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
def plot_wfo_results(result: WFOResult, data: np.ndarray):
"""Визуализация результатов Walk-Forward Optimization."""
fig, axes = plt.subplots(3, 1, figsize=(16, 14))
ax = axes[0]
ax.plot(result.oos_equity, color='#4FC3F7', linewidth=1.5)
ax.axhline(1.0, color='#FF5252', linestyle='--', alpha=0.5, label='Break-even')
ax.set_title(f'OOS Equity Curve (WFER={result.wfer:.2f}, Sharpe={result.oos_sharpe:.2f})')
ax.set_ylabel('Equity')
ax.legend()
ax.grid(True, alpha=0.3)
ax = axes[1]
wfers = [w.wfer for w in result.windows]
colors = ['#69F0AE' if w >= 0.5 else '#FFAB40' if w >= 0.3 else '#FF5252'
for w in wfers]
ax.bar(range(len(wfers)), wfers, color=colors, edgecolor='#1A237E', alpha=0.8)
ax.axhline(0.5, color='#E040FB', linestyle='--', label='Threshold (0.5)')
ax.axhline(0, color='gray', linestyle='-', alpha=0.3)
ax.set_title('Walk-Forward Efficiency Ratio по окнам')
ax.set_xlabel('Window')
ax.set_ylabel('WFER')
ax.legend()
ax = axes[2]
x = np.arange(len(result.windows))
width = 0.35
ax.bar(x - width/2, [w.is_pnl for w in result.windows],
width, label='IS PnL', color='#7C4DFF', alpha=0.7)
ax.bar(x + width/2, [w.oos_pnl for w in result.windows],
width, label='OOS PnL', color='#4FC3F7', alpha=0.7)
ax.set_title('In-Sample vs Out-of-Sample PnL')
ax.set_xlabel('Window')
ax.set_ylabel('PnL')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('wfo_results.png', dpi=150)
plt.show()
Практические рекомендации
Чек-лист перед запуском стратегии в продакшен
1. Запустите WFO (rolling + anchored)
Сравните результаты обоих режимов. Если rolling WFO проваливается, а anchored проходит — скорее всего, стратегия работает только на ранних данных.
2. Проверьте WFER по каждому окну
Не только aggregate WFER, но и каждое окно отдельно. Если 2 из 6 окон имеют WFER < 0 — это проблема, даже если aggregate > 0.5.
3. Сравните параметры между окнами
Если оптимальные параметры «прыгают» от окна к окну — стабильного edge нет. Используйте Plateau analysis для проверки стабильности оптимума.
4. Проверьте degradation rate
Сильно отрицательный degradation rate = параметры быстро теряют эффективность. Нужна более частая реоптимизация или пересмотр стратегии.
5. Примените Monte Carlo bootstrap к OOS-результатам
Aggregate OOS PnL — тоже single-point estimate. Примените Monte Carlo bootstrap к массиву OOS-доходностей для получения confidence intervals.
6. Учтите costs
OOS PnL должен учитывать комиссии, slippage и funding rates. Красивый OOS PnL без costs — иллюзия. Подробнее — Funding rates убивают ваш leverage.
Минимальные требования по данным
| Число параметров | Min OOS trades | Min окон WFO | Min данных (2 сделки/день) |
|---|---|---|---|
| 2-5 | 50 | 3 | ~6 месяцев |
| 6-10 | 100 | 4 | ~12 месяцев |
| 11-15 | 150 | 5 | ~18 месяцев |
| 16-21 | 210 | 6 | ~24 месяца |
| 22+ | 300+ | 8+ | ~36+ месяцев |
Стратегия с 21 параметром и 25 месяцами данных
Вернёмся к вопросу из начала статьи: 21 параметр, оптимизированных на 25 месяцах данных одной пары. PnL@ML = +3342%. Как валидировать?
Шаг 1. Rolling WFO: train = 8 месяцев, test = 2 месяца, step = 2 месяца. Получим ~8 окон.
Шаг 2. Anchored WFO: первый train = 8 месяцев, test = 2 месяца. Получим ~8 окон.
Шаг 3. CPCV: 10 групп по ~2.5 месяца, k = 2. Получим 45 комбинаций.
Шаг 4. Для каждого метода проверить:
- WFER >= 0.5?
- Параметры стабильны между окнами?
- Degradation rate приемлемый?
- OOS trades / Parameters >= 10?
Шаг 5. Monte Carlo bootstrap по aggregate OOS returns. 5th percentile PnL > 0?
Если хотя бы один из этих тестов проваливается — стратегия с +3342% скорее всего переобучена. 21 параметр на 25 месяцах одной пары — это экстремально высокое соотношение параметров к данным. Без прохождения WFO доверия быть не может.
Дополнительно рекомендуем проверить эффективность стратегии с учётом PnL по активному времени — это даст понимание, какая часть +3342% обусловлена временем в позиции, а какая — реальным edge.
Заключение
Walk-Forward Optimization — не опция, а необходимость. Это единственный метод, который системно проверяет переносимость параметров на новые данные. Single train/test split — это лотерея. Полный бэктест на всех данных — это self-deception.
Ключевые выводы:
-
WFER < 0.5 = overfitting. Если out-of-sample PnL меньше половины in-sample — параметры подогнаны.
-
Стабильность параметров важнее максимума. Параметры, которые дают +15% в каждом окне, лучше параметров, которые дают +40% в одном и -10% в другом.
-
Rolling WFO для крипты. Режимные переключения делают anchored WFO менее надёжным. Rolling window 4-6 месяцев — оптимальный баланс.
-
Чем больше параметров — тем строже требования. 21 параметр требует минимум 210 OOS-сделок и 6+ окон WFO. Без этого результат не верифицируем.
-
WFO + Monte Carlo bootstrap + Plateau analysis — три слоя защиты от overfitting. Каждый слой ловит то, что пропускают остальные.
Стратегия, прошедшая WFO с WFER > 0.5 по всем окнам, стабильными параметрами и положительным 5th-percentile bootstrap — это стратегия, которой можно доверять реальные деньги. Всё остальное — curve fitting с красивым equity curve.
Полезные ссылки
- Pardo, R. — The Evaluation and Optimization of Trading Strategies (Wiley)
- Lopez de Prado, M. — Advances in Financial Machine Learning, Chapter 12: Backtesting
- Bailey, D.H. et al. — The Probability of Backtest Overfitting
- Lopez de Prado, M. — The Combinatorial Purged Cross-Validation (CPCV)
- Aronson, D.R. — Evidence-Based Technical Analysis
- Optuna: A Next-generation Hyperparameter Optimization Framework
- Kevin Davey — Building Winning Algorithmic Trading Systems: Walk-Forward Analysis
- White, H. — A Reality Check for Data Snooping (2000)
- Harvey, C.R. & Liu, Y. — Backtesting (2015)
- NumPy — numpy.cumprod
Цитирование
@article{soloviov2026walkforwardoptimization,
author = {Soloviov, Eugen},
title = {Walk-Forward Optimization: единственный честный тест стратегии},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/walk-forward-optimization},
version = {0.1.0},
description = {Почему single train/test split не защищает от overfitting, как walk-forward optimization системно проверяет робастность параметров, и почему стратегия с +3342\% PnL@ML на 21 параметре — бомба замедленного действия без WFO.}
}
MarketMaker.cc Team
Количественные исследования и стратегии
Читайте также

Plateau analysis: как отличить робастный оптимум от overfitting

Adaptive drill-down: бэктест с переменной гранулярностью от минут до сырых сделок
