Координатный спуск vs Bayesian optimization: что находит лучшие параметры
Это пятая статья серии «Бэктесты без иллюзий». В предыдущих статьях мы разобрали асимметрию убытков, Monte Carlo bootstrap, влияние funding rates и Parquet-кэш для ускорения бэктестов. Теперь поговорим о самом процессе поиска оптимальных параметров стратегии — задаче, где интуиция подводит чаще всего.
У вас есть стратегия с 12 параметрами. Каждый параметр принимает ~9 значений. Вы хотите найти комбинацию, максимизирующую PnL при ограниченной просадке. Как вы это делаете?
Если ваш ответ — «перебираю все комбинации» — у вас проблема. Если ваш ответ — «меняю по одному параметру» — у вас другая проблема. Эта статья о том, какие проблемы скрываются за каждым подходом и как их решить.
Почему полный перебор невозможен

Проклятие размерности
Полный перебор (grid search) тестирует каждую комбинацию значений каждого параметра. Для двух параметров с 9 значениями это прогон — вполне реально. Для трёх: — терпимо.
Но для реальной стратегии с 12 параметрами:
Двести восемьдесят два миллиарда прогонов. Даже если один бэктест занимает 1 секунду (что уже оптимистично), полный перебор займёт:
Это экспоненциальный рост: каждый новый параметр умножает пространство поиска в 9 раз. Добавили 13-й параметр — и вместо 9 000 лет нужно 80 000.
import math
def grid_search_cost(n_params: int, values_per_param: int, seconds_per_trial: float) -> dict:
"""Оценка стоимости полного перебора."""
total_trials = values_per_param ** n_params
total_seconds = total_trials * seconds_per_trial
return {
"total_trials": total_trials,
"total_hours": total_seconds / 3600,
"total_years": total_seconds / (3600 * 24 * 365),
}
cost = grid_search_cost(12, 9, 1.0)
print(f"Trials: {cost['total_trials']:,.0f}") # 282,429,536,481
print(f"Years: {cost['total_years']:,.0f}") # 8,950
Даже с предвычислением
В статье про Parquet-кэш мы показали, как предвычисление таймфреймов и индикаторов ускоряет один бэктест до ~1 секунды. Но даже при скорости 0.1 секунды на прогон полный перебор 12 параметров потребует 895 лет. Предвычисление помогает, но не решает фундаментальную проблему экспоненциального роста.
Нужны методы, которые исследуют пространство параметров умнее, чем полный перебор.
Координатный спуск и OAT: быстрые, но слепые
Два варианта одной идеи
Есть два родственных подхода — оба оптимизируют по одному параметру за раз, но отличаются количеством проходов:
OAT (One-at-a-Time) sweep — один проход по всем параметрам. Перебрали значения первого параметра, зафиксировали лучшее, перешли ко второму — и так далее. Один раз. Быстро и дёшево.
Координатный спуск (Coordinate Descent) — многопроходный. После оптимизации последнего параметра возвращаемся к первому и проверяем, не изменился ли оптимум (ведь контекст поменялся — значения других параметров стали другими). Повторяем раунды до сходимости. Дороже, но точнее — каждый раунд может уточнять решение.
На практике для бэктестов чаще используют OAT: один проход по 12 параметрам — 96 прогонов. Координатный спуск с 3–5 раундами — 300–500 прогонов, что уже сопоставимо с Optuna, но без его преимуществ.
Для 12 параметров с ~8 значениями каждого:
Сравните с для grid search. OAT линеен: вместо . Это и его главное преимущество, и его главная проблема.
def oat_sweep(
param_grid: dict[str, list],
run_backtest_fn,
initial_params: dict,
metric: str = "effective_score",
) -> dict:
"""
OAT sweep: один проход, оптимизация по одному параметру за раз.
param_grid: {"htf_entry_sell": [0.0, 0.005, ..., 0.05], ...}
initial_params: стартовые значения всех параметров
metric: метрика для оптимизации (рекомендуется effective_score —
PnL per active time с экстраполяцией на год)
"""
best_params = initial_params.copy()
best_score = run_backtest_fn(**best_params)[metric]
for param_name, values in param_grid.items():
param_best_val = best_params[param_name]
param_best_score = best_score
for val in values:
candidate = best_params.copy()
candidate[param_name] = val
result = run_backtest_fn(**candidate)
score = result[metric]
if score > param_best_score:
param_best_score = score
param_best_val = val
best_params[param_name] = param_best_val
best_score = param_best_score
print(f"{param_name}: best={param_best_val}, score={param_best_score:.4f}")
return best_params
Какую метрику выбрать для оптимизации? Вместо raw PnL или PnL@MaxLev рекомендуется использовать effective score — PnL per active time с экстраполяцией на год. Эта метрика учитывает время в позиции и позволяет корректно сравнивать стратегии с разной частотой торговли.
Слепое пятно: взаимодействия параметров
OAT предполагает, что влияние каждого параметра аддитивно — то есть оптимальное значение одного параметра не зависит от значений других. Это допущение справедливо для некоторых параметров, но нарушается для связанных.
Аддитивные vs связанные параметры
Прежде чем оптимизировать — полезно классифицировать параметры:
Аддитивные (независимые) — оптимальное значение одного не зависит от другого. Их можно оптимизировать по одному дёшево:
htf_entry_sellиhtf_entry_buy— пороги входа для разных направлений (sell/buy) на одном таймфрейме. Sell-порог фильтрует шорт-сигналы, buy-порог — лонг. Они работают на разных подмножествах сделок.tp_targetиbe_trigger— take-profit и breakeven, если они не создают конфликтующих условий выхода.
Связанные (интерактивные) — оптимальное значение одного зависит от другого. Нужна совместная оптимизация:
htf_entry_sellиmtf_entry_sell— пороги для одного направления (sell) на разных таймфреймах. HTF определяет, какие сигналы дойдут до MTF, а порог MTF определяет эффективность фильтрации. Оптимум HTF сдвигается при изменении MTF.ltf_entry_sell,mtf_entry_sell,htf_entry_sell— вся цепочка порогов одного направления.partial_fracиtp_target— размер частичного закрытия зависит от уровня TP.
Практический подход: сначала дёшево оптимизируйте аддитивные параметры через OAT. Затем связанные группы — через Optuna. Это сокращает бюджет: вместо 12 параметров в Optuna отправляем только 6–8 связанных, а остальные уже зафиксированы.
Пример: как OAT пропускает взаимодействие
Рассмотрим два связанных порога:
htf_entry_sell— порог на старшем таймфрейме (sell direction)mtf_entry_sell— порог на среднем таймфрейме (sell direction)
OAT фиксирует mtf_entry_sell = 0.01 (начальное значение) и перебирает htf_entry_sell. Находит лучшее значение: htf_entry_sell = 0.02. Фиксирует его и переходит к следующему параметру — больше не возвращается.
Вот что OAT пропустил:
htf_entry_sell |
mtf_entry_sell |
PnL |
|---|---|---|
| 0.02 | 0.01 | +42% |
| 0.02 | 0.02 | +38% |
| 0.03 | 0.02 | +51% |
| 0.03 | 0.01 | +35% |
Комбинация (0.03, 0.02) даёт PnL +51%, но OAT никогда её не рассмотрит, потому что при фиксированном mtf_entry_sell = 0.01 значение htf_entry_sell = 0.03 даёт лишь +35%. OAT «застрял» в локальном оптимуме (0.02, 0.01) и не видит глобальный оптимум (0.03, 0.02).
Это классическая проблема: если ландшафт целевой функции содержит диагональные хребты (когда оптимум одного параметра сдвигается при изменении другого), OAT их пропускает.
Формализация проблемы
Пусть — целевая функция (PnL). OAT находит точку, в которой:
Но это условие необходимое, а не достаточное для глобального оптимума. Если матрица Гессиана имеет значимые недиагональные элементы — OAT не учитывает кросс-производные при .
Для связанных параметров (пороги одного направления через несколько таймфреймов) — взаимодействия скорее правило, чем исключение. Порог входа на старшем таймфрейме определяет, какие сигналы дойдут до среднего, а порог на среднем определяет эффективность фильтрации на младшем. Для аддитивных параметров (разные направления, независимые фильтры) кросс-производные близки к нулю — и OAT работает хорошо.
Bayesian optimization: умный поиск

Идея
Вместо слепого перебора или жадного поиска, Bayesian optimization строит суррогатную модель целевой функции и на каждом шаге выбирает точку, в которой ожидаемое улучшение максимально.
Алгоритм:
- Выбираем несколько случайных точек, считаем целевую функцию
- Строим суррогатную модель (аппроксимирует по наблюдённым точкам)
- Находим точку с максимальным ожидаемым улучшением (acquisition function)
- Считаем целевую функцию в этой точке
- Обновляем суррогатную модель
- Повторяем шаги 3–5
Ключевое отличие от OAT: Bayesian optimization учитывает все параметры одновременно и может исследовать диагональные хребты в пространстве параметров.
TPE (Tree-structured Parzen Estimator)

TPE — сэмплер по умолчанию в Optuna. Вместо того чтобы моделировать напрямую, TPE моделирует два распределения:
- — распределение параметров, при которых целевая функция лучше порога
- — распределение параметров, при которых целевая функция хуже порога
Acquisition function TPE — отношение:
TPE выбирает точки, где велико (параметры похожи на «хорошие»), а мало (параметры не похожи на «плохие»).
Почему TPE подходит для бэктестов:
- Работает с условными зависимостями между параметрами
- Не требует непрерывности целевой функции
- Эффективен при умеренном бюджете (100–1000 итераций)
- Поддерживает категориальные и дискретные параметры
Gaussian Process (GP)
Альтернатива TPE — Gaussian Process. GP моделирует как многомерный нормальный процесс и даёт не только прогноз значения, но и неопределённость в каждой точке.
где — среднее, — ковариационная функция (kernel).
GP хорош, когда:
- Параметров немного (до 10–15)
- Целевая функция гладкая
- Каждый прогон дорогой (минуты, часы)
Для бэктестов с предвычисленным Parquet-кэшем, где один прогон занимает ~1 секунду, TPE обычно предпочтительнее: он быстрее строит модель и лучше масштабируется на 500+ итераций.
Практическая интеграция с Optuna
Полный рабочий пример
import optuna
from optuna.samplers import TPESampler
import numpy as np
def run_backtest(htf_pre, mtf_pre, ltf_pre, **params) -> dict:
"""
Запускает бэктест с заданными параметрами.
Возвращает dict с метриками: pnl, max_dd, n_trades, trading_time, sharpe.
Использует предвычисленный Parquet-кэш — ~1 секунда на прогон.
"""
pass
def objective(trial: optuna.Trial) -> float:
"""Целевая функция для Optuna."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
study = optuna.create_study(
sampler=TPESampler(seed=42),
study_name="strategy_optimization",
direction="minimize",
)
study.optimize(objective, n_trials=500, show_progress_bar=True)
print(f"Best PnL: {-study.best_value:.2f}%")
print(f"Best params: {study.best_params}")
print(f"Total trials: {len(study.trials)}")
При скорости ~1 секунда на бэктест (с предвычисленным кэшем):
Восемь минут против 8 950 лет полного перебора. И при этом TPE в 500 итерациях находит комбинации, которые OAT пропускает за 96, потому что исследует пространство параметров одновременно, а не по одной оси.
Сохранение и возобновление исследования
import optuna
study = optuna.create_study(
storage="sqlite:///optuna_study.db",
study_name="strategy_v2",
sampler=TPESampler(seed=42),
direction="minimize",
load_if_exists=True, # продолжить, если исследование уже есть
)
study.optimize(objective, n_trials=300)
study.optimize(objective, n_trials=200)
Добавление ограничений
Не все комбинации параметров допустимы. Например, порог выхода не должен быть больше порога входа:
def objective_with_constraints(trial: optuna.Trial) -> float:
htf_entry = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
htf_exit = trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005)
if htf_exit > htf_entry:
raise optuna.TrialPruned()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
Сравнение сэмплеров
Optuna поддерживает несколько сэмплеров. Каждый имеет свои сильные стороны.
TPESampler (по умолчанию)
sampler = optuna.samplers.TPESampler(
n_startup_trials=20, # случайных проб перед началом моделирования
seed=42,
)
- Принцип: Tree-structured Parzen Estimator
- Сильные стороны: хорош для смешанных типов параметров, масштабируется до 1000+ итераций
- Слабые стороны: может быть менее эффективен при сильных взаимодействиях параметров
- Когда использовать: по умолчанию, если нет причин выбрать другой
CmaEsSampler
sampler = optuna.samplers.CmaEsSampler(seed=42)
- Принцип: Covariance Matrix Adaptation Evolution Strategy — эволюционный алгоритм, адаптирующий ковариационную матрицу
- Сильные стороны: отлично находит взаимодействия между непрерывными параметрами, учитывает корреляции
- Слабые стороны: не поддерживает категориальные параметры, требует больше итераций для инициализации
- Когда использовать: если все параметры непрерывные и вы подозреваете сильные взаимодействия
GPSampler
sampler = optuna.samplers.GPSampler(seed=42)
- Принцип: Gaussian Process с acquisition function
- Сильные стороны: лучшая sample efficiency (меньше итераций для хорошего результата), даёт оценку неопределённости
- Слабые стороны: по числу итераций — медленный при
- Когда использовать: если один бэктест дорогой (минуты) и бюджет ограничен 100–200 итерациями
RandomSampler (базовая линия)
sampler = optuna.samplers.RandomSampler(seed=42)
- Принцип: равномерная случайная выборка
- Сильные стороны: не застревает в локальных оптимумах, полное покрытие пространства
- Слабые стороны: не учитывает предыдущие результаты
- Когда использовать: как baseline для сравнения, или для разведочного анализа
QMCSampler
sampler = optuna.samplers.QMCSampler(seed=42)
- Принцип: Quasi-Monte Carlo (последовательности Sobol/Halton) — заполняет пространство равномернее, чем случайный сэмплер
- Сильные стороны: лучшее покрытие пространства, чем RandomSampler, воспроизводимость
- Слабые стороны: не адаптируется к результатам
- Когда использовать: для первых 50–100 итераций перед переключением на TPE
Сводная таблица
| Сэмплер | Тип | Взаимодействия | Категориальные | Лучший бюджет |
|---|---|---|---|---|
| TPE | Bayesian | Частично | Да | 100–1000 |
| CmaEs | Эволюционный | Да | Нет | 200–2000 |
| GP | Bayesian | Да | Ограничено | 50–200 |
| Random | Случайный | Нет | Да | Любой (baseline) |
| QMC | Квази-случайный | Нет | Нет | 50–500 |
Практический бенчмарк
import optuna
import time
def benchmark_sampler(sampler, n_trials=300):
"""Сравнение сэмплеров на одной задаче."""
study = optuna.create_study(sampler=sampler, direction="minimize")
start = time.time()
study.optimize(objective, n_trials=n_trials, show_progress_bar=False)
elapsed = time.time() - start
return {
"best_value": -study.best_value,
"elapsed_sec": elapsed,
"best_trial": study.best_trial.number,
}
samplers = {
"TPE": optuna.samplers.TPESampler(seed=42),
"CmaEs": optuna.samplers.CmaEsSampler(seed=42),
"GP": optuna.samplers.GPSampler(seed=42),
"Random": optuna.samplers.RandomSampler(seed=42),
"QMC": optuna.samplers.QMCSampler(seed=42),
}
for name, sampler in samplers.items():
result = benchmark_sampler(sampler, n_trials=300)
print(f"{name:8s}: best PnL={result['best_value']:.2f}%, "
f"found at trial #{result['best_trial']}, "
f"time={result['elapsed_sec']:.1f}s")
Типичные результаты для стратегии с 12 параметрами:
| Сэмплер | Best PnL | Найден на итерации | Overhead сэмплера |
|---|---|---|---|
| TPE | ~51% | ~180 | Низкий |
| CmaEs | ~49% | ~250 | Средний |
| GP | ~48% | ~90 | Высокий при |
| Random | ~42% | ~270 | Минимальный |
| QMC | ~43% | ~200 | Минимальный |
TPE и CmaEs стабильно обходят случайный поиск на 15–20% по итоговому PnL. GP находит хорошие результаты раньше, но упирается в вычислительный потолок при большом числе итераций.
Многокритериальная оптимизация: PnL vs MaxDD
Почему одного критерия недостаточно
Максимизация PnL без ограничений на просадку — путь к катастрофе. Стратегия с PnL +80% и MaxDD -30% при асимметрии убытков значительно рискованнее, чем стратегия с PnL +50% и MaxDD -5%.
Задача оптимизации на самом деле многокритериальная:
Эти цели конфликтуют: агрессивные параметры увеличивают и PnL, и просадку. Решение — не одна точка, а фронт Парето: множество решений, в которых нельзя улучшить одну метрику, не ухудшив другую.
NSGA-II / NSGA-III в Optuna
import optuna
def multi_objective(trial: optuna.Trial) -> tuple[float, float]:
"""Многокритериальная целевая функция: (PnL, MaxDD)."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
pnl = result["pnl"] # максимизируем
max_dd = result["max_dd"] # минимизируем (уже отрицательное число)
return pnl, max_dd # Optuna: оба направления задаются в create_study
study = optuna.create_study(
directions=["maximize", "minimize"],
sampler=optuna.samplers.NSGAIIISampler(seed=42),
study_name="multi_objective_strategy",
)
study.optimize(multi_objective, n_trials=500)
pareto_trials = study.best_trials
print(f"Pareto front: {len(pareto_trials)} solutions")
for t in pareto_trials[:5]:
print(f" PnL={t.values[0]:.2f}%, MaxDD={t.values[1]:.2f}%")
Выбор точки на фронте Парето
Фронт Парето даёт множество решений. Как выбрать одно?
def select_from_pareto(
pareto_trials: list,
max_dd_limit: float = -5.0,
min_pnl: float = 20.0,
) -> list:
"""
Фильтрация фронта Парето по ограничениям.
max_dd_limit: максимально допустимая просадка (например, -5%)
min_pnl: минимально приемлемый PnL (%)
"""
filtered = []
for trial in pareto_trials:
pnl, max_dd = trial.values
if max_dd >= max_dd_limit and pnl >= min_pnl:
max_lev = min(50 / abs(max_dd), 100) if max_dd != 0 else 100
pnl_at_max_lev = pnl * max_lev
filtered.append({
"trial": trial,
"pnl": pnl,
"max_dd": max_dd,
"max_lev": max_lev,
"pnl_at_max_lev": pnl_at_max_lev,
})
filtered.sort(key=lambda x: x["pnl_at_max_lev"], reverse=True)
return filtered
Обратите внимание: при расчёте PnL при максимальном плече необходимо учитывать funding rates, иначе теоретически высокий leverage обернётся убытком на реальном рынке. Кроме того, итоговый PnL — это single-point estimate, и для оценки устойчивости результата нужен Monte Carlo bootstrap.
Пример: три стратегии на фронте Парето
| Стратегия | PnL | MaxDD | MaxLev | PnL@MaxLev | Trading time |
|---|---|---|---|---|---|
| Strategy A | ~55% | ~0.9% | ~55x | ~3025% | ~15% |
| Strategy B | ~25% | ~0.75% | ~66x | ~1650% | ~5% |
| Strategy C | ~300% | ~17% | ~3x | ~900% | ~45% |
Strategy C с впечатляющим PnL +300% оказывается наименее привлекательной по PnL@MaxLev из-за высокой просадки. Strategy A лидирует по чистой доходности при плече, но с учётом PnL по активному времени Strategy B может оказаться предпочтительнее — 95% свободного времени можно заполнить другими стратегиями.
Contour plots и важность параметров

Визуализация ландшафта
После оптимизации — визуализация. Optuna предоставляет встроенные инструменты:
import optuna.visualization as vis
fig_contour = vis.plot_contour(
study,
params=["htf_entry_sell", "mtf_entry_sell"],
)
fig_contour.show()
fig_importance = vis.plot_param_importances(study)
fig_importance.show()
fig_history = vis.plot_optimization_history(study)
fig_history.show()
fig_parallel = vis.plot_parallel_coordinate(
study,
params=["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell"],
)
fig_parallel.show()
fig_slice = vis.plot_slice(study)
fig_slice.show()
Contour plot: читаем взаимодействия
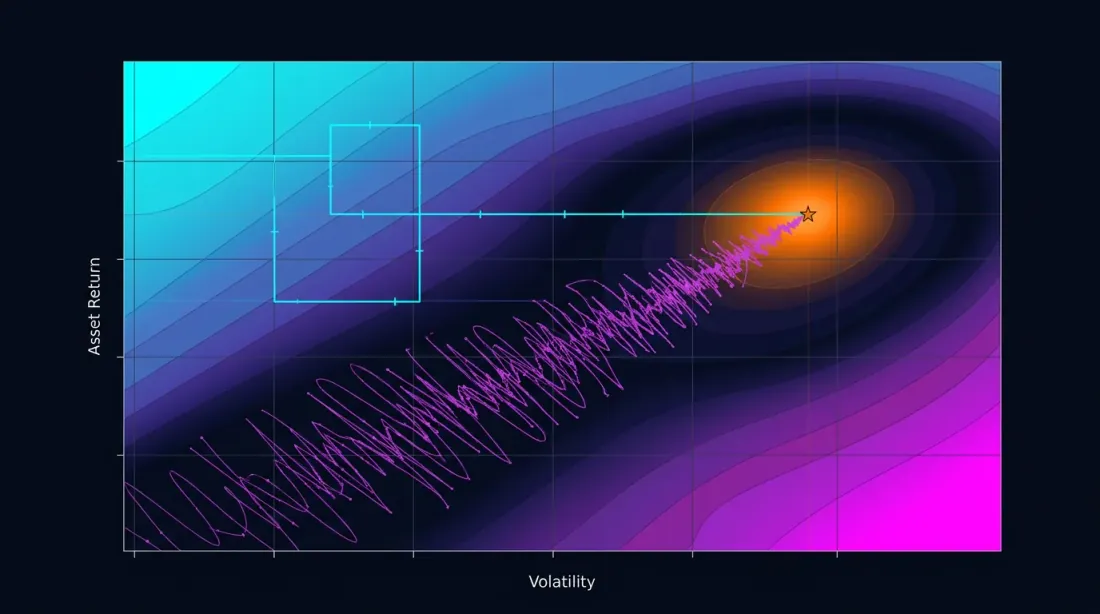
Contour plot строит двумерное сечение целевой функции для пары параметров. Если изолинии параллельны одной из осей — параметры не взаимодействуют, и OAT нашёл бы тот же оптимум. Если изолинии диагональные — взаимодействие есть, и OAT промахнётся.
key_params = ["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell",
"htf_entry_buy", "mtf_entry_buy", "ltf_entry_buy"]
for i, p1 in enumerate(key_params):
for p2 in key_params[i+1:]:
fig = vis.plot_contour(study, params=[p1, p2])
fig.write_image(f"contour_{p1}_vs_{p2}.png")
Если contour plot показывает плато — область, где целевая функция мало меняется — это хороший знак. Плато означает, что результат устойчив к небольшим отклонениям параметров. Подробнее об анализе плато и его связи с оверфиттингом — в готовящейся статье Plateau analysis.
Parameter importance
importance = optuna.importance.get_param_importances(study)
for param, imp in importance.items():
print(f"{param:20s}: {imp:.4f}")
Типичный вывод:
htf_entry_sell : 0.2841
mtf_entry_sell : 0.2103
ltf_entry_sell : 0.1567
trail_pct : 0.1204
htf_entry_buy : 0.0892
...
Параметры с importance < 0.01 можно зафиксировать на значении по умолчанию — это снизит размерность задачи и ускорит оптимизацию. Но будьте осторожны: низкая importance может означать и то, что параметр важен только во взаимодействии с другими. Проверяйте через contour plots.
Предвычисленный кэш: почему 1 секунда на бэктест меняет всё
Скорость одного бэктеста определяет, какой метод оптимизации вы можете себе позволить.
| Время бэктеста | 96 OAT | 500 TPE | 2000 CmaEs |
|---|---|---|---|
| 60 секунд | 1.6 часа | 8.3 часа | 33 часа |
| 10 секунд | 16 минут | 83 минуты | 5.5 часов |
| 1 секунда | 1.5 минуты | 8 минут | 33 минуты |
| 0.1 секунды | 10 секунд | 50 секунд | 3.3 минуты |
При 60 секундах на бэктест 500 итераций TPE — это 8 часов. Уже терпимо, но итерировать (изменить целевую функцию, перезапустить) дорого. При 1 секунде — 8 минут, и можно запускать десятки экспериментов за день.
Именно поэтому предвычисление в Parquet-кэш — не просто оптимизация скорости, а расширение пространства доступных методов. Без кэша вы ограничены OAT или 100 итерациями GP. С кэшем — можете позволить себе 2000 итераций CmaEs или полноценный multi-objective NSGA-III.
import pyarrow.parquet as pq
import time
t0 = time.time()
htf_pre = pq.read_table("cache/htf_indicators.parquet").to_pandas()
mtf_pre = pq.read_table("cache/mtf_indicators.parquet").to_pandas()
ltf_pre = pq.read_table("cache/ltf_indicators.parquet").to_pandas()
print(f"Cache loaded in {time.time() - t0:.2f}s") # ~0.3s
t1 = time.time()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, htf_entry_sell=0.02, ...)
print(f"Backtest in {time.time() - t1:.2f}s") # ~1.0s
Практические рекомендации
Когда использовать OAT
OAT оправдан в следующих случаях:
-
Разведочный анализ. Вы только начинаете исследовать стратегию и хотите понять, какие параметры вообще влияют на результат. 96 прогонов за 1.5 минуты — отличная отправная точка.
-
Аддитивные параметры. Для параметров, которые работают на непересекающихся подмножествах сделок (sell vs buy направления, разные инструменты), OAT даст корректный результат быстрее.
-
Очень дорогой бэктест. Если один прогон занимает 10+ минут и ускорить его невозможно, OAT с 96 прогонами (16 часов) предпочтительнее 500 итераций TPE (3.5 дня).
Когда использовать Optuna
Optuna предпочтительнее в большинстве случаев:
-
Больше 3 параметров. Взаимодействия практически гарантированы — OAT пропустит оптимум.
-
Мультитаймфрейм-стратегии. Пороги на разных таймфреймах почти всегда взаимосвязаны.
-
Финальная оптимизация. Когда стратегия прошла Monte Carlo bootstrap и вы уверены в её робастности — Optuna найдёт лучшие параметры.
-
Многокритериальная задача. PnL vs MaxDD vs trading time — OAT не может решить эту задачу в принципе.
Гибридный подход: OAT для аддитивных + Optuna для связанных
Не обязательно выбирать между OAT и Optuna — лучше комбинировать:
-
Классифицируйте параметры. Разделите на аддитивные (независимые) и связанные (интерактивные). Пример для 12 separation-параметров:
- Аддитивные:
htf_entry_sell↔htf_entry_buy,mtf_entry_sell↔mtf_entry_buy,ltf_entry_sell↔ltf_entry_buy(sell/buy — разные направления, работают на непересекающихся сделках) - Связанные группа sell:
htf_entry_sell,mtf_entry_sell,ltf_entry_sell(цепочка фильтрации: HTF → MTF → LTF для sell-сигналов) - Связанные группа buy:
htf_entry_buy,mtf_entry_buy,ltf_entry_buy
- Аддитивные:
-
OAT для аддитивных. Оптимизируйте sell- и buy-группы независимо. Если sell-параметры не влияют на buy-сделки — OAT даст корректный результат за минуты.
-
Optuna для связанных. Внутри каждой группы (sell: 6 параметров entry+exit) используйте TPE. 6 параметров вместо 12 — бюджет сокращается вдвое.
sell_params = oat_sweep(sell_param_grid, run_backtest, initial_params)
def objective_sell(trial):
params = sell_params.copy()
params["htf_entry_sell"] = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
params["mtf_entry_sell"] = trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005)
params["ltf_entry_sell"] = trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005)
params["htf_exit_sell"] = trial.suggest_float("htf_exit_sell", 0.0, 0.02, step=0.001)
params["mtf_exit_sell"] = trial.suggest_float("mtf_exit_sell", 0.0, 0.02, step=0.001)
params["ltf_exit_sell"] = trial.suggest_float("ltf_exit_sell", 0.0, 0.02, step=0.001)
return -run_backtest(**params)["effective_score"]
study = optuna.create_study(sampler=optuna.samplers.TPESampler())
study.optimize(objective_sell, n_trials=300) # 6 параметров → 300 достаточно
Полный пайплайн оптимизации
1. Предвычислить Parquet-кэш (один раз)
2. Классифицировать параметры: аддитивные vs связанные
3. OAT для аддитивных (~50 прогонов, ~1 мин) → зафиксировать
4. Optuna TPE для связанных групп (300 итераций × 2 группы, ~10 мин)
5. Optuna NSGA-III для мета-параметров (500 итераций, ~8 мин) → фронт Парето
6. Contour plots → визуализировать взаимодействия
7. Monte Carlo bootstrap лучших точек → confidence intervals
8. Walk-Forward → проверка на out-of-sample
Шаг 8 — walk-forward оптимизация — критически важен для защиты от оверфиттинга. Подробнее об этом — в готовящейся статье Walk-Forward.
Ловушки при оптимизации
Оверфиттинг. Чем больше параметров и чем точнее оптимизация — тем выше риск подогнать стратегию под исторические данные. 500 итераций Optuna с 12 параметрами найдут комбинацию, идеально работающую на обучающей выборке, но бесполезную на новых данных.
Защита:
- Разделяйте данные на train/test (70/30)
- Используйте Monte Carlo bootstrap для оценки устойчивости
- Проверяйте через walk-forward
- Предпочитайте решения на плато (об этом — в Plateau analysis)
Multiple comparisons problem. Если вы тестируете 500 комбинаций, вероятность случайно найти «хороший» результат растёт. Поправка Бонферрони или контроль FDR (False Discovery Rate) помогают, но проще — валидация на out-of-sample.
Недостаточный бюджет. TPE с 50 итерациями при 12 параметрах — это мало. Первые 20 итераций — случайные (startup), остаётся всего 30 для моделирования. Минимальный бюджет: итераций для 12 параметров, рекомендуемый: .
Freqtrade: как это устроено в production-фреймворке

Freqtrade — один из популярных фреймворков для алготрейдинга — использует Optuna под капотом через модуль Hyperopt. Его опыт подтверждает наши рекомендации:
- Сэмплеры: TPE (по умолчанию), GP, CmaEs, NSGA-II, QMC — все доступны через конфигурацию
- Loss functions: 12 встроенных функций потерь, включая ShortTradeDurHyperOptLoss, SharpeHyperOptLoss, MaxDrawDownHyperOptLoss
- Multi-objective: поддержка NSGA-II и NSGA-III для одновременной оптимизации нескольких метрик
- Custom samplers: возможность подключить любой Optuna-совместимый сэмплер
Ключевой урок из экосистемы Freqtrade: встроенные loss functions покрывают типовые сценарии, но для серьёзной оптимизации нужна кастомная целевая функция, учитывающая специфику вашей стратегии — активное время, funding costs, adaptive drill-down для точного fill simulation.
Заключение

Координатный спуск (OAT) — быстрый и интуитивно понятный метод. Для 12 параметров он требует всего 96 прогонов и работает за полторы минуты. Но он слеп к взаимодействиям параметров — а в мультитаймфрейм-стратегиях взаимодействия есть почти всегда.
Bayesian optimization через Optuna (TPE, GP, CmaEs) исследует пространство параметров целиком. 500 итераций за 8 минут — с предвычисленным Parquet-кэшем — находят комбинации, невидимые для OAT.
Многокритериальная оптимизация (NSGA-III) превращает задачу «максимизировать PnL» в задачу «построить фронт Парето PnL vs MaxDD» — и даёт набор решений с разным балансом доходности и риска.
Но оптимизация — это лишь часть пайплайна. Найденные параметры нужно проверить через Monte Carlo bootstrap, скорректировать на funding rates, пересчитать с учётом активного времени, и провести через walk-forward validation. Об этом — в следующих статьях серии.
Полезные ссылки
- Optuna: A Next-generation Hyperparameter Optimization Framework (Akiba et al., 2019)
- Algorithms for Hyper-Parameter Optimization (Bergstra et al., 2011) — оригинальная статья о TPE
- Optuna Documentation — Samplers
- Optuna Visualization Module
- Hansen, N. — The CMA Evolution Strategy: A Tutorial
- Deb, K. et al. — NSGA-II: A Fast and Elitist Multiobjective Genetic Algorithm (2002)
- Snoek, J. et al. — Practical Bayesian Optimization of Machine Learning Algorithms (2012)
- Freqtrade Documentation — Hyperopt
- Marcos Lopez de Prado — Advances in Financial Machine Learning, Chapter 12
- Bergstra, J. & Bengio, Y. — Random Search for Hyper-Parameter Optimization (2012)
Цитирование
@article{soloviov2026optuna,
author = {Soloviov, Eugen},
title = {Координатный спуск vs Bayesian optimization: что находит лучшие параметры},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/optuna-vs-coordinate-descent},
description = {Почему полный перебор невозможен для 12+ параметров, как координатный спуск пропускает взаимодействия, и как Optuna с TPE-сэмплером за 500 итераций находит то, что OAT не может за 96.}
}
MarketMaker.cc Team
Количественные исследования и стратегии
Читайте также

Adaptive drill-down: бэктест с переменной гранулярностью от минут до сырых сделок

Агрегированный Parquet-кэш: как ускорить мультитаймфрейм-бэктест в сотни раз
