Monte Carlo Bootstrap: วิธีรับช่วงความเชื่อมั่นสำหรับ Backtest ใน 10 บรรทัดของโค้ด
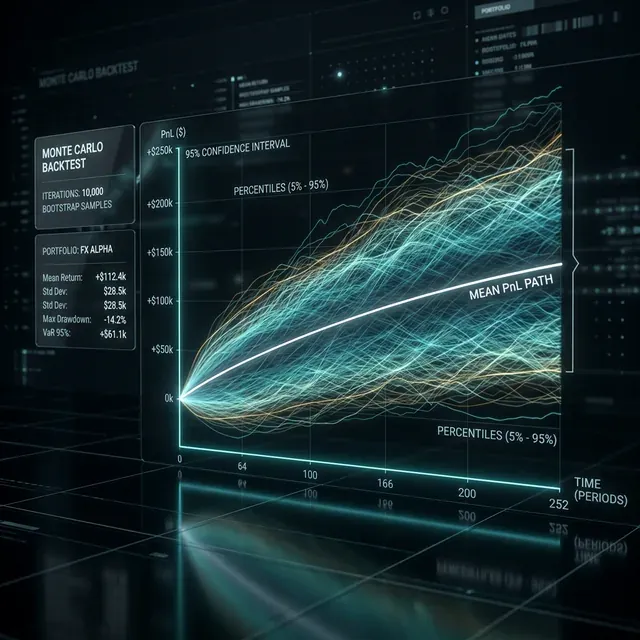
คุณรันกลยุทธ์ผ่าน backtest แล้วได้ PnL +42%, Sharpe 1.8, MaxDD -12% ผลลัพธ์ดูยอดเยี่ยม คุณเปิดบอทในการซื้อขายจริง และหนึ่งเดือนต่อมาพบว่า drawdown อยู่ที่ -28% แล้ว และ PnL กำลังมุ่งหน้าสู่ศูนย์
เกิดอะไรขึ้น? ไม่ใช่บั๊ก และไม่ใช่ "ตลาดที่เปลี่ยนแปลง" ปัญหาคือคุณตัดสินใจโดยอิงจาก ตัวเลขเดียว — การประมาณค่าจุดเดียว คุณรู้ว่ากลยุทธ์ แสดงผล +42% แต่คุณไม่รู้ว่า จะเชื่อถือตัวเลขนั้นได้มากแค่ไหน
ปัญหาของการประมาณค่าจุดเดียว
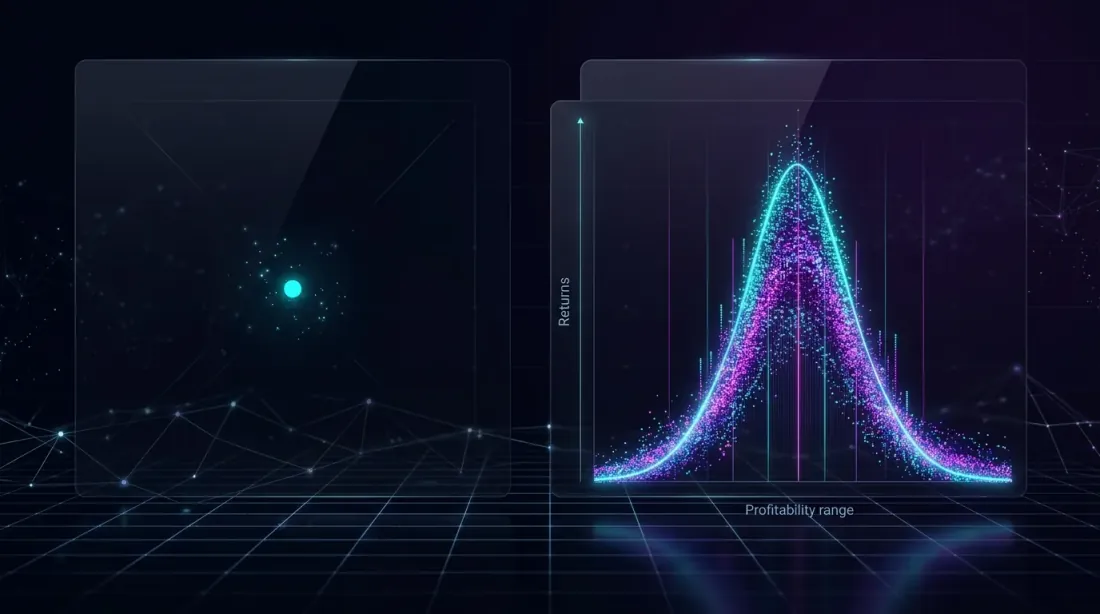 จุดข้อมูลเดียว (ซ้าย) ให้ภาพที่เข้าใจผิด ในขณะที่การกระจายแบบเต็ม (ขวา) เผยให้เห็นช่วงผลลัพธ์ที่แท้จริง
จุดข้อมูลเดียว (ซ้าย) ให้ภาพที่เข้าใจผิด ในขณะที่การกระจายแบบเต็ม (ขวา) เผยให้เห็นช่วงผลลัพธ์ที่แท้จริง
การ backtest บนข้อมูลประวัติศาสตร์คือการรันผ่านลำดับเหตุการณ์ตลาดเฉพาะหนึ่งครั้ง ผลลัพธ์ขึ้นอยู่กับลำดับการซื้อขาย: กลยุทธ์เดียวกันกับการซื้อขายเดียวกัน แต่ในลำดับที่แตกต่างกัน อาจแสดง maximum drawdown ที่แตกต่างกันโดยสิ้นเชิง
ลองนึกภาพการซื้อขาย 491 ครั้ง การซื้อขายแต่ละครั้งเป็นเหตุการณ์สุ่มที่มีการกระจายผลตอบแทนบางอย่าง backtest ประวัติศาสตร์แสดงเพียง การรับรู้เดียว ของกระบวนการนี้ มันเหมือนกับการทอยลูกเต๋าครั้งเดียวแล้วสรุปว่าลูกเต๋าจะออกสี่เสมอ
สิ่งที่เราต้องการจริงๆ:
- ไม่ใช่การประมาณค่าจุด แต่เป็น ช่วง: "ด้วยความน่าจะเป็น 95%, PnL สุดท้ายจะอยู่ระหว่าง X และ Y"
- ไม่ใช่ maximum drawdown เดียว แต่เป็น การกระจาย: "ใน 5% ของสถานการณ์เลวร้ายที่สุด drawdown เกิน Z%"
- ไม่ใช่ค่าเฉลี่ย แต่เป็น ปลายหาง: จะเกิดอะไรขึ้นถ้าโชคไม่เข้าข้างคุณ?
นี่คือจุดประสงค์ของ Monte Carlo bootstrap
Monte Carlo Bootstrap คืออะไร
 Bootstrap สร้างเส้นทาง equity ทางเลือกหลายพันเส้นโดยการสุ่มตัวอย่างการซื้อขายซ้ำจากชุดข้อมูลเดิม
Bootstrap สร้างเส้นทาง equity ทางเลือกหลายพันเส้นโดยการสุ่มตัวอย่างการซื้อขายซ้ำจากชุดข้อมูลเดิม
Bootstrap เป็นวิธีการสุ่มตัวอย่างใหม่ที่เสนอโดย Bradley Efron ในปี 1979 แนวคิดนี้สง่างาม: ถ้าเรามีตัวอย่างข้อมูล เราสามารถสร้างตัวอย่าง "ใหม่" หลายพันตัวอย่างโดยการสุ่มเลือกองค์ประกอบจากต้นฉบับ พร้อมการเปลี่ยนทดแทน
ในบริบทของ backtest มันทำงานดังนี้:
- คุณมีอาร์เรย์ผลตอบแทนสำหรับการซื้อขายแต่ละครั้ง — เช่น 491 ค่า
- คุณสุ่มเลือก 491 ค่าจากอาร์เรย์นี้ พร้อมการเปลี่ยนทดแทน — การซื้อขายบางอย่างจะปรากฏสองครั้ง บางอย่างจะไม่ปรากฏเลย
- คุณสร้างเส้น equity จากตัวอย่างใหม่นี้
- คุณทำซ้ำ 10,000 ครั้ง
- คุณได้รับ การกระจาย ของตัวชี้วัดสุดท้าย ไม่ใช่ตัวเลขเดียว
การวนซ้ำแต่ละครั้งคือ "สถานการณ์ทางเลือก" หนึ่ง: สิ่งที่ อาจเกิดขึ้น หากลำดับและชุดการซื้อขายแตกต่างออกไปเล็กน้อย
การนำไปใช้ใน 10 บรรทัด
นี่คือการนำไปใช้งานที่สมบูรณ์:
import numpy as np
def max_drawdown(equity_curve):
"""Calculate the maximum drawdown of an equity curve."""
peak = np.maximum.accumulate(equity_curve)
drawdown = (equity_curve - peak) / peak
return drawdown.min()
trade_returns = [...] # 491 values, e.g. [0.012, -0.005, 0.008, ...]
n_simulations = 10000
results = []
for _ in range(n_simulations):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
results.append({
"final_pnl": equity[-1] - 1,
"max_dd": max_drawdown(equity),
"sharpe": np.mean(sampled) / np.std(sampled) * np.sqrt(252)
})
เวลาดำเนินการ: ~2 วินาที บนแล็ปท็อปทั่วไป ประวัติศาสตร์ทางเลือก 10,000 รายการของกลยุทธ์ของคุณ
การสกัดช่วงความเชื่อมั่น
 ช่วงความเชื่อมั่นสำหรับตัวชี้วัดกลยุทธ์หลัก: PnL, MaxDD และ Sharpe Ratio แสดงแถบเปอร์เซ็นไทล์ที่ 5 (แย่ที่สุด), 50 (มัธยฐาน) และ 95 (ดีที่สุด)
ช่วงความเชื่อมั่นสำหรับตัวชี้วัดกลยุทธ์หลัก: PnL, MaxDD และ Sharpe Ratio แสดงแถบเปอร์เซ็นไทล์ที่ 5 (แย่ที่สุด), 50 (มัธยฐาน) และ 95 (ดีที่สุด)
ตอนนี้เรามีไม่ใช่ตัวเลขเดียว แต่เป็นการกระจาย นี่คือวิธีสกัดข้อมูลที่มีประโยชน์จากมัน:
import pandas as pd
df = pd.DataFrame(results)
pnl_5 = np.percentile(df['final_pnl'], 5)
pnl_50 = np.percentile(df['final_pnl'], 50)
pnl_95 = np.percentile(df['final_pnl'], 95)
dd_5 = np.percentile(df['max_dd'], 5) # 5th — worst case
dd_50 = np.percentile(df['max_dd'], 50)
dd_95 = np.percentile(df['max_dd'], 95) # 95th — best case
print(f"PnL: {pnl_5:.1%} | {pnl_50:.1%} | {pnl_95:.1%}")
print(f"MaxDD: {dd_5:.1%} | {dd_50:.1%} | {dd_95:.1%}")
print(f"Sharpe: {np.percentile(df['sharpe'], 5):.2f} — {np.percentile(df['sharpe'], 95):.2f}")
ตัวอย่างผลลัพธ์สำหรับกลยุทธ์จริง:
| ตัวชี้วัด | เปอร์เซ็นไทล์ที่ 5 (แย่ที่สุด) | มัธยฐาน | เปอร์เซ็นไทล์ที่ 95 (ดีที่สุด) |
|---|---|---|---|
| PnL | +18.3% | +41.7% | +72.1% |
| MaxDD | -23.4% | -12.8% | -5.1% |
| Sharpe | 1.12 | 1.76 | 2.41 |
ตอนนี้ความแตกต่างชัดเจน:
- backtest แสดง PnL +42% — แต่ใน 5% ของสถานการณ์ แย่ที่สุด PnL อยู่ที่ +18.3% เท่านั้น
- backtest แสดง MaxDD -12% — แต่ใน 5% ของสถานการณ์ แย่ที่สุด drawdown คือ -23.4%
- Sharpe 1.8 — แต่ขอบล่างคือ 1.12
เปอร์เซ็นไทล์ที่ 5 คือ "กรณีเลวร้ายที่สมจริง" ของคุณ ถ้ากลยุทธ์หยุดทำกำไรที่เปอร์เซ็นไทล์ที่ 5 การนำไปใช้งานจริงมีความเสี่ยง
การแสดงภาพ: Fan Chart
Monte Carlo bootstrap แสดงภาพได้อย่างเป็นธรรมชาติในรูปแบบ fan chart — พัดของเส้น equity:
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
ax = axes[0]
for i in range(min(500, n_simulations)):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
ax.plot(equity, alpha=0.02, color='#4FC3F7')
all_equities = []
for _ in range(n_simulations):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
all_equities.append(equity)
all_equities = np.array(all_equities)
p5 = np.percentile(all_equities, 5, axis=0)
p50 = np.percentile(all_equities, 50, axis=0)
p95 = np.percentile(all_equities, 95, axis=0)
ax.fill_between(range(len(p5)), p5, p95, alpha=0.3, color='#7C4DFF', label='90% CI')
ax.plot(p50, color='#E040FB', linewidth=2, label='Median')
ax.set_title('Monte Carlo Bootstrap: Equity Curves')
ax.legend()
ax = axes[1]
ax.hist(df['final_pnl'] * 100, bins=80, color='#4FC3F7', alpha=0.7, edgecolor='#1A237E')
ax.axvline(pnl_5 * 100, color='#FF5252', linestyle='--', label=f'5th: {pnl_5:.1%}')
ax.axvline(pnl_50 * 100, color='#E040FB', linestyle='--', label=f'Median: {pnl_50:.1%}')
ax.axvline(pnl_95 * 100, color='#69F0AE', linestyle='--', label=f'95th: {pnl_95:.1%}')
ax.set_title('Distribution of Final PnL')
ax.set_xlabel('PnL, %')
ax.legend()
plt.tight_layout()
plt.savefig('monte_carlo_fan_chart.png', dpi=150)
plt.show()
Fan chart ให้ความเข้าใจที่ใช้งานง่ายเกี่ยวกับ การกระจาย ของผลลัพธ์ที่เป็นไปได้ พัดแคบหมายความว่ากลยุทธ์มีเสถียรภาพ พัดกว้างหมายความว่าผลลัพธ์ขึ้นอยู่กับ "โชค" กับลำดับการซื้อขายอย่างมาก
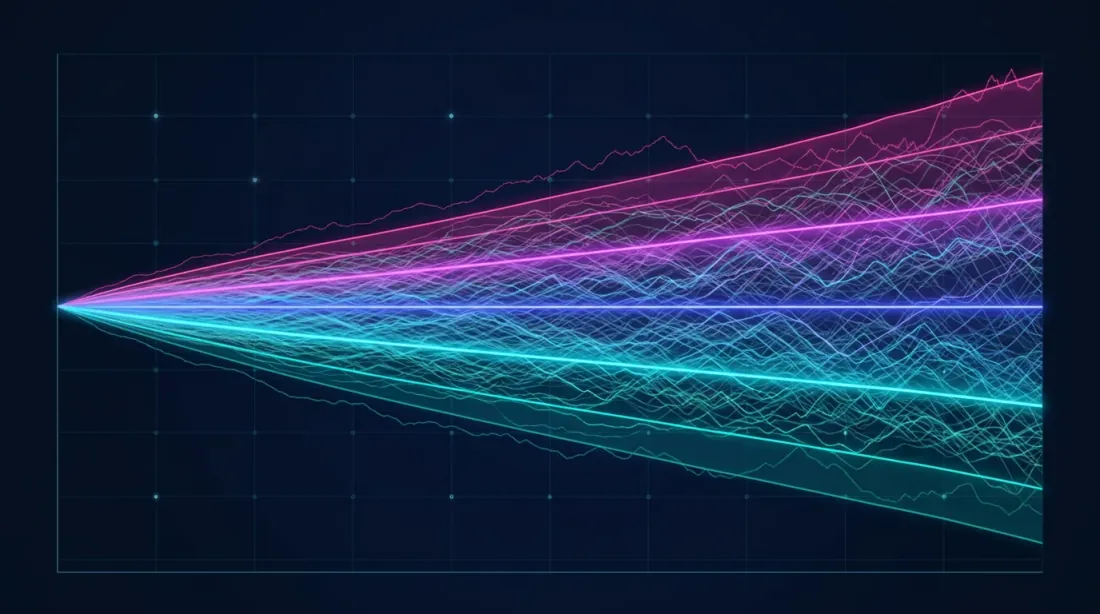 Fan chart (ซ้าย) แสดงการกระจายของเส้นทาง equity ที่เป็นไปได้ และ histogram (ขวา) แสดงการกระจายความหนาแน่นของผลตอบแทนสุดท้ายพร้อมช่วงความเชื่อมั่นที่เน้น (5%, 50%, 95%)
Fan chart (ซ้าย) แสดงการกระจายของเส้นทาง equity ที่เป็นไปได้ และ histogram (ขวา) แสดงการกระจายความหนาแน่นของผลตอบแทนสุดท้ายพร้อมช่วงความเชื่อมั่นที่เน้น (5%, 50%, 95%)
การวิเคราะห์ขั้นสูง: ความน่าจะเป็นของการล้มละลาย
 การแสดงภาพความน่าจะเป็นของการล้มละลาย: เส้นทาง equity ที่รอด (ฟ้า) โค้งขึ้น ในขณะที่เส้นทางที่ล้มละลาย (แดง) ดิ่งลงต่ำกว่าขอบ equity ศูนย์
การแสดงภาพความน่าจะเป็นของการล้มละลาย: เส้นทาง equity ที่รอด (ฟ้า) โค้งขึ้น ในขณะที่เส้นทางที่ล้มละลาย (แดง) ดิ่งลงต่ำกว่าขอบ equity ศูนย์
Bootstrap ช่วยให้คุณตอบคำถามสำคัญ: ความน่าจะเป็นที่กลยุทธ์จะสูญเสียทุน X% คือเท่าไร?
ruin_threshold = -0.20
prob_ruin = (df['max_dd'] < ruin_threshold).mean()
print(f"P(MaxDD < -20%) = {prob_ruin:.1%}")
prob_loss = (df['final_pnl'] < 0).mean()
print(f"P(PnL < 0) = {prob_loss:.1%}")
worst_5pct = df['final_pnl'].quantile(0.05)
cvar = df[df['final_pnl'] <= worst_5pct]['final_pnl'].mean()
print(f"CVaR(5%) = {cvar:.1%}")
ตัวชี้วัดเหล่านี้ เป็นไปไม่ได้ ที่จะได้รับจากการรัน backtest ครั้งเดียว แต่มีความสำคัญอย่างยิ่งสำหรับการตัดสินใจเปิดตัวกลยุทธ์
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับเหตุใด drawdown ที่ลึกจึงอันตรายทางคณิตศาสตร์และความไม่สมมาตรของผลตอบแทนทำงานอย่างไร อ่านบทความของเรา ความไม่สมมาตรของการสูญเสีย-กำไร
เมื่อ Classical Bootstrap ไม่ทำงาน
วิธีการนี้มีข้อจำกัดที่สำคัญที่ต้องรู้
Autocorrelation ของผลตอบแทน
Classical bootstrap สมมติว่าการซื้อขายเป็น อิสระ ในความเป็นจริง มักไม่เป็นเช่นนั้น — กลยุทธ์อาจมีช่วงที่ชนะและแพ้ต่อเนื่อง ถ้า autocorrelation มีนัยสำคัญ ให้ใช้ block bootstrap:
def block_bootstrap(returns, block_size=10, n_simulations=10000):
"""Bootstrap preserving local dependency structure."""
n = len(returns)
results = []
for _ in range(n_simulations):
starts = np.random.randint(0, n - block_size + 1, size=n // block_size + 1)
sampled = np.concatenate([returns[s:s+block_size] for s in starts])[:n]
equity = np.cumprod(1 + sampled)
results.append({
"final_pnl": equity[-1] - 1,
"max_dd": max_drawdown(equity),
})
return pd.DataFrame(results)
Block bootstrap รักษาความสัมพันธ์ท้องถิ่นระหว่างการซื้อขายที่ต่อเนื่องกัน โดยให้ช่วงความเชื่อมั่นที่สมจริงยิ่งขึ้นสำหรับ MaxDD
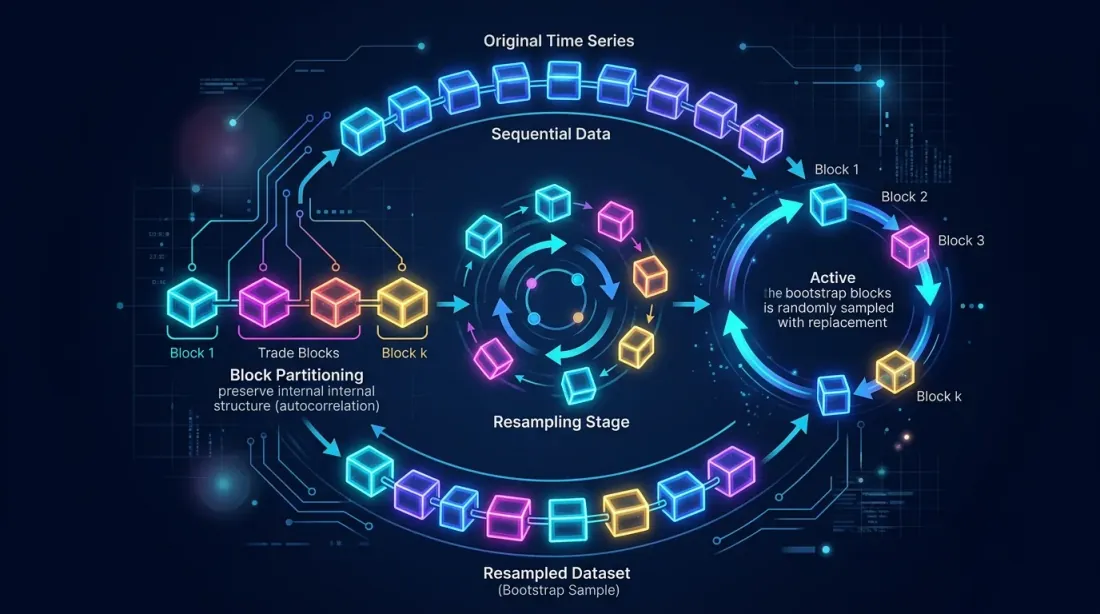 Block bootstrap รักษา autocorrelation ภายในบล็อกโดยแบ่งลำดับการซื้อขายออกเป็นบล็อกและสุ่มตัวอย่างพร้อมการเปลี่ยนทดแทน
Block bootstrap รักษา autocorrelation ภายในบล็อกโดยแบ่งลำดับการซื้อขายออกเป็นบล็อกและสุ่มตัวอย่างพร้อมการเปลี่ยนทดแทน
ความไม่หยุดนิ่งของตลาด
Bootstrap ทำงานกับการกระจายการซื้อขายเดิม ถ้าตลาดเปลี่ยนแปลงเชิงโครงสร้าง (เช่น ความผันผวนลดลงหรือสภาพคล่องเปลี่ยนแปลง) การซื้อขายในอดีตอาจไม่เป็นตัวแทนที่ดี เพื่อพิจารณาเรื่องนี้:
- ใช้ rolling window: bootstrap เฉพาะการซื้อขาย N ครั้งล่าสุด
- ให้น้ำหนักการซื้อขายล่าสุดมากขึ้น: weighted bootstrap
- แบ่งข้อมูลตามระบอบตลาดและ bootstrap แยกกัน
จำนวนการซื้อขายน้อย
Bootstrap เชื่อถือได้เมื่อ n > 30 การซื้อขาย ถ้าคุณมี 10 การซื้อขาย การสุ่มตัวอย่างใหม่ไม่ว่าจะมากแค่ไหนก็ไม่ช่วย 491 การซื้อขายเป็นตัวอย่างที่ดีเยี่ยม คุณสามารถเชื่อถือผลลัพธ์ได้
การเปรียบเทียบแนวทางการประเมินความแข็งแกร่งของ Backtest
| วิธีการ | สิ่งที่ให้ | ความซับซ้อน | เวลา | เมื่อใดใช้ |
|---|---|---|---|---|
| Backtest เดียว | การประมาณค่าจุดเดียว | น้อยที่สุด | วินาที | ไม่ควรใช้เป็นผลลัพธ์สุดท้าย |
| Walk-forward | ตัวชี้วัด out-of-sample | ปานกลาง | นาที | เพื่อตรวจสอบ overfitting |
| Monte Carlo bootstrap | ช่วงความเชื่อมั่น | น้อยที่สุด | ~2 วินาที | เสมอ ก่อน production |
| Monte Carlo path | เส้นทางราคาใหม่ | สูง | นาที-ชั่วโมง | สำหรับ stress testing |
| Cross-validation | ตัวชี้วัดเฉลี่ยข้าม fold | ปานกลาง | นาที | สำหรับการปรับพารามิเตอร์ |
Monte Carlo bootstrap เป็นวิธีเดียวที่ในเวลาน้อยที่สุดให้ ภาพรวมความเสี่ยงที่สมบูรณ์
Checklist: การตีความผลลัพธ์
นี่คือวิธีที่เราแนะนำในการตีความผลลัพธ์ Monte Carlo bootstrap:
เปิดใช้งานใน production ถ้า:
- PnL ที่เปอร์เซ็นไทล์ที่ 5 เป็น บวก
- MaxDD ที่เปอร์เซ็นไทล์ที่ 5 ยอมรับได้ สำหรับความเบี่ยงเบนความเสี่ยงของคุณ
- ความน่าจะเป็นของการล้มละลาย < 1%
- Sharpe ที่เปอร์เซ็นไทล์ที่ 5 > 0.5
ต้องปรับปรุง ถ้า:
- PnL ที่เปอร์เซ็นไทล์ที่ 5 ใกล้ศูนย์
- MaxDD ที่เปอร์เซ็นไทล์ที่ 5 แย่กว่าที่ 50 อย่างมีนัยสำคัญ
- การกระจาย fan chart กว้าง — กลยุทธ์ไม่มีเสถียรภาพ
อย่าเปิดใช้งาน ถ้า:
- PnL ที่เปอร์เซ็นไทล์ที่ 5 เป็น ลบ
- ความน่าจะเป็นของการล้มละลาย > 5%
- ช่วงความเชื่อมั่นของ Sharpe รวม 0
ประสบการณ์ของเราที่ marketmaker.cc
ที่ marketmaker.cc เราพัฒนา backtest engine ของเราเอง และ Monte Carlo bootstrap เป็นส่วนสำคัญของ pipeline ของเรา ทุกกลยุทธ์ผ่าน bootstrap โดยอัตโนมัติ ก่อนได้รับอนุมัติสำหรับการซื้อขายสด
เรารวม bootstrap เข้ากับ backtest engine โดยตรง: หลังจากการรัน คุณจะได้รับไม่เพียงแค่ PnL สุดท้าย แต่รายงานครบถ้วนพร้อมช่วงความเชื่อมั่น fan chart ความน่าจะเป็นของการล้มละลาย และการเปรียบเทียบ block vs. standard bootstrap ซึ่งใช้เวลาเพิ่มเติม 2-3 วินาที — ราคาที่ไม่สำคัญสำหรับการทำความเข้าใจความเสี่ยงที่แท้จริง
จากประสบการณ์ของเรา: ประมาณ 30% ของกลยุทธ์ ที่ดูน่าสนใจจากการประมาณค่าจุดเดียวถูกกรองออกหลัง Monte Carlo bootstrap PnL ที่เปอร์เซ็นไทล์ที่ 5 ของพวกเขากลายเป็นลบ หรือ MaxDD กลายเป็นสิ่งที่ยอมรับไม่ได้ หากไม่มี bootstrap กลยุทธ์เหล่านี้จะไปถึง production และมีแนวโน้มสูงมากที่จะส่งผลให้เกิดการขาดทุน
สรุป
Monte Carlo bootstrap คือโค้ดประมาณ 10 บรรทัดและการคำนวณประมาณ 2 วินาที มันแปลงตัวเลขเดียวจาก backtest ให้กลายเป็นการกระจายแบบเต็มพร้อมช่วงความเชื่อมั่น นี่คือ ROI สูงสุดของเครื่องมือการวิเคราะห์เชิงปริมาณ:
- ต้นทุนน้อยที่สุด: การนำไปใช้ภายใน 30 นาที
- ผลตอบแทนสูงสุด: ความเข้าใจความเสี่ยงกลยุทธ์ที่แท้จริง
- ไม่มี dependencies: ต้องการเพียง NumPy
ถ้าคุณยังไม่ใช้ bootstrap — เพิ่มลงใน pipeline ของคุณวันนี้ มันเป็นวิธีเดียวที่จะรู้ว่าคุณสามารถเชื่อถือผลลัพธ์ backtest ของคุณได้มากแค่ไหน
อ้างอิง
- Efron, B. — Bootstrap Methods: Another Look at the Jackknife (1979)
- Davison, A.C., Hinkley, D.V. — Bootstrap Methods and their Application (Cambridge)
- Aronson, D.R. — Evidence-Based Technical Analysis: Monte Carlo permutation
- QuantStart — Monte Carlo Simulation for Backtest Analysis
- Marcos Lopez de Prado — Advances in Financial Machine Learning, Chapter 12: Backtesting
- Kevin Davey — Building Winning Algorithmic Trading Systems: Monte Carlo Analysis
- NumPy — numpy.random.choice
การอ้างอิง
@software{soloviov2026montecarlobootstrap,
author = {Soloviov, Eugen},
title = {Monte Carlo Bootstrap: How to Get Confidence Intervals for a Backtest in 10 Lines of Code},
year = {2026},
url = {https://marketmaker.cc/th/blog/post/monte-carlo-bootstrap-backtest},
version = {0.1.0},
description = {เหตุใดการประมาณค่าจุดเดียวจาก backtest จึงเป็นภาพลวงตาที่อันตราย Monte Carlo bootstrap ใช้เวลาคำนวณ 2 วินาที ให้ช่วงความเชื่อมั่น 95\% สำหรับ PnL และ MaxDD และเหตุใดขั้นตอนนี้จึงเป็นสิ่งบังคับก่อนนำกลยุทธ์ไปใช้งานจริง}
}
ผู้เขียน

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
อ่านเพิ่มเติม

PnL ตามเวลาที่ใช้งาน: ตัวชี้วัดที่เปลี่ยนการจัดอันดับกลยุทธ์

Adaptive Drill-Down: แบ็คเทสต์ด้วยความละเอียดข้อมูลแบบยืดหยุ่น ตั้งแต่นาทีจนถึงการเทรดดิบ
