Adaptive Drill-Down: แบ็คเทสต์ด้วยความละเอียดข้อมูลแบบยืดหยุ่น ตั้งแต่นาทีจนถึงการเทรดดิบ
แท่งเทียนรายนาทีคือความละเอียดมาตรฐานสำหรับแบ็คเทสต์ แต่ภายในแท่งเทียนหนึ่งนาที ราคาอาจเคลื่อนไหวแตกต่างกัน: บางครั้งเพียง 0.01% บางครั้งถึง 2% เมื่อทั้ง stop-loss และ take-profit อยู่ในช่วง [low, high] ของแท่งเทียนเดียวกัน แบ็คเทสต์ไม่รู้ว่าอันไหนถูกเรียกก่อน นี่คือปัญหา fill ambiguity
วิธีแก้ที่ง่ายที่สุดคือเปลี่ยนมาใช้ข้อมูลระดับวินาทีสำหรับแบ็คเทสต์ทั้งหมด แต่ในช่วงสองปี นั่นหมายถึง ~63 ล้าน second bars แทนที่จะเป็น ~1 ล้าน minute bars พื้นที่จัดเก็บเพิ่มขึ้น 60 เท่า ความเร็วลดลงตามสัดส่วน
Adaptive drill-down แก้ปัญหานี้: ใช้ความละเอียดสูงเฉพาะในจุดที่จำเป็นจริงๆ
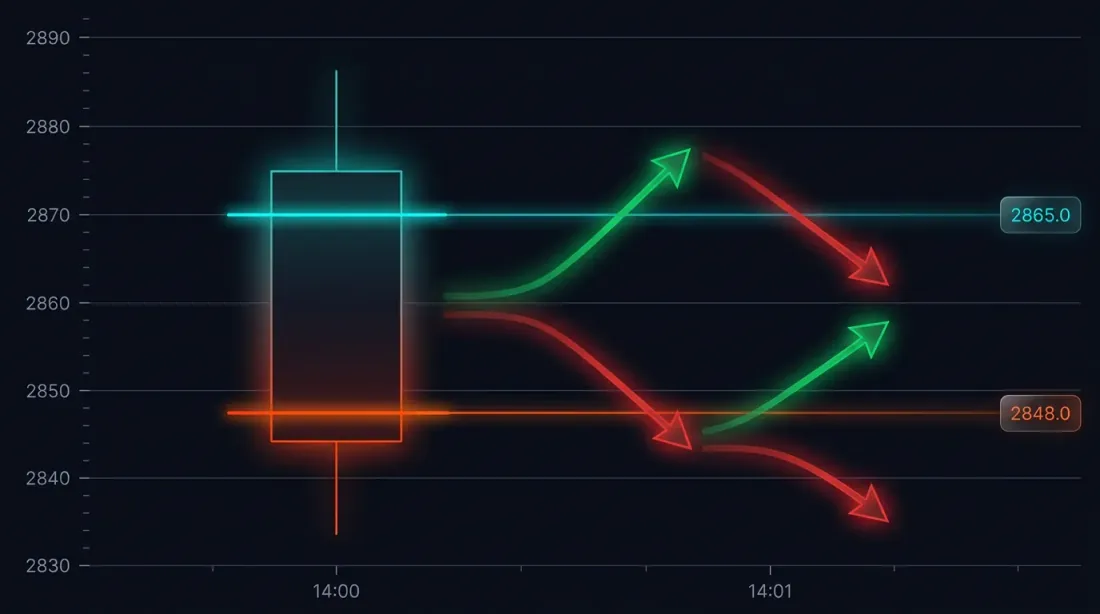
ปัญหา: Fill Ambiguity บนแท่งเทียนขนาดใหญ่
ลองพิจารณาสถานการณ์เฉพาะ กลยุทธ์เปิด long ที่ 3000 USDT Stop-loss: 2970 (-1%) Take-profit: 3060 (+2%)
แท่งเทียนรายนาทีที่ 14:37:
- Open: 3010
- High: 3065
- Low: 2965
- Close: 3050
ทั้ง SL (2970) และ TP (3060) อยู่ในช่วง [2965, 3065] อันไหนถูกเรียกก่อน?
ผลลัพธ์ที่เป็นไปได้:
- ราคาลงก่อน -> SL ถูกเรียก -> ขาดทุน -1%
- ราคาขึ้นก่อน -> TP ถูกเรียก -> กำไร +2%
ความแตกต่างในการเทรดครั้งเดียว: 3 เปอร์เซ็นต์พอยท์ ด้วย leverage 10x — 30% สำหรับแบ็คเทสต์ที่มีการเทรดหลายร้อยครั้ง การแก้ไข fill ambiguity ที่ไม่ถูกต้องจะบิดเบือนผลลัพธ์อย่างเป็นระบบ
วิธีที่ Framework จัดการโดยค่าเริ่มต้น
เครื่องมือแบ็คเทสต์ส่วนใหญ่ใช้ heuristic หนึ่งในสองแบบ:
- Optimistic: TP ถูกเรียกก่อน -> ผลลัพธ์สูงเกินจริง
- Pessimistic: SL ถูกเรียกก่อน -> ผลลัพธ์ต่ำเกินจริง
ทั้งสองวิธีคือการเดา ข้อมูลจริงมีอยู่ในระดับวินาทีหรือแม้แต่มิลลิวินาที และไม่มีเหตุผลที่จะเดาเมื่อสามารถตรวจสอบได้
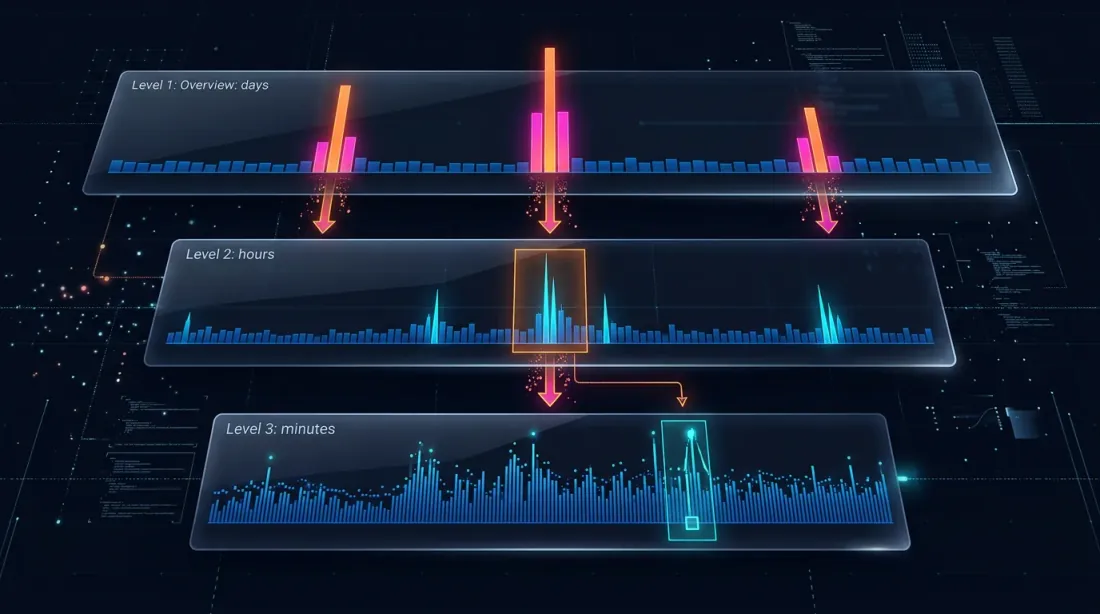
Drill-Down: กลยุทธ์สี่ระดับ

แนวคิด drill-down: เริ่มต้นที่ระดับนาทีและ "เจาะลึก" ลงสู่ระดับล่างเฉพาะเมื่อมี ambiguity — ไม่ว่าจะเกิดจากการเคลื่อนไหวของราคาหรือปริมาณการซื้อขายที่พุ่งสูง
ระดับ 1: 1m (แท่งเทียนรายนาที)
-> ถ้า SL หรือ TP อยู่นอกช่วง [low, high] อย่างชัดเจน — แก้ไขทันที
-> ถ้าทั้งสองอยู่ในช่วง — drill down
ระดับ 2: 1s (แท่งเทียนรายวินาที)
-> โหลด 60 second bars สำหรับนาทีนี้
-> ตรวจสอบทีละวินาที: อันไหนถูกเรียกก่อน?
-> ถ้า second bar ไม่ชัดเจน หรือ price_move >= min_pct หรือ volume >= median_1s * vol_mult — drill down
ระดับ 3: 100ms (แท่งเทียนมิลลิวินาที)
-> โหลดสูงสุด 10 bars ของ 100ms สำหรับวินาทีนี้
-> ตรวจสอบทีละ 100ms
-> ถ้า 100ms bar ไม่ชัดเจน หรือ price_move >= min_pct หรือ volume >= median_100ms * vol_mult — drill down
ระดับ 4: Raw trades
-> โหลดการเทรดแต่ละรายการสำหรับ 100ms bucket นี้
-> แก้ไข fill ในระดับเทรดต่อเทรด — ความแม่นยำสูงสุดที่เป็นไปได้
เมื่อไม่ต้องการ Drill-Down
ใน 95% ของกรณี ไม่จำเป็นต้อง drill-down สถานการณ์ทั่วไป:
SL ที่ชัดเจน: high ของแท่งเทียนไม่ถึง TP แต่ low ทะลุ SL -> SL ถูกเรียก ไม่ต้อง drill-down
TP ที่ชัดเจน: low ไม่ถึง SL แต่ high ทะลุ TP -> TP ถูกเรียก ไม่ต้อง drill-down
ไม่ถูกเรียกทั้งคู่: ทั้งสองระดับอยู่นอกช่วง -> position ยังคงเปิดอยู่
Gap detection: open ของแท่งเทียนถัดไปกระโดดผ่าน SL หรือ TP -> execution ที่ราคา open ไม่ต้อง drill-down
Drill-down จำเป็นสำหรับแค่ ~5% ของ bars — เมื่อทั้งสองระดับอยู่ในช่วงของแท่งเทียนเดียว
class AdaptiveFillSimulator:
"""
Four-level drill-down สำหรับการกำหนดลำดับ fill
"""
def __init__(self, data_loader):
self.loader = data_loader
self.cache_1s = {} # Cache ของข้อมูลวินาทีตามเดือน
def check_fill(self, timestamp, candle_1m, sl_price, tp_price, side):
"""
ตรวจสอบว่า SL หรือ TP ถูกเรียกบนแท่งเทียนรายนาทีที่กำหนด
คืนค่า: ('sl', fill_price) | ('tp', fill_price) | None
"""
low, high = candle_1m['low'], candle_1m['high']
open_price = candle_1m['open']
if side == 'long':
if open_price <= sl_price:
return ('sl', open_price)
if open_price >= tp_price:
return ('tp', open_price)
else:
if open_price >= sl_price:
return ('sl', open_price)
if open_price <= tp_price:
return ('tp', open_price)
sl_hit = self._level_hit(sl_price, low, high, side, 'sl')
tp_hit = self._level_hit(tp_price, low, high, side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if not sl_hit and not tp_hit:
return None
return self._drill_down_1s(timestamp, sl_price, tp_price, side)
def _drill_down_1s(self, minute_ts, sl_price, tp_price, side):
"""ระดับ 2: ตรวจสอบทีละวินาที"""
bars_1s = self.loader.load_1s_for_minute(minute_ts)
if bars_1s is None or len(bars_1s) == 0:
return self._pessimistic_fill(side, sl_price, tp_price)
for bar in bars_1s:
sl_hit = self._level_hit(sl_price, bar['low'], bar['high'], side, 'sl')
tp_hit = self._level_hit(tp_price, bar['low'], bar['high'], side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if sl_hit and tp_hit:
result = self._drill_down_100ms(bar['timestamp'], sl_price, tp_price, side)
if result:
return result
return self._pessimistic_fill(side, sl_price, tp_price)
def _pessimistic_fill(self, side, sl_price, tp_price):
"""สมมติฐาน pessimistic: SL สำหรับ long, TP สำหรับ short"""
if side == 'long':
return ('sl', sl_price)
else:
return ('sl', sl_price)
ประสิทธิภาพ
| โหมด | เวลาต่อการตรวจสอบ fill | เมื่อใช้ |
|---|---|---|
| 1m (ไม่มี drill-down) | ~0ms | ~95% ของกรณี |
| 1s drill-down | ~5ms (การเข้าถึงเดือนครั้งแรก) | ~5% ของกรณี |
| 100ms drill-down | ~1ms | <0.5% ของกรณี |
| Raw trades drill-down | ~0.5ms | <0.1% ของกรณี |
ในแบ็คเทสต์ 2 ปีที่มี ~400 การเทรด drill-down ถูกเรียกประมาณ 20 แท่งเทียน overhead รวมทั้งหมด — น้อยกว่า 1 วินาทีสำหรับแบ็คเทสต์ทั้งหมด
การจัดเก็บข้อมูลแบบ Adaptive
Drill-down ต้องการข้อมูลวินาทีและมิลลิวินาที แต่การจัดเก็บทุกอย่างในความละเอียดสูงสุดนั้นไม่ใช่เรื่องจริง:
| ความละเอียด | Bars ใน 2 ปี | ขนาด Parquet |
|---|---|---|
| 1m | ~1.05M | ~15 MB |
| 1s | ~63M | ~550 MB/เดือน |
| 100ms | ~630M | ~5 GB/เดือน |
archive 1s ทั้งหมดใน 2 ปีประมาณ 13 GB 100ms — กว่า 100 GB การจัดเก็บทั้งหมดเป็นไปได้แต่สิ้นเปลือง เมื่อพิจารณาว่า drill-down ใช้ข้อมูลน้อยกว่า 1% ของทั้งหมด
Hot-Second Detection
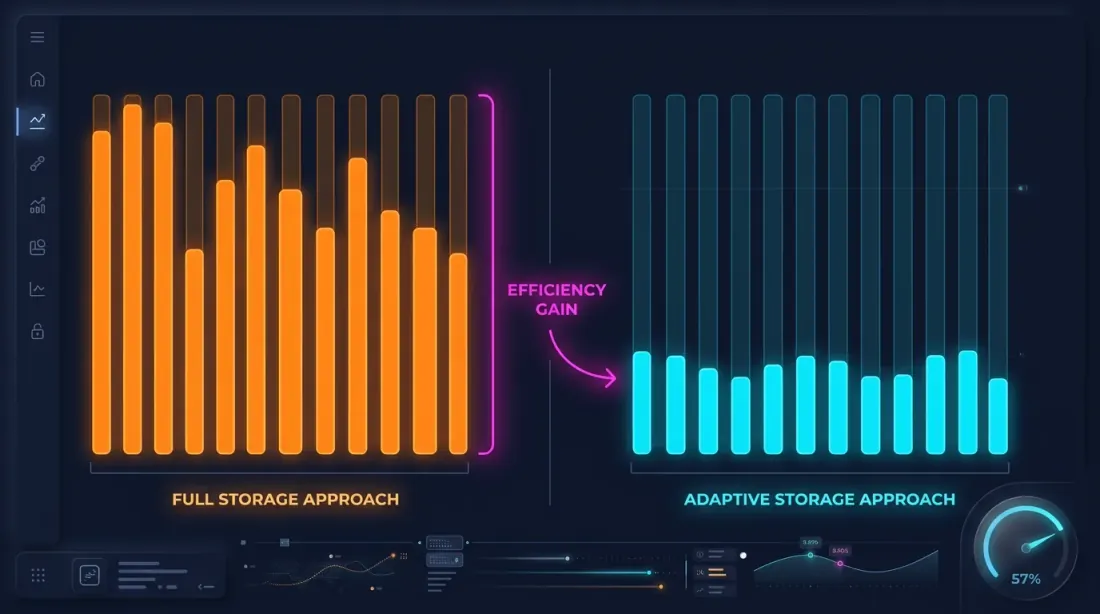
ข้อสังเกตสำคัญ: วินาทีที่ราคาเคลื่อนไหวอย่างมีนัยสำคัญมีสัดส่วนน้อย ถ้าราคาเปลี่ยนแปลงน้อยกว่า 0.1% ในหนึ่งวินาที — ไม่มีประโยชน์ที่จะจัดเก็บรายละเอียด 100ms สำหรับวินาทีนั้น
Hot-second detection: เมื่อดาวน์โหลดและประมวลผลข้อมูล เราวิเคราะห์แต่ละวินาทีและสร้างแท่งเทียน 100ms เฉพาะสำหรับวินาที "hot" — วินาทีที่การเคลื่อนไหวของราคาเกินเกณฑ์
def process_trades_adaptive(
trades: pd.DataFrame,
min_price_change_pct: float = 1.0,
) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
ประมวลผลการเทรดดิบเป็นโครงสร้างแบบ adaptive:
- แท่งเทียน 1s สำหรับทุกวินาที
- แท่งเทียน 100ms เฉพาะสำหรับวินาที "hot"
Args:
trades: DataFrame ที่มีคอลัมน์ [timestamp, price, quantity]
min_price_change_pct: เกณฑ์สำหรับ drill-down ลงสู่ 100ms
Returns:
(df_1s, df_100ms_hot) — แท่งเทียนวินาทีและ 100ms สำหรับวินาที hot
"""
trades['second'] = trades['timestamp'].dt.floor('1s')
df_1s = trades.groupby('second').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
df_1s['price_change_pct'] = (df_1s['high'] - df_1s['low']) / df_1s['open'] * 100
hot_seconds = df_1s[df_1s['price_change_pct'] >= min_price_change_pct].index
hot_trades = trades[trades['second'].isin(hot_seconds)]
hot_trades['bucket_100ms'] = hot_trades['timestamp'].dt.floor('100ms')
df_100ms = hot_trades.groupby('bucket_100ms').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
return df_1s, df_100ms
การประหยัดพื้นที่จัดเก็บ
ตัวอย่าง — ETHUSDT ในเดือนทั่วไป:
| วิธีการ | ขนาด | ความละเอียด |
|---|---|---|
| 1m เท่านั้น | ~1 MB | 1 นาที |
| ทั้งหมด 1s | ~550 MB | 1 วินาที |
| ทั้งหมด 100ms | ~5 GB | 100 ms |
| Adaptive | ~600 MB | 1s + 100ms เฉพาะวินาที hot |
ด้วยเกณฑ์ min_price_change_pct = 1.0% วินาที hot คิดเป็นน้อยกว่า 1% ของวินาทีทั้งหมด ข้อมูล 100ms สำหรับวินาทีเหล่านั้นเพิ่มประมาณ 50 MB ลงใน 550 MB ของข้อมูลวินาที — overhead ที่เล็กน้อยมาก
ถ้าข้อมูลวินาทีถูกจัดเก็บแบบ adaptive ด้วย (เฉพาะเมื่อการเคลื่อนไหวภายในนาทีเกิน 0.1%) ปริมาณสามารถลดลงได้อีก 3-5 เท่า
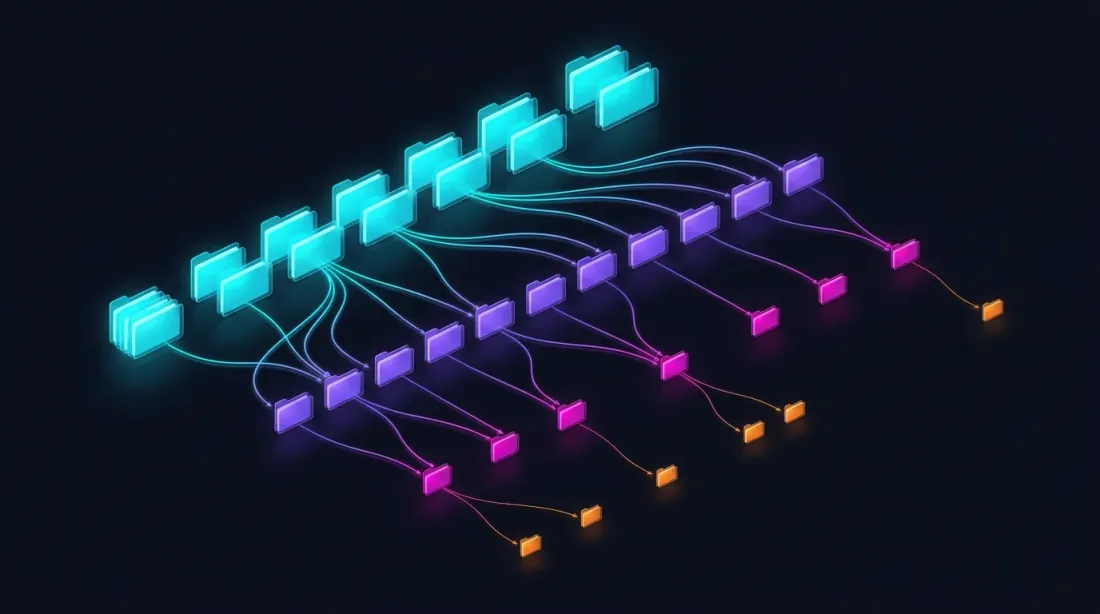
โครงสร้างการจัดเก็บ Parquet
data/{SYMBOL}/
├── source.json # แหล่งข้อมูล Exchange: {"exchange": "binance"} หรือ {"exchange": "bybit"}
├── stats.json # Median volumes ที่คำนวณล่วงหน้า: {"median_volume_1s": ..., "median_volume_100ms": ...}
├── klines_1m/
│ ├── 2024-01.parquet # ~1 MB
│ ├── 2024-02.parquet
│ └── ...
├── klines_1s/
│ ├── 2024-01.parquet # ~550 MB
│ └── ...
├── klines_100ms_hot/
│ ├── 2024-01.parquet # ~50 MB (เฉพาะวินาที hot)
│ └── ...
├── trades_hot/
│ ├── 2024-01.parquet # Raw trades สำหรับ 100ms hot buckets
│ └── ...
└── states_1m.parquet # Rolling state cache ที่คำนวณล่วงหน้า (~112 MB)
แต่ละไฟล์ครอบคลุมข้อมูลหนึ่งเดือน ข้อมูลวินาที มิลลิวินาที และการเทรดถูกโหลดแบบ lazy — เฉพาะเมื่อ drill-down ร้องขอ ไฟล์ stats.json มี median volumes ที่คำนวณล่วงหน้าที่ใช้สำหรับ volume-based drill-down triggers
การปรับแต่ง Parquet สำหรับข้อมูลการเงิน
ข้อมูลการเงินมีลักษณะเฉพาะ: timestamps เพิ่มขึ้นแบบ monotonic ราคาเปลี่ยนแปลงอย่างราบเรียบ ปริมาณแตกต่างกันมาก การตั้งค่าที่เหมาะสม:
import pyarrow as pa
import pyarrow.parquet as pq
schema = pa.schema([
pa.field("timestamp", pa.int32()), # วินาทีจาก epoch — int32 เพียงพอ
pa.field("open", pa.float32()),
pa.field("high", pa.float32()),
pa.field("low", pa.float32()),
pa.field("close", pa.float32()),
pa.field("volume", pa.float32()),
])
column_encodings = {
"timestamp": "DELTA_BINARY_PACKED", # Monotonic int -> delta compression
"open": "BYTE_STREAM_SPLIT", # Float -> byte-stream split
"high": "BYTE_STREAM_SPLIT",
"low": "BYTE_STREAM_SPLIT",
"close": "BYTE_STREAM_SPLIT",
"volume": "BYTE_STREAM_SPLIT",
}
def save_optimized_parquet(df, path):
table = pa.Table.from_pandas(df, schema=schema)
pq.write_table(
table, path,
compression="zstd",
compression_level=9,
use_dictionary=False,
write_statistics=False,
column_encoding=column_encodings,
)
เหตุผลที่เลือกการตั้งค่าเหล่านี้:
- DELTA_BINARY_PACKED สำหรับ timestamps: timestamps ต่อเนื่องกันต่างกันด้วยค่าคงที่ (60 สำหรับ 1m, 1 สำหรับ 1s) Delta encoding บีบอัดให้เกือบเป็นศูนย์
- BYTE_STREAM_SPLIT สำหรับ float: แยก bytes ของ float32 เป็น streams (bytes แรกทั้งหมดรวมกัน, bytes ที่สองทั้งหมดรวมกัน ฯลฯ) สำหรับราคาที่เปลี่ยนแปลงอย่างราบเรียบ บรรลุการบีบอัด 2-3 เท่าดีกว่า standard encoding
- ZSTD level 9: การบีบอัดดีด้วยความเร็ว decompression ที่ยอมรับได้
- float32 แทน float64: เพียงพอสำหรับราคาและปริมาณ ประหยัดหน่วยความจำ 50%
Lazy Loading พร้อม Caching
Drill-down ร้องขอข้อมูลวินาทีสำหรับนาทีเฉพาะ การโหลดไฟล์ parquet สำหรับแต่ละคำขอช้า วิธีแก้ — lazy loading พร้อม LRU cache ตามเดือน
from functools import lru_cache
import pyarrow.parquet as pq
import pandas as pd
class AdaptiveDataLoader:
"""
Lazy loader พร้อม cache: โหลดข้อมูลวินาทีตามเดือน
เก็บ N เดือนล่าสุดไว้ในหน่วยความจำ
"""
def __init__(self, symbol: str, data_dir: str = "data", cache_months: int = 2):
self.symbol = symbol
self.data_dir = data_dir
self.cache_months = cache_months
self._cache_1s: dict[str, pd.DataFrame] = {}
def load_1s_for_minute(self, minute_ts: pd.Timestamp) -> pd.DataFrame | None:
"""โหลดข้อมูล 1s สำหรับนาทีเฉพาะ"""
month_key = minute_ts.strftime("%Y-%m")
if month_key not in self._cache_1s:
self._load_month_1s(month_key)
if month_key not in self._cache_1s:
return None
df = self._cache_1s[month_key]
minute_start = minute_ts.floor('1min')
minute_end = minute_start + pd.Timedelta(minutes=1)
return df[(df.index >= minute_start) & (df.index < minute_end)]
def load_100ms_for_second(self, second_ts: pd.Timestamp) -> pd.DataFrame | None:
"""โหลดข้อมูล 100ms สำหรับวินาที hot"""
month_key = second_ts.strftime("%Y-%m")
path = f"{self.data_dir}/{self.symbol}/klines_100ms_hot/{month_key}.parquet"
try:
df = pd.read_parquet(path)
second_start = second_ts.floor('1s')
second_end = second_start + pd.Timedelta(seconds=1)
return df[(df.index >= second_start) & (df.index < second_end)]
except FileNotFoundError:
return None
def _load_month_1s(self, month_key: str):
"""โหลดข้อมูล 1s หนึ่งเดือน ลบข้อมูลเก่าออกจาก cache"""
path = f"{self.data_dir}/{self.symbol}/klines_1s/{month_key}.parquet"
try:
df = pd.read_parquet(path)
df.index = pd.to_datetime(df['timestamp'], unit='s')
if len(self._cache_1s) >= self.cache_months:
oldest = min(self._cache_1s.keys())
del self._cache_1s[oldest]
self._cache_1s[month_key] = df
except FileNotFoundError:
pass
การนำ Drill-Down ไปใช้ในการ Backtesting
การรวมเข้ากับ backtest loop:
def backtest_with_adaptive_fill(
states: pd.DataFrame,
strategy_params: dict,
data_loader: AdaptiveDataLoader,
) -> list:
"""
แบ็คเทสต์พร้อม adaptive drill-down สำหรับการจำลอง fill
"""
fill_sim = AdaptiveFillSimulator(data_loader)
trades = []
position = None
for i in range(len(states)):
row = states.iloc[i]
ts = states.index[i]
candle_1m = {
'open': row['open'], 'high': row['high'],
'low': row['low'], 'close': row['close'],
'timestamp': ts,
}
if position is not None:
fill = fill_sim.check_fill(
ts, candle_1m,
position['sl'], position['tp'],
position['side'],
)
if fill is not None:
fill_type, fill_price = fill
trades.append({
'entry_time': position['entry_time'],
'exit_time': ts,
'side': position['side'],
'entry_price': position['entry_price'],
'exit_price': fill_price,
'exit_type': fill_type,
'drill_down': fill_sim.last_drill_depth, # 0, 1, หรือ 2
})
position = None
continue
signal = check_entry_signal(row, strategy_params)
if signal and position is None:
position = {
'side': signal['side'],
'entry_price': row['close'],
'entry_time': ts,
'sl': signal['sl'],
'tp': signal['tp'],
}
return trades
ความสัมพันธ์กับ Rolling State Cache
Drill-down เสริม aggregated parquet cache — ทั้งสองแก้ปัญหาที่ต่างกัน:
| Rolling state cache | Adaptive drill-down | |
|---|---|---|
| วัตถุประสงค์ | ค่า HTF indicator ที่ถูกต้อง | ลำดับการ execute SL/TP ที่แม่นยำ |
| ทำงานบน | ทุกแท่งเทียน 1m | เฉพาะระหว่าง fill ambiguity (~5%) |
| ข้อมูล | คำนวณล่วงหน้า จัดเก็บถาวร | โหลดแบบ lazy, cache ของเดือนล่าสุด |
| ส่งผลต่อ | สัญญาณ entry/exit | ราคาและเวลา execution |
ทั้งสองวิธีขจัดข้อผิดพลาดที่มองไม่เห็นในระดับแท่งเทียนรายวัน แต่สำคัญมากสำหรับการ backtesting ที่สมจริง
สรุป: การเปรียบเทียบวิธีการจำลอง Fill
| วิธีการ | ความแม่นยำ | ความเร็ว | พื้นที่จัดเก็บ |
|---|---|---|---|
| OHLC heuristic (optimist/pessimist) | ต่ำ | ทันที | 1m เท่านั้น |
| แบ็คเทสต์ 1s เต็มรูปแบบ | สูง | ช้า (x60) | ~550 MB/เดือน |
| แบ็คเทสต์ 100ms เต็มรูปแบบ | สูงมาก | ช้ามาก (x600) | ~5 GB/เดือน |
| แบ็คเทสต์ raw trades เต็มรูปแบบ | สูงสุด | ช้าสุดขีด | ~50 GB/เดือน |
| Adaptive drill-down (4-level) | สูงสุด | ~ทันที | 1m + 1s + 100ms hot + trades hot |
Drill-down ให้ความแม่นยำเทียบเท่าแบ็คเทสต์ 1s เต็มรูปแบบด้วยความเร็วของแบ็คเทสต์ 1m ข้อสังเกตสำคัญ: ไม่จำเป็นต้องมีความละเอียดสูงทุกที่ — เฉพาะที่จุดตัดสินใจเท่านั้น
Volume-Based Drill-Down
Drill-down เดิมกระตุ้นเฉพาะจากการเคลื่อนไหวของราคา — เมื่อช่วง [low, high] ของแท่งเทียนกว้างพอที่จะสร้าง fill ambiguity แต่ราคาไม่ใช่สัญญาณเดียวที่บ่งบอกว่ามีบางอย่างน่าสนใจเกิดขึ้นภายใน bar
Volume spikes เป็น trigger ที่สำคัญไม่แพ้กัน วินาทีที่ปริมาณมากกว่า median 500 เท่า มักสอดคล้องกับ market order ขนาดใหญ่, การ cascade ของ liquidation หรือ flash crash แม้ว่า candle body จะดูเล็กน้อย เส้นทางราคาจริงภายในวินาทีนั้นอาจผันผวนรุนแรง — แตะ extremes ที่การแสดงผล OHLC ซ่อนไว้
เงื่อนไข drill-down ตอนนี้เป็น OR-based: ทั้งการเคลื่อนไหวของราคาที่มีนัยสำคัญหรือ volume spike ที่ผิดปกติ กระตุ้นการลงสู่ความละเอียดที่ละเอียดกว่า
def is_hot(bar, median_volume, min_pct=0.1, vol_mult=500):
"""
กำหนดว่า bar ต้องการ drill-down ลงสู่ระดับถัดไปหรือไม่
Triggers อิสระสองตัว (OR logic):
- ราคาเคลื่อนไหว >= min_pct ภายใน bar
- ปริมาณเกิน median * vol_mult
"""
price_move = (bar['high'] - bar['low']) / bar['open'] * 100
return price_move >= min_pct or bar['volume'] >= median_volume * vol_mult
วิธีนี้จับสถานการณ์ที่มองไม่เห็นด้วยการตรวจสอบราคาอย่างเดียว: bar ที่มี open=3000, close=3001 แต่ปริมาณมากกว่าค่าปกติ 50,000 เท่า อาจแตะ 2950 และ 3050 ภายในมิลลิวินาที หากไม่มี volume-based drill-down แบ็คเทสต์จะไม่ตรวจสอบวินาทีนี้อย่างละเอียด
Raw Trades: ระดับที่สี่
ลำดับชั้นสามระดับเดิม (1m -> 1s -> 100ms) ยังมีช่องว่าง: ภายใน 100ms bucket เดียว การเทรดหลายรายการสามารถ execute ที่ราคาต่างกัน สำหรับ bucket ที่มี high=3060 และ low=2965 เรายังไม่รู้ลำดับที่แน่นอน
วิธีแก้: drill down ลงสู่ raw trades เป็นระดับที่สี่และสุดท้าย
แท่งเทียน 1m (ฐาน)
└─> แท่งเทียน 1s (เมื่อ 1s แสดง price_move >= min_pct หรือ volume >= median_1s * vol_mult)
└─> แท่งเทียน 100ms (เมื่อตรวจพบวินาที hot)
└─> Raw trades (เมื่อ 100ms แสดง price_move >= min_pct หรือ volume >= median_100ms * vol_mult)
ที่ระดับ raw trades ไม่มี ambiguity — การเทรดแต่ละรายการมีราคาและ timestamp ที่แน่นอน fill ถูกแก้ไขอย่างเด็ดขาด:
def resolve_from_trades(trades, sl_price, tp_price, side):
"""
ผ่านการเทรดแต่ละรายการตามลำดับเวลา
การเทรดรายการแรกที่ผ่าน SL หรือ TP กำหนด fill
"""
for trade in trades:
price = trade['price']
if side == 'long':
if price <= sl_price:
return ('sl', price)
if price >= tp_price:
return ('tp', price)
else: # short
if price >= sl_price:
return ('sl', price)
if price <= tp_price:
return ('tp', price)
return None
ระดับ raw trades ถูกเรียกน้อยมาก — น้อยกว่า 0.1% ของ bars ทั้งหมด — แต่เมื่อถูกเรียก มันให้ ground truth ที่การประมาณจากแท่งเทียนไม่สามารถเทียบได้
Thresholds แยกต่างหากต่อการเปลี่ยนผ่านแต่ละครั้ง
การเปลี่ยนผ่านความละเอียดที่ต่างกันมีลักษณะต่างกัน การเคลื่อนไหวของราคา 0.1% ภายในวินาทีมีนัยสำคัญ แต่ 0.1% เดียวกันภายใน 100ms bucket นั้นสุดขีด เช่นเดียวกัน การกระจายของปริมาณต่างกันในแต่ละ timescale
การเปลี่ยนผ่านแต่ละระดับตอนนี้มีพารามิเตอร์ min_pct และ vol_mult ของตัวเอง:
1s → 100ms: --min-pct-1s 0.1 --vol-mult-1s 500
100ms → trades: --min-pct-100ms 0.1 --vol-mult-100ms 500
วิธีนี้ช่วยให้ปรับความไวของแต่ละการเปลี่ยนผ่านได้อย่างอิสระ ในทางปฏิบัติ การเปลี่ยนผ่านจาก 100ms ไปยัง trades สามารถใช้เกณฑ์ที่เข้มงวดกว่า เนื่องจากต้นทุนการโหลด raw trades สำหรับ 100ms bucket เดียวนั้นน้อยมาก
@dataclass
class DrillDownConfig:
min_pct_1s: float = 0.1
vol_mult_1s: float = 500
min_pct_100ms: float = 0.1
vol_mult_100ms: float = 500
Median Statistics ถาวร
Volume-based drill-down ต้องการทราบ median volume ในแต่ละ timescale การคำนวณ medians แบบ on-the-fly สำหรับทุก backtest จะลบล้างประโยชน์ด้านประสิทธิภาพ วิธีแก้: คำนวณ medians ครั้งเดียวและ cache ไว้
สำหรับแต่ละ symbol median volumes ที่ granularity 1s และ 100ms ถูกคำนวณจากข้อมูลประวัติศาสตร์และจัดเก็บในไฟล์ stats.json:
{
"ETHUSDT": {
"median_volume_1s": 12.5,
"median_volume_100ms": 1.8
},
"BTCUSDT": {
"median_volume_1s": 0.45,
"median_volume_100ms": 0.06
}
}
สถิติถูกคำนวณครั้งเดียวต่อ symbol เมื่อดาวน์โหลดข้อมูลครั้งแรก และนำมาใช้ซ้ำในทุก backtest ที่ตามมา ถ้าข้อมูลถูกอัปเดต (ดาวน์โหลดเดือนใหม่) สถิติจะถูกคำนวณใหม่แบบ incremental
def compute_median_stats(symbol, data_dir):
"""คำนวณและ cache สถิติ median volume สำหรับ symbol"""
stats_path = f"{data_dir}/{symbol}/stats.json"
all_1s = load_all_months(f"{data_dir}/{symbol}/klines_1s/")
median_1s = all_1s['volume'].median()
all_100ms = load_all_months(f"{data_dir}/{symbol}/klines_100ms_hot/")
median_100ms = all_100ms['volume'].median()
stats = {
"median_volume_1s": float(median_1s),
"median_volume_100ms": float(median_100ms),
}
with open(stats_path, 'w') as f:
json.dump(stats, f, indent=2)
return stats

รองรับหลาย Exchange: Bybit
ไม่ใช่ทุก symbol จะมีให้บน Binance สำหรับสินทรัพย์เช่น XAUTUSDT (ทอง) ข้อมูลต้องมาจาก exchange อื่น ระบบ drill-down ตอนนี้รองรับ Bybit เป็นแหล่งข้อมูลทางเลือก
สำหรับ symbols ของ Bybit ทุกระดับแท่งเทียน (1m, 1s, 100ms) และ raw trades ถูกสร้างจาก raw trade stream ของ Bybit กระบวนการเหมือนกัน — raw trades ถูก aggregate เป็นแท่งเทียนในแต่ละ timescale — แต่แหล่งข้อมูลต่างกัน
data/{SYMBOL}/
├── source.json # {"exchange": "bybit"} หรือ {"exchange": "binance"}
├── klines_1m/
│ └── ...
├── klines_1s/
│ └── ...
├── klines_100ms_hot/
│ └── ...
└── trades_hot/ # Raw trades สำหรับ 100ms hot buckets
└── ...
data loader ตรวจสอบ source.json และใช้ download pipeline ที่เหมาะสม จากมุมมองของ backtest engine รูปแบบข้อมูลเหมือนกันไม่ว่าจะเป็น source exchange ใด — drill-down logic ไม่ขึ้นกับ exchange
สิ่งนี้สำคัญอย่างยิ่งสำหรับกลยุทธ์ cross-exchange หรือ symbols ที่ซื้อขายเฉพาะบน venues บางแห่ง
บทสรุป
Adaptive drill-down คือการประยุกต์ใช้หลักการง่ายๆ: ใช้ทรัพยากรการคำนวณและพื้นที่จัดเก็บตามสัดส่วนกับความสำคัญของข้อมูล
สี่ระดับความละเอียด:
- 1m — ผ่านฐานสำหรับ 95% ของ bars
- 1s — drill-down ระหว่าง fill ambiguity หรือ volume spikes
- 100ms — drill-down สำหรับวินาที hot ที่มีการเคลื่อนไหวสุดขีดหรือปริมาณผิดปกติ
- Raw trades — drill-down สำหรับ 100ms buckets hot แก้ไข fills ในระดับการเทรดแต่ละรายการ
สี่ระดับการจัดเก็บ:
- ทั้งหมด 1m — archive สมบูรณ์, ~15 MB ใน 2 ปี
- ทั้งหมด 1s — archive สมบูรณ์หรือ adaptive, ~550 MB/เดือน
- เฉพาะ 100ms hot — <1% ของวินาที, ~50 MB/เดือน
- เฉพาะ trades hot — raw trades สำหรับ 100ms buckets ที่รุนแรงที่สุด
Drill-down triggers สอง trigger (OR logic):
- ตามราคา: ช่วงราคาของ bar เกิน
min_pct - ตามปริมาณ: ปริมาณของ bar เกิน
median * vol_mult
ผลลัพธ์: แบ็คเทสต์ที่มีความแม่นยำระดับ tick simulator ด้วยความเร็วระดับนาที พื้นที่จัดเก็บที่เพิ่มขึ้นแบบ linear ไม่ใช่แบบ exponential และรองรับหลาย exchange — Binance และ Bybit — ด้วย drill-down logic ที่ไม่ขึ้นกับ exchange
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับ precomputed cache สำหรับกลยุทธ์ multi-timeframe ดูบทความ Aggregated Parquet Cache เกี่ยวกับผลกระทบของ funding rates ต่อผลลัพธ์ด้วย leverage สูง — Funding rates kill your leverage
ลิงก์ที่มีประโยชน์
- Apache Parquet — รูปแบบการจัดเก็บข้อมูล
- Apache Arrow — BYTE_STREAM_SPLIT encoding
- Zstandard — อัลกอริทึมการบีบอัด
- Lopez de Prado — Advances in Financial Machine Learning
- Binance — Historical Market Data
การอ้างอิง
@article{soloviov2026adaptivedrilldown,
author = {Soloviov, Eugen},
title = {Adaptive Drill-Down: Backtest with Variable Granularity from Minutes to Raw Trades},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/adaptive-resolution-drill-down-backtest},
description = {วิธีที่ความละเอียดข้อมูลแบบปรับตัวได้ช่วยเร่งความเร็วแบ็คเทสต์และประหยัดพื้นที่จัดเก็บ: drill-down จาก 1m ลงสู่ 1s, 100ms และการเทรดดิบ เฉพาะในจุดที่ราคาเคลื่อนไหวอย่างมีนัยสำคัญหรือปริมาณการซื้อขายพุ่งสูง}
}
ผู้เขียน

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
อ่านเพิ่มเติม

Aggregated Parquet Cache: วิธีเร่งความเร็วแบ็คเทสต์หลาย Timeframe ได้หลายร้อยเท่า

Coordinate Descent กับ Bayesian Optimization: วิธีไหนหาพารามิเตอร์ที่ดีกว่ากัน
