Aggregated Parquet Cache: วิธีเร่งความเร็วแบ็คเทสต์หลาย Timeframe ได้หลายร้อยเท่า

กลยุทธ์แบบ multi-timeframe ใช้หลาย timeframe พร้อมกัน: รายวันใช้กำหนดทิศทาง trend รายชั่วโมงใช้ระบุจุดเข้าเทรด และ 5 นาทีใช้กำหนดจังหวะการดำเนินการ แต่ละ timeframe ต้องการ indicator ของตัวเอง: moving average, oscillator, ระดับต่างๆ
สำหรับแบ็คเทสต์ครั้งเดียวนั้นตรงไปตรงมา — คำนวณ timeframe ใหม่จากข้อมูลรายนาที คำนวณ indicator แล้วรันกลยุทธ์ แต่ในระหว่างการปรับแต่งจำนวนมาก — เมื่อต้องทดสอบพารามิเตอร์หลายพันชุด — การคำนวณ timeframe และ indicator ในทุก iteration จะกลายเป็นคอขวด การผ่านข้อมูลรายนาทีในช่วงสองปีหมายความว่าต้องประมวลผลแท่งเทียนกว่าหนึ่งล้านแท่ง และการทำซ้ำพันครั้งนั้นสิ้นเปลือง
วิธีแก้: คำนวณทุกอย่างครั้งเดียวแล้วแคชไว้ในไฟล์ parquet
ปัญหา: การคำนวณซ้ำซ้อนระหว่างการปรับแต่ง
pipeline แบ็คเทสต์แบบ multi-timeframe ทั่วไปมีลักษณะดังนี้:
for params in parameter_grid:
df_1m = load_candles("ETHUSDT", "1m", start, end)
df_5m = resample_ohlcv(df_1m, "5m")
df_1h = resample_ohlcv(df_1m, "1h")
df_4h = resample_ohlcv(df_1m, "4h")
df_1d = resample_ohlcv(df_1m, "D")
ma_1h = compute_ma(df_1h["close"], length=params["ma_1h_len"])
ma_4h = compute_ma(df_4h["close"], length=params["ma_4h_len"])
ma_1d = compute_ma(df_1d["close"], length=params["ma_1d_len"])
result = run_strategy(df_1m, ma_1h, ma_4h, ma_1d, params)
ในทุก iteration ขั้นตอนที่ 1-3 จะถูกคำนวณใหม่ทั้งที่ข้อมูลเหมือนเดิม มีเพียงพารามิเตอร์เกณฑ์ของกลยุทธ์เท่านั้นที่เปลี่ยน (ขั้นตอนที่ 4) มันเหมือนกับการสร้างบ้านใหม่ทั้งหลังทุกครั้งที่เพียงแค่อยากลองเปลี่ยนสีผนัง
แนวคิด: คำนวณครั้งเดียว บันทึก นำกลับมาใช้หลายครั้ง
ข้อสังเกตสำคัญ: timeframe และ indicator ขึ้นอยู่กับข้อมูลรายนาทีและพารามิเตอร์ indicator เท่านั้น ไม่ใช่พารามิเตอร์ของกลยุทธ์ ถ้าเรากำหนดชุด indicator ที่ต้องการไว้ล่วงหน้า เราสามารถคำนวณครั้งเดียวแล้วบันทึกได้
แผนผัง:
ขั้นตอนที่ 1 (ครั้งเดียว):
แท่งเทียนรายนาที -> Resampling timeframe -> คำนวณ indicator -> ไฟล์ Parquet
ขั้นตอนที่ 2 (หลายครั้ง):
ไฟล์ Parquet -> กลยุทธ์ด้วยพารามิเตอร์ต่างกัน -> ผลลัพธ์
การจำลอง Timeframe จากแท่งเทียนรายนาที
เรามีคลังข้อมูลแท่งเทียนรายนาทีครบถ้วน จากข้อมูลนี้เราสามารถสร้าง timeframe ที่สูงกว่าได้อย่างแม่นยำ แต่มีข้อควรระวัง: ด้วย resample มาตรฐาน เราจะได้หนึ่งแถวต่อรอบ (หนึ่งแถวต่อชั่วโมง หนึ่งแถวต่อ 4 ชั่วโมง ฯลฯ) ซึ่งใช้งานไม่ได้สำหรับแบ็คเทสต์แบบนาทีต่อนาที — เราต้องรู้ค่า indicator ณ ทุกนาที
ดังนั้น เราจำลองค่า timeframe ที่สูงกว่าสำหรับแท่งเทียนรายนาทีแต่ละแท่ง โดยสร้างแบบจำลองวิธีที่บอทเห็นข้อมูลแบบ real-time:
- บอทได้รับแท่งเทียนรายนาทีถัดไป
- อัปเดตแท่งปัจจุบัน (ที่ยังไม่ปิด) ของ timeframe ที่สูงกว่า — คำนวณ High, Low, Close, Volume ใหม่
- คำนวณ indicator ใหม่ครอบคลุมแท่งที่ปิดแล้วทั้งหมดรวมถึงแท่งปัจจุบันที่ยังไม่สมบูรณ์
- เมื่อรอบสิ้นสุด — แท่งถูกสรุปและแท่งใหม่เริ่มต้น
วิธีนี้รับประกันว่าแบ็คเทสต์เห็นข้อมูลเหมือนกับที่บอทเห็นแบบ real-time ไม่มีการมองอนาคต — แท่งเทียนรายนาทีแต่ละแท่งถูกประมวลผลอย่างเคร่งครัดด้วยข้อมูลที่จะพร้อมใช้งาน ณ เวลานั้น
class RunningCandleBuffer:
"""
Emulates real-time updates of a higher timeframe bar
using 1-minute candles.
"""
def __init__(self, period_seconds: int):
self.period = period_seconds # 86400 for Daily, 3600 for 1h
self.closed_bars = []
self.current_bar = None
def update(self, timestamp, open_, high, low, close, volume):
bar_start = self._align_to_period(timestamp)
if self.current_bar is None or bar_start != self.current_bar['start']:
if self.current_bar is not None:
self.closed_bars.append(self.current_bar)
self.current_bar = {
'start': bar_start,
'open': open_, 'high': high,
'low': low, 'close': close,
'volume': volume,
}
else:
self.current_bar['high'] = max(self.current_bar['high'], high)
self.current_bar['low'] = min(self.current_bar['low'], low)
self.current_bar['close'] = close
self.current_bar['volume'] += volume
return self.closed_bars + [self.current_bar]
RunningCandleBuffer แยกต่างหากถูกสร้างสำหรับแต่ละ timeframe ที่สูงกว่า ในทุกแท่งเทียนรายนาที บัฟเฟอร์ทั้งหมดถูกอัปเดต ให้เราเห็นสถานะปัจจุบันของแต่ละ timeframe — ราวกับว่าบอทกำลังทำงานแบบ real-time
โครงสร้าง Parquet Cache
ผลลัพธ์ของการคำนวณล่วงหน้าคือไฟล์ parquet ไฟล์เดียว ที่แต่ละแถวสอดคล้องกับแท่งเทียนรายนาทีหนึ่งแท่ง และคอลัมน์ประกอบด้วย:
timestamp — timestamp ของแท่งเทียนรายนาที
open, high, low, — OHLCV ของแท่งเทียนรายนาที
close, volume
close_5m — Close ของแท่ง 5m ที่จำลองไว้ ณ เวลานี้
close_1h — Close ของแท่ง 1h ที่จำลองไว้
close_4h — Close ของแท่ง 4h ที่จำลองไว้
close_1d — Close ของแท่งรายวันที่จำลองไว้
ma_20_1h — MA(20) บน 1h คำนวณใหม่ ณ นาทีนี้
ma_50_1h — MA(50) บน 1h
ma_20_4h — MA(20) บน 4h
ma_50_4h — MA(50) บน 4h
ma_6_1d — MA(6) บน Daily
ma_12_1d — MA(12) บน Daily
cross_ma_1h — สัญญาณ MA crossover บน 1h ('buy'/'sell'/None)
cross_ma_4h — สัญญาณ MA crossover บน 4h
cross_ma_1d — สัญญาณ MA crossover บน Daily
separation_1h — ความแตกต่าง MA เป็น % บน 1h
separation_4h — ความแตกต่าง MA เป็น % บน 4h
separation_1d — ความแตกต่าง MA เป็น % บน Daily
ค่าแต่ละค่าสะท้อนสถานะจริงของ indicator ณ เวลาของแท่งเทียนรายนาทีที่สอดคล้องกัน — คำนึงถึงแท่งที่ยังไม่ปิดของ timeframe ที่สูงกว่า
Precompute: การสร้าง Cache
def precompute_cache(
df_1m: pd.DataFrame,
timeframes: dict[str, int], # {"5m": 300, "1h": 3600, "4h": 14400, "D": 86400}
indicators: dict, # {"ma_20": 20, "ma_50": 50}
) -> pd.DataFrame:
"""
Single pass through all minute candles.
Returns a DataFrame with emulated timeframes and indicators.
"""
buffers = {tf: RunningCandleBuffer(secs) for tf, secs in timeframes.items()}
n = len(df_1m)
result = {}
for tf_name, buf in buffers.items():
closes = np.zeros(n)
ma_values = {name: np.full(n, np.nan) for name in indicators}
for i in range(n):
row = df_1m.iloc[i]
bars = buf.update(
df_1m.index[i],
row['open'], row['high'], row['low'], row['close'], row['volume']
)
all_closes = [b['close'] for b in bars]
closes[i] = all_closes[-1]
for ind_name, length in indicators.items():
if len(all_closes) >= length:
ma_values[ind_name][i] = np.mean(all_closes[-length:])
result[f'close_{tf_name}'] = closes
for ind_name in indicators:
result[f'{ind_name}_{tf_name}'] = ma_values[ind_name]
cache_df = pd.DataFrame(result, index=df_1m.index)
cache_df = pd.concat([df_1m[['open', 'high', 'low', 'close', 'volume']], cache_df], axis=1)
return cache_df
cache = precompute_cache(
df_1m,
timeframes={"5m": 300, "1h": 3600, "4h": 14400, "D": 86400},
indicators={"ma_20": 20, "ma_50": 50, "ma_6": 6, "ma_12": 12},
)
cache.to_parquet("cache_ETHUSDT_2024_2026.parquet")
การใช้ Cache ระหว่างการปรับแต่ง
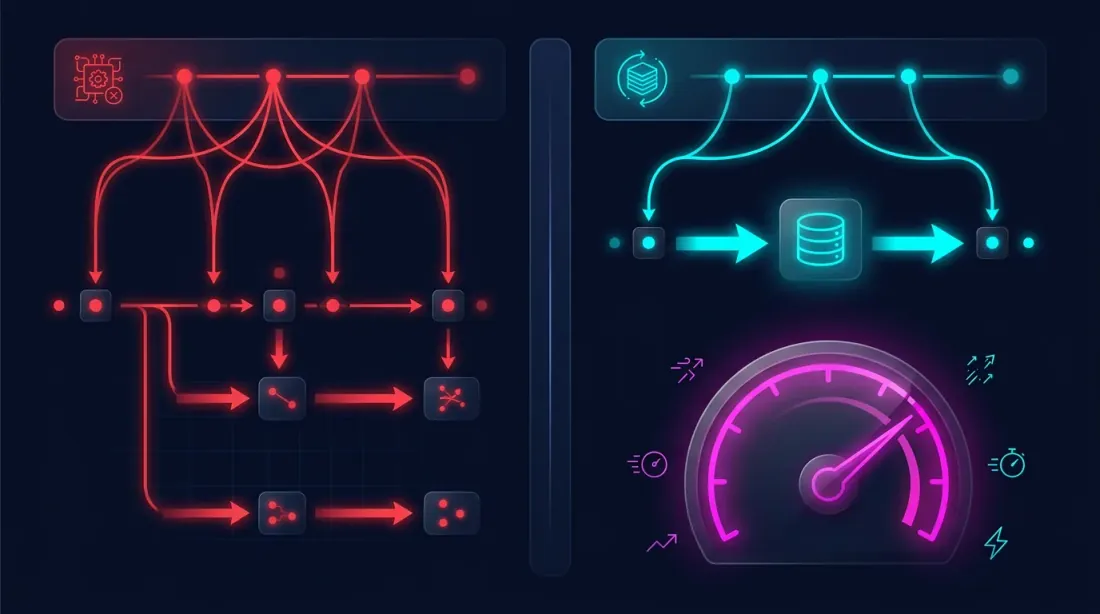
ตอนนี้การปรับแต่งมีลักษณะดังนี้:
cache = pd.read_parquet("cache_ETHUSDT_2024_2026.parquet")
for params in parameter_grid:
result = run_strategy(cache, params)
กลยุทธ์ทำงานกับคอลัมน์ที่สร้างไว้ล่วงหน้า — ไม่มีการผ่านแท่งเทียนหนึ่งล้านแท่งซ้ำๆ ไม่มีการคำนวณ MA ใหม่ ไม่มีการจำลอง timeframe เพียงแค่อ่านจาก DataFrame และตรวจสอบเงื่อนไขเข้า/ออก
ทำไมต้อง Parquet
Parquet คือรูปแบบการจัดเก็บข้อมูลแบบคอลัมน์ที่เหมาะสมที่สุดสำหรับงานนี้:
- การบีบอัด Parquet บีบอัดข้อมูลตัวเลขได้ 5-10 เท่า cache ที่มี 1.1 ล้านแถวกับ 30 คอลัมน์ใช้พื้นที่ ~50 MB แทนที่จะเป็น ~500 MB ในรูปแบบ CSV
- การอ่านแบบคอลัมน์ หากกลยุทธ์ใช้เพียง
ma_20_4hและma_50_4hparquet จะอ่านเฉพาะคอลัมน์เหล่านั้น ข้ามส่วนที่เหลือ - การรักษา type ประเภทข้อมูล (float64, int64, string) ถูกรักษาไว้อย่างไม่สูญเสีย — ไม่ต้องแปลง string เมื่อโหลด
- ความเร็วในการอ่าน การโหลด parquet เข้า pandas ใช้เวลาหลักสิบมิลลิวินาที เร็วกว่า CSV เป็นลำดับขนาด
การขยาย Cache: การเพิ่ม Indicator ใหม่
หากกลยุทธ์ต้องการ indicator ใหม่ (RSI, MACD, Bollinger Bands) เพียงแค่:
- คำนวณเฉพาะ indicator ใหม่จากข้อมูลรายนาทีเดิม
- เพิ่มคอลัมน์เข้าในไฟล์ parquet ที่มีอยู่
- คอลัมน์ที่คำนวณไว้ก่อนหน้าทั้งหมดยังคงอยู่
cache = pd.read_parquet("cache_ETHUSDT_2024_2026.parquet")
rsi_cols = compute_rsi_for_timeframes(df_1m, timeframes, length=14)
cache = pd.concat([cache, rsi_cols], axis=1)
cache.to_parquet("cache_ETHUSDT_2024_2026.parquet")
สรุป: การเปรียบเทียบวิธีการ
| วิธีทั่วไป | Aggregated Cache | |
|---|---|---|
| Timeframe resampling | ทุก iteration | ครั้งเดียว |
| การคำนวณ indicator | ทุก iteration | ครั้งเดียว |
| เวลาต่อ iteration | หลายนาที | น้อยกว่าหนึ่งวินาที |
| 1000 iteration | หลายวัน | หลายนาที |
| การใช้หน่วยความจำ | โหลด 1m + คำนวณใหม่ | DataFrame เดียว |
| ความสอดคล้องแบ็คเทสต์-live | ขึ้นอยู่กับการนำไปใช้ | รับประกัน (emulation = real-time) |
สรุปความ
แนวทาง aggregated parquet cache แก้ปัญหาสองอย่างพร้อมกัน:
-
ความถูกต้อง การจำลอง timeframe จากแท่งเทียนรายนาทีผ่าน RunningCandleBuffer รับประกันว่าแบ็คเทสต์เห็นข้อมูลเหมือนกับที่บอทเห็นแบบ real-time — ไม่มีการมองอนาคตและไม่มีการหน่วงเวลาเทียม
-
ความเร็ว timeframe และ indicator ที่คำนวณไว้ล่วงหน้าช่วยให้ทดสอบพารามิเตอร์หลายพันชุดได้ในเวลาไม่กี่นาทีแทนที่จะเป็นหลายวัน
แนวคิดนั้นง่าย: คำนวณครั้งเดียว — นำกลับมาใช้หลายครั้ง แท่งเทียนรายนาทีคือข้อมูลต้นทาง ทุกอย่างอื่นเป็นข้อมูลที่ได้รับมาและสามารถคำนวณล่วงหน้าและแคชได้ Parquet ทำให้ cache นี้กะทัดรัด เร็ว และสะดวกในการใช้งาน
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับวิธีปรับปรุงความแม่นยำของการจำลอง fill ด้วย adaptive drill-down จากนาทีสู่วินาทีและมิลลิวินาที ดูบทความ Adaptive drill-down: แบ็คเทสต์ด้วยความละเอียดข้อมูลแบบยืดหยุ่น
ลิงก์ที่เป็นประโยชน์
- Apache Parquet — รูปแบบการจัดเก็บข้อมูล
- pandas — การทำงานกับ parquet
- Lopez de Prado — Advances in Financial Machine Learning
- Ernest Chan — Quantitative Trading
การอ้างอิง
@article{soloviov2026parquetcache,
author = {Soloviov, Eugen},
title = {Aggregated Parquet Cache: How to Speed Up Multi-Timeframe Backtests by Hundreds of Times},
year = {2026},
url = {https://marketmaker.cc/th/blog/post/parquet-cache-multitimeframe-backtest},
description = {วิธีคำนวณ timeframe และ indicator ล่วงหน้าจากแท่งเทียนรายนาที บันทึกลง parquet และนำมาใช้สำหรับการทดสอบกลยุทธ์จำนวนมากโดยไม่ต้องคำนวณซ้ำซ้อน}
}
ผู้เขียน

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
อ่านเพิ่มเติม

Adaptive Drill-Down: แบ็คเทสต์ด้วยความละเอียดข้อมูลแบบยืดหยุ่น ตั้งแต่นาทีจนถึงการเทรดดิบ

Coordinate Descent กับ Bayesian Optimization: วิธีไหนหาพารามิเตอร์ที่ดีกว่ากัน
