QuestDB per il Trading Algoritmico: Dai Libri degli Ordini all'Architettura di Produzione

Parte 3 di 3 — disponibile anche in RU · ZH
Avviso legale: Le informazioni fornite in questo articolo hanno scopo esclusivamente educativo e informativo e non costituiscono consulenza finanziaria, di investimento o di trading. Il trading di criptovalute comporta un rischio significativo di perdita.
Benvenuti all'ultima parte della nostra serie su QuestDB. Nella Parte 1 abbiamo trattato l'architettura di archiviazione. Nella Parte 2 abbiamo esplorato le estensioni SQL. Ora mettiamo tutto insieme: viste materializzate per l'analisi in tempo reale, archiviazione nativa del libro degli ordini con array 2D e un'architettura di riferimento per una piattaforma di trading algoritmico in produzione.
Viste Materializzate: Analisi Pre-Calcolata alla Velocità del Cavo
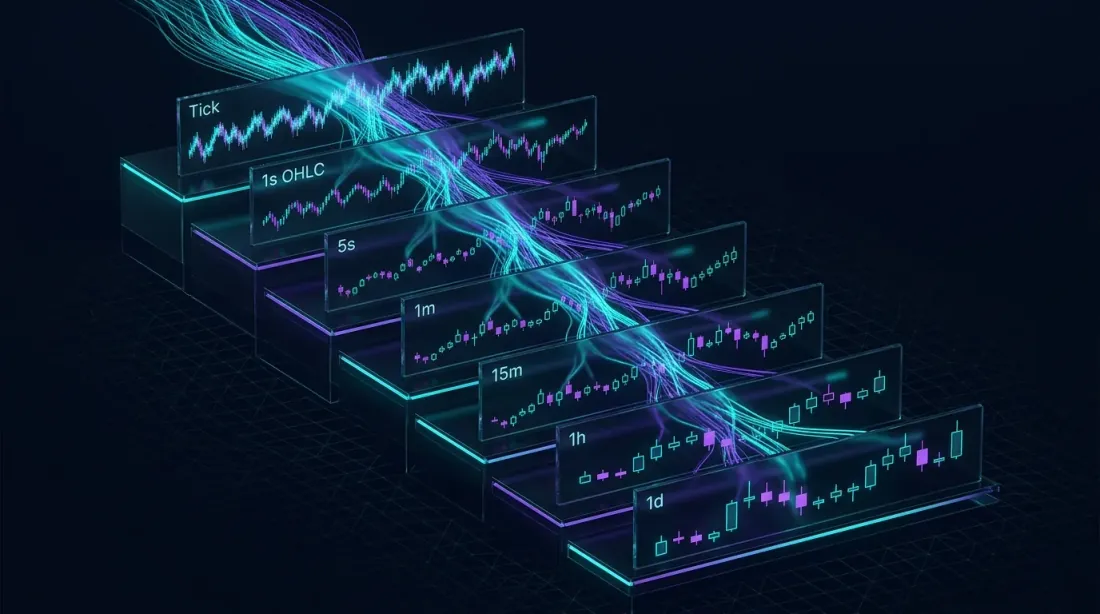 Viste materializzate a cascata: i dati di tick grezzi fluiscono attraverso livelli di aggregazione progressivamente più grossolani, con ogni livello che elabora un dataset notevolmente più piccolo
Viste materializzate a cascata: i dati di tick grezzi fluiscono attraverso livelli di aggregazione progressivamente più grossolani, con ogni livello che elabora un dataset notevolmente più piccolo
Se SAMPLE BY è la query più utilizzata di QuestDB, le viste materializzate ne rappresentano l'ottimizzazione più impattante. Il concetto è semplice: invece di calcolare le aggregazioni OHLCV ad ogni aggiornamento della dashboard o chiamata API, si pre-calcolano una volta e si mantiene il risultato continuamente aggiornato.
Vista Materializzata OHLC di Base
CREATE MATERIALIZED VIEW trades_OHLC_15m
WITH BASE 'trades'
REFRESH IMMEDIATE
AS
SELECT timestamp, symbol,
first(price) AS open,
max(price) AS high,
min(price) AS low,
last(price) AS close,
sum(quantity) AS volume
FROM trades
SAMPLE BY 15m;
Questa è l'intera definizione. Ogni volta che vengono inserite nuove righe nella tabella trades, QuestDB aggiorna automaticamente e in modo incrementale questa vista. Non si tratta di un ricalcolo completo — vengono aggiornati solo i bucket temporali interessati. Le query su trades_OHLC_15m diventano semplici ricerche su un dataset molto più piccolo e pre-aggregato.
La differenza di prestazioni è notevole. Su una tabella con miliardi di righe, interrogare la tabella base per i dati OHLC potrebbe richiedere 200ms. La vista materializzata restituisce lo stesso risultato in meno di 5ms. Con più utenti della dashboard in simultanea, non si tratta solo di un'ottimizzazione — è la differenza tra un sistema reattivo e uno che crolla sotto il carico.
Viste a Cascata: Multi-Timeframe da un'Unica Sorgente
Ecco dove le viste materializzate diventano architetturalmente eleganti. È possibile concatenarle — ogni vista alimenta la successiva, creando una gerarchia di livelli di aggregazione da un'unica sorgente di dati grezzi:
-- Barre a 1 secondo dai trade grezzi
CREATE MATERIALIZED VIEW ohlc_1s AS
SELECT timestamp, symbol,
first(price) AS open, max(price) AS high,
min(price) AS low, last(price) AS close,
sum(quantity) AS volume
FROM trades
SAMPLE BY 1s;
-- Barre a 5 secondi dalle barre a 1 secondo
CREATE MATERIALIZED VIEW ohlc_5s AS
SELECT timestamp, symbol,
first(open) AS open, max(high) AS high,
min(low) AS low, last(close) AS close,
sum(volume) AS volume
FROM ohlc_1s
SAMPLE BY 5s;
-- Barre a 1 minuto dalle barre a 5 secondi
CREATE MATERIALIZED VIEW ohlc_1m AS
SELECT timestamp, symbol,
first(open) AS open, max(high) AS high,
min(low) AS low, last(close) AS close,
sum(volume) AS volume
FROM ohlc_5s
SAMPLE BY 1m;
Ogni livello elabora un dataset notevolmente più piccolo rispetto al precedente. La vista a 1 minuto non scansiona i trade grezzi — legge solo le barre a 5 secondi pre-aggregate. Questo schema a cascata si scala a qualsiasi numero di timeframe: 1s → 5s → 1m → 5m → 15m → 1h → 4h → 1d.
Per una piattaforma di dati crypto che acquisisce dati da oltre 100 exchange, questa è la spina dorsale dell'intera pipeline di consegna OHLC.
Strategie di Aggiornamento
QuestDB offre tre modalità di aggiornamento, ciascuna adatta a carichi di lavoro diversi:
REFRESH IMMEDIATE innesca un aggiornamento asincrono dopo ogni transazione sulla tabella base. Ideale per dashboard in tempo reale dove la latenza inferiore al secondo è importante.
REFRESH EVERY 1h (basato su timer) raggruppa gli aggiornamenti in refresh periodici. Più adatto per l'acquisizione ad alto throughput, dove innescare un refresh su ogni micro-batch genererebbe un overhead eccessivo.
REFRESH PERIOD (LENGTH 1d TIME ZONE 'Europe/London' DELAY 2h) definisce periodi allineati al calendario. Il "delay" tiene conto dei dati in ritardo — fondamentale per i mercati che potrebbero inviare feed di correzione ore dopo la sessione di trading.
REFRESH MANUAL offre il controllo completo. La vista si aggiorna solo quando si esegue esplicitamente un comando REFRESH — utile per i flussi di lavoro di riconciliazione a fine giornata.
Il Pattern di Accelerazione con LATEST ON
Uno dei pattern più potenti combina le viste materializzate con LATEST ON per snapshot istantanei del portafoglio. Scansionare 1,3 miliardi di righe grezze per trovare il prezzo più recente di ogni simbolo richiede secondi. Ma con una vista pre-aggregata giornaliera:
CREATE MATERIALIZED VIEW trades_latest_1d AS
SELECT timestamp, symbol, side,
last(price) AS price,
last(quantity) AS quantity,
last(timestamp) AS latest
FROM trades
SAMPLE BY 1d;
La query LATEST ON scansiona circa 25.000 righe pre-aggregate invece di miliardi:
SELECT symbol, side, price, quantity, latest AS timestamp
FROM (
trades_latest_1d
LATEST ON timestamp PARTITION BY symbol, side
)
ORDER BY timestamp DESC;
Da secondi a millisecondi. È così che le dashboard di trading in produzione ottengono reattività in tempo reale su dataset massivi.
TTL: Ciclo di Vita Automatico dei Dati
Le viste materializzate supportano le policy TTL (time-to-live) per la scadenza automatica dei dati:
CREATE MATERIALIZED VIEW ohlc_1h AS (
SELECT timestamp, symbol,
avg(price) AS avg_price
FROM trades
SAMPLE BY 1h
) PARTITION BY WEEK TTL 8 WEEKS;
Questo mantiene 8 settimane di dati orari, eliminando automaticamente le partizioni più vecchie. Combinato con il motore di archiviazione a tre livelli, si ottiene un ciclo di vita naturale dei dati: i tick grezzi fluiscono attraverso WAL → archiviazione colonnare → Parquet su object storage, mentre le viste materializzate mantengono i riepiloghi pre-aggregati che le applicazioni interrogano effettivamente.
Array 2D: Analisi Nativa del Libro degli Ordini
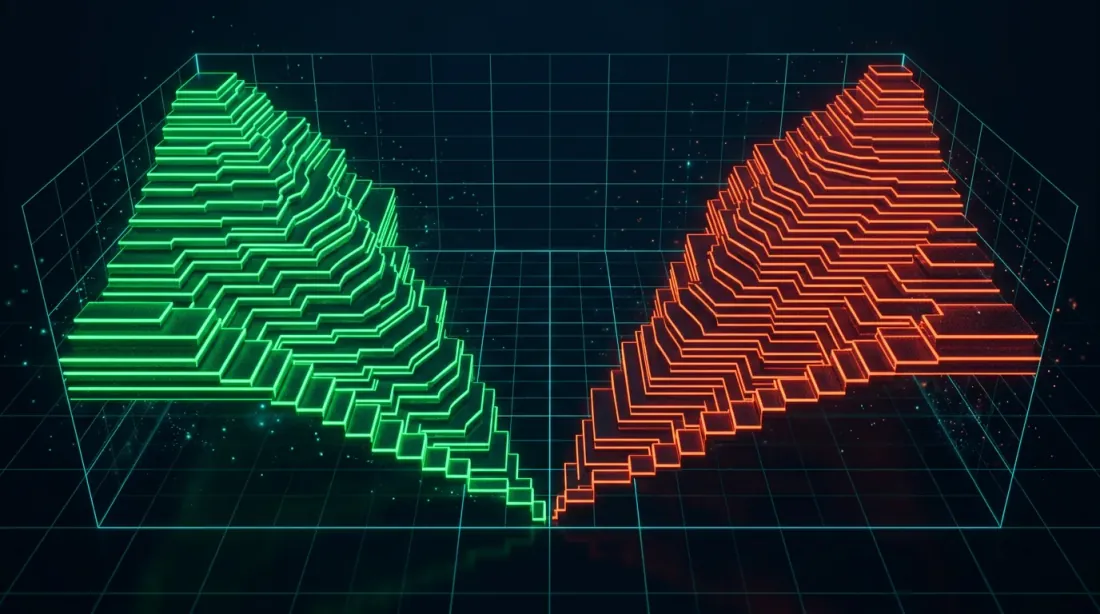 Profondità 3D del libro degli ordini: livelli bid e ask archiviati come array 2D nativi, abilitando calcoli spread ottimizzati con SIMD e analisi della liquidità
Profondità 3D del libro degli ordini: livelli bid e ask archiviati come array 2D nativi, abilitando calcoli spread ottimizzati con SIMD e analisi della liquidità
QuestDB 9.0 ha introdotto gli array N-dimensionali — veri array con forma e stride, simili a NumPy, che gestiscono operazioni comuni (slicing, trasposizione) senza copie. Per il trading, l'applicazione killer è l'archiviazione del libro degli ordini.
Il Problema Tradizionale
Storicamente, archiviare gli snapshot del libro degli ordini in un database relazionale era problematico. Si avevano due scelte: una riga per livello di prezzo (esplosione delle righe, costoso interrogare la profondità), oppure un numero fisso di colonne come bid1_price, bid1_size, bid2_price, bid2_size, ecc. (rigido, dispendioso e scomodo).
Gli array 2D di QuestDB eliminano entrambi i problemi:
CREATE TABLE market_data (
timestamp TIMESTAMP,
symbol SYMBOL,
bids DOUBLE[][],
asks DOUBLE[][]
) TIMESTAMP(timestamp) PARTITION BY HOUR;
Ogni colonna bids e asks archivia un array 2D dove la prima riga contiene i prezzi e la seconda riga contiene i volumi per ogni livello. Un libro degli ordini a 20 livelli è un singolo array compatto, non 40 colonne separate.
Analisi del Libro degli Ordini in SQL
Calcolo dello spread — la metrica più basilare e più frequentemente calcolata:
SELECT timestamp,
spread(bids[1][1], asks[1][1]) AS spread
FROM market_data
WHERE symbol = 'EURUSD'
AND timestamp IN today();
La funzione spread() è integrata e calcola la differenza tra il miglior ask e il miglior bid. bids[1][1] accede al primo elemento (miglior prezzo) della prima riga (prezzi) nell'array bids.
Per analisi più sofisticate — profondità della liquidità, squilibrio del libro degli ordini, probabilità di esecuzione a un dato livello di prezzo — lo slicing degli array e le operazioni vettorizzate rendono semplici query precedentemente complesse:
-- Trovare il livello in cui verrebbe colpito un prezzo target
-- e sommare tutti i volumi fino a quel livello
DECLARE @target := bids[1][1] * 1.01;
SELECT timestamp,
array_sum(asks[2][1:level_idx]) AS volume_to_fill
FROM market_data
WHERE symbol = 'EURUSD';
Le operazioni sugli array ottimizzate con SIMD fanno sì che questi calcoli vengano eseguiti quasi alla velocità dell'hardware, anche su milioni di snapshot.
Acquisizione di Dati Array
Le librerie client di QuestDB supportano l'acquisizione nativa di array. Il client Python si integra direttamente con gli array NumPy:
import numpy as np
from questdb.ingress import Sender
bids = np.array([[9.3, 9.2, 9.1], [100, 200, 150]]) # prezzi, volumi
asks = np.array([[9.5, 9.6, 9.7], [80, 160, 120]])
with Sender.from_conf("http::addr=localhost:9000;") as sender:
sender.row(
'market_data',
symbols={'symbol': 'EURUSD'},
columns={'bids': bids, 'asks': asks},
at=timestamp
)
Protocol Version 2 codifica gli array in forma binaria, riducendo drasticamente la larghezza di banda e l'overhead di parsing lato server rispetto ai protocolli basati su testo. Per l'acquisizione ad alta frequenza del libro degli ordini — dove si potrebbero ricevere migliaia di snapshot al secondo per simbolo — questa efficienza è fondamentale.
I client C/C++ usano array flat row-major con descrittori di forma, abilitando l'acquisizione zero-copy dalle strutture dati esistenti dei sistemi di trading.
Mettere Tutto Insieme: Architettura di Riferimento
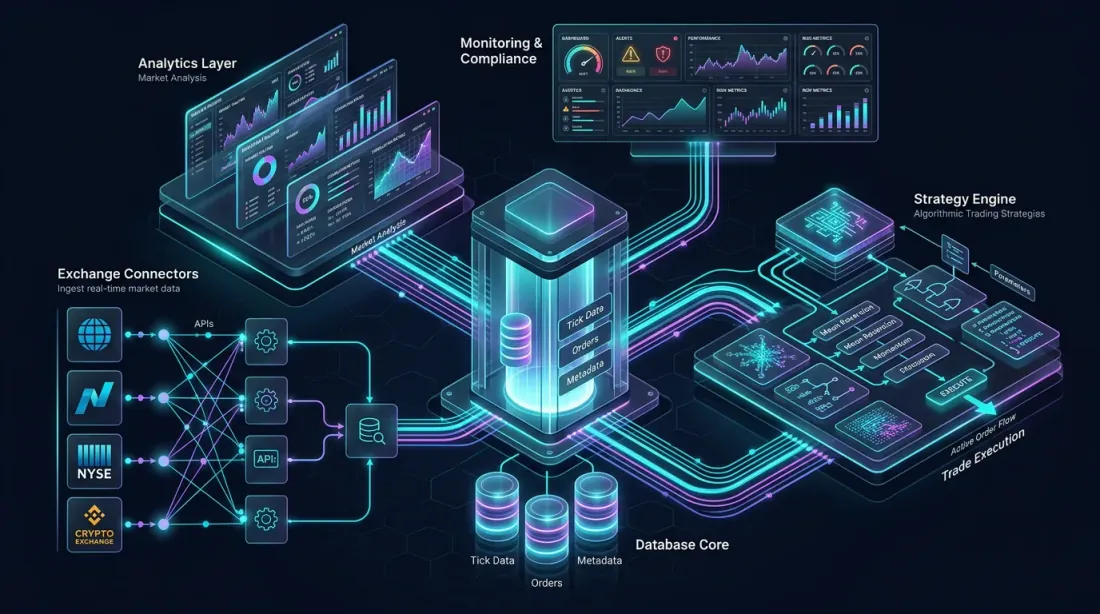 Architettura di riferimento: connettori di exchange, core del database colonnare, livello di analisi, motore di strategia e dashboard di monitoraggio — tutti interconnessi
Architettura di riferimento: connettori di exchange, core del database colonnare, livello di analisi, motore di strategia e dashboard di monitoraggio — tutti interconnessi
Progettiamo una piattaforma completa di trading algoritmico basata su QuestDB per i mercati crypto. Questa architettura gestisce l'acquisizione da più exchange, l'analisi in tempo reale, il backtesting e l'esecuzione delle strategie.
Livello di Acquisizione Dati
 Acquisizione dati: più connettori di exchange alimentano i dati di mercato in tempo reale attraverso pipeline WebSocket in QuestDB tramite ILP
Acquisizione dati: più connettori di exchange alimentano i dati di mercato in tempo reale attraverso pipeline WebSocket in QuestDB tramite ILP
Più connessioni WebSocket agli exchange (Binance, Bybit, OKX, ecc.) alimentano i dati di mercato grezzi in QuestDB tramite ILP su HTTP. Ogni connettore di exchange è un processo separato, garantendo isolamento e tolleranza ai guasti.
I flussi di dati includono: trade (timestamp, symbol, side, price, quantity), snapshot del libro degli ordini (timestamp, symbol, bids[][], asks[][]) e funding rate/liquidazioni come flussi ausiliari.
Obiettivo di throughput di acquisizione: milioni di righe al secondo tra tutti gli exchange combinati. Il WAL di QuestDB gestisce questo agevolmente, con la deduplicazione che cattura gli inevitabili duplicati provenienti da connessioni ridondanti agli exchange.
Livello di Analisi in Tempo Reale
Le viste materializzate formano il nucleo del livello di analisi:
Raw trades → ohlc_1s → ohlc_5s → ohlc_1m → ohlc_5m → ohlc_15m → ohlc_1h → ohlc_1d
Ogni livello si aggiorna in modo incrementale. Una dashboard Grafana connessa tramite il plugin nativo di QuestDB interroga queste viste per i grafici a candele, con tempi di risposta inferiori a 5ms indipendentemente da quanti dati storici esistano.
Ulteriori viste materializzate calcolano: VWAP (prezzo medio ponderato per volume) per simbolo al giorno, stime della volatilità rolling e monitoraggio dello spread cross-exchange.
Le query LATEST ON su viste pre-aggregate alimentano la dashboard del portafoglio in tempo reale — mostrando le posizioni correnti, il P&L non realizzato e l'esposizione per exchange.
Motore di Strategia
 Motore di strategia: il calcolo degli indicatori in tempo reale alimenta il processo decisionale algoritmico, con percorsi di esecuzione buy/sell ottimizzati dalle viste materializzate
Motore di strategia: il calcolo degli indicatori in tempo reale alimenta il processo decisionale algoritmico, con percorsi di esecuzione buy/sell ottimizzati dalle viste materializzate
Le strategie di trading interrogano QuestDB per lo stato attuale del mercato e i pattern storici. Il protocollo PG wire di QuestDB significa che qualsiasi linguaggio con un driver PostgreSQL può connettersi: Python per le strategie di ricerca, Rust o C++ per l'esecuzione sensibile alla latenza.
Pattern di query chiave per le strategie: ASOF JOIN per abbinare le esecuzioni alle condizioni di mercato al momento del fill, WINDOW JOIN per calcolare metriche a breve orizzonte attorno a ogni evento e funzioni window per il calcolo degli indicatori in tempo reale (RSI, Bollinger Bands, ATR).
Per le strategie critiche per la latenza, le viste materializzate pre-calcolate minimizzano il tempo di query. Un grid bot che monitora 50 simboli non ha bisogno di calcolare 50 medie mobili separate ad ogni tick — le legge da una vista materializzata.
Pipeline di Backtesting
I dati storici risiedono in Parquet su object storage. QuestDB li interroga in modo trasparente, ma per carichi di lavoro di backtesting intensivi, i dati possono anche essere letti direttamente da Polars, Pandas o DuckDB — bypassando completamente il database.
Questo pattern di doppio accesso è potente: la strategia live utilizza l'interfaccia SQL di QuestDB per decisioni in tempo reale, mentre il framework di backtesting legge gli stessi dati tramite Parquet/Arrow per l'elaborazione batch. Gli stessi dati, due percorsi di accesso ottimizzati.
Monitoraggio e Analisi Post-Trade
HORIZON JOIN alimenta la pipeline di analisi post-trade:
- Analisi dello slippage: Confronta il prezzo di esecuzione con il mid-price al momento del fill
- Curve di markout: Traccia l'evoluzione del prezzo 1s, 5s, 30s, 60s dopo ogni fill
- Implementation shortfall: Scompone i costi di esecuzione in spread, impatto temporaneo e impatto permanente
- Venue scoring: Confronta la qualità dei fill tra gli exchange per ottimizzare il routing degli ordini
Queste analisi vengono eseguite come query pianificate, scrivendo i risultati in tabelle dedicate che alimentano le dashboard di monitoraggio. Le regole di allerta si attivano sulle anomalie — picchi improvvisi di slippage, pattern di markout insoliti o qualità dei fill degradata su venue specifiche.
Considerazioni sulle Prestazioni
 Ottimizzazione delle prestazioni in produzione: monitoraggio di latenza, throughput e memoria accanto al ciclo di vita dei dati hot-warm-cold
Ottimizzazione delle prestazioni in produzione: monitoraggio di latenza, throughput e memoria accanto al ciclo di vita dei dati hot-warm-cold
Alcune note pratiche dagli deployment in produzione:
Dimensionamento delle partizioni: Per i dati di tick crypto con milioni di righe al giorno, PARTITION BY HOUR è tipicamente ottimale. Questo mantiene le singole partizioni gestibili sia per l'archiviazione che per le prestazioni delle query.
Cascata delle viste materializzate: Non creare troppi livelli intermedi. Ogni livello aggiunge latenza di aggiornamento. Per la maggior parte dei casi d'uso, 3-4 livelli (1s → 1m → 15m → 1d) offrono un buon equilibrio tra prestazioni delle query e freschezza dei dati.
Overhead della deduplicazione: Abilita la deduplicazione sulle tabelle con sorgenti di dati ridondanti. Il costo è minimo per i dati con timestamp univoci, ma aumenta con molte righe allo stesso timestamp che richiedono deduplicazione a livello di colonna.
Allocazione della memoria: Il motore zero-GC di QuestDB è efficiente, ma alloca abbastanza memoria per le partizioni calde e la cache di scrittura. Monitora tramite l'endpoint delle metriche integrato.
Scelta del protocollo client: Usa ILP su HTTP per l'acquisizione (con retry automatici e health check). Usa PG wire per le query. ILP Protocol Version 2 (codifica binaria) è significativamente più efficiente per i dati array e i valori double ad alto throughput.
QuestDB vs. le Alternative
 Panorama competitivo: QuestDB posizionato rispetto a TimescaleDB, ClickHouse, InfluxDB e kdb+ nelle dimensioni chiave delle capacità
Panorama competitivo: QuestDB posizionato rispetto a TimescaleDB, ClickHouse, InfluxDB e kdb+ nelle dimensioni chiave delle capacità
Un breve posizionamento rispetto ai database comunemente usati nel trading:
vs. TimescaleDB: TimescaleDB è PostgreSQL con estensioni time-series. Eredita la generalità di PG ma anche il suo overhead. Il motore colonnare nativo di QuestDB e l'esecuzione SIMD offrono prestazioni di query significativamente migliori sui carichi di lavoro time-series, e funzionalità come ASOF JOIN non hanno un equivalente diretto in TimescaleDB.
vs. ClickHouse: ClickHouse eccelle nelle query analitiche su dataset massivi. Ma non è stato progettato specificamente per le time-series — nessun ASOF JOIN nativo, nessun SAMPLE BY con FILL, nessun array 2D per i libri degli ordini. Per carichi di lavoro OLAP + time-series misti, ClickHouse potrebbe vincere; per dati di trading puri, QuestDB è più ergonomico.
vs. InfluxDB: InfluxDB ha limitazioni di alta cardinalità che sono problematiche per i dati crypto multi-exchange. Il suo linguaggio di query (Flux, ora deprecato; InfluxQL) manca dell'espressività delle estensioni SQL di QuestDB. Le prestazioni su query storiche di grandi dimensioni sono generalmente peggiori.
vs. kdb+/q: Lo standard de facto per l'HFT. kdb+ è più veloce per certe operazioni vettoriali single-threaded e il suo linguaggio q è incredibilmente conciso. Ma è proprietario, costoso e ha una curva di apprendimento ripida. QuestDB offre l'80-90% delle capacità a una frazione del costo, con SQL standard e licenza open-source.
Conclusione: Un Database che Comprende il Trading
In questi tre articoli abbiamo trattato l'architettura di QuestDB (archiviazione a tre livelli con WAL, colonnare e Parquet), le sue estensioni SQL (SAMPLE BY, ASOF JOIN, HORIZON JOIN, WINDOW JOIN, LATEST ON, TWAP) e le sue applicazioni pratiche (viste materializzate, array del libro degli ordini, architettura di riferimento).
Il filo conduttore è coerente: QuestDB è stato progettato esattamente per i carichi di lavoro che il trading algoritmico produce. Non ti costringe a lavorare attorno al database — al contrario, i suoi primitivi si mappano direttamente sui concetti di trading. L'aggregazione OHLC è un'istruzione in una riga. L'allineamento trade-to-quote è un singolo JOIN. L'analisi post-trade è un HORIZON JOIN, non una procedura PL/SQL di più pagine.
Per i team che costruiscono infrastrutture di trading — che si tratti di una piattaforma di dati di mercato crypto, un ambiente di ricerca quantitativa o un motore di trading algoritmico completo — QuestDB merita una valutazione seria. La versione open-source copre la maggior parte dei casi d'uso, e l'edizione Enterprise colma le lacune per gli ambienti regolamentati.
Il panorama delle infrastrutture di dati finanziari si sta evolvendo rapidamente. I database che parlano il linguaggio dei mercati vinceranno. QuestDB è fluente.
Buon trading, e che le vostre latenze siano basse.
Citazione
@software{soloviov2025questdb_algotrading_p3,
author = {Soloviov, Eugen},
title = {QuestDB for Algorithmic Trading: From Order Books to Production Architecture},
year = {2025},
url = {https://marketmaker.cc/it/blog/post/questdb-algotrading-production},
version = {0.1.0},
description = {Viste materializzate, analisi del libro degli ordini con array 2D e architettura di riferimento per una piattaforma di trading algoritmico basata su QuestDB.}
}
Autori

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Leggi di Più

QuestDB per il Trading Algoritmico: Le Estensioni SQL che Cambiano le Regole del Gioco

QuestDB per il Trading Algoritmico: Un'Architettura che Parla il Linguaggio dei Mercati