QuestDB สำหรับการเทรดแบบอัลกอริทึม: จาก Order Book สู่สถาปัตยกรรมระดับ Production

ตอนที่ 3 จาก 3 — อ่านได้ใน RU · ZH
ข้อสงวนสิทธิ์: ข้อมูลที่นำเสนอในบทความนี้มีวัตถุประสงค์เพื่อการศึกษาและให้ข้อมูลเท่านั้น และไม่ถือเป็นคำแนะนำทางการเงิน การลงทุน หรือการเทรด การเทรดสกุลเงินดิจิทัลมีความเสี่ยงในการสูญเสียอย่างมีนัยสำคัญ
ยินดีต้อนรับสู่ตอนสุดท้ายของซีรีส์ QuestDB ของเรา ใน ตอนที่ 1 เราได้ครอบคลุมสถาปัตยกรรมการจัดเก็บข้อมูล ใน ตอนที่ 2 เราได้สำรวจส่วนขยาย SQL ตอนนี้มาประมวลทุกอย่างเข้าด้วยกัน: materialized views สำหรับการวิเคราะห์แบบเรียลไทม์, การจัดเก็บ order book แบบ native ด้วย 2D arrays และสถาปัตยกรรมอ้างอิงสำหรับแพลตฟอร์มการเทรดแบบอัลกอริทึมระดับ production
Materialized Views: การวิเคราะห์ที่คำนวณล่วงหน้าด้วยความเร็วสาย
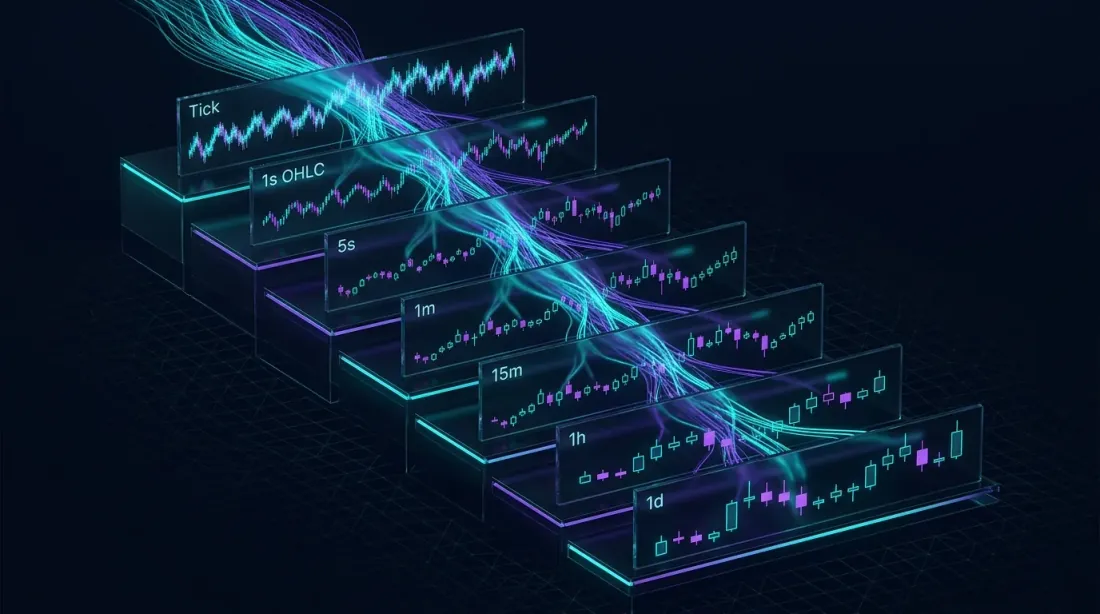 Cascading materialized views: raw tick data ไหลผ่านชั้นการรวมกลุ่มที่หยาบขึ้นเรื่อยๆ โดยแต่ละระดับประมวลผลชุดข้อมูลที่เล็กลงอย่างมาก
Cascading materialized views: raw tick data ไหลผ่านชั้นการรวมกลุ่มที่หยาบขึ้นเรื่อยๆ โดยแต่ละระดับประมวลผลชุดข้อมูลที่เล็กลงอย่างมาก
ถ้า SAMPLE BY คือคำสั่ง query ที่ใช้บ่อยที่สุดของ QuestDB แล้ว materialized views ก็คือการปรับแต่งที่มีผลกระทบมากที่สุด แนวคิดนั้นเรียบง่าย: แทนที่จะคำนวณการรวมกลุ่ม OHLCV ในทุกครั้งที่รีเฟรช dashboard หรือเรียก API ให้คำนวณล่วงหน้าครั้งเดียวและอัปเดตผลลัพธ์อย่างต่อเนื่อง
Materialized View ของ OHLC พื้นฐาน
CREATE MATERIALIZED VIEW trades_OHLC_15m
WITH BASE 'trades'
REFRESH IMMEDIATE
AS
SELECT timestamp, symbol,
first(price) AS open,
max(price) AS high,
min(price) AS low,
last(price) AS close,
sum(quantity) AS volume
FROM trades
SAMPLE BY 15m;
นี่คือคำนิยามทั้งหมด ทุกครั้งที่มีการแทรกแถวใหม่ลงในตาราง trades QuestDB จะรีเฟรช view นี้โดยอัตโนมัติและแบบเพิ่มทีละส่วน ไม่ใช่การคำนวณใหม่ทั้งหมด — มีเพียง time bucket ที่ได้รับผลกระทบเท่านั้นที่ถูกอัปเดต การ query ต่อ trades_OHLC_15m กลายเป็นการค้นหาง่ายๆ บนชุดข้อมูลขนาดเล็กที่รวมกลุ่มไว้แล้ว
ความแตกต่างด้านประสิทธิภาพนั้นชัดเจนมาก บนตารางที่มีหลายพันล้านแถว การ query ตาราง base สำหรับข้อมูล OHLC อาจใช้เวลา 200ms Materialized view คืนผลลัพธ์เดียวกันในเวลาน้อยกว่า 5ms เมื่อมีผู้ใช้ dashboard พร้อมกันหลายคน นี่ไม่ใช่แค่การปรับแต่ง — มันคือความแตกต่างระหว่างระบบที่ตอบสนองได้กับระบบที่ล่ม
Cascaded Views: หลาย Timeframe จากแหล่งข้อมูลเดียว
นี่คือจุดที่ materialized views มีความสง่างามทางสถาปัตยกรรม คุณสามารถเชื่อมต่อพวกมันได้ — แต่ละ view ป้อนข้อมูลให้กับอันถัดไป สร้างลำดับชั้นของระดับการรวมกลุ่มจากแหล่งข้อมูล raw เดียว:
-- 1-second bars จาก raw trades
CREATE MATERIALIZED VIEW ohlc_1s AS
SELECT timestamp, symbol,
first(price) AS open, max(price) AS high,
min(price) AS low, last(price) AS close,
sum(quantity) AS volume
FROM trades
SAMPLE BY 1s;
-- 5-second bars จาก 1-second bars
CREATE MATERIALIZED VIEW ohlc_5s AS
SELECT timestamp, symbol,
first(open) AS open, max(high) AS high,
min(low) AS low, last(close) AS close,
sum(volume) AS volume
FROM ohlc_1s
SAMPLE BY 5s;
-- 1-minute bars จาก 5-second bars
CREATE MATERIALIZED VIEW ohlc_1m AS
SELECT timestamp, symbol,
first(open) AS open, max(high) AS high,
min(low) AS low, last(close) AS close,
sum(volume) AS volume
FROM ohlc_5s
SAMPLE BY 1m;
แต่ละระดับประมวลผลชุดข้อมูลที่เล็กกว่าระดับก่อนหน้าอย่างมาก View ขนาด 1 นาทีไม่ได้สแกน raw trades — มันอ่านเพียง 5-second bars ที่รวมกลุ่มไว้แล้ว รูปแบบการเรียงต่อกันนี้ขยายไปได้ทุกจำนวน timeframe: 1s → 5s → 1m → 5m → 15m → 1h → 4h → 1d
สำหรับแพลตฟอร์มข้อมูล crypto ที่รับข้อมูลจากกว่า 100 exchanges นี่คือกระดูกสันหลังของ pipeline การส่งมอบ OHLC ทั้งหมด
กลยุทธ์การ Refresh
QuestDB มีโหมดการ refresh สามแบบ แต่ละแบบเหมาะกับ workload ที่แตกต่างกัน:
REFRESH IMMEDIATE ทริกเกอร์การ refresh แบบ async หลังจากทุก transaction ของตาราง base เหมาะที่สุดสำหรับ dashboard แบบเรียลไทม์ที่ latency ต่ำกว่า 1 วินาทีมีความสำคัญ
REFRESH EVERY 1h (แบบตั้งเวลา) รวมการอัปเดตเป็นการ refresh เป็นระยะ ดีกว่าสำหรับการนำเข้าข้อมูลปริมาณสูงที่การทริกเกอร์ refresh ในทุก micro-batch จะสร้าง overhead
REFRESH PERIOD (LENGTH 1d TIME ZONE 'Europe/London' DELAY 2h) กำหนด period ที่สอดคล้องกับปฏิทิน "delay" รองรับข้อมูลที่มาช้า — สำคัญมากสำหรับตลาดที่อาจส่ง correction feeds หลายชั่วโมงหลังจากเซสชันการเทรด
REFRESH MANUAL ให้การควบคุมเต็มที่ View จะอัปเดตเฉพาะเมื่อคุณรันคำสั่ง REFRESH อย่างชัดแจ้ง — มีประโยชน์สำหรับ workflow การกระทบยอดสิ้นวัน
รูปแบบการเร่งความเร็วด้วย LATEST ON
รูปแบบที่ทรงพลังที่สุดอย่างหนึ่งรวม materialized views เข้ากับ LATEST ON สำหรับ snapshot พอร์ตโฟลิโอทันที การสแกน 1.3 พันล้านแถวดิบเพื่อหาราคาล่าสุดของแต่ละสัญลักษณ์ใช้เวลาหลายวินาที แต่ด้วย view ที่รวมกลุ่มรายวันล่วงหน้า:
CREATE MATERIALIZED VIEW trades_latest_1d AS
SELECT timestamp, symbol, side,
last(price) AS price,
last(quantity) AS quantity,
last(timestamp) AS latest
FROM trades
SAMPLE BY 1d;
คำสั่ง query LATEST ON สแกนประมาณ 25,000 แถวที่รวมกลุ่มไว้แล้วแทนที่จะเป็นหลายพันล้าน:
SELECT symbol, side, price, quantity, latest AS timestamp
FROM (
trades_latest_1d
LATEST ON timestamp PARTITION BY symbol, side
)
ORDER BY timestamp DESC;
จากหลายวินาทีลดเหลือมิลลิวินาที นี่คือวิธีที่ trading dashboard ระดับ production บรรลุการตอบสนองแบบเรียลไทม์บนชุดข้อมูลขนาดมหึมา
TTL: วงจรชีวิตข้อมูลอัตโนมัติ
Materialized views รองรับ policy TTL (time-to-live) สำหรับการหมดอายุข้อมูลอัตโนมัติ:
CREATE MATERIALIZED VIEW ohlc_1h AS (
SELECT timestamp, symbol,
avg(price) AS avg_price
FROM trades
SAMPLE BY 1h
) PARTITION BY WEEK TTL 8 WEEKS;
คำสั่งนี้เก็บข้อมูลรายชั่วโมง 8 สัปดาห์ โดยลบ partition เก่าออกโดยอัตโนมัติ ผสานกับ storage engine สามระดับ คุณจะได้วงจรชีวิตข้อมูลแบบธรรมชาติ: raw ticks ไหลผ่าน WAL → columnar storage → Parquet บน object storage ในขณะที่ materialized views รักษาสรุปที่รวมกลุ่มล่วงหน้าที่แอปพลิเคชันของคุณ query จริงๆ
2D Arrays: การวิเคราะห์ Order Book แบบ Native
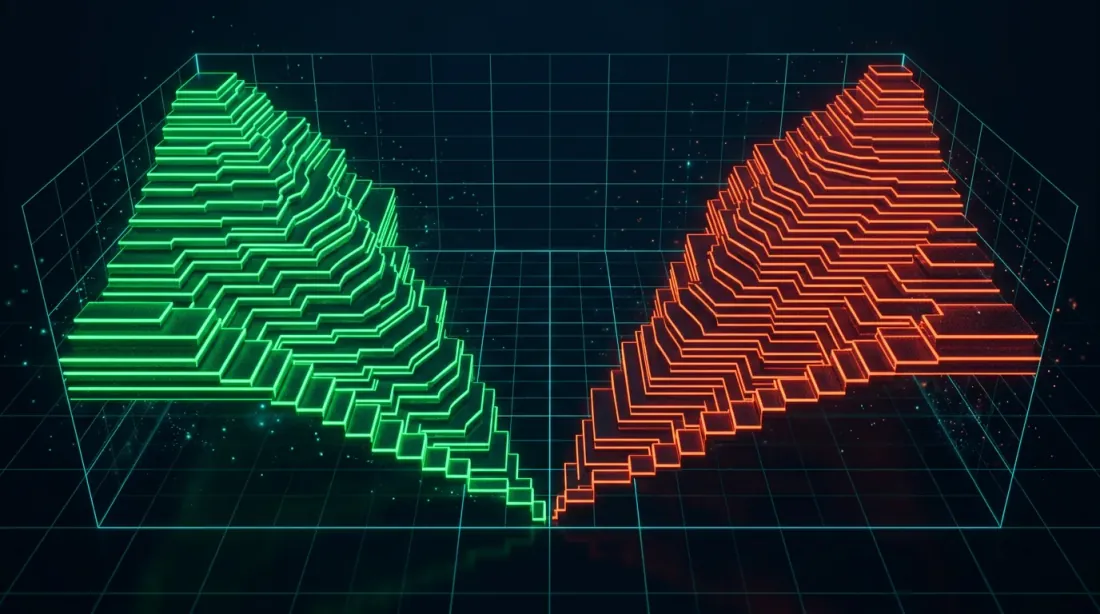 3D order book depth: ระดับ bid และ ask จัดเก็บเป็น native 2D arrays ช่วยให้การคำนวณ spread ที่ปรับแต่งด้วย SIMD และการวิเคราะห์สภาพคล่องทำได้อย่างมีประสิทธิภาพ
3D order book depth: ระดับ bid และ ask จัดเก็บเป็น native 2D arrays ช่วยให้การคำนวณ spread ที่ปรับแต่งด้วย SIMD และการวิเคราะห์สภาพคล่องทำได้อย่างมีประสิทธิภาพ
QuestDB 9.0 แนะนำ N-dimensional arrays — arrays จริงที่มีรูปทรงและ stride แบบ NumPy ที่จัดการการดำเนินการทั่วไป (slicing, transposing) โดยไม่ต้องคัดลอก สำหรับการเทรด แอปพลิเคชันหลักคือการจัดเก็บ order book
ปัญหาดั้งเดิม
ในอดีต การจัดเก็บ order book snapshots ในฐานข้อมูลเชิงสัมพันธ์เป็นเรื่องที่เจ็บปวด คุณมีสองตัวเลือก: หนึ่งแถวต่อหนึ่งระดับราคา (การระเบิดของแถว ค้นหา depth ได้ยาก) หรือจำนวนคอลัมน์คงที่เช่น bid1_price, bid1_size, bid2_price, bid2_size เป็นต้น (แข็งกระด้าง, สิ้นเปลือง และน่าเกลียด)
2D arrays ของ QuestDB ขจัดทั้งสองปัญหา:
CREATE TABLE market_data (
timestamp TIMESTAMP,
symbol SYMBOL,
bids DOUBLE[][],
asks DOUBLE[][]
) TIMESTAMP(timestamp) PARTITION BY HOUR;
แต่ละคอลัมน์ bids และ asks จัดเก็บ 2D array ที่แถวแรกมีราคาและแถวที่สองมี volume ในแต่ละระดับ Order book 20 ระดับคือ array compact เดียว ไม่ใช่ 40 คอลัมน์แยกกัน
การวิเคราะห์ Order Book ใน SQL
การคำนวณ spread — metric พื้นฐานและคำนวณบ่อยที่สุด:
SELECT timestamp,
spread(bids[1][1], asks[1][1]) AS spread
FROM market_data
WHERE symbol = 'EURUSD'
AND timestamp IN today();
ฟังก์ชัน spread() เป็น built-in ที่คำนวณความแตกต่างระหว่าง best ask และ best bid bids[1][1] เข้าถึงองค์ประกอบแรก (ราคาที่ดีที่สุด) ของแถวแรก (ราคา) ใน bids array
สำหรับการวิเคราะห์ที่ซับซ้อนกว่า — ความลึกสภาพคล่อง, ความไม่สมดุลของ order book, ความน่าจะเป็นในการดำเนินการที่ระดับราคาที่กำหนด — การ slicing array และการดำเนินการ vectorized ทำให้ query ที่ซับซ้อนก่อนหน้านี้ตรงไปตรงมา:
-- หาระดับที่ราคาเป้าหมายจะถูก hit
-- และรวม volume ทั้งหมดจนถึงระดับนั้น
DECLARE @target := bids[1][1] * 1.01;
SELECT timestamp,
array_sum(asks[2][1:level_idx]) AS volume_to_fill
FROM market_data
WHERE symbol = 'EURUSD';
การดำเนินการ array ที่ปรับแต่งด้วย SIMD หมายความว่าการคำนวณเหล่านี้ทำงานด้วยความเร็วใกล้เคียงฮาร์ดแวร์ แม้จะผ่าน snapshot หลายล้านรายการ
การนำเข้าข้อมูล Array
ไลบรารี client ของ QuestDB รองรับการนำเข้า array แบบ native ไคลเอนต์ Python ผสานรวมโดยตรงกับ NumPy arrays:
import numpy as np
from questdb.ingress import Sender
bids = np.array([[9.3, 9.2, 9.1], [100, 200, 150]]) # prices, volumes
asks = np.array([[9.5, 9.6, 9.7], [80, 160, 120]])
with Sender.from_conf("http::addr=localhost:9000;") as sender:
sender.row(
'market_data',
symbols={'symbol': 'EURUSD'},
columns={'bids': bids, 'asks': asks},
at=timestamp
)
Protocol Version 2 เข้ารหัส array ในรูปแบบ binary ลด bandwidth และ overhead การ parse ฝั่งเซิร์ฟเวอร์อย่างมากเมื่อเปรียบเทียบกับ protocol แบบ text สำหรับการนำเข้า order book ความถี่สูง — ที่คุณอาจรับ snapshot หลายพันรายการต่อวินาทีต่อสัญลักษณ์ — ประสิทธิภาพนี้มีความสำคัญ
ไคลเอนต์ C/C++ ใช้ flat row-major arrays พร้อม shape descriptors ช่วยให้การนำเข้าแบบ zero-copy จากโครงสร้างข้อมูลระบบการเทรดที่มีอยู่
ประมวลรวมทุกอย่าง: สถาปัตยกรรมอ้างอิง
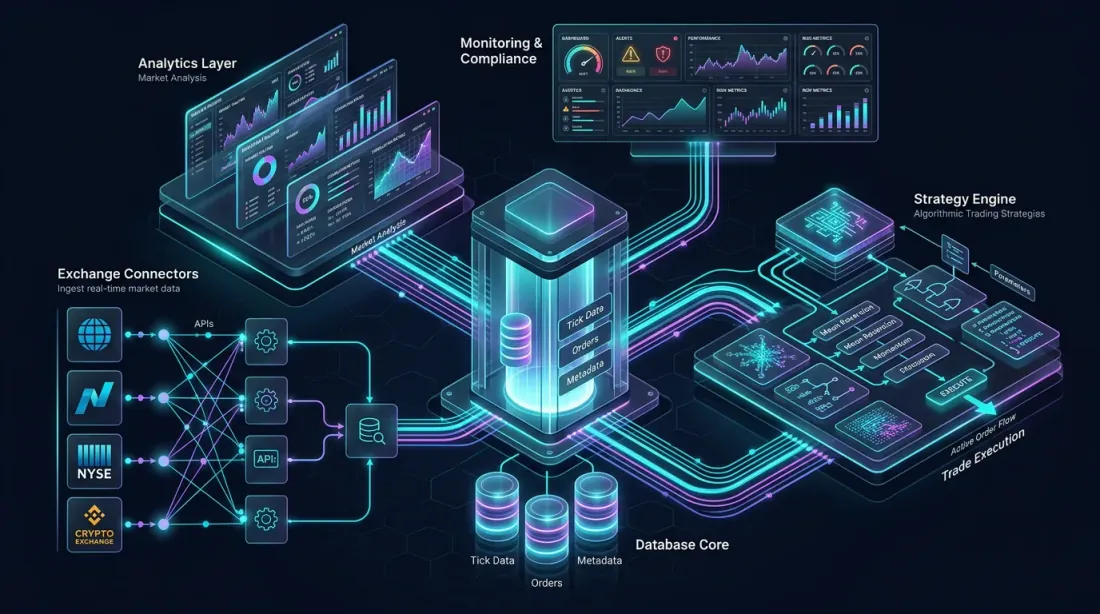 สถาปัตยกรรมอ้างอิง: exchange connectors, แกนฐานข้อมูลแบบ columnar, analytics layer, strategy engine และ monitoring dashboards — ทั้งหมดเชื่อมต่อกัน
สถาปัตยกรรมอ้างอิง: exchange connectors, แกนฐานข้อมูลแบบ columnar, analytics layer, strategy engine และ monitoring dashboards — ทั้งหมดเชื่อมต่อกัน
มาออกแบบแพลตฟอร์มการเทรดแบบอัลกอริทึมที่ขับเคลื่อนด้วย QuestDB ครบวงจรสำหรับตลาด crypto สถาปัตยกรรมนี้จัดการการนำเข้าจากหลาย exchanges, analytics แบบเรียลไทม์, backtesting และการดำเนินกลยุทธ์
Data Ingestion Layer
 Data ingestion: exchange connectors หลายตัวส่ง market data แบบเรียลไทม์ผ่าน WebSocket pipelines เข้า QuestDB ผ่าน ILP
Data ingestion: exchange connectors หลายตัวส่ง market data แบบเรียลไทม์ผ่าน WebSocket pipelines เข้า QuestDB ผ่าน ILP
การเชื่อมต่อ WebSocket หลายตัวกับ exchanges (Binance, Bybit, OKX ฯลฯ) ส่ง raw market data เข้า QuestDB ผ่าน ILP over HTTP Exchange connector แต่ละตัวเป็น process แยกกัน ให้การแยกตัวและความทนทานต่อความล้มเหลว
Data streams ประกอบด้วย: trades (timestamp, symbol, side, price, quantity), order book snapshots (timestamp, symbol, bids[][], asks[][]) และ funding rates/liquidations เป็น auxiliary streams
เป้าหมายปริมาณการนำเข้า: หลายล้านแถวต่อวินาทีจากทุก exchanges รวมกัน WAL ของ QuestDB จัดการสิ่งนี้ได้อย่างสบาย โดย deduplication จับ duplicate ที่หลีกเลี่ยงไม่ได้จากการเชื่อมต่อ exchange ที่ซ้ำซ้อน
Real-Time Analytics Layer
Materialized views ก่อตัวเป็นแกนหลักของ analytics layer:
Raw trades → ohlc_1s → ohlc_5s → ohlc_1m → ohlc_5m → ohlc_15m → ohlc_1h → ohlc_1d
แต่ละระดับ refresh แบบเพิ่มทีละส่วน Grafana dashboard ที่เชื่อมต่อผ่าน QuestDB native plugin query views เหล่านี้สำหรับ candlestick charts พร้อมเวลาตอบสนองต่ำกว่า 5ms โดยไม่คำนึงว่ามีข้อมูลประวัติมากแค่ไหน
Materialized views เพิ่มเติมคำนวณ: VWAP (volume-weighted average price) ต่อสัญลักษณ์ต่อวัน, การประมาณค่า volatility แบบ rolling และการติดตาม spread ข้าม exchanges
LATEST ON queries ต่อ views ที่รวมกลุ่มล่วงหน้าขับเคลื่อน real-time portfolio dashboard — แสดง positions ปัจจุบัน, unrealized P&L และการกระจาย exposure ต่อ exchange
Strategy Engine
 Strategy engine: การคำนวณ indicator แบบเรียลไทม์ป้อนการตัดสินใจแบบอัลกอริทึม พร้อมเส้นทางการดำเนินการ buy/sell ที่ปรับแต่งด้วย materialized views
Strategy engine: การคำนวณ indicator แบบเรียลไทม์ป้อนการตัดสินใจแบบอัลกอริทึม พร้อมเส้นทางการดำเนินการ buy/sell ที่ปรับแต่งด้วย materialized views
กลยุทธ์การเทรด query QuestDB สำหรับสถานะตลาดปัจจุบันและรูปแบบประวัติ PG wire protocol ของ QuestDB หมายความว่าภาษาใดก็ตามที่มี PostgreSQL driver สามารถเชื่อมต่อได้: Python สำหรับกลยุทธ์วิจัย, Rust หรือ C++ สำหรับการดำเนินการที่ sensitive ต่อ latency
รูปแบบ query หลักสำหรับกลยุทธ์: ASOF JOIN สำหรับจับคู่การดำเนินการกับสภาพตลาดในเวลา fill, WINDOW JOIN สำหรับคำนวณ metrics ระยะสั้นรอบๆ แต่ละเหตุการณ์ และ window functions สำหรับการคำนวณ indicator แบบเรียลไทม์ (RSI, Bollinger Bands, ATR)
สำหรับกลยุทธ์ที่ sensitive ต่อ latency materialized views ที่คำนวณล่วงหน้าลด query time ให้น้อยที่สุด Grid bot ที่ติดตาม 50 สัญลักษณ์ไม่จำเป็นต้องคำนวณ moving average 50 รายการแยกกันในทุก tick — มันอ่านจาก materialized view
Backtesting Pipeline
ข้อมูลประวัติอยู่ใน Parquet บน object storage QuestDB query ได้อย่างโปร่งใส แต่สำหรับ backtesting workload หนัก ข้อมูลยังสามารถอ่านได้โดยตรงโดย Polars, Pandas หรือ DuckDB — ข้ามฐานข้อมูลไปเลย
รูปแบบการเข้าถึงสองช่องทางนี้มีพลังมาก: กลยุทธ์ live ใช้ SQL interface ของ QuestDB สำหรับการตัดสินใจแบบเรียลไทม์ ในขณะที่ backtesting framework อ่านข้อมูลเดียวกันผ่าน Parquet/Arrow สำหรับการประมวลผล batch ข้อมูลเดียวกัน สองเส้นทางการเข้าถึงที่ปรับแต่งสำหรับแต่ละงาน
Monitoring และการวิเคราะห์หลังการเทรด
HORIZON JOIN ขับเคลื่อน post-trade analysis pipeline:
- การวิเคราะห์ slippage: เปรียบเทียบราคาดำเนินการกับ mid-price ในเวลา fill
- Markout curves: ติดตามการเปลี่ยนแปลงราคา 1s, 5s, 30s, 60s หลังจากแต่ละ fill
- Implementation shortfall: แยกต้นทุนการดำเนินการออกเป็น spread, temporary impact และ permanent impact
- Venue scoring: เปรียบเทียบคุณภาพ fill ข้าม exchanges เพื่อปรับแต่งการกำหนดเส้นทาง order
การวิเคราะห์เหล่านี้รันเป็น scheduled queries เขียนผลลัพธ์ไปยังตารางเฉพาะที่ป้อน monitoring dashboards กฎ alert ทริกเกอร์เมื่อพบความผิดปกติ — การพุ่งขึ้นของ slippage กะทันหัน, รูปแบบ markout ที่ผิดปกติ หรือคุณภาพ fill ที่ลดลงบน venue เฉพาะ
การพิจารณาด้านประสิทธิภาพ
 การปรับแต่งประสิทธิภาพ production: การติดตาม latency, throughput และหน่วยความจำควบคู่กับวงจรชีวิตข้อมูล hot-warm-cold
การปรับแต่งประสิทธิภาพ production: การติดตาม latency, throughput และหน่วยความจำควบคู่กับวงจรชีวิตข้อมูล hot-warm-cold
บันทึกการปฏิบัติจากการ deploy ระดับ production:
ขนาด Partition: สำหรับข้อมูล crypto tick ที่มีหลายล้านแถวต่อวัน PARTITION BY HOUR มักเหมาะสมที่สุด สิ่งนี้ทำให้ partition แต่ละอันจัดการได้ทั้งสำหรับ storage และประสิทธิภาพ query
การ cascade ของ Materialized view: อย่าสร้างระดับกลางมากเกินไป แต่ละระดับเพิ่ม latency การ refresh สำหรับ use case ส่วนใหญ่ 3-4 ระดับ (1s → 1m → 15m → 1d) ให้ความสมดุลที่ดีระหว่างประสิทธิภาพ query และความสดใหม่ของข้อมูล
Overhead ของ deduplication: เปิดใช้ deduplication บนตารางที่มีแหล่งข้อมูลซ้ำซ้อน ต้นทุนน้อยมากสำหรับข้อมูล unique-timestamp แต่เพิ่มขึ้นเมื่อมีแถว same-timestamp จำนวนมากที่ต้องการ deduplication ระดับคอลัมน์
การจัดสรรหน่วยความจำ: zero-GC engine ของ QuestDB มีประสิทธิภาพ แต่จัดสรรหน่วยความจำให้เพียงพอสำหรับ hot partitions และ write cache ติดตามผ่าน built-in metrics endpoint
การเลือก client protocol: ใช้ ILP over HTTP สำหรับการนำเข้า (พร้อม automatic retries และ health checks) ใช้ PG wire สำหรับ queries ILP Protocol Version 2 (binary encoding) มีประสิทธิภาพสูงกว่าอย่างมีนัยสำคัญสำหรับข้อมูล array และค่า double ปริมาณสูง
QuestDB เทียบกับทางเลือกอื่น
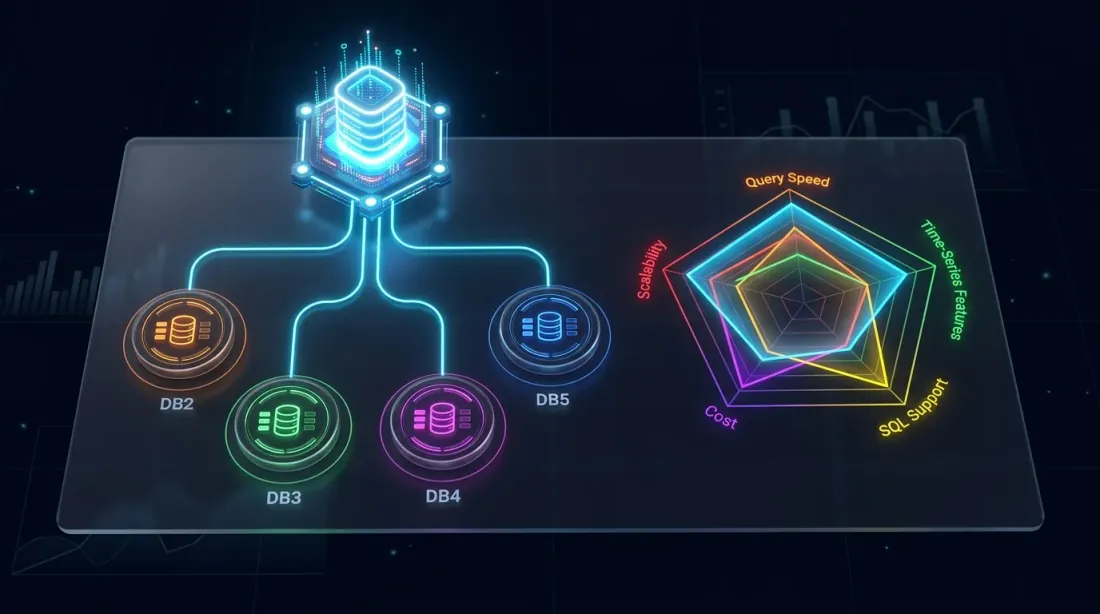 ภูมิทัศน์การแข่งขัน: QuestDB เทียบกับ TimescaleDB, ClickHouse, InfluxDB และ kdb+ ในมิติความสามารถหลัก
ภูมิทัศน์การแข่งขัน: QuestDB เทียบกับ TimescaleDB, ClickHouse, InfluxDB และ kdb+ ในมิติความสามารถหลัก
การวางตำแหน่งโดยย่อเทียบกับฐานข้อมูลที่ใช้กันทั่วไปในการเทรด:
เทียบกับ TimescaleDB: TimescaleDB คือ PostgreSQL ที่มี time-series extensions มันรับ generality ของ PG แต่ก็รับ overhead ของมันด้วย native columnar engine และ SIMD execution ของ QuestDB ให้ประสิทธิภาพ query ที่ดีกว่าอย่างมีนัยสำคัญใน time-series workloads และฟีเจอร์อย่าง ASOF JOIN ไม่มี TimescaleDB equivalent โดยตรง
เทียบกับ ClickHouse: ClickHouse เก่งในการ query เชิงวิเคราะห์บนชุดข้อมูลขนาดมหึมา แต่มันไม่ได้ออกแบบมาเพื่อ time-series โดยเฉพาะ — ไม่มี native ASOF JOIN, ไม่มี SAMPLE BY พร้อม FILL, ไม่มี 2D arrays สำหรับ order books สำหรับ workload OLAP + time-series แบบผสม ClickHouse อาจชนะ สำหรับข้อมูลการเทรดล้วนๆ QuestDB มีความเป็นธรรมชาติมากกว่า
เทียบกับ InfluxDB: InfluxDB มีข้อจำกัด high-cardinality ที่เจ็บปวดสำหรับข้อมูล crypto หลาย exchanges ภาษา query (Flux ซึ่งตอนนี้ deprecated แล้ว; InfluxQL) ขาดความสามารถแสดงออกของ SQL extensions ของ QuestDB ประสิทธิภาพใน query ประวัติขนาดใหญ่มักแย่กว่า
เทียบกับ kdb+/q: มาตรฐานทองสำหรับ HFT kdb+ เร็วกว่าสำหรับ vector operations แบบ single-threaded บางอย่าง และภาษา q ของมันกระชับอย่างไม่น่าเชื่อ แต่มันเป็น proprietary, แพง และมี learning curve ที่ชัน QuestDB มีความสามารถ 80-90% ของมันในราคาส่วนหนึ่ง พร้อม SQL มาตรฐานและสิทธิ์การใช้งาน open-source
บทสรุป: ฐานข้อมูลที่เข้าใจการเทรด
ตลอดสามบทความนี้ เราได้ครอบคลุมสถาปัตยกรรมของ QuestDB (three-tier storage พร้อม WAL, columnar และ Parquet), SQL extensions (SAMPLE BY, ASOF JOIN, HORIZON JOIN, WINDOW JOIN, LATEST ON, TWAP) และการประยุกต์ใช้งานจริง (materialized views, order book arrays, reference architecture)
แก่นสำคัญที่ต่อเนื่องกัน: QuestDB ถูกออกแบบมาสำหรับ workloads ที่การเทรดแบบอัลกอริทึมสร้างขึ้นโดยเฉพาะ มันไม่บังคับให้คุณทำงานรอบฐานข้อมูล — แต่ primitives ของมัน map ตรงกับแนวคิดการเทรด การรวมกลุ่ม OHLC เป็นเพียงหนึ่งบรรทัด การจัดแนว trade-to-quote เป็น JOIN เดียว การวิเคราะห์หลังการเทรดเป็น HORIZON JOIN ไม่ใช่ขั้นตอน PL/SQL หลายหน้า
สำหรับทีมที่สร้าง trading infrastructure — ไม่ว่าจะเป็นแพลตฟอร์มข้อมูลตลาด crypto, สภาพแวดล้อมการวิจัยเชิงปริมาณ หรือ algorithmic trading engine เต็มรูปแบบ — QuestDB คุ้มค่าแก่การประเมินอย่างจริงจัง เวอร์ชัน open-source ครอบคลุม use case ส่วนใหญ่ และ Enterprise edition เติมเต็มช่องว่างสำหรับสภาพแวดล้อมที่มีการกำกับดูแล
ภูมิทัศน์ infrastructure ข้อมูลทางการเงินกำลังพัฒนาอย่างรวดเร็ว ฐานข้อมูลที่พูดภาษาของตลาดจะเป็นผู้ชนะ QuestDB พูดได้คล่อง
ขอให้เทรดได้ดี และขอให้ latency ของคุณต่ำเสมอ
การอ้างอิง
@software{soloviov2025questdb_algotrading_p3,
author = {Soloviov, Eugen},
title = {QuestDB for Algorithmic Trading: From Order Books to Production Architecture},
year = {2025},
url = {https://marketmaker.cc/th/blog/post/questdb-algotrading-production},
version = {0.1.0},
description = {Materialized views, การวิเคราะห์ order book ด้วย 2D array และสถาปัตยกรรมอ้างอิงสำหรับแพลตฟอร์มการเทรดแบบอัลกอริทึมที่ขับเคลื่อนด้วย QuestDB}
}
ผู้เขียน

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
อ่านเพิ่มเติม
คิวภายในกำแพง: การวิเคราะห์ตำแหน่งคำสั่งซื้อในความหนาแน่นของ Order Book
ลายนิ้วมือดิจิทัลของนักเทรด: วิธีระบุตัวตน Market Maker จากพฤติกรรมใน Order Book
