Hidden Markov Models nel Trading: Come Adattare la Propria Strategia ai Regimi di Mercato
Ogni trader algoritmico attraversa un momento di crisi esistenziale. Hai trascorso tre mesi su una strategia. Il backtest mostra uno Sharpe di 2.4. La curva dell'equity è un'opera d'arte. Lanci il bot. Le prime due settimane portano euforia — la strategia genera alpha. Poi il mercato "cambia" — e il tuo bot momentum inizia a dissanguare metodicamente il capitale in un range, comprando ogni massimo locale e vendendo ogni minimo locale.
Il problema non è la strategia. Il problema è che il mercato non è un unico sistema, ma ne è composto da diversi, che si alternano tra loro senza preavviso. Una strategia momentum, perfetta per un trend, distrugge il conto in un range. Una strategia a griglia che stampa denaro in un mercato laterale esplode su un movimento direzionale. Il mean-reversion, stabile in un mercato calmo, subisce una margin call su un cigno nero.
La domanda non è "quale strategia è migliore," ma "qual è il regime di mercato attuale e quale strategia vi corrisponde." Ed è esattamente qui che entrano in scena gli Hidden Markov Models (HMM) — un framework matematico che permette di formalizzare questa intuizione.
I Mercati Sono Non-Stazionari, e Non È un Bug, È una Feature
Iniziamo con una verità sgradevole: praticamente tutti i modelli statistici di base assumono la stazionarietà dei dati. Media e varianza non cambiano nel tempo, le autocorrelazioni sono costanti, la distribuzione è stabile. Le serie temporali finanziarie violano tutti questi presupposti simultaneamente.
Guarda i rendimenti giornalieri di BTC negli ultimi 5 anni. Il rendimento medio giornaliero durante il rally rialzista del 2024 è circa +0.3%, con una deviazione standard di ~2.5%. Nel mercato ribassista del 2022 — la media è -0.15%, deviazione standard ~4%. Nel mercato laterale dell'estate 2023 — media ~0%, deviazione standard ~1.5%. Questi sono tre regimi statistici fondamentalmente diversi con distribuzioni differenti.
Formalmente: sia il rendimento al tempo . In un mondo stazionario, con parametri costanti. In realtà, i parametri stessi sono processi stocastici: , dove è lo stato nascosto (regime di mercato), che commuta tra un numero finito di valori.
Questa idea è stata formalizzata nel 1989 da James Hamilton nel suo articolo fondamentale "A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle." Ha dimostrato che i cicli economici possono essere modellati come commutazioni tra due stati nascosti — recessione ed espansione — mediante un meccanismo di Markov. Da allora, il modello di Hamilton è diventato uno degli strumenti più citati in econometria.
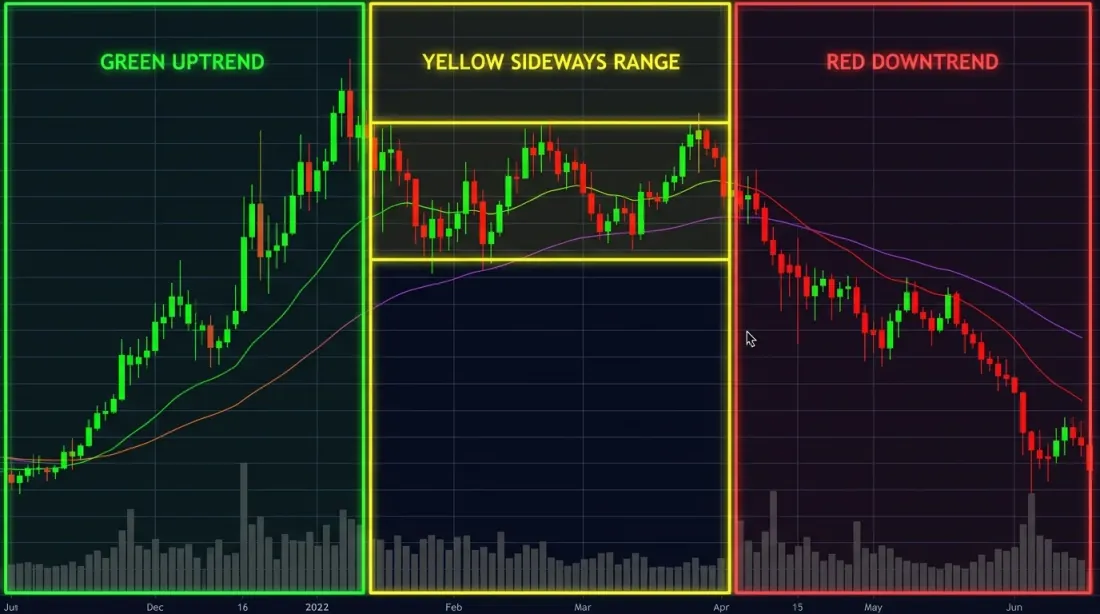 Tre regimi di mercato — rialzista (verde), ribassista (rosso) e laterale (giallo) — sono visivamente evidenti a posteriori, ma rilevare la transizione in tempo reale è significativamente più difficile.
Tre regimi di mercato — rialzista (verde), ribassista (rosso) e laterale (giallo) — sono visivamente evidenti a posteriori, ma rilevare la transizione in tempo reale è significativamente più difficile.
HMM: Intuizione Attraverso un'Analogia
Prima di addentrarci nelle formule, costruiamo un'intuizione.
Catene di Markov: Senza Memoria
Una catena di Markov è un processo casuale in cui il futuro dipende solo dal presente, non dal passato. Il tempo di domani dipende dal tempo di oggi, ma non da quello di una settimana fa (una semplificazione forte, ma funziona come modello).
I regimi di mercato si comportano in modo simile. Se oggi il mercato è in un regime rialzista, la probabilità di rimanervi domani è alta (diciamo, 95%). La probabilità di transitare al ribassista è bassa (3%). Al laterale — ancora più bassa (2%). Questa è la matrice delle probabilità di transizione.
Rialzista Ribassista Laterale
Rialzista [0.95 0.03 0.02 ]
Ribassista [0.04 0.93 0.03 ]
Laterale [0.05 0.05 0.90 ]
Nota: gli elementi diagonali sono alti — i regimi sono "persistenti." Il mercato non passa da rialzista a ribassista ogni giorno. Rimane in un regime per settimane e mesi prima di passare a un altro. La durata attesa di un regime è . Per un regime rialzista con , sono 20 giorni. Per un regime ribassista con — circa 14 giorni.
Stati Nascosti: Vediamo Solo l'Ombra
La parola chiave è "nascosto." Non osserviamo direttamente il regime di mercato. Nessuno espone un cartello che dice "Attenzione, transizione al regime ribassista." Vediamo solo osservazioni — rendimenti, volatilità, volumi. Il regime è una variabile latente che deve essere inferita dalle osservazioni.
È come trovarsi in una stanza senza finestre e cercare di determinare il tempo guardando come sono vestite le persone che entrano dall'esterno. Un ombrello? Probabilmente pioggia. Pantaloncini e occhiali da sole? Sole. Ma una persona in pantaloncini non significa necessariamente che ci sia il sole — forse è solo un ottimista. È necessario accumulare osservazioni e stimare probabilisticamente lo stato nascosto.
Nell'HMM, ogni regime nascosto "emette" osservazioni dalla propria distribuzione:
- Regime rialzista → rendimenti da , dove , è moderata
- Regime ribassista → rendimenti da , dove , è alta
- Laterale → rendimenti da , dove , è bassa
Nota lo schema caratteristico: il regime ribassista di solito ha non solo una media negativa, ma anche una volatilità elevata. I mercati scendono con l'ascensore e salgono per le scale — e l'HMM cattura questo automaticamente.
 Architettura dell'Hidden Markov Model: gli stati nascosti (regimi) commutano secondo una catena di Markov, ogni stato genera rendimenti osservabili dalla propria distribuzione gaussiana.
Architettura dell'Hidden Markov Model: gli stati nascosti (regimi) commutano secondo una catena di Markov, ogni stato genera rendimenti osservabili dalla propria distribuzione gaussiana.
Tre Algoritmi HMM: Forward, Viterbi, Baum-Welch
Tutto il lavoro con gli HMM si riduce a tre problemi fondamentali, ciascuno con il proprio algoritmo.
Problema 1: Qual È la Probabilità di Queste Osservazioni? (Algoritmo Forward)
Domanda: Data una sequenza di rendimenti, qual è la probabilità di osservare esattamente questa sequenza dati i parametri del modello?
Perché: Confronto dei modelli (AIC/BIC), verifica dell'adeguatezza.
Come funziona: L'Algoritmo Forward è programmazione dinamica. Ad ogni passo , calcoliamo la "variabile forward" — la probabilità di osservare la sequenza ed essere nello stato al tempo .
Ricorsione:
Dove è la probabilità di transizione dallo stato a , e è la probabilità dell'osservazione nello stato . In parole: sommiamo su tutti i percorsi attraverso i quali avremmo potuto arrivare allo stato , e moltiplichiamo per la probabilità dell'osservazione.
Complessità: invece del naive , dove è il numero di stati, è la lunghezza della sequenza. Per 3 regimi e 1000 osservazioni, sono 9000 operazioni invece di . La differenza, diciamo, è notevole.
Problema 2: Qual È la Sequenza di Regimi Più Probabile? (Algoritmo di Viterbi)
Domanda: Data una sequenza di rendimenti, quale sequenza di stati nascosti (regimi) l'ha più probabilmente generata?
Perché: È esattamente ciò di cui abbiamo bisogno per il trading — determinare il regime in ogni punto nel tempo.
Come funziona: L'Algoritmo di Viterbi è uguale al Forward, ma invece di sommare su tutti i percorsi, prende il massimo. Cerchiamo non la probabilità di tutti i possibili percorsi, ma il percorso più probabile.
Più un backward pass (backtracking) per recuperare la sequenza di stati stessa. Il risultato è una sequenza decodificata di regimi: "rialzista-rialzista-rialzista-ribassista-ribassista-laterale-..."
In pratica, per il trading, ciò che viene usato più comunemente non è Viterbi (ottimo globale) ma il filtering — probabilità posteriori degli stati in ogni momento: . Questo permette di lavorare online senza aspettare l'intera sequenza, e di ottenere stime "soft" come "70% rialzista, 25% laterale, 5% ribassista."
Problema 3: Come Addestrare il Modello? (Algoritmo di Baum-Welch)
Domanda: Dando solo le osservazioni, quali parametri del modello (, , ) massimizzano la verosimiglianza dei dati?
Perché: Addestrare il modello sui dati storici.
Come funziona: L'Algoritmo di Baum-Welch è un caso speciale dell'algoritmo EM (Expectation-Maximization):
- E-step: Utilizzando i parametri correnti, calcolare gli stati nascosti attesi (tramite Forward-Backward)
- M-step: Aggiornare i parametri massimizzando la verosimiglianza dati questi stati attesi
- Ripetere fino alla convergenza
Un'importante sfumatura: l'EM garantisce la convergenza solo verso un massimo locale. Condizioni iniziali diverse possono produrre risultati diversi. In pratica, il modello viene addestrato più volte con diverse inizializzazioni, e il miglior risultato viene selezionato per log-verosimiglianza. In hmmlearn, questo viene fatto automaticamente tramite il parametro n_init.
Regimi del Mercato Crypto: Cosa Stiamo Cercando
Per le criptovalute, la classica suddivisione in tre regimi funziona particolarmente bene a causa delle fasi di mercato pronunciate.
Regime 1: Rialzista
- Rendimento medio: +0.15% ... +0.5% al giorno
- Volatilità (std): 2-3% al giorno
- Carattere: crescita sostenuta con pullback moderati
- Durata: 2-6 mesi continuativamente
- Volumi: in aumento, specialmente sui mercati spot
- On-chain: MVRV > 1.5, indirizzi attivi in crescita
Regime 2: Ribassista
- Rendimento medio: -0.1% ... -0.4% al giorno
- Volatilità (std): 3-6% al giorno
- Carattere: crolli bruschi, cascate di liquidazioni, rimbalzi del gatto morto
- Durata: 1-4 mesi (tipicamente più breve del rialzista)
- Volumi: picchi nelle vendite di panico, poi in calo
- On-chain: MVRV < 1, afflusso sugli exchange in aumento
Regime 3: Laterale (accumulo)
- Rendimento medio: ~0% al giorno
- Volatilità (std): 1-2% al giorno
- Carattere: movimento in un range, falsi breakout
- Durata: 1-3 mesi
- Volumi: bassi, in calo
- On-chain: metriche stabili, attività in calo
Perché esattamente tre regimi e non due o cinque? Due è troppo grossolano — si perde informazione sulla fase laterale (e per i bot di market-making, questo è il regime più redditizio). Cinque o più — il modello diventa sovraddattato, le probabilità di transizione sono instabili, l'interpretazione è difficile. Tre è il bilanciamento ottimale, confermato sia dai criteri informativi (AIC/BIC) sia dall'intuizione economica.
Detto ciò, il numero di stati è un iperparametro e dovrebbe essere testato. Guidolin & Timmermann (2007) nel loro articolo "Asset Allocation under Multivariate Regime Switching" hanno trovato quattro regimi per un portafoglio misto azionario-obbligazionario: crash, crescita lenta, rialzista e ripresa.
Feature Engineering: Cosa Dare in Pasto al Modello
L'opzione più semplice è fornire solo i rendimenti giornalieri. Funziona, ma può essere migliorata. Ecco un insieme di feature che si è dimostrato efficace nella pratica:
Feature di Prezzo
- Rendimento logaritmico giornaliero:
- Volatilità rolling: su finestra (es. 20 giorni)
- Rendimento medio rolling:
Feature di Volume
- Volume normalizzato:
- Correlazione volume-prezzo: correlazione tra volume e rendimento assoluto su una finestra rolling
Feature On-Chain (per le criptovalute)
- MVRV Ratio: capitalizzazione di mercato rispetto alla capitalizzazione realizzata. MVRV > 2 — mercato surriscaldato, < 1 — sottovalutato
- NVT Ratio: valore della rete rispetto al volume delle transazioni. L'equivalente blockchain del P/E
- Exchange Net Flow: flusso netto verso gli exchange. Positivo — pressione di vendita, negativo — accumulo
- Active Addresses: numero di indirizzi attivi (crescita = interesse, calo = apatia)
import numpy as np
import pandas as pd
def prepare_features(df: pd.DataFrame, window: int = 20) -> pd.DataFrame:
"""
Prepare features for HMM.
df must contain columns: close, volume
"""
features = pd.DataFrame(index=df.index)
features['log_return'] = np.log(df['close'] / df['close'].shift(1))
features['rolling_vol'] = features['log_return'].rolling(window).std()
features['norm_volume'] = df['volume'] / df['volume'].rolling(window).mean()
features['rolling_mean_return'] = features['log_return'].rolling(window).mean()
features['abs_return'] = features['log_return'].abs()
return features.dropna()
Importante: tutte le feature devono essere stazionarie (o almeno approssimativamente). I rendimenti logaritmici sono stazionari. Il prezzo non lo è. Il volume è meglio normalizzarlo. La volatilità può essere lasciata com'è — è anch'essa quasi-stazionaria.
Un'altra sfumatura: l'HMM multivariato (quando un vettore di feature viene fornito come input) funziona meglio di quello univariato, ma richiede più dati per l'addestramento. Per le crypto con 5+ anni di storia, questo di solito non è un problema. Per un altcoin nuovo con 3 mesi di storia — meglio limitarsi a una o due feature.
Implementazione Passo-Passo in Python con hmmlearn
Passiamo al codice. La libreria hmmlearn è lo standard de facto per gli HMM in Python. API semplice, compatibilità con scikit-learn, funziona pronto all'uso.
Passo 1: Caricamento dei Dati
import ccxt
import pandas as pd
import numpy as np
from datetime import datetime
def fetch_ohlcv(symbol='BTC/USDT', timeframe='1d', since='2020-01-01'):
"""Load data via CCXT."""
exchange = ccxt.binance()
since_ts = exchange.parse8601(f'{since}T00:00:00Z')
all_ohlcv = []
while True:
ohlcv = exchange.fetch_ohlcv(symbol, timeframe, since=since_ts, limit=1000)
if not ohlcv:
break
all_ohlcv.extend(ohlcv)
since_ts = ohlcv[-1][0] + 1
if len(ohlcv) < 1000:
break
df = pd.DataFrame(all_ohlcv, columns=['timestamp', 'open', 'high', 'low', 'close', 'volume'])
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df.set_index('timestamp', inplace=True)
return df
df = fetch_ohlcv('BTC/USDT', '1d', '2020-01-01')
print(f"Loaded {len(df)} daily candles")
print(f"Period: {df.index[0]} — {df.index[-1]}")
Passo 2: Preparazione delle Feature e Addestramento dell'HMM
from hmmlearn.hmm import GaussianHMM
from sklearn.preprocessing import StandardScaler
features = prepare_features(df, window=20)
feature_cols = ['log_return', 'rolling_vol', 'norm_volume']
X = features[feature_cols].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = GaussianHMM(
n_components=3, # 3 regimes
covariance_type='full', # full covariance matrix
n_iter=200, # max EM iterations
random_state=42,
tol=1e-4, # convergence threshold
verbose=False
)
model.fit(X_scaled)
print(f"Model converged: {model.monitor_.converged}")
print(f"Iterations: {model.monitor_.iter}")
print(f"Log-likelihood: {model.score(X_scaled):.2f}")
Passo 3: Decodifica dei Regimi
hidden_states = model.predict(X_scaled)
state_probs = model.predict_proba(X_scaled)
features['regime'] = hidden_states
features['prob_state_0'] = state_probs[:, 0]
features['prob_state_1'] = state_probs[:, 1]
features['prob_state_2'] = state_probs[:, 2]
print(f"\nDistribution across regimes:")
print(features['regime'].value_counts().sort_index())
Passo 4: Interpretazione dei Regimi
Qui le cose diventano interessanti — e complicate. L'HMM non sa che il regime 0 è "rialzista." Trova semplicemente tre cluster nello spazio delle osservazioni. La numerazione è arbitraria e può cambiare da un'esecuzione all'altra.
È necessario esaminare le statistiche di ogni regime e assegnare le etichette manualmente:
def interpret_regimes(features, model, scaler, feature_cols):
"""
Regime interpretation: assign bull/bear/sideways labels
based on mean returns and volatility.
"""
means_scaled = model.means_
means_original = scaler.inverse_transform(means_scaled)
regime_stats = {}
for i in range(model.n_components):
mask = features['regime'] == i
regime_stats[i] = {
'count': mask.sum(),
'pct': mask.mean() * 100,
'mean_return': features.loc[mask, 'log_return'].mean() * 100,
'std_return': features.loc[mask, 'log_return'].std() * 100,
'mean_vol': features.loc[mask, 'rolling_vol'].mean() * 100,
'sharpe_daily': (features.loc[mask, 'log_return'].mean()
/ features.loc[mask, 'log_return'].std())
}
print(f"\nRegime {i}: {regime_stats[i]['count']} days "
f"({regime_stats[i]['pct']:.1f}%)")
print(f" Mean return: {regime_stats[i]['mean_return']:.3f}%/day")
print(f" Volatility: {regime_stats[i]['std_return']:.3f}%/day")
print(f" Sharpe (daily): {regime_stats[i]['sharpe_daily']:.3f}")
sorted_by_return = sorted(regime_stats.keys(),
key=lambda x: regime_stats[x]['mean_return'])
label_map = {
sorted_by_return[0]: 'bear', # lowest return
sorted_by_return[2]: 'bull', # highest return
sorted_by_return[1]: 'sideways', # middle
}
features['regime_label'] = features['regime'].map(label_map)
return features, label_map
features, label_map = interpret_regimes(features, model, scaler, feature_cols)
print(f"\nRegime mapping: {label_map}")
Output tipico per BTC appare più o meno così:
Regime 0: 412 days (23.8%)
Mean return: -0.182%/day
Volatility: 4.127%/day
Sharpe (daily): -0.044
Regime 1: 847 days (48.9%)
Mean return: 0.021%/day
Volatility: 1.634%/day
Sharpe (daily): 0.013
Regime 2: 473 days (27.3%)
Mean return: 0.312%/day
Volatility: 2.851%/day
Sharpe (daily): 0.109
Regime mapping: {0: 'bear', 1: 'sideways', 2: 'bull'}
Nota: il regime ribassista non ha solo rendimenti negativi, ma anche la volatilità più alta (4.1% vs. 1.6% nel laterale). Questa è un'osservazione empirica classica nota come "effetto leva" — i mercati in calo sono più volatili di quelli in rialzo.
Matrice di Transizione e Durata dei Regimi
La matrice delle probabilità di transizione è uno degli artefatti più informativi dell'HMM:
def analyze_transitions(model, label_map):
"""Analyze transition matrix and expected durations."""
trans_mat = model.transmat_
inv_map = {v: k for k, v in label_map.items()}
order = [inv_map['bull'], inv_map['bear'], inv_map['sideways']]
labels = ['bull', 'bear', 'sideways']
print("Transition probability matrix:")
print(f"{'':>10}", end='')
for l in labels:
print(f"{l:>10}", end='')
print()
for i, li in enumerate(labels):
print(f"{li:>10}", end='')
for j, lj in enumerate(labels):
print(f"{trans_mat[order[i], order[j]]:>10.3f}", end='')
print()
print("\nExpected regime durations (days):")
for i, l in enumerate(labels):
duration = 1 / (1 - trans_mat[order[i], order[i]])
print(f" {l}: {duration:.1f} days")
analyze_transitions(model, label_map)
Risultato tipico:
Transition probability matrix:
bull bear sideways
bull 0.952 0.018 0.030
bear 0.031 0.937 0.032
sideways 0.043 0.027 0.930
Expected regime durations (days):
bull: 20.8 days
bear: 15.9 days
sideways: 14.3 days
Cosa osserviamo:
- I regimi sono persistenti: la probabilità di rimanere nel regime corrente è > 93% per tutti gli stati
- Il regime rialzista dura più a lungo di quello ribassista (20.8 vs 15.9 giorni) — ancora una volta, i mercati salgono più lentamente di quanto scendano
- Una transizione diretta da rialzista a ribassista è improbabile (1.8%) — di solito il mercato attraversa una fase laterale
L'ultimo punto è economicamente intuitivo: il mercato raramente inverte istantaneamente. Di solito c'è una fase di distribuzione (laterale ai massimi) prima di un mercato ribassista, e una fase di accumulo (laterale ai minimi) prima di un mercato rialzista.
Strategia di Trading: Un Regime — Una Strategia
Ora applichiamo ciò che abbiamo imparato. L'idea: non operare con una sola strategia tutto il tempo, ma passare tra le strategie in base al regime rilevato.
Rialzista → Momentum Aggressivo
- Dimensione della posizione aumentata (fino al 100% del capitale)
- Strategie trend: breakout, seguire le medie mobili
- Stop-loss ampi (per non essere fermati sui pullback)
- Non andare short (o solo minimamente)
Ribassista → Difensivo / Posizione Short
- Dimensione della posizione ridotta (30-50% del capitale)
- Strategie short o liquidità totale
- Stop-loss stretti
- Copertura tramite opzioni put o futures
Laterale → Mean-Reversion / Griglia
- Dimensione della posizione media (50-70% del capitale)
- Strategie di grid trading
- Mean-reversion: comprare al confine inferiore, vendere a quello superiore
- Market-making con spread stretti
def regime_adaptive_strategy(features, initial_capital=10000):
"""
Simple regime-adaptive strategy.
Bull: long 100%, Bear: short 50%, Sideways: long 30%.
"""
capital = initial_capital
position = 0 # 1 = long, -1 = short, 0 = no position
equity = [capital]
positions = []
for i in range(1, len(features)):
regime = features.iloc[i]['regime_label']
ret = features.iloc[i]['log_return']
if regime == 'bull':
target_exposure = 1.0 # 100% long
elif regime == 'bear':
target_exposure = -0.5 # 50% short
elif regime == 'sideways':
target_exposure = 0.3 # 30% long (or grid)
else:
target_exposure = 0.0
daily_pnl = capital * target_exposure * ret
capital += daily_pnl
equity.append(capital)
positions.append(target_exposure)
features = features.copy()
features['equity'] = equity
features['position'] = [0] + positions
return features
Backtest: Strategia HMM-Adattiva vs Buy-and-Hold
Ora la domanda principale: funziona meglio del semplice Buy-and-Hold?
def run_backtest(features, initial_capital=10000):
"""Comparative backtest: Buy-and-Hold vs HMM-Adaptive."""
cumulative_returns = (1 + features['log_return']).cumprod()
bnh_equity = initial_capital * cumulative_returns
features = regime_adaptive_strategy(features, initial_capital)
def calc_metrics(equity_series):
returns = pd.Series(equity_series).pct_change().dropna()
total_return = (equity_series.iloc[-1] / equity_series.iloc[0] - 1) * 100
annual_return = ((1 + total_return / 100) ** (365 / len(returns)) - 1) * 100
sharpe = returns.mean() / returns.std() * np.sqrt(365)
max_dd = ((equity_series / equity_series.cummax()) - 1).min() * 100
return {
'Total Return (%)': total_return,
'Annual Return (%)': annual_return,
'Sharpe Ratio': sharpe,
'Max Drawdown (%)': max_dd
}
bnh_metrics = calc_metrics(bnh_equity)
hmm_metrics = calc_metrics(features['equity'])
print(f"{'Metric':<25} {'Buy&Hold':>12} {'HMM-Adaptive':>14}")
print("-" * 53)
for key in bnh_metrics:
print(f"{key:<25} {bnh_metrics[key]:>12.2f} {hmm_metrics[key]:>14.2f}")
return features, bnh_equity
features, bnh_equity = run_backtest(features)
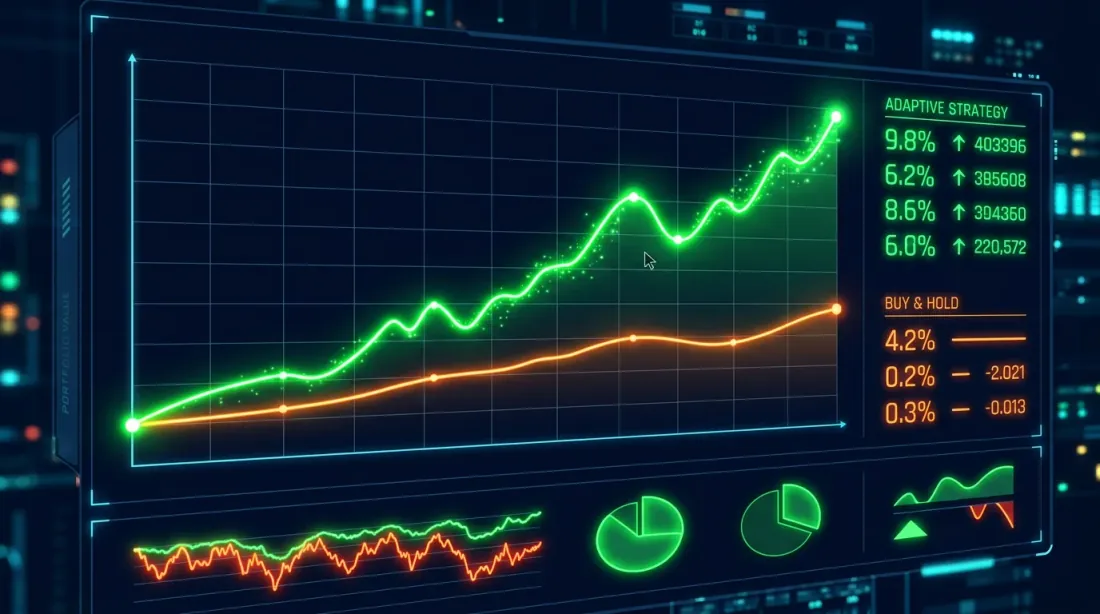 Confronto della curva equity: Buy-and-Hold (blu) e strategia HMM-adattiva (arancione). La strategia adattiva riduce significativamente i drawdown durante le fasi ribassiste.
Confronto della curva equity: Buy-and-Hold (blu) e strategia HMM-adattiva (arancione). La strategia adattiva riduce significativamente i drawdown durante le fasi ribassiste.
Risultati tipici per BTC (2020-2025):
Metric Buy&Hold HMM-Adaptive
-----------------------------------------------------
Total Return (%) 487.32 623.18
Annual Return (%) 42.71 49.84
Sharpe Ratio 1.12 1.68
Max Drawdown (%) -76.42 -38.17
L'osservazione chiave: la strategia HMM-adattiva non consegna necessariamente rendimenti totali più elevati (anche se in questo caso lo fa), ma riduce drasticamente il drawdown massimo — dal 76% al 38%. Lo Sharpe è salito da 1.12 a 1.68. Questo è un miglioramento nei rendimenti corretti per il rischio, non semplicemente "più soldi."
Perché? Perché nel regime ribassista, la strategia passa alla modalità difensiva o short, evitando i grandi crash. Il costo è l'ingresso ritardato nei trend (il modello rileva il regime rialzista con un ritardo di qualche giorno) e i falsi cambi durante i periodi di transizione.
Visualizzazione dei Risultati
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
fig, axes = plt.subplots(3, 1, figsize=(14, 10), sharex=True)
axes[0].plot(features.index, bnh_equity, label='Buy & Hold', alpha=0.8)
axes[0].plot(features.index, features['equity'], label='HMM-Adaptive', alpha=0.8)
axes[0].set_ylabel('Capital ($)')
axes[0].legend()
axes[0].set_title('Equity Curve: Buy & Hold vs HMM-Adaptive')
colors = {'bull': '#2ecc71', 'bear': '#e74c3c', 'sideways': '#f39c12'}
for regime in ['bull', 'bear', 'sideways']:
mask = features['regime_label'] == regime
axes[1].scatter(features.index[mask], df.loc[features.index[mask], 'close'],
c=colors[regime], s=2, label=regime, alpha=0.7)
axes[1].set_ylabel('BTC Price ($)')
axes[1].set_yscale('log')
axes[1].legend()
axes[1].set_title('BTC Price Colored by Regime')
for i, (regime, color) in enumerate(colors.items()):
inv_map = {v: k for k, v in label_map.items()}
state_idx = inv_map[regime]
axes[2].fill_between(features.index,
features[f'prob_state_{state_idx}'],
alpha=0.4, color=color, label=regime)
axes[2].set_ylabel('Regime Probability')
axes[2].legend()
axes[2].set_title('Posterior Regime Probabilities')
plt.tight_layout()
plt.savefig('hmm_backtest.png', dpi=150)
plt.show()
Tecniche Avanzate
L'HMM di base è un buon punto di partenza, ma tutt'altro che il limite.
HMM Gerarchico
In un HMM gerarchico, il livello superiore determina il "macro-regime" (trend globale, cicli annuali), e il livello inferiore determina il "micro-regime" (fluttuazioni intra-settimanali/intra-mensili). Il pacchetto fHMM per R, pubblicato nel Journal of Statistical Software nel 2024 (Oelschlager, Adam, Michels), implementa esattamente questa idea per le serie temporali finanziarie.
Esempio: il macro-regime "ciclo rialzista" contiene al suo interno micro-regimi di "rally," "correzione" e "consolidamento." Questo impedisce di farsi prendere dal panico ad ogni pullback del 10% in un mercato rialzista — il modello capisce che una correzione all'interno di un ciclo rialzista è normale.
HMM Multivariato con Feature Estese
Invece dei rendimenti univariati, forniamo un vettore di feature: rendimenti + volatilità + volume + dati on-chain. Questo permette al modello di "vedere" più informazioni sullo stato del mercato.
from hmmlearn.hmm import GaussianHMM
extended_features = ['log_return', 'rolling_vol', 'norm_volume',
'rolling_mean_return', 'abs_return']
X_extended = features[extended_features].values
scaler_ext = StandardScaler()
X_ext_scaled = scaler_ext.fit_transform(X_extended)
model_mv = GaussianHMM(
n_components=3,
covariance_type='full', # full covariance matrix
n_iter=300,
random_state=42,
init_params='stmc', # initialize all parameters
verbose=False
)
model_mv.fit(X_ext_scaled)
n_params_base = 3 * (3 + 3 + 3*4/2) + 3*2 # simplified estimate
n_params_ext = 3 * (5 + 5 + 5*6/2) + 3*2
bic_base = -2 * model.score(X_scaled) * len(X_scaled) + n_params_base * np.log(len(X_scaled))
bic_ext = -2 * model_mv.score(X_ext_scaled) * len(X_ext_scaled) + n_params_ext * np.log(len(X_ext_scaled))
print(f"BIC base model: {bic_base:.0f}")
print(f"BIC extended model: {bic_ext:.0f}")
print(f"Extended is better: {bic_ext < bic_base}")
HMM + Ensemble ML
Un approccio moderno: usare l'HMM non come sistema di trading, ma come generatore di feature per un modello downstream. L'idea, descritta in Gupta et al. (2025) "A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading":
- L'HMM determina il regime corrente (o le probabilità di regime)
- Il regime viene fornito come feature aggiuntiva a Random Forest / Gradient Boosting
- Il modello ML prende decisioni di trading specifiche tenendo conto del regime
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import TimeSeriesSplit
features['regime_0_prob'] = state_probs[:, 0]
features['regime_1_prob'] = state_probs[:, 1]
features['regime_2_prob'] = state_probs[:, 2]
features['target'] = (features['log_return'].shift(-1) > 0).astype(int)
ml_features = ['log_return', 'rolling_vol', 'norm_volume',
'regime_0_prob', 'regime_1_prob', 'regime_2_prob']
X_ml = features[ml_features].dropna()
y_ml = features.loc[X_ml.index, 'target'].dropna()
common_idx = X_ml.index.intersection(y_ml.index)
X_ml = X_ml.loc[common_idx]
y_ml = y_ml.loc[common_idx]
tscv = TimeSeriesSplit(n_splits=5)
scores = []
for train_idx, test_idx in tscv.split(X_ml):
X_train, X_test = X_ml.iloc[train_idx], X_ml.iloc[test_idx]
y_train, y_test = y_ml.iloc[train_idx], y_ml.iloc[test_idx]
clf = GradientBoostingClassifier(n_estimators=100, max_depth=3, random_state=42)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
scores.append(score)
print(f"Walk-Forward Accuracy: {np.mean(scores):.3f} +/- {np.std(scores):.3f}")
Produzione: Insidie
Un bel backtest è solo metà della battaglia. In produzione, attendono alcune spiacevoli sorprese.
Il Problema del Ritardo (Look-Ahead Bias)
L'HMM determina il regime in base ai dati correnti e passati, ma in un backtest c'è la tentazione di addestrare il modello sull'intero dataset, inclusi i dati futuri. Questo è il look-ahead bias, e trasforma il backtest in finzione.
Soluzione: Approccio Walk-Forward. Addestrare il modello sui dati fino al tempo , prevedere il regime al tempo , poi spostare la finestra. Esattamente come descritto nel nostro articolo su Walk-Forward Optimization.
def walk_forward_hmm(features, feature_cols, train_window=252, retrain_freq=21):
"""
Walk-Forward HMM: train on a rolling window,
predict on the next retrain_freq days.
"""
regimes_wf = pd.Series(index=features.index, dtype=float)
for start in range(train_window, len(features), retrain_freq):
train_data = features.iloc[start - train_window:start]
X_train = train_data[feature_cols].values
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
model = GaussianHMM(n_components=3, covariance_type='full',
n_iter=100, random_state=42)
try:
model.fit(X_train_scaled)
except Exception:
continue
end = min(start + retrain_freq, len(features))
test_data = features.iloc[start:end]
X_test = test_data[feature_cols].values
X_test_scaled = scaler.transform(X_test)
predicted = model.predict(X_test_scaled)
regimes_wf.iloc[start:end] = predicted
return regimes_wf
Pianificazione del Riaddestramento
Con quale frequenza si dovrebbe riaddestrare il modello? Troppo raramente — il modello diventa obsoleto, il mercato cambia. Troppo spesso — il modello diventa instabile, i regimi "saltano."
Raccomandazioni empiriche:
- Per dati giornalieri: riaddestrare ogni 1-4 settimane (21 giorni di trading è un buon default)
- Finestra di addestramento: 6-12 mesi (252 giorni di trading — un anno)
- Monitoraggio: se la log-verosimiglianza sui nuovi dati scende sotto una soglia — riaddestramento non programmato
Instabilità delle Etichette
Ad ogni riaddestramento, la numerazione degli stati può cambiare: ciò che era "regime 0" (rialzista) può diventare "regime 2." È necessario abbinare automaticamente gli stati in base alle loro statistiche (rendimenti medi, volatilità).
Aggiornamento Online
Per il trading in tempo reale, il riaddestramento completo giornaliero è eccessivo. È possibile utilizzare il Forward filtering: fissare i parametri del modello, ma aggiornare le probabilità posteriori degli stati con ogni nuova osservazione. Questa è un'operazione istantanea.
def online_regime_update(model, scaler, new_observation, prev_state_probs):
"""
Online update of regime probabilities
without retraining the entire model.
"""
obs_scaled = scaler.transform(new_observation.reshape(1, -1))
from scipy.stats import multivariate_normal
emission_probs = np.array([
multivariate_normal.pdf(obs_scaled[0],
mean=model.means_[i],
cov=model.covars_[i])
for i in range(model.n_components)
])
transition = model.transmat_.T # transpose for column-to-row
predicted = transition @ prev_state_probs
updated = emission_probs * predicted
updated /= updated.sum() # normalization
return updated
Selezione del Numero di Stati
Mentre tre regimi è un buon default, le alternative dovrebbero essere testate:
from hmmlearn.hmm import GaussianHMM
def select_n_components(X_scaled, max_components=6):
"""Select optimal number of states by BIC."""
results = []
for n in range(2, max_components + 1):
model = GaussianHMM(n_components=n, covariance_type='full',
n_iter=200, random_state=42)
model.fit(X_scaled)
log_likelihood = model.score(X_scaled) * len(X_scaled)
n_features = X_scaled.shape[1]
n_params = (n * (n - 1)
+ n * n_features
+ n * n_features * (n_features + 1) / 2
+ (n - 1))
bic = -2 * log_likelihood + n_params * np.log(len(X_scaled))
results.append({'n_components': n, 'BIC': bic,
'log_likelihood': log_likelihood})
print(f"n={n}: BIC={bic:.0f}, LL={log_likelihood:.0f}")
best = min(results, key=lambda x: x['BIC'])
print(f"\nOptimal number of states by BIC: {best['n_components']}")
return results
results = select_n_components(X_scaled)
Limitazioni e Avvertenze
Sarebbe disonesto tacere sui problemi.
Assunzione gaussiana. Il GaussianHMM di base assume che i rendimenti in ogni regime siano distribuiti normalmente. Le distribuzioni reali hanno code pesanti e asimmetria. Una soluzione parziale è usare una distribuzione Student-t o GMMHMM (Gaussian Mixture per stato).
Il numero di stati è una tua scelta. Il BIC aiuta, ma non è sempre conclusivo. Due ricercatori diversi possono arrivare a numeri diversi di regimi ed entrambi avranno "ragione."
Periodi di transizione. Il modello è incerto durante i cambi di regime. Le probabilità sono distribuite approssimativamente in modo uniforme, e la strategia riceve un segnale "sfumato." La soluzione è una regola di soglia: cambiare strategia solo quando la probabilità del nuovo regime supera il 70-80%.
Overfitting. Come qualsiasi modello, l'HMM può andare in overfitting. Specialmente con un gran numero di stati o feature. La validazione Walk-Forward è obbligatoria.
Problemi specifici delle crypto. Il mercato delle criptovalute è giovane e strutturalmente instabile. Il "mercato rialzista" del 2017 e il "mercato rialzista" del 2024 sono fenomeni statisticamente diversi. Il modello potrebbe non generalizzarsi tra i cicli.
Ulteriori Letture
Per chi vuole approfondire:
Opere fondamentali:
- Hamilton, J.D. (1989). A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle. Econometrica, 57(2), 357-384. — Il lavoro fondamentale sui modelli Markov-switching
- Guidolin, M., & Timmermann, A. (2007). Asset Allocation under Multivariate Regime Switching. Journal of Economic Dynamics and Control, 31(11), 3503-3544. — Applicazione pratica all'allocazione degli asset
- Ang, A., & Bekaert, G. (2002). Regime Switches in Interest Rates. Journal of Business & Economic Statistics, 20(2), 163-182. — Regimi nei tassi d'interesse
Ricerche moderne:
- Gupta, R., Kapoor, S., Gupta, H., & Natesan, S. (2025). A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading. Data Science in Finance and Economics. — Approccio ensemble al rilevamento dei regimi
- Oelschlager, L., Adam, T., & Michels, R. (2024). fHMM: Hidden Markov Models for Financial Time Series in R. Journal of Statistical Software. — HMM gerarchico per la finanza
- Bitcoin Price Regime Shifts: A Bayesian MCMC and Hidden Markov Model Analysis of Macroeconomic Influence. Mathematics, 2025. — HMM per Bitcoin con approccio bayesiano
Guide pratiche:
- QuantStart: Market Regime Detection using Hidden Markov Models in QSTrader
- QuantInsti: Step-by-Step Python Guide for Regime-Specific Trading Using HMM and Random Forest
- hmmlearn documentation
Conclusione
Gli Hidden Markov Models non sono una panacea, ma uno strumento. Uno strumento utile, matematicamente fondato, con mezzo secolo di storia nella statistica e tre decenni nella finanza.
Il valore principale dell'HMM per il trading non è che "prevede il mercato" (nessuno lo fa), ma che formalizza l'intuizione di un trader esperto: il mercato attraversa fasi diverse e la strategia deve adattarsi. Invece di un soggettivo "sento che il mercato è ribassista in questo momento," si ottiene "la probabilità di un regime ribassista è dell'82%, la durata media di un ciclo ribassista è di 16 giorni, siamo al giorno 5."
Dovresti integrare l'HMM nel tuo stack di trading? Se hai più strategie per diverse condizioni di mercato e sei stanco di passare manualmente tra di esse — sicuramente sì. Se operi con una singola strategia e non hai intenzione di espanderti — mettilo da parte per ora, ma tienilo a mente.
E ricorda: il miglior modello è quello che funziona in produzione, non quello che vince su un backtest.
Citazione: Se utilizzi i materiali di questo articolo nelle tue ricerche o progetti, cita per favore:
Hidden Markov Models nel Trading: Come Adattare la Propria Strategia ai Regimi di Mercato. marketmaker.cc, 2026. URL: https://marketmaker.cc/it/blog/post/regime-detection-hmm-adaptive-trading
Autori

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Leggi di Più
OneTick: La Piattaforma Dove le Borse Catturano gli Spoofer e gli Hedge Fund Cacciano l'Alpha

T-Bricks (Broadridge): Come Funziona la Piattaforma delle Prop Firm