Hidden Markov Models ในการเทรด: วิธีปรับกลยุทธ์ให้เข้ากับระบอบตลาด
ทุก algo trader ล้วนเคยมีช่วงวิกฤตอัตถิภาวะ คุณใช้เวลาสามเดือนสร้างกลยุทธ์หนึ่งขึ้นมา backtest แสดง Sharpe 2.4 เส้นโค้ง equity งดงามราวกับงานศิลปะ คุณปล่อยบอทรัน สองสัปดาห์แรกเต็มไปด้วยความตื่นเต้น — กลยุทธ์กำลังสร้าง alpha จากนั้นตลาด "สลับ" — และ momentum bot ของคุณเริ่มเลือดออกทีละน้อยอย่างเป็นระบบในช่วง range ซื้อทุกจุดสูงสุดในท้องถิ่นและขายทุกจุดต่ำสุดในท้องถิ่น
ปัญหาไม่ใช่กลยุทธ์ ปัญหาคือตลาดไม่ใช่ระบบเดียว แต่เป็นหลายระบบที่สลับกันโดยไม่มีการเตือน กลยุทธ์ momentum ที่สมบูรณ์แบบในช่วงเทรนด์จะทำลายพอร์ตในช่วง range กลยุทธ์ grid ที่พิมพ์เงินในตลาด sideways จะระเบิดเมื่อตลาดเคลื่อนไหวทิศทาง mean-reversion ที่เสถียรในตลาดสงบจะถูก margin call ในช่วง black swan
คำถามไม่ใช่ "กลยุทธ์ไหนดีกว่า" แต่คือ "ระบอบตลาดปัจจุบันคืออะไร และกลยุทธ์ไหนเหมาะสม" และนี่คือจุดที่ Hidden Markov Models (HMM) เข้าสู่เวที — กรอบทางคณิตศาสตร์ที่ช่วยให้คุณทำให้สัญชาตญาณนี้เป็นรูปธรรมได้
ตลาดไม่หยุดนิ่ง และนั่นไม่ใช่ bug แต่เป็น feature
เริ่มด้วยความจริงที่ไม่น่าพึงใจ: โมเดลสถิติพื้นฐานแทบทุกตัวสมมติให้ข้อมูลอยู่ในสภาวะ stationarity ค่าเฉลี่ยและความแปรปรวนไม่เปลี่ยนแปลงตามเวลา autocorrelation คงที่ การกระจายตัวเสถียร อนุกรมเวลาทางการเงินละเมิดสมมติฐานเหล่านี้ทั้งหมดในเวลาเดียวกัน
ดู BTC daily return ย้อนหลัง 5 ปี ผลตอบแทนรายวันเฉลี่ยในช่วง bull rally ปี 2024 อยู่ที่ประมาณ +0.3% ส่วนเบี่ยงเบนมาตรฐาน ~2.5% ในตลาดหมีปี 2022 — เฉลี่ย -0.15% ส่วนเบี่ยงเบน ~4% ในตลาด sideways ฤดูร้อนปี 2023 — เฉลี่ย ~0% ส่วนเบี่ยงเบน ~1.5% นี่คือสามระบอบสถิติที่แตกต่างกันโดยพื้นฐานด้วยการกระจายตัวที่ต่างกัน
อย่างเป็นทางการ: ให้ คือผลตอบแทน ณ เวลา ในโลก stationary ด้วยพารามิเตอร์คงที่ ในความเป็นจริง พารามิเตอร์เองเป็น random process: โดยที่ คือสถานะที่ซ่อนอยู่ (ระบอบตลาด) ซึ่งสลับระหว่างค่าจำนวนจำกัด
แนวคิดนี้ถูกทำให้เป็นรูปธรรมในปี 1989 โดย James Hamilton ในผลงานพื้นฐานของเขา "A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle" เขาแสดงให้เห็นว่าวัฏจักรธุรกิจสามารถจำลองเป็นการสลับระหว่างสองสถานะที่ซ่อนอยู่ — ภาวะถดถอยและการขยายตัว — โดยใช้กลไก Markov ตั้งแต่นั้นมา โมเดลของ Hamilton ได้กลายเป็นหนึ่งในเครื่องมือที่ถูกอ้างอิงมากที่สุดในเศรษฐมิติ
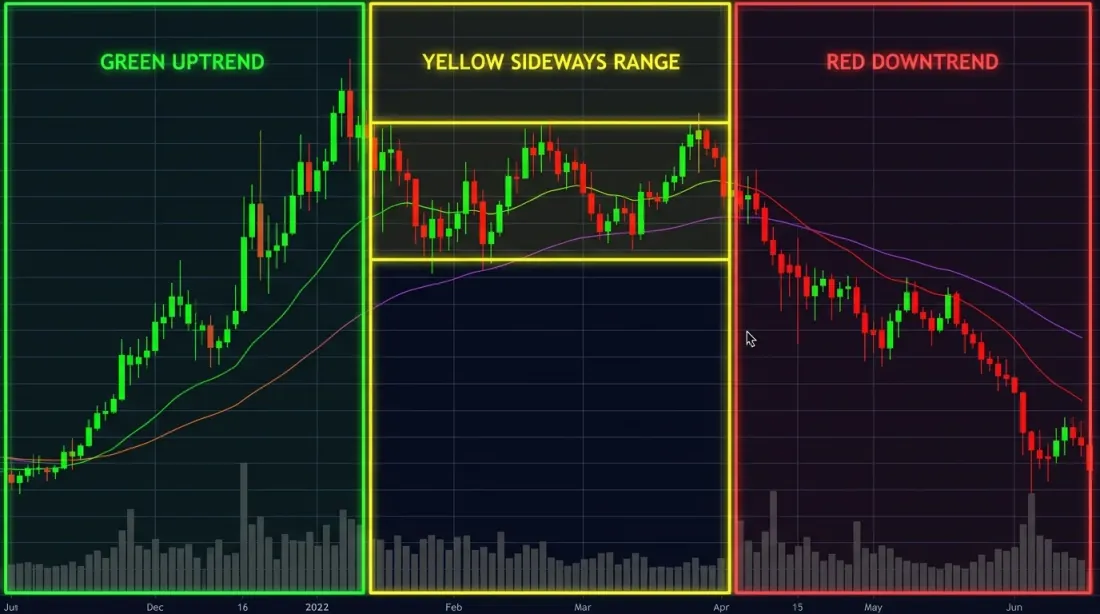 สามระบอบตลาด — กระทิง (เขียว) หมี (แดง) และ sideways (เหลือง) — มองเห็นได้ชัดเจนในมุมมองย้อนหลัง แต่การตรวจจับการเปลี่ยนแปลงในเวลาจริงนั้นยากกว่ามาก
สามระบอบตลาด — กระทิง (เขียว) หมี (แดง) และ sideways (เหลือง) — มองเห็นได้ชัดเจนในมุมมองย้อนหลัง แต่การตรวจจับการเปลี่ยนแปลงในเวลาจริงนั้นยากกว่ามาก
HMM: สัญชาตญาณผ่านการเปรียบเทียบ
ก่อนจะดำดิ่งสู่สูตรคณิตศาสตร์ มาสร้างความเข้าใจเชิงสัญชาตญาณกันก่อน
Markov Chains: ไม่มีความทรงจำ
Markov chain คือ random process ที่อนาคตขึ้นอยู่กับปัจจุบันเท่านั้น ไม่ใช่อดีต สภาพอากาศพรุ่งนี้ขึ้นอยู่กับสภาพอากาศวันนี้ แต่ไม่ขึ้นกับสภาพอากาศเมื่อสัปดาห์ที่แล้ว (การทำให้เรียบง่ายอย่างมาก แต่ใช้ได้ในฐานะโมเดล)
ระบอบตลาดมีพฤติกรรมในลักษณะเดียวกัน ถ้าวันนี้ตลาดอยู่ในระบอบกระทิง ความน่าจะเป็นที่จะอยู่ในระบอบนั้นต่อพรุ่งนี้สูง (เช่น 95%) ความน่าจะเป็นที่จะเปลี่ยนไปเป็นหมีต่ำ (3%) ไปสู่ sideways — ต่ำกว่าอีก (2%) นี่คือเมทริกซ์ความน่าจะเป็นการเปลี่ยนสถานะ
Bull Bear Sideways
Bull [0.95 0.03 0.02 ]
Bear [0.04 0.93 0.03 ]
Sideways[0.05 0.05 0.90 ]
สังเกต: องค์ประกอบในแนวทแยงสูง — ระบอบมีความ "เหนียว" ตลาดไม่กระโดดจากกระทิงไปหมีทุกวัน มันอยู่ในระบอบเดียวเป็นสัปดาห์และเดือนก่อนเปลี่ยน ระยะเวลาที่คาดหวังของระบอบคือ สำหรับระบอบกระทิงที่ นั่นคือ 20 วัน สำหรับระบอบหมีที่ — ประมาณ 14 วัน
สถานะที่ซ่อนอยู่: เราเห็นแต่เงา
คำสำคัญคือ "ซ่อนอยู่" เราไม่สังเกตระบอบตลาดโดยตรง ไม่มีใครแขวนป้ายว่า "ระวัง กำลังเปลี่ยนสู่ระบอบหมี" เรามองเห็นแต่ observations — ผลตอบแทน ความผันผวน ปริมาณ ระบอบคือตัวแปรแฝงที่ต้องอนุมานจาก observations
มันเหมือนกับการอยู่ในห้องที่ไม่มีหน้าต่างแล้วพยายามระบุสภาพอากาศจากการแต่งกายของคนที่เดินเข้ามาจากข้างนอก ร่ม? น่าจะฝน กางเกงขาสั้นและแว่นตากันแดด? แดดออก แต่คนใส่กางเกงขาสั้นคนเดียวไม่ได้หมายความว่าแดดออกแน่นอน — อาจเป็นแค่คนที่มองโลกในแง่ดี คุณต้องสะสม observations และประมาณสถานะที่ซ่อนอยู่แบบความน่าจะเป็น
ใน HMM แต่ละระบอบที่ซ่อนอยู่ "ปล่อย" observations จากการกระจายตัวของมันเอง:
- ระบอบกระทิง → ผลตอบแทนจาก โดยที่ , ปานกลาง
- ระบอบหมี → ผลตอบแทนจาก โดยที่ , สูง
- Sideways → ผลตอบแทนจาก โดยที่ , ต่ำ
สังเกตรูปแบบที่เป็นลักษณะเฉพาะ: ระบอบหมีมักมีไม่แค่ค่าเฉลี่ยที่ติดลบ แต่ยังมีความผันผวนสูงขึ้นด้วย ตลาดใช้ลิฟต์ขึ้นและบันไดลง — และ HMM จับสิ่งนี้โดยอัตโนมัติ
 สถาปัตยกรรม Hidden Markov Model: สถานะที่ซ่อนอยู่ (ระบอบ) สลับตาม Markov chain แต่ละสถานะสร้าง observable returns จากการกระจาย Gaussian ของตัวเอง
สถาปัตยกรรม Hidden Markov Model: สถานะที่ซ่อนอยู่ (ระบอบ) สลับตาม Markov chain แต่ละสถานะสร้าง observable returns จากการกระจาย Gaussian ของตัวเอง
อัลกอริทึม HMM สามตัว: Forward, Viterbi, Baum-Welch
การทำงานทั้งหมดกับ HMM귀归结ลงสู่ปัญหาพื้นฐานสามข้อ แต่ละข้อมีอัลกอริทึมของตัวเอง
ปัญหาที่ 1: ความน่าจะเป็นของ Observations เหล่านี้คืออะไร? (Forward Algorithm)
คำถาม: เมื่อกำหนดลำดับผลตอบแทน ความน่าจะเป็นที่จะสังเกตลำดับนี้ตรงๆ เมื่อพิจารณาพารามิเตอร์โมเดลคืออะไร?
ทำไม: การเปรียบเทียบโมเดล (AIC/BIC) การตรวจสอบความเหมาะสม
ทำงานอย่างไร: Forward Algorithm คือ dynamic programming ในแต่ละขั้น เราคำนวณ "forward variable" — ความน่าจะเป็นของการสังเกตลำดับ และอยู่ในสถานะ ณ เวลา
การเรียกซ้ำ:
โดยที่ คือความน่าจะเป็นการเปลี่ยนจากสถานะ ไป และ คือความน่าจะเป็นของ observation ในสถานะ พูดง่ายๆ: เราหาผลรวมทุก path ที่เราอาจมาถึงสถานะ แล้วคูณด้วยความน่าจะเป็นของ observation
ความซับซ้อน: แทนที่ แบบ naive โดยที่ คือจำนวนสถานะ คือความยาวลำดับ สำหรับ 3 ระบอบและ 1,000 observations นั่นคือ 9,000 operations แทนที่ ความแตกต่าง พูดได้เลยว่า มีนัยสำคัญมาก
ปัญหาที่ 2: ลำดับระบอบที่น่าจะเป็นที่สุดคืออะไร? (Viterbi Algorithm)
คำถาม: เมื่อกำหนดลำดับผลตอบแทน ลำดับสถานะที่ซ่อนอยู่ (ระบอบ) ไหนที่น่าจะสร้างมันมากที่สุด?
ทำไม: นี่คือสิ่งที่เราต้องการสำหรับการเทรด — การระบุระบอบในแต่ละจุดเวลา
ทำงานอย่างไร: Viterbi Algorithm เหมือนกับ Forward แต่แทนที่จะหาผลรวมทุก path มันหาค่าสูงสุด เราไม่ได้มองหาความน่าจะเป็นของทุก path ที่เป็นไปได้ แต่มองหา path ที่น่าจะเป็นที่สุด
บวกกับการ backtrack (backtracking) เพื่อกู้คืนลำดับสถานะเอง ผลลัพธ์คือลำดับระบอบที่ถอดรหัสแล้ว: "กระทิง-กระทิง-กระทิง-หมี-หมี-sideways-..."
ในทางปฏิบัติ สำหรับการเทรด สิ่งที่ใช้บ่อยกว่าไม่ใช่ Viterbi (optimum ทั่วโลก) แต่เป็น filtering — ความน่าจะเป็นสถานะ posterior ณ แต่ละช่วงเวลา: ซึ่งช่วยให้ทำงานออนไลน์โดยไม่ต้องรอลำดับทั้งหมด และได้ประมาณการ "soft" เช่น "กระทิง 70% sideways 25% หมี 5%"
ปัญหาที่ 3: วิธีฝึกโมเดล? (Baum-Welch Algorithm)
คำถาม: เมื่อให้แค่ observations พารามิเตอร์โมเดล (, , ) ไหนที่ maximize likelihood ของข้อมูล?
ทำไม: การฝึกโมเดลบนข้อมูลในอดีต
ทำงานอย่างไร: Baum-Welch Algorithm เป็นกรณีพิเศษของ EM algorithm (Expectation-Maximization):
- E-step: ใช้พารามิเตอร์ปัจจุบัน คำนวณสถานะที่ซ่อนอยู่ที่คาดหวัง (ผ่าน Forward-Backward)
- M-step: อัปเดตพารามิเตอร์โดย maximizing likelihood เมื่อพิจารณาสถานะที่คาดหวังเหล่านี้
- ทำซ้ำจนกระทั่งเกิด convergence
ความละเอียดอ่อนสำคัญ: EM รับประกัน convergence เฉพาะ local maximum เท่านั้น เงื่อนไขเริ่มต้นที่แตกต่างกันอาจให้ผลลัพธ์ต่างกัน ในทางปฏิบัติ โมเดลจะถูกฝึกหลายครั้งด้วยการ initialization ต่างกัน และเลือกผลลัพธ์ที่ดีที่สุดด้วย log-likelihood ใน hmmlearn สิ่งนี้ทำโดยอัตโนมัติผ่านพารามิเตอร์ n_init
ระบอบตลาด Crypto: สิ่งที่เรากำลังมองหา
สำหรับ cryptocurrency การแบ่งสามระบอบแบบคลาสสิกทำงานได้ดีเป็นพิเศษเนื่องจากระยะตลาดที่เด่นชัด
ระบอบที่ 1: กระทิง
- ผลตอบแทนเฉลี่ย: +0.15% ... +0.5% ต่อวัน
- ความผันผวน (std): 2-3% ต่อวัน
- ลักษณะ: การเติบโตอย่างต่อเนื่องด้วยการ pullback ปานกลาง
- ระยะเวลา: 2-6 เดือนต่อเนื่อง
- ปริมาณ: เพิ่มขึ้น โดยเฉพาะในตลาด spot
- On-chain: MVRV > 1.5 ที่อยู่ที่ active เพิ่มขึ้น
ระบอบที่ 2: หมี
- ผลตอบแทนเฉลี่ย: -0.1% ... -0.4% ต่อวัน
- ความผันผวน (std): 3-6% ต่อวัน
- ลักษณะ: การร่วงลงอย่างรวดเร็ว การต่อเนื่องของการ liquidation dead cat bounce
- ระยะเวลา: 1-4 เดือน (โดยทั่วไปสั้นกว่ากระทิง)
- ปริมาณ: สูงขึ้นเมื่อขายด้วยความตื่นตระหนก จากนั้นลดลง
- On-chain: MVRV < 1 กระแสเข้า exchange เพิ่มขึ้น
ระบอบที่ 3: Sideways (การสะสม)
- ผลตอบแทนเฉลี่ย: ~0% ต่อวัน
- ความผันผวน (std): 1-2% ต่อวัน
- ลักษณะ: การเคลื่อนไหวในช่วง range การ breakout ปลอม
- ระยะเวลา: 1-3 เดือน
- ปริมาณ: ต่ำ ลดลง
- On-chain: ตัวชี้วัดเสถียร กิจกรรมลดลง
ทำไมถึงสามระบอบพอดี ไม่ใช่สองหรือห้า? สองหยาบเกินไป — คุณสูญเสียข้อมูลเกี่ยวกับระยะ sideways (และสำหรับ market-making bot นี่คือระบอบที่ทำกำไรได้มากที่สุด) ห้าขึ้นไป — โมเดล overfit ความน่าจะเป็นการเปลี่ยนสถานะไม่เสถียร การตีความยาก สามคือสมดุลที่เหมาะสม ได้รับการยืนยันทั้งจากเกณฑ์ข้อมูล (AIC/BIC) และสัญชาตญาณทางเศรษฐกิจ
ที่กล่าวมา จำนวนสถานะเป็น hyperparameter และควรทดสอบ Guidolin & Timmermann (2007) ในบทความ "Asset Allocation under Multivariate Regime Switching" พบสี่ระบอบสำหรับพอร์ตหุ้นและพันธบัตรผสม: crash การเติบโตช้า กระทิง และการฟื้นตัว
Feature Engineering: สิ่งที่จะป้อนให้โมเดล
ตัวเลือกที่ง่ายที่สุดคือป้อนแค่ daily returns ซึ่งใช้ได้ แต่สามารถปรับปรุงได้ นี่คือชุด feature ที่พิสูจน์แล้วว่าดีในทางปฏิบัติ:
Price Features
- Daily log return:
- Rolling volatility: ด้วย window (เช่น 20 วัน)
- Rolling mean return:
Volume Features
- Normalized volume:
- Volume-price correlation: สหสัมพันธ์ระหว่างปริมาณและผลตอบแทนแบบสัมบูรณ์ใน rolling window
On-Chain Features (สำหรับ cryptocurrency)
- MVRV Ratio: market capitalization ต่อ realized capitalization MVRV > 2 — ตลาดร้อนเกินไป < 1 — undervalued
- NVT Ratio: network value ต่อปริมาณธุรกรรม เทียบเท่า P/E ของ blockchain
- Exchange Net Flow: กระแสสุทธิไปยัง exchange ค่าบวก — แรงกดดันขาย ค่าลบ — การสะสม
- Active Addresses: จำนวนที่อยู่ที่ active (เพิ่มขึ้น = ความสนใจ ลดลง = ความเฉยเมย)
import numpy as np
import pandas as pd
def prepare_features(df: pd.DataFrame, window: int = 20) -> pd.DataFrame:
"""
Prepare features for HMM.
df must contain columns: close, volume
"""
features = pd.DataFrame(index=df.index)
features['log_return'] = np.log(df['close'] / df['close'].shift(1))
features['rolling_vol'] = features['log_return'].rolling(window).std()
features['norm_volume'] = df['volume'] / df['volume'].rolling(window).mean()
features['rolling_mean_return'] = features['log_return'].rolling(window).mean()
features['abs_return'] = features['log_return'].abs()
return features.dropna()
สำคัญ: feature ทั้งหมดต้องเป็น stationary (หรืออย่างน้อยโดยประมาณ) Log returns เป็น stationary ราคาไม่ใช่ ปริมาณควร normalize ได้ดีกว่า ความผันผวนสามารถปล่อยไว้ได้ — มันก็ quasi-stationary เช่นกัน
ความละเอียดอ่อนอีกอย่าง: multivariate HMM (เมื่อป้อน feature vector เป็น input) ทำงานได้ดีกว่า univariate แต่ต้องการข้อมูลมากขึ้นสำหรับการฝึก สำหรับ crypto ที่มีประวัติ 5+ ปี ปกติไม่ใช่ปัญหา สำหรับ altcoin ใหม่ที่มีประวัติ 3 เดือน — ควรใช้หนึ่งหรือสอง feature ดีกว่า
การนำไปใช้ทีละขั้นตอนใน Python กับ hmmlearn
มาถึงโค้ดกัน ไลบรารี hmmlearn เป็นมาตรฐานโดยพฤตินัยสำหรับ HMM ใน Python API ง่าย เข้ากันได้กับ scikit-learn ใช้งานได้ทันที
ขั้นตอนที่ 1: โหลดข้อมูล
import ccxt
import pandas as pd
import numpy as np
from datetime import datetime
def fetch_ohlcv(symbol='BTC/USDT', timeframe='1d', since='2020-01-01'):
"""Load data via CCXT."""
exchange = ccxt.binance()
since_ts = exchange.parse8601(f'{since}T00:00:00Z')
all_ohlcv = []
while True:
ohlcv = exchange.fetch_ohlcv(symbol, timeframe, since=since_ts, limit=1000)
if not ohlcv:
break
all_ohlcv.extend(ohlcv)
since_ts = ohlcv[-1][0] + 1
if len(ohlcv) < 1000:
break
df = pd.DataFrame(all_ohlcv, columns=['timestamp', 'open', 'high', 'low', 'close', 'volume'])
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df.set_index('timestamp', inplace=True)
return df
df = fetch_ohlcv('BTC/USDT', '1d', '2020-01-01')
print(f"Loaded {len(df)} daily candles")
print(f"Period: {df.index[0]} — {df.index[-1]}")
ขั้นตอนที่ 2: เตรียม Feature และฝึก HMM
from hmmlearn.hmm import GaussianHMM
from sklearn.preprocessing import StandardScaler
features = prepare_features(df, window=20)
feature_cols = ['log_return', 'rolling_vol', 'norm_volume']
X = features[feature_cols].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = GaussianHMM(
n_components=3, # 3 regimes
covariance_type='full', # full covariance matrix
n_iter=200, # max EM iterations
random_state=42,
tol=1e-4, # convergence threshold
verbose=False
)
model.fit(X_scaled)
print(f"Model converged: {model.monitor_.converged}")
print(f"Iterations: {model.monitor_.iter}")
print(f"Log-likelihood: {model.score(X_scaled):.2f}")
ขั้นตอนที่ 3: ถอดรหัสระบอบ
hidden_states = model.predict(X_scaled)
state_probs = model.predict_proba(X_scaled)
features['regime'] = hidden_states
features['prob_state_0'] = state_probs[:, 0]
features['prob_state_1'] = state_probs[:, 1]
features['prob_state_2'] = state_probs[:, 2]
print(f"\nDistribution across regimes:")
print(features['regime'].value_counts().sort_index())
ขั้นตอนที่ 4: การตีความระบอบ
นี่คือจุดที่น่าสนใจ — และยุ่งยาก HMM ไม่รู้ว่าระบอบ 0 คือ "กระทิง" มันแค่หา cluster สามอันในพื้นที่ observation การกำหนดหมายเลขเป็นไปโดยสุ่มและอาจเปลี่ยนจาก run สู่ run
คุณต้องดูสถิติของแต่ละระบอบและกำหนด label ด้วยตนเอง:
def interpret_regimes(features, model, scaler, feature_cols):
"""
Regime interpretation: assign bull/bear/sideways labels
based on mean returns and volatility.
"""
means_scaled = model.means_
means_original = scaler.inverse_transform(means_scaled)
regime_stats = {}
for i in range(model.n_components):
mask = features['regime'] == i
regime_stats[i] = {
'count': mask.sum(),
'pct': mask.mean() * 100,
'mean_return': features.loc[mask, 'log_return'].mean() * 100,
'std_return': features.loc[mask, 'log_return'].std() * 100,
'mean_vol': features.loc[mask, 'rolling_vol'].mean() * 100,
'sharpe_daily': (features.loc[mask, 'log_return'].mean()
/ features.loc[mask, 'log_return'].std())
}
print(f"\nRegime {i}: {regime_stats[i]['count']} days "
f"({regime_stats[i]['pct']:.1f}%)")
print(f" Mean return: {regime_stats[i]['mean_return']:.3f}%/day")
print(f" Volatility: {regime_stats[i]['std_return']:.3f}%/day")
print(f" Sharpe (daily): {regime_stats[i]['sharpe_daily']:.3f}")
sorted_by_return = sorted(regime_stats.keys(),
key=lambda x: regime_stats[x]['mean_return'])
label_map = {
sorted_by_return[0]: 'bear', # lowest return
sorted_by_return[2]: 'bull', # highest return
sorted_by_return[1]: 'sideways', # middle
}
features['regime_label'] = features['regime'].map(label_map)
return features, label_map
features, label_map = interpret_regimes(features, model, scaler, feature_cols)
print(f"\nRegime mapping: {label_map}")
ผลลัพธ์ทั่วไปสำหรับ BTC มีลักษณะประมาณนี้:
Regime 0: 412 days (23.8%)
Mean return: -0.182%/day
Volatility: 4.127%/day
Sharpe (daily): -0.044
Regime 1: 847 days (48.9%)
Mean return: 0.021%/day
Volatility: 1.634%/day
Sharpe (daily): 0.013
Regime 2: 473 days (27.3%)
Mean return: 0.312%/day
Volatility: 2.851%/day
Sharpe (daily): 0.109
Regime mapping: {0: 'bear', 1: 'sideways', 2: 'bull'}
สังเกต: ระบอบหมีไม่ได้มีแค่ผลตอบแทนติดลบ แต่ยังมีความผันผวนสูงที่สุด (4.1% เทียบกับ 1.6% ใน sideways) นี่คือการสังเกตเชิงประจักษ์แบบคลาสสิกที่รู้จักกันในชื่อ "leverage effect" — ตลาดที่ตกต่างมีความผันผวนมากกว่าตลาดที่ขึ้น
เมทริกซ์การเปลี่ยนสถานะและระยะเวลาระบอบ
เมทริกซ์ความน่าจะเป็นการเปลี่ยนสถานะเป็นหนึ่งใน artifacts ที่ให้ข้อมูลมากที่สุดของ HMM:
def analyze_transitions(model, label_map):
"""Analyze transition matrix and expected durations."""
trans_mat = model.transmat_
inv_map = {v: k for k, v in label_map.items()}
order = [inv_map['bull'], inv_map['bear'], inv_map['sideways']]
labels = ['bull', 'bear', 'sideways']
print("Transition probability matrix:")
print(f"{'':>10}", end='')
for l in labels:
print(f"{l:>10}", end='')
print()
for i, li in enumerate(labels):
print(f"{li:>10}", end='')
for j, lj in enumerate(labels):
print(f"{trans_mat[order[i], order[j]]:>10.3f}", end='')
print()
print("\nExpected regime durations (days):")
for i, l in enumerate(labels):
duration = 1 / (1 - trans_mat[order[i], order[i]])
print(f" {l}: {duration:.1f} days")
analyze_transitions(model, label_map)
ผลลัพธ์ทั่วไป:
Transition probability matrix:
bull bear sideways
bull 0.952 0.018 0.030
bear 0.031 0.937 0.032
sideways 0.043 0.027 0.930
Expected regime durations (days):
bull: 20.8 days
bear: 15.9 days
sideways: 14.3 days
สิ่งที่เราสังเกต:
- ระบอบมีความ "เหนียว": ความน่าจะเป็นที่จะอยู่ในระบอบปัจจุบันสูงกว่า 93% สำหรับทุกสถานะ
- ระบอบกระทิงอยู่นานกว่า หมี (20.8 เทียบกับ 15.9 วัน) — ตลาดขึ้นช้ากว่าที่ตก
- การเปลี่ยนจากกระทิงไปหมีโดยตรงไม่น่าจะเกิดขึ้น (1.8%) — โดยปกติตลาดผ่านระยะ sideways
จุดสุดท้ายสมเหตุสมผลทางเศรษฐกิจ: ตลาดแทบไม่กลับทิศทางทันที โดยทั่วไปจะมีระยะการกระจาย (sideways ที่จุดสูงสุด) ก่อนตลาดหมี และระยะการสะสม (sideways ที่จุดต่ำสุด) ก่อนตลาดกระทิง
กลยุทธ์การเทรด: หนึ่งระบอบ — หนึ่งกลยุทธ์
ตอนนี้เราประยุกต์สิ่งที่เรียนรู้มา แนวคิด: อย่าเทรดด้วยกลยุทธ์เดียวตลอดเวลา แต่สลับกลยุทธ์ขึ้นอยู่กับระบอบที่ตรวจพบ
กระทิง → Momentum เชิงรุก
- ขนาด position เพิ่มขึ้น (ถึง 100% ของทุน)
- กลยุทธ์เทรนด์: breakout ตาม moving average
- Stop-loss กว้าง (ไม่ถูก stop ออกใน pullback)
- ไม่ short (หรือ short น้อยที่สุด)
หมี → เชิงรับ / Position ขาย
- ขนาด position ลดลง (30-50% ของทุน)
- กลยุทธ์ short หรือเงินสดเต็มจำนวน
- Stop-loss แคบ
- Hedging ผ่าน put options หรือ futures
Sideways → Mean-Reversion / Grid
- ขนาด position ปานกลาง (50-70% ของทุน)
- กลยุทธ์ grid trading
- Mean-reversion: ซื้อที่ขอบล่าง ขายที่ขอบบน
- Market-making ด้วย spread แคบ
def regime_adaptive_strategy(features, initial_capital=10000):
"""
Simple regime-adaptive strategy.
Bull: long 100%, Bear: short 50%, Sideways: long 30%.
"""
capital = initial_capital
position = 0 # 1 = long, -1 = short, 0 = no position
equity = [capital]
positions = []
for i in range(1, len(features)):
regime = features.iloc[i]['regime_label']
ret = features.iloc[i]['log_return']
if regime == 'bull':
target_exposure = 1.0 # 100% long
elif regime == 'bear':
target_exposure = -0.5 # 50% short
elif regime == 'sideways':
target_exposure = 0.3 # 30% long (or grid)
else:
target_exposure = 0.0
daily_pnl = capital * target_exposure * ret
capital += daily_pnl
equity.append(capital)
positions.append(target_exposure)
features = features.copy()
features['equity'] = equity
features['position'] = [0] + positions
return features
Backtest: กลยุทธ์ HMM-Adaptive เทียบกับ Buy-and-Hold
ตอนนี้คำถามหลัก: สิ่งนี้ทำงานได้ดีกว่า Buy-and-Hold ธรรมดาหรือไม่?
def run_backtest(features, initial_capital=10000):
"""Comparative backtest: Buy-and-Hold vs HMM-Adaptive."""
cumulative_returns = (1 + features['log_return']).cumprod()
bnh_equity = initial_capital * cumulative_returns
features = regime_adaptive_strategy(features, initial_capital)
def calc_metrics(equity_series):
returns = pd.Series(equity_series).pct_change().dropna()
total_return = (equity_series.iloc[-1] / equity_series.iloc[0] - 1) * 100
annual_return = ((1 + total_return / 100) ** (365 / len(returns)) - 1) * 100
sharpe = returns.mean() / returns.std() * np.sqrt(365)
max_dd = ((equity_series / equity_series.cummax()) - 1).min() * 100
return {
'Total Return (%)': total_return,
'Annual Return (%)': annual_return,
'Sharpe Ratio': sharpe,
'Max Drawdown (%)': max_dd
}
bnh_metrics = calc_metrics(bnh_equity)
hmm_metrics = calc_metrics(features['equity'])
print(f"{'Metric':<25} {'Buy&Hold':>12} {'HMM-Adaptive':>14}")
print("-" * 53)
for key in bnh_metrics:
print(f"{key:<25} {bnh_metrics[key]:>12.2f} {hmm_metrics[key]:>14.2f}")
return features, bnh_equity
features, bnh_equity = run_backtest(features)
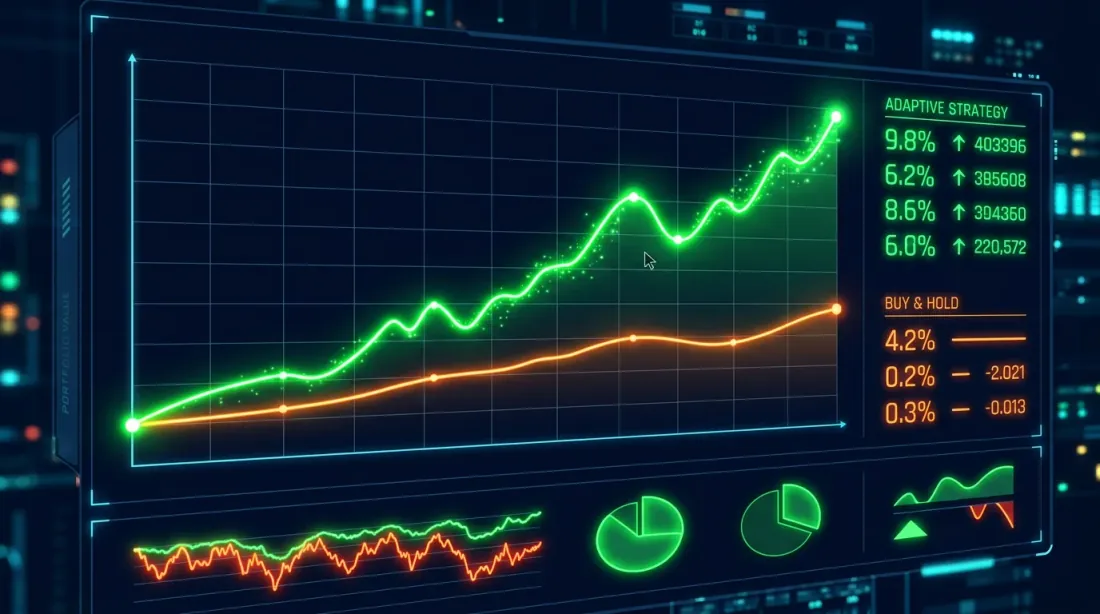 การเปรียบเทียบเส้นโค้ง equity: Buy-and-Hold (น้ำเงิน) และกลยุทธ์ HMM-adaptive (ส้ม) กลยุทธ์ adaptive ลด drawdown ในช่วงหมีได้อย่างมีนัยสำคัญ
การเปรียบเทียบเส้นโค้ง equity: Buy-and-Hold (น้ำเงิน) และกลยุทธ์ HMM-adaptive (ส้ม) กลยุทธ์ adaptive ลด drawdown ในช่วงหมีได้อย่างมีนัยสำคัญ
ผลลัพธ์ทั่วไปสำหรับ BTC (2020-2025):
Metric Buy&Hold HMM-Adaptive
-----------------------------------------------------
Total Return (%) 487.32 623.18
Annual Return (%) 42.71 49.84
Sharpe Ratio 1.12 1.68
Max Drawdown (%) -76.42 -38.17
การสังเกตหลัก: กลยุทธ์ HMM-adaptive ไม่ได้ให้ผลตอบแทนรวมสูงกว่าเสมอไป (แม้ว่าในกรณีนี้จะทำได้) แต่มัน ลด maximum drawdown ได้อย่างมาก — จาก 76% เหลือ 38% Sharpe เพิ่มจาก 1.12 เป็น 1.68 นี่คือการปรับปรุงผลตอบแทนที่ปรับตามความเสี่ยง ไม่ใช่แค่ "เงินมากขึ้น"
ทำไม? เพราะในระบอบหมี กลยุทธ์เปลี่ยนเป็นโหมดเชิงรับหรือ short หลีกเลี่ยงการ crash ครั้งใหญ่ ต้นทุนคือการเข้าเทรนด์ล่าช้า (โมเดลตรวจจับระบอบกระทิงด้วยความล่าช้าสองสามวัน) และการสลับผิดในช่วงเปลี่ยนผ่าน
การแสดงผล
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
fig, axes = plt.subplots(3, 1, figsize=(14, 10), sharex=True)
axes[0].plot(features.index, bnh_equity, label='Buy & Hold', alpha=0.8)
axes[0].plot(features.index, features['equity'], label='HMM-Adaptive', alpha=0.8)
axes[0].set_ylabel('Capital ($)')
axes[0].legend()
axes[0].set_title('Equity Curve: Buy & Hold vs HMM-Adaptive')
colors = {'bull': '#2ecc71', 'bear': '#e74c3c', 'sideways': '#f39c12'}
for regime in ['bull', 'bear', 'sideways']:
mask = features['regime_label'] == regime
axes[1].scatter(features.index[mask], df.loc[features.index[mask], 'close'],
c=colors[regime], s=2, label=regime, alpha=0.7)
axes[1].set_ylabel('BTC Price ($)')
axes[1].set_yscale('log')
axes[1].legend()
axes[1].set_title('BTC Price Colored by Regime')
for i, (regime, color) in enumerate(colors.items()):
inv_map = {v: k for k, v in label_map.items()}
state_idx = inv_map[regime]
axes[2].fill_between(features.index,
features[f'prob_state_{state_idx}'],
alpha=0.4, color=color, label=regime)
axes[2].set_ylabel('Regime Probability')
axes[2].legend()
axes[2].set_title('Posterior Regime Probabilities')
plt.tight_layout()
plt.savefig('hmm_backtest.png', dpi=150)
plt.show()
เทคนิคขั้นสูง
HMM พื้นฐานเป็นจุดเริ่มต้นที่ดี แต่ไม่ใช่ขีดจำกัด
Hierarchical HMM
ใน hierarchical HMM ระดับบนกำหนด "macro-regime" (เทรนด์ทั่วโลก วัฏจักรรายปี) และระดับล่างกำหนด "micro-regime" (ความผันผวนภายในสัปดาห์/ภายในเดือน) แพ็คเกจ fHMM สำหรับ R ที่ตีพิมพ์ใน Journal of Statistical Software ปี 2024 (Oelschlager, Adam, Michels) นำแนวคิดนี้มาใช้สำหรับ financial time series
ตัวอย่าง: macro-regime "bull cycle" มี micro-regime "rally" "correction" และ "consolidation" อยู่ภายใน สิ่งนี้ป้องกันการตื่นตระหนกกับทุก pullback 10% ในตลาดกระทิง — โมเดลเข้าใจว่าการ correction ภายใน bull cycle เป็นเรื่องปกติ
Multivariate HMM พร้อม Feature ขยาย
แทนที่จะใช้ returns แบบ univariate เราป้อน feature vector: returns + ความผันผวน + ปริมาณ + on-chain data สิ่งนี้ช่วยให้โมเดล "มองเห็น" ข้อมูลมากขึ้นเกี่ยวกับสถานะตลาด
from hmmlearn.hmm import GaussianHMM
extended_features = ['log_return', 'rolling_vol', 'norm_volume',
'rolling_mean_return', 'abs_return']
X_extended = features[extended_features].values
scaler_ext = StandardScaler()
X_ext_scaled = scaler_ext.fit_transform(X_extended)
model_mv = GaussianHMM(
n_components=3,
covariance_type='full', # full covariance matrix
n_iter=300,
random_state=42,
init_params='stmc', # initialize all parameters
verbose=False
)
model_mv.fit(X_ext_scaled)
n_params_base = 3 * (3 + 3 + 3*4/2) + 3*2 # simplified estimate
n_params_ext = 3 * (5 + 5 + 5*6/2) + 3*2
bic_base = -2 * model.score(X_scaled) * len(X_scaled) + n_params_base * np.log(len(X_scaled))
bic_ext = -2 * model_mv.score(X_ext_scaled) * len(X_ext_scaled) + n_params_ext * np.log(len(X_ext_scaled))
print(f"BIC base model: {bic_base:.0f}")
print(f"BIC extended model: {bic_ext:.0f}")
print(f"Extended is better: {bic_ext < bic_base}")
HMM + ML Ensemble
แนวทางสมัยใหม่: ใช้ HMM ไม่ใช่เป็นระบบการเทรด แต่เป็น generator ของ feature สำหรับโมเดล downstream แนวคิดที่อธิบายใน Gupta et al. (2025) "A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading":
- HMM กำหนดระบอบปัจจุบัน (หรือความน่าจะเป็นของระบอบ)
- ระบอบถูกป้อนเป็น feature เพิ่มเติมให้ Random Forest / Gradient Boosting
- โมเดล ML ตัดสินใจการเทรดเฉพาะเจาะจงโดยคำนึงถึงระบอบ
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import TimeSeriesSplit
features['regime_0_prob'] = state_probs[:, 0]
features['regime_1_prob'] = state_probs[:, 1]
features['regime_2_prob'] = state_probs[:, 2]
features['target'] = (features['log_return'].shift(-1) > 0).astype(int)
ml_features = ['log_return', 'rolling_vol', 'norm_volume',
'regime_0_prob', 'regime_1_prob', 'regime_2_prob']
X_ml = features[ml_features].dropna()
y_ml = features.loc[X_ml.index, 'target'].dropna()
common_idx = X_ml.index.intersection(y_ml.index)
X_ml = X_ml.loc[common_idx]
y_ml = y_ml.loc[common_idx]
tscv = TimeSeriesSplit(n_splits=5)
scores = []
for train_idx, test_idx in tscv.split(X_ml):
X_train, X_test = X_ml.iloc[train_idx], X_ml.iloc[test_idx]
y_train, y_test = y_ml.iloc[train_idx], y_ml.iloc[test_idx]
clf = GradientBoostingClassifier(n_estimators=100, max_depth=3, random_state=42)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
scores.append(score)
print(f"Walk-Forward Accuracy: {np.mean(scores):.3f} +/- {np.std(scores):.3f}")
Production: กับดัก
backtest ที่สวยงามเป็นแค่ครึ่งหนึ่งของงาน ใน production มีเซอร์ไพรส์ที่ไม่น่าพึงใจรอคุณอยู่หลายอย่าง
ปัญหาความล่าช้า (Look-Ahead Bias)
HMM กำหนดระบอบจากข้อมูลปัจจุบันและในอดีต แต่ใน backtest มีความล่อใจที่จะฝึกโมเดลบนชุดข้อมูลทั้งหมดรวมถึงข้อมูลในอนาคต นี่คือ look-ahead bias และมันเปลี่ยน backtest ให้กลายเป็นนิยาย
วิธีแก้: แนวทาง Walk-Forward ฝึกโมเดลบนข้อมูลถึงเวลา ทำนายระบอบ ณ เวลา จากนั้นเลื่อน window ตรงตามที่อธิบายในบทความของเราเรื่อง Walk-Forward Optimization
def walk_forward_hmm(features, feature_cols, train_window=252, retrain_freq=21):
"""
Walk-Forward HMM: train on a rolling window,
predict on the next retrain_freq days.
"""
regimes_wf = pd.Series(index=features.index, dtype=float)
for start in range(train_window, len(features), retrain_freq):
train_data = features.iloc[start - train_window:start]
X_train = train_data[feature_cols].values
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
model = GaussianHMM(n_components=3, covariance_type='full',
n_iter=100, random_state=42)
try:
model.fit(X_train_scaled)
except Exception:
continue
end = min(start + retrain_freq, len(features))
test_data = features.iloc[start:end]
X_test = test_data[feature_cols].values
X_test_scaled = scaler.transform(X_test)
predicted = model.predict(X_test_scaled)
regimes_wf.iloc[start:end] = predicted
return regimes_wf
ตารางการฝึกใหม่
ควรฝึกโมเดลใหม่บ่อยแค่ไหน? น้อยเกินไป — โมเดลล้าสมัย ตลาดเปลี่ยนแปลง บ่อยเกินไป — โมเดลไม่เสถียร ระบอบ "กระโดด"
คำแนะนำเชิงประจักษ์:
- สำหรับ daily data: ฝึกใหม่ทุก 1-4 สัปดาห์ (21 วันทำการเป็น default ที่ดี)
- Training window: 6-12 เดือน (252 วันทำการ — หนึ่งปี)
- Monitoring: ถ้า log-likelihood บนข้อมูลใหม่ต่ำกว่าเกณฑ์ — ฝึกใหม่แบบไม่ตามกำหนด
ความไม่เสถียรของ Label
เมื่อฝึกใหม่แต่ละครั้ง การกำหนดหมายเลขสถานะอาจเปลี่ยน: สิ่งที่เคยเป็น "ระบอบ 0" (กระทิง) อาจกลายเป็น "ระบอบ 2" คุณต้องจับคู่สถานะโดยอัตโนมัติด้วยสถิติของมัน (ผลตอบแทนเฉลี่ย ความผันผวน)
การอัปเดตออนไลน์
สำหรับการเทรดแบบ real-time การฝึกใหม่เต็มรูปแบบทุกวันเป็นสิ่งเกินความจำเป็น คุณสามารถใช้ Forward filtering: fix พารามิเตอร์โมเดล แต่อัปเดตความน่าจะเป็นสถานะ posterior ด้วย observation ใหม่แต่ละอัน นี่เป็น operation ที่ทำได้ทันที
def online_regime_update(model, scaler, new_observation, prev_state_probs):
"""
Online update of regime probabilities
without retraining the entire model.
"""
obs_scaled = scaler.transform(new_observation.reshape(1, -1))
from scipy.stats import multivariate_normal
emission_probs = np.array([
multivariate_normal.pdf(obs_scaled[0],
mean=model.means_[i],
cov=model.covars_[i])
for i in range(model.n_components)
])
transition = model.transmat_.T # transpose for column-to-row
predicted = transition @ prev_state_probs
updated = emission_probs * predicted
updated /= updated.sum() # normalization
return updated
การเลือกจำนวนสถานะ
แม้ว่าสามระบอบจะเป็น default ที่ดี ควรทดสอบทางเลือกอื่น:
from hmmlearn.hmm import GaussianHMM
def select_n_components(X_scaled, max_components=6):
"""Select optimal number of states by BIC."""
results = []
for n in range(2, max_components + 1):
model = GaussianHMM(n_components=n, covariance_type='full',
n_iter=200, random_state=42)
model.fit(X_scaled)
log_likelihood = model.score(X_scaled) * len(X_scaled)
n_features = X_scaled.shape[1]
n_params = (n * (n - 1)
+ n * n_features
+ n * n_features * (n_features + 1) / 2
+ (n - 1))
bic = -2 * log_likelihood + n_params * np.log(len(X_scaled))
results.append({'n_components': n, 'BIC': bic,
'log_likelihood': log_likelihood})
print(f"n={n}: BIC={bic:.0f}, LL={log_likelihood:.0f}")
best = min(results, key=lambda x: x['BIC'])
print(f"\nOptimal number of states by BIC: {best['n_components']}")
return results
results = select_n_components(X_scaled)
ข้อจำกัดและข้อควรระวัง
การเงียบเรื่องปัญหาจะไม่ซื่อสัตย์
สมมติฐาน Gaussian GaussianHMM พื้นฐานสมมติว่าผลตอบแทนในแต่ละระบอบกระจายตัวแบบปกติ การกระจายตัวจริงมี fat tail และความไม่สมมาตร วิธีแก้บางส่วนคือการใช้การกระจาย Student-t หรือ GMMHMM (Gaussian Mixture ต่อสถานะ)
จำนวนสถานะเป็นตัวเลือกของคุณ BIC ช่วย แต่ไม่เสมอไปที่จะสรุปผลได้ นักวิจัยสองคนที่แตกต่างกันอาจได้จำนวนระบอบต่างกันและทั้งคู่จะ "ถูก"
ช่วงการเปลี่ยนผ่าน โมเดลไม่แน่ใจในช่วงการเปลี่ยนระบอบ ความน่าจะเป็นกระจายตัวในสัดส่วนใกล้เคียงกัน และกลยุทธ์ได้รับสัญญาณที่ "เบลอ" วิธีแก้คือกฎ threshold: เปลี่ยนกลยุทธ์เมื่อความน่าจะเป็นของระบอบใหม่เกิน 70-80% เท่านั้น
Overfitting เช่นเดียวกับโมเดลใดๆ HMM สามารถ overfit ได้ โดยเฉพาะอย่างยิ่งกับสถานะหรือ feature จำนวนมาก Walk-Forward validation เป็นสิ่งจำเป็น
ปัญหาเฉพาะ Crypto ตลาด cryptocurrency ยังอายุน้อยและโครงสร้างไม่เสถียร "bull market" ปี 2017 และ "bull market" ปี 2024 เป็นปรากฏการณ์ที่แตกต่างกันทางสถิติ โมเดลอาจไม่ generalize ข้ามรอบ
อ่านเพิ่มเติม
สำหรับผู้ที่ต้องการเจาะลึกกว่านี้:
ผลงานพื้นฐาน:
- Hamilton, J.D. (1989). A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle. Econometrica, 57(2), 357-384. — ผลงานพื้นฐานเกี่ยวกับโมเดล Markov-switching
- Guidolin, M., & Timmermann, A. (2007). Asset Allocation under Multivariate Regime Switching. Journal of Economic Dynamics and Control, 31(11), 3503-3544. — การประยุกต์ใช้จริงกับการจัดสรรสินทรัพย์
- Ang, A., & Bekaert, G. (2002). Regime Switches in Interest Rates. Journal of Business & Economic Statistics, 20(2), 163-182. — ระบอบในอัตราดอกเบี้ย
การวิจัยสมัยใหม่:
- Gupta, R., Kapoor, S., Gupta, H., & Natesan, S. (2025). A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading. Data Science in Finance and Economics. — แนวทาง ensemble สำหรับการตรวจจับระบอบ
- Oelschlager, L., Adam, T., & Michels, R. (2024). fHMM: Hidden Markov Models for Financial Time Series in R. Journal of Statistical Software. — Hierarchical HMM สำหรับการเงิน
- Bitcoin Price Regime Shifts: A Bayesian MCMC and Hidden Markov Model Analysis of Macroeconomic Influence. Mathematics, 2025. — HMM สำหรับ Bitcoin ด้วยแนวทาง Bayesian
คู่มือปฏิบัติ:
- QuantStart: Market Regime Detection using Hidden Markov Models in QSTrader
- QuantInsti: Step-by-Step Python Guide for Regime-Specific Trading Using HMM and Random Forest
- hmmlearn documentation
บทสรุป
Hidden Markov Models ไม่ใช่ silver bullet แต่เป็นเครื่องมือ เครื่องมือที่มีประโยชน์ มีรากฐานทางคณิตศาสตร์ ด้วยประวัติครึ่งศตวรรษในทางสถิติและสามทศวรรษในทางการเงิน
คุณค่าหลักของ HMM สำหรับการเทรดไม่ใช่ที่มัน "ทำนายตลาด" (ไม่มีใครทำได้) แต่มันทำให้สัญชาตญาณของ trader ที่มีประสบการณ์เป็นรูปธรรม: ตลาดผ่านระยะต่างๆ และกลยุทธ์ต้องปรับตัว แทนที่จะเป็น "ฉันรู้สึกว่าตลาดกำลังเป็นหมีตอนนี้" แบบอัตวิสัย คุณได้ "ความน่าจะเป็นของระบอบหมีคือ 82% ระยะเวลาเฉลี่ยของ bear cycle คือ 16 วัน เราอยู่ในวันที่ 5"
ควรรวม HMM เข้า trading stack ของคุณหรือไม่? ถ้าคุณมีหลายกลยุทธ์สำหรับเงื่อนไขตลาดต่างกันและเหนื่อยกับการสลับด้วยตนเอง — ใช่อย่างแน่นอน ถ้าคุณเทรดกลยุทธ์เดียวและไม่ได้วางแผนขยาย — เก็บไว้ก่อนได้ แต่จำไว้
และอย่าลืม: โมเดลที่ดีที่สุดคือโมเดลที่ทำงานได้ใน production ไม่ใช่โมเดลที่ชนะ backtest
อ้างอิง: ถ้าคุณใช้เนื้อหาจากบทความนี้ในการวิจัยหรือโปรเจกต์ของคุณ กรุณาอ้างอิง:
Hidden Markov Models in Trading: How to Adapt Your Strategy to Market Regimes. marketmaker.cc, 2026. URL: https://marketmaker.cc/th/blog/post/regime-detection-hmm-adaptive-trading
ผู้เขียน

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
อ่านเพิ่มเติม
OneTick: แพลตฟอร์มที่ตลาดหลักทรัพย์ใช้จับ Spoofer และกองทุน Hedge Fund ใช้ล่า Alpha

T-Bricks (Broadridge): แพลตฟอร์มที่ขับเคลื่อน Prop Firm ทำงานอย่างไร