Mô Hình Markov Ẩn trong Giao Dịch: Cách Thích Nghi Chiến Lược Với Chế Độ Thị Trường
Mọi nhà giao dịch thuật toán đều có một khoảnh khắc khủng hoảng hiện sinh. Bạn dành ba tháng xây dựng một chiến lược. Backtest cho thấy Sharpe 2.4. Đường cong vốn như một tác phẩm nghệ thuật. Bạn khởi động bot. Hai tuần đầu là cảm giác hưng phấn — chiến lược đang tạo ra alpha. Rồi thị trường "chuyển đổi" — và con bot momentum của bạn bắt đầu đốt cháy vốn một cách có hệ thống trong vùng dao động, mua mỗi đỉnh cục bộ và bán mỗi đáy cục bộ.
Vấn đề không phải ở chiến lược. Vấn đề là thị trường không phải một hệ thống duy nhất, mà là nhiều hệ thống, và chúng chuyển đổi giữa nhau mà không báo trước. Chiến lược momentum, hoàn hảo trong xu hướng, tàn phá tài khoản trong vùng dao động. Chiến lược lưới kiếm tiền trong thị trường đi ngang nhưng nổ tung khi có biến động định hướng. Mean-reversion ổn định trong thị trường bình lặng, bị gọi ký quỹ khi gặp thiên nga đen.
Câu hỏi không phải "chiến lược nào tốt hơn," mà là "chế độ thị trường hiện tại là gì và chiến lược nào phù hợp với nó." Và đây chính là nơi Mô hình Markov Ẩn (HMM) xuất hiện — một khung toán học cho phép bạn hình thức hóa trực giác này.
Thị Trường Phi Dừng, và Đó Không Phải Lỗi, Mà Là Đặc Tính
Hãy bắt đầu từ một sự thật khó chịu: hầu hết các mô hình thống kê cơ bản đều giả định tính dừng của dữ liệu. Trung bình và phương sai không thay đổi theo thời gian, tự tương quan là hằng số, phân phối ổn định. Chuỗi thời gian tài chính vi phạm tất cả các giả định này cùng một lúc.
Hãy nhìn vào lợi suất hằng ngày của BTC trong 5 năm qua. Lợi suất hằng ngày trung bình trong đợt tăng giá năm 2024 khoảng +0.3%, với độ lệch chuẩn ~2.5%. Trong thị trường gấu năm 2022 — trung bình là -0.15%, độ lệch chuẩn ~4%. Trong thị trường đi ngang mùa hè 2023 — trung bình ~0%, độ lệch chuẩn ~1.5%. Đây là ba chế độ thống kê hoàn toàn khác nhau với các phân phối khác nhau.
Về mặt hình thức: gọi là lợi suất tại thời điểm . Trong thế giới dừng, với các tham số không đổi. Trong thực tế, bản thân các tham số là các quá trình ngẫu nhiên: , trong đó là trạng thái ẩn (chế độ thị trường), chuyển đổi giữa một số lượng hữu hạn các giá trị.
Ý tưởng này được James Hamilton hình thức hóa năm 1989 trong bài báo nền tảng "A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle." Ông chỉ ra rằng chu kỳ kinh doanh có thể được mô hình hóa như sự chuyển đổi giữa hai trạng thái ẩn — suy thoái và tăng trưởng — sử dụng cơ chế Markov. Kể từ đó, mô hình của Hamilton đã trở thành một trong những công cụ được trích dẫn nhiều nhất trong kinh tế lượng.
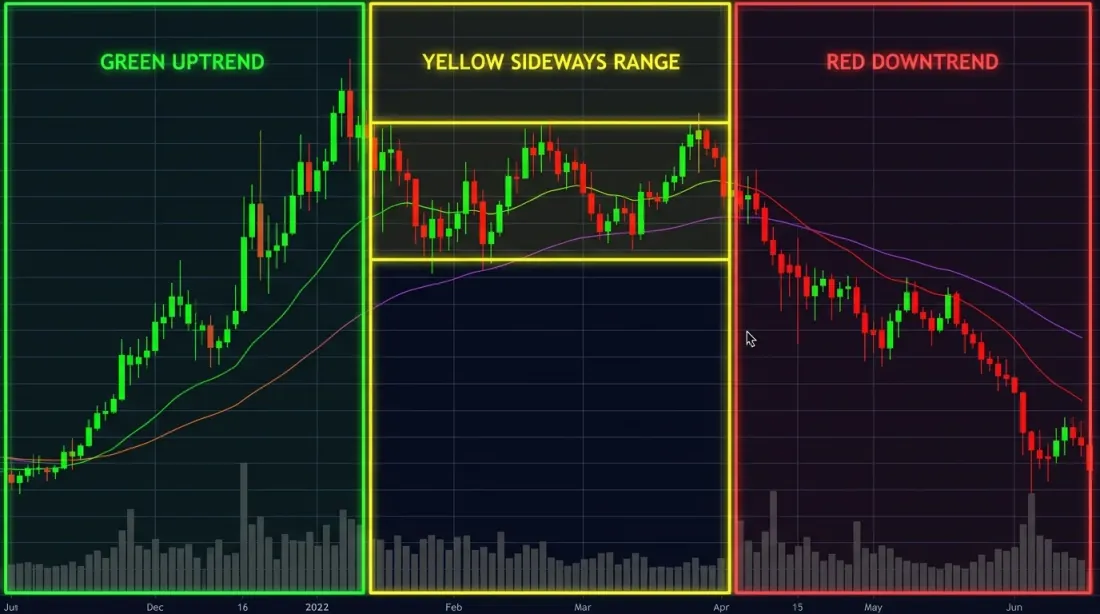 Ba chế độ thị trường — tăng giá (xanh lá), giảm giá (đỏ), và đi ngang (vàng) — rõ ràng về mặt hình ảnh khi nhìn lại, nhưng phát hiện sự chuyển đổi trong thời gian thực khó hơn đáng kể.
Ba chế độ thị trường — tăng giá (xanh lá), giảm giá (đỏ), và đi ngang (vàng) — rõ ràng về mặt hình ảnh khi nhìn lại, nhưng phát hiện sự chuyển đổi trong thời gian thực khó hơn đáng kể.
HMM: Trực Giác Qua Phép Loại Suy
Trước khi đi vào công thức, hãy xây dựng một số trực giác.
Chuỗi Markov: Không Có Bộ Nhớ
Chuỗi Markov là một quá trình ngẫu nhiên trong đó tương lai chỉ phụ thuộc vào hiện tại, không phải quá khứ. Thời tiết ngày mai phụ thuộc vào thời tiết hôm nay, nhưng không phụ thuộc vào thời tiết một tuần trước (một sự đơn giản hóa mạnh, nhưng hoạt động như một mô hình).
Chế độ thị trường hoạt động tương tự. Nếu hôm nay thị trường ở chế độ tăng giá, xác suất duy trì ngày mai là cao (giả sử 95%). Xác suất chuyển sang giảm giá là thấp (3%). Sang đi ngang — còn thấp hơn (2%). Đây là ma trận xác suất chuyển đổi.
Tăng Giảm Đi Ngang
Tăng [0.95 0.03 0.02 ]
Giảm [0.04 0.93 0.03 ]
Đi Ngang[0.05 0.05 0.90 ]
Chú ý: các phần tử đường chéo cao — các chế độ "có tính bám dính." Thị trường không nhảy từ tăng sang giảm mỗi ngày. Nó ở trong một chế độ trong nhiều tuần và tháng trước khi chuyển đổi. Thời gian dự kiến của một chế độ là . Đối với chế độ tăng với , đó là 20 ngày. Đối với chế độ giảm với — khoảng 14 ngày.
Trạng Thái Ẩn: Chúng Ta Chỉ Thấy Cái Bóng
Từ khóa là "ẩn." Chúng ta không quan sát trực tiếp chế độ thị trường. Không ai dựng biển "Chú ý, đang chuyển sang chế độ giảm giá." Chúng ta chỉ thấy quan sát — lợi suất, biến động, khối lượng. Chế độ là một biến tiềm ẩn phải được suy luận từ các quan sát.
Cũng giống như đang ở trong một căn phòng không có cửa sổ và cố gắng xác định thời tiết bằng cách nhìn vào cách mọi người từ bên ngoài vào mặc gì. Một chiếc ô? Có lẽ đang mưa. Quần short và kính râm? Trời nắng. Nhưng một người mặc quần short không có nghĩa là nhất định trời nắng — có thể họ chỉ là người lạc quan. Bạn cần tích lũy các quan sát và ước tính xác suất trạng thái ẩn.
Trong HMM, mỗi chế độ ẩn "phát ra" các quan sát từ phân phối riêng của nó:
- Chế độ tăng → lợi suất từ , trong đó , vừa phải
- Chế độ giảm → lợi suất từ , trong đó , cao
- Đi ngang → lợi suất từ , trong đó , thấp
Chú ý đến mô hình đặc trưng: chế độ giảm thường không chỉ có trung bình âm, mà còn có biến động cao hơn. Thị trường đi thang máy xuống và đi cầu thang lên — và HMM nắm bắt điều này tự động.
 Kiến trúc Mô hình Markov Ẩn: các trạng thái ẩn (chế độ) chuyển đổi theo chuỗi Markov, mỗi trạng thái tạo ra các lợi suất quan sát được từ phân phối Gaussian riêng của nó.
Kiến trúc Mô hình Markov Ẩn: các trạng thái ẩn (chế độ) chuyển đổi theo chuỗi Markov, mỗi trạng thái tạo ra các lợi suất quan sát được từ phân phối Gaussian riêng của nó.
Ba Thuật Toán HMM: Forward, Viterbi, Baum-Welch
Toàn bộ công việc với HMM quy về ba bài toán cơ bản, mỗi bài có thuật toán riêng.
Bài Toán 1: Xác Suất Của Các Quan Sát Này Là Bao Nhiêu? (Thuật Toán Forward)
Câu hỏi: Cho một chuỗi lợi suất, xác suất quan sát chính xác chuỗi này với các tham số mô hình cho trước là bao nhiêu?
Tại sao: So sánh mô hình (AIC/BIC), kiểm tra độ phù hợp.
Cách hoạt động: Thuật toán Forward là lập trình động. Tại mỗi bước , chúng ta tính "biến forward" — xác suất quan sát chuỗi và ở trạng thái tại thời điểm .
Đệ quy:
Trong đó là xác suất chuyển đổi từ trạng thái sang , và là xác suất quan sát trong trạng thái . Bằng lời: chúng ta tổng hợp trên tất cả các đường dẫn có thể đến trạng thái , và nhân với xác suất quan sát.
Độ phức tạp: thay vì ngây thơ, trong đó là số trạng thái, là độ dài chuỗi. Với 3 chế độ và 1000 quan sát, đó là 9000 phép tính thay vì . Sự khác biệt, hãy nói, là đáng kể.
Bài Toán 2: Chuỗi Chế Độ Có Khả Năng Nhất Là Gì? (Thuật Toán Viterbi)
Câu hỏi: Cho một chuỗi lợi suất, chuỗi trạng thái ẩn (chế độ) nào có khả năng đã tạo ra nó nhất?
Tại sao: Đây chính xác là điều chúng ta cần cho giao dịch — xác định chế độ tại mỗi thời điểm.
Cách hoạt động: Thuật toán Viterbi giống như Forward, nhưng thay vì tổng hợp trên tất cả các đường dẫn, nó lấy tối đa. Chúng ta tìm kiếm không phải xác suất của tất cả các đường dẫn có thể, mà là đường dẫn có xác suất cao nhất.
Cộng thêm một lượt duyệt ngược (backtracking) để khôi phục chuỗi trạng thái. Kết quả là một chuỗi chế độ được giải mã: "tăng-tăng-tăng-giảm-giảm-ngang-..."
Trong thực tế, cho giao dịch, điều thường được sử dụng hơn không phải Viterbi (tối ưu toàn cục) mà là lọc — xác suất trạng thái hậu nghiệm tại mỗi thời điểm: . Điều này cho phép làm việc trực tuyến mà không cần chờ toàn bộ chuỗi, và nhận được các ước tính "mềm" như "70% tăng, 25% ngang, 5% giảm."
Bài Toán 3: Làm Thế Nào Để Huấn Luyện Mô Hình? (Thuật Toán Baum-Welch)
Câu hỏi: Chỉ cho các quan sát, tham số mô hình (, , ) nào tối đa hóa khả năng dữ liệu?
Tại sao: Huấn luyện mô hình trên dữ liệu lịch sử.
Cách hoạt động: Thuật toán Baum-Welch là trường hợp đặc biệt của thuật toán EM (Expectation-Maximization):
- Bước E: Sử dụng tham số hiện tại, tính các trạng thái ẩn kỳ vọng (qua Forward-Backward)
- Bước M: Cập nhật tham số bằng cách tối đa hóa khả năng cho các trạng thái kỳ vọng này
- Lặp lại cho đến khi hội tụ
Một sắc thái quan trọng: EM chỉ đảm bảo hội tụ đến cực đại cục bộ. Các điều kiện ban đầu khác nhau có thể cho kết quả khác nhau. Trong thực tế, mô hình được huấn luyện nhiều lần với các khởi tạo khác nhau, và kết quả tốt nhất được chọn theo log-likelihood. Trong hmmlearn, điều này được thực hiện tự động qua tham số n_init.
Chế Độ Thị Trường Crypto: Chúng Ta Đang Tìm Kiếm Gì
Đối với tiền điện tử, phân chia ba chế độ cổ điển hoạt động đặc biệt tốt do các giai đoạn thị trường rõ ràng.
Chế Độ 1: Tăng Giá
- Lợi suất trung bình: +0.15% ... +0.5% mỗi ngày
- Biến động (std): 2-3% mỗi ngày
- Đặc điểm: tăng trưởng bền vững với các đợt điều chỉnh vừa phải
- Thời gian: 2-6 tháng liên tục
- Khối lượng: tăng, đặc biệt trên thị trường giao ngay
- On-chain: MVRV > 1.5, địa chỉ hoạt động tăng
Chế Độ 2: Giảm Giá
- Lợi suất trung bình: -0.1% ... -0.4% mỗi ngày
- Biến động (std): 3-6% mỗi ngày
- Đặc điểm: sụp đổ mạnh, chuỗi thanh lý, phục hồi giả
- Thời gian: 1-4 tháng (thường ngắn hơn tăng giá)
- Khối lượng: tăng đột biến khi bán tháo hoảng loạn, sau đó giảm dần
- On-chain: MVRV < 1, dòng vào sàn giao dịch tăng
Chế Độ 3: Đi Ngang (tích lũy)
- Lợi suất trung bình: ~0% mỗi ngày
- Biến động (std): 1-2% mỗi ngày
- Đặc điểm: chuyển động trong vùng, đột phá giả
- Thời gian: 1-3 tháng
- Khối lượng: thấp, giảm dần
- On-chain: các chỉ số ổn định, hoạt động giảm
Tại sao chính xác là ba chế độ chứ không phải hai hoặc năm? Hai thì quá thô — bạn mất thông tin về giai đoạn đi ngang (và đối với các bot tạo lập thị trường, đây là chế độ sinh lời nhất). Năm hoặc hơn — mô hình trở nên quá khớp, xác suất chuyển đổi không ổn định, khó giải thích. Ba là sự cân bằng tối ưu, được xác nhận bởi cả tiêu chí thông tin (AIC/BIC) và trực giác kinh tế.
Tuy nhiên, số lượng trạng thái là một siêu tham số và nên được kiểm tra. Guidolin & Timmermann (2007) trong bài báo "Asset Allocation under Multivariate Regime Switching" đã tìm thấy bốn chế độ cho danh mục cổ phiếu-trái phiếu hỗn hợp: sụp đổ, tăng trưởng chậm, tăng giá, và phục hồi.
Kỹ Thuật Đặc Trưng: Nên Cho Mô Hình Ăn Gì
Lựa chọn đơn giản nhất là chỉ đưa vào lợi suất hằng ngày. Điều này hoạt động, nhưng có thể cải thiện. Đây là bộ đặc trưng đã chứng minh được trong thực tế:
Đặc Trưng Giá
- Lợi suất log hằng ngày:
- Biến động trượt: trên cửa sổ (ví dụ: 20 ngày)
- Lợi suất trung bình trượt:
Đặc Trưng Khối Lượng
- Khối lượng chuẩn hóa:
- Tương quan khối lượng-giá: tương quan giữa khối lượng và lợi suất tuyệt đối trên cửa sổ trượt
Đặc Trưng On-Chain (cho tiền điện tử)
- Tỷ lệ MVRV: vốn hóa thị trường so với vốn hóa đã thực hiện. MVRV > 2 — thị trường quá nhiệt, < 1 — định giá thấp
- Tỷ lệ NVT: giá trị mạng lưới so với khối lượng giao dịch. Tương đương P/E của blockchain
- Dòng Ròng Sàn Giao Dịch: dòng ròng vào sàn giao dịch. Dương — áp lực bán, âm — tích lũy
- Địa Chỉ Hoạt Động: số địa chỉ hoạt động (tăng = quan tâm, giảm = thờ ơ)
import numpy as np
import pandas as pd
def prepare_features(df: pd.DataFrame, window: int = 20) -> pd.DataFrame:
"""
Prepare features for HMM.
df must contain columns: close, volume
"""
features = pd.DataFrame(index=df.index)
features['log_return'] = np.log(df['close'] / df['close'].shift(1))
features['rolling_vol'] = features['log_return'].rolling(window).std()
features['norm_volume'] = df['volume'] / df['volume'].rolling(window).mean()
features['rolling_mean_return'] = features['log_return'].rolling(window).mean()
features['abs_return'] = features['log_return'].abs()
return features.dropna()
Quan trọng: tất cả các đặc trưng phải là dừng (hoặc ít nhất là xấp xỉ dừng). Lợi suất log là dừng. Giá thì không. Khối lượng tốt hơn nên chuẩn hóa. Biến động có thể để nguyên — nó cũng là quasi-stationary.
Một sắc thái khác: HMM đa biến (khi vector đặc trưng được đưa vào làm đầu vào) hoạt động tốt hơn đơn biến, nhưng cần nhiều dữ liệu hơn để huấn luyện. Đối với crypto với lịch sử 5+ năm, điều này thường không phải vấn đề. Đối với một altcoin mới với 3 tháng lịch sử — tốt hơn nên bám vào một hoặc hai đặc trưng.
Triển Khai Từng Bước Trong Python với hmmlearn
Hãy đến với code. Thư viện hmmlearn là tiêu chuẩn thực tế cho HMM trong Python. API đơn giản, tương thích với scikit-learn, hoạt động ngay lập tức.
Bước 1: Tải Dữ Liệu
import ccxt
import pandas as pd
import numpy as np
from datetime import datetime
def fetch_ohlcv(symbol='BTC/USDT', timeframe='1d', since='2020-01-01'):
"""Load data via CCXT."""
exchange = ccxt.binance()
since_ts = exchange.parse8601(f'{since}T00:00:00Z')
all_ohlcv = []
while True:
ohlcv = exchange.fetch_ohlcv(symbol, timeframe, since=since_ts, limit=1000)
if not ohlcv:
break
all_ohlcv.extend(ohlcv)
since_ts = ohlcv[-1][0] + 1
if len(ohlcv) < 1000:
break
df = pd.DataFrame(all_ohlcv, columns=['timestamp', 'open', 'high', 'low', 'close', 'volume'])
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df.set_index('timestamp', inplace=True)
return df
df = fetch_ohlcv('BTC/USDT', '1d', '2020-01-01')
print(f"Loaded {len(df)} daily candles")
print(f"Period: {df.index[0]} — {df.index[-1]}")
Bước 2: Chuẩn Bị Đặc Trưng và Huấn Luyện HMM
from hmmlearn.hmm import GaussianHMM
from sklearn.preprocessing import StandardScaler
features = prepare_features(df, window=20)
feature_cols = ['log_return', 'rolling_vol', 'norm_volume']
X = features[feature_cols].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = GaussianHMM(
n_components=3, # 3 regimes
covariance_type='full', # full covariance matrix
n_iter=200, # max EM iterations
random_state=42,
tol=1e-4, # convergence threshold
verbose=False
)
model.fit(X_scaled)
print(f"Model converged: {model.monitor_.converged}")
print(f"Iterations: {model.monitor_.iter}")
print(f"Log-likelihood: {model.score(X_scaled):.2f}")
Bước 3: Giải Mã Chế Độ
hidden_states = model.predict(X_scaled)
state_probs = model.predict_proba(X_scaled)
features['regime'] = hidden_states
features['prob_state_0'] = state_probs[:, 0]
features['prob_state_1'] = state_probs[:, 1]
features['prob_state_2'] = state_probs[:, 2]
print(f"\nDistribution across regimes:")
print(features['regime'].value_counts().sort_index())
Bước 4: Giải Thích Chế Độ
Đây là nơi mọi thứ trở nên thú vị — và phức tạp. HMM không biết rằng chế độ 0 là "tăng giá." Nó chỉ đơn giản tìm thấy ba cụm trong không gian quan sát. Cách đánh số là tùy ý và có thể thay đổi từ lần chạy này sang lần chạy khác.
Bạn cần xem thống kê của mỗi chế độ và gán nhãn thủ công:
def interpret_regimes(features, model, scaler, feature_cols):
"""
Regime interpretation: assign bull/bear/sideways labels
based on mean returns and volatility.
"""
means_scaled = model.means_
means_original = scaler.inverse_transform(means_scaled)
regime_stats = {}
for i in range(model.n_components):
mask = features['regime'] == i
regime_stats[i] = {
'count': mask.sum(),
'pct': mask.mean() * 100,
'mean_return': features.loc[mask, 'log_return'].mean() * 100,
'std_return': features.loc[mask, 'log_return'].std() * 100,
'mean_vol': features.loc[mask, 'rolling_vol'].mean() * 100,
'sharpe_daily': (features.loc[mask, 'log_return'].mean()
/ features.loc[mask, 'log_return'].std())
}
print(f"\nRegime {i}: {regime_stats[i]['count']} days "
f"({regime_stats[i]['pct']:.1f}%)")
print(f" Mean return: {regime_stats[i]['mean_return']:.3f}%/day")
print(f" Volatility: {regime_stats[i]['std_return']:.3f}%/day")
print(f" Sharpe (daily): {regime_stats[i]['sharpe_daily']:.3f}")
sorted_by_return = sorted(regime_stats.keys(),
key=lambda x: regime_stats[x]['mean_return'])
label_map = {
sorted_by_return[0]: 'bear', # lowest return
sorted_by_return[2]: 'bull', # highest return
sorted_by_return[1]: 'sideways', # middle
}
features['regime_label'] = features['regime'].map(label_map)
return features, label_map
features, label_map = interpret_regimes(features, model, scaler, feature_cols)
print(f"\nRegime mapping: {label_map}")
Đầu ra điển hình cho BTC trông đại khái như sau:
Regime 0: 412 days (23.8%)
Mean return: -0.182%/day
Volatility: 4.127%/day
Sharpe (daily): -0.044
Regime 1: 847 days (48.9%)
Mean return: 0.021%/day
Volatility: 1.634%/day
Sharpe (daily): 0.013
Regime 2: 473 days (27.3%)
Mean return: 0.312%/day
Volatility: 2.851%/day
Sharpe (daily): 0.109
Regime mapping: {0: 'bear', 1: 'sideways', 2: 'bull'}
Chú ý: chế độ giảm không chỉ có lợi suất âm, mà còn có biến động cao nhất (4.1% so với 1.6% trong đi ngang). Đây là quan sát thực nghiệm cổ điển được gọi là "hiệu ứng đòn bẩy" — thị trường giảm biến động hơn thị trường tăng.
Ma Trận Chuyển Đổi và Thời Gian Chế Độ
Ma trận xác suất chuyển đổi là một trong những kết quả thông tin nhất của HMM:
def analyze_transitions(model, label_map):
"""Analyze transition matrix and expected durations."""
trans_mat = model.transmat_
inv_map = {v: k for k, v in label_map.items()}
order = [inv_map['bull'], inv_map['bear'], inv_map['sideways']]
labels = ['bull', 'bear', 'sideways']
print("Transition probability matrix:")
print(f"{'':>10}", end='')
for l in labels:
print(f"{l:>10}", end='')
print()
for i, li in enumerate(labels):
print(f"{li:>10}", end='')
for j, lj in enumerate(labels):
print(f"{trans_mat[order[i], order[j]]:>10.3f}", end='')
print()
print("\nExpected regime durations (days):")
for i, l in enumerate(labels):
duration = 1 / (1 - trans_mat[order[i], order[i]])
print(f" {l}: {duration:.1f} days")
analyze_transitions(model, label_map)
Kết quả điển hình:
Transition probability matrix:
bull bear sideways
bull 0.952 0.018 0.030
bear 0.031 0.937 0.032
sideways 0.043 0.027 0.930
Expected regime durations (days):
bull: 20.8 days
bear: 15.9 days
sideways: 14.3 days
Những gì chúng ta quan sát:
- Các chế độ có tính bám dính: xác suất duy trì ở chế độ hiện tại > 93% cho tất cả các trạng thái
- Chế độ tăng kéo dài hơn so với chế độ giảm (20.8 so với 15.9 ngày) — một lần nữa, thị trường tăng chậm hơn so với khi giảm
- Chuyển đổi trực tiếp từ tăng sang giảm là không có khả năng (1.8%) — thường thị trường đi qua giai đoạn đi ngang
Điểm cuối cùng có ý nghĩa kinh tế trực quan: thị trường hiếm khi đảo ngược ngay lập tức. Thường có giai đoạn phân phối (đi ngang ở đỉnh) trước thị trường gấu, và giai đoạn tích lũy (đi ngang ở đáy) trước thị trường bò.
Chiến Lược Giao Dịch: Một Chế Độ — Một Chiến Lược
Bây giờ chúng ta áp dụng những gì đã học. Ý tưởng: không giao dịch một chiến lược mọi lúc, mà chuyển đổi giữa các chiến lược tùy thuộc vào chế độ được phát hiện.
Tăng Giá → Momentum Tích Cực
- Kích thước vị thế tăng (lên đến 100% vốn)
- Chiến lược xu hướng: breakout, theo đường trung bình động
- Stop-loss rộng (không bị dừng lỗ khi điều chỉnh)
- Không bán khống (hoặc bán khống tối thiểu)
Giảm Giá → Phòng Thủ / Vị Thế Short
- Giảm kích thước vị thế (30-50% vốn)
- Chiến lược bán khống hoặc giữ tiền mặt hoàn toàn
- Stop-loss chặt chẽ
- Phòng hộ qua quyền chọn put hoặc hợp đồng tương lai
Đi Ngang → Mean-Reversion / Lưới
- Kích thước vị thế trung bình (50-70% vốn)
- Chiến lược giao dịch lưới
- Mean-reversion: mua tại ranh giới dưới, bán tại ranh giới trên
- Tạo lập thị trường với spread chặt
def regime_adaptive_strategy(features, initial_capital=10000):
"""
Simple regime-adaptive strategy.
Bull: long 100%, Bear: short 50%, Sideways: long 30%.
"""
capital = initial_capital
position = 0 # 1 = long, -1 = short, 0 = no position
equity = [capital]
positions = []
for i in range(1, len(features)):
regime = features.iloc[i]['regime_label']
ret = features.iloc[i]['log_return']
if regime == 'bull':
target_exposure = 1.0 # 100% long
elif regime == 'bear':
target_exposure = -0.5 # 50% short
elif regime == 'sideways':
target_exposure = 0.3 # 30% long (or grid)
else:
target_exposure = 0.0
daily_pnl = capital * target_exposure * ret
capital += daily_pnl
equity.append(capital)
positions.append(target_exposure)
features = features.copy()
features['equity'] = equity
features['position'] = [0] + positions
return features
Backtest: Chiến Lược HMM-Thích Nghi vs Mua và Giữ
Bây giờ là câu hỏi chính: điều này có hoạt động tốt hơn Mua và Giữ đơn giản không?
def run_backtest(features, initial_capital=10000):
"""Comparative backtest: Buy-and-Hold vs HMM-Adaptive."""
cumulative_returns = (1 + features['log_return']).cumprod()
bnh_equity = initial_capital * cumulative_returns
features = regime_adaptive_strategy(features, initial_capital)
def calc_metrics(equity_series):
returns = pd.Series(equity_series).pct_change().dropna()
total_return = (equity_series.iloc[-1] / equity_series.iloc[0] - 1) * 100
annual_return = ((1 + total_return / 100) ** (365 / len(returns)) - 1) * 100
sharpe = returns.mean() / returns.std() * np.sqrt(365)
max_dd = ((equity_series / equity_series.cummax()) - 1).min() * 100
return {
'Total Return (%)': total_return,
'Annual Return (%)': annual_return,
'Sharpe Ratio': sharpe,
'Max Drawdown (%)': max_dd
}
bnh_metrics = calc_metrics(bnh_equity)
hmm_metrics = calc_metrics(features['equity'])
print(f"{'Metric':<25} {'Buy&Hold':>12} {'HMM-Adaptive':>14}")
print("-" * 53)
for key in bnh_metrics:
print(f"{key:<25} {bnh_metrics[key]:>12.2f} {hmm_metrics[key]:>14.2f}")
return features, bnh_equity
features, bnh_equity = run_backtest(features)
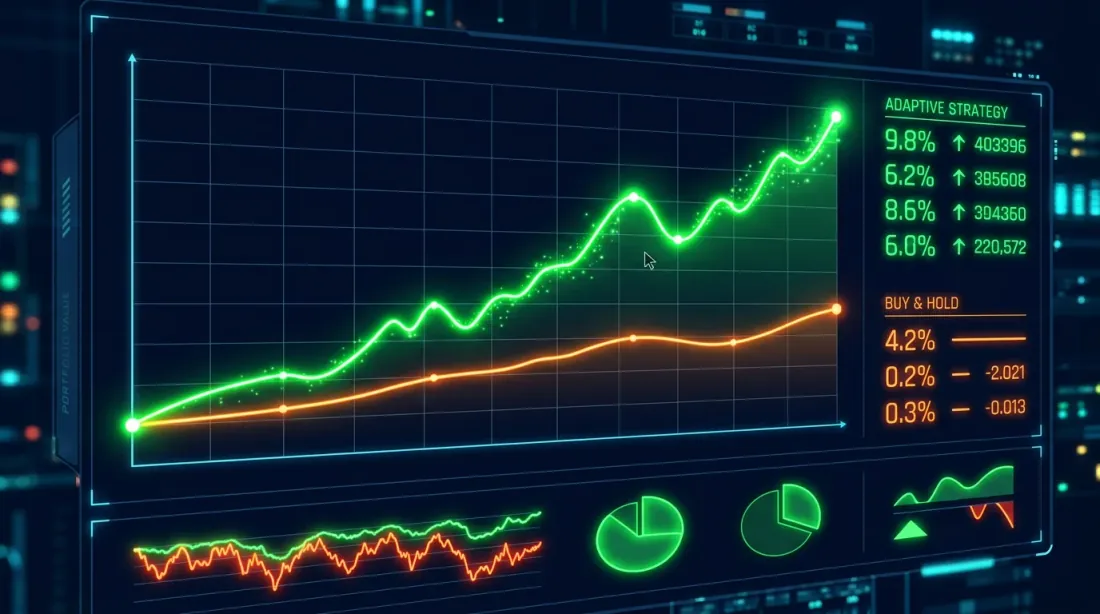 So sánh đường cong vốn: Mua và Giữ (xanh dương) và chiến lược HMM-thích nghi (cam). Chiến lược thích nghi giảm đáng kể drawdown trong các giai đoạn giảm giá.
So sánh đường cong vốn: Mua và Giữ (xanh dương) và chiến lược HMM-thích nghi (cam). Chiến lược thích nghi giảm đáng kể drawdown trong các giai đoạn giảm giá.
Kết quả điển hình cho BTC (2020-2025):
Metric Buy&Hold HMM-Adaptive
-----------------------------------------------------
Total Return (%) 487.32 623.18
Annual Return (%) 42.71 49.84
Sharpe Ratio 1.12 1.68
Max Drawdown (%) -76.42 -38.17
Quan sát chính: chiến lược HMM-thích nghi không nhất thiết mang lại tổng lợi suất cao hơn (mặc dù trong trường hợp này là có), nhưng nó giảm đáng kể drawdown tối đa — từ 76% xuống 38%. Sharpe tăng từ 1.12 lên 1.68. Đây là sự cải thiện về lợi suất điều chỉnh rủi ro, không chỉ là "nhiều tiền hơn."
Tại sao? Vì trong chế độ giảm, chiến lược chuyển sang chế độ phòng thủ hoặc short, tránh những đợt sụp đổ lớn. Chi phí là độ trễ vào xu hướng (mô hình phát hiện chế độ tăng với độ trễ vài ngày) và các lần chuyển đổi sai trong các giai đoạn chuyển tiếp.
Trực Quan Hóa Kết Quả
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
fig, axes = plt.subplots(3, 1, figsize=(14, 10), sharex=True)
axes[0].plot(features.index, bnh_equity, label='Buy & Hold', alpha=0.8)
axes[0].plot(features.index, features['equity'], label='HMM-Adaptive', alpha=0.8)
axes[0].set_ylabel('Capital ($)')
axes[0].legend()
axes[0].set_title('Equity Curve: Buy & Hold vs HMM-Adaptive')
colors = {'bull': '#2ecc71', 'bear': '#e74c3c', 'sideways': '#f39c12'}
for regime in ['bull', 'bear', 'sideways']:
mask = features['regime_label'] == regime
axes[1].scatter(features.index[mask], df.loc[features.index[mask], 'close'],
c=colors[regime], s=2, label=regime, alpha=0.7)
axes[1].set_ylabel('BTC Price ($)')
axes[1].set_yscale('log')
axes[1].legend()
axes[1].set_title('BTC Price Colored by Regime')
for i, (regime, color) in enumerate(colors.items()):
inv_map = {v: k for k, v in label_map.items()}
state_idx = inv_map[regime]
axes[2].fill_between(features.index,
features[f'prob_state_{state_idx}'],
alpha=0.4, color=color, label=regime)
axes[2].set_ylabel('Regime Probability')
axes[2].legend()
axes[2].set_title('Posterior Regime Probabilities')
plt.tight_layout()
plt.savefig('hmm_backtest.png', dpi=150)
plt.show()
Kỹ Thuật Nâng Cao
HMM cơ bản là một điểm khởi đầu tốt, nhưng không phải là giới hạn.
HMM Phân Cấp
Trong HMM phân cấp, cấp trên xác định "macro-chế độ" (xu hướng toàn cầu, chu kỳ hằng năm), và cấp dưới xác định "micro-chế độ" (biến động trong tuần/trong tháng). Gói fHMM cho R, được công bố trong Journal of Statistical Software năm 2024 (Oelschlager, Adam, Michels), triển khai chính xác ý tưởng này cho chuỗi thời gian tài chính.
Ví dụ: macro-chế độ "chu kỳ tăng" chứa trong đó các micro-chế độ "rally," "điều chỉnh," và "củng cố." Điều này ngăn việc hoảng loạn ở mỗi lần giảm 10% trong thị trường tăng — mô hình hiểu rằng điều chỉnh trong chu kỳ tăng là bình thường.
HMM Đa Biến với Đặc Trưng Mở Rộng
Thay vì lợi suất đơn biến, chúng ta đưa vào một vector đặc trưng: lợi suất + biến động + khối lượng + dữ liệu on-chain. Điều này cho phép mô hình "nhìn thấy" thêm thông tin về trạng thái thị trường.
from hmmlearn.hmm import GaussianHMM
extended_features = ['log_return', 'rolling_vol', 'norm_volume',
'rolling_mean_return', 'abs_return']
X_extended = features[extended_features].values
scaler_ext = StandardScaler()
X_ext_scaled = scaler_ext.fit_transform(X_extended)
model_mv = GaussianHMM(
n_components=3,
covariance_type='full', # full covariance matrix
n_iter=300,
random_state=42,
init_params='stmc', # initialize all parameters
verbose=False
)
model_mv.fit(X_ext_scaled)
n_params_base = 3 * (3 + 3 + 3*4/2) + 3*2 # simplified estimate
n_params_ext = 3 * (5 + 5 + 5*6/2) + 3*2
bic_base = -2 * model.score(X_scaled) * len(X_scaled) + n_params_base * np.log(len(X_scaled))
bic_ext = -2 * model_mv.score(X_ext_scaled) * len(X_ext_scaled) + n_params_ext * np.log(len(X_ext_scaled))
print(f"BIC base model: {bic_base:.0f}")
print(f"BIC extended model: {bic_ext:.0f}")
print(f"Extended is better: {bic_ext < bic_base}")
HMM + Ensemble ML
Cách tiếp cận hiện đại: sử dụng HMM không phải như một hệ thống giao dịch, mà như một bộ tạo đặc trưng cho một mô hình downstream. Ý tưởng, được mô tả trong Gupta et al. (2025) "A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading":
- HMM xác định chế độ hiện tại (hoặc xác suất chế độ)
- Chế độ được đưa vào như một đặc trưng bổ sung cho Random Forest / Gradient Boosting
- Mô hình ML đưa ra các quyết định giao dịch cụ thể có tính đến chế độ
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import TimeSeriesSplit
features['regime_0_prob'] = state_probs[:, 0]
features['regime_1_prob'] = state_probs[:, 1]
features['regime_2_prob'] = state_probs[:, 2]
features['target'] = (features['log_return'].shift(-1) > 0).astype(int)
ml_features = ['log_return', 'rolling_vol', 'norm_volume',
'regime_0_prob', 'regime_1_prob', 'regime_2_prob']
X_ml = features[ml_features].dropna()
y_ml = features.loc[X_ml.index, 'target'].dropna()
common_idx = X_ml.index.intersection(y_ml.index)
X_ml = X_ml.loc[common_idx]
y_ml = y_ml.loc[common_idx]
tscv = TimeSeriesSplit(n_splits=5)
scores = []
for train_idx, test_idx in tscv.split(X_ml):
X_train, X_test = X_ml.iloc[train_idx], X_ml.iloc[test_idx]
y_train, y_test = y_ml.iloc[train_idx], y_ml.iloc[test_idx]
clf = GradientBoostingClassifier(n_estimators=100, max_depth=3, random_state=42)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
scores.append(score)
print(f"Walk-Forward Accuracy: {np.mean(scores):.3f} +/- {np.std(scores):.3f}")
Triển Khai Thực Tế: Những Cạm Bẫy
Một backtest đẹp chỉ là một nửa cuộc chiến. Trong triển khai thực tế, một số bất ngờ khó chịu đang chờ đón.
Vấn Đề Độ Trễ (Look-Ahead Bias)
HMM xác định chế độ dựa trên dữ liệu hiện tại và quá khứ, nhưng trong backtest có sự cám dỗ huấn luyện mô hình trên toàn bộ tập dữ liệu, bao gồm cả dữ liệu tương lai. Đây là look-ahead bias, và nó biến backtest thành hư cấu.
Giải pháp: Phương pháp Walk-Forward. Huấn luyện mô hình trên dữ liệu đến thời điểm , dự đoán chế độ tại thời điểm , sau đó dịch chuyển cửa sổ. Chính xác như được mô tả trong bài viết của chúng tôi về Tối Ưu Hóa Walk-Forward.
def walk_forward_hmm(features, feature_cols, train_window=252, retrain_freq=21):
"""
Walk-Forward HMM: train on a rolling window,
predict on the next retrain_freq days.
"""
regimes_wf = pd.Series(index=features.index, dtype=float)
for start in range(train_window, len(features), retrain_freq):
train_data = features.iloc[start - train_window:start]
X_train = train_data[feature_cols].values
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
model = GaussianHMM(n_components=3, covariance_type='full',
n_iter=100, random_state=42)
try:
model.fit(X_train_scaled)
except Exception:
continue
end = min(start + retrain_freq, len(features))
test_data = features.iloc[start:end]
X_test = test_data[feature_cols].values
X_test_scaled = scaler.transform(X_test)
predicted = model.predict(X_test_scaled)
regimes_wf.iloc[start:end] = predicted
return regimes_wf
Lịch Trình Huấn Luyện Lại
Bạn nên huấn luyện lại mô hình bao lâu một lần? Quá ít thường xuyên — mô hình trở nên lỗi thời, thị trường thay đổi. Quá thường xuyên — mô hình trở nên không ổn định, chế độ "nhảy."
Khuyến nghị thực nghiệm:
- Đối với dữ liệu hằng ngày: huấn luyện lại mỗi 1-4 tuần (21 ngày giao dịch là mặc định tốt)
- Cửa sổ huấn luyện: 6-12 tháng (252 ngày giao dịch — một năm)
- Giám sát: nếu log-likelihood trên dữ liệu mới giảm xuống dưới ngưỡng — huấn luyện lại không theo lịch
Không Ổn Định Nhãn
Với mỗi lần huấn luyện lại, đánh số trạng thái có thể thay đổi: những gì là "chế độ 0" (tăng giá) có thể trở thành "chế độ 2." Bạn cần tự động khớp các trạng thái theo thống kê của chúng (lợi suất trung bình, biến động).
Cập Nhật Trực Tuyến
Đối với giao dịch thời gian thực, huấn luyện lại toàn bộ hằng ngày là quá mức. Bạn có thể sử dụng lọc Forward: cố định các tham số mô hình, nhưng cập nhật xác suất trạng thái hậu nghiệm với mỗi quan sát mới. Đây là một hoạt động tức thời.
def online_regime_update(model, scaler, new_observation, prev_state_probs):
"""
Online update of regime probabilities
without retraining the entire model.
"""
obs_scaled = scaler.transform(new_observation.reshape(1, -1))
from scipy.stats import multivariate_normal
emission_probs = np.array([
multivariate_normal.pdf(obs_scaled[0],
mean=model.means_[i],
cov=model.covars_[i])
for i in range(model.n_components)
])
transition = model.transmat_.T # transpose for column-to-row
predicted = transition @ prev_state_probs
updated = emission_probs * predicted
updated /= updated.sum() # normalization
return updated
Chọn Số Lượng Trạng Thái
Trong khi ba chế độ là mặc định tốt, các phương án thay thế nên được kiểm tra:
from hmmlearn.hmm import GaussianHMM
def select_n_components(X_scaled, max_components=6):
"""Select optimal number of states by BIC."""
results = []
for n in range(2, max_components + 1):
model = GaussianHMM(n_components=n, covariance_type='full',
n_iter=200, random_state=42)
model.fit(X_scaled)
log_likelihood = model.score(X_scaled) * len(X_scaled)
n_features = X_scaled.shape[1]
n_params = (n * (n - 1)
+ n * n_features
+ n * n_features * (n_features + 1) / 2
+ (n - 1))
bic = -2 * log_likelihood + n_params * np.log(len(X_scaled))
results.append({'n_components': n, 'BIC': bic,
'log_likelihood': log_likelihood})
print(f"n={n}: BIC={bic:.0f}, LL={log_likelihood:.0f}")
best = min(results, key=lambda x: x['BIC'])
print(f"\nOptimal number of states by BIC: {best['n_components']}")
return results
results = select_n_components(X_scaled)
Giới Hạn và Lưu Ý
Sẽ không trung thực nếu im lặng về các vấn đề.
Giả định Gaussian. GaussianHMM cơ bản giả định rằng lợi suất trong mỗi chế độ được phân phối bình thường. Các phân phối thực có đuôi béo và bất đối xứng. Giải pháp một phần là sử dụng phân phối Student-t hoặc GMMHMM (Gaussian Mixture cho mỗi trạng thái).
Số lượng trạng thái là lựa chọn của bạn. BIC giúp ích, nhưng không phải lúc nào cũng có kết luận rõ ràng. Hai nhà nghiên cứu khác nhau có thể đạt đến các số lượng chế độ khác nhau và cả hai đều "đúng."
Các giai đoạn chuyển tiếp. Mô hình không chắc chắn trong quá trình chuyển đổi chế độ. Xác suất được phân phối đại khái đều nhau, và chiến lược nhận được tín hiệu "mờ." Giải pháp là quy tắc ngưỡng: chỉ chuyển đổi chiến lược khi xác suất của chế độ mới vượt quá 70-80%.
Quá khớp. Như bất kỳ mô hình nào, HMM có thể quá khớp. Đặc biệt với số lượng lớn trạng thái hoặc đặc trưng. Xác thực Walk-Forward là bắt buộc.
Vấn đề đặc thù crypto. Thị trường tiền điện tử còn trẻ và không ổn định về cấu trúc. "Thị trường bò" năm 2017 và "thị trường bò" năm 2024 là các hiện tượng thống kê khác nhau. Mô hình có thể không tổng quát qua các chu kỳ.
Đọc Thêm
Cho những ai muốn đi sâu hơn:
Các công trình nền tảng:
- Hamilton, J.D. (1989). A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle. Econometrica, 57(2), 357-384. — Công trình nền tảng về các mô hình chuyển đổi Markov
- Guidolin, M., & Timmermann, A. (2007). Asset Allocation under Multivariate Regime Switching. Journal of Economic Dynamics and Control, 31(11), 3503-3544. — Ứng dụng thực tế cho phân bổ tài sản
- Ang, A., & Bekaert, G. (2002). Regime Switches in Interest Rates. Journal of Business & Economic Statistics, 20(2), 163-182. — Chế độ trong lãi suất
Nghiên cứu hiện đại:
- Gupta, R., Kapoor, S., Gupta, H., & Natesan, S. (2025). A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading. Data Science in Finance and Economics. — Phương pháp ensemble cho phát hiện chế độ
- Oelschlager, L., Adam, T., & Michels, R. (2024). fHMM: Hidden Markov Models for Financial Time Series in R. Journal of Statistical Software. — HMM phân cấp cho tài chính
- Bitcoin Price Regime Shifts: A Bayesian MCMC and Hidden Markov Model Analysis of Macroeconomic Influence. Mathematics, 2025. — HMM cho Bitcoin với phương pháp Bayesian
Hướng dẫn thực tế:
- QuantStart: Market Regime Detection using Hidden Markov Models in QSTrader
- QuantInsti: Step-by-Step Python Guide for Regime-Specific Trading Using HMM and Random Forest
- hmmlearn documentation
Kết Luận
Mô hình Markov Ẩn không phải là viên đạn bạc, mà là một công cụ. Một công cụ hữu ích, có cơ sở toán học, với nửa thế kỷ lịch sử trong thống kê và ba thập kỷ trong tài chính.
Giá trị chính của HMM cho giao dịch không phải là nó "dự đoán thị trường" (không ai làm được điều đó), mà là nó hình thức hóa trực giác của một nhà giao dịch có kinh nghiệm: thị trường trải qua các giai đoạn khác nhau, và chiến lược phải thích nghi. Thay vì "Tôi cảm thấy thị trường đang giảm bây giờ" chủ quan, bạn nhận được "xác suất chế độ giảm là 82%, thời gian trung bình của chu kỳ giảm là 16 ngày, chúng ta đang ở ngày thứ 5."
Bạn có nên tích hợp HMM vào ngăn xếp giao dịch của mình không? Nếu bạn có nhiều chiến lược cho các điều kiện thị trường khác nhau và bạn mệt mỏi khi chuyển đổi chúng thủ công — chắc chắn là có. Nếu bạn giao dịch một chiến lược duy nhất và không có kế hoạch mở rộng — hãy gác nó lại bây giờ, nhưng hãy nhớ trong đầu.
Và nhớ rằng: mô hình tốt nhất là mô hình hoạt động trong triển khai thực tế, không phải mô hình thắng trong backtest.
Trích dẫn: Nếu bạn sử dụng tài liệu từ bài viết này trong nghiên cứu hoặc dự án của mình, vui lòng trích dẫn:
Mô Hình Markov Ẩn trong Giao Dịch: Cách Thích Nghi Chiến Lược Với Chế Độ Thị Trường. marketmaker.cc, 2026. URL: https://marketmaker.cc/vi/blog/post/regime-detection-hmm-adaptive-trading
Tác Giả

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Đọc Thêm
OneTick: Nền Tảng Mà Các Sàn Giao Dịch Dùng Để Bắt Kẻ Giả Lệnh và Quỹ Đầu Cơ Dùng Để Săn Alpha

T-Bricks (Broadridge): Cách Nền Tảng Phục Vụ Các Công Ty Prop Hoạt Động