Cache Parquet Teragregat: Cara Mempercepatkan Backtest Pelbagai Jangka Masa Ratusan Kali

Strategi pelbagai jangka masa menggunakan beberapa jangka masa serentak: jangka masa harian menentukan arah aliran, jangka masa sejam mengenal pasti titik masuk, dan jangka masa 5 minit menentukan masa pelaksanaan dengan tepat. Setiap jangka masa memerlukan penunjuknya sendiri: purata bergerak, pengayun, aras.
Untuk satu backtest tunggal, semuanya mudah — kira semula jangka masa daripada data minit, kira penunjuk, jalankan strategi. Tetapi semasa pengoptimuman besar-besaran — apabila anda perlu menguji ribuan kombinasi parameter — mengira semula jangka masa dan penunjuk pada setiap ulangan menjadi kesesakan. Satu laluan melalui data minit selama dua tahun bermakna memproses lebih daripada satu juta bar, dan mengulanginya seribu kali adalah pembaziran.
Penyelesaiannya: kira awal semua perkara sekali dan cache dalam fail parquet.
Masalah: Pengiraan Berlebihan Semasa Pengoptimuman
Saluran paip backtest pelbagai jangka masa yang tipikal kelihatan seperti ini:
for params in parameter_grid:
df_1m = load_candles("ETHUSDT", "1m", start, end)
df_5m = resample_ohlcv(df_1m, "5m")
df_1h = resample_ohlcv(df_1m, "1h")
df_4h = resample_ohlcv(df_1m, "4h")
df_1d = resample_ohlcv(df_1m, "D")
ma_1h = compute_ma(df_1h["close"], length=params["ma_1h_len"])
ma_4h = compute_ma(df_4h["close"], length=params["ma_4h_len"])
ma_1d = compute_ma(df_1d["close"], length=params["ma_1d_len"])
result = run_strategy(df_1m, ma_1h, ma_4h, ma_1d, params)
Pada setiap ulangan, langkah 1-3 dikira semula walaupun datanya sama. Hanya parameter ambang strategi yang berubah (langkah 4). Ia seperti membina semula seluruh rumah setiap kali anda hanya ingin mencuba warna dinding yang berbeza.
Idea: Kira Sekali, Simpan, Guna Semula Berkali-kali
Pemerhatian utama: jangka masa dan penunjuk hanya bergantung pada data minit dan parameter penunjuk, bukan pada parameter strategi. Jika kita menetapkan set penunjuk yang diperlukan, kita boleh mengiranya sekali dan menyimpannya.
Skemanya:
Langkah 1 (sekali):
Lilin minit -> Pensampelan semula jangka masa -> Pengiraan penunjuk -> Fail parquet
Langkah 2 (berkali-kali):
Fail parquet -> Strategi dengan parameter berbeza -> Keputusan
Mensimulasikan Jangka Masa daripada Lilin Minit
Kita mempunyai arkib lengkap lilin minit. Daripadanya, kita boleh menghasilkan semula mana-mana jangka masa yang lebih tinggi dengan tepat. Tetapi ada nuansa: dengan resample standard, kita mendapat satu baris setiap tempoh (satu baris sejam, satu setiap 4 jam, dan sebagainya). Ini tidak berfungsi untuk backtest minit demi minit — kita perlu mengetahui nilai penunjuk pada setiap minit.
Oleh itu, kita mensimulasikan nilai jangka masa yang lebih tinggi untuk setiap lilin minit, memodelkan cara bot melihat data dalam masa nyata:
- Bot menerima lilin minit seterusnya
- Mengemas kini bar semasa (yang belum ditutup) bagi jangka masa yang lebih tinggi — mengira semula High, Low, Close, Volume
- Mengira semula penunjuk merentas semua bar tertutup ditambah bar separa semasa
- Apabila tempoh tamat — bar dimuktamadkan dan yang baharu bermula
Pendekatan ini menjamin bahawa backtest melihat data yang sama seperti bot dalam masa nyata. Tiada melihat ke masa hadapan — setiap lilin minit diproses secara ketat dengan data yang tersedia pada saat itu.
class RunningCandleBuffer:
"""
Emulates real-time updates of a higher timeframe bar
using 1-minute candles.
"""
def __init__(self, period_seconds: int):
self.period = period_seconds # 86400 for Daily, 3600 for 1h
self.closed_bars = []
self.current_bar = None
def update(self, timestamp, open_, high, low, close, volume):
bar_start = self._align_to_period(timestamp)
if self.current_bar is None or bar_start != self.current_bar['start']:
if self.current_bar is not None:
self.closed_bars.append(self.current_bar)
self.current_bar = {
'start': bar_start,
'open': open_, 'high': high,
'low': low, 'close': close,
'volume': volume,
}
else:
self.current_bar['high'] = max(self.current_bar['high'], high)
self.current_bar['low'] = min(self.current_bar['low'], low)
self.current_bar['close'] = close
self.current_bar['volume'] += volume
return self.closed_bars + [self.current_bar]
RunningCandleBuffer yang berasingan dicipta untuk setiap jangka masa yang lebih tinggi. Pada setiap lilin minit, semua penimbal dikemas kini, memberikan kita keadaan semasa setiap jangka masa — seolah-olah bot sedang berjalan dalam masa nyata.
Struktur Cache Parquet
Hasil pra-pengiraan ialah satu fail parquet di mana setiap baris sepadan dengan satu lilin minit, dan lajur mengandungi:
timestamp — cap masa lilin minit
open, high, low, — OHLCV lilin minit
close, volume
close_5m — Close lilin 5m yang disimulasikan pada saat ini
close_1h — Close lilin 1h yang disimulasikan
close_4h — Close lilin 4h yang disimulasikan
close_1d — Close lilin harian yang disimulasikan
ma_20_1h — MA(20) pada 1h, dikira semula pada minit ini
ma_50_1h — MA(50) pada 1h
ma_20_4h — MA(20) pada 4h
ma_50_4h — MA(50) pada 4h
ma_6_1d — MA(6) pada Harian
ma_12_1d — MA(12) pada Harian
cross_ma_1h — Isyarat persilangan MA pada 1h ('buy'/'sell'/None)
cross_ma_4h — Isyarat persilangan MA pada 4h
cross_ma_1d — Isyarat persilangan MA pada Harian
separation_1h — Perbezaan MA dalam % pada 1h
separation_4h — Perbezaan MA dalam % pada 4h
separation_1d — Perbezaan MA dalam % pada Harian
Setiap nilai mencerminkan keadaan penunjuk yang sebenar pada saat lilin minit yang berkaitan — dengan mengambil kira bar yang belum ditutup bagi jangka masa yang lebih tinggi.
Pra-pengiraan: Membina Cache
def precompute_cache(
df_1m: pd.DataFrame,
timeframes: dict[str, int], # {"5m": 300, "1h": 3600, "4h": 14400, "D": 86400}
indicators: dict, # {"ma_20": 20, "ma_50": 50}
) -> pd.DataFrame:
"""
Single pass through all minute candles.
Returns a DataFrame with emulated timeframes and indicators.
"""
buffers = {tf: RunningCandleBuffer(secs) for tf, secs in timeframes.items()}
n = len(df_1m)
result = {}
for tf_name, buf in buffers.items():
closes = np.zeros(n)
ma_values = {name: np.full(n, np.nan) for name in indicators}
for i in range(n):
row = df_1m.iloc[i]
bars = buf.update(
df_1m.index[i],
row['open'], row['high'], row['low'], row['close'], row['volume']
)
all_closes = [b['close'] for b in bars]
closes[i] = all_closes[-1]
for ind_name, length in indicators.items():
if len(all_closes) >= length:
ma_values[ind_name][i] = np.mean(all_closes[-length:])
result[f'close_{tf_name}'] = closes
for ind_name in indicators:
result[f'{ind_name}_{tf_name}'] = ma_values[ind_name]
cache_df = pd.DataFrame(result, index=df_1m.index)
cache_df = pd.concat([df_1m[['open', 'high', 'low', 'close', 'volume']], cache_df], axis=1)
return cache_df
cache = precompute_cache(
df_1m,
timeframes={"5m": 300, "1h": 3600, "4h": 14400, "D": 86400},
indicators={"ma_20": 20, "ma_50": 50, "ma_6": 6, "ma_12": 12},
)
cache.to_parquet("cache_ETHUSDT_2024_2026.parquet")
Menggunakan Cache Semasa Pengoptimuman
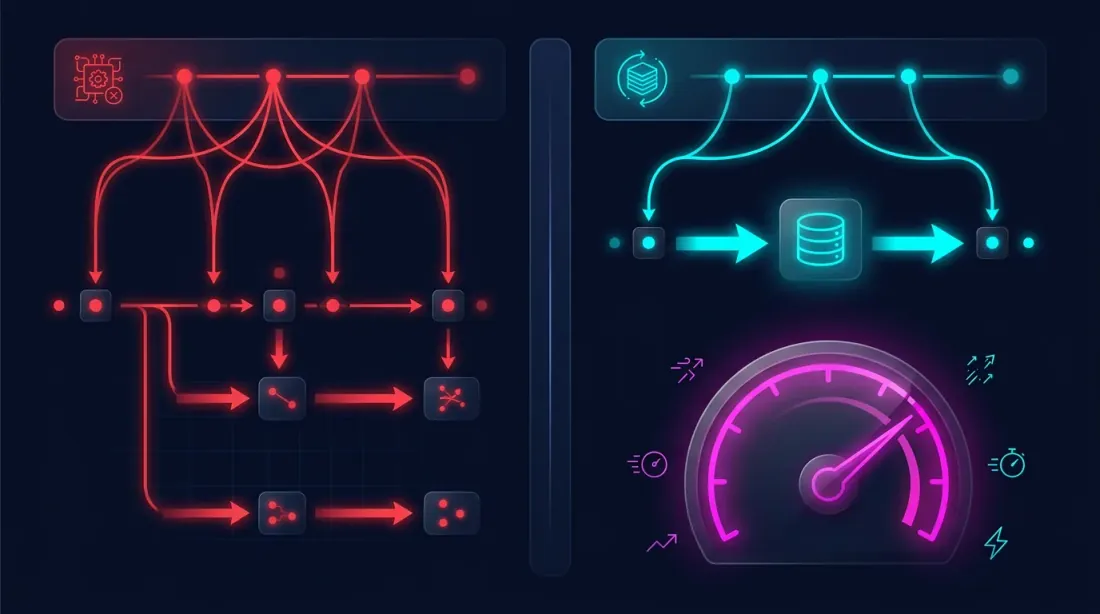
Kini pengoptimuman kelihatan seperti ini:
cache = pd.read_parquet("cache_ETHUSDT_2024_2026.parquet")
for params in parameter_grid:
result = run_strategy(cache, params)
Strategi berfungsi dengan lajur yang telah dibina — tiada laluan berulang melalui satu juta bar, tiada pengiraan semula MA, tiada emulasi jangka masa. Hanya membaca daripada DataFrame dan menyemak syarat masuk/keluar.
Mengapa Parquet
Parquet ialah format penyimpanan data berbentuk lajur, optimum untuk tugas ini:
- Pemampatan. Parquet memampatkan data berangka 5-10x. Cache dengan 1.1 juta baris dan 30 lajur mengambil ~50 MB berbanding ~500 MB dalam CSV.
- Pembacaan berbentuk lajur. Jika strategi hanya menggunakan
ma_20_4hdanma_50_4h, parquet hanya membaca lajur tersebut, melangkau yang lain. - Pemeliharaan jenis. Jenis data (float64, int64, string) dipelihara tanpa kehilangan — tidak perlu menghurai rentetan semasa pemuatan.
- Kelajuan baca. Memuatkan parquet ke dalam pandas mengambil masa puluhan milisaat, lebih cepat daripada CSV dalam susunan magnitud.
Meluaskan Cache: Menambah Penunjuk Baharu
Jika strategi memerlukan penunjuk baharu (RSI, MACD, Bollinger Bands), cukup:
- Kira semula hanya penunjuk baharu daripada data minit yang sama
- Tambah lajur ke fail parquet yang sedia ada
- Semua lajur yang telah dikira sebelum ini kekal tidak diubah
cache = pd.read_parquet("cache_ETHUSDT_2024_2026.parquet")
rsi_cols = compute_rsi_for_timeframes(df_1m, timeframes, length=14)
cache = pd.concat([cache, rsi_cols], axis=1)
cache.to_parquet("cache_ETHUSDT_2024_2026.parquet")
Ringkasan: Perbandingan Pendekatan
| Pendekatan Naif | Cache Teragregat | |
|---|---|---|
| Pensampelan semula jangka masa | Setiap ulangan | Sekali |
| Pengiraan penunjuk | Setiap ulangan | Sekali |
| Masa setiap ulangan | Minit | Kurang daripada sesaat |
| 1000 ulangan | Hari | Minit |
| Penggunaan memori | Muatkan 1m + kira semula | DataFrame tunggal |
| Pariti backtest-langsung | Bergantung pada pelaksanaan | Dijamin (emulasi = masa nyata) |
Kesimpulan
Pendekatan cache parquet teragregat menyelesaikan dua masalah serentak:
-
Ketepatan. Emulasi jangka masa daripada lilin minit melalui RunningCandleBuffer menjamin bahawa backtest melihat data yang sama seperti bot dalam masa nyata — tiada melihat ke masa hadapan dan tiada kelewatan buatan.
-
Kelajuan. Jangka masa dan penunjuk yang telah dikira awal membolehkan pengujian ribuan kombinasi parameter dalam minit berbanding hari.
Ideanya mudah: kira sekali — guna semula berkali-kali. Lilin minit adalah data sumber. Semua yang lain adalah terbitan dan boleh dikira awal serta dicache. Parquet menjadikan cache ini padat, pantas, dan mudah digunakan.
Untuk maklumat lanjut tentang cara meningkatkan ketepatan simulasi pengisian dengan drill-down adaptif daripada minit ke saat dan milisaat, lihat artikel Drill-down adaptif: backtest dengan granulariti berubah-ubah.
Pautan Berguna
- Apache Parquet — format penyimpanan data
- pandas — bekerja dengan parquet
- Lopez de Prado — Advances in Financial Machine Learning
- Ernest Chan — Quantitative Trading
Petikan
@article{soloviov2026parquetcache,
author = {Soloviov, Eugen},
title = {Aggregated Parquet Cache: How to Speed Up Multi-Timeframe Backtests by Hundreds of Times},
year = {2026},
url = {https://marketmaker.cc/ms/blog/post/parquet-cache-multitimeframe-backtest},
description = {Cara mengira awal jangka masa dan penunjuk daripada lilin minit, menyimpannya ke parquet, dan menggunakannya untuk ujian strategi besar-besaran tanpa pengiraan semula yang berlebihan.}
}
Pengarang

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Baca Lagi

Adaptive Drill-Down: Backtest dengan Granulariti Pemboleh ubah dari Minit hingga Dagangan Mentah

Walk-Forward Optimization: Satu-Satunya Ujian Strategi yang Jujur
