Toplu Parquet Önbelleği: Çoklu Zaman Dilimi Backtestlerini Yüzlerce Kat Nasıl Hızlandırırsınız

Çoklu zaman dilimi stratejisi birkaç zaman dilimini eş zamanlı kullanır: günlük trend yönünü belirler, saatlik giriş noktalarını tanımlar ve 5 dakikalık uygulama zamanlamasını saptar. Her zaman dilimi kendi göstergelerini gerektirir: hareketli ortalamalar, osilatörler, seviyeler.
Tek bir backtest için her şey basittir — dakikalık verilerden zaman dilimlerini yeniden hesaplayın, göstergeleri hesaplayın, stratejiyi çalıştırın. Ancak toplu optimizasyon sırasında — binlerce parametre kombinasyonunu test etmeniz gerektiğinde — her iterasyonda zaman dilimlerini ve göstergeleri yeniden hesaplamak bir darboğaz haline gelir. İki yıllık dakikalık veriler üzerindeki tek bir geçiş, bir milyondan fazla çubuğun işlenmesi anlamına gelir ve bunu bin kez tekrarlamak israftır.
Çözüm: her şeyi bir kez önceden hesaplayıp parquet dosyasında önbelleğe almak.
Sorun: Optimizasyon Sırasında Gereksiz Hesaplamalar
Tipik bir çoklu zaman dilimi backtest süreci şöyle görünür:
for params in parameter_grid:
df_1m = load_candles("ETHUSDT", "1m", start, end)
df_5m = resample_ohlcv(df_1m, "5m")
df_1h = resample_ohlcv(df_1m, "1h")
df_4h = resample_ohlcv(df_1m, "4h")
df_1d = resample_ohlcv(df_1m, "D")
ma_1h = compute_ma(df_1h["close"], length=params["ma_1h_len"])
ma_4h = compute_ma(df_4h["close"], length=params["ma_4h_len"])
ma_1d = compute_ma(df_1d["close"], length=params["ma_1d_len"])
result = run_strategy(df_1m, ma_1h, ma_4h, ma_1d, params)
Her iterasyonda 1-3. adımlar yeniden hesaplanır, oysa veriler aynıdır. Yalnızca strateji eşik parametreleri (4. adım) değişir. Bu, sadece farklı bir duvar rengi denemek istediğinizde her seferinde tüm evi yeniden inşa etmeye benzer.
Fikir: Bir Kez Hesapla, Kaydet, Defalarca Kullan
Temel gözlem: zaman dilimleri ve göstergeler yalnızca dakikalık verilere ve gösterge parametrelerine bağlıdır, strateji parametrelerine değil. Gerekli göstergeler kümesini sabitlersek, onları bir kez hesaplayıp kaydedebiliriz.
Şema:
Adım 1 (bir kez):
Dakikalık mumlar -> Zaman dilimi yeniden örnekleme -> Gösterge hesaplama -> Parquet dosyası
Adım 2 (defalarca):
Parquet dosyası -> Farklı parametrelerle strateji -> Sonuç
Dakikalık Mumlardan Zaman Dilimi Emülasyonu
Eksiksiz bir dakikalık mum arşivimiz var. Bundan herhangi bir daha yüksek zaman dilimini doğru şekilde yeniden üretebiliriz. Ancak bir nüans var: standart resample ile dönem başına bir satır elde ederiz (saatte bir satır, 4 saatte bir vb.). Bu, dakika dakika backtesting için işe yaramaz — her dakikada gösterge değerini bilmemiz gerekir.
Bu nedenle, botun gerçek zamanlı olarak verileri nasıl gördüğünü modelleyerek her dakikalık mum için daha yüksek zaman dilimi değerlerini emüle ederiz:
- Bot bir sonraki dakikalık mumu alır
- Daha yüksek zaman diliminin mevcut (kapanmamış) çubuğunu günceller — High, Low, Close, Volume'u yeniden hesaplar
- Tüm kapalı çubuklar artı mevcut kısmi çubuk üzerinden göstergeyi yeniden hesaplar
- Dönem sona erdiğinde — çubuk sonlandırılır ve yeni biri başlar
Bu yaklaşım, backtestin botun gerçek zamanlı olarak gördüğü verilerle birebir aynı verileri görmesini garanti eder. Geleceğe bakmak yok — her dakikalık mum, o anda mevcut olacak verilerle sıkı bir şekilde işlenir.
class RunningCandleBuffer:
"""
1 dakikalık mumları kullanarak daha yüksek zaman dilimi
çubuğunun gerçek zamanlı güncellemelerini emüle eder.
"""
def __init__(self, period_seconds: int):
self.period = period_seconds # Günlük için 86400, 1h için 3600
self.closed_bars = []
self.current_bar = None
def update(self, timestamp, open_, high, low, close, volume):
bar_start = self._align_to_period(timestamp)
if self.current_bar is None or bar_start != self.current_bar['start']:
if self.current_bar is not None:
self.closed_bars.append(self.current_bar)
self.current_bar = {
'start': bar_start,
'open': open_, 'high': high,
'low': low, 'close': close,
'volume': volume,
}
else:
self.current_bar['high'] = max(self.current_bar['high'], high)
self.current_bar['low'] = min(self.current_bar['low'], low)
self.current_bar['close'] = close
self.current_bar['volume'] += volume
return self.closed_bars + [self.current_bar]
Her daha yüksek zaman dilimi için ayrı bir RunningCandleBuffer oluşturulur. Her dakikalık mumda tüm tamponlar güncellenir ve bize her zaman diliminin mevcut durumunu verir — sanki bot gerçek zamanlı çalışıyormuş gibi.
Parquet Önbellek Yapısı
Ön hesaplamanın sonucu, her satırın bir dakikalık muma karşılık geldiği ve sütunların şunları içerdiği tek bir parquet dosyasıdır:
timestamp — dakikalık mum zaman damgası
open, high, low, — dakikalık mum OHLCV
close, volume
close_5m — bu andaki emüle edilmiş 5 dakikalık mumun Close değeri
close_1h — emüle edilmiş 1 saatlik mumun Close değeri
close_4h — emüle edilmiş 4 saatlik mumun Close değeri
close_1d — emüle edilmiş günlük mumun Close değeri
ma_20_1h — 1 saatlikte MA(20), bu dakikada yeniden hesaplanmış
ma_50_1h — 1 saatlikte MA(50)
ma_20_4h — 4 saatlikte MA(20)
ma_50_4h — 4 saatlikte MA(50)
ma_6_1d — Günlükte MA(6)
ma_12_1d — Günlükte MA(12)
cross_ma_1h — 1 saatlikte MA kesişim sinyali ('buy'/'sell'/None)
cross_ma_4h — 4 saatlikte MA kesişim sinyali
cross_ma_1d — Günlükte MA kesişim sinyali
separation_1h — 1 saatlikte % cinsinden MA sapması
separation_4h — 4 saatlikte % cinsinden MA sapması
separation_1d — Günlükte % cinsinden MA sapması
Her değer, ilgili dakikalık mumun anındaki göstergenin gerçek durumunu yansıtır — daha yüksek zaman dilimlerinin kapanmamış çubukları dahil.
Ön Hesaplama: Önbelleği Oluşturma
def precompute_cache(
df_1m: pd.DataFrame,
timeframes: dict[str, int], # {"5m": 300, "1h": 3600, "4h": 14400, "D": 86400}
indicators: dict, # {"ma_20": 20, "ma_50": 50}
) -> pd.DataFrame:
"""
Tüm dakikalık mumlar üzerinde tek geçiş.
Emüle edilmiş zaman dilimleri ve göstergelerle bir DataFrame döndürür.
"""
buffers = {tf: RunningCandleBuffer(secs) for tf, secs in timeframes.items()}
n = len(df_1m)
result = {}
for tf_name, buf in buffers.items():
closes = np.zeros(n)
ma_values = {name: np.full(n, np.nan) for name in indicators}
for i in range(n):
row = df_1m.iloc[i]
bars = buf.update(
df_1m.index[i],
row['open'], row['high'], row['low'], row['close'], row['volume']
)
all_closes = [b['close'] for b in bars]
closes[i] = all_closes[-1]
for ind_name, length in indicators.items():
if len(all_closes) >= length:
ma_values[ind_name][i] = np.mean(all_closes[-length:])
result[f'close_{tf_name}'] = closes
for ind_name in indicators:
result[f'{ind_name}_{tf_name}'] = ma_values[ind_name]
cache_df = pd.DataFrame(result, index=df_1m.index)
cache_df = pd.concat([df_1m[['open', 'high', 'low', 'close', 'volume']], cache_df], axis=1)
return cache_df
cache = precompute_cache(
df_1m,
timeframes={"5m": 300, "1h": 3600, "4h": 14400, "D": 86400},
indicators={"ma_20": 20, "ma_50": 50, "ma_6": 6, "ma_12": 12},
)
cache.to_parquet("cache_ETHUSDT_2024_2026.parquet")
Optimizasyon Sırasında Önbelleği Kullanma
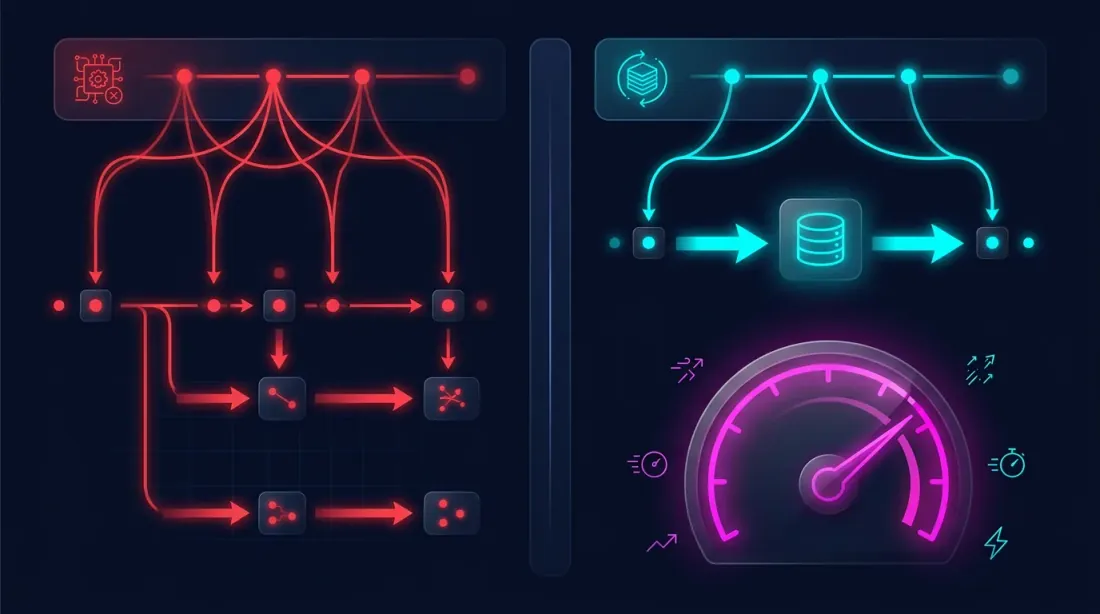
Artık optimizasyon şöyle görünür:
cache = pd.read_parquet("cache_ETHUSDT_2024_2026.parquet")
for params in parameter_grid:
result = run_strategy(cache, params)
Strateji, önceden oluşturulmuş sütunlarla çalışır — bir milyon çubar üzerinde tekrar tekrar geçiş yok, MA yeniden hesaplama yok, zaman dilimi emülasyonu yok. Sadece bir DataFrame'den okuma ve giriş/çıkış koşullarını kontrol etme.
Neden Parquet
Parquet, bu görev için optimal bir sütunsal veri depolama formatıdır:
- Sıkıştırma. Parquet sayısal verileri 5-10 kat sıkıştırır. 30 sütunlu 1,1 milyon satırlık bir önbellek, CSV'deki ~500 MB yerine ~50 MB kaplar.
- Sütunsal okuma. Strateji yalnızca
ma_20_4hvema_50_4hkullanıyorsa, parquet yalnızca o sütunları okur, geri kalanını atlar. - Tür koruması. Veri türleri (float64, int64, string) kayıpsız korunur — yüklemede dizeleri ayrıştırmaya gerek yoktur.
- Okuma hızı. Parquet'i pandas'a yüklemek onlarca milisaniye sürer, CSV'den bir büyüklük sırası daha hızlıdır.
Önbelleği Genişletme: Yeni Göstergeler Ekleme
Strateji yeni bir gösterge gerektiriyorsa (RSI, MACD, Bollinger Bantları), sadece şunları yapmanız yeterlidir:
- Yalnızca yeni göstergeyi aynı dakikalık verilerden yeniden hesaplayın
- Sütunları mevcut parquet dosyasına ekleyin
- Daha önce hesaplanmış tüm sütunlar dokunulmadan kalır
cache = pd.read_parquet("cache_ETHUSDT_2024_2026.parquet")
rsi_cols = compute_rsi_for_timeframes(df_1m, timeframes, length=14)
cache = pd.concat([cache, rsi_cols], axis=1)
cache.to_parquet("cache_ETHUSDT_2024_2026.parquet")
Özet: Yaklaşım Karşılaştırması
| Naif Yaklaşım | Toplu Önbellek | |
|---|---|---|
| Zaman dilimi yeniden örnekleme | Her iterasyonda | Bir kez |
| Gösterge hesaplama | Her iterasyonda | Bir kez |
| İterasyon başına süre | Dakikalar | Bir saniyeden az |
| 1000 iterasyon | Günler | Dakikalar |
| Bellek tüketimi | 1m yükle + yeniden hesapla | Tek DataFrame |
| Backtest-canlı uyumu | Uygulamaya bağlı | Garantili (emülasyon = gerçek zamanlı) |
Sonuç
Toplu parquet önbelleği yaklaşımı iki sorunu aynı anda çözer:
-
Doğruluk. RunningCandleBuffer aracılığıyla dakikalık mumlardan zaman dilimi emülasyonu, backtestin gerçek zamanlı olarak botun gördüğü verilerle aynı verileri gördüğünü garanti eder — geleceğe bakmak yok ve yapay gecikmeler yok.
-
Hız. Önceden hesaplanmış zaman dilimleri ve göstergeler, günler yerine dakikalar içinde binlerce parametre kombinasyonunun test edilmesine olanak tanır.
Fikir basittir: bir kez hesapla — defalarca kullan. Dakikalık mumlar kaynak veridir. Diğer her şey türevdir ve önceden hesaplanıp önbelleğe alınabilir. Parquet bu önbelleği kompakt, hızlı ve kullanışlı kılar.
Dakikalardan saniyelere ve milisaniyelere adaptif detaylandırma ile dolum simülasyonu doğruluğunu nasıl artıracağınız hakkında daha fazla bilgi için Adaptif detaylandırma: değişken granülariteli backtest makalesine bakın.
Faydalı Bağlantılar
- Apache Parquet — veri depolama formatı
- pandas — parquet ile çalışma
- Lopez de Prado — Finansal Makine Öğrenmesinde Gelişmeler
- Ernest Chan — Nicel Ticaret
Atıf
@article{soloviov2026parquetcache,
author = {Soloviov, Eugen},
title = {Aggregated Parquet Cache: How to Speed Up Multi-Timeframe Backtests by Hundreds of Times},
year = {2026},
url = {https://marketmaker.cc/tr/blog/post/parquet-cache-multitimeframe-backtest},
description = {Dakikalık mumlardan zaman dilimlerini ve göstergeleri önceden hesaplama, parquet'e kaydetme ve gereksiz yeniden hesaplamalar olmadan toplu strateji testi için kullanma yöntemi.}
}
Yazarlar

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Daha Fazla Oku

Uyarlanabilir Drill-Down: Dakikadan Ham İşlemlere Değişken Granülerlikle Backtest

Walk-Forward Optimizasyonu: Tek Dürüst Strateji Testi
