Chiến Lược Cascade: Ưu Tiên Thực Thi với Lấp Đầy Dự Phòng

Phần kết của loạt bài "Backtest Không Ảo Tưởng". Cách xây dựng bộ điều phối từ N chiến lược trên M cặp, triển khai chế độ cascade với ưu tiên và thực thi dự phòng, chọn dual_size, và tại sao danh mục chiến lược không thể được kiểm tra bằng cách đơn giản cộng tổng PnL.
Tại Sao Bạn Cần Một Danh Mục Chiến Lược
 Nhiều chiến lược cạnh tranh cho vốn hạn chế — hầu hết ngồi không trong khi chỉ một vài chiến lược giao dịch tại bất kỳ thời điểm nào
Nhiều chiến lược cạnh tranh cho vốn hạn chế — hầu hết ngồi không trong khi chỉ một vài chiến lược giao dịch tại bất kỳ thời điểm nào
Bạn đã đưa một chiến lược qua toàn bộ pipeline. Monte Carlo bootstrap cho thấy bách phân vị thứ 5 có thể chấp nhận được. Walk-forward xác nhận lợi nhuận ngoài mẫu. Phí funding đã được tính, phân tích plateau đã qua. Chiến lược thực sự hoạt động.
Nhưng nó giao dịch 15% thời gian. 85% còn lại vốn của bạn ngồi không.
Chạy một chiến lược thứ hai? Thứ ba? Thứ mười? Ý tưởng rõ ràng. Triển khai thì không. Một danh mục chiến lược tạo ra các vấn đề không tồn tại với một bot duy nhất:
- Xung đột: hai chiến lược muốn mở các vị thế đối lập trên cùng một cặp.
- Ràng buộc: sàn giao dịch/quản lý rủi ro cho phép không quá vị thế đồng thời.
- Phân bổ: phần vốn nào nên cấp cho mỗi chiến lược?
- Tương quan: 10 chiến lược trên các cặp crypto tương quan không phải là đa dạng hóa 10 lần.
Chiến lược cascade là một mẫu kiến trúc giải quyết các vấn đề này: chiến lược chính nhận được kích thước vị thế đầy đủ, trong khi chiến lược dự phòng lấp đầy thời gian nhàn rỗi với một vị thế giảm.
Khái Niệm Cascade: Chính + Dự Phòng

Chiến Lược Có Niềm Tin Cao (Chính)
Chính là một chiến lược với tiêu chí vào lệnh nghiêm ngặt. Ví dụ, ba khung thời gian với ba cấp độ xác nhận: tín hiệu trên daily + 4 giờ + 1 giờ, với lọc biến động và khối lượng.
Đặc điểm:
- Ít giao dịch (hàng chục trong suốt thời gian backtest)
- PnL cao mỗi giao dịch
- Ít thời gian trong vị thế (5-15%)
- Tin tưởng cao vào mỗi lần vào lệnh
Chiến Lược Dự Phòng
Dự phòng là một chiến lược với tiêu chí nới lỏng. Hai khung thời gian, ít bộ lọc hơn, dung sai rộng hơn. Nó giao dịch thường xuyên hơn, nhưng với lợi thế thấp hơn mỗi giao dịch.
Đặc điểm:
- Nhiều giao dịch hơn (hàng trăm trong thời gian)
- PnL vừa phải mỗi giao dịch
- Nhiều thời gian trong vị thế (30-50%)
- Niềm tin vừa phải — được bù đắp bằng kích thước vị thế giảm
Chế Độ Cascade
timeline: ──────────────────────────────────────────────────
primary: ___████___________________████████____███________
fallback: ███____███████████████████________████___████████
capital: [dual][ full ][ dual_size ][ full ][ dual ]
Khi chính mở một vị thế — dự phòng im lặng (hoặc đóng). Khi chính không hoạt động — dự phòng giao dịch với vị thế giảm (dual_size). Ưu tiên là vô điều kiện: chính luôn thay thế dự phòng.
Các Chiến Lược Cho Ví Dụ
Trong suốt loạt bài, chúng ta đã sử dụng ba chiến lược. Đây là các tham số của chúng cho kỳ 750 ngày:
| Tham số | Chiến lược A | Chiến lược B | Chiến lược C |
|---|---|---|---|
| PnL | +55% | +27% | +300% |
| Giao dịch | ~500 | ~40 | ~400 |
| Thời gian giao dịch | ~15% | ~5% | ~45% |
| MaxDD | ~0.9% | ~0.75% | ~17% |
| PnL/ngày hoạt động | 0.49%/ngày | 0.72%/ngày | 0.89%/ngày |
| Đặc điểm | Hoạt động vừa phải | Hiếm, niềm tin cao | Thường xuyên, tích cực |
Như chúng ta đã chỉ ra trong PnL trên Thời Gian Hoạt Động, xếp hạng theo PnL thô và theo PnL/ngày hoạt động cho kết quả khác nhau. Đối với điều phối cascade, số liệu thứ hai mới là điều quan trọng.
dual_size Tối Ưu
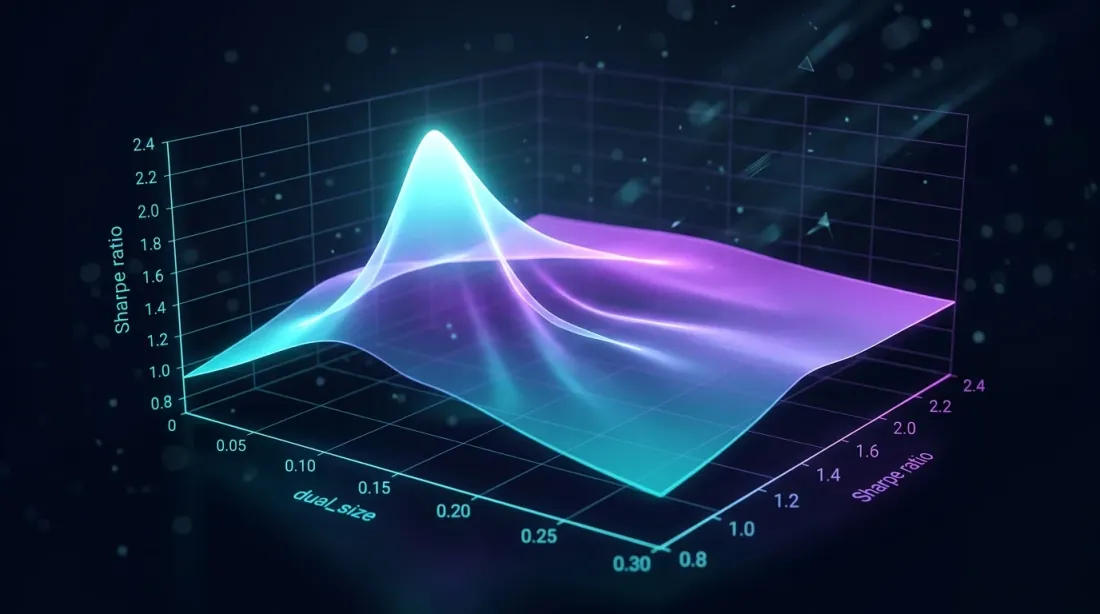 Tìm kiếm lưới trên dual_size cho thấy đỉnh Sharpe ratio — quá lớn làm tăng drawdown, quá nhỏ lãng phí thời gian nhàn rỗi
Tìm kiếm lưới trên dual_size cho thấy đỉnh Sharpe ratio — quá lớn làm tăng drawdown, quá nhỏ lãng phí thời gian nhàn rỗi
Vấn Đề Lựa Chọn
dual_size là phần của vị thế đầy đủ mà chiến lược dự phòng nhận được. Đây là tham số cascade chính:
-
Quá lớn (ví dụ: 0.5 = 50%): khi chính và dự phòng đồng thời hoạt động, tổng rủi ro = 150% mục tiêu. Drawdown tăng gấp đôi. Bất đối xứng lỗ-lãi làm điều này tốn kém không cân xứng.
-
Quá nhỏ (ví dụ: 0.01 = 1%): dự phòng lấp đầy 85% thời gian nhàn rỗi nhưng kiếm được một chút. Vốn hiệu quả ngồi không.
-
Tối ưu: dự phòng đóng góp PnL có ý nghĩa mà không làm tăng drawdown nghiêm trọng trong thời gian hoạt động đồng thời với chính.
Hình Thức Hóa
Cho:
- — PnL chính trên đơn vị thời gian
- — PnL dự phòng trên đơn vị thời gian
- — phần thời gian trong vị thế (chính)
- — phần thời gian trong vị thế (dự phòng)
- — dual_size (0..1)
- — phần thời gian khi cả hai đều trong vị thế
Tổng PnL cascade:
Tổng MaxDD (trường hợp xấu nhất — tương quan đầy đủ):
Nếu chúng ta giới hạn tổng drawdown ở :
Tìm Kiếm Lưới
Trong thực tế, dual_size tối ưu được tìm thông qua tìm kiếm lưới trên cascade backtest:
import numpy as np
from dataclasses import dataclass
@dataclass
class CascadeResult:
dual_size: float
total_pnl: float
max_dd: float
sharpe: float
pnl_per_active_day: float
def grid_search_dual_size(
primary_equity: np.ndarray, # equity curve primary (minute bars)
fallback_equity: np.ndarray, # equity curve fallback (minute bars)
primary_positions: np.ndarray, # 1 = in position, 0 = flat
fallback_positions: np.ndarray,
grid: np.ndarray = np.arange(0.01, 0.30, 0.005),
) -> list[CascadeResult]:
"""
Grid search for dual_size.
primary_equity and fallback_equity are log-returns, minute bars.
"""
results = []
for d in grid:
fallback_active = fallback_positions & ~primary_positions
cascade_returns = (
primary_equity * primary_positions
+ d * fallback_equity * fallback_active
)
equity_curve = np.cumprod(1 + cascade_returns)
peak = np.maximum.accumulate(equity_curve)
drawdown = (equity_curve - peak) / peak
max_dd = drawdown.min()
total_pnl = equity_curve[-1] - 1
sharpe = (
np.mean(cascade_returns) / np.std(cascade_returns)
* np.sqrt(525_600) # minutes per year
) if np.std(cascade_returns) > 0 else 0
active_minutes = np.sum(primary_positions | fallback_active)
active_days = active_minutes / (24 * 60)
pnl_per_day = total_pnl / active_days if active_days > 0 else 0
results.append(CascadeResult(
dual_size=d,
total_pnl=total_pnl,
max_dd=max_dd,
sharpe=sharpe,
pnl_per_active_day=pnl_per_day,
))
return sorted(results, key=lambda r: r.sharpe, reverse=True)
Tối ưu điển hình cho các chiến lược crypto: dual_size trong phạm vi 0.05-0.10 (5-10% vị thế đầy đủ). Với Chiến lược B là chính (MaxDD 0.75%) và Chiến lược A là dự phòng (MaxDD 0.9%):
Ràng buộc drawdown không ràng buộc — tối ưu được xác định bởi Sharpe cascade. Trong thực tế, tìm kiếm lưới thường cho (6.8%).
Phân Bổ Dựa Trên Điểm Số
 Các chiến lược được xếp hạng theo điểm số tổng hợp — điều chỉnh độ tin cậy phạt các mẫu nhỏ, chi phí funding làm giảm lợi thế ròng
Các chiến lược được xếp hạng theo điểm số tổng hợp — điều chỉnh độ tin cậy phạt các mẫu nhỏ, chi phí funding làm giảm lợi thế ròng
Khi có hơn hai chiến lược, cascade tổng quát hóa thành phân bổ dựa trên điểm số.
Xếp Hạng theo PnL trên Thời Gian Hoạt Động
Như đã mô tả chi tiết trong PnL trên Thời Gian Hoạt Động, điểm số chiến lược được tính toán có tính đến:
- PnL trên ngày hoạt động — hiệu quả sử dụng vốn
- Điều chỉnh độ tin cậy — phạt cho các mẫu nhỏ (phân phối t)
- Chi phí funding — chi phí thực sự của đòn bẩy (Phí Funding)
- MaxLev — chia tỷ lệ với xem xét drawdown (Bất đối xứng lỗ-lãi)
Điều Chỉnh Độ Tin Cậy cho Chiến Lược Hiếm
Chiến lược B với 40 giao dịch cần một hình phạt nghiêm túc. Chúng ta sử dụng giới hạn dưới của khoảng tin cậy:
import scipy.stats as st
import numpy as np
def confidence_factor(trade_returns: np.ndarray, confidence: float = 0.95) -> float:
"""Confidence factor: 0..1, penalty for small samples."""
n = len(trade_returns)
if n < 10:
return 0.0
mean_r = np.mean(trade_returns)
if mean_r <= 0:
return 0.0
se = np.std(trade_returns, ddof=1) / np.sqrt(n)
t_crit = st.t.ppf(1 - (1 - confidence) / 2, df=n - 1)
ci_lower = mean_r - t_crit * se
return max(0.0, ci_lower / mean_r)
cf_b = confidence_factor(np.random.normal(0.0067, 0.028, 40))
cf_a = confidence_factor(np.random.normal(0.0011, 0.008, 500))
Tích Hợp Chi Phí Funding
Trên hợp đồng tương lai vĩnh cửu, funding được thanh toán mỗi 8 giờ. Với đòn bẩy và tỷ lệ trung bình :
Đối với Chiến lược A với MaxLev = 55x và tỷ lệ funding trung bình 0.01%:
Với PnL/ngày hoạt động = 0.49%, PnL ròng là âm: /ngày. Chiến lược không có lợi nhuận ở đòn bẩy đầy đủ. Phân tích chi tiết trong Phí Funding Giết Chết Đòn Bẩy Của Bạn.
Bộ Điều Phối Đa Chiến Lược
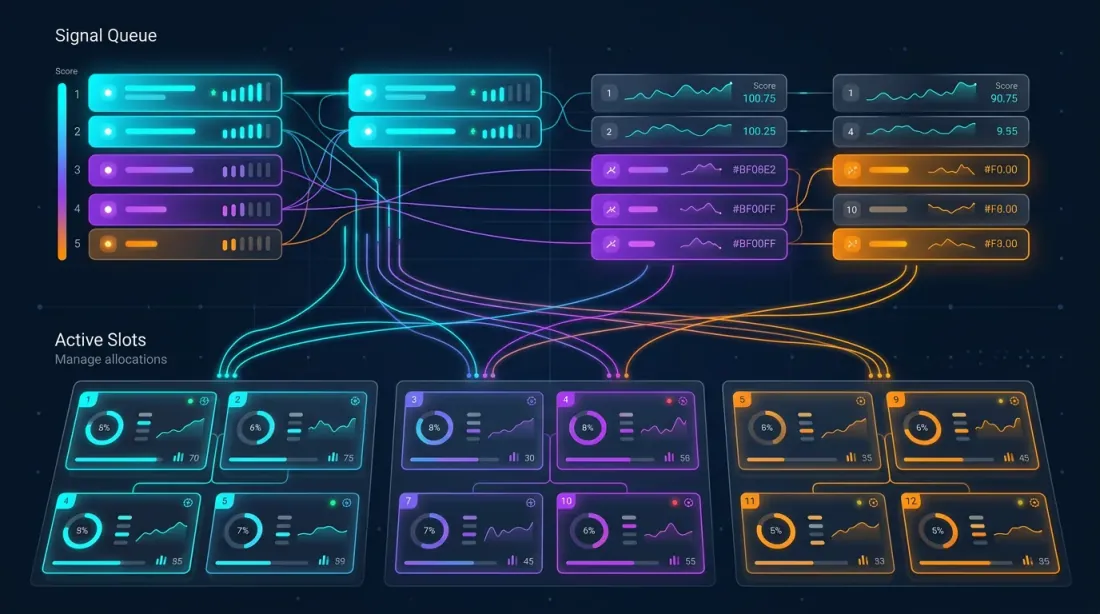
Kiến Trúc
Bộ điều phối quản lý chiến lược trên cặp giao dịch. Tổng số vị thế tiềm năng: . Nhưng vốn bị giới hạn — không quá vị thế đồng thời (slot) được phép.
┌─────────────────────────────────────────────┐
│ ORCHESTRATOR │
│ │
│ Signal Queue (sorted by score): │
│ ┌──────────────────────────────────────┐ │
│ │ 1. Strategy C × ETHUSDT score=223 │ │
│ │ 2. Strategy B × BTCUSDT score=142 │ │
│ │ 3. Strategy A × SOLUSDT score=100 │ │
│ │ 4. Strategy C × BTCUSDT score=89 │ │
│ │ 5. Strategy A × ETHUSDT score=76 │ │
│ └──────────────────────────────────────┘ │
│ │
│ Active Slots (max_parallel = 3): │
│ ┌──────────────────────────────────────┐ │
│ │ Slot 1: Strategy C × ETHUSDT [FULL] │ │
│ │ Slot 2: Strategy B × BTCUSDT [FULL] │ │
│ │ Slot 3: Strategy A × SOLUSDT [DUAL] │ │
│ └──────────────────────────────────────┘ │
│ │
│ Conflict Rules: │
│ - One position per pair │
│ - Primary displaces fallback on same pair │
│ - Higher score wins for cross-pair slots │
└─────────────────────────────────────────────┘
Quản Lý Slot
from dataclasses import dataclass, field
from enum import Enum
from typing import Optional
import heapq
import time
class SlotType(Enum):
FULL = "full" # primary strategy, 100% position
DUAL = "dual" # fallback strategy, dual_size position
@dataclass
class Signal:
strategy_id: str
pair: str
direction: str # "long" | "short"
score: float
is_primary: bool # primary or fallback
timestamp: float
@dataclass(order=True)
class Slot:
"""A single orchestrator slot."""
priority: float = field(compare=True) # negative score for min-heap
strategy_id: str = field(compare=False)
pair: str = field(compare=False)
slot_type: SlotType = field(compare=False)
entry_time: float = field(compare=False)
class Orchestrator:
"""
Multi-strategy orchestrator with cascade mode.
Manages N strategies x M pairs within max_parallel_positions slots.
Primary strategies have unconditional priority over fallback.
"""
def __init__(
self,
max_parallel_positions: int = 10,
dual_size: float = 0.068,
min_score: float = 0,
):
self.max_parallel = max_parallel_positions
self.dual_size = dual_size
self.min_score = min_score
self.active_slots: dict[str, Slot] = {} # pair -> Slot
self.pending_signals: list[Signal] = []
def on_signal(self, signal: Signal) -> Optional[dict]:
"""
Process a new signal. Returns an action or None.
Actions:
- {"action": "open", "pair": ..., "size": ..., "slot_type": ...}
- {"action": "replace", "pair": ..., "close_strategy": ..., "open_strategy": ...}
- None (signal rejected)
"""
if signal.score < self.min_score:
return None
pair = signal.pair
if pair in self.active_slots:
existing = self.active_slots[pair]
if signal.is_primary and existing.slot_type == SlotType.DUAL:
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=SlotType.FULL,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": 1.0,
}
if signal.score > -existing.priority:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # existing has higher priority
if len(self.active_slots) < self.max_parallel:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "open",
"pair": pair,
"strategy": signal.strategy_id,
"size": size,
"slot_type": slot_type,
}
worst_pair = min(
self.active_slots,
key=lambda p: -self.active_slots[p].priority,
)
worst_slot = self.active_slots[worst_pair]
if signal.score > -worst_slot.priority:
del self.active_slots[worst_pair]
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": worst_slot.strategy_id,
"close_pair": worst_pair,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # all active slots have higher scores
def on_exit(self, pair: str) -> None:
"""Strategy closed a position."""
if pair in self.active_slots:
del self.active_slots[pair]
def utilization(self) -> float:
"""Current slot utilization."""
return len(self.active_slots) / self.max_parallel
def fill_efficiency_snapshot(self) -> float:
"""Weighted utilization: FULL=1.0, DUAL=dual_size."""
total = sum(
1.0 if s.slot_type == SlotType.FULL else self.dual_size
for s in self.active_slots.values()
)
return total / self.max_parallel
Giải Quyết Xung Đột
Ba cấp độ xung đột:
Cấp 1 — Cùng cặp, cùng hướng. Chiến lược có điểm số cao hơn thắng. Nếu cả hai đều là chính — điểm số xác định người thắng. Nếu một là chính và cái kia là dự phòng — chính thắng vô điều kiện.
Cấp 2 — Cùng cặp, hướng đối lập. Bị cấm: bạn không thể đồng thời long và short trên cùng một cặp. Chiến lược có điểm số cao nhất thắng.
Cấp 3 — Cạnh tranh giữa các cặp. Khi tất cả các slot bị chiếm, một tín hiệu mới đẩy ra slot có điểm số thấp nhất. Điều này hoạt động như một hàng đợi ưu tiên.
Backtest Cascade: Phương Pháp
 Mô phỏng chung: đường cong equity chính và dự phòng với vùng chồng lấp và kết quả cascade kết hợp
Mô phỏng chung: đường cong equity chính và dự phòng với vùng chồng lấp và kết quả cascade kết hợp
Tại Sao Bạn Không Thể Chỉ Cộng PnL
Cách tiếp cận ngây thơ: backtest từng chiến lược riêng lẻ, cộng tổng PnL. Điều này tạo ra kết quả phóng đại vì ba lý do:
-
Chồng lấp thời gian. Khi chính và dự phòng đồng thời hoạt động, dự phòng không nên giao dịch (hoặc giao dịch ở dual_size). Cộng đơn giản bỏ qua sự chồng lấp này.
-
Ràng buộc vốn. Tổng vị thế bị giới hạn. Nếu 5 chiến lược muốn mở đồng thời nhưng chỉ có 3 slot — hai chiến lược sẽ không vào. PnL của chúng không thể được tính.
-
Chi phí giao dịch. Chuyển đổi cascade (đóng dự phòng, mở chính) tạo ra thêm hoa hồng không có trong backtest riêng lẻ.
Mô Phỏng Chung
Backtest cascade đúng là mô phỏng chung của tất cả các chiến lược trên một dòng thời gian chia sẻ:
import numpy as np
from typing import NamedTuple
class Trade(NamedTuple):
strategy: str
pair: str
entry_time: int # minute index
exit_time: int # minute index
pnl_per_minute: float # log-return per minute
is_primary: bool
score: float
def backtest_cascade(
all_trades: list[Trade],
total_minutes: int,
max_slots: int = 10,
dual_size: float = 0.068,
switch_cost: float = 0.0006, # 0.06% round-trip
) -> dict:
"""
Joint simulation of cascade portfolio.
Walk through each minute, apply orchestrator rules,
calculate PnL accounting for overlap and slot constraints.
"""
entries = {}
exits = {}
active_trades = {} # trade_id -> Trade
for i, trade in enumerate(all_trades):
entries.setdefault(trade.entry_time, []).append((i, trade))
exits.setdefault(trade.exit_time, []).append((i, trade))
active_slots = {} # pair -> (trade_id, SlotType)
equity = np.ones(total_minutes)
switch_costs_total = 0.0
for t in range(1, total_minutes):
for trade_id, trade in exits.get(t, []):
if trade.pair in active_slots:
slot_id, _ = active_slots[trade.pair]
if slot_id == trade_id:
del active_slots[trade.pair]
new_signals = sorted(
entries.get(t, []),
key=lambda x: x[1].score,
reverse=True,
)
for trade_id, trade in new_signals:
pair = trade.pair
if pair in active_slots:
existing_id, existing_type = active_slots[pair]
existing_trade = all_trades[existing_id]
if trade.is_primary and existing_type == SlotType.DUAL:
active_slots[pair] = (trade_id, SlotType.FULL)
switch_costs_total += switch_cost
continue
if trade.score > existing_trade.score:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
switch_costs_total += switch_cost
elif len(active_slots) < max_slots:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
minute_return = 0.0
for pair, (trade_id, slot_type) in active_slots.items():
trade = all_trades[trade_id]
size = 1.0 if slot_type == SlotType.FULL else dual_size
minute_return += trade.pnl_per_minute * size
equity[t] = equity[t - 1] * (1 + minute_return)
peak = np.maximum.accumulate(equity)
max_dd = ((equity - peak) / peak).min()
total_pnl = equity[-1] - 1 - switch_costs_total
return {
"total_pnl": total_pnl,
"max_dd": max_dd,
"switch_costs": switch_costs_total,
"equity_curve": equity,
}
Chi Phí Giao Dịch khi Chuyển Đổi
Mỗi lần chuyển đổi cascade (dự phòng -> chính) yêu cầu:
- Đóng vị thế dự phòng: phí taker (0.04% trên Binance futures)
- Mở vị thế chính: phí taker (0.04%)
- Spread: ~0.01-0.02%
Tổng chi phí chuyển đổi: ~0.06-0.10% mỗi lần chuyển đổi. Với 100 lần chuyển đổi trong kỳ:
Đây là một khoản đáng kể. Một cascade với chuyển đổi thường xuyên có thể kém hiệu quả hơn một chiến lược duy nhất do chi phí giao dịch.
Mở Rộng Đa Cặp: N Chiến Lược trên M Cặp
 Mạng N chiến lược kết nối với M cặp giao dịch — độ mạnh tương quan xác định đa dạng hóa hiệu quả
Mạng N chiến lược kết nối với M cặp giao dịch — độ mạnh tương quan xác định đa dạng hóa hiệu quả
Không Gian Kết Hợp
3 chiến lược trên 10 cặp = 30 tín hiệu tiềm năng. Với max_slots = 5, bộ điều phối chọn 5 hàng đầu theo điểm số. Đây là một bài toán tổ hợp: danh mục có thể tại mỗi thời điểm.
Trong thực tế, thuật toán tham lam (sắp xếp theo điểm số, điền từ trên xuống) tạo ra kết quả gần tối ưu trong .
Tương Quan Giữa Các Cặp
Các cặp crypto có tương quan mạnh. BTC giảm — ETH, SOL, AVAX cũng giảm cùng nhau. Điều này có nghĩa là 5 vị thế long trên 5 cặp khác nhau thực tế là một vị thế lớn trên "thị trường crypto."
Như chúng ta đã phân tích chi tiết trong Tương Quan Tín Hiệu, số lượng vị thế độc lập hiệu quả:
trong đó là tương quan trung bình giữa các cặp.
Với và :
Năm vị thế trên các cặp tương quan tương đương với 1.3 vị thế độc lập. Đa dạng hóa hầu như không có.
Hàm Ý Thực Tế cho Cascade
def effective_diversification(
positions: list[dict], # [{"pair": "BTCUSDT", "direction": "long"}, ...]
correlation_matrix: np.ndarray,
pair_index: dict[str, int],
) -> float:
"""
Calculate effective diversification of open positions.
Returns:
N_eff / N — diversification coefficient (0..1)
"""
n = len(positions)
if n <= 1:
return 1.0
total_corr = 0.0
pairs_count = 0
for i in range(n):
for j in range(i + 1, n):
idx_i = pair_index[positions[i]["pair"]]
idx_j = pair_index[positions[j]["pair"]]
rho = correlation_matrix[idx_i, idx_j]
if positions[i]["direction"] != positions[j]["direction"]:
rho = -rho
total_corr += rho
pairs_count += 1
avg_rho = total_corr / pairs_count if pairs_count > 0 else 0
n_eff = n / (1 + (n - 1) * max(0, avg_rho))
return n_eff / n
Bộ điều phối nên tính đến tương quan khi điền các slot. Hai tùy chọn:
- Phần thưởng đa dạng hóa: khi xếp hạng, thêm phần thưởng vào điểm số của các chiến lược trên các cặp không tương quan.
- Giới hạn tương quan: giới hạn số lượng vị thế cùng hướng trên các cặp tương quan.
Pipeline Tối Ưu Hóa Cascade
 Tám giai đoạn kết nối từ chuẩn bị dữ liệu qua xác thực đến điều phối trực tiếp — mỗi giai đoạn xây dựng trên giai đoạn trước
Tám giai đoạn kết nối từ chuẩn bị dữ liệu qua xác thực đến điều phối trực tiếp — mỗi giai đoạn xây dựng trên giai đoạn trước
Pipeline đầy đủ từ dữ liệu đến production gồm 8 giai đoạn:
Giai Đoạn 0: Chuẩn Bị Dữ Liệu
Tải dữ liệu lịch sử, xây dựng bộ nhớ đệm Parquet cho truy cập đa khung thời gian. Không có bộ nhớ đệm hiệu quả, các giai đoạn tiếp theo sẽ chậm không thể chấp nhận.
Giai Đoạn 1: TF + Length (Hill-Climbing Grid)
Chọn khung thời gian cơ sở và độ dài cửa sổ chỉ báo. Lưới thô: TF từ {1m, 5m, 15m, 1h, 4h}, Length từ {10, 20, 50, 100, 200}. Hill-climbing từ điểm lưới tốt nhất.
Giai Đoạn 2: Tách Biệt (Coordinate Descent, 12 Tham Số)
Tối ưu hóa các tham số tách biệt (vào/ra). Coordinate descent trên 12 tham số — ngưỡng chỉ báo, bộ lọc, stop-loss, take-profit. Coordinate descent rẻ hơn Optuna cho các hàm mục tiêu tất định chiều cao.
Giai Đoạn 3: Meta-Tham Số (Coordinate Descent)
Meta-tham số: thời gian giữ tối đa, PnL tối thiểu để thoát, cấu hình trailing stop. Lại coordinate descent. Kiểm tra độ bền vững qua phân tích plateau — nếu điểm tối ưu là dạng điểm, chiến lược bị over-optimize.
Giai Đoạn 4: Tối Ưu Hóa Combo
Tìm kiếm lưới trên các cặp (Chính, Dự phòng). Đối với mỗi kết hợp: chọn dual_size, tính PnL cascade qua mô phỏng chung.
Giai Đoạn 5: Xác Thực
Xác thực đa cấp:
- Đa ký hiệu: chiến lược được kiểm tra trên 10+ cặp, không chỉ cặp tối ưu hóa
- Walk-forward: cửa sổ IS/OOS trượt
- Độ ổn định tham số: phân tích plateau ở mỗi giai đoạn
- Monte Carlo bootstrap: khoảng tin cậy cho PnL cascade
- Tương đồng backtest-live: so sánh backtest với giao dịch giấy
Giai Đoạn 6: Xếp Hạng và Lựa Chọn
Xếp hạng các kết hợp cascade theo điểm số. Top-K kết hợp tiến lên Giai đoạn 7. Điểm số tính đến điều chỉnh độ tin cậy, chi phí funding và fill_efficiency.
Giai Đoạn 7: Điều Phối
Giai đoạn cuối: khởi động bộ điều phối trên chiến lược và cặp trong chế độ cascade. Quản lý slot, hàng đợi ưu tiên, giải quyết xung đột — tất cả được mô tả ở trên.
Phân Tích Hiệu Suất: Cascade vs. Đơn Lẻ
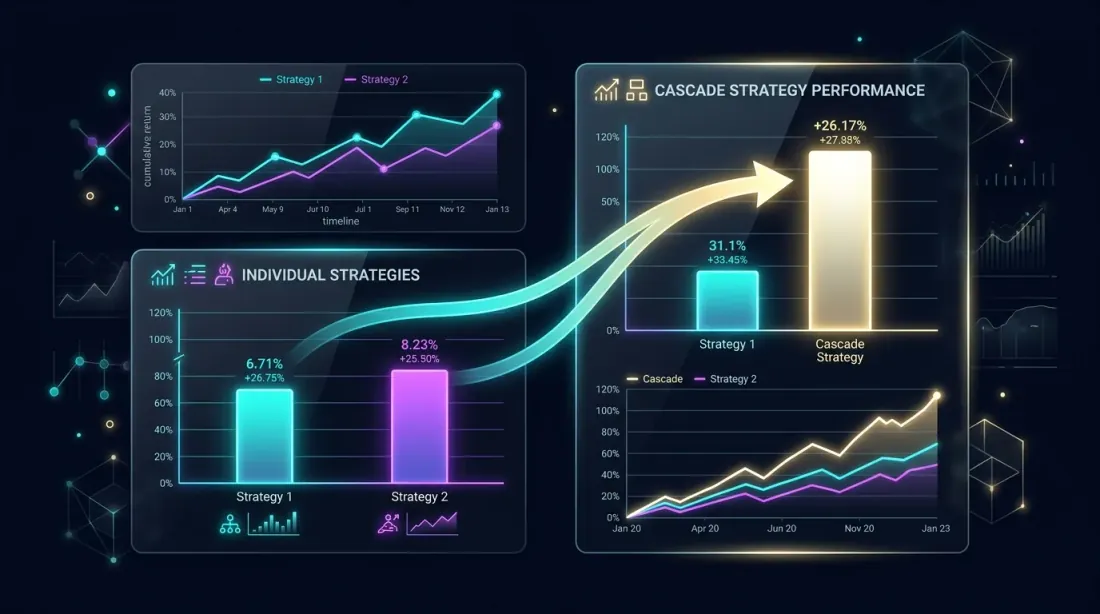 So sánh song song: danh mục cascade vượt trội hơn các chiến lược đơn lẻ thông qua sử dụng thời gian nhàn rỗi
So sánh song song: danh mục cascade vượt trội hơn các chiến lược đơn lẻ thông qua sử dụng thời gian nhàn rỗi
Lợi Thế Cascade Lý Thuyết
Giả sử chính giao dịch thời gian với PnL/ngày = 0.49%. Dự phòng giao dịch với PnL/ngày = 0.89%. Chồng lấp = (giả định độc lập).
Chính đơn lẻ (Chiến lược A):
Cascade (A chính + C dự phòng):
Lợi ích cascade: +31% PnL từ dự phòng, với mức tăng drawdown tối thiểu ( thêm vào MaxDD).
Khi Cascade Không Giúp Ích
Cascade không hiệu quả khi:
- Chính hoạt động >80% thời gian. Ít thời gian nhàn rỗi — không có chỗ cho dự phòng.
- Các chiến lược có tương quan cao. Chính và dự phòng tạo tín hiệu đồng thời — chồng lấp cao, và dự phòng nhàn rỗi chính xác khi chính cũng nhàn rỗi.
- Chi phí chuyển đổi vượt quá PnL dự phòng. Với chuyển đổi thường xuyên, hoa hồng cascade ăn mòn lợi nhuận dự phòng.
- dual_size quá nhỏ. Ở , dự phòng kiếm 1% tiềm năng — dưới hoa hồng.
Bảng So Sánh
| Cấu hình | PnL hàng năm | MaxDD | Sharpe | Chi phí chuyển đổi |
|---|---|---|---|---|
| Chiến lược A đơn lẻ | 26.8% | 0.9% | 1.42 | 0 |
| Chiến lược C đơn lẻ | 146.1% | 17% | 1.15 | 0 |
| Cascade A+C (d=0.068) | 35.2% | 2.06% | 1.58 | ~1.2% |
| Cascade B+A (d=0.068) | 19.4% | 1.36% | 1.71 | ~0.3% |
| Bộ điều phối 3 chiến lược | 48.7% | 3.1% | 1.63 | ~2.1% |
Cascade A+C: chính A đạt +8.4% từ dự phòng C. Sharpe tăng thông qua sử dụng thời gian nhàn rỗi. MaxDD tăng vừa phải ().
Điều Phối: fill_efficiency trong Thực Tế
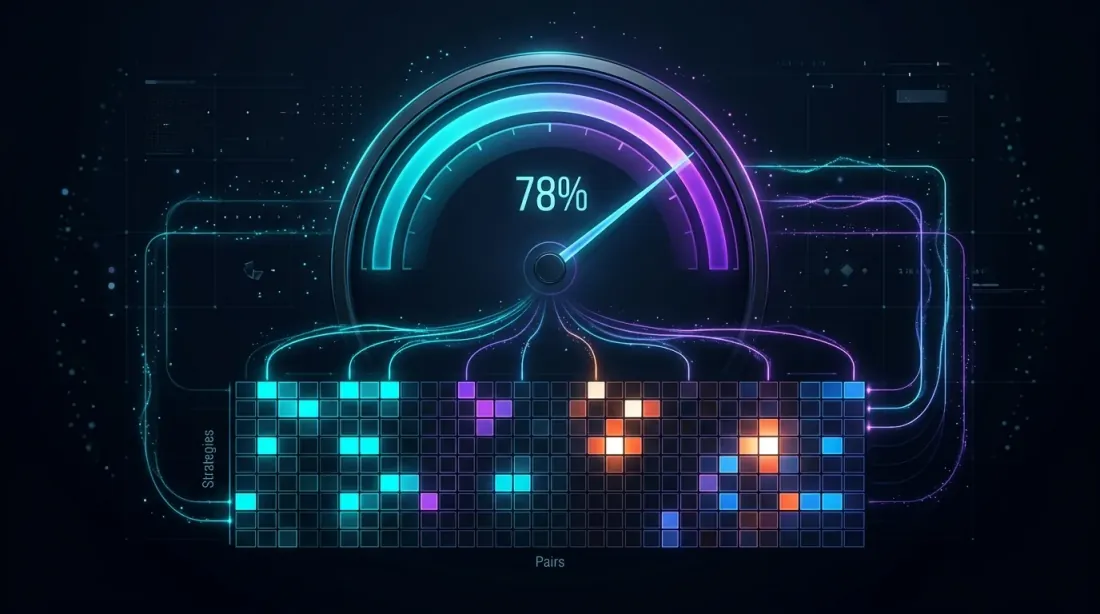 Fill efficiency ở ~78%: bản đồ nhiệt cho thấy sử dụng thời gian trên các chiến lược và cặp, ô sáng biểu thị giao dịch đang hoạt động
Fill efficiency ở ~78%: bản đồ nhiệt cho thấy sử dụng thời gian trên các chiến lược và cặp, ô sáng biểu thị giao dịch đang hoạt động
Tham số fill_efficiency xác định phần thời gian nhàn rỗi mà bộ điều phối thực sự sử dụng. Như được chỉ ra trong PnL trên Thời Gian Hoạt Động, nó có thể được ước tính theo ba cách:
- Hằng số cố định (0.80) — thô nhưng phổ quát
- Ước tính phân tích qua — tính đến tương quan
- Mô phỏng từ dữ liệu — chính xác nhất
Đối với cascade với 3 chiến lược trên 10 cặp:
def cascade_fill_efficiency(
strategies: list[dict], # [{"trading_time": 0.15, "is_primary": True}, ...]
n_pairs: int = 10,
correlation_factor: float = 3.0,
) -> float:
"""Estimate fill_efficiency for a cascade portfolio."""
n_eff = n_pairs / correlation_factor
primary_times = [s["trading_time"] for s in strategies if s["is_primary"]]
p_primary = 1 - np.prod([(1 - t) ** n_eff for t in primary_times])
fallback_times = [s["trading_time"] for s in strategies if not s["is_primary"]]
p_fallback = 1 - np.prod([(1 - t) ** n_eff for t in fallback_times])
fill = p_primary + (1 - p_primary) * p_fallback
return min(fill, 1.0)
strategies = [
{"trading_time": 0.05, "is_primary": True}, # Strategy B
{"trading_time": 0.15, "is_primary": True}, # Strategy A
{"trading_time": 0.45, "is_primary": False}, # Strategy C as fallback
]
eff = cascade_fill_efficiency(strategies, n_pairs=10, correlation_factor=3.0)
Khuyến Nghị Thực Tế
 Sáu khuyến nghị chính để triển khai cascade — từ bắt đầu nhỏ đến hiệu chỉnh thích ứng
Sáu khuyến nghị chính để triển khai cascade — từ bắt đầu nhỏ đến hiệu chỉnh thích ứng
1. Bắt Đầu với Hai Chiến Lược
Đừng khởi động 10 chiến lược trên 20 cặp ngay. Bắt đầu với một chính + một dự phòng trên 3-5 cặp. Đảm bảo mô phỏng chung khớp với hành vi thực. Tương đồng backtest-live rất quan trọng: nếu backtest cascade phân kỳ so với live ngay cả 5-10% — có lỗi trong logic bộ điều phối.
2. dual_size từ Tìm Kiếm Lưới, Không Phải Trực Giác
dual_size tối ưu phụ thuộc vào cặp chiến lược cụ thể. 6.8% là hướng dẫn, không phải hằng số phổ quát. Chạy tìm kiếm lưới từ 1% đến 30% với bước 0.5% và chọn giá trị Sharpe cực đại.
3. Giới Hạn Slot Xác Định Kiến Trúc
Với max_slots = 1, cascade suy biến thành chuyển đổi chiến lược đơn giản. Với max_slots = 50, ràng buộc không ràng buộc và bài toán giảm về danh mục độc lập. Vùng thú vị: max_slots = 3-10, nơi quản lý slot thực sự ảnh hưởng đến kết quả.
4. Tính Đến Độ Trễ
Trong giao dịch trực tiếp, chuyển đổi cascade không tức thời. Đóng vị thế dự phòng + mở chính = 2 lần gọi API + độ trễ mạng + khớp lệnh sàn. Trên thị trường biến động, giá có thể di chuyển trong 200-500ms. Xây dựng ngân sách trượt giá.
5. Theo Dõi fill_efficiency
Theo dõi fill_efficiency thực tế trong production. Nếu nó thấp hơn đáng kể so với backtest — bộ điều phối không sử dụng thời gian nhàn rỗi như dự kiến. Nguyên nhân: độ trễ API, lệnh bị từ chối, ràng buộc margin.
6. Sử Dụng Tối Ưu Hóa Thích Ứng
Các tham số cascade (dual_size, trọng số điểm số, giới hạn slot) không nên tĩnh. Sử dụng adaptive drill-down để hiệu chỉnh định kỳ trên dữ liệu mới. Thị trường thay đổi — các tham số cascade nên theo dõi.
Loạt Bài "Backtest Không Ảo Tưởng": Tóm Tắt
 Kiến trúc hệ thống hoàn chỉnh: 13 mô-đun kết nối từ toán học qua xác thực đến điều phối trực tiếp
Kiến trúc hệ thống hoàn chỉnh: 13 mô-đun kết nối từ toán học qua xác thực đến điều phối trực tiếp
Bài viết này là phần kết của loạt bài 13+ bài. Mỗi bài đề cập đến một vấn đề cụ thể trên con đường từ backtest đến production. Đây là cách chúng kết nối:
Nền Tảng: Toán Học Lợi Nhuận
Bất Đối Xứng Lỗ-Lãi — bản chất nhân của lợi nhuận, volatility drag, tiêu chí Kelly. Đây là nền tảng toán học cho mọi thứ tiếp theo: tại sao MaxDD xác định đòn bẩy, tại sao Sharpe quan trọng hơn PnL thô, tại sao tỷ lệ thắng 50% với R:R đối xứng là không có lợi nhuận.
Xác Thực: Khoảng Tin Cậy và Độ Bền Vững
Monte Carlo Bootstrap — biến ước tính điểm đơn thành phân phối với khoảng tin cậy. Bất kỳ số liệu nào (PnL, MaxDD, Sharpe) chỉ có ý nghĩa với khoảng tin cậy.
Walk-Forward Optimization — xác thực ngoài mẫu. Backtest trên dữ liệu lịch sử là kết quả IS; WFO cho thấy chiến lược hoạt động như thế nào trên dữ liệu mới.
Phân Tích Plateau — kiểm tra độ bền vững tham số. Nếu điểm tối ưu là dạng điểm, chiến lược bị over-optimize.
Tương Đồng Backtest-Live — so sánh backtest với kết quả thực. Kiểm tra cuối cùng trước khi mở rộng.
Chi Phí Thực Tế: Funding và Đòn Bẩy
Phí Funding Giết Chết Đòn Bẩy — chi phí ẩn của đòn bẩy trên hợp đồng tương lai vĩnh cửu. Không tính đến funding, backtest đẹp trở thành thua lỗ.
Kinh Doanh Chênh Lệch Phí Funding — cách biến funding từ chi phí thành nguồn doanh thu thông qua các chiến lược đa sàn.
Số Liệu và Xếp Hạng
PnL trên Thời Gian Hoạt Động — số liệu để xếp hạng chiến lược trong danh mục. PnL thô không có thể chia tỷ lệ; PnL/ngày hoạt động thì có.
Tương Quan Tín Hiệu — đa dạng hóa hiệu quả trong danh mục các cặp tương quan.
Cơ Sở Hạ Tầng và Tối Ưu Hóa
Bộ Nhớ Đệm Parquet cho Backtest Đa Khung Thời Gian — cơ sở hạ tầng dữ liệu cho các lần lặp nhanh.
Adaptive Drill-Down — tối ưu hóa thích ứng: lưới thô -> tinh chỉnh trong các vùng hứa hẹn.
Optuna vs. Coordinate Descent — lựa chọn bộ tối ưu hóa: Optuna cho chiều thấp với mục tiêu nhiễu, coordinate descent cho chiều cao với mục tiêu trơn.
Polars vs Pandas — hiệu suất thao tác DataFrame cho backtesting.
Điều Phối (Bài Viết Này)
Chiến Lược Cascade — kết hợp tất cả các thành phần trước thành một hệ thống hoạt động. Phân bổ dựa trên điểm số sử dụng PnL/thời gian hoạt động, điều chỉnh độ tin cậy, chi phí funding. Chế độ cascade lấp đầy thời gian nhàn rỗi. Mô phỏng chung xác thực danh mục. Monte Carlo bootstrap cung cấp khoảng tin cậy cho PnL cascade.
Mỗi bài viết là một mô-đun độc lập. Cùng nhau chúng tạo thành một pipeline hoàn chỉnh từ tải dữ liệu đến điều phối trực tiếp của danh mục chiến lược.
Kết Luận
Cascade không phải là phương pháp duy nhất cho danh mục chiến lược. Nhưng đây là một trong những cách đơn giản và thực tế nhất: chiến lược chính giao dịch với toàn công suất, dự phòng lấp đầy thời gian nhàn rỗi với vị thế giảm. Hai tham số chính (dual_size và max_slots) cung cấp đủ linh hoạt cho hầu hết các cấu hình.
Ba bài học:
-
Cascade phải được backtest qua mô phỏng chung duy nhất. Cộng tổng PnL riêng lẻ phóng đại kết quả. Chi phí chuyển đổi, chồng lấp, ràng buộc slot — tất cả điều này chỉ được nắm bắt trong mô phỏng chung.
-
dual_size xác định đánh đổi PnL vs. drawdown. Tối ưu điển hình là 5-10%. Tìm kiếm lưới trên Sharpe là phương pháp lựa chọn đáng tin cậy.
-
Bộ điều phối là hàng đợi ưu tiên dựa trên điểm số. Mọi thứ đều quy về một con số duy nhất (điểm số) cho mỗi tín hiệu. Điểm số = f(PnL/ngày hoạt động, MaxLev, độ tin cậy, funding). Các chiến lược có điểm số cao nhất nhận slot. Phần còn lại chờ đợi.
Loạt bài "Backtest Không Ảo Tưởng" chứng minh một điều: giữa backtest đẹp và lợi nhuận thực sự có hàng chục cạm bẫy. Mỗi bài viết loại bỏ một. Điều phối cascade là bước cuối cùng: biến một tập hợp các chiến lược đã được xác thực thành một danh mục hoạt động.
Liên Kết Hữu Ích
- López de Prado — Advances in Financial Machine Learning: Portfolio Construction
- Pardo, R. — The Evaluation and Optimization of Trading Strategies
- Ernest Chan — Algorithmic Trading: Winning Strategies and Their Rationale
- Perry Kaufman — Trading Systems and Methods, Chapter on Portfolio Allocation
- Tomasini, Jaekle — Trading Systems: A New Approach to System Development and Portfolio Optimisation
- Bailey, D.H. & López de Prado — The Deflated Sharpe Ratio
- Markowitz, H. — Portfolio Selection (1952)
- Kelly, J.L. — A New Interpretation of Information Rate (1956)
Trích Dẫn
@article{soloviov2026cascadestrategies,
author = {Soloviov, Eugen},
title = {Cascade Strategies: Priority Execution with Fallback Filling},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/cascade-strategies-orchestration},
version = {0.1.0},
description = {Finale of the "Backtests Without Illusions" series. How to build an orchestrator from N strategies x M pairs, implement cascade mode with priority and fallback filling, choose dual\_size, and why strategy portfolios cannot be backtested by summing PnL.}
}
Tác Giả

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Đọc Thêm
Tương Quan Tín Hiệu: Cần Theo Dõi Bao Nhiêu Cặp Giao Dịch

Tái Cân Bằng Danh Mục ETF Tự Động: Cách Chúng Tôi Xây Dựng Bot cho Tinkoff Invest