Cascade Strategies: การดำเนินการแบบมีลำดับความสำคัญพร้อม Fallback Filling

บทสรุปของซีรีส์ "Backtests Without Illusions" วิธีสร้าง orchestrator จาก N กลยุทธ์บน M คู่เทรด, การใช้ cascade mode ที่มีลำดับความสำคัญและ fallback execution, การเลือก dual_size, และเหตุใดพอร์ตโฟลิโอกลยุทธ์จึงไม่สามารถ backtest ได้โดยการรวม PnL เพียงอย่างเดียว
เหตุใดคุณจึงต้องการพอร์ตโฟลิโอกลยุทธ์
 กลยุทธ์หลายตัวแข่งขันกันเพื่อทุนที่จำกัด — ส่วนใหญ่นอนเฉยในขณะที่มีเพียงไม่กี่ตัวที่เทรดในช่วงใดช่วงหนึ่ง
กลยุทธ์หลายตัวแข่งขันกันเพื่อทุนที่จำกัด — ส่วนใหญ่นอนเฉยในขณะที่มีเพียงไม่กี่ตัวที่เทรดในช่วงใดช่วงหนึ่ง
คุณนำกลยุทธ์ผ่านกระบวนการทั้งหมดแล้ว Monte Carlo bootstrap แสดงให้เห็น percentile ที่ 5 ที่ยอมรับได้ Walk-forward ยืนยันผลตอบแทน out-of-sample Funding rates ได้รับการคำนึงถึง, plateau analysis ผ่านแล้ว กลยุทธ์นี้ใช้งานได้จริง
แต่มันเทรดเพียง 15% ของเวลา อีก 85% ที่เหลือทุนของคุณนอนเฉยอยู่
เพิ่มกลยุทธ์ที่สอง? ที่สาม? ที่สิบ? ความคิดนั้นชัดเจน แต่การนำไปใช้ไม่ใช่เรื่องง่าย พอร์ตโฟลิโอกลยุทธ์สร้างปัญหาที่ไม่มีอยู่กับบอตตัวเดียว:
- ความขัดแย้ง: กลยุทธ์สองตัวต้องการเปิดโพซิชันตรงข้ามบนคู่เดียวกัน
- ข้อจำกัด: การแลกเปลี่ยน/การบริหารความเสี่ยงอนุญาตไม่เกิน โพซิชันพร้อมกัน
- การจัดสรร: จะให้ทุนสัดส่วนเท่าใดแก่กลยุทธ์แต่ละตัว?
- ความสัมพันธ์: 10 กลยุทธ์บนคู่ crypto ที่มีความสัมพันธ์กัน ไม่ใช่การกระจายความเสี่ยง 10 เท่า
Cascade strategy คือ architectural pattern ที่แก้ปัญหาเหล่านี้: กลยุทธ์หลักได้รับขนาดโพซิชันเต็มจำนวน ในขณะที่กลยุทธ์ fallback เติมเวลาว่างด้วยโพซิชันที่ลดลง
แนวคิด Cascade: Primary + Fallback

กลยุทธ์ High-Conviction (Primary)
Primary คือกลยุทธ์ที่มีเกณฑ์การเข้าเทรดที่เข้มงวด ตัวอย่างเช่น triple timeframe ที่มีสามระดับยืนยัน: สัญญาณบน daily + 4-hour + hourly พร้อม volatility และ volume filtering
ลักษณะ:
- เทรดน้อย (หลักสิบครั้งในช่วง backtest)
- PnL ต่อเทรดสูง
- เวลาในโพซิชันต่ำ (5-15%)
- ความเชื่อมั่นสูงในการเข้าแต่ละครั้ง
กลยุทธ์ Fallback
Fallback คือกลยุทธ์ที่มีเกณฑ์ผ่อนคลาย Dual timeframe, ตัวกรองน้อยกว่า, ค่าความคลาดเคลื่อนกว้างกว่า มันเทรดบ่อยกว่า แต่มี edge ต่อเทรดน้อยกว่า
ลักษณะ:
- เทรดมากกว่า (หลักร้อยครั้งในช่วงเวลานั้น)
- PnL ต่อเทรดปานกลาง
- เวลาในโพซิชันสูง (30-50%)
- ความเชื่อมั่นปานกลาง — ชดเชยด้วยขนาดโพซิชันที่ลดลง
Cascade Mode
timeline: ──────────────────────────────────────────────────
primary: ___████___________________████████____███________
fallback: ███____███████████████████________████___████████
capital: [dual][ full ][ dual_size ][ full ][ dual ]
เมื่อ primary เปิดโพซิชัน — fallback จะเงียบ (หรือปิด) เมื่อ primary ว่าง — fallback เทรดที่โพซิชันที่ลดลง (dual_size) ลำดับความสำคัญนั้นไม่มีเงื่อนไข: primary แทนที่ fallback เสมอ
กลยุทธ์สำหรับตัวอย่าง
ตลอดซีรีส์เราใช้สามกลยุทธ์ นี่คือพารามิเตอร์ของพวกมันสำหรับช่วง 750 วัน:
| พารามิเตอร์ | กลยุทธ์ A | กลยุทธ์ B | กลยุทธ์ C |
|---|---|---|---|
| PnL | +55% | +27% | +300% |
| จำนวนเทรด | ~500 | ~40 | ~400 |
| เวลาเทรด | ~15% | ~5% | ~45% |
| MaxDD | ~0.9% | ~0.75% | ~17% |
| PnL/active day | 0.49%/d | 0.72%/d | 0.89%/d |
| ลักษณะ | กิจกรรมปานกลาง | หายาก, ความเชื่อมั่นสูง | บ่อย, เชิงรุก |
ดังที่เราแสดงใน PnL per Active Time การจัดอันดับตาม PnL ดิบและตาม PnL/active day ให้ผลลัพธ์ที่แตกต่างกัน สำหรับ cascade orchestration เมตริกที่สองคือสิ่งสำคัญ
Optimal dual_size
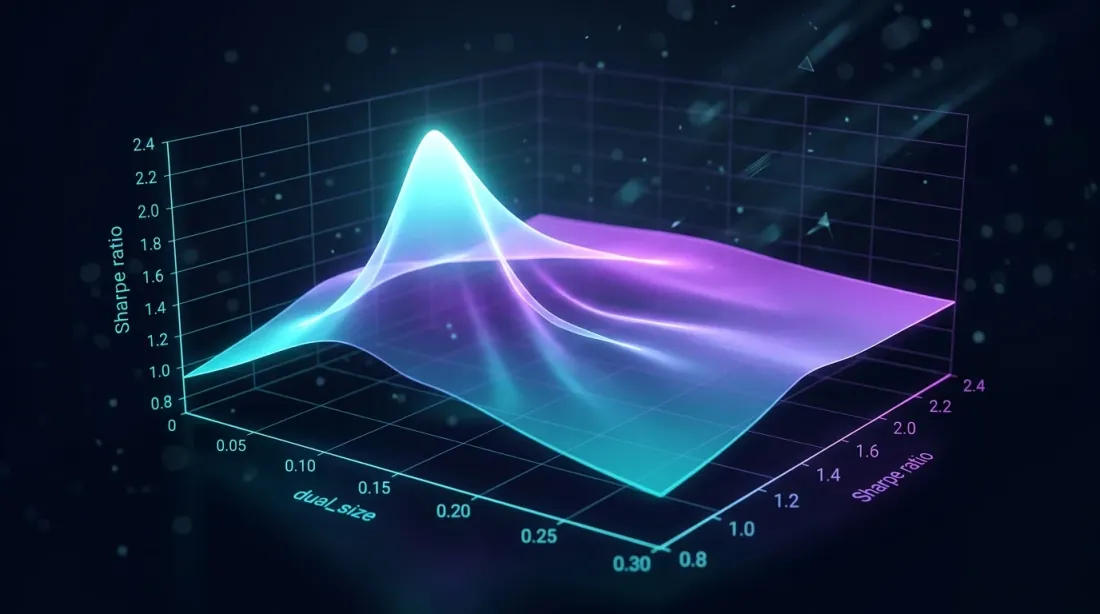 Grid search บน dual_size เผยให้เห็นจุดสูงสุดของ Sharpe ratio — ใหญ่เกินไปเพิ่ม drawdown, เล็กเกินไปสูญเสียเวลาว่าง
Grid search บน dual_size เผยให้เห็นจุดสูงสุดของ Sharpe ratio — ใหญ่เกินไปเพิ่ม drawdown, เล็กเกินไปสูญเสียเวลาว่าง
ปัญหาการเลือก
dual_size คือเศษส่วนของโพซิชันเต็มจำนวนที่กลยุทธ์ fallback ได้รับ เป็นพารามิเตอร์ cascade หลัก:
-
ใหญ่เกินไป (เช่น 0.5 = 50%): เมื่อ primary และ fallback ทำงานพร้อมกัน, exposure รวม = 150% ของเป้าหมาย Drawdown เพิ่มเป็นสองเท่า Loss-profit asymmetry ทำให้ค่าใช้จ่ายนี้สูงไม่สมสัดส่วน
-
เล็กเกินไป (เช่น 0.01 = 1%): fallback เติม 85% ของเวลาว่าง แต่ได้กำไรเพียงน้อยนิด ทุนนอนเฉยอยู่จริง ๆ
-
เหมาะสม: fallback สร้าง PnL ที่มีความหมายโดยไม่เพิ่ม drawdown อย่างวิกฤตในระหว่างการทำงานพร้อมกับ primary
การกำหนดสูตร
ให้:
- — PnL ของ primary ต่อหน่วยเวลา
- — PnL ของ fallback ต่อหน่วยเวลา
- — สัดส่วนเวลาในโพซิชัน (primary)
- — สัดส่วนเวลาในโพซิชัน (fallback)
- — dual_size (0..1)
- — สัดส่วนเวลาที่ทั้งสองอยู่ในโพซิชัน
PnL cascade รวม:
MaxDD รวม (กรณีเลวร้ายที่สุด — ความสัมพันธ์เต็มที่):
หากเราจำกัด drawdown รวมไว้ที่ :
Grid Search
ในทางปฏิบัติ dual_size ที่เหมาะสมจะพบได้ผ่าน grid search บน cascade backtest:
import numpy as np
from dataclasses import dataclass
@dataclass
class CascadeResult:
dual_size: float
total_pnl: float
max_dd: float
sharpe: float
pnl_per_active_day: float
def grid_search_dual_size(
primary_equity: np.ndarray, # equity curve primary (minute bars)
fallback_equity: np.ndarray, # equity curve fallback (minute bars)
primary_positions: np.ndarray, # 1 = in position, 0 = flat
fallback_positions: np.ndarray,
grid: np.ndarray = np.arange(0.01, 0.30, 0.005),
) -> list[CascadeResult]:
"""
Grid search for dual_size.
primary_equity and fallback_equity are log-returns, minute bars.
"""
results = []
for d in grid:
fallback_active = fallback_positions & ~primary_positions
cascade_returns = (
primary_equity * primary_positions
+ d * fallback_equity * fallback_active
)
equity_curve = np.cumprod(1 + cascade_returns)
peak = np.maximum.accumulate(equity_curve)
drawdown = (equity_curve - peak) / peak
max_dd = drawdown.min()
total_pnl = equity_curve[-1] - 1
sharpe = (
np.mean(cascade_returns) / np.std(cascade_returns)
* np.sqrt(525_600) # minutes per year
) if np.std(cascade_returns) > 0 else 0
active_minutes = np.sum(primary_positions | fallback_active)
active_days = active_minutes / (24 * 60)
pnl_per_day = total_pnl / active_days if active_days > 0 else 0
results.append(CascadeResult(
dual_size=d,
total_pnl=total_pnl,
max_dd=max_dd,
sharpe=sharpe,
pnl_per_active_day=pnl_per_day,
))
return sorted(results, key=lambda r: r.sharpe, reverse=True)
ค่าที่เหมาะสมทั่วไปสำหรับกลยุทธ์ crypto: dual_size ในช่วง 0.05-0.10 (5-10% ของโพซิชันเต็ม) กับ Strategy B เป็น primary (MaxDD 0.75%) และ Strategy A เป็น fallback (MaxDD 0.9%):
ข้อจำกัด drawdown ไม่มีผลผูกพัน — ค่าที่เหมาะสมถูกกำหนดโดย cascade Sharpe ในทางปฏิบัติ grid search มักให้ค่า (6.8%)
การจัดสรรตาม Score
 กลยุทธ์จัดอันดับตาม composite score — การปรับ confidence ลงโทษตัวอย่างขนาดเล็ก, ค่าใช้จ่าย funding ลด edge สุทธิ
กลยุทธ์จัดอันดับตาม composite score — การปรับ confidence ลงโทษตัวอย่างขนาดเล็ก, ค่าใช้จ่าย funding ลด edge สุทธิ
เมื่อมีกลยุทธ์มากกว่าสองตัว cascade จะขยายไปสู่การจัดสรรตาม score
การจัดอันดับตาม PnL per Active Time
ดังที่อธิบายโดยละเอียดใน PnL per Active Time score ของกลยุทธ์คำนวณโดยคำนึงถึง:
- PnL per active day — ประสิทธิภาพการใช้ทุน
- Confidence adjustment — บทลงโทษสำหรับตัวอย่างขนาดเล็ก (t-distribution)
- Funding costs — ค่าใช้จ่ายจริงของ leverage (Funding rates)
- MaxLev — การปรับขนาดโดยคำนึงถึง drawdown (Loss-profit asymmetry)
Confidence Adjustment สำหรับกลยุทธ์หายาก
Strategy B ที่มี 40 เทรดต้องการการลงโทษที่ร้ายแรง เราใช้ขอบล่างของช่วงความเชื่อมั่น:
import scipy.stats as st
import numpy as np
def confidence_factor(trade_returns: np.ndarray, confidence: float = 0.95) -> float:
"""Confidence factor: 0..1, penalty for small samples."""
n = len(trade_returns)
if n < 10:
return 0.0
mean_r = np.mean(trade_returns)
if mean_r <= 0:
return 0.0
se = np.std(trade_returns, ddof=1) / np.sqrt(n)
t_crit = st.t.ppf(1 - (1 - confidence) / 2, df=n - 1)
ci_lower = mean_r - t_crit * se
return max(0.0, ci_lower / mean_r)
cf_b = confidence_factor(np.random.normal(0.0067, 0.028, 40))
cf_a = confidence_factor(np.random.normal(0.0011, 0.008, 500))
การผนวก Funding Cost
บน perpetual futures การชำระ funding จะเกิดทุก 8 ชั่วโมง ด้วย leverage และ average rate :
สำหรับ Strategy A ที่มี MaxLev = 55x และ average funding rate 0.01%:
กับ PnL/active day = 0.49%, PnL สุทธิ ติดลบ: /วัน กลยุทธ์ไม่ทำกำไรที่ leverage เต็ม การวิเคราะห์โดยละเอียดใน Funding Rates Kill Your Leverage
Multi-Strategy Orchestrator
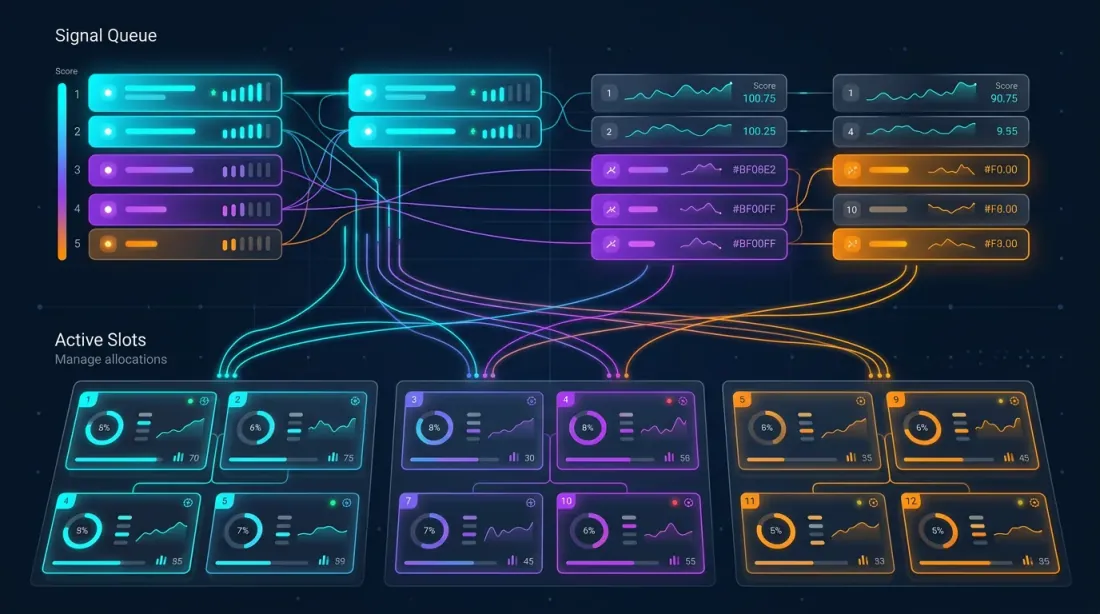
สถาปัตยกรรม
orchestrator จัดการ กลยุทธ์บน คู่เทรด จำนวนรวมของโพซิชันที่เป็นไปได้: แต่ทุนมีจำกัด — อนุญาตไม่เกิน โพซิชันพร้อมกัน (slots)
┌─────────────────────────────────────────────┐
│ ORCHESTRATOR │
│ │
│ Signal Queue (sorted by score): │
│ ┌──────────────────────────────────────┐ │
│ │ 1. Strategy C × ETHUSDT score=223 │ │
│ │ 2. Strategy B × BTCUSDT score=142 │ │
│ │ 3. Strategy A × SOLUSDT score=100 │ │
│ │ 4. Strategy C × BTCUSDT score=89 │ │
│ │ 5. Strategy A × ETHUSDT score=76 │ │
│ └──────────────────────────────────────┘ │
│ │
│ Active Slots (max_parallel = 3): │
│ ┌──────────────────────────────────────┐ │
│ │ Slot 1: Strategy C × ETHUSDT [FULL] │ │
│ │ Slot 2: Strategy B × BTCUSDT [FULL] │ │
│ │ Slot 3: Strategy A × SOLUSDT [DUAL] │ │
│ └──────────────────────────────────────┘ │
│ │
│ Conflict Rules: │
│ - One position per pair │
│ - Primary displaces fallback on same pair │
│ - Higher score wins for cross-pair slots │
└─────────────────────────────────────────────┘
การจัดการ Slot
from dataclasses import dataclass, field
from enum import Enum
from typing import Optional
import heapq
import time
class SlotType(Enum):
FULL = "full" # primary strategy, 100% position
DUAL = "dual" # fallback strategy, dual_size position
@dataclass
class Signal:
strategy_id: str
pair: str
direction: str # "long" | "short"
score: float
is_primary: bool # primary or fallback
timestamp: float
@dataclass(order=True)
class Slot:
"""A single orchestrator slot."""
priority: float = field(compare=True) # negative score for min-heap
strategy_id: str = field(compare=False)
pair: str = field(compare=False)
slot_type: SlotType = field(compare=False)
entry_time: float = field(compare=False)
class Orchestrator:
"""
Multi-strategy orchestrator with cascade mode.
Manages N strategies x M pairs within max_parallel_positions slots.
Primary strategies have unconditional priority over fallback.
"""
def __init__(
self,
max_parallel_positions: int = 10,
dual_size: float = 0.068,
min_score: float = 0,
):
self.max_parallel = max_parallel_positions
self.dual_size = dual_size
self.min_score = min_score
self.active_slots: dict[str, Slot] = {} # pair -> Slot
self.pending_signals: list[Signal] = []
def on_signal(self, signal: Signal) -> Optional[dict]:
"""
Process a new signal. Returns an action or None.
Actions:
- {"action": "open", "pair": ..., "size": ..., "slot_type": ...}
- {"action": "replace", "pair": ..., "close_strategy": ..., "open_strategy": ...}
- None (signal rejected)
"""
if signal.score < self.min_score:
return None
pair = signal.pair
if pair in self.active_slots:
existing = self.active_slots[pair]
if signal.is_primary and existing.slot_type == SlotType.DUAL:
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=SlotType.FULL,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": 1.0,
}
if signal.score > -existing.priority:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # existing has higher priority
if len(self.active_slots) < self.max_parallel:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "open",
"pair": pair,
"strategy": signal.strategy_id,
"size": size,
"slot_type": slot_type,
}
worst_pair = min(
self.active_slots,
key=lambda p: -self.active_slots[p].priority,
)
worst_slot = self.active_slots[worst_pair]
if signal.score > -worst_slot.priority:
del self.active_slots[worst_pair]
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": worst_slot.strategy_id,
"close_pair": worst_pair,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # all active slots have higher scores
def on_exit(self, pair: str) -> None:
"""Strategy closed a position."""
if pair in self.active_slots:
del self.active_slots[pair]
def utilization(self) -> float:
"""Current slot utilization."""
return len(self.active_slots) / self.max_parallel
def fill_efficiency_snapshot(self) -> float:
"""Weighted utilization: FULL=1.0, DUAL=dual_size."""
total = sum(
1.0 if s.slot_type == SlotType.FULL else self.dual_size
for s in self.active_slots.values()
)
return total / self.max_parallel
การแก้ไขความขัดแย้ง
ความขัดแย้งสามระดับ:
ระดับ 1 — คู่เดียวกัน, ทิศทางเดียวกัน กลยุทธ์ที่มี score สูงกว่าชนะ หากทั้งสองเป็น primary — score เป็นตัวตัดสิน หากหนึ่งเป็น primary และอีกหนึ่งเป็น fallback — primary ชนะโดยไม่มีเงื่อนไข
ระดับ 2 — คู่เดียวกัน, ทิศทางตรงกันข้าม ห้าม: คุณไม่สามารถ long และ short บนคู่เดียวกันพร้อมกัน กลยุทธ์ที่มี score สูงสุดชนะ
ระดับ 3 — การแข่งขันข้ามคู่ เมื่อ slot ทั้งหมดถูกครอบครอง สัญญาณใหม่จะขับไล่ slot ที่มี score ต่ำสุดออก ทำงานเป็น priority queue
Cascade Backtesting: ระเบียบวิธี
 การจำลองร่วม: equity curves ของ primary และ fallback พร้อมโซน overlap และผลลัพธ์ cascade รวม
การจำลองร่วม: equity curves ของ primary และ fallback พร้อมโซน overlap และผลลัพธ์ cascade รวม
เหตุใดคุณจึงไม่สามารถรวม PnL เพียงอย่างเดียว
แนวทางง่าย ๆ: backtest แต่ละกลยุทธ์แยกกัน แล้วรวม PnL ผลลัพธ์ที่ได้คือ ตัวเลขที่สูงเกินจริง ด้วยเหตุผลสามประการ:
-
การซ้อนทับของเวลา เมื่อ primary และ fallback ทำงานพร้อมกัน fallback ไม่ควรเทรด (หรือเทรดที่ dual_size) การรวมแบบง่ายละเว้นการซ้อนทับนี้
-
ข้อจำกัดทุน โพซิชันรวมมีจำกัด หาก 5 กลยุทธ์ต้องการเปิดพร้อมกันแต่มีเพียง 3 slots — สองกลยุทธ์จะไม่เข้า PnL ของพวกมันไม่สามารถนับได้
-
ค่าธรรมเนียมการทำธุรกรรม การสลับ cascade (ปิด fallback, เปิด primary) สร้างค่าคอมมิชชั่นเพิ่มเติมที่ไม่มีอยู่ใน backtest แต่ละตัว
การจำลองร่วม
cascade backtest ที่ถูกต้องคือ การจำลองร่วม ของกลยุทธ์ทั้งหมดบน timeline ที่ใช้ร่วมกัน:
import numpy as np
from typing import NamedTuple
class Trade(NamedTuple):
strategy: str
pair: str
entry_time: int # minute index
exit_time: int # minute index
pnl_per_minute: float # log-return per minute
is_primary: bool
score: float
def backtest_cascade(
all_trades: list[Trade],
total_minutes: int,
max_slots: int = 10,
dual_size: float = 0.068,
switch_cost: float = 0.0006, # 0.06% round-trip
) -> dict:
"""
Joint simulation of cascade portfolio.
Walk through each minute, apply orchestrator rules,
calculate PnL accounting for overlap and slot constraints.
"""
entries = {}
exits = {}
active_trades = {} # trade_id -> Trade
for i, trade in enumerate(all_trades):
entries.setdefault(trade.entry_time, []).append((i, trade))
exits.setdefault(trade.exit_time, []).append((i, trade))
active_slots = {} # pair -> (trade_id, SlotType)
equity = np.ones(total_minutes)
switch_costs_total = 0.0
for t in range(1, total_minutes):
for trade_id, trade in exits.get(t, []):
if trade.pair in active_slots:
slot_id, _ = active_slots[trade.pair]
if slot_id == trade_id:
del active_slots[trade.pair]
new_signals = sorted(
entries.get(t, []),
key=lambda x: x[1].score,
reverse=True,
)
for trade_id, trade in new_signals:
pair = trade.pair
if pair in active_slots:
existing_id, existing_type = active_slots[pair]
existing_trade = all_trades[existing_id]
if trade.is_primary and existing_type == SlotType.DUAL:
active_slots[pair] = (trade_id, SlotType.FULL)
switch_costs_total += switch_cost
continue
if trade.score > existing_trade.score:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
switch_costs_total += switch_cost
elif len(active_slots) < max_slots:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
minute_return = 0.0
for pair, (trade_id, slot_type) in active_slots.items():
trade = all_trades[trade_id]
size = 1.0 if slot_type == SlotType.FULL else dual_size
minute_return += trade.pnl_per_minute * size
equity[t] = equity[t - 1] * (1 + minute_return)
peak = np.maximum.accumulate(equity)
max_dd = ((equity - peak) / peak).min()
total_pnl = equity[-1] - 1 - switch_costs_total
return {
"total_pnl": total_pnl,
"max_dd": max_dd,
"switch_costs": switch_costs_total,
"equity_curve": equity,
}
ค่าธรรมเนียมการทำธุรกรรมเมื่อสลับ
การสลับ cascade แต่ละครั้ง (fallback -> primary) ต้องการ:
- ปิดโพซิชัน fallback: taker fee (0.04% บน Binance futures)
- เปิดโพซิชัน primary: taker fee (0.04%)
- Spread: ~0.01-0.02%
ค่าใช้จ่ายการสลับรวม: ~0.06-0.10% ต่อครั้ง ด้วย 100 ครั้งในช่วงเวลานั้น:
นี่คือจำนวนที่มีนัยสำคัญ cascade ที่มีการสลับบ่อยอาจทำผลงานต่ำกว่ากลยุทธ์เดียวเนื่องจากค่าธรรมเนียมการทำธุรกรรม
การขยาย Multi-Pair: N กลยุทธ์บน M คู่
 เครือข่ายของ N กลยุทธ์ที่เชื่อมต่อกับ M คู่เทรด — ความแข็งแกร่งของความสัมพันธ์กำหนดการกระจายความเสี่ยงที่มีประสิทธิภาพ
เครือข่ายของ N กลยุทธ์ที่เชื่อมต่อกับ M คู่เทรด — ความแข็งแกร่งของความสัมพันธ์กำหนดการกระจายความเสี่ยงที่มีประสิทธิภาพ
พื้นที่การรวม
3 กลยุทธ์บน 10 คู่ = 30 สัญญาณที่เป็นไปได้ ด้วย max_slots = 5, orchestrator เลือก 5 อันดับสูงสุดตาม score นี่คือปัญหาเชิงการรวม: พอร์ตโฟลิโอที่เป็นไปได้ในแต่ละช่วงเวลา
ในทางปฏิบัติ greedy algorithm (เรียงตาม score, เติมจากบนลงล่าง) ให้ผลลัพธ์ใกล้เคียงกับค่าที่เหมาะสมใน
ความสัมพันธ์ระหว่างคู่
คู่ crypto มีความสัมพันธ์กันอย่างแน่นหนา BTC ลด — ETH, SOL, AVAX ลดพร้อมกัน หมายความว่า 5 โพซิชัน long บน 5 คู่ที่แตกต่างกันคือโพซิชันขนาดใหญ่หนึ่งตัวบน "ตลาด crypto" จริง ๆ
ดังที่เราวิเคราะห์โดยละเอียดใน Signal Correlation จำนวนโพซิชันอิสระที่มีประสิทธิภาพ:
โดยที่ คือค่าเฉลี่ยความสัมพันธ์ระหว่างคู่
กับ และ :
ห้าโพซิชันบนคู่ที่มีความสัมพันธ์กันเทียบเท่ากับ 1.3 โพซิชันอิสระ การกระจายความเสี่ยงแทบไม่มีอยู่
ผลกระทบในทางปฏิบัติต่อ Cascade
def effective_diversification(
positions: list[dict], # [{"pair": "BTCUSDT", "direction": "long"}, ...]
correlation_matrix: np.ndarray,
pair_index: dict[str, int],
) -> float:
"""
Calculate effective diversification of open positions.
Returns:
N_eff / N — diversification coefficient (0..1)
"""
n = len(positions)
if n <= 1:
return 1.0
total_corr = 0.0
pairs_count = 0
for i in range(n):
for j in range(i + 1, n):
idx_i = pair_index[positions[i]["pair"]]
idx_j = pair_index[positions[j]["pair"]]
rho = correlation_matrix[idx_i, idx_j]
if positions[i]["direction"] != positions[j]["direction"]:
rho = -rho
total_corr += rho
pairs_count += 1
avg_rho = total_corr / pairs_count if pairs_count > 0 else 0
n_eff = n / (1 + (n - 1) * max(0, avg_rho))
return n_eff / n
orchestrator ควรคำนึงถึงความสัมพันธ์เมื่อเติม slot สองตัวเลือก:
- Diversification bonus: เมื่อจัดอันดับ ให้เพิ่ม bonus ต่อ score ของกลยุทธ์บนคู่ที่ไม่มีความสัมพันธ์
- Correlation cap: จำกัดจำนวนโพซิชัน same-direction บนคู่ที่มีความสัมพันธ์กัน
Cascade Optimization Pipeline
 แปดขั้นตอนที่เชื่อมต่อกันตั้งแต่การเตรียมข้อมูลผ่านการตรวจสอบถึง live orchestration — แต่ละขั้นสร้างบนขั้นก่อนหน้า
แปดขั้นตอนที่เชื่อมต่อกันตั้งแต่การเตรียมข้อมูลผ่านการตรวจสอบถึง live orchestration — แต่ละขั้นสร้างบนขั้นก่อนหน้า
pipeline ทั้งหมดจากข้อมูลสู่การผลิตประกอบด้วย 8 ขั้นตอน:
ขั้นตอนที่ 0: การเตรียมข้อมูล
โหลดข้อมูลประวัติ, สร้าง Parquet cache สำหรับการเข้าถึงแบบ multi-timeframe หากไม่มี caching ที่มีประสิทธิภาพ ขั้นตอนต่อไปจะช้าเกินที่จะยอมรับได้
ขั้นตอนที่ 1: TF + Length (Hill-Climbing Grid)
เลือก base timeframe และความยาว indicator window Grid หยาบ: TF จาก {1m, 5m, 15m, 1h, 4h}, Length จาก {10, 20, 50, 100, 200} Hill-climbing จากจุด grid ที่ดีที่สุด
ขั้นตอนที่ 2: Separation (Coordinate Descent, 12 พารามิเตอร์)
ปรับแต่งพารามิเตอร์การแยก (entries/exits) Coordinate descent บน 12 พารามิเตอร์ — เกณฑ์ indicator, ตัวกรอง, stop-losses, take-profits Coordinate descent ถูกกว่า Optuna สำหรับฟังก์ชันเป้าหมายเชิงกำหนดที่มีมิติสูง
ขั้นตอนที่ 3: Meta-Parameters (Coordinate Descent)
Meta-parameters: เวลาถือสูงสุด, PnL ขั้นต่ำสำหรับการออก, การตั้งค่า trailing stop Coordinate descent อีกครั้ง ตรวจสอบความแข็งแกร่งผ่าน plateau analysis — หากค่าที่เหมาะสมเป็นแบบ point-like กลยุทธ์ถูก over-optimized
ขั้นตอนที่ 4: Combo Optimization
Grid search บนคู่ (Primary, Fallback) สำหรับแต่ละการรวม: เลือก dual_size, คำนวณ cascade PnL ผ่านการจำลองร่วม
ขั้นตอนที่ 5: Validation
Multi-level validation:
- Multi-symbol: กลยุทธ์ทดสอบบน 10+ คู่ ไม่ใช่แค่คู่ที่ optimize
- Walk-forward: หน้าต่าง IS/OOS แบบเลื่อน
- ความเสถียรของพารามิเตอร์: plateau analysis ในแต่ละขั้นตอน
- Monte Carlo bootstrap: ช่วงความเชื่อมั่นสำหรับ cascade PnL
- Backtest-live parity: การเปรียบเทียบ backtest กับ paper trading
ขั้นตอนที่ 6: การจัดอันดับและการเลือก
จัดอันดับการรวม cascade ตาม score Top-K การรวมก้าวหน้าสู่ขั้นตอนที่ 7 Score คำนึงถึง confidence adjustment, ค่าใช้จ่าย funding, และ fill_efficiency
ขั้นตอนที่ 7: Orchestration
ขั้นตอนสุดท้าย: เปิดตัว orchestrator บน กลยุทธ์และ คู่ใน cascade mode การจัดการ slot, priority queue, การแก้ไขความขัดแย้ง — ทั้งหมดที่อธิบายไว้ข้างต้น
การวิเคราะห์ประสิทธิภาพ: Cascade เทียบกับตัวเดียว
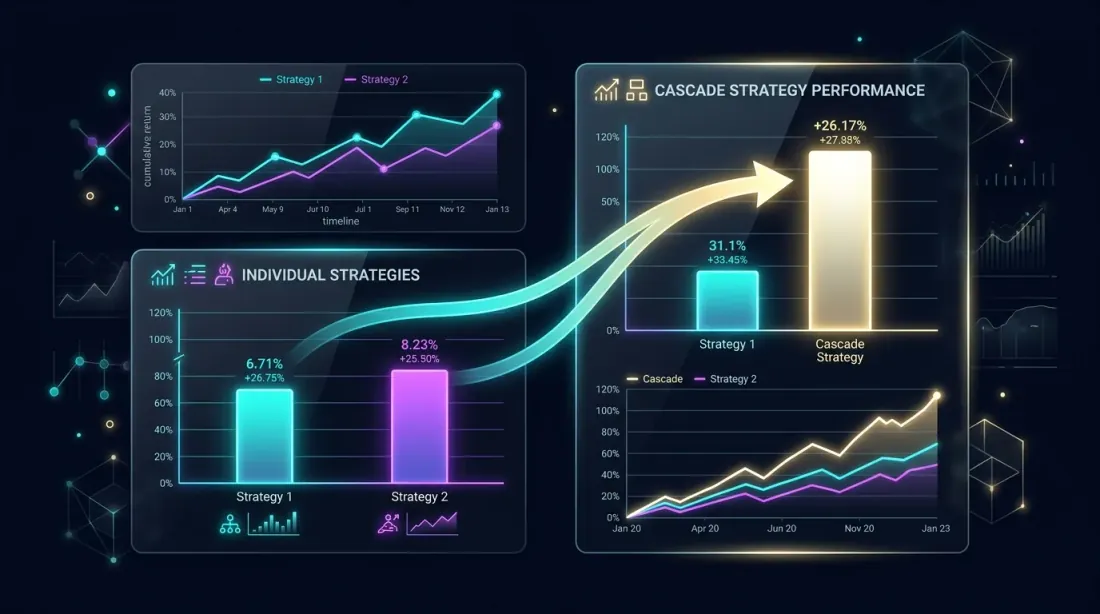 การเปรียบเทียบแบบ side-by-side: cascade portfolio มีผลงานดีกว่ากลยุทธ์เดียวผ่านการใช้ประโยชน์จากเวลาว่าง
การเปรียบเทียบแบบ side-by-side: cascade portfolio มีผลงานดีกว่ากลยุทธ์เดียวผ่านการใช้ประโยชน์จากเวลาว่าง
ข้อได้เปรียบ Cascade ทางทฤษฎี
สมมติว่า primary เทรด ของเวลาด้วย PnL/day = 0.49% Fallback เทรด ด้วย PnL/day = 0.89% Overlap = (สมมติว่าเป็นอิสระ)
Primary เพียงอย่างเดียว (Strategy A):
Cascade (A primary + C fallback):
ผลกำไร cascade: +31% ต่อ PnL จาก fallback พร้อมการเพิ่ม drawdown น้อยที่สุด ( เพิ่มต่อ MaxDD)
เมื่อ Cascade ไม่ช่วย
Cascade ไม่มีประสิทธิภาพเมื่อ:
- Primary ทำงาน >80% ของเวลา เวลาว่างน้อย — fallback ไม่มีที่ให้เข้า
- กลยุทธ์มีความสัมพันธ์สูง Primary และ fallback สร้างสัญญาณพร้อมกัน — overlap สูง และ fallback ว่างพอดีเมื่อ primary ก็ว่างด้วย
- ค่าใช้จ่ายการสลับเกิน PnL ของ fallback ด้วยการสลับบ่อย ค่าคอมมิชชั่น cascade กินกำไร fallback
- dual_size เล็กเกินไป ที่ , fallback ทำได้ 1% ของศักยภาพ — ต่ำกว่าค่าคอมมิชชั่น
ตารางเปรียบเทียบ
| การตั้งค่า | Annual PnL | MaxDD | Sharpe | Switch costs |
|---|---|---|---|---|
| Strategy A เพียงอย่างเดียว | 26.8% | 0.9% | 1.42 | 0 |
| Strategy C เพียงอย่างเดียว | 146.1% | 17% | 1.15 | 0 |
| Cascade A+C (d=0.068) | 35.2% | 2.06% | 1.58 | ~1.2% |
| Cascade B+A (d=0.068) | 19.4% | 1.36% | 1.71 | ~0.3% |
| 3-strategy orchestrator | 48.7% | 3.1% | 1.63 | ~2.1% |
Cascade A+C: primary A ได้รับ +8.4% จาก fallback C Sharpe เพิ่มขึ้นผ่านการใช้ประโยชน์จากเวลาว่าง MaxDD เพิ่มขึ้นปานกลาง ()
Orchestration: fill_efficiency ในทางปฏิบัติ
 Fill efficiency ~78%: heatmap แสดงการใช้เวลาในกลยุทธ์และคู่ต่าง ๆ เซลล์สว่างบ่งบอกถึงการเทรดที่ใช้งานอยู่
Fill efficiency ~78%: heatmap แสดงการใช้เวลาในกลยุทธ์และคู่ต่าง ๆ เซลล์สว่างบ่งบอกถึงการเทรดที่ใช้งานอยู่
พารามิเตอร์ fill_efficiency กำหนดว่า orchestrator ใช้ประโยชน์จากเวลาว่างได้จริงเท่าใด ดังที่แสดงใน PnL per Active Time สามารถประเมินได้สามวิธี:
- ค่าคงที่คงที่ (0.80) — หยาบแต่ใช้ได้ทั่วไป
- การประมาณค่าเชิงวิเคราะห์ ผ่าน — คำนึงถึงความสัมพันธ์
- การจำลอง จากข้อมูล — แม่นยำที่สุด
สำหรับ cascade ที่มี 3 กลยุทธ์บน 10 คู่:
def cascade_fill_efficiency(
strategies: list[dict], # [{"trading_time": 0.15, "is_primary": True}, ...]
n_pairs: int = 10,
correlation_factor: float = 3.0,
) -> float:
"""Estimate fill_efficiency for a cascade portfolio."""
n_eff = n_pairs / correlation_factor
primary_times = [s["trading_time"] for s in strategies if s["is_primary"]]
p_primary = 1 - np.prod([(1 - t) ** n_eff for t in primary_times])
fallback_times = [s["trading_time"] for s in strategies if not s["is_primary"]]
p_fallback = 1 - np.prod([(1 - t) ** n_eff for t in fallback_times])
fill = p_primary + (1 - p_primary) * p_fallback
return min(fill, 1.0)
strategies = [
{"trading_time": 0.05, "is_primary": True}, # Strategy B
{"trading_time": 0.15, "is_primary": True}, # Strategy A
{"trading_time": 0.45, "is_primary": False}, # Strategy C as fallback
]
eff = cascade_fill_efficiency(strategies, n_pairs=10, correlation_factor=3.0)
คำแนะนำในทางปฏิบัติ
 คำแนะนำหลัก 6 ข้อสำหรับการ deploy cascade — ตั้งแต่เริ่มเล็กไปถึงการปรับเทียบแบบ adaptive
คำแนะนำหลัก 6 ข้อสำหรับการ deploy cascade — ตั้งแต่เริ่มเล็กไปถึงการปรับเทียบแบบ adaptive
1. เริ่มด้วยสองกลยุทธ์
อย่าเปิด 10 กลยุทธ์บน 20 คู่ทันที เริ่มด้วย primary หนึ่งตัว + fallback หนึ่งตัวบน 3-5 คู่ ตรวจสอบให้แน่ใจว่าการจำลองร่วมตรงกับพฤติกรรมจริง Backtest-live parity มีความสำคัญอย่างยิ่ง: หาก cascade backtest แตกต่างจาก live แม้ 5-10% — มีข้อผิดพลาดใน orchestrator logic
2. dual_size จาก Grid Search ไม่ใช่จากสัญชาตญาณ
dual_size ที่เหมาะสมขึ้นอยู่กับคู่กลยุทธ์ที่เฉพาะเจาะจง 6.8% เป็นแนวทาง ไม่ใช่ค่าคงที่สากล รัน grid search จาก 1% ถึง 30% ด้วยขั้น 0.5% และเลือกค่าสูงสุดของ Sharpe
3. Slot Limit กำหนดสถาปัตยกรรม
กับ max_slots = 1, cascade เสื่อมถอยเป็นการสลับกลยุทธ์แบบง่าย กับ max_slots = 50, ข้อจำกัดไม่มีผลผูกพันและปัญหาลดลงเป็นพอร์ตโฟลิโออิสระ โซนที่น่าสนใจ: max_slots = 3-10 ที่การจัดการ slot ส่งผลต่อผลลัพธ์อย่างแท้จริง
4. คำนึงถึง Latency
ใน live trading การสลับ cascade ไม่ใช่แบบทันที การปิดโพซิชัน fallback + เปิด primary = 2 API calls + network latency + exchange matching บนตลาดที่ผันผวน ราคาสามารถเคลื่อนที่ใน 200-500ms สร้างงบประมาณ slippage ไว้ด้วย
5. ติดตาม fill_efficiency
ติดตาม fill_efficiency จริงใน production หากมันต่ำกว่า backtest อย่างมีนัยสำคัญ — orchestrator ไม่ได้ใช้ประโยชน์จากเวลาว่างตามที่คาดไว้ สาเหตุ: ความล่าช้าของ API, คำสั่งที่ถูกปฏิเสธ, ข้อจำกัด margin
6. ใช้ Adaptive Optimization
พารามิเตอร์ cascade (dual_size, score weights, slot limits) ไม่ควรคงที่ ใช้ adaptive drill-down สำหรับการปรับเทียบเป็นระยะบนข้อมูลใหม่ ตลาดเปลี่ยน — พารามิเตอร์ cascade ควรตามไปด้วย
ซีรีส์ "Backtests Without Illusions": สรุป
 สถาปัตยกรรมระบบสมบูรณ์: 13 โมดูลที่เชื่อมต่อกันตั้งแต่คณิตศาสตร์ผ่านการตรวจสอบถึง live orchestration
สถาปัตยกรรมระบบสมบูรณ์: 13 โมดูลที่เชื่อมต่อกันตั้งแต่คณิตศาสตร์ผ่านการตรวจสอบถึง live orchestration
บทความนี้เป็นบทสรุปของซีรีส์ 13+ บทความ แต่ละบทความแก้ไขปัญหาเฉพาะหนึ่งอย่างบนเส้นทางจาก backtest สู่การผลิต นี่คือวิธีที่พวกมันเชื่อมต่อกัน:
รากฐาน: คณิตศาสตร์ของผลตอบแทน
Loss-Profit Asymmetry — ธรรมชาติเชิงคูณของผลตอบแทน, volatility drag, Kelly criterion นี่คือรากฐานทางคณิตศาสตร์สำหรับทุกสิ่งที่ตามมา: เหตุใด MaxDD จึงกำหนด leverage, เหตุใด Sharpe สำคัญกว่า PnL ดิบ, เหตุใดอัตราชนะ 50% พร้อม symmetric R:R จึงไม่ทำกำไร
Validation: ช่วงความเชื่อมั่นและความแข็งแกร่ง
Monte Carlo Bootstrap — การเปลี่ยนการประมาณค่าเดียวเป็น distribution พร้อมช่วงความเชื่อมั่น เมตริกใด ๆ (PnL, MaxDD, Sharpe) มีความหมายเฉพาะเมื่อมีช่วงความเชื่อมั่น
Walk-Forward Optimization — out-of-sample validation Backtest บนข้อมูลประวัติคือผล IS; WFO แสดงว่ากลยุทธ์ทำงานอย่างไรบนข้อมูลใหม่
Plateau Analysis — การตรวจสอบความแข็งแกร่งของพารามิเตอร์ หากค่าที่เหมาะสมเป็นแบบ point-like กลยุทธ์ถูก over-optimized
Backtest-Live Parity — การเปรียบเทียบ backtest กับผลลัพธ์จริง การตรวจสอบขั้นสุดท้ายก่อนการขยาย
ค่าใช้จ่ายจริง: Funding และ Leverage
Funding Rates Kill Leverage — ค่าใช้จ่ายซ่อนเร้นของ leverage บน perpetual futures หากไม่คำนึงถึง funding backtest ที่สวยงามจะกลายเป็นการขาดทุน
Funding Rate Arbitrage — วิธีเปลี่ยน funding จากค่าใช้จ่ายเป็นแหล่งรายได้ผ่านกลยุทธ์ cross-exchange
เมตริกและการจัดอันดับ
PnL per Active Time — เมตริกสำหรับการจัดอันดับกลยุทธ์ในพอร์ตโฟลิโอ PnL ดิบไม่ scale; PnL/active day scale ได้
Signal Correlation — การกระจายความเสี่ยงที่มีประสิทธิภาพในพอร์ตโฟลิโอของคู่ที่มีความสัมพันธ์กัน
โครงสร้างพื้นฐานและการ Optimization
Parquet Cache for Multi-Timeframe Backtests — โครงสร้างพื้นฐานข้อมูลสำหรับการทำซ้ำอย่างรวดเร็ว
Adaptive Drill-Down — การ optimization แบบ adaptive: coarse grid -> การปรับจูนในโซนที่มีแนวโน้ม
Optuna vs. Coordinate Descent — การเลือก optimizer: Optuna สำหรับมิติต่ำที่มีเป้าหมายที่มีสัญญาณรบกวน, coordinate descent สำหรับมิติสูงที่มีเป้าหมายที่ราบรื่น
Polars vs Pandas — ประสิทธิภาพการดำเนินการ DataFrame สำหรับ backtesting
Orchestration (บทความนี้)
Cascade Strategies — การรวมส่วนประกอบก่อนหน้าทั้งหมดเป็นระบบที่ใช้งานได้ การจัดสรรตาม score ใช้ PnL/active time, confidence adjustment, ค่าใช้จ่าย funding Cascade mode เติมเวลาว่าง การจำลองร่วมตรวจสอบพอร์ตโฟลิโอ Monte Carlo bootstrap ให้ช่วงความเชื่อมั่นสำหรับ cascade PnL
แต่ละบทความเป็นโมดูลอิสระ ร่วมกันพวกมันสร้าง pipeline สมบูรณ์ตั้งแต่การโหลดข้อมูลถึง live orchestration ของพอร์ตโฟลิโอกลยุทธ์
บทสรุป
Cascade ไม่ใช่แนวทางเดียวสำหรับพอร์ตโฟลิโอกลยุทธ์ แต่เป็นหนึ่งในแนวทางที่ง่ายและใช้งานได้จริงที่สุด: กลยุทธ์ primary เทรดเต็มกำลัง, fallback เติมเวลาว่างที่โพซิชันลดลง พารามิเตอร์หลักสองตัว (dual_size และ max_slots) ให้ความยืดหยุ่นเพียงพอสำหรับการตั้งค่าส่วนใหญ่
สามบทเรียนสำคัญ:
-
Cascade ต้องได้รับการ backtest ผ่านการจำลองร่วมเท่านั้น การรวม PnL แต่ละตัวให้ผลลัพธ์ที่สูงเกินจริง ค่าใช้จ่ายการสลับ, overlap, ข้อจำกัด slot — ทั้งหมดนี้จะได้รับการจับในการจำลองร่วมเท่านั้น
-
dual_size กำหนดการแลกเปลี่ยน PnL กับ drawdown ค่าที่เหมาะสมทั่วไปคือ 5-10% Grid search บน Sharpe เป็นวิธีการเลือกที่เชื่อถือได้
-
orchestrator คือ priority queue ตาม score ทุกอย่างลดลงเป็นตัวเลขเดียว (score) สำหรับแต่ละสัญญาณ Score = f(PnL/active day, MaxLev, confidence, funding) กลยุทธ์ที่มี score สูงสุดได้รับ slots ส่วนที่เหลือรอ
ซีรีส์ "Backtests Without Illusions" แสดงให้เห็นสิ่งหนึ่ง: ระหว่าง backtest ที่สวยงามและกำไรจริงมีหลุมพรางหลายสิบอย่าง แต่ละบทความขจัดหนึ่งอย่าง Cascade orchestration คือขั้นตอนสุดท้าย: การเปลี่ยนชุดกลยุทธ์ที่ผ่านการตรวจสอบแล้วเป็นพอร์ตโฟลิโอที่ใช้งานได้
ลิงก์ที่มีประโยชน์
- López de Prado — Advances in Financial Machine Learning: Portfolio Construction
- Pardo, R. — The Evaluation and Optimization of Trading Strategies
- Ernest Chan — Algorithmic Trading: Winning Strategies and Their Rationale
- Perry Kaufman — Trading Systems and Methods, Chapter on Portfolio Allocation
- Tomasini, Jaekle — Trading Systems: A New Approach to System Development and Portfolio Optimisation
- Bailey, D.H. & López de Prado — The Deflated Sharpe Ratio
- Markowitz, H. — Portfolio Selection (1952)
- Kelly, J.L. — A New Interpretation of Information Rate (1956)
การอ้างอิง
@article{soloviov2026cascadestrategies,
author = {Soloviov, Eugen},
title = {Cascade Strategies: Priority Execution with Fallback Filling},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/cascade-strategies-orchestration},
version = {0.1.0},
description = {Finale of the "Backtests Without Illusions" series. How to build an orchestrator from N strategies x M pairs, implement cascade mode with priority and fallback filling, choose dual\_size, and why strategy portfolios cannot be backtested by summing PnL.}
}
ผู้เขียน

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.