Strategie Cascade: Esecuzione Prioritaria con Riempimento di Fallback

Finale della serie "Backtest Senza Illusioni". Come costruire un orchestratore da N strategie su M coppie, implementare la modalità cascade con esecuzione prioritaria e di fallback, scegliere dual_size e perché i portafogli di strategie non possono essere testati semplicemente sommando il PnL.
Perché Hai Bisogno di un Portafoglio di Strategie
 Più strategie competono per un capitale limitato — la maggior parte rimane inattiva mentre solo poche operano in un dato momento
Più strategie competono per un capitale limitato — la maggior parte rimane inattiva mentre solo poche operano in un dato momento
Hai portato una strategia attraverso l'intera pipeline. Il bootstrap Monte Carlo ha mostrato un quinto percentile accettabile. Il walk-forward ha confermato i rendimenti out-of-sample. I tassi di funding sono stati considerati, l'analisi del plateau è superata. La strategia funziona davvero.
Ma opera il 15% del tempo. Il restante 85% il tuo capitale è inattivo.
Avviare una seconda strategia? Una terza? Una decima? L'idea è ovvia. L'implementazione no. Un portafoglio di strategie crea problemi che non esistono con un singolo bot:
- Conflitti: due strategie vogliono aprire posizioni opposte sulla stessa coppia.
- Vincoli: l'exchange/la gestione del rischio consente non più di posizioni simultanee.
- Allocazione: quale frazione di capitale assegnare a ciascuna strategia?
- Correlazione: 10 strategie su coppie crypto correlate non equivale a una diversificazione 10x.
La strategia cascade è un pattern architetturale che risolve questi problemi: la strategia primaria ottiene la dimensione completa della posizione, mentre la strategia di fallback riempie il tempo inattivo con una posizione ridotta.
Il Concetto di Cascade: Primario + Fallback

Strategia ad Alta Convinzione (Primaria)
La primaria è una strategia con criteri di ingresso rigidi. Ad esempio, multi-timeframe triplo con tre livelli di conferma: segnale su daily + 4 ore + orario, con filtri di volatilità e volume.
Caratteristiche:
- Poche operazioni (decine nel periodo di backtest)
- PnL elevato per operazione
- Basso tempo in posizione (5-15%)
- Alta fiducia in ogni ingresso
Strategia di Fallback
Il fallback è una strategia con criteri meno rigidi. Doppio timeframe, meno filtri, tolleranze più ampie. Opera più frequentemente, ma con un vantaggio inferiore per operazione.
Caratteristiche:
- Più operazioni (centinaia nel periodo)
- PnL moderato per operazione
- Alto tempo in posizione (30-50%)
- Fiducia moderata — compensata da una dimensione di posizione ridotta
Modalità Cascade
timeline: ──────────────────────────────────────────────────
primary: ___████___________________████████____███________
fallback: ███____███████████████████________████___████████
capital: [dual][ full ][ dual_size ][ full ][ dual ]
Quando la primaria apre una posizione — il fallback tace (o chiude). Quando la primaria è inattiva — il fallback opera con una posizione ridotta (dual_size). La priorità è incondizionata: la primaria sostituisce sempre il fallback.
Strategie per gli Esempi
Nel corso della serie abbiamo utilizzato tre strategie. Ecco i loro parametri per il periodo di 750 giorni:
| Parametro | Strategia A | Strategia B | Strategia C |
|---|---|---|---|
| PnL | +55% | +27% | +300% |
| Operazioni | ~500 | ~40 | ~400 |
| Tempo di trading | ~15% | ~5% | ~45% |
| MaxDD | ~0.9% | ~0.75% | ~17% |
| PnL/giorno attivo | 0.49%/g | 0.72%/g | 0.89%/g |
| Carattere | Attività media | Rara, alta convinzione | Frequente, aggressiva |
Come abbiamo mostrato in PnL per Tempo Attivo, la classifica per PnL grezzo e per PnL/giorno attivo produce risultati diversi. Per l'orchestrazione cascade, è la seconda metrica che conta.
dual_size Ottimale
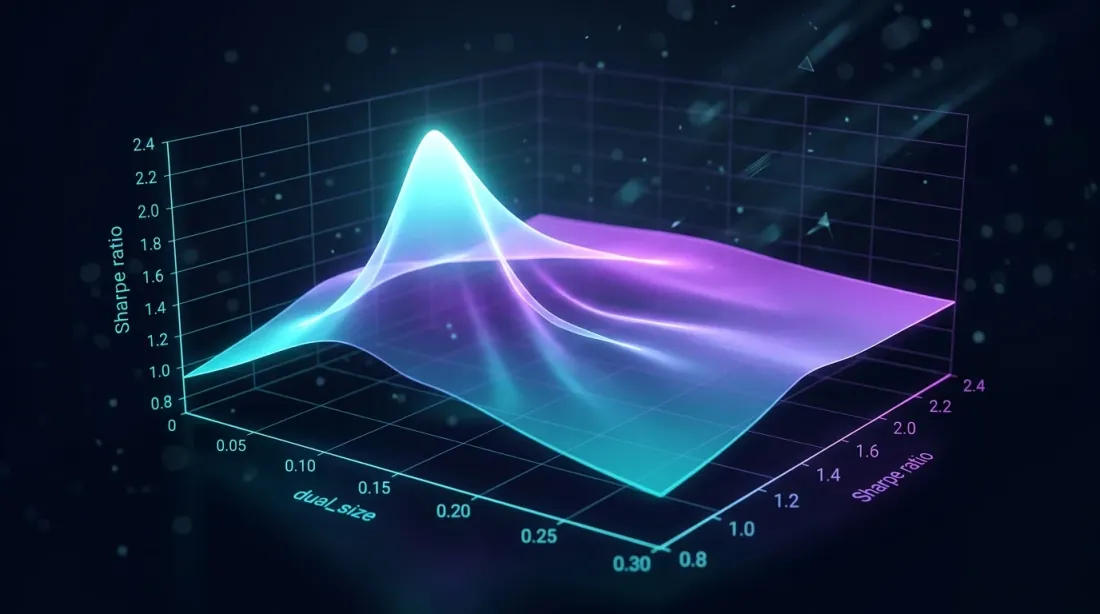 La ricerca a griglia sul dual_size rivela un picco del rapporto di Sharpe — troppo grande aumenta il drawdown, troppo piccolo spreca il tempo inattivo
La ricerca a griglia sul dual_size rivela un picco del rapporto di Sharpe — troppo grande aumenta il drawdown, troppo piccolo spreca il tempo inattivo
Il Problema della Selezione
dual_size è la frazione della posizione completa che la strategia di fallback riceve. È il parametro cascade chiave:
-
Troppo grande (es. 0.5 = 50%): quando primaria e fallback sono attive simultaneamente, l'esposizione totale = 150% dell'obiettivo. Il drawdown raddoppia. L'asimmetria perdita-profitto rende questo sproporzionatamente costoso.
-
Troppo piccolo (es. 0.01 = 1%): il fallback riempie l'85% del tempo inattivo ma guadagna pochissimo. Il capitale rimane effettivamente inattivo.
-
Ottimale: il fallback contribuisce un PnL significativo senza aumentare criticamente il drawdown durante l'operazione simultanea con la primaria.
Formalizzazione
Sia:
- — PnL primario per unità di tempo
- — PnL fallback per unità di tempo
- — frazione di tempo in posizione (primario)
- — frazione di tempo in posizione (fallback)
- — dual_size (0..1)
- — frazione di tempo in cui entrambi sono in posizione
PnL cascade totale:
MaxDD totale (caso peggiore — correlazione completa):
Se vincoliamo il drawdown totale a :
Ricerca a Griglia
In pratica, il dual_size ottimale viene trovato tramite ricerca a griglia sul backtest cascade:
import numpy as np
from dataclasses import dataclass
@dataclass
class CascadeResult:
dual_size: float
total_pnl: float
max_dd: float
sharpe: float
pnl_per_active_day: float
def grid_search_dual_size(
primary_equity: np.ndarray, # equity curve primario (barre al minuto)
fallback_equity: np.ndarray, # equity curve fallback (barre al minuto)
primary_positions: np.ndarray, # 1 = in posizione, 0 = flat
fallback_positions: np.ndarray,
grid: np.ndarray = np.arange(0.01, 0.30, 0.005),
) -> list[CascadeResult]:
"""
Ricerca a griglia per dual_size.
primary_equity e fallback_equity sono log-rendimenti, barre al minuto.
"""
results = []
for d in grid:
fallback_active = fallback_positions & ~primary_positions
cascade_returns = (
primary_equity * primary_positions
+ d * fallback_equity * fallback_active
)
equity_curve = np.cumprod(1 + cascade_returns)
peak = np.maximum.accumulate(equity_curve)
drawdown = (equity_curve - peak) / peak
max_dd = drawdown.min()
total_pnl = equity_curve[-1] - 1
sharpe = (
np.mean(cascade_returns) / np.std(cascade_returns)
* np.sqrt(525_600) # minuti per anno
) if np.std(cascade_returns) > 0 else 0
active_minutes = np.sum(primary_positions | fallback_active)
active_days = active_minutes / (24 * 60)
pnl_per_day = total_pnl / active_days if active_days > 0 else 0
results.append(CascadeResult(
dual_size=d,
total_pnl=total_pnl,
max_dd=max_dd,
sharpe=sharpe,
pnl_per_active_day=pnl_per_day,
))
return sorted(results, key=lambda r: r.sharpe, reverse=True)
L'ottimo tipico per le strategie crypto: dual_size nell'intervallo 0.05-0.10 (5-10% della posizione completa). Con la Strategia B come primaria (MaxDD 0.75%) e la Strategia A come fallback (MaxDD 0.9%):
Il vincolo di drawdown non è vincolante — l'ottimo è determinato dal Sharpe cascade. In pratica, la ricerca a griglia tipicamente produce (6.8%).
Allocazione Basata su Score
 Strategie classificate per score composito — la correzione della fiducia penalizza i campioni piccoli, i costi di funding riducono il vantaggio netto
Strategie classificate per score composito — la correzione della fiducia penalizza i campioni piccoli, i costi di funding riducono il vantaggio netto
Quando ci sono più di due strategie, il cascade si generalizza all'allocazione basata su score.
Classifica per PnL per Tempo Attivo
Come descritto in dettaglio in PnL per Tempo Attivo, lo score della strategia viene calcolato tenendo conto di:
- PnL per giorno attivo — efficienza nell'utilizzo del capitale
- Correzione della fiducia — penalità per campioni piccoli (distribuzione t)
- Costi di funding — costo reale della leva (Tassi di funding)
- MaxLev — scalabilità con considerazione del drawdown (Asimmetria perdita-profitto)
Correzione della Fiducia per Strategie Rare
La Strategia B con 40 operazioni richiede una penalità seria. Utilizziamo il limite inferiore dell'intervallo di confidenza:
import scipy.stats as st
import numpy as np
def confidence_factor(trade_returns: np.ndarray, confidence: float = 0.95) -> float:
"""Fattore di fiducia: 0..1, penalità per campioni piccoli."""
n = len(trade_returns)
if n < 10:
return 0.0
mean_r = np.mean(trade_returns)
if mean_r <= 0:
return 0.0
se = np.std(trade_returns, ddof=1) / np.sqrt(n)
t_crit = st.t.ppf(1 - (1 - confidence) / 2, df=n - 1)
ci_lower = mean_r - t_crit * se
return max(0.0, ci_lower / mean_r)
cf_b = confidence_factor(np.random.normal(0.0067, 0.028, 40))
cf_a = confidence_factor(np.random.normal(0.0011, 0.008, 500))
Integrazione dei Costi di Funding
Sui futures perpetui, il funding viene pagato ogni 8 ore. Con leva e tasso medio :
Per la Strategia A con MaxLev = 55x e tasso di funding medio dello 0.01%:
Con PnL/giorno attivo = 0.49%, il PnL netto è negativo: /giorno. La strategia è non redditizia alla leva completa. Analisi dettagliata in I Tassi di Funding Distruggono la Tua Leva.
Orchestratore Multi-Strategia
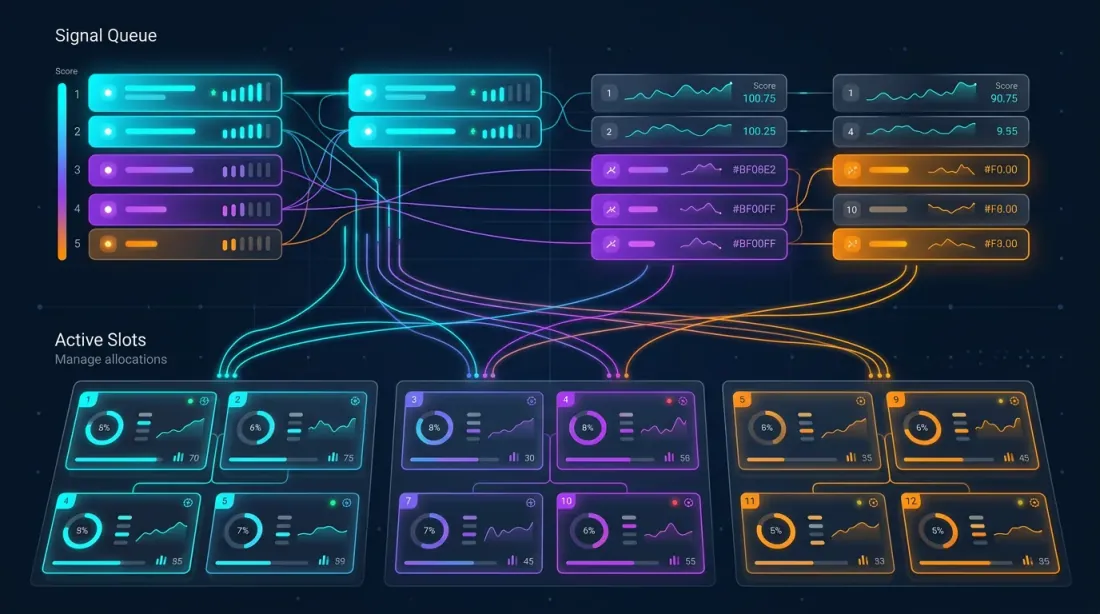
Architettura
L'orchestratore gestisce strategie su coppie di trading. Numero totale di posizioni potenziali: . Ma il capitale è limitato — non sono consentite più di posizioni simultanee (slot).
┌─────────────────────────────────────────────┐
│ ORCHESTRATORE │
│ │
│ Coda dei Segnali (ordinata per score): │
│ ┌──────────────────────────────────────┐ │
│ │ 1. Strategia C × ETHUSDT score=223 │ │
│ │ 2. Strategia B × BTCUSDT score=142 │ │
│ │ 3. Strategia A × SOLUSDT score=100 │ │
│ │ 4. Strategia C × BTCUSDT score=89 │ │
│ │ 5. Strategia A × ETHUSDT score=76 │ │
│ └──────────────────────────────────────┘ │
│ │
│ Slot Attivi (max_parallel = 3): │
│ ┌──────────────────────────────────────┐ │
│ │ Slot 1: Strategia C × ETHUSDT [FULL]│ │
│ │ Slot 2: Strategia B × BTCUSDT [FULL]│ │
│ │ Slot 3: Strategia A × SOLUSDT [DUAL]│ │
│ └──────────────────────────────────────┘ │
│ │
│ Regole di Conflitto: │
│ - Una posizione per coppia │
│ - La primaria sostituisce il fallback │
│ sulla stessa coppia │
│ - Lo score più alto vince per gli slot │
│ cross-pair │
└─────────────────────────────────────────────┘
Gestione degli Slot
from dataclasses import dataclass, field
from enum import Enum
from typing import Optional
import heapq
import time
class SlotType(Enum):
FULL = "full" # strategia primaria, posizione 100%
DUAL = "dual" # strategia fallback, posizione dual_size
@dataclass
class Signal:
strategy_id: str
pair: str
direction: str # "long" | "short"
score: float
is_primary: bool # primaria o fallback
timestamp: float
@dataclass(order=True)
class Slot:
"""Un singolo slot dell'orchestratore."""
priority: float = field(compare=True) # score negativo per min-heap
strategy_id: str = field(compare=False)
pair: str = field(compare=False)
slot_type: SlotType = field(compare=False)
entry_time: float = field(compare=False)
class Orchestrator:
"""
Orchestratore multi-strategia con modalità cascade.
Gestisce N strategie x M coppie entro max_parallel_positions slot.
Le strategie primarie hanno priorità incondizionata sul fallback.
"""
def __init__(
self,
max_parallel_positions: int = 10,
dual_size: float = 0.068,
min_score: float = 0,
):
self.max_parallel = max_parallel_positions
self.dual_size = dual_size
self.min_score = min_score
self.active_slots: dict[str, Slot] = {} # coppia -> Slot
self.pending_signals: list[Signal] = []
def on_signal(self, signal: Signal) -> Optional[dict]:
"""
Elabora un nuovo segnale. Restituisce un'azione o None.
Azioni:
- {"action": "open", "pair": ..., "size": ..., "slot_type": ...}
- {"action": "replace", "pair": ..., "close_strategy": ..., "open_strategy": ...}
- None (segnale rifiutato)
"""
if signal.score < self.min_score:
return None
pair = signal.pair
if pair in self.active_slots:
existing = self.active_slots[pair]
if signal.is_primary and existing.slot_type == SlotType.DUAL:
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=SlotType.FULL,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": 1.0,
}
if signal.score > -existing.priority:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # lo slot esistente ha priorità più alta
if len(self.active_slots) < self.max_parallel:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "open",
"pair": pair,
"strategy": signal.strategy_id,
"size": size,
"slot_type": slot_type,
}
worst_pair = min(
self.active_slots,
key=lambda p: -self.active_slots[p].priority,
)
worst_slot = self.active_slots[worst_pair]
if signal.score > -worst_slot.priority:
del self.active_slots[worst_pair]
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": worst_slot.strategy_id,
"close_pair": worst_pair,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # tutti gli slot attivi hanno score più alti
def on_exit(self, pair: str) -> None:
"""La strategia ha chiuso una posizione."""
if pair in self.active_slots:
del self.active_slots[pair]
def utilization(self) -> float:
"""Utilizzo corrente degli slot."""
return len(self.active_slots) / self.max_parallel
def fill_efficiency_snapshot(self) -> float:
"""Utilizzo ponderato: FULL=1.0, DUAL=dual_size."""
total = sum(
1.0 if s.slot_type == SlotType.FULL else self.dual_size
for s in self.active_slots.values()
)
return total / self.max_parallel
Risoluzione dei Conflitti
Tre livelli di conflitto:
Livello 1 — Stessa coppia, stessa direzione. Vince la strategia con lo score più alto. Se entrambe sono primarie — lo score determina il vincitore. Se una è primaria e l'altra fallback — la primaria vince incondizionatamente.
Livello 2 — Stessa coppia, direzione opposta. Vietato: non puoi essere simultaneamente long e short sulla stessa coppia. Vince la strategia con lo score più alto.
Livello 3 — Competizione cross-pair. Quando tutti gli slot sono occupati, un nuovo segnale espelle lo slot con lo score più basso. Questo funziona come una coda prioritaria.
Backtest Cascade: Metodologia
 Simulazione congiunta: curve di equity primaria e fallback con zone di sovrapposizione e il risultato cascade combinato
Simulazione congiunta: curve di equity primaria e fallback con zone di sovrapposizione e il risultato cascade combinato
Perché Non Puoi Semplicemente Sommare il PnL
L'approccio ingenuo: eseguire il backtest di ogni strategia separatamente, sommare il PnL. Questo produce un risultato gonfiato per tre motivi:
-
Sovrapposizione temporale. Quando primaria e fallback sono attive simultaneamente, il fallback non dovrebbe operare (o opera a dual_size). La semplice somma ignora questa sovrapposizione.
-
Vincolo di capitale. La posizione totale è limitata. Se 5 strategie vogliono aprire simultaneamente ma ci sono solo 3 slot — due strategie non entreranno. Il loro PnL non può essere conteggiato.
-
Costi di transazione. Il cambio cascade (chiusura fallback, apertura primaria) genera commissioni aggiuntive non presenti nei backtest individuali.
Simulazione Congiunta
Il backtest cascade corretto è una simulazione congiunta di tutte le strategie su una timeline condivisa:
import numpy as np
from typing import NamedTuple
class Trade(NamedTuple):
strategy: str
pair: str
entry_time: int # indice al minuto
exit_time: int # indice al minuto
pnl_per_minute: float # log-rendimento per minuto
is_primary: bool
score: float
def backtest_cascade(
all_trades: list[Trade],
total_minutes: int,
max_slots: int = 10,
dual_size: float = 0.068,
switch_cost: float = 0.0006, # 0.06% round-trip
) -> dict:
"""
Simulazione congiunta del portafoglio cascade.
Percorre ogni minuto, applica le regole dell'orchestratore,
calcola il PnL tenendo conto della sovrapposizione e dei vincoli degli slot.
"""
entries = {}
exits = {}
active_trades = {} # trade_id -> Trade
for i, trade in enumerate(all_trades):
entries.setdefault(trade.entry_time, []).append((i, trade))
exits.setdefault(trade.exit_time, []).append((i, trade))
active_slots = {} # coppia -> (trade_id, SlotType)
equity = np.ones(total_minutes)
switch_costs_total = 0.0
for t in range(1, total_minutes):
for trade_id, trade in exits.get(t, []):
if trade.pair in active_slots:
slot_id, _ = active_slots[trade.pair]
if slot_id == trade_id:
del active_slots[trade.pair]
new_signals = sorted(
entries.get(t, []),
key=lambda x: x[1].score,
reverse=True,
)
for trade_id, trade in new_signals:
pair = trade.pair
if pair in active_slots:
existing_id, existing_type = active_slots[pair]
existing_trade = all_trades[existing_id]
if trade.is_primary and existing_type == SlotType.DUAL:
active_slots[pair] = (trade_id, SlotType.FULL)
switch_costs_total += switch_cost
continue
if trade.score > existing_trade.score:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
switch_costs_total += switch_cost
elif len(active_slots) < max_slots:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
minute_return = 0.0
for pair, (trade_id, slot_type) in active_slots.items():
trade = all_trades[trade_id]
size = 1.0 if slot_type == SlotType.FULL else dual_size
minute_return += trade.pnl_per_minute * size
equity[t] = equity[t - 1] * (1 + minute_return)
peak = np.maximum.accumulate(equity)
max_dd = ((equity - peak) / peak).min()
total_pnl = equity[-1] - 1 - switch_costs_total
return {
"total_pnl": total_pnl,
"max_dd": max_dd,
"switch_costs": switch_costs_total,
"equity_curve": equity,
}
Costo di Transazione al Cambio
Ogni cambio cascade (fallback -> primario) richiede:
- Chiusura della posizione fallback: commissione taker (0.04% su Binance futures)
- Apertura della posizione primaria: commissione taker (0.04%)
- Spread: ~0.01-0.02%
Costo totale di cambio: ~0.06-0.10% per cambio. Con 100 cambi nel periodo:
Questo è un importo significativo. Un cascade con cambi frequenti può sottoperformare una singola strategia a causa dei costi di transazione.
Estensione Multi-Coppia: N Strategie su M Coppie
 Rete di N strategie collegate a M coppie di trading — la forza della correlazione determina la diversificazione effettiva
Rete di N strategie collegate a M coppie di trading — la forza della correlazione determina la diversificazione effettiva
Spazio delle Combinazioni
3 strategie su 10 coppie = 30 segnali potenziali. Con max_slots = 5, l'orchestratore seleziona i top 5 per score. Questo è un problema combinatorio: portafogli possibili in ogni momento.
In pratica, un algoritmo greedy (ordina per score, riempie dall'alto verso il basso) produce risultati quasi ottimali in .
Correlazione tra Coppie
Le coppie crypto sono fortemente correlate. BTC scende — ETH, SOL, AVAX scendono insieme. Questo significa che 5 posizioni long su 5 coppie diverse sono effettivamente un'unica grande posizione sul "mercato crypto".
Come abbiamo analizzato in dettaglio in Correlazione dei Segnali, il numero effettivo di posizioni indipendenti:
dove è la correlazione media tra le coppie.
Con e :
Cinque posizioni su coppie correlate equivalgono a 1.3 posizioni indipendenti. La diversificazione è praticamente assente.
Implicazioni Pratiche per il Cascade
def effective_diversification(
positions: list[dict], # [{"pair": "BTCUSDT", "direction": "long"}, ...]
correlation_matrix: np.ndarray,
pair_index: dict[str, int],
) -> float:
"""
Calcola la diversificazione effettiva delle posizioni aperte.
Restituisce:
N_eff / N — coefficiente di diversificazione (0..1)
"""
n = len(positions)
if n <= 1:
return 1.0
total_corr = 0.0
pairs_count = 0
for i in range(n):
for j in range(i + 1, n):
idx_i = pair_index[positions[i]["pair"]]
idx_j = pair_index[positions[j]["pair"]]
rho = correlation_matrix[idx_i, idx_j]
if positions[i]["direction"] != positions[j]["direction"]:
rho = -rho
total_corr += rho
pairs_count += 1
avg_rho = total_corr / pairs_count if pairs_count > 0 else 0
n_eff = n / (1 + (n - 1) * max(0, avg_rho))
return n_eff / n
L'orchestratore dovrebbe tenere conto della correlazione quando riempie gli slot. Due opzioni:
- Bonus di diversificazione: durante la classificazione, aggiungere un bonus allo score delle strategie su coppie non correlate.
- Cap di correlazione: limitare il numero di posizioni nella stessa direzione su coppie correlate.
Pipeline di Ottimizzazione Cascade
 Otto fasi collegate dalla preparazione dei dati attraverso la validazione all'orchestrazione live — ognuna si basa sulla precedente
Otto fasi collegate dalla preparazione dei dati attraverso la validazione all'orchestrazione live — ognuna si basa sulla precedente
La pipeline completa dai dati alla produzione consiste di 8 fasi:
Fase 0: Preparazione dei Dati
Carica i dati storici, costruisci la cache Parquet per l'accesso multi-timeframe. Senza una caching efficiente, le fasi successive sono inaccettabilmente lente.
Fase 1: TF + Lunghezza (Grid Hill-Climbing)
Seleziona il timeframe di base e le lunghezze delle finestre degli indicatori. Griglia approssimativa: TF tra {1m, 5m, 15m, 1h, 4h}, Lunghezza tra {10, 20, 50, 100, 200}. Hill-climbing dal miglior punto della griglia.
Fase 2: Separazione (Discesa per Coordinate, 12 Parametri)
Ottimizza i parametri di separazione (ingressi/uscite). Discesa per coordinate su 12 parametri — soglie degli indicatori, filtri, stop-loss, take-profit. La discesa per coordinate è meno costosa di Optuna per funzioni obiettivo deterministiche ad alta dimensionalità.
Fase 3: Meta-Parametri (Discesa per Coordinate)
Meta-parametri: tempo massimo di mantenimento, PnL minimo per uscita, configurazione dello stop trailing. Ancora discesa per coordinate. Verifica la robustezza tramite analisi del plateau — se l'ottimo è puntiforme, la strategia è sovra-ottimizzata.
Fase 4: Ottimizzazione Combo
Ricerca a griglia sulle coppie (Primario, Fallback). Per ogni combinazione: seleziona dual_size, calcola il PnL cascade tramite simulazione congiunta.
Fase 5: Validazione
Validazione multi-livello:
- Multi-simbolo: strategia testata su 10+ coppie, non solo sulla coppia di ottimizzazione
- Walk-forward: finestra IS/OOS scorrevole
- Stabilità dei parametri: analisi del plateau in ogni fase
- Bootstrap Monte Carlo: intervalli di confidenza per il PnL cascade
- Parità backtest-live: confronto del backtest con il paper trading
Fase 6: Classificazione e Selezione
Classifica le combinazioni cascade per score. Le combinazioni top-K avanzano alla Fase 7. Lo score tiene conto della correzione della fiducia, dei costi di funding e della fill_efficiency.
Fase 7: Orchestrazione
Fase finale: avvia l'orchestratore su strategie e coppie in modalità cascade. Gestione degli slot, coda prioritaria, risoluzione dei conflitti — tutto quanto descritto sopra.
Analisi delle Prestazioni: Cascade vs. Individuale
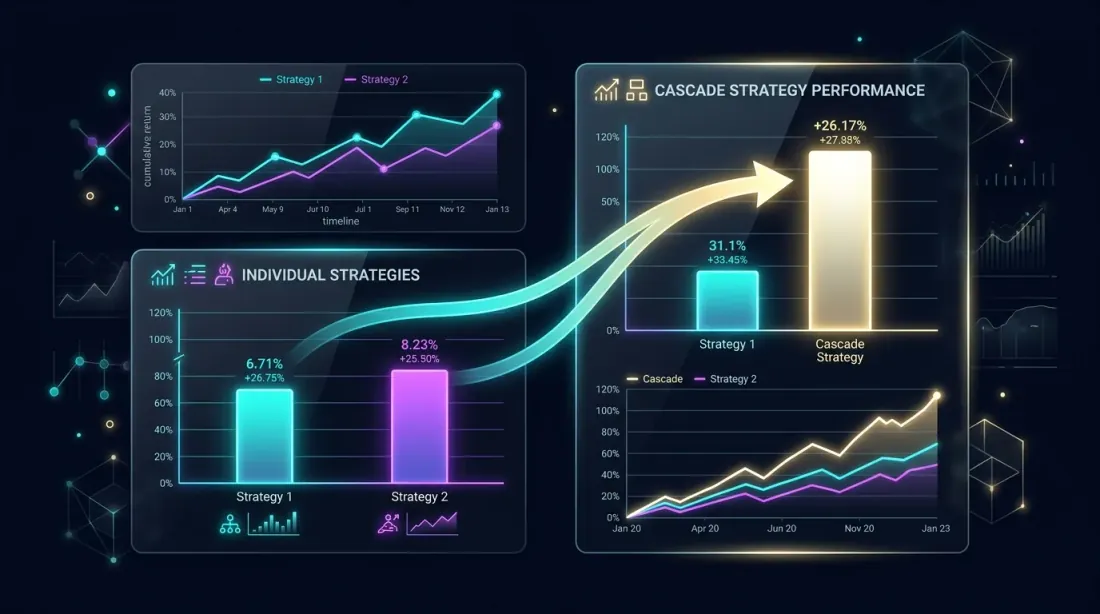 Confronto fianco a fianco: il portafoglio cascade supera le strategie individuali attraverso l'utilizzo del tempo inattivo
Confronto fianco a fianco: il portafoglio cascade supera le strategie individuali attraverso l'utilizzo del tempo inattivo
Vantaggio Teorico del Cascade
Supponi che la primaria operi del tempo con PnL/giorno = 0.49%. Il fallback opera con PnL/giorno = 0.89%. Sovrapposizione = (assumendo indipendenza).
Solo Primaria (Strategia A):
Cascade (A primaria + C fallback):
Guadagno cascade: +31% al PnL dal fallback, con un aumento minimo del drawdown ( aggiunto al MaxDD).
Quando il Cascade Non Aiuta
Il cascade è inefficace quando:
- La primaria è attiva >80% del tempo. Poco tempo inattivo — nessuno spazio per il fallback.
- Le strategie sono altamente correlate. Primaria e fallback generano segnali simultaneamente — la sovrapposizione è alta, e il fallback è inattivo proprio quando anche la primaria è inattiva.
- I costi di cambio superano il PnL del fallback. Con cambi frequenti, le commissioni cascade consumano i profitti del fallback.
- dual_size è troppo piccolo. Con , il fallback guadagna l'1% del suo potenziale — al di sotto delle commissioni.
Tabella di Confronto
| Configurazione | PnL Annuale | MaxDD | Sharpe | Costi di cambio |
|---|---|---|---|---|
| Solo Strategia A | 26.8% | 0.9% | 1.42 | 0 |
| Solo Strategia C | 146.1% | 17% | 1.15 | 0 |
| Cascade A+C (d=0.068) | 35.2% | 2.06% | 1.58 | ~1.2% |
| Cascade B+A (d=0.068) | 19.4% | 1.36% | 1.71 | ~0.3% |
| Orchestratore 3 strategie | 48.7% | 3.1% | 1.63 | ~2.1% |
Cascade A+C: la primaria A guadagna +8.4% dal fallback C. Il Sharpe aumenta grazie all'utilizzo del tempo inattivo. Il MaxDD cresce moderatamente ().
Orchestrazione: fill_efficiency in Pratica
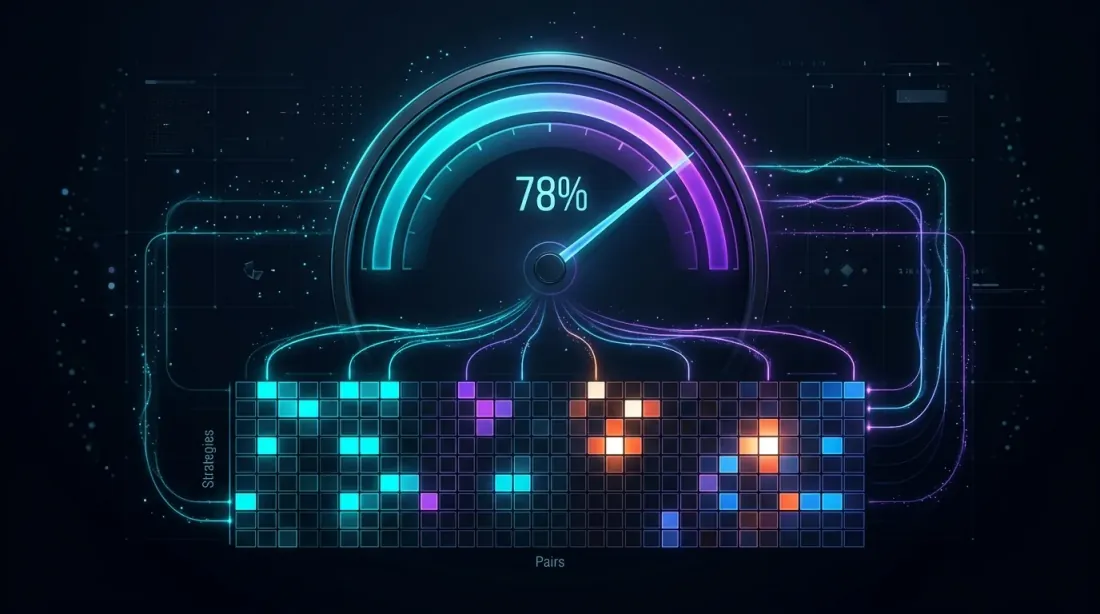 Fill efficiency al ~78%: la heatmap mostra l'utilizzo del tempo tra strategie e coppie, le celle luminose indicano il trading attivo
Fill efficiency al ~78%: la heatmap mostra l'utilizzo del tempo tra strategie e coppie, le celle luminose indicano il trading attivo
Il parametro fill_efficiency determina quale frazione del tempo inattivo l'orchestratore utilizza effettivamente. Come mostrato in PnL per Tempo Attivo, può essere stimato in tre modi:
- Costante fissa (0.80) — approssimativa ma universale
- Stima analitica tramite — tiene conto della correlazione
- Simulazione dai dati — più accurata
Per un cascade con 3 strategie su 10 coppie:
def cascade_fill_efficiency(
strategies: list[dict], # [{"trading_time": 0.15, "is_primary": True}, ...]
n_pairs: int = 10,
correlation_factor: float = 3.0,
) -> float:
"""Stima fill_efficiency per un portafoglio cascade."""
n_eff = n_pairs / correlation_factor
primary_times = [s["trading_time"] for s in strategies if s["is_primary"]]
p_primary = 1 - np.prod([(1 - t) ** n_eff for t in primary_times])
fallback_times = [s["trading_time"] for s in strategies if not s["is_primary"]]
p_fallback = 1 - np.prod([(1 - t) ** n_eff for t in fallback_times])
fill = p_primary + (1 - p_primary) * p_fallback
return min(fill, 1.0)
strategies = [
{"trading_time": 0.05, "is_primary": True}, # Strategia B
{"trading_time": 0.15, "is_primary": True}, # Strategia A
{"trading_time": 0.45, "is_primary": False}, # Strategia C come fallback
]
eff = cascade_fill_efficiency(strategies, n_pairs=10, correlation_factor=3.0)
Raccomandazioni Pratiche
 Sei raccomandazioni chiave per il deployment cascade — dall'inizio in piccolo alla ricalibrazione adattiva
Sei raccomandazioni chiave per il deployment cascade — dall'inizio in piccolo alla ricalibrazione adattiva
1. Inizia con Due Strategie
Non avviare subito 10 strategie su 20 coppie. Inizia con una primaria + una fallback su 3-5 coppie. Assicurati che la simulazione congiunta corrisponda al comportamento reale. La parità backtest-live è critica: se il backtest cascade diverge dal live anche solo del 5-10% — c'è un errore nella logica dell'orchestratore.
2. dual_size dalla Ricerca a Griglia, Non dall'Intuizione
Il dual_size ottimale dipende dalla coppia specifica di strategie. Il 6.8% è una linea guida, non una costante universale. Esegui la ricerca a griglia dall'1% al 30% con passi dello 0.5% e seleziona il massimo del Sharpe.
3. Il Limite degli Slot Definisce l'Architettura
Con max_slots = 1, il cascade degenera in un semplice cambio di strategia. Con max_slots = 50, il vincolo non è vincolante e il problema si riduce a un portafoglio indipendente. La zona interessante: max_slots = 3-10, dove la gestione degli slot impatta genuinamente i risultati.
4. Considera la Latenza
Nel trading live, il cambio cascade non è istantaneo. Chiudere una posizione fallback + aprire la primaria = 2 chiamate API + latenza di rete + matching dell'exchange. Su un mercato volatile, il prezzo può muoversi in 200-500ms. Includi un budget per lo slippage.
5. Monitora fill_efficiency
Traccia la fill_efficiency reale in produzione. Se è significativamente inferiore al backtest — l'orchestratore non sta utilizzando il tempo inattivo come previsto. Cause: ritardi API, ordini rifiutati, vincoli di margine.
6. Usa l'Ottimizzazione Adattiva
I parametri cascade (dual_size, pesi degli score, limiti degli slot) non dovrebbero essere statici. Usa il drill-down adattivo per la ricalibrazione periodica su dati freschi. Il mercato cambia — i parametri cascade dovrebbero seguirlo.
Serie "Backtest Senza Illusioni": Riepilogo
 Architettura completa del sistema: 13 moduli interconnessi dalla matematica attraverso la validazione all'orchestrazione live
Architettura completa del sistema: 13 moduli interconnessi dalla matematica attraverso la validazione all'orchestrazione live
Questo articolo è il finale di una serie di 13+ articoli. Ogni articolo ha affrontato un problema specifico sul percorso dal backtest alla produzione. Ecco come si collegano:
Fondamenti: Matematica dei Rendimenti
Asimmetria Perdita-Profitto — la natura moltiplicativa dei rendimenti, la volatility drag, il criterio di Kelly. Questa è la base matematica per tutto ciò che segue: perché il MaxDD determina la leva, perché il Sharpe conta più del PnL grezzo, perché un win rate del 50% con R:R simmetrico è non redditizio.
Validazione: Intervalli di Confidenza e Robustezza
Bootstrap Monte Carlo — trasformare una stima puntuale in una distribuzione con intervalli di confidenza. Qualsiasi metrica (PnL, MaxDD, Sharpe) ha senso solo con un intervallo di confidenza.
Walk-Forward Optimization — validazione out-of-sample. Un backtest sui dati storici è un risultato IS; il WFO mostra come la strategia si comporta su nuovi dati.
Analisi del Plateau — verifica della robustezza dei parametri. Se l'ottimo è puntiforme, la strategia è sovra-ottimizzata.
Parità Backtest-Live — confronto del backtest con i risultati reali. Il controllo finale prima dello scaling.
Costi Realistici: Funding e Leva
I Tassi di Funding Distruggono la Leva — il costo nascosto della leva sui futures perpetui. Senza considerare il funding, un bel backtest si trasforma in una perdita.
Arbitraggio del Tasso di Funding — come trasformare il funding da una spesa in una fonte di entrate attraverso strategie cross-exchange.
Metriche e Classificazione
PnL per Tempo Attivo — la metrica per classificare le strategie in un portafoglio. Il PnL grezzo non scala; il PnL/giorno attivo sì.
Correlazione dei Segnali — diversificazione effettiva in un portafoglio di coppie correlate.
Infrastruttura e Ottimizzazione
Cache Parquet per Backtest Multi-Timeframe — infrastruttura dati per iterazioni veloci.
Drill-Down Adattivo — ottimizzazione adattiva: griglia approssimativa -> messa a punto nelle zone promettenti.
Optuna vs. Discesa per Coordinate — selezione dell'ottimizzatore: Optuna per basse dimensioni con obiettivi rumorosi, discesa per coordinate per alte dimensioni con obiettivi lisci.
Polars vs Pandas — prestazioni delle operazioni DataFrame per il backtesting.
Orchestrazione (Questo Articolo)
Strategie Cascade — combinare tutti i componenti precedenti in un sistema funzionante. L'allocazione basata su score utilizza PnL/tempo attivo, correzione della fiducia, costi di funding. La modalità cascade riempie il tempo inattivo. La simulazione congiunta valida il portafoglio. Il bootstrap Monte Carlo fornisce intervalli di confidenza per il PnL cascade.
Ogni articolo è un modulo indipendente. Insieme formano una pipeline completa dal caricamento dei dati all'orchestrazione live di un portafoglio di strategie.
Conclusione
Il cascade non è l'unico approccio ai portafogli di strategie. Ma è uno dei più semplici e pratici: la strategia primaria opera a piena capacità, il fallback riempie il tempo inattivo con una posizione ridotta. Due parametri chiave (dual_size e max_slots) forniscono sufficiente flessibilità per la maggior parte delle configurazioni.
Tre conclusioni:
-
Il cascade deve essere testato solo tramite simulazione congiunta. Sommare il PnL individuale gonfia i risultati. Costi di cambio, sovrapposizione, vincoli degli slot — tutto questo viene catturato solo nella simulazione congiunta.
-
dual_size determina il trade-off PnL vs. drawdown. L'ottimo tipico è 5-10%. La ricerca a griglia sul Sharpe è un metodo di selezione affidabile.
-
L'orchestratore è una coda prioritaria basata su score. Tutto si riduce a un singolo numero (score) per ogni segnale. Score = f(PnL/giorno attivo, MaxLev, fiducia, funding). Le strategie con lo score più alto ottengono gli slot. Le altre aspettano.
La serie "Backtest Senza Illusioni" dimostra una cosa: tra un bel backtest e un profitto reale si celano decine di insidie. Ogni articolo ne rimuove una. L'orchestrazione cascade è l'ultimo passo: trasformare un insieme di strategie validate in un portafoglio funzionante.
Link Utili
- López de Prado — Advances in Financial Machine Learning: Portfolio Construction
- Pardo, R. — The Evaluation and Optimization of Trading Strategies
- Ernest Chan — Algorithmic Trading: Winning Strategies and Their Rationale
- Perry Kaufman — Trading Systems and Methods, Chapter on Portfolio Allocation
- Tomasini, Jaekle — Trading Systems: A New Approach to System Development and Portfolio Optimisation
- Bailey, D.H. & López de Prado — The Deflated Sharpe Ratio
- Markowitz, H. — Portfolio Selection (1952)
- Kelly, J.L. — A New Interpretation of Information Rate (1956)
Citazione
@article{soloviov2026cascadestrategies,
author = {Soloviov, Eugen},
title = {Strategie Cascade: Esecuzione Prioritaria con Riempimento di Fallback},
year = {2026},
url = {https://marketmaker.cc/it/blog/post/cascade-strategies-orchestration},
version = {0.1.0},
description = {Finale della serie "Backtest Senza Illusioni". Come costruire un orchestratore da N strategie x M coppie, implementare la modalità cascade con priorità e riempimento di fallback, scegliere dual\_size e perché i portafogli di strategie non possono essere testati sommando il PnL.}
}
Autori

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Leggi di Più

PnL per Tempo Attivo: La Metrica che Cambia il Ranking delle Strategie
Correlazione dei Segnali: Quante Coppie Monitorare
