Adaptive Drill-Down: Backtest với Độ Phân Giải Biến Đổi từ Phút đến Giao Dịch Thô
Nến phút là độ phân giải chuẩn cho backtest. Nhưng trong một nến phút, giá có thể biến động theo nhiều cách khác nhau: đôi khi chỉ 0,01%, đôi khi lên đến 2%. Khi cả stop-loss và take-profit đều nằm trong phạm vi [low, high] của một nến phút, backtest không biết cái nào kích hoạt trước. Đây là vấn đề mơ hồ lệnh khớp (fill ambiguity).
Giải pháp ngây thơ là chuyển sang dữ liệu theo giây cho toàn bộ backtest. Nhưng trong hai năm, đó là khoảng ~63 triệu thanh giây thay vì ~1 triệu thanh phút. Dung lượng lưu trữ tăng 60 lần, tốc độ giảm tương tự.
Adaptive drill-down giải quyết vấn đề này: chỉ sử dụng độ phân giải cao ở những nơi thực sự cần thiết.
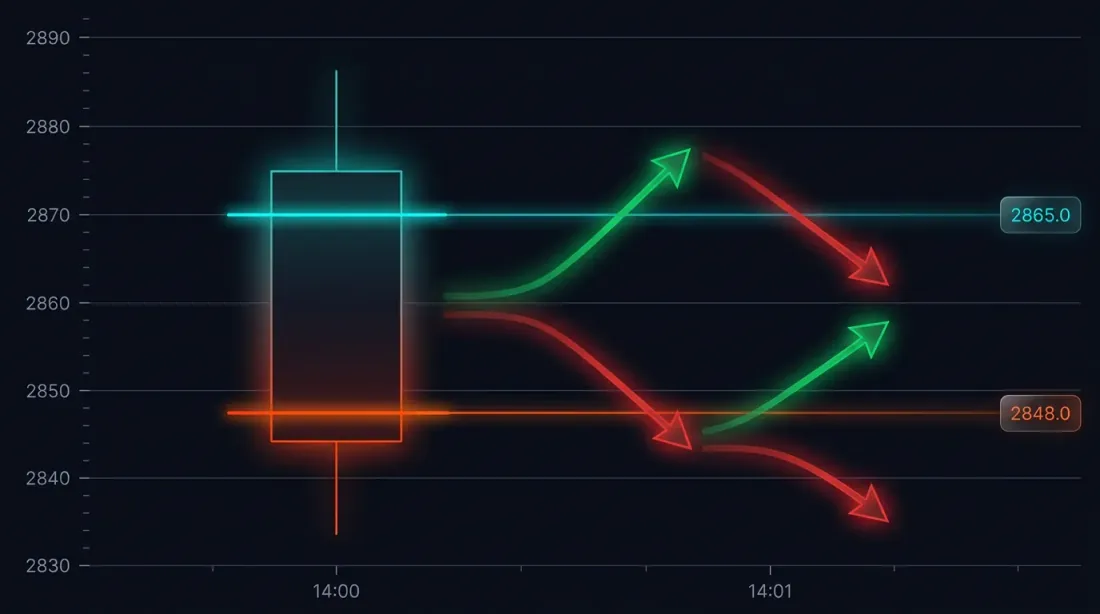
Vấn Đề: Mơ Hồ Lệnh Khớp trên Nến Lớn
Hãy xem xét một tình huống cụ thể. Chiến lược mở vị thế long tại 3000 USDT. Stop-loss: 2970 (-1%). Take-profit: 3060 (+2%).
Nến phút lúc 14:37:
- Open: 3010
- High: 3065
- Low: 2965
- Close: 3050
Cả SL (2970) và TP (3060) đều nằm trong phạm vi [2965, 3065]. Cái nào kích hoạt trước?
Các kết quả có thể xảy ra:
- Giá xuống trước -> SL kích hoạt -> lỗ -1%
- Giá lên trước -> TP kích hoạt -> lời +2%
Sự khác biệt trong một giao dịch: 3 điểm phần trăm. Với đòn bẩy 10x — 30%. Đối với backtest với hàng trăm giao dịch, việc giải quyết mơ hồ lệnh khớp không đúng sẽ làm sai lệch kết quả một cách có hệ thống.
Cách Các Framework Xử Lý Điều Này Theo Mặc Định
Hầu hết các engine backtest sử dụng một trong hai heuristic:
- Lạc quan: TP kích hoạt trước -> kết quả bị thổi phồng
- Bi quan: SL kích hoạt trước -> kết quả bị hạ thấp
Cả hai cách tiếp cận đều là đoán mò. Dữ liệu thực tế có sẵn ở cấp độ giây hoặc thậm chí mili-giây, và không có lý do gì để đoán khi bạn có thể tra cứu.
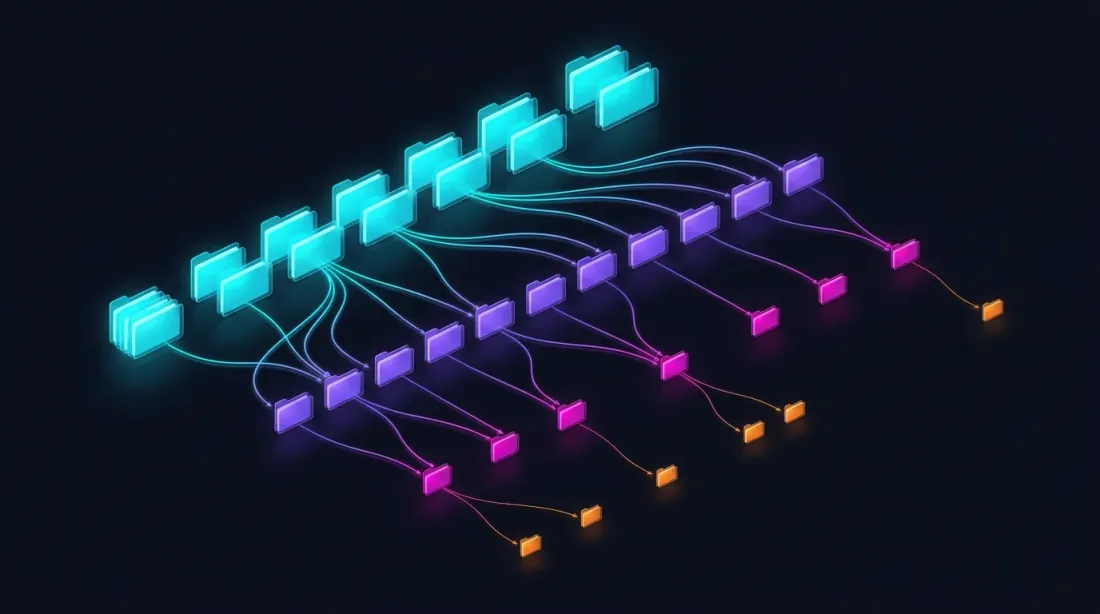
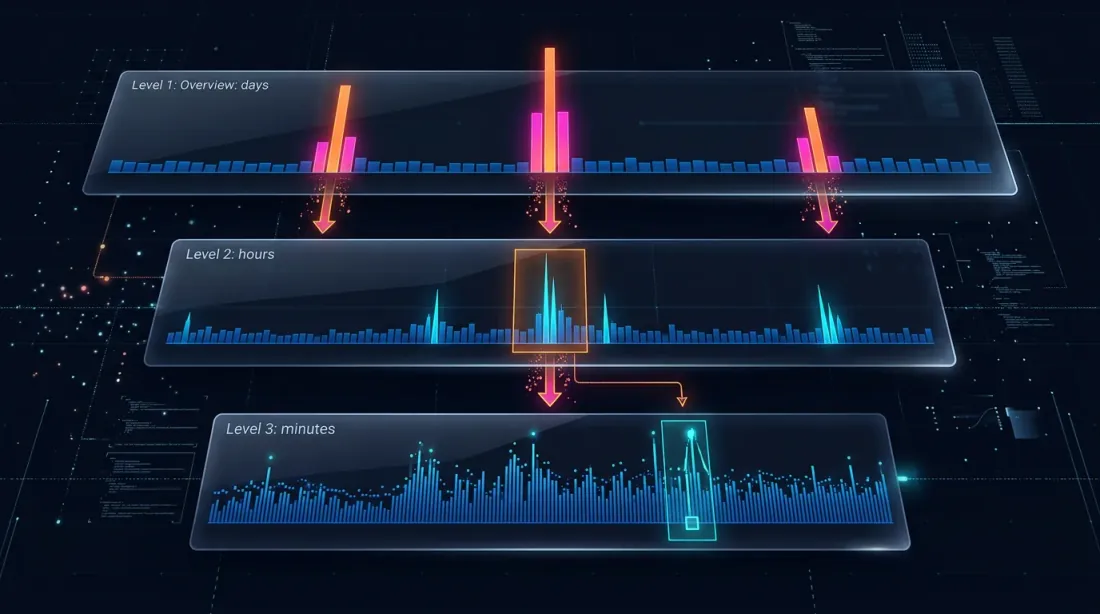
Drill-Down: Chiến Lược Bốn Cấp Độ

Ý tưởng drill-down: bắt đầu ở cấp độ phút và "drill down" xuống cấp thấp hơn chỉ khi có sự mơ hồ — do biến động giá hoặc khối lượng tăng đột biến.
Cấp 1: 1m (nến phút)
-> Nếu SL hoặc TP rõ ràng nằm ngoài phạm vi [low, high] — giải quyết ngay
-> Nếu cả hai nằm trong phạm vi — drill down
Cấp 2: 1s (nến giây)
-> Tải 60 thanh giây cho phút này
-> Duyệt từng giây: cái nào kích hoạt trước?
-> Nếu thanh giây mơ hồ, HOẶC price_move >= min_pct, HOẶC volume >= median_1s * vol_mult — drill down
Cấp 3: 100ms (nến mili-giây)
-> Tải tối đa 10 thanh 100ms cho giây này
-> Duyệt từng 100ms
-> Nếu thanh 100ms mơ hồ, HOẶC price_move >= min_pct, HOẶC volume >= median_100ms * vol_mult — drill down
Cấp 4: Giao dịch thô
-> Tải các giao dịch riêng lẻ cho bucket 100ms này
-> Giải quyết lệnh khớp ở cấp độ từng giao dịch — độ chính xác tối đa có thể
Khi Nào Không Cần Drill-Down
Trong 95% trường hợp, drill-down không cần thiết. Các tình huống điển hình:
SL rõ ràng: high của nến không đạt đến TP, low phá qua SL -> SL kích hoạt, không cần drill-down.
TP rõ ràng: low không đạt SL, high phá qua TP -> TP kích hoạt, không cần drill-down.
Không kích hoạt: cả hai cấp độ đều nằm ngoài phạm vi -> vị thế vẫn mở.
Phát hiện gap: giá mở của nến tiếp theo nhảy qua SL hoặc TP -> khớp lệnh tại giá mở, không cần drill-down.
Drill-down chỉ cần thiết cho khoảng ~5% thanh — khi cả hai cấp độ đều nằm trong phạm vi một nến.
class AdaptiveFillSimulator:
"""
Drill-down bốn cấp để xác định thứ tự lệnh khớp.
"""
def __init__(self, data_loader):
self.loader = data_loader
self.cache_1s = {} # Cache dữ liệu giây theo tháng
def check_fill(self, timestamp, candle_1m, sl_price, tp_price, side):
"""
Kiểm tra xem SL hay TP có kích hoạt trên nến phút đã cho không.
Trả về: ('sl', fill_price) | ('tp', fill_price) | None
"""
low, high = candle_1m['low'], candle_1m['high']
open_price = candle_1m['open']
if side == 'long':
if open_price <= sl_price:
return ('sl', open_price)
if open_price >= tp_price:
return ('tp', open_price)
else:
if open_price >= sl_price:
return ('sl', open_price)
if open_price <= tp_price:
return ('tp', open_price)
sl_hit = self._level_hit(sl_price, low, high, side, 'sl')
tp_hit = self._level_hit(tp_price, low, high, side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if not sl_hit and not tp_hit:
return None
return self._drill_down_1s(timestamp, sl_price, tp_price, side)
def _drill_down_1s(self, minute_ts, sl_price, tp_price, side):
"""Cấp 2: duyệt từng giây."""
bars_1s = self.loader.load_1s_for_minute(minute_ts)
if bars_1s is None or len(bars_1s) == 0:
return self._pessimistic_fill(side, sl_price, tp_price)
for bar in bars_1s:
sl_hit = self._level_hit(sl_price, bar['low'], bar['high'], side, 'sl')
tp_hit = self._level_hit(tp_price, bar['low'], bar['high'], side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if sl_hit and tp_hit:
result = self._drill_down_100ms(bar['timestamp'], sl_price, tp_price, side)
if result:
return result
return self._pessimistic_fill(side, sl_price, tp_price)
def _pessimistic_fill(self, side, sl_price, tp_price):
"""Giả định bi quan: SL cho long, TP cho short."""
if side == 'long':
return ('sl', sl_price)
else:
return ('sl', sl_price)
Hiệu Suất
| Chế độ | Thời gian mỗi lần kiểm tra | Khi sử dụng |
|---|---|---|
| 1m (không drill-down) | ~0ms | ~95% trường hợp |
| 1s drill-down | ~5ms (lần đầu truy cập tháng) | ~5% trường hợp |
| 100ms drill-down | ~1ms | <0,5% trường hợp |
| Raw trades drill-down | ~0,5ms | <0,1% trường hợp |
Trong backtest 2 năm với ~400 giao dịch, drill-down được gọi cho khoảng 20 nến. Tổng chi phí — dưới 1 giây cho toàn bộ backtest.
Lưu Trữ Dữ Liệu Thích Ứng
Drill-down yêu cầu dữ liệu giây và mili-giây. Nhưng lưu trữ mọi thứ ở độ phân giải tối đa là không thực tế:
| Độ phân giải | Thanh trong 2 năm | Kích thước Parquet |
|---|---|---|
| 1m | ~1,05M | ~15 MB |
| 1s | ~63M | ~550 MB/tháng |
| 100ms | ~630M | ~5 GB/tháng |
Lưu trữ 1s đầy đủ trong 2 năm khoảng 13 GB. 100ms — hơn 100 GB. Lưu trữ tất cả là có thể nhưng lãng phí, xét rằng drill-down sử dụng chưa đến 1% dữ liệu này.
Phát Hiện Hot-Second
Quan sát chính: các giây có biến động giá đáng kể chiếm một phần nhỏ. Nếu giá thay đổi dưới 0,1% trong một giây — không cần lưu trữ phân tích 100ms cho giây đó.
Phát hiện hot-second: khi tải và xử lý dữ liệu, chúng ta phân tích từng giây và tạo nến 100ms chỉ cho các "hot" second — những giây có biến động giá vượt ngưỡng.
def process_trades_adaptive(
trades: pd.DataFrame,
min_price_change_pct: float = 1.0,
) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Xử lý giao dịch thô thành cấu trúc thích ứng:
- Nến 1s cho tất cả các giây
- Nến 100ms chỉ cho các "hot" second
Args:
trades: DataFrame với các cột [timestamp, price, quantity]
min_price_change_pct: ngưỡng để drill-down xuống 100ms
Returns:
(df_1s, df_100ms_hot) — nến giây và 100ms cho hot second
"""
trades['second'] = trades['timestamp'].dt.floor('1s')
df_1s = trades.groupby('second').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
df_1s['price_change_pct'] = (df_1s['high'] - df_1s['low']) / df_1s['open'] * 100
hot_seconds = df_1s[df_1s['price_change_pct'] >= min_price_change_pct].index
hot_trades = trades[trades['second'].isin(hot_seconds)]
hot_trades['bucket_100ms'] = hot_trades['timestamp'].dt.floor('100ms')
df_100ms = hot_trades.groupby('bucket_100ms').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
return df_1s, df_100ms
Tiết Kiệm Lưu Trữ
Ví dụ — ETHUSDT trong một tháng điển hình:
| Cách tiếp cận | Kích thước | Độ phân giải |
|---|---|---|
| Chỉ 1m | ~1 MB | 1 phút |
| Tất cả 1s | ~550 MB | 1 giây |
| Tất cả 100ms | ~5 GB | 100 ms |
| Thích ứng | ~600 MB | 1s + 100ms chỉ cho hot second |
Với ngưỡng min_price_change_pct = 1,0%, hot second chiếm chưa đến 1% tổng số giây. Dữ liệu 100ms cho chúng thêm khoảng ~50 MB vào 550 MB dữ liệu giây — chi phí không đáng kể.
Nếu dữ liệu giây cũng được lưu trữ thích ứng (chỉ khi biến động trong phút vượt 0,1%), khối lượng có thể giảm thêm 3-5 lần.
Cấu Trúc Lưu Trữ Parquet
data/{SYMBOL}/
├── source.json # Nguồn sàn giao dịch: {"exchange": "binance"} hoặc {"exchange": "bybit"}
├── stats.json # Khối lượng median được tính trước: {"median_volume_1s": ..., "median_volume_100ms": ...}
├── klines_1m/
│ ├── 2024-01.parquet # ~1 MB
│ ├── 2024-02.parquet
│ └── ...
├── klines_1s/
│ ├── 2024-01.parquet # ~550 MB
│ └── ...
├── klines_100ms_hot/
│ ├── 2024-01.parquet # ~50 MB (chỉ hot second)
│ └── ...
├── trades_hot/
│ ├── 2024-01.parquet # Giao dịch thô cho các bucket 100ms hot
│ └── ...
└── states_1m.parquet # Cache trạng thái rolling được tính trước (~112 MB)
Mỗi file bao phủ một tháng dữ liệu. Dữ liệu giây, mili-giây và giao dịch được tải lazily — chỉ khi drill-down yêu cầu. File stats.json chứa khối lượng median được tính trước dùng cho các trigger drill-down dựa trên khối lượng.
Tối Ưu Hóa Parquet cho Dữ Liệu Tài Chính
Dữ liệu tài chính có đặc điểm riêng: timestamp tăng đơn điệu, giá thay đổi mượt mà, khối lượng biến động đáng kể. Các cài đặt tối ưu:
import pyarrow as pa
import pyarrow.parquet as pq
schema = pa.schema([
pa.field("timestamp", pa.int32()), # Giây từ epoch — int32 là đủ
pa.field("open", pa.float32()),
pa.field("high", pa.float32()),
pa.field("low", pa.float32()),
pa.field("close", pa.float32()),
pa.field("volume", pa.float32()),
])
column_encodings = {
"timestamp": "DELTA_BINARY_PACKED", # Int đơn điệu -> nén delta
"open": "BYTE_STREAM_SPLIT", # Float -> byte-stream split
"high": "BYTE_STREAM_SPLIT",
"low": "BYTE_STREAM_SPLIT",
"close": "BYTE_STREAM_SPLIT",
"volume": "BYTE_STREAM_SPLIT",
}
def save_optimized_parquet(df, path):
table = pa.Table.from_pandas(df, schema=schema)
pq.write_table(
table, path,
compression="zstd",
compression_level=9,
use_dictionary=False,
write_statistics=False,
column_encoding=column_encodings,
)
Lý do chọn các cài đặt này:
- DELTA_BINARY_PACKED cho timestamp: các timestamp liên tiếp khác nhau một giá trị cố định (60 cho 1m, 1 cho 1s). Mã hóa delta nén chúng gần như bằng không.
- BYTE_STREAM_SPLIT cho float: tách byte float32 thành các luồng (tất cả byte đầu tiên cùng nhau, tất cả byte thứ hai cùng nhau, v.v.). Đối với giá thay đổi mượt mà, điều này đạt được nén tốt hơn 2-3 lần so với mã hóa chuẩn.
- ZSTD cấp 9: nén tốt với tốc độ giải nén chấp nhận được.
- float32 thay vì float64: đủ cho giá và khối lượng, tiết kiệm 50% bộ nhớ.
Tải Lazily với Caching
Drill-down yêu cầu dữ liệu giây cho một phút cụ thể. Tải file parquet cho mỗi yêu cầu thì chậm. Giải pháp — tải lazily với LRU cache theo tháng.
from functools import lru_cache
import pyarrow.parquet as pq
import pandas as pd
class AdaptiveDataLoader:
"""
Bộ tải lazily với cache: tải dữ liệu giây theo tháng,
giữ N tháng gần nhất trong bộ nhớ.
"""
def __init__(self, symbol: str, data_dir: str = "data", cache_months: int = 2):
self.symbol = symbol
self.data_dir = data_dir
self.cache_months = cache_months
self._cache_1s: dict[str, pd.DataFrame] = {}
def load_1s_for_minute(self, minute_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Tải dữ liệu 1s cho một phút cụ thể."""
month_key = minute_ts.strftime("%Y-%m")
if month_key not in self._cache_1s:
self._load_month_1s(month_key)
if month_key not in self._cache_1s:
return None
df = self._cache_1s[month_key]
minute_start = minute_ts.floor('1min')
minute_end = minute_start + pd.Timedelta(minutes=1)
return df[(df.index >= minute_start) & (df.index < minute_end)]
def load_100ms_for_second(self, second_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Tải dữ liệu 100ms cho một hot second."""
month_key = second_ts.strftime("%Y-%m")
path = f"{self.data_dir}/{self.symbol}/klines_100ms_hot/{month_key}.parquet"
try:
df = pd.read_parquet(path)
second_start = second_ts.floor('1s')
second_end = second_start + pd.Timedelta(seconds=1)
return df[(df.index >= second_start) & (df.index < second_end)]
except FileNotFoundError:
return None
def _load_month_1s(self, month_key: str):
"""Tải một tháng dữ liệu 1s, xóa dữ liệu cũ khỏi cache."""
path = f"{self.data_dir}/{self.symbol}/klines_1s/{month_key}.parquet"
try:
df = pd.read_parquet(path)
df.index = pd.to_datetime(df['timestamp'], unit='s')
if len(self._cache_1s) >= self.cache_months:
oldest = min(self._cache_1s.keys())
del self._cache_1s[oldest]
self._cache_1s[month_key] = df
except FileNotFoundError:
pass
Áp Dụng Drill-Down vào Backtesting
Tích hợp vào vòng lặp backtest:
def backtest_with_adaptive_fill(
states: pd.DataFrame,
strategy_params: dict,
data_loader: AdaptiveDataLoader,
) -> list:
"""
Backtest với adaptive drill-down để mô phỏng lệnh khớp.
"""
fill_sim = AdaptiveFillSimulator(data_loader)
trades = []
position = None
for i in range(len(states)):
row = states.iloc[i]
ts = states.index[i]
candle_1m = {
'open': row['open'], 'high': row['high'],
'low': row['low'], 'close': row['close'],
'timestamp': ts,
}
if position is not None:
fill = fill_sim.check_fill(
ts, candle_1m,
position['sl'], position['tp'],
position['side'],
)
if fill is not None:
fill_type, fill_price = fill
trades.append({
'entry_time': position['entry_time'],
'exit_time': ts,
'side': position['side'],
'entry_price': position['entry_price'],
'exit_price': fill_price,
'exit_type': fill_type,
'drill_down': fill_sim.last_drill_depth, # 0, 1, hoặc 2
})
position = None
continue
signal = check_entry_signal(row, strategy_params)
if signal and position is None:
position = {
'side': signal['side'],
'entry_price': row['close'],
'entry_time': ts,
'sl': signal['sl'],
'tp': signal['tp'],
}
return trades
Mối Quan Hệ với Rolling State Cache
Drill-down bổ sung cho cache parquet tổng hợp — chúng giải quyết các vấn đề khác nhau:
| Rolling state cache | Adaptive drill-down | |
|---|---|---|
| Mục đích | Giá trị chỉ số HTF chính xác | Thứ tự thực thi SL/TP chính xác |
| Hoạt động trên | Mỗi nến 1m | Chỉ trong khi mơ hồ lệnh khớp (~5%) |
| Dữ liệu | Được tính trước, lưu trữ vĩnh viễn | Tải lazily, cache các tháng gần đây |
| Ảnh hưởng đến | Tín hiệu vào/ra | Giá thực thi và thời gian |
Cả hai cách tiếp cận đều loại bỏ các lỗi vô hình ở cấp độ nến ngày nhưng quan trọng cho backtesting thực tế.
Tóm Tắt: So Sánh Cách Tiếp Cận Mô Phỏng Lệnh Khớp
| Cách tiếp cận | Độ chính xác | Tốc độ | Lưu trữ |
|---|---|---|---|
| OHLC heuristic (lạc quan/bi quan) | Thấp | Tức thì | Chỉ 1m |
| Backtest 1s đầy đủ | Cao | Chậm (x60) | ~550 MB/tháng |
| Backtest 100ms đầy đủ | Rất cao | Rất chậm (x600) | ~5 GB/tháng |
| Backtest raw trades đầy đủ | Tối đa | Cực kỳ chậm | ~50 GB/tháng |
| Adaptive drill-down (4 cấp) | Tối đa | ~Tức thì | 1m + 1s + 100ms hot + trades hot |
Drill-down cung cấp độ chính xác của backtest 1s đầy đủ ở tốc độ của backtest 1m. Quan sát chính: độ phân giải cao không cần thiết ở khắp nơi — chỉ tại các điểm quyết định.
Drill-Down Dựa trên Khối Lượng
Drill-down ban đầu chỉ kích hoạt dựa trên biến động giá — khi phạm vi [low, high] của nến đủ rộng để tạo ra mơ hồ lệnh khớp. Nhưng giá không phải là tín hiệu duy nhất cho thấy điều gì đó thú vị đã xảy ra trong một thanh.
Khối lượng tăng đột biến là một trigger quan trọng không kém. Một giây có khối lượng gấp 500 lần median thường tương ứng với lệnh thị trường lớn, cascade thanh lý, hoặc flash crash. Ngay cả khi thân nến trông nhỏ, đường giá thực tế trong giây đó có thể đã rất biến động — chạm các cực trị mà biểu diễn OHLC che giấu.
Điều kiện drill-down hiện là OR-based: biến động giá đáng kể HOẶC khối lượng bất thường đều kích hoạt việc đi xuống độ phân giải mịn hơn.
def is_hot(bar, median_volume, min_pct=0.1, vol_mult=500):
"""
Xác định xem một thanh có cần drill-down xuống cấp tiếp theo không.
Hai trigger độc lập (logic OR):
- giá biến động >= min_pct trong thanh
- khối lượng vượt median * vol_mult
"""
price_move = (bar['high'] - bar['low']) / bar['open'] * 100
return price_move >= min_pct or bar['volume'] >= median_volume * vol_mult
Điều này bắt được các tình huống vô hình với phát hiện chỉ dựa trên giá: một thanh với open=3000, close=3001 nhưng khối lượng gấp 50.000 lần mức bình thường có thể đã chạm thoáng qua 2950 và 3050 trong mili-giây. Nếu không có drill-down dựa trên khối lượng, backtest sẽ không bao giờ kiểm tra giây này kỹ hơn.
Giao Dịch Thô: Cấp Độ Thứ Tư
Hệ thống phân cấp ba cấp ban đầu (1m -> 1s -> 100ms) vẫn còn khoảng trống: trong một bucket 100ms, nhiều giao dịch có thể thực hiện ở các mức giá khác nhau. Đối với một bucket có high=3060 và low=2965, chúng ta vẫn không biết thứ tự chính xác.
Giải pháp: drill down xuống giao dịch thô là cấp độ thứ tư và cuối cùng.
Nến 1m (cơ sở)
└─> Nến 1s (khi 1s cho thấy price_move >= min_pct HOẶC volume >= median_1s * vol_mult)
└─> Nến 100ms (khi phát hiện hot second)
└─> Giao dịch thô (khi 100ms cho thấy price_move >= min_pct HOẶC volume >= median_100ms * vol_mult)
Ở cấp độ giao dịch thô, không có sự mơ hồ — mỗi giao dịch có giá và timestamp chính xác. Lệnh khớp được giải quyết dứt khoát:
def resolve_from_trades(trades, sl_price, tp_price, side):
"""
Duyệt qua các giao dịch riêng lẻ theo thứ tự thời gian.
Giao dịch đầu tiên vượt qua SL hoặc TP xác định lệnh khớp.
"""
for trade in trades:
price = trade['price']
if side == 'long':
if price <= sl_price:
return ('sl', price)
if price >= tp_price:
return ('tp', price)
else: # short
if price >= sl_price:
return ('sl', price)
if price <= tp_price:
return ('tp', price)
return None
Cấp độ giao dịch thô được gọi cực kỳ hiếm — ít hơn 0,1% tổng số thanh — nhưng khi được gọi, nó cung cấp dữ liệu thực tế mà không có phép xấp xỉ dựa trên nến nào có thể sánh kịp.
Ngưỡng Riêng Biệt cho Mỗi Chuyển Tiếp
Các chuyển tiếp độ phân giải khác nhau có đặc điểm khác nhau. Biến động giá 0,1% trong một giây là đáng kể; cùng 0,1% trong bucket 100ms là cực đoan. Tương tự, phân phối khối lượng khác nhau ở mỗi thang thời gian.
Mỗi chuyển tiếp cấp độ hiện có thông số min_pct và vol_mult riêng:
1s → 100ms: --min-pct-1s 0.1 --vol-mult-1s 500
100ms → trades: --min-pct-100ms 0.1 --vol-mult-100ms 500
Điều này cho phép tinh chỉnh độ nhạy của mỗi chuyển tiếp một cách độc lập. Trong thực tế, chuyển tiếp từ 100ms sang giao dịch có thể sử dụng ngưỡng chặt hơn vì chi phí tải giao dịch thô cho một bucket 100ms là tối thiểu.
@dataclass
class DrillDownConfig:
min_pct_1s: float = 0.1
vol_mult_1s: float = 500
min_pct_100ms: float = 0.1
vol_mult_100ms: float = 500
Thống Kê Median Bền Vững
Drill-down dựa trên khối lượng yêu cầu biết khối lượng median ở mỗi thang thời gian. Tính toán median ngay lập tức cho mỗi backtest sẽ phủ nhận lợi ích hiệu suất. Giải pháp: tính trước median một lần và cache chúng.
Đối với mỗi symbol, khối lượng median ở độ phân giải 1s và 100ms được tính từ dữ liệu lịch sử và lưu trong file stats.json:
{
"ETHUSDT": {
"median_volume_1s": 12.5,
"median_volume_100ms": 1.8
},
"BTCUSDT": {
"median_volume_1s": 0.45,
"median_volume_100ms": 0.06
}
}
Thống kê được tính một lần cho mỗi symbol khi dữ liệu được tải xuống lần đầu và tái sử dụng cho tất cả các backtest tiếp theo. Nếu dữ liệu được cập nhật (tháng mới được tải xuống), thống kê được tính lại gia tăng.
def compute_median_stats(symbol, data_dir):
"""Tính và cache thống kê khối lượng median cho một symbol."""
stats_path = f"{data_dir}/{symbol}/stats.json"
all_1s = load_all_months(f"{data_dir}/{symbol}/klines_1s/")
median_1s = all_1s['volume'].median()
all_100ms = load_all_months(f"{data_dir}/{symbol}/klines_100ms_hot/")
median_100ms = all_100ms['volume'].median()
stats = {
"median_volume_1s": float(median_1s),
"median_volume_100ms": float(median_100ms),
}
with open(stats_path, 'w') as f:
json.dump(stats, f, indent=2)
return stats

Hỗ Trợ Đa Sàn: Bybit
Không phải tất cả symbol đều có sẵn trên Binance. Đối với các tài sản như XAUTUSDT (vàng), dữ liệu phải đến từ các sàn giao dịch khác. Hệ thống drill-down hiện hỗ trợ Bybit như một nguồn dữ liệu thay thế.
Đối với các symbol Bybit, tất cả cấp độ nến (1m, 1s, 100ms) và giao dịch thô được xây dựng từ luồng giao dịch thô của Bybit. Quy trình giống nhau — giao dịch thô được tổng hợp thành nến ở mỗi thang thời gian — nhưng nguồn dữ liệu khác.
data/{SYMBOL}/
├── source.json # {"exchange": "bybit"} hoặc {"exchange": "binance"}
├── klines_1m/
│ └── ...
├── klines_1s/
│ └── ...
├── klines_100ms_hot/
│ └── ...
└── trades_hot/ # Giao dịch thô cho các bucket 100ms hot
└── ...
Bộ tải dữ liệu kiểm tra source.json và sử dụng pipeline tải xuống phù hợp. Từ góc độ của engine backtest, định dạng dữ liệu giống hệt nhau bất kể sàn nguồn — logic drill-down không phụ thuộc vào sàn giao dịch.
Điều này đặc biệt quan trọng cho các chiến lược đa sàn hoặc các symbol chỉ giao dịch trên một số sàn nhất định.
Kết Luận
Adaptive drill-down là ứng dụng của một nguyên tắc đơn giản: chi phí tài nguyên tính toán và lưu trữ tỷ lệ thuận với tầm quan trọng của dữ liệu.
Bốn cấp độ phân giải:
- 1m — lượt cơ sở cho 95% thanh
- 1s — drill-down trong mơ hồ lệnh khớp hoặc khối lượng tăng đột biến
- 100ms — drill-down cho hot second có biến động cực đoan hoặc khối lượng bất thường
- Giao dịch thô — drill-down cho các bucket 100ms hot, giải quyết lệnh khớp ở cấp độ giao dịch riêng lẻ
Bốn cấp độ lưu trữ:
- Tất cả 1m — lưu trữ đầy đủ, ~15 MB trong 2 năm
- Tất cả 1s — lưu trữ đầy đủ hoặc thích ứng, ~550 MB/tháng
- Chỉ 100ms hot — <1% giây, ~50 MB/tháng
- Chỉ trades hot — giao dịch thô cho các bucket 100ms cực đoan nhất
Hai trigger drill-down (logic OR):
- Dựa trên giá: phạm vi giá của thanh vượt
min_pct - Dựa trên khối lượng: khối lượng của thanh vượt
median * vol_mult
Kết quả: backtest với độ chính xác tick simulator ở tốc độ cấp phút. Lưu trữ tăng tuyến tính, không phải hàm mũ. Và hỗ trợ đa sàn — Binance và Bybit — với logic drill-down không phụ thuộc sàn giao dịch.
Để biết thêm về cache được tính trước cho chiến lược đa khung thời gian, xem bài viết Aggregated Parquet Cache. Về tác động của funding rate đến kết quả với đòn bẩy cao — Funding rates kill your leverage.
Liên Kết Hữu Ích
- Apache Parquet — định dạng lưu trữ dữ liệu
- Apache Arrow — mã hóa BYTE_STREAM_SPLIT
- Zstandard — thuật toán nén
- Lopez de Prado — Advances in Financial Machine Learning
- Binance — Historical Market Data
Trích Dẫn
@article{soloviov2026adaptivedrilldown,
author = {Soloviov, Eugen},
title = {Adaptive Drill-Down: Backtest with Variable Granularity from Minutes to Raw Trades},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/adaptive-resolution-drill-down-backtest},
description = {Cách độ phân giải dữ liệu thích ứng tăng tốc backtest và tiết kiệm lưu trữ: drill-down từ 1m xuống 1s, 100ms và giao dịch thô chỉ ở nơi giá biến động đáng kể hoặc khối lượng tăng đột biến.}
}
Tác Giả

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Đọc Thêm

Bộ nhớ đệm Parquet tổng hợp: Cách tăng tốc backtest đa khung thời gian lên hàng trăm lần

Phân Tích Plateau: Cách Phân Biệt Tối Ưu Bền Vững với Overfitting
