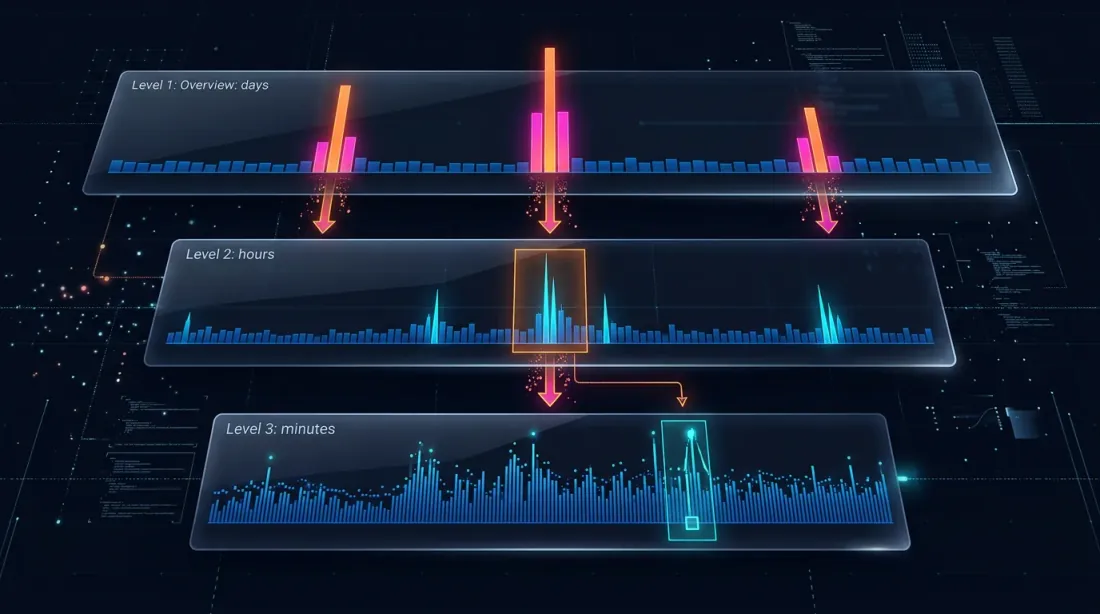
Uyarlanabilir Drill-Down: Dakikadan Ham İşlemlere Değişken Granülerlikle Backtest
Dakika mum çubukları, backtestler için standart granülerlik düzeyidir. Ancak tek bir dakika mum çubuğu içinde fiyat farklı şekillerde hareket edebilir: bazen %0,01, bazen %2. Hem stop-loss hem de take-profit tek bir dakika mum çubuğunun [low, high] aralığına düştüğünde, backtest hangisinin önce tetiklendiğini bilemez. Bu, emir gerçekleşme belirsizliği sorunudur.
Saf çözüm, tüm backtest için saniye düzeyindeki verilere geçmektir. Ancak iki yıl boyunca bu, ~1 milyon dakika çubuğu yerine ~63 milyon saniye çubuğu anlamına gelir. Depolama 60 kat artar, hız orantılı olarak düşer.
Uyarlanabilir drill-down bu sorunu çözer: ince granülerliği yalnızca gerçekten gerekli olan yerde kullanın.
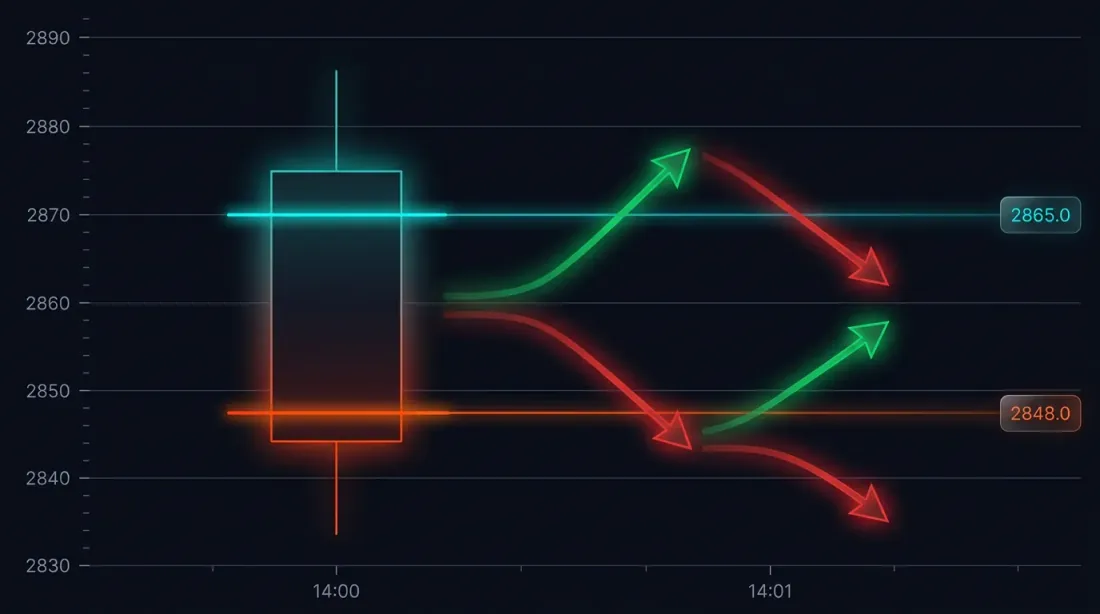
Sorun: Büyük Mum Çubuklarında Emir Gerçekleşme Belirsizliği
Belirli bir durumu ele alalım. Strateji 3000 USDT'de long açtı. Stop-loss: 2970 (-%1). Take-profit: 3060 (+%2).
14:37'deki dakika mum çubuğu:
- Açılış: 3010
- Yüksek: 3065
- Düşük: 2965
- Kapanış: 3050
Hem SL (2970) hem de TP (3060), [2965, 3065] aralığına düşüyor. Hangisi önce tetiklendi?
Olası sonuçlar:
- Fiyat önce aşağı gitti -> SL tetiklendi -> -%1 zarar
- Fiyat önce yukarı gitti -> TP tetiklendi -> +%2 kâr
Tek bir işlemdeki fark: 3 yüzde puanı. 10x kaldıraçla — %30. Yüzlerce işlem içeren bir backtestte, yanlış emir gerçekleşme belirsizliği çözümü sonuçları sistematik olarak çarpıtır.
Frameworkler Bunu Varsayılan Olarak Nasıl Ele Alır
Çoğu backtest motoru iki sezgisel yöntemden birini kullanır:
- İyimser: TP önce tetiklenir -> şişirilmiş sonuçlar
- Kötümser: SL önce tetiklenir -> düşürülmüş sonuçlar
Her iki yaklaşım da tahmindir. Gerçek veri saniye hatta milisaniye düzeyinde mevcuttur ve bakabilecekken tahmin etmeye gerek yoktur.
Drill-Down: Dört Seviyeli Strateji

Drill-down fikri: dakika düzeyinde başla ve yalnızca belirsizlik olduğunda — fiyat hareketi ya da hacim ani yükselişi nedeniyle — daha alt seviyeye "in".
Seviye 1: 1m (dakika mum çubukları)
-> SL veya TP [low, high] aralığının kesin olarak dışındaysa — yerinde çöz
-> Her ikisi de aralık içindeyse — drill-down yap
Seviye 2: 1s (saniye mum çubukları)
-> Bu dakika için 60 saniye çubuğu yükle
-> Saniye saniye geç: hangisi önce tetiklendi?
-> Bir saniye çubuğu belirsizse, VEYA price_move >= min_pct, VEYA volume >= median_1s * vol_mult — drill-down yap
Seviye 3: 100ms (milisaniye mum çubukları)
-> Bu saniye için 10'a kadar 100ms çubuğu yükle
-> 100ms'den 100ms'ye geç
-> Bir 100ms çubuğu belirsizse, VEYA price_move >= min_pct, VEYA volume >= median_100ms * vol_mult — drill-down yap
Seviye 4: Ham işlemler
-> Bu 100ms dilimi için tekil işlemleri yükle
-> Emir gerçekleşmesini işlem bazında çöz — maksimum olası hassasiyet
Drill-Down'ın Gerekmediği Durumlar
Vakaların %95'inde drill-down gerekmez. Tipik senaryolar:
Kesin SL: mum çubuğu yükseği TP'ye ulaşmıyor, düşüğü SL'yi kırıyor -> SL tetiklendi, drill-down gerekmiyor.
Kesin TP: düşük SL'ye ulaşmıyor, yüksek TP'yi kırıyor -> TP tetiklendi, drill-down gerekmiyor.
Hiçbiri tetiklenmedi: her iki seviye de aralığın dışında -> pozisyon açık kalır.
Gap tespiti: bir sonraki mum çubuğunun açılışı SL veya TP'yi atlıyor -> açılış fiyatında gerçekleşme, drill-down gerekmiyor.
Drill-down yalnızca yaklaşık %5 çubuğunda gereklidir — her iki seviye de tek bir mum çubuğunun aralığına düştüğünde.
class AdaptiveFillSimulator:
"""
Emir gerçekleşme sırası belirlemek için dört seviyeli drill-down.
"""
def __init__(self, data_loader):
self.loader = data_loader
self.cache_1s = {} # Aya göre saniye verisi önbelleği
def check_fill(self, timestamp, candle_1m, sl_price, tp_price, side):
"""
Verilen dakika mum çubuğunda SL veya TP'nin tetiklenip tetiklenmediğini kontrol eder.
Döndürür: ('sl', fill_price) | ('tp', fill_price) | None
"""
low, high = candle_1m['low'], candle_1m['high']
open_price = candle_1m['open']
if side == 'long':
if open_price <= sl_price:
return ('sl', open_price)
if open_price >= tp_price:
return ('tp', open_price)
else:
if open_price >= sl_price:
return ('sl', open_price)
if open_price <= tp_price:
return ('tp', open_price)
sl_hit = self._level_hit(sl_price, low, high, side, 'sl')
tp_hit = self._level_hit(tp_price, low, high, side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if not sl_hit and not tp_hit:
return None
return self._drill_down_1s(timestamp, sl_price, tp_price, side)
def _drill_down_1s(self, minute_ts, sl_price, tp_price, side):
"""Seviye 2: saniye saniye geçiş."""
bars_1s = self.loader.load_1s_for_minute(minute_ts)
if bars_1s is None or len(bars_1s) == 0:
return self._pessimistic_fill(side, sl_price, tp_price)
for bar in bars_1s:
sl_hit = self._level_hit(sl_price, bar['low'], bar['high'], side, 'sl')
tp_hit = self._level_hit(tp_price, bar['low'], bar['high'], side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if sl_hit and tp_hit:
result = self._drill_down_100ms(bar['timestamp'], sl_price, tp_price, side)
if result:
return result
return self._pessimistic_fill(side, sl_price, tp_price)
def _pessimistic_fill(self, side, sl_price, tp_price):
"""Kötümser varsayım: longlar için SL, shortlar için TP."""
if side == 'long':
return ('sl', sl_price)
else:
return ('sl', sl_price)
Performans
| Mod | Emir gerçekleşme kontrolü başına süre | Ne zaman kullanılır |
|---|---|---|
| 1m (drill-down yok) | ~0ms | Vakaların ~%95'i |
| 1s drill-down | ~5ms (aya ilk erişimde) | Vakaların ~%5'i |
| 100ms drill-down | ~1ms | <%0,5 vaka |
| Ham işlem drill-down | ~0,5ms | <%0,1 vaka |
~400 işlem içeren 2 yıllık bir backtestte, drill-down yaklaşık 20 mum çubuğu için çağrılır. Toplam ek yük — tüm backtest için 1 saniyeden az.
Uyarlanabilir Veri Depolama
Drill-down, saniye ve milisaniye verisi gerektirir. Ancak her şeyi maksimum granülerlikte depolamak pratik değildir:
| Granülerlik | 2 yıllık çubuk sayısı | Parquet boyutu |
|---|---|---|
| 1m | ~1,05M | ~15 MB |
| 1s | ~63M | ~550 MB/ay |
| 100ms | ~630M | ~5 GB/ay |
2 yıllık eksiksiz 1s arşivi yaklaşık 13 GB'dir. 100ms — 100 GB'ın üzerinde. Her şeyi depolamak mümkündür ancak drill-down'ın bu verinin %1'inden azını kullandığı düşünüldüğünde israftır.
Sıcak Saniye Tespiti
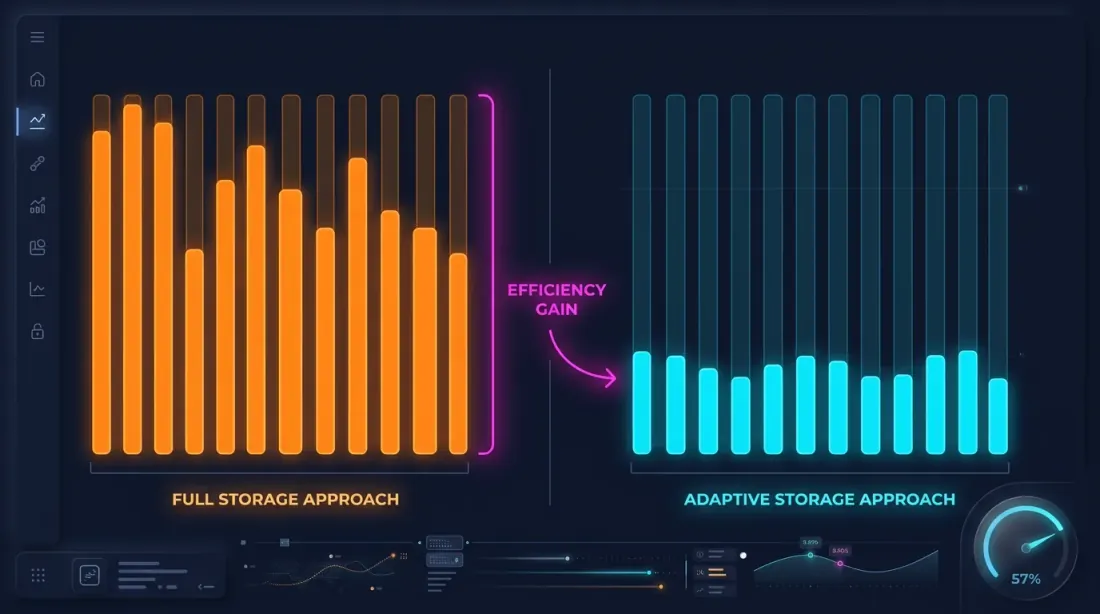
Temel gözlem: fiyatın önemli ölçüde hareket ettiği saniyeler küçük bir kesimi oluşturur. Bir saniye içinde fiyat %0,1'den az değiştiyse — o saniye için 100ms dağılımını depolamanın anlamı yoktur.
Sıcak saniye tespiti: veri indirip işlerken her saniyeyi analiz ederiz ve 100ms mum çubuklarını yalnızca "sıcak" saniyeler için oluştururuz — fiyat hareketi eşiği aşan saniyeler.
def process_trades_adaptive(
trades: pd.DataFrame,
min_price_change_pct: float = 1.0,
) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Ham işlemleri uyarlanabilir bir yapıya işler:
- Tüm saniyeler için 1s mum çubukları
- Yalnızca "sıcak" saniyeler için 100ms mum çubukları
Args:
trades: [timestamp, price, quantity] sütunlarına sahip DataFrame
min_price_change_pct: 100ms'ye drill-down için eşik
Döndürür:
(df_1s, df_100ms_hot) — saniye mum çubukları ve sıcak saniyeler için 100ms
"""
trades['second'] = trades['timestamp'].dt.floor('1s')
df_1s = trades.groupby('second').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
df_1s['price_change_pct'] = (df_1s['high'] - df_1s['low']) / df_1s['open'] * 100
hot_seconds = df_1s[df_1s['price_change_pct'] >= min_price_change_pct].index
hot_trades = trades[trades['second'].isin(hot_seconds)]
hot_trades['bucket_100ms'] = hot_trades['timestamp'].dt.floor('100ms')
df_100ms = hot_trades.groupby('bucket_100ms').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
return df_1s, df_100ms
Depolama Tasarrufları
Örneğin — tipik bir ayda ETHUSDT:
| Yaklaşım | Boyut | Granülerlik |
|---|---|---|
| Yalnızca 1m | ~1 MB | 1 dakika |
| Tüm 1s | ~550 MB | 1 saniye |
| Tüm 100ms | ~5 GB | 100 ms |
| Uyarlanabilir | ~600 MB | 1s + yalnızca sıcak saniyeler için 100ms |
min_price_change_pct = 1,0% eşiğiyle, sıcak saniyeler tüm saniyelerin %1'inden azını oluşturur. Onlar için 100ms verisi, 550 MB saniye verisine ~50 MB ekler — ihmal edilebilir bir ek yük.
Saniye verisi de uyarlanabilir şekilde (yalnızca bir dakika içindeki hareket %0,1'i aşıyorsa) depolanırsa, hacim 3-5 kat daha azaltılabilir.
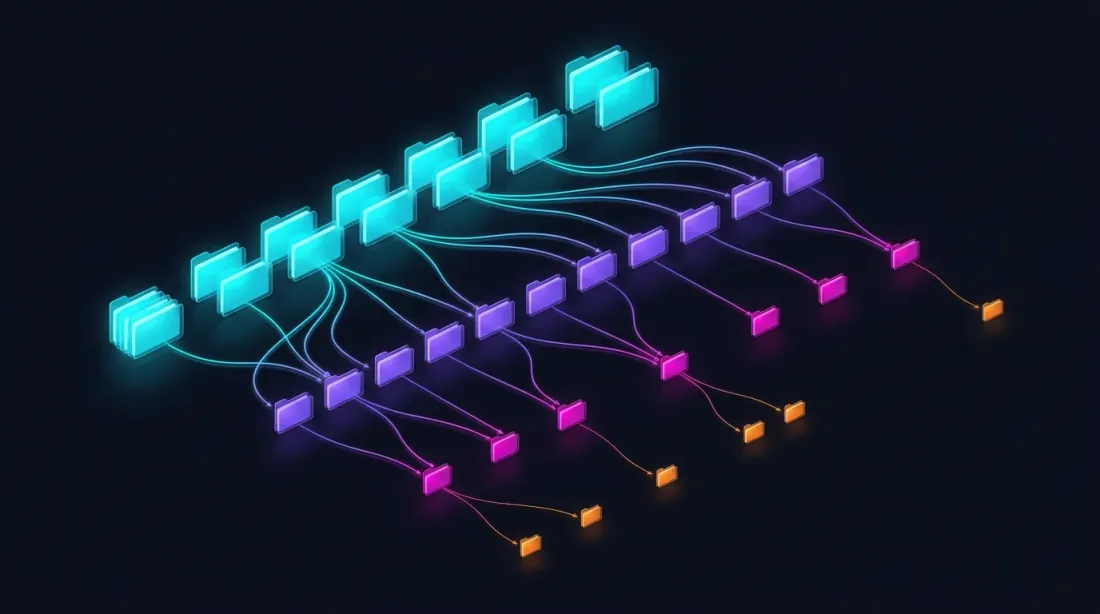
Parquet Depolama Yapısı
data/{SYMBOL}/
├── source.json # Borsa kaynağı: {"exchange": "binance"} veya {"exchange": "bybit"}
├── stats.json # Önceden hesaplanmış medyan hacimler: {"median_volume_1s": ..., "median_volume_100ms": ...}
├── klines_1m/
│ ├── 2024-01.parquet # ~1 MB
│ ├── 2024-02.parquet
│ └── ...
├── klines_1s/
│ ├── 2024-01.parquet # ~550 MB
│ └── ...
├── klines_100ms_hot/
│ ├── 2024-01.parquet # ~50 MB (yalnızca sıcak saniyeler)
│ └── ...
├── trades_hot/
│ ├── 2024-01.parquet # Sıcak 100ms dilimleri için ham işlemler
│ └── ...
└── states_1m.parquet # Önceden hesaplanmış kayan durum önbelleği (~112 MB)
Her dosya bir aylık veriyi kapsar. Saniye, milisaniye ve işlem verisi tembel yüklenir — yalnızca drill-down talep ettiğinde. stats.json dosyası, hacim tabanlı drill-down tetikleyicileri için kullanılan önceden hesaplanmış medyan hacimleri içerir.
Finansal Veri için Parquet Optimizasyonu
Finansal verinin belirli özellikleri vardır: zaman damgaları monoton olarak artar, fiyatlar düzgünce değişir, hacimler önemli ölçüde değişir. Optimal ayarlar:
import pyarrow as pa
import pyarrow.parquet as pq
schema = pa.schema([
pa.field("timestamp", pa.int32()), # Epoch'tan saniyeler — int32 yeterli
pa.field("open", pa.float32()),
pa.field("high", pa.float32()),
pa.field("low", pa.float32()),
pa.field("close", pa.float32()),
pa.field("volume", pa.float32()),
])
column_encodings = {
"timestamp": "DELTA_BINARY_PACKED", # Monoton int -> delta sıkıştırma
"open": "BYTE_STREAM_SPLIT", # Float -> bayt akışı bölme
"high": "BYTE_STREAM_SPLIT",
"low": "BYTE_STREAM_SPLIT",
"close": "BYTE_STREAM_SPLIT",
"volume": "BYTE_STREAM_SPLIT",
}
def save_optimized_parquet(df, path):
table = pa.Table.from_pandas(df, schema=schema)
pq.write_table(
table, path,
compression="zstd",
compression_level=9,
use_dictionary=False,
write_statistics=False,
column_encoding=column_encodings,
)
Bu ayarların nedeni:
- Zaman damgaları için DELTA_BINARY_PACKED: ardışık zaman damgaları sabit bir değer kadar farklılık gösterir (1m için 60, 1s için 1). Delta kodlaması onları neredeyse sıfıra sıkıştırır.
- Float için BYTE_STREAM_SPLIT: float32 baytlarını akışlara böler (tüm ilk baytlar bir arada, tüm ikinci baytlar bir arada, vb.). Düzgünce değişen fiyatlar için standart kodlamaya göre 2-3 kat daha iyi sıkıştırma sağlar.
- ZSTD seviye 9: kabul edilebilir sıkıştırma açma hızıyla iyi sıkıştırma.
- float64 yerine float32: fiyatlar ve hacimler için yeterli, %50 bellek tasarrufu sağlar.
Önbelleklemeyle Tembel Yükleme
Drill-down, belirli bir dakika için saniye verisi talep eder. Her talep için bir parquet dosyası yüklemek yavaştır. Çözüm — aya göre LRU önbelleğiyle tembel yükleme.
from functools import lru_cache
import pyarrow.parquet as pq
import pandas as pd
class AdaptiveDataLoader:
"""
Önbellekli tembel yükleyici: saniye verisini aya göre yükler,
son N ayı bellekte tutar.
"""
def __init__(self, symbol: str, data_dir: str = "data", cache_months: int = 2):
self.symbol = symbol
self.data_dir = data_dir
self.cache_months = cache_months
self._cache_1s: dict[str, pd.DataFrame] = {}
def load_1s_for_minute(self, minute_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Belirli bir dakika için 1s verisini yükle."""
month_key = minute_ts.strftime("%Y-%m")
if month_key not in self._cache_1s:
self._load_month_1s(month_key)
if month_key not in self._cache_1s:
return None
df = self._cache_1s[month_key]
minute_start = minute_ts.floor('1min')
minute_end = minute_start + pd.Timedelta(minutes=1)
return df[(df.index >= minute_start) & (df.index < minute_end)]
def load_100ms_for_second(self, second_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Sıcak bir saniye için 100ms verisi yükle."""
month_key = second_ts.strftime("%Y-%m")
path = f"{self.data_dir}/{self.symbol}/klines_100ms_hot/{month_key}.parquet"
try:
df = pd.read_parquet(path)
second_start = second_ts.floor('1s')
second_end = second_start + pd.Timedelta(seconds=1)
return df[(df.index >= second_start) & (df.index < second_end)]
except FileNotFoundError:
return None
def _load_month_1s(self, month_key: str):
"""1s verisinin bir ayını yükle, önbellekten eski veriyi çıkar."""
path = f"{self.data_dir}/{self.symbol}/klines_1s/{month_key}.parquet"
try:
df = pd.read_parquet(path)
df.index = pd.to_datetime(df['timestamp'], unit='s')
if len(self._cache_1s) >= self.cache_months:
oldest = min(self._cache_1s.keys())
del self._cache_1s[oldest]
self._cache_1s[month_key] = df
except FileNotFoundError:
pass
Drill-Down'ın Backtesting'e Uygulanması
Backtest döngüsüne entegrasyon:
def backtest_with_adaptive_fill(
states: pd.DataFrame,
strategy_params: dict,
data_loader: AdaptiveDataLoader,
) -> list:
"""
Emir gerçekleşme simülasyonu için uyarlanabilir drill-down ile backtest.
"""
fill_sim = AdaptiveFillSimulator(data_loader)
trades = []
position = None
for i in range(len(states)):
row = states.iloc[i]
ts = states.index[i]
candle_1m = {
'open': row['open'], 'high': row['high'],
'low': row['low'], 'close': row['close'],
'timestamp': ts,
}
if position is not None:
fill = fill_sim.check_fill(
ts, candle_1m,
position['sl'], position['tp'],
position['side'],
)
if fill is not None:
fill_type, fill_price = fill
trades.append({
'entry_time': position['entry_time'],
'exit_time': ts,
'side': position['side'],
'entry_price': position['entry_price'],
'exit_price': fill_price,
'exit_type': fill_type,
'drill_down': fill_sim.last_drill_depth, # 0, 1 veya 2
})
position = None
continue
signal = check_entry_signal(row, strategy_params)
if signal and position is None:
position = {
'side': signal['side'],
'entry_price': row['close'],
'entry_time': ts,
'sl': signal['sl'],
'tp': signal['tp'],
}
return trades
Kayan Durum Önbelleğiyle İlişki
Drill-down, toplanmış parquet önbelleğini tamamlar — farklı sorunları çözerler:
| Kayan durum önbelleği | Uyarlanabilir drill-down | |
|---|---|---|
| Amaç | Doğru HTF gösterge değerleri | Kesin SL/TP gerçekleşme sırası |
| Çalıştığı yer | Her 1m mum çubuğu | Yalnızca emir gerçekleşme belirsizliğinde (~%5) |
| Veri | Önceden hesaplanmış, kalıcı depolanmış | Tembel yüklenen, son ayların önbelleği |
| Etkiler | Giriş/çıkış sinyalleri | Gerçekleşme fiyatı ve zamanı |
Her iki yaklaşım da günlük mum çubuğu düzeyinde görünmez olan ancak gerçekçi backtesting için kritik olan hataları ortadan kaldırır.
Özet: Emir Gerçekleşme Simülasyonu Yaklaşımı Karşılaştırması
| Yaklaşım | Doğruluk | Hız | Depolama |
|---|---|---|---|
| OHLC sezgisel (iyimser/kötümser) | Düşük | Anlık | Yalnızca 1m |
| Tam 1s backtesti | Yüksek | Yavaş (x60) | ~550 MB/ay |
| Tam 100ms backtesti | Çok yüksek | Çok yavaş (x600) | ~5 GB/ay |
| Tam ham işlem backtesti | Maksimum | Son derece yavaş | ~50 GB/ay |
| Uyarlanabilir drill-down (4 seviyeli) | Maksimum | ~Anlık | 1m + 1s + 100ms sıcak + işlemler sıcak |
Drill-down, tam 1s backtest doğruluğunu 1m backtest hızında sağlar. Temel gözlem: yüksek granülerlik her yerde değil — yalnızca karar noktalarında gereklidir.
Hacim Tabanlı Drill-Down
Orijinal drill-down yalnızca fiyat hareketini tetikler — bir mum çubuğunun [low, high] aralığı emir gerçekleşme belirsizliği yaratacak kadar genişse. Ancak fiyat, bir çubuk içinde ilginç bir şeyler olduğunun tek sinyali değildir.
Hacim ani yükselişleri eşit derecede önemli bir tetikleyicidir. Hacmin medyanın 500 katı olduğu bir saniye genellikle büyük bir piyasa emrine, tasfiye zincirine veya ani çöküşe karşılık gelir. Mum gövdesi küçük görünse bile, o saniye içindeki gerçek fiyat yolu vahşi olmuş olabilir — OHLC gösteriminin gizlediği aşırı uçlara dokunmuş olabilir.
Drill-down koşulu artık VEYA tabanlı: önemli bir fiyat hareketi VEYA anormal bir hacim ani yükselişi daha ince granülerliğe inişi tetikler.
def is_hot(bar, median_volume, min_pct=0.1, vol_mult=500):
"""
Bir çubuğun bir sonraki seviyeye drill-down'ı hak edip etmediğini belirler.
İki bağımsız tetikleyici (VEYA mantığı):
- fiyat çubuk içinde >= min_pct hareket etti
- hacim medyan * vol_mult'u aştı
"""
price_move = (bar['high'] - bar['low']) / bar['open'] * 100
return price_move >= min_pct or bar['volume'] >= median_volume * vol_mult
Bu, yalnızca fiyat tespitinde görünmez olan senaryoları yakalar: open=3000, close=3001 ama hacmi normun 50.000 katı olan bir çubuk, milisaniyeler içinde kısaca 2950 ve 3050'ye dokunmuş olabilir. Hacim tabanlı drill-down olmadan, backtest bu saniyeyi hiçbir zaman daha yakından incelemezdi.
Ham İşlemler: Dördüncü Seviye
Orijinal üç seviyeli hiyerarşi (1m -> 1s -> 100ms) hâlâ bir boşluk bırakır: tek bir 100ms dilimi içinde, birden fazla işlem farklı fiyatlarda gerçekleşebilir. high=3060 ve low=2965 olan bir dilim için, hâlâ tam sırayı bilmiyoruz.
Çözüm: dördüncü ve son seviye olarak ham işlemlere drill-down.
1m mum çubukları (taban)
└─> 1s mum çubukları (1s price_move >= min_pct VEYA volume >= median_1s * vol_mult gösterdiğinde)
└─> 100ms mum çubukları (sıcak saniye tespit edildiğinde)
└─> Ham işlemler (100ms price_move >= min_pct VEYA volume >= median_100ms * vol_mult gösterdiğinde)
Ham işlemler düzeyinde belirsizlik yoktur — her işlemin tam fiyatı ve zaman damgası vardır. Emir gerçekleşmesi kesin olarak çözülür:
def resolve_from_trades(trades, sl_price, tp_price, side):
"""
Tekil işlemleri kronolojik sırayla geç.
SL veya TP'yi geçen ilk işlem gerçekleşmeyi belirler.
"""
for trade in trades:
price = trade['price']
if side == 'long':
if price <= sl_price:
return ('sl', price)
if price >= tp_price:
return ('tp', price)
else: # short
if price >= sl_price:
return ('sl', price)
if price <= tp_price:
return ('tp', price)
return None
Ham işlemler düzeyi son derece nadir çağrılır — tüm çubukların %0,1'inden az — ancak çağrıldığında, hiçbir mum tabanlı yaklaşımın eşleşemeyeceği temel gerçeği sağlar.
Geçiş Başına Ayrı Eşikler
Farklı çözünürlük geçişlerinin farklı özellikleri vardır. Bir saniye içindeki %0,1'lik fiyat hareketi önemlidir; aynı %0,1'lik hareket 100ms diliminde aşırıdır. Benzer şekilde, hacim dağılımları her zaman ölçeğinde farklılık gösterir.
Her seviye geçişinin artık kendi min_pct ve vol_mult parametreleri vardır:
1s → 100ms: --min-pct-1s 0.1 --vol-mult-1s 500
100ms → işlemler: --min-pct-100ms 0.1 --vol-mult-100ms 500
Bu, her geçişin hassasiyetini bağımsız olarak ince ayar yapma imkânı tanır. Pratikte, tek bir 100ms dilimi için ham işlem yüklemenin maliyeti minimum olduğundan, 100ms'den işlemlere geçiş daha sıkı bir eşik kullanabilir.
@dataclass
class DrillDownConfig:
min_pct_1s: float = 0.1
vol_mult_1s: float = 500
min_pct_100ms: float = 0.1
vol_mult_100ms: float = 500
Kalıcı Medyan İstatistikleri
Hacim tabanlı drill-down, her zaman ölçeğinde medyan hacmi bilmeyi gerektirir. Her backtest için anlık medyan hesaplamak performans avantajlarını ortadan kaldırır. Çözüm: medyanları bir kez önceden hesapla ve önbelleğe al.
Her sembol için, 1s ve 100ms granülerliğindeki medyan hacimler tarihsel verilerden hesaplanır ve bir stats.json dosyasında depolanır:
{
"ETHUSDT": {
"median_volume_1s": 12.5,
"median_volume_100ms": 1.8
},
"BTCUSDT": {
"median_volume_1s": 0.45,
"median_volume_100ms": 0.06
}
}
İstatistikler veri ilk indirildiğinde sembol başına bir kez hesaplanır ve sonraki tüm backtestlerde yeniden kullanılır. Veri güncellenirse (yeni aylar indirilirse), istatistikler artımlı olarak yeniden hesaplanır.
def compute_median_stats(symbol, data_dir):
"""Bir sembol için medyan hacim istatistiklerini hesapla ve önbelleğe al."""
stats_path = f"{data_dir}/{symbol}/stats.json"
all_1s = load_all_months(f"{data_dir}/{symbol}/klines_1s/")
median_1s = all_1s['volume'].median()
all_100ms = load_all_months(f"{data_dir}/{symbol}/klines_100ms_hot/")
median_100ms = all_100ms['volume'].median()
stats = {
"median_volume_1s": float(median_1s),
"median_volume_100ms": float(median_100ms),
}
with open(stats_path, 'w') as f:
json.dump(stats, f, indent=2)
return stats

Çok Borsa Desteği: Bybit
Tüm semboller Binance'te mevcut değildir. XAUTUSDT (altın) gibi varlıklar için veri başka borsalardan gelmek zorundadır. Drill-down sistemi artık alternatif bir veri kaynağı olarak Bybit'i desteklemektedir.
Bybit sembolleri için, tüm mum düzeyleri (1m, 1s, 100ms) ve ham işlemler Bybit'in ham işlem akışından oluşturulur. Süreç aynıdır — ham işlemler her zaman ölçeğinde mum çubuklarına toplanır — ancak veri kaynağı farklıdır.
data/{SYMBOL}/
├── source.json # {"exchange": "bybit"} veya {"exchange": "binance"}
├── klines_1m/
│ └── ...
├── klines_1s/
│ └── ...
├── klines_100ms_hot/
│ └── ...
└── trades_hot/ # Sıcak 100ms dilimleri için ham işlemler
└── ...
Veri yükleyici source.json'u kontrol eder ve uygun indirme pipeline'ını kullanır. Backtest motorunun bakış açısından, kaynak borsadan bağımsız olarak veri formatı aynıdır — drill-down mantığı borsadan bağımsızdır.
Bu, çapraz borsa stratejileri veya yalnızca belirli platformlarda işlem gören semboller için özellikle önemlidir.
Sonuç
Uyarlanabilir drill-down, basit bir ilkenin uygulamasıdır: hesaplama kaynakları ve depolamayı veri önemine orantılı olarak harca.
Dört granülerlik seviyesi:
- 1m — çubukların %95'i için temel geçiş
- 1s — emir gerçekleşme belirsizliğinde veya hacim ani yükselişlerinde drill-down
- 100ms — aşırı hareket veya anormal hacimli sıcak saniyeler için drill-down
- Ham işlemler — sıcak 100ms dilimleri için drill-down, tekil işlem düzeyinde gerçekleşmeleri çözme
Dört depolama seviyesi:
- Tüm 1m — eksiksiz arşiv, 2 yıl için ~15 MB
- Tüm 1s — eksiksiz veya uyarlanabilir arşiv, ~550 MB/ay
- Yalnızca sıcak 100ms — saniyelerin <%1'i, ~50 MB/ay
- Yalnızca sıcak işlemler — en aşırı 100ms dilimleri için ham işlemler
İki drill-down tetikleyicisi (VEYA mantığı):
- Fiyat tabanlı: çubuğun fiyat aralığı
min_pct'i aşıyor - Hacim tabanlı: çubuğun hacmi
medyan * vol_mult'u aşıyor
Sonuç: dakika düzeyinde hızda tick simülatörü doğruluğuyla backtest. Üstel değil doğrusal büyüyen depolama. Ve Binance ve Bybit — borsadan bağımsız drill-down mantığıyla çoklu borsa desteği.
Çoklu zaman dilimi stratejileri için önceden hesaplanmış önbellek hakkında daha fazla bilgi için Toplanmış Parquet Önbelleği makalesine bakın. Yüksek kaldıraçla sonuçlar üzerindeki fonlama oranı etkisi için — Fonlama oranları kaldıracınızı öldürür.
Faydalı Bağlantılar
- Apache Parquet — veri depolama formatı
- Apache Arrow — BYTE_STREAM_SPLIT kodlaması
- Zstandard — sıkıştırma algoritması
- Lopez de Prado — Finansal Makine Öğrenmesinde Gelişmeler
- Binance — Tarihsel Piyasa Verisi
Atıf
@article{soloviov2026adaptivedrilldown,
author = {Soloviov, Eugen},
title = {Adaptive Drill-Down: Backtest with Variable Granularity from Minutes to Raw Trades},
year = {2026},
url = {https://marketmaker.cc/tr/blog/post/adaptive-resolution-drill-down-backtest},
description = {Uyarlanabilir veri granülerliğinin backtestleri nasıl hızlandırdığı ve depolama alanını nasıl tasarruf ettirdiği: yalnızca fiyatın önemli ölçüde hareket ettiği veya hacmin ani yükseldiği yerlerde 1m'den 1s, 100ms ve ham işlemlere drill-down.}
}
Yazarlar

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Daha Fazla Oku

Toplu Parquet Önbelleği: Çoklu Zaman Dilimi Backtestlerini Yüzlerce Kat Nasıl Hızlandırırsınız

Walk-Forward Optimizasyonu: Tek Dürüst Strateji Testi
