Parità backtest-live: perché il tuo bot fa trading in modo diverso dal backtest

Hai eseguito una strategia nel backtest. Sharpe 2,1, MaxDD -8%, PnL +67%. Hai lanciato il bot. Un mese dopo confronti i risultati: stessi segnali, stesso periodo — ma il PnL live è inferiore del 40%. Il drawdown è una volta e mezza più profondo. Due operazioni su dieci non sono state eseguite affatto.
Non è un bug. È la divergenza backtest-live — una discrepanza sistematica tra i risultati del backtest e il trading reale. Ce l'hanno tutti. L'unica domanda è se lo sai e se riesci a controllarlo.
Questo articolo fornisce una tassonomia completa delle divergenze, pattern architetturali per minimizzarle e una checklist pratica per il monitoraggio della parità in produzione.
La sindrome del "funzionava nel backtest"

Ogni algotrader attraversa questo ciclo:
- Ha scritto una strategia in un Jupyter notebook
- Ha eseguito un backtest su dati CSV storici — i risultati sono ottimi
- Ha riscritto la logica come bot (spesso in un linguaggio o framework diverso)
- Ha lanciato — i risultati non corrispondono
- Ha iniziato a cercare un bug, non lo ha trovato — "il mercato è cambiato"
Il problema non è il mercato. Il problema è che il backtest e il bot sono due prodotti software diversi che modellano la stessa realtà in modo diverso. Le divergenze sono inevitabili, ma possono essere sistematizzate e minimizzate.
Tassonomia delle Divergenze

Tutte le fonti di divergenza rientrano in quattro categorie. Per ciascuna — un rating di gravità (da 1 a 5) e un contributo tipico alla divergenza del PnL.
1. Divergenze dei dati (gravità: 3/5)
I dati che il backtest vede e i dati che il bot vede in tempo reale non sono la stessa cosa.
Timestamp. Gli exchange consegnano le candele con regole diverse per l'assegnazione del timestamp. Un exchange marca la candela con l'inizio del periodo, un altro con la fine. Una REST API può restituire una candela con un ritardo di 1-3 secondi dopo la chiusura effettiva. Il backtest lavora con timestamp "ideali" dal file storico.
Aggregazione OHLCV. I dati storici sono spesso aggregati dal provider in modo diverso rispetto a come fa l'exchange in tempo reale. La differenza è nell'ultima cifra — ma con segnali di soglia (crossover MA, breakout di livello) questo determina se la strategia entra in posizione o meno.
Gap e dati mancanti. I dati storici sono solitamente puliti — le candele mancanti vengono riempite per interpolazione. In tempo reale, un WebSocket può cadere e il bot perde 30 secondi di dati.
Contributo tipico alla divergenza del PnL: 2-5% del PnL annuo.
2. Divergenze di esecuzione (gravità: 5/5)
La classe di divergenze più pericolosa. Il backtest simula l'esecuzione perfettamente — la realtà è ben lontana dall'ideale.
Slippage. Il backtest riempie l'ordine al prezzo di chiusura (o al prezzo del segnale). In realtà, un ordine di mercato viene eseguito al miglior bid/ask più lo slippage che dipende dal volume e dalla liquidità. Per una posizione da $10K su un altcoin a liquidità media, lo slippage può essere dello 0,05-0,3%.
Formula per lo slippage cumulativo su trade:
dove è lo slippage dell'-esimo trade, dipendente dalla profondità dell'orderbook:
Latenza. Dal momento in cui viene generato un segnale all'esecuzione dell'ordine trascorre del tempo: calcolo del segnale (1-50 ms), trasmissione della richiesta (10-200 ms), matching sull'exchange (1-10 ms). Nel backtest, la latenza = 0. In live — il prezzo può muoversi.
Fill parziali. Il backtest assume che il 100% dell'ordine venga riempito istantaneamente. In realtà, un ordine limite potrebbe essere parzialmente riempito — o non riempito affatto se il prezzo si inverte. Per un ordine di mercato su un mercato illiquido, l'ordine "scivola" attraverso più livelli dell'orderbook.
Priorità di coda. Un ordine limite piazzato al prezzo del miglior bid non verrà riempito immediatamente — fa la coda dietro tutti gli ordini precedentemente piazzati a quel livello. Un backtest che considera "il prezzo è stato toccato = ordine riempito" sopravvaluta sistematicamente il tasso di riempimento.
Contributo tipico alla divergenza del PnL: 10-30% del PnL annuo.
3. Divergenze di logica (gravità: 4/5)
Queste sono divergenze nel codice della strategia stessa tra il backtest e il bot.
Codebase separate. L'anti-pattern classico: backtests/strategy_a.py e bot/strategy_a.py — due file separati che "fanno la stessa cosa". Dopo tre mesi di modifiche, inevitabilmente divergono. Qualcuno ha aggiunto un filtro nel backtest e si è dimenticato di replicarlo nel bot. O il contrario — un bug è stato corretto nel bot ma è rimasto nel backtest.
Framework diversi. Backtest su pandas con operazioni vettorializzate, bot su asyncio con logica event-driven. Anche con una strategia identica, i casi limite vengono gestiti diversamente: arrotondamento, ordine dei controlli delle condizioni, gestione dei NaN.
Gestione dello stato. Il backtest è solitamente stateless — itera su un array di dati. Il bot è stateful — memorizza posizioni, saldi, storico degli ordini. Riavvio del bot, perdita di stato, desincronizzazione con l'exchange — tutte queste sono fonti di divergenza.
Contributo tipico alla divergenza del PnL: 5-20% del PnL annuo.
4. Divergenze dei costi (gravità: 3/5)
Divergenze nella modellazione dei costi di trading.
Tassi di funding. La maggior parte dei backtest sui futures perpetui non tiene affatto conto dei tassi di funding. Con una leva 10x e un tasso medio dello 0,01% ogni 8 ore, questo fa all'anno — più del PnL della maggior parte delle strategie. Un'analisi dettagliata è nell'articolo I tassi di funding distruggono la tua leva.
Commissioni. Le commissioni maker/taker sono solitamente modellate ma spesso con il tasso sbagliato. Livelli VIP, sconti BNB, rebate — tutto questo influisce sul risultato finale.
Spread. Un backtest basato su candele non vede lo spread bid-ask. Su una candela a 1 minuto, close = 3000, ma in realtà bid = 2999,5 e ask = 3000,5. Ogni trade "costa" metà dello spread.
Contributo tipico alla divergenza del PnL: 5-15% del PnL annuo.
Effetto Cumulativo
Tutte e quattro le categorie agiscono simultaneamente e, di regola, nella stessa direzione — contro il trader:
Una divergenza totale del 20-50% dal PnL del backtest è normale per un sistema non raffinato. Con la leva, l'effetto si moltiplica.
Pattern Architetturali per la Parità
Pattern 1: Shared Core (estrazione di un core comune)
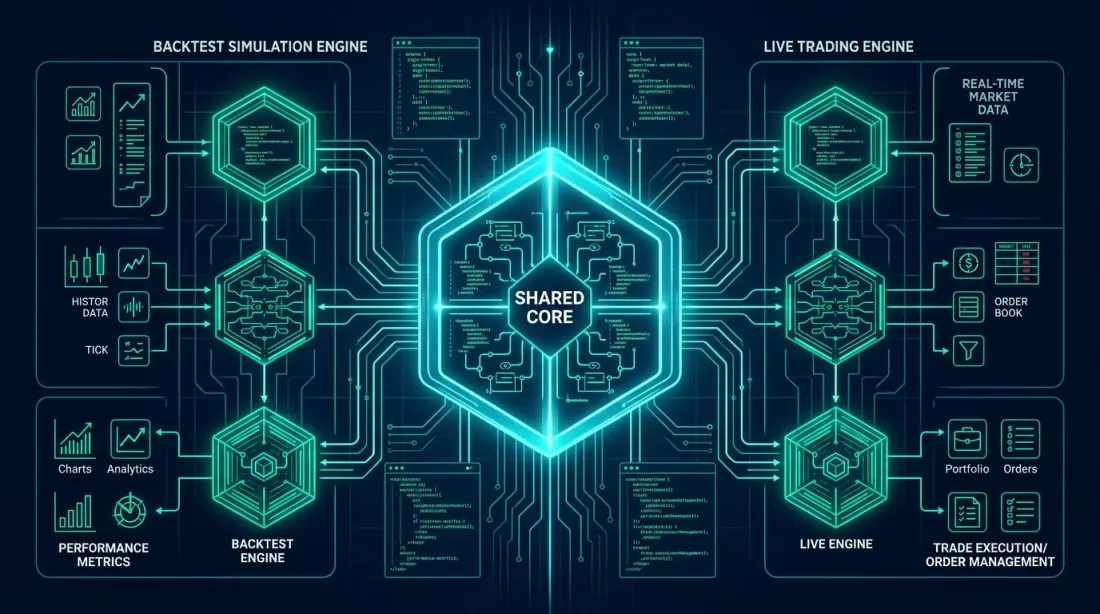
L'idea: estrarre il core della strategia — generazione dei segnali e logica di esecuzione — in un modulo separato usato sia dal backtest che dal bot. Solo l'infrastruttura circostante differisce: la fonte dei dati e il meccanismo di invio degli ordini.
┌─────────────────────────────────────┐
│ strategy_core.py │
│ ┌─────────────┐ ┌───────────────┐ │
│ │ SignalEngine │ │ OrderManager │ │
│ └──────┬──────┘ └──────┬────────┘ │
│ │ │ │
│ generate_signal() create_order()│
└─────────┬───────────────┬───────────┘
│ │
┌─────┴─────┐ ┌─────┴──────┐
│ Backtest │ │ Live │
│ DataFeed │ │ DataFeed │
│ FillModel │ │ Exchange │
└────────────┘ └────────────┘
from dataclasses import dataclass
from typing import Optional
import numpy as np
@dataclass
class Signal:
side: str # 'long' | 'short'
entry_price: float
sl_price: float
tp_price: float
size: float
timestamp: int
@dataclass
class OrderRequest:
side: str
order_type: str # 'market' | 'limit'
price: float
size: float
class StrategyCore:
"""
Strategy core. Identical code for backtest and live.
Depends only on data, not on infrastructure.
"""
def __init__(self, params: dict):
self.fast_period = params.get('fast_ma', 20)
self.slow_period = params.get('slow_ma', 50)
self.sl_pct = params.get('sl_pct', 0.02)
self.tp_pct = params.get('tp_pct', 0.04)
self.position: Optional[Signal] = None
self._closes: list[float] = []
def on_candle(self, timestamp: int, o: float, h: float,
l: float, c: float, v: float) -> Optional[OrderRequest]:
"""
Process a new candle. Returns an OrderRequest or None.
This method is called identically from the backtest and the bot.
"""
self._closes.append(c)
if len(self._closes) < self.slow_period:
return None
fast_ma = np.mean(self._closes[-self.fast_period:])
slow_ma = np.mean(self._closes[-self.slow_period:])
if self.position is not None:
exit_order = self._check_exit(h, l, c)
if exit_order:
self.position = None
return exit_order
if self.position is None:
if fast_ma > slow_ma and self._prev_fast_ma <= self._prev_slow_ma:
self.position = Signal(
side='long', entry_price=c,
sl_price=c * (1 - self.sl_pct),
tp_price=c * (1 + self.tp_pct),
size=1.0, timestamp=timestamp,
)
return OrderRequest('buy', 'market', c, 1.0)
self._prev_fast_ma = fast_ma
self._prev_slow_ma = slow_ma
return None
def _check_exit(self, high: float, low: float,
close: float) -> Optional[OrderRequest]:
pos = self.position
if pos.side == 'long':
if low <= pos.sl_price:
return OrderRequest('sell', 'market', pos.sl_price, pos.size)
if high >= pos.tp_price:
return OrderRequest('sell', 'market', pos.tp_price, pos.size)
return None
Ora il backtest e il bot usano lo stesso StrategyCore:
from strategy_core import StrategyCore
def run_backtest(candles, params, fill_model):
core = StrategyCore(params)
trades = []
for candle in candles:
order = core.on_candle(
candle['timestamp'], candle['open'], candle['high'],
candle['low'], candle['close'], candle['volume'],
)
if order:
fill_price = fill_model.simulate_fill(order, candle)
trades.append({'price': fill_price, 'side': order.side})
return trades
from strategy_core import StrategyCore
async def run_live(exchange, symbol, params):
core = StrategyCore(params)
async for candle in exchange.stream_candles(symbol, '1m'):
order = core.on_candle(
candle['timestamp'], candle['open'], candle['high'],
candle['low'], candle['close'], candle['volume'],
)
if order:
await exchange.place_order(symbol, order.side,
order.order_type, order.size)
La regola chiave: StrategyCore non sa da dove provengono i dati o dove vengono inviati gli ordini. Riceve OHLCV e restituisce un OrderRequest. Tutto il resto è responsabilità del livello infrastrutturale.
Pattern 2: Unificazione event-driven (approccio NautilusTrader)
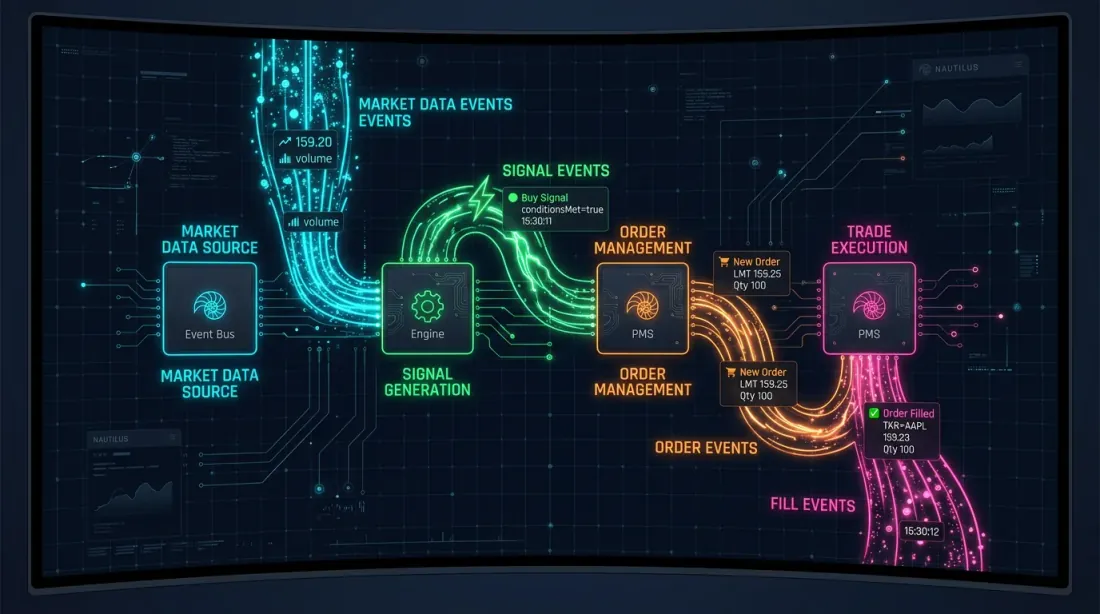
NautilusTrader implementa la parità attraverso un NautilusKernel unificato — un motore Rust-native con un core event-driven deterministico e risoluzione al nanosecondo. La stessa implementazione della strategia funziona sia nel backtest che nel trading live.
L'architettura è costruita sul pattern ports and adapters (architettura esagonale):
┌──────────────────────────────────┐
│ NautilusKernel │
│ ┌───────────┐ ┌─────────────┐ │
│ │ Strategy │ │ RiskEngine │ │
│ │ (Python) │ │ (Rust) │ │
│ └─────┬─────┘ └──────┬──────┘ │
│ │ │ │
│ ┌─────┴───────────────┴──────┐ │
│ │ Message Bus (Rust) │ │
│ └─────┬───────────────┬──────┘ │
└────────┼───────────────┼─────────┘
│ │
┌─────┴─────┐ ┌─────┴──────┐
│ Backtest │ │ Live │
│ Adapter │ │ Adapter │
│ FillModel │ │ Exchange │
│ (L2 book) │ │ Gateway │
└────────────┘ └────────────┘
Vantaggi:
- Replay deterministico. Gli eventi vengono elaborati in un ordine rigorosamente definito — il risultato del backtest è bit-riproducibile.
- FillModel personalizzato. Simulazione dell'orderbook L2 per ogni esecuzione — lo slippage è simulato in base alla reale profondità dell'orderbook.
- Performance. Fino a 5 milioni di righe/sec, elaborando dati che non entrano in RAM.
- Redis + PostgreSQL. Cache e message bus tramite Redis, persistenza tramite PostgreSQL — infrastruttura identica per backtest e live.
Pattern 3: Strategy Interface (approccio Freqtrade)
Freqtrade utilizza un'interfaccia IStrategy unificata: la stessa classe di strategia funziona sia nel backtest che in live. L'unica differenza è il livello di persistenza.
class IStrategy:
"""Unified interface — the implementation does not know if this is a backtest or live."""
def populate_indicators(self, dataframe, metadata):
"""Compute indicators."""
dataframe['fast_ma'] = dataframe['close'].rolling(20).mean()
dataframe['slow_ma'] = dataframe['close'].rolling(50).mean()
return dataframe
def populate_entry_trend(self, dataframe, metadata):
"""Determine entry signals."""
dataframe.loc[
(dataframe['fast_ma'] > dataframe['slow_ma']) &
(dataframe['fast_ma'].shift(1) <= dataframe['slow_ma'].shift(1)),
'enter_long'
] = 1
return dataframe
def populate_exit_trend(self, dataframe, metadata):
"""Determine exit signals."""
dataframe.loc[
(dataframe['fast_ma'] < dataframe['slow_ma']),
'exit_long'
] = 1
return dataframe
Freqtrade fornisce inoltre:
- Hyperopt tramite Optuna — ottimizzazione dei parametri della strategia
--timeframe-detail— drill-down a un timeframe più fine per il raffinamento dei fill (simile al drill-down adattivo)
Confronto dei Pattern
| Shared Core | Event-driven (NautilusTrader) | Strategy Interface (Freqtrade) | |
|---|---|---|---|
| Complessità di implementazione | Bassa | Alta | Media |
| Livello di parità | Medio | Massimo | Alto |
| Simulazione dei fill | FillModel separato | Orderbook L2 | --timeframe-detail |
| Linguaggio core | Python | Rust + Python | Python |
| Adatto per | Motori personalizzati | Trading istituzionale | Avvio rapido |
Accuratezza della Simulazione dei Fill
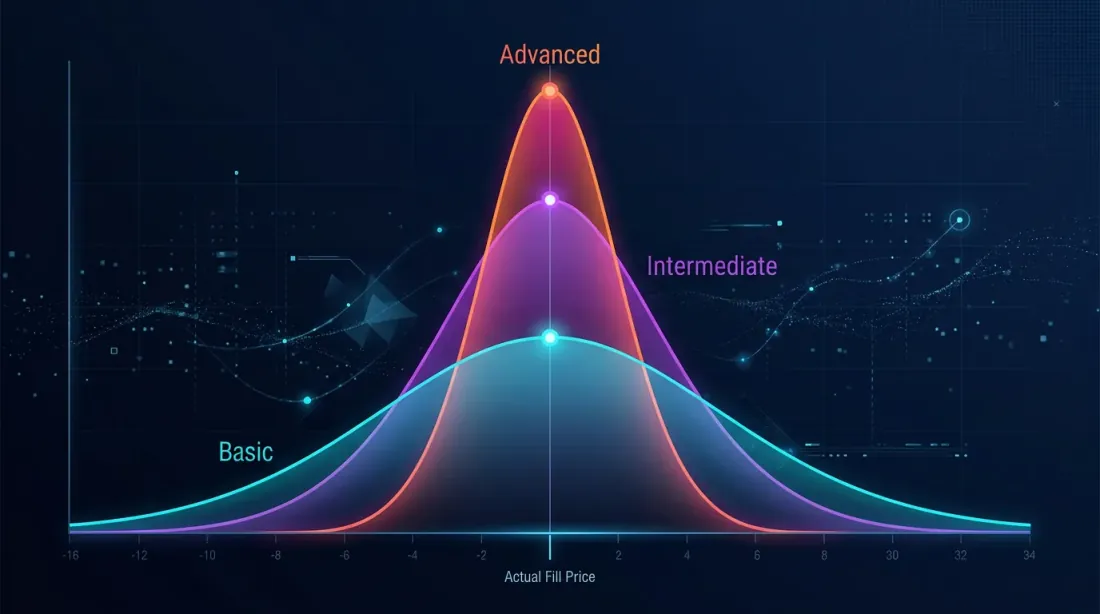
La simulazione dei fill è la principale fonte di divergenza di esecuzione. Tre livelli di accuratezza:
Livello 1: Naive (fill al prezzo di chiusura)
fill_price = candle['close']
Errore: non tiene conto di slippage, spread o fill parziali. Sopravvaluta sistematicamente il PnL.
Livello 2: Modello di slippage
def simulate_fill(order, candle, slippage_bps=5):
"""Fill con slippage."""
base_price = candle['close']
slip = base_price * slippage_bps / 10000
if order.side == 'buy':
return base_price + slip # Acquisto a un prezzo più alto
else:
return base_price - slip # Vendita a un prezzo più basso
Errore: lo slippage fisso non tiene conto della liquidità e della dimensione dell'ordine. Meglio del naive, ma comunque un modello grezzo.
Livello 3: Drill-down adattivo con dati 1s/100ms
L'opzione migliore: utilizzare dati reali a granularità fine per una determinazione precisa dell'ordine di fill SL/TP. Descritto in dettaglio nell'articolo Drill-down adattivo: backtest con granularità variabile.
class RealisticFillModel:
"""
Combined fill model: slippage + spread + volume impact.
"""
def __init__(self, avg_spread_bps=3, impact_coeff=0.1):
self.avg_spread_bps = avg_spread_bps
self.impact_coeff = impact_coeff
def simulate_fill(self, order, candle, order_size_usd):
base_price = candle['close']
spread_cost = base_price * self.avg_spread_bps / 20000
candle_volume_usd = candle['volume'] * candle['close']
participation_rate = order_size_usd / max(candle_volume_usd, 1)
impact = base_price * self.impact_coeff * np.sqrt(participation_rate)
if order.side == 'buy':
return base_price + spread_cost + impact
else:
return base_price - spread_cost - impact
Formula dell'impatto di mercato (modello Almgren-Chriss semplificato):
dove è la volatilità, è il coefficiente di impatto, è il volume dell'ordine e è il volume di mercato per il periodo.
Checklist Pratica per la Parità

Prima di lanciare il bot in live, verifica ogni elemento:
Codice:
- La strategia utilizza un core condiviso (un modulo per backtest e live)
- Nessuna duplicazione della logica dei segnali in due posti
- I test unitari verificano output identici del core per input identici
- L'ordine dei controlli delle condizioni è identico (SL prima di TP? TP prima di SL?)
Dati:
- Il formato del timestamp è identico (UTC, stesso provider)
- L'aggregazione OHLCV usa le stesse regole
- La gestione delle candele mancanti è identica
- Nessun look-ahead bias — il backtest non guarda nel futuro
Esecuzione:
- Il modello di slippage è calibrato su dati reali
- I fill parziali sono modellati (o almeno stimati pessimisticamente)
- Gli ordini limite hanno un modello di priorità di coda
- La latenza è considerata (ritardo di 100-500 ms dal segnale al fill)
Costi:
- Le commissioni maker/taker sono incluse con il tasso corrente
- I tassi di funding sono considerati con i futures perpetui
- Lo spread è modellato (almeno la media)
Infrastruttura:
- Persistenza dello stato: il bot recupera le posizioni dopo il riavvio
- Logica di riconnessione: il WebSocket si riconnette senza perdita di dati
- Logging: tutti gli ordini e i fill sono loggati per l'analisi post-mortem
Monitoraggio della Divergenza in Produzione
La parità non è un controllo una-tantum ma un processo continuo. Dopo il lancio del bot, le divergenze devono essere monitorate in tempo reale.
Modalità shadow (paper trading)
Esegui il bot in parallelo con il backtest sugli stessi dati. Il bot genera segnali ma non invia ordini — fa solo logging. Contemporaneamente, il backtest elabora gli stessi dati. Confronta:
class DivergenceMonitor:
"""
Compares backtest and live bot signals in real time.
"""
def __init__(self, tolerance_pct=0.5):
self.tolerance = tolerance_pct / 100
self.divergences = []
def compare_signal(self, backtest_signal, live_signal, timestamp):
"""Compare backtest and live signals."""
if backtest_signal is None and live_signal is None:
return # Both silent — OK
if (backtest_signal is None) != (live_signal is None):
self.divergences.append({
'timestamp': timestamp,
'type': 'signal_mismatch',
'backtest': backtest_signal,
'live': live_signal,
'severity': 'HIGH',
})
return
price_diff = abs(
backtest_signal.entry_price - live_signal.entry_price
) / backtest_signal.entry_price
if price_diff > self.tolerance:
self.divergences.append({
'timestamp': timestamp,
'type': 'price_divergence',
'diff_pct': price_diff * 100,
'severity': 'MEDIUM',
})
def compare_fill(self, backtest_fill, live_fill, timestamp):
"""Compare execution."""
if backtest_fill and live_fill:
slippage = (live_fill['price'] - backtest_fill['price']
) / backtest_fill['price']
self.divergences.append({
'timestamp': timestamp,
'type': 'fill_divergence',
'slippage_bps': slippage * 10000,
'severity': 'LOW' if abs(slippage) < 0.001 else 'MEDIUM',
})
def report(self):
"""Weekly divergence report."""
from collections import Counter
severity_counts = Counter(d['severity'] for d in self.divergences)
return {
'total_divergences': len(self.divergences),
'by_severity': dict(severity_counts),
'avg_slippage_bps': np.mean([
d['slippage_bps'] for d in self.divergences
if d['type'] == 'fill_divergence'
]) if any(d['type'] == 'fill_divergence'
for d in self.divergences) else 0,
}
Metriche del Dashboard
| Metrica | Formula | Soglia di allerta |
|---|---|---|
| Tasso di corrispondenza segnali | < 95% | |
| Slippage medio | (bps) | > 10 bps |
| Tasso di fill | < 90% | |
| Divergenza PnL | > 20% | |
| Latenza p99 | 99° percentile segnale-to-fill | > 500 ms |
Calibrazione del Modello di Slippage
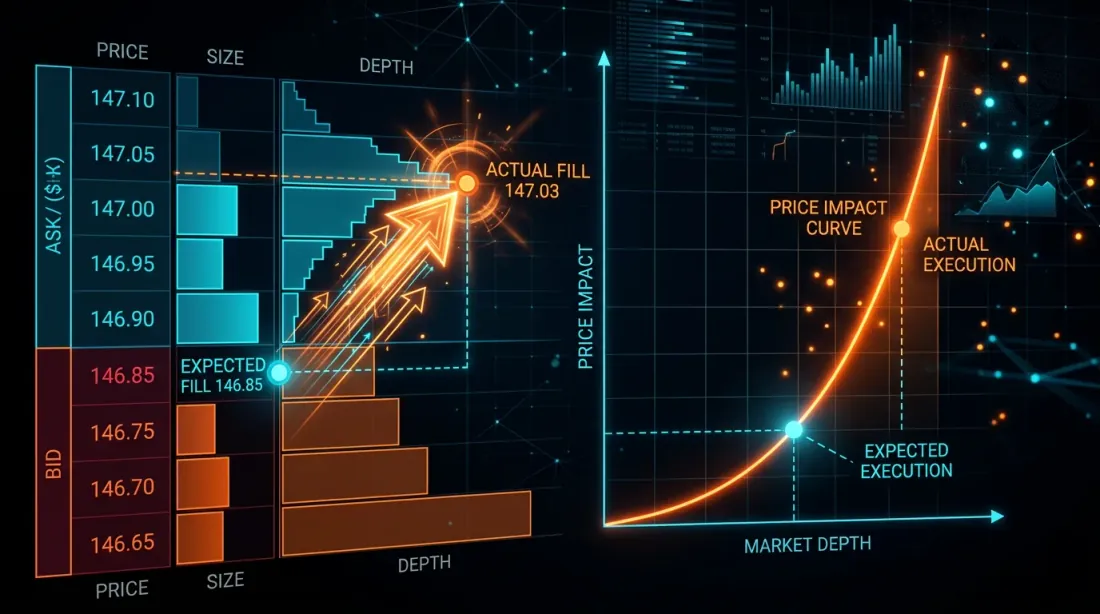
Dopo aver accumulato dati per 2-4 settimane, puoi calibrare il modello di slippage del backtest sui dati reali:
def calibrate_slippage(live_fills: list[dict]) -> dict:
"""
Calibrate slippage model using real fills.
live_fills: [{'expected_price': ..., 'actual_price': ..., 'size_usd': ..., 'volume_usd': ...}]
"""
slippages = []
participation_rates = []
for fill in live_fills:
slip = abs(fill['actual_price'] - fill['expected_price']
) / fill['expected_price']
part = fill['size_usd'] / max(fill['volume_usd'], 1)
slippages.append(slip)
participation_rates.append(part)
slippages = np.array(slippages)
participation_rates = np.array(participation_rates)
from scipy.optimize import curve_fit
def model(x, k, base):
return k * np.sqrt(x) + base
popt, _ = curve_fit(model, participation_rates, slippages,
p0=[0.1, 0.0001])
return {
'impact_coeff': popt[0],
'base_slippage': popt[1],
'mean_slippage_bps': np.mean(slippages) * 10000,
'p95_slippage_bps': np.percentile(slippages, 95) * 10000,
}
Connessioni con Altri Strumenti
La parità backtest-live non è un compito isolato. Si interseca con altri strumenti della serie "Backtest Senza Illusioni":
- Drill-down adattivo — migliora l'accuratezza della simulazione dei fill, un componente chiave della parità di esecuzione.
- Tassi di funding — se il backtest non modella il funding, la parità è impossibile a leva > 3x.
- Cache Parquet — i timeframe e gli indicatori precalcolati assicurano che il backtest veda gli stessi dati del bot. L'emulazione RunningCandleBuffer = aggiornamento in tempo reale.
- Polars vs Pandas — quando si passa da pandas (backtest) a Polars (live), è necessario garantire che i risultati numerici corrispondano.
- Walk-Forward — il walk-forward su dati out-of-sample mostra come la strategia degrada — questo è più vicino al live rispetto a un backtest in-sample.
Raccomandazioni
-
Il core condiviso è obbligatorio. Una singola codebase per la generazione dei segnali è il requisito minimo per la parità. Due file con logica identica garantiscono la divergenza entro un mese.
-
Calibra il modello di fill. Uno slippage fisso di 5 bps è meglio di niente. Un modello di slippage calibrato su dati reali è significativamente migliore.
-
Usa la modalità shadow per le prime 2-4 settimane. Non fare trading con denaro reale finché il tasso di corrispondenza dei segnali non raggiunge il 95%+.
-
Modella i tassi di funding. Per i futures perpetui, questo non è opzionale — è obbligatorio. Il funding può consumare tutto il PnL a leva > 5x.
-
Logga tutto. Ogni segnale, ogni ordine, ogni fill — con timestamp. Senza log, l'analisi post-mortem è impossibile.
-
Automatizza il confronto. Un report settimanale di DivergenceMonitor dovrebbe arrivare automaticamente. Non aspettare finché il PnL diventa negativo.
-
Backtest pessimistico per default. È meglio sottostimare le aspettative nel backtest ed essere piacevolmente sorpresi in live che il contrario. Il modello di slippage dovrebbe essere conservativo.
Conclusione
La parità backtest-live non è una proprietà di un sistema ma un processo. La parità perfetta non esiste: un backtest è per definizione un modello della realtà, e un modello semplifica sempre. Ma la differenza tra "il modello differisce del 5%" e "il modello differisce del 50%" è determinata dall'architettura.
Tre livelli di maturità:
- Base. Core condiviso, slippage fisso, commissioni. Divergenza: 10-20%.
- Avanzato. Architettura event-driven, drill-down adattivo, modello di funding, modalità shadow. Divergenza: 5-10%.
- Istituzionale. Simulazione orderbook L2, modello di impatto calibrato, monitoraggio della divergenza in tempo reale. Divergenza: 2-5%.
Il tuo compito è determinare a che livello sei e capire quale divergenza ritieni accettabile per la tua dimensione di posizione e leva.
Link Utili
- NautilusTrader — High-Performance Algorithmic Trading Platform
- Freqtrade — Free, open source crypto trading bot
- Almgren, R., Chriss, N. — Optimal Execution of Portfolio Transactions (2001)
- Lopez de Prado — Advances in Financial Machine Learning, Chapter 12: Backtesting
- Ernest Chan — Quantitative Trading: How to Build Your Own Algorithmic Trading Business
- Hexagonal Architecture (Ports and Adapters) — Alistair Cockburn
- Optuna — Hyperparameter Optimization Framework
Citazione
@article{soloviov2026backtestliveparity,
author = {Soloviov, Eugen},
title = {Parità backtest-live: perché il tuo bot fa trading in modo diverso dal backtest},
year = {2026},
url = {https://marketmaker.cc/it/blog/post/backtest-live-parity},
description = {Tassonomia completa delle divergenze tra backtest e trading live: dallo slippage e i fill parziali alla desincronizzazione del codice. Pattern architetturali per ottenere la parità e una checklist di monitoraggio in produzione.}
}
Autori

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Leggi di Più

PnL per Tempo Attivo: La Metrica che Cambia il Ranking delle Strategie

Drill-Down Adattivo: Backtest con Granularità Variabile dai Minuti ai Trade Grezzi
