Backtest-live parity: tại sao bot của bạn giao dịch khác so với backtest

Bạn đã chạy chiến lược qua backtest. Sharpe 2.1, MaxDD -8%, PnL +67%. Bạn ra mắt bot. Một tháng sau bạn so sánh: cùng tín hiệu, cùng giai đoạn — nhưng PnL thực tế thấp hơn 40%. Drawdown sâu hơn một lần rưỡi. Hai trong mười lệnh giao dịch không được thực hiện.
Đây không phải lỗi. Đây là sai lệch backtest-live — sự chênh lệch có hệ thống giữa kết quả backtest và giao dịch thực. Ai cũng gặp phải. Câu hỏi duy nhất là liệu bạn có biết về nó và có thể kiểm soát nó không.
Bài viết này cung cấp phân loại đầy đủ các sai lệch, các mô hình kiến trúc để giảm thiểu chúng, và danh sách kiểm tra thực tế để giám sát parity trong production.
Hội chứng "đã hoạt động trong backtest"

Mỗi nhà giao dịch theo thuật toán đều trải qua chu kỳ này:
- Viết chiến lược trong Jupyter notebook
- Chạy backtest trên CSV lịch sử — kết quả tuyệt vời
- Viết lại logic thành bot (thường bằng ngôn ngữ hoặc framework khác)
- Ra mắt — kết quả không khớp
- Bắt đầu tìm lỗi, không tìm thấy — "thị trường đã thay đổi"
Vấn đề không phải ở thị trường. Vấn đề là backtest và bot là hai sản phẩm phần mềm khác nhau mô hình hóa cùng một thực tế theo cách khác nhau. Sai lệch là không thể tránh khỏi, nhưng chúng có thể được hệ thống hóa và giảm thiểu.
Phân loại Sai lệch

Tất cả các nguồn sai lệch rơi vào bốn danh mục. Với mỗi danh mục — đánh giá mức độ nghiêm trọng (từ 1 đến 5) và đóng góp điển hình vào sai lệch PnL.
1. Sai lệch dữ liệu (mức độ nghiêm trọng: 3/5)
Dữ liệu mà backtest nhìn thấy và dữ liệu mà bot nhìn thấy trong thời gian thực không giống nhau.
Timestamps. Các sàn giao dịch phân phối nến với các quy tắc gán timestamp khác nhau. Một sàn đánh dấu nến bằng thời điểm bắt đầu chu kỳ, sàn khác bằng thời điểm kết thúc. REST API có thể trả về nến với độ trễ 1-3 giây sau khi thực sự đóng. Backtest làm việc với timestamps "lý tưởng" từ file lịch sử.
Tổng hợp OHLCV. Dữ liệu lịch sử thường được tổng hợp bởi nhà cung cấp theo cách khác so với sàn giao dịch thực hiện trong thời gian thực. Sự khác biệt là ở chữ số cuối cùng — nhưng với các tín hiệu ngưỡng (MA crossover, breakout mức độ), điều này xác định liệu chiến lược có vào vị thế hay không.
Khoảng trống và dữ liệu thiếu. Dữ liệu lịch sử thường sạch — các nến bị thiếu được điền bởi nội suy. Trong thời gian thực, WebSocket có thể bị ngắt và bot bỏ lỡ 30 giây dữ liệu.
Đóng góp điển hình vào sai lệch PnL: 2-5% PnL hàng năm.
2. Sai lệch thực thi (mức độ nghiêm trọng: 5/5)
Lớp sai lệch nguy hiểm nhất. Backtest mô phỏng việc thực thi hoàn hảo — thực tế thì rất xa lý tưởng.
Slippage. Backtest điền lệnh ở giá đóng (hoặc giá tín hiệu). Trong thực tế, lệnh thị trường được thực thi ở bid/ask tốt nhất cộng với slippage phụ thuộc vào khối lượng và thanh khoản. Đối với vị thế $10K trên altcoin thanh khoản trung bình, slippage có thể là 0.05-0.3%.
Công thức cho slippage tích lũy qua giao dịch:
trong đó là slippage của giao dịch thứ , phụ thuộc vào độ sâu orderbook:
Độ trễ. Từ lúc tín hiệu được tạo ra đến khi thực thi lệnh, thời gian trôi qua: tính toán tín hiệu (1-50 ms), truyền yêu cầu (10-200 ms), khớp lệnh trên sàn (1-10 ms). Trong backtest, độ trễ = 0. Trong thực tế — giá có thể di chuyển.
Khớp lệnh một phần. Backtest giả định 100% lệnh được khớp ngay lập tức. Trong thực tế, lệnh giới hạn có thể được khớp một phần — hoặc hoàn toàn không được khớp nếu giá đảo chiều. Đối với lệnh thị trường trên thị trường kém thanh khoản, lệnh "trượt" qua nhiều mức orderbook.
Ưu tiên hàng đợi. Lệnh giới hạn được đặt ở giá bid tốt nhất sẽ không được khớp ngay lập tức — nó xếp hàng sau tất cả các lệnh đã được đặt trước đó ở mức đó. Backtest coi "giá đã chạm = lệnh được khớp" một cách có hệ thống làm phóng đại tỷ lệ khớp lệnh.
Đóng góp điển hình vào sai lệch PnL: 10-30% PnL hàng năm.
3. Sai lệch logic (mức độ nghiêm trọng: 4/5)
Đây là các sai lệch trong code chiến lược giữa backtest và bot.
Codebase riêng biệt. Anti-pattern cổ điển: backtests/strategy_a.py và bot/strategy_a.py — hai file riêng biệt "làm cùng một việc". Sau ba tháng chỉnh sửa, chúng không tránh khỏi sai lệch. Ai đó thêm filter trong backtest và quên sao chép vào bot. Hoặc ngược lại — một lỗi được sửa trong bot nhưng vẫn còn trong backtest.
Framework khác nhau. Backtest trên pandas với các thao tác vector hóa, bot trên asyncio với logic hướng sự kiện. Ngay cả với chiến lược giống hệt nhau, các trường hợp đặc biệt được xử lý khác nhau: làm tròn, thứ tự kiểm tra điều kiện, xử lý NaN.
Quản lý trạng thái. Backtest thường không có trạng thái — nó lặp qua một mảng dữ liệu. Bot có trạng thái — nó lưu trữ vị thế, số dư, lịch sử lệnh. Khởi động lại bot, mất trạng thái, không đồng bộ với sàn — tất cả đều là nguồn gốc của sai lệch.
Đóng góp điển hình vào sai lệch PnL: 5-20% PnL hàng năm.
4. Sai lệch chi phí (mức độ nghiêm trọng: 3/5)
Sai lệch trong mô hình hóa chi phí giao dịch.
Funding rates. Hầu hết các backtest hợp đồng tương lai vĩnh cửu không tính đến funding rates. Ở đòn bẩy 10x và tỷ lệ trung bình 0.01% mỗi 8 giờ, đây là mỗi năm — nhiều hơn PnL của hầu hết các chiến lược. Phân tích chi tiết trong bài viết Funding rates tiêu diệt đòn bẩy của bạn.
Hoa hồng. Hoa hồng maker/taker thường được mô hình hóa nhưng thường với mức sai. Các bậc VIP, giảm giá BNB, hoàn tiền — tất cả đều ảnh hưởng đến kết quả cuối cùng.
Spread. Backtest dựa trên nến không thấy spread bid-ask. Trên nến 1 phút, close = 3000, nhưng trong thực tế bid = 2999.5 và ask = 3000.5. Mỗi giao dịch "tốn" nửa spread.
Đóng góp điển hình vào sai lệch PnL: 5-15% PnL hàng năm.
Hiệu ứng tích lũy
Cả bốn danh mục tác động đồng thời và thường theo một hướng — chống lại nhà giao dịch:
Tổng sai lệch 20-50% so với PnL backtest là bình thường đối với một hệ thống chưa được tinh chỉnh. Với đòn bẩy, hiệu ứng được nhân lên.
Các Mô hình Kiến trúc cho Parity
Mô hình 1: Shared Core (trích xuất một core chung)
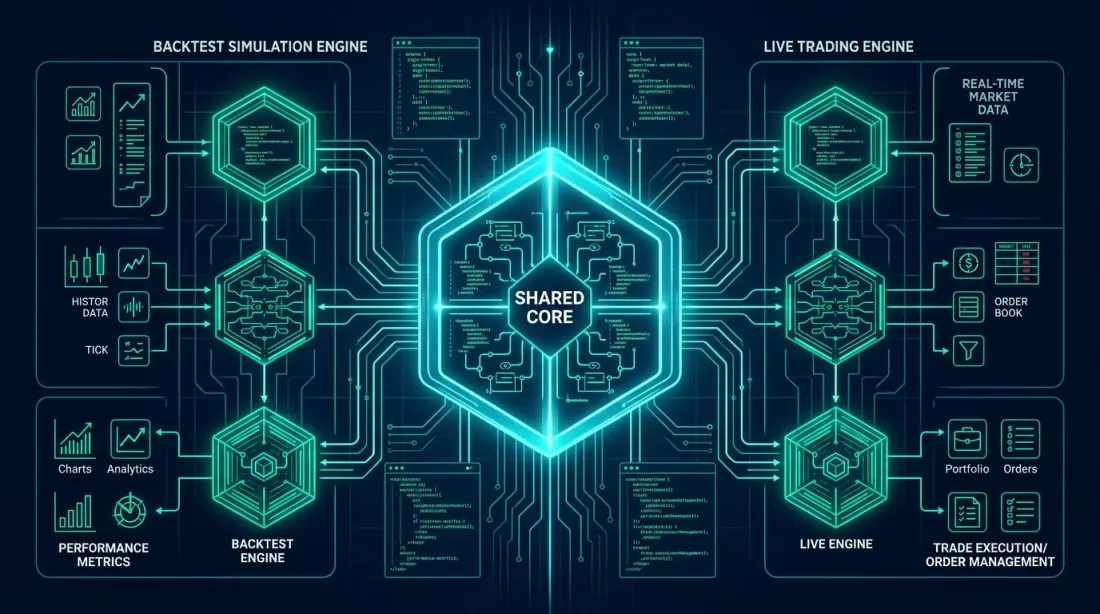
Ý tưởng: trích xuất core chiến lược — tạo tín hiệu và logic thực thi — vào một module riêng biệt được cả backtest và bot sử dụng. Chỉ có cơ sở hạ tầng xung quanh khác nhau: nguồn dữ liệu và cơ chế gửi lệnh.
┌─────────────────────────────────────┐
│ strategy_core.py │
│ ┌─────────────┐ ┌───────────────┐ │
│ │ SignalEngine │ │ OrderManager │ │
│ └──────┬──────┘ └──────┬────────┘ │
│ │ │ │
│ generate_signal() create_order()│
└─────────┬───────────────┬───────────┘
│ │
┌─────┴─────┐ ┌─────┴──────┐
│ Backtest │ │ Live │
│ DataFeed │ │ DataFeed │
│ FillModel │ │ Exchange │
└────────────┘ └────────────┘
from dataclasses import dataclass
from typing import Optional
import numpy as np
@dataclass
class Signal:
side: str # 'long' | 'short'
entry_price: float
sl_price: float
tp_price: float
size: float
timestamp: int
@dataclass
class OrderRequest:
side: str
order_type: str # 'market' | 'limit'
price: float
size: float
class StrategyCore:
"""
Strategy core. Identical code for backtest and live.
Depends only on data, not on infrastructure.
"""
def __init__(self, params: dict):
self.fast_period = params.get('fast_ma', 20)
self.slow_period = params.get('slow_ma', 50)
self.sl_pct = params.get('sl_pct', 0.02)
self.tp_pct = params.get('tp_pct', 0.04)
self.position: Optional[Signal] = None
self._closes: list[float] = []
def on_candle(self, timestamp: int, o: float, h: float,
l: float, c: float, v: float) -> Optional[OrderRequest]:
"""
Process a new candle. Returns an OrderRequest or None.
This method is called identically from the backtest and the bot.
"""
self._closes.append(c)
if len(self._closes) < self.slow_period:
return None
fast_ma = np.mean(self._closes[-self.fast_period:])
slow_ma = np.mean(self._closes[-self.slow_period:])
if self.position is not None:
exit_order = self._check_exit(h, l, c)
if exit_order:
self.position = None
return exit_order
if self.position is None:
if fast_ma > slow_ma and self._prev_fast_ma <= self._prev_slow_ma:
self.position = Signal(
side='long', entry_price=c,
sl_price=c * (1 - self.sl_pct),
tp_price=c * (1 + self.tp_pct),
size=1.0, timestamp=timestamp,
)
return OrderRequest('buy', 'market', c, 1.0)
self._prev_fast_ma = fast_ma
self._prev_slow_ma = slow_ma
return None
def _check_exit(self, high: float, low: float,
close: float) -> Optional[OrderRequest]:
pos = self.position
if pos.side == 'long':
if low <= pos.sl_price:
return OrderRequest('sell', 'market', pos.sl_price, pos.size)
if high >= pos.tp_price:
return OrderRequest('sell', 'market', pos.tp_price, pos.size)
return None
Bây giờ backtest và bot sử dụng cùng StrategyCore:
from strategy_core import StrategyCore
def run_backtest(candles, params, fill_model):
core = StrategyCore(params)
trades = []
for candle in candles:
order = core.on_candle(
candle['timestamp'], candle['open'], candle['high'],
candle['low'], candle['close'], candle['volume'],
)
if order:
fill_price = fill_model.simulate_fill(order, candle)
trades.append({'price': fill_price, 'side': order.side})
return trades
from strategy_core import StrategyCore
async def run_live(exchange, symbol, params):
core = StrategyCore(params)
async for candle in exchange.stream_candles(symbol, '1m'):
order = core.on_candle(
candle['timestamp'], candle['open'], candle['high'],
candle['low'], candle['close'], candle['volume'],
)
if order:
await exchange.place_order(symbol, order.side,
order.order_type, order.size)
Quy tắc chính: StrategyCore không biết dữ liệu đến từ đâu hay lệnh được gửi đến đâu. Nó nhận OHLCV và trả về OrderRequest. Mọi thứ khác là trách nhiệm của lớp cơ sở hạ tầng.
Mô hình 2: Thống nhất hướng sự kiện (cách tiếp cận NautilusTrader)
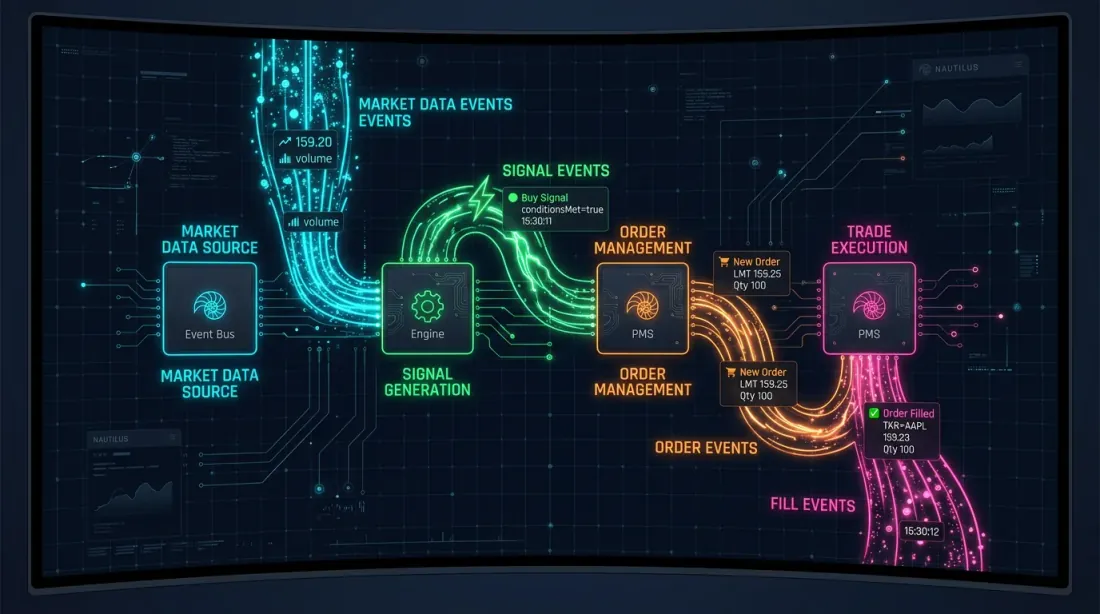
NautilusTrader triển khai parity thông qua NautilusKernel thống nhất — engine native Rust với core hướng sự kiện xác định và độ phân giải nanosecond. Cùng một triển khai chiến lược hoạt động trong cả backtest và giao dịch thực.
Kiến trúc được xây dựng trên mô hình ports and adapters (kiến trúc hexagonal):
┌──────────────────────────────────┐
│ NautilusKernel │
│ ┌───────────┐ ┌─────────────┐ │
│ │ Strategy │ │ RiskEngine │ │
│ │ (Python) │ │ (Rust) │ │
│ └─────┬─────┘ └──────┬──────┘ │
│ │ │ │
│ ┌─────┴───────────────┴──────┐ │
│ │ Message Bus (Rust) │ │
│ └─────┬───────────────┬──────┘ │
└────────┼───────────────┼─────────┘
│ │
┌─────┴─────┐ ┌─────┴──────┐
│ Backtest │ │ Live │
│ Adapter │ │ Adapter │
│ FillModel │ │ Exchange │
│ (L2 book) │ │ Gateway │
└────────────┘ └────────────┘
Ưu điểm:
- Replay xác định. Các sự kiện được xử lý theo thứ tự được xác định nghiêm ngặt — kết quả backtest có thể tái tạo bit.
- FillModel tùy chỉnh. Mô phỏng L2 orderbook cho mọi lần thực thi — slippage được mô phỏng dựa trên độ sâu orderbook thực.
- Hiệu suất. Lên đến 5 triệu hàng/giây, xử lý dữ liệu không vừa trong RAM.
- Redis + PostgreSQL. Cache và message bus qua Redis, persistence qua PostgreSQL — cơ sở hạ tầng giống hệt nhau cho backtest và thực tế.
Mô hình 3: Strategy Interface (cách tiếp cận Freqtrade)
Freqtrade sử dụng interface IStrategy thống nhất: cùng một class chiến lược hoạt động trong cả backtest và thực tế. Sự khác biệt duy nhất là lớp persistence.
class IStrategy:
"""Giao diện thống nhất — triển khai không biết đây là backtest hay thực tế."""
def populate_indicators(self, dataframe, metadata):
"""Tính toán các chỉ báo."""
dataframe['fast_ma'] = dataframe['close'].rolling(20).mean()
dataframe['slow_ma'] = dataframe['close'].rolling(50).mean()
return dataframe
def populate_entry_trend(self, dataframe, metadata):
"""Xác định tín hiệu vào lệnh."""
dataframe.loc[
(dataframe['fast_ma'] > dataframe['slow_ma']) &
(dataframe['fast_ma'].shift(1) <= dataframe['slow_ma'].shift(1)),
'enter_long'
] = 1
return dataframe
def populate_exit_trend(self, dataframe, metadata):
"""Xác định tín hiệu thoát lệnh."""
dataframe.loc[
(dataframe['fast_ma'] < dataframe['slow_ma']),
'exit_long'
] = 1
return dataframe
Freqtrade còn cung cấp thêm:
- Hyperopt qua Optuna — tối ưu hóa tham số chiến lược
--timeframe-detail— drill-down đến timeframe mịn hơn để tinh chỉnh khớp lệnh (tương tự adaptive drill-down)
So sánh Mô hình
| Shared Core | Hướng sự kiện (NautilusTrader) | Strategy Interface (Freqtrade) | |
|---|---|---|---|
| Độ phức tạp triển khai | Thấp | Cao | Trung bình |
| Mức độ parity | Trung bình | Tối đa | Cao |
| Mô phỏng khớp lệnh | FillModel riêng | L2 orderbook | --timeframe-detail |
| Ngôn ngữ core | Python | Rust + Python | Python |
| Phù hợp cho | Engine tùy chỉnh | Giao dịch tổ chức | Bắt đầu nhanh |
Độ chính xác Mô phỏng Khớp lệnh
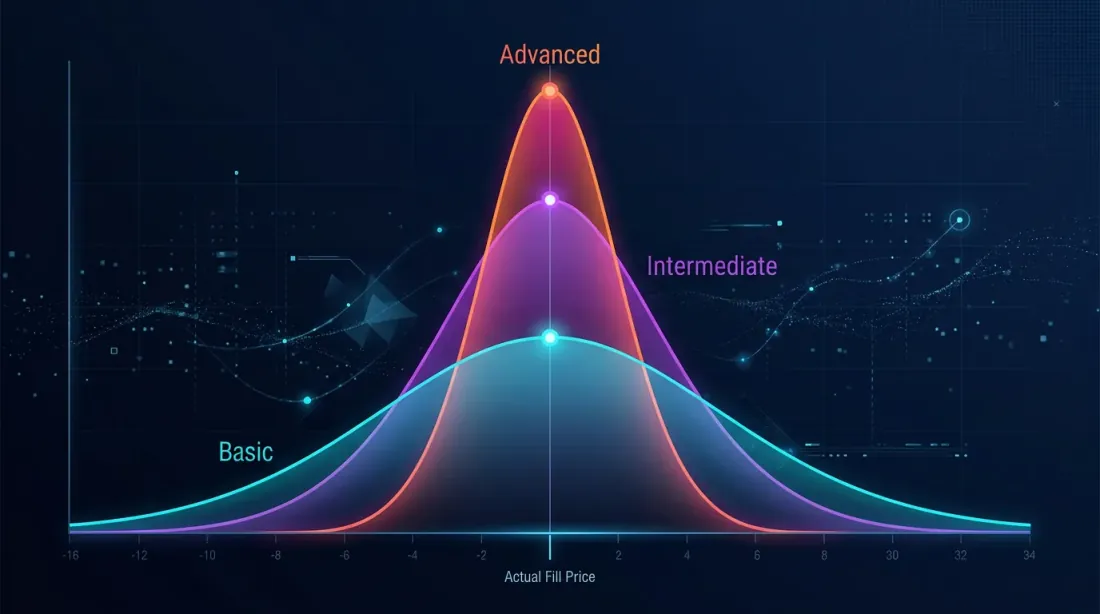
Mô phỏng khớp lệnh là nguồn chính của sai lệch thực thi. Ba mức độ chính xác:
Mức 1: Naive (khớp lệnh ở giá đóng)
fill_price = candle['close']
Sai số: không tính đến slippage, spread hoặc khớp lệnh một phần. Một cách có hệ thống làm phóng đại PnL.
Mức 2: Mô hình slippage
def simulate_fill(order, candle, slippage_bps=5):
"""Khớp lệnh với slippage."""
base_price = candle['close']
slip = base_price * slippage_bps / 10000
if order.side == 'buy':
return base_price + slip # Mua ở giá cao hơn
else:
return base_price - slip # Bán ở giá thấp hơn
Sai số: slippage cố định không tính đến thanh khoản và kích thước lệnh. Tốt hơn naive, nhưng vẫn là mô hình thô.
Mức 3: Adaptive drill-down với dữ liệu 1s/100ms
Lựa chọn tốt nhất: sử dụng dữ liệu thực với độ chi tiết mịn để xác định chính xác thứ tự khớp lệnh SL/TP. Được mô tả chi tiết trong bài viết Adaptive drill-down: backtesting với độ chi tiết biến đổi.
class RealisticFillModel:
"""
Mô hình khớp lệnh kết hợp: slippage + spread + tác động khối lượng.
"""
def __init__(self, avg_spread_bps=3, impact_coeff=0.1):
self.avg_spread_bps = avg_spread_bps
self.impact_coeff = impact_coeff
def simulate_fill(self, order, candle, order_size_usd):
base_price = candle['close']
spread_cost = base_price * self.avg_spread_bps / 20000
candle_volume_usd = candle['volume'] * candle['close']
participation_rate = order_size_usd / max(candle_volume_usd, 1)
impact = base_price * self.impact_coeff * np.sqrt(participation_rate)
if order.side == 'buy':
return base_price + spread_cost + impact
else:
return base_price - spread_cost - impact
Công thức tác động thị trường (mô hình Almgren-Chriss đơn giản hóa):
trong đó là biến động, là hệ số tác động, là khối lượng lệnh, và là khối lượng thị trường trong giai đoạn.
Danh sách kiểm tra Parity Thực tế

Trước khi ra mắt bot thực tế, hãy xác minh từng mục:
Code:
- Chiến lược sử dụng core dùng chung (một module cho backtest và thực tế)
- Không có sự trùng lặp logic tín hiệu ở hai nơi
- Unit tests xác minh các đầu ra core giống hệt nhau cho các đầu vào giống nhau
- Thứ tự kiểm tra điều kiện giống hệt nhau (SL trước TP? TP trước SL?)
Dữ liệu:
- Định dạng timestamp giống hệt nhau (UTC, cùng nhà cung cấp)
- Tổng hợp OHLCV sử dụng các quy tắc giống nhau
- Xử lý nến bị thiếu giống hệt nhau
- Không có look-ahead bias — backtest không nhìn trước vào tương lai
Thực thi:
- Mô hình slippage được hiệu chỉnh trên dữ liệu thực
- Khớp lệnh một phần được mô hình hóa (hoặc ít nhất được ước tính bi quan)
- Lệnh giới hạn có mô hình ưu tiên hàng đợi
- Độ trễ được tính đến (độ trễ 100-500 ms từ tín hiệu đến khớp lệnh)
Chi phí:
- Hoa hồng maker/taker được bao gồm với mức hiện tại
- Funding rates được tính đến với hợp đồng tương lai vĩnh cửu
- Spread được mô hình hóa (ít nhất là trung bình)
Cơ sở hạ tầng:
- Persistence trạng thái: bot khôi phục vị thế sau khi khởi động lại
- Logic kết nối lại: WebSocket kết nối lại mà không mất dữ liệu
- Logging: tất cả lệnh và khớp lệnh được ghi lại để phân tích post-mortem
Giám sát Sai lệch trong Production
Parity không phải là kiểm tra một lần mà là một quy trình liên tục. Sau khi ra mắt bot, các sai lệch phải được theo dõi trong thời gian thực.
Shadow mode (giao dịch giả lập)
Chạy bot song song với backtest trên cùng dữ liệu. Bot tạo tín hiệu nhưng không gửi lệnh — chỉ ghi log. Đồng thời, backtest xử lý cùng dữ liệu. So sánh:
class DivergenceMonitor:
"""
So sánh tín hiệu backtest và bot thực tế theo thời gian thực.
"""
def __init__(self, tolerance_pct=0.5):
self.tolerance = tolerance_pct / 100
self.divergences = []
def compare_signal(self, backtest_signal, live_signal, timestamp):
"""So sánh tín hiệu backtest và thực tế."""
if backtest_signal is None and live_signal is None:
return # Cả hai im lặng — OK
if (backtest_signal is None) != (live_signal is None):
self.divergences.append({
'timestamp': timestamp,
'type': 'signal_mismatch',
'backtest': backtest_signal,
'live': live_signal,
'severity': 'HIGH',
})
return
price_diff = abs(
backtest_signal.entry_price - live_signal.entry_price
) / backtest_signal.entry_price
if price_diff > self.tolerance:
self.divergences.append({
'timestamp': timestamp,
'type': 'price_divergence',
'diff_pct': price_diff * 100,
'severity': 'MEDIUM',
})
def compare_fill(self, backtest_fill, live_fill, timestamp):
"""So sánh thực thi."""
if backtest_fill and live_fill:
slippage = (live_fill['price'] - backtest_fill['price']
) / backtest_fill['price']
self.divergences.append({
'timestamp': timestamp,
'type': 'fill_divergence',
'slippage_bps': slippage * 10000,
'severity': 'LOW' if abs(slippage) < 0.001 else 'MEDIUM',
})
def report(self):
"""Báo cáo sai lệch hàng tuần."""
from collections import Counter
severity_counts = Counter(d['severity'] for d in self.divergences)
return {
'total_divergences': len(self.divergences),
'by_severity': dict(severity_counts),
'avg_slippage_bps': np.mean([
d['slippage_bps'] for d in self.divergences
if d['type'] == 'fill_divergence'
]) if any(d['type'] == 'fill_divergence'
for d in self.divergences) else 0,
}
Số liệu Dashboard
| Số liệu | Công thức | Ngưỡng cảnh báo |
|---|---|---|
| Tỷ lệ khớp tín hiệu | < 95% | |
| Slippage trung bình | (bps) | > 10 bps |
| Tỷ lệ khớp lệnh | < 90% | |
| Sai lệch PnL | > 20% | |
| Độ trễ p99 | Phân vị 99 tín hiệu đến khớp lệnh | > 500 ms |
Hiệu chỉnh Mô hình Slippage
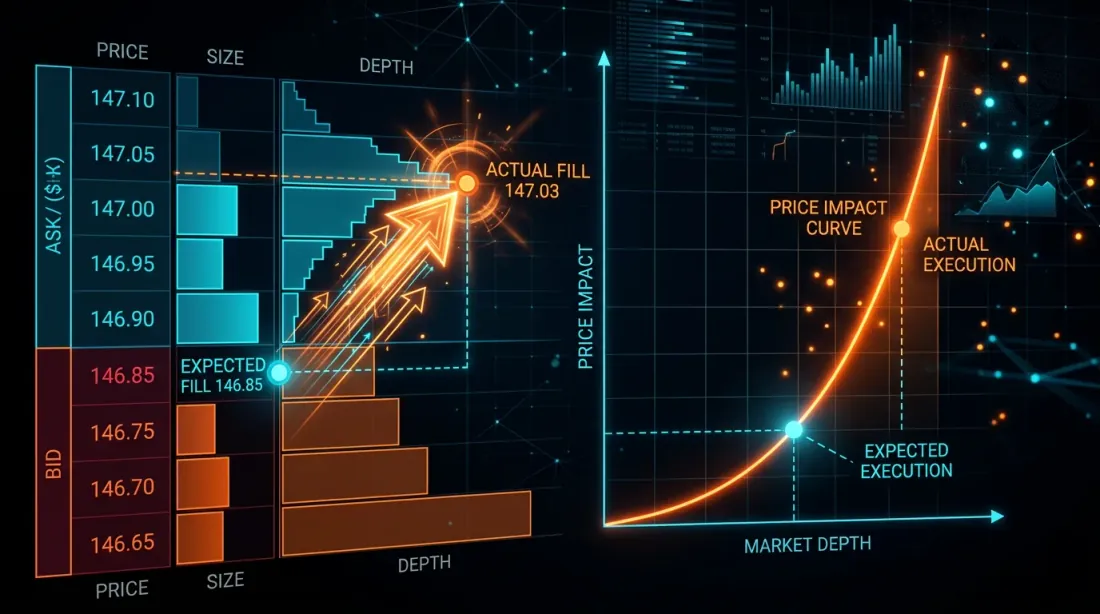
Sau khi tích lũy dữ liệu trong 2-4 tuần, bạn có thể hiệu chỉnh mô hình slippage backtest trên dữ liệu thực:
def calibrate_slippage(live_fills: list[dict]) -> dict:
"""
Hiệu chỉnh mô hình slippage sử dụng các lần khớp lệnh thực.
live_fills: [{'expected_price': ..., 'actual_price': ..., 'size_usd': ..., 'volume_usd': ...}]
"""
slippages = []
participation_rates = []
for fill in live_fills:
slip = abs(fill['actual_price'] - fill['expected_price']
) / fill['expected_price']
part = fill['size_usd'] / max(fill['volume_usd'], 1)
slippages.append(slip)
participation_rates.append(part)
slippages = np.array(slippages)
participation_rates = np.array(participation_rates)
from scipy.optimize import curve_fit
def model(x, k, base):
return k * np.sqrt(x) + base
popt, _ = curve_fit(model, participation_rates, slippages,
p0=[0.1, 0.0001])
return {
'impact_coeff': popt[0],
'base_slippage': popt[1],
'mean_slippage_bps': np.mean(slippages) * 10000,
'p95_slippage_bps': np.percentile(slippages, 95) * 10000,
}
Kết nối với Các Công cụ Khác
Backtest-live parity không phải là nhiệm vụ độc lập. Nó giao thoa với các công cụ khác từ loạt bài "Backtests Không Ảo tưởng":
- Adaptive drill-down — cải thiện độ chính xác mô phỏng khớp lệnh, thành phần chính của parity thực thi.
- Funding rates — nếu backtest không mô hình hóa funding, parity là không thể ở đòn bẩy > 3x.
- Parquet cache — các timeframe và chỉ báo được tính toán trước đảm bảo backtest nhìn thấy cùng dữ liệu như bot. Mô phỏng RunningCandleBuffer = cập nhật thời gian thực.
- Polars vs Pandas — khi chuyển từ pandas (backtest) sang Polars (thực tế), bạn cần đảm bảo kết quả số khớp nhau.
- Walk-Forward — walk-forward trên dữ liệu out-of-sample cho thấy cách chiến lược suy giảm — điều này gần với thực tế hơn backtest in-sample.
Khuyến nghị
-
Shared core là bắt buộc. Một codebase duy nhất để tạo tín hiệu là yêu cầu tối thiểu cho parity. Hai file với logic giống hệt nhau đảm bảo sai lệch trong vòng một tháng.
-
Hiệu chỉnh mô hình khớp lệnh. Slippage cố định 5 bps tốt hơn không có gì. Mô hình slippage được hiệu chỉnh trên dữ liệu thực tốt hơn đáng kể.
-
Sử dụng shadow mode trong 2-4 tuần đầu tiên. Không giao dịch bằng tiền thật cho đến khi tỷ lệ khớp tín hiệu đạt 95%+.
-
Mô hình hóa funding rates. Đối với hợp đồng tương lai vĩnh cửu, đây không phải tùy chọn — đây là bắt buộc. Funding có thể tiêu thụ toàn bộ PnL ở đòn bẩy > 5x.
-
Ghi log mọi thứ. Mọi tín hiệu, mọi lệnh, mọi lần khớp lệnh — với timestamps. Không có logs, phân tích post-mortem là không thể.
-
Tự động hóa việc so sánh. Báo cáo DivergenceMonitor hàng tuần nên đến tự động. Đừng chờ cho đến khi PnL âm.
-
Backtest bi quan theo mặc định. Tốt hơn là đánh giá thấp kỳ vọng trong backtest và ngạc nhiên dễ chịu trong thực tế hơn là ngược lại. Mô hình slippage nên bảo thủ.
Kết luận
Backtest-live parity không phải là thuộc tính của một hệ thống mà là một quy trình. Parity hoàn hảo không tồn tại: backtest theo định nghĩa là mô hình của thực tế, và mô hình luôn đơn giản hóa. Nhưng sự khác biệt giữa "mô hình khác 5%" và "mô hình khác 50%" được xác định bởi kiến trúc.
Ba mức độ trưởng thành:
- Cơ bản. Shared core, slippage cố định, hoa hồng. Sai lệch: 10-20%.
- Nâng cao. Kiến trúc hướng sự kiện, adaptive drill-down, mô hình funding, shadow mode. Sai lệch: 5-10%.
- Tổ chức. Mô phỏng L2 orderbook, mô hình tác động được hiệu chỉnh, giám sát sai lệch thời gian thực. Sai lệch: 2-5%.
Nhiệm vụ của bạn là xác định bạn đang ở mức nào và hiểu sai lệch nào bạn coi là chấp nhận được cho kích thước vị thế và đòn bẩy của bạn.
Liên kết Hữu ích
- NautilusTrader — Nền tảng Giao dịch Thuật toán Hiệu suất Cao
- Freqtrade — Bot giao dịch crypto miễn phí, mã nguồn mở
- Almgren, R., Chriss, N. — Optimal Execution of Portfolio Transactions (2001)
- Lopez de Prado — Advances in Financial Machine Learning, Chapter 12: Backtesting
- Ernest Chan — Quantitative Trading: How to Build Your Own Algorithmic Trading Business
- Hexagonal Architecture (Ports and Adapters) — Alistair Cockburn
- Optuna — Framework Tối ưu hóa Siêu tham số
Trích dẫn
@article{soloviov2026backtestliveparity,
author = {Soloviov, Eugen},
title = {Backtest-live parity: why your bot trades differently from the backtest},
year = {2026},
url = {https://marketmaker.cc/vi/blog/post/backtest-live-parity},
description = {Phân loại đầy đủ các sai lệch giữa backtest và giao dịch thực: từ slippage và khớp lệnh một phần đến sự không đồng bộ codebase. Các mô hình kiến trúc để đạt được parity và danh sách kiểm tra giám sát production.}
}
Tác Giả

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Đọc Thêm

PnL theo Thời Gian Hoạt Động: Chỉ Số Thay Đổi Thứ Hạng Chiến Lược

Adaptive Drill-Down: Backtest với Độ Phân Giải Biến Đổi từ Phút đến Giao Dịch Thô
