Coordinate Descent vs Optimasi Bayesian: Mana yang Menemukan Parameter Terbaik
Ini adalah artikel kelima dalam seri "Backtest Tanpa Ilusi". Dalam artikel sebelumnya kita membahas asimetri loss-profit, bootstrap Monte Carlo, dampak funding rate, dan cache Parquet untuk backtest lebih cepat. Sekarang mari kita bicara tentang proses menemukan parameter strategi yang optimal — tugas di mana intuisi paling sering gagal.
Anda memiliki strategi dengan 12 parameter. Setiap parameter mengambil ~9 nilai. Anda ingin menemukan kombinasi yang memaksimalkan PnL dengan drawdown terbatas. Bagaimana cara melakukannya?
Jika jawaban Anda adalah "Saya iterasi semua kombinasi" — Anda punya masalah. Jika jawaban Anda adalah "Saya mengubah satu parameter pada satu waktu" — Anda punya masalah yang berbeda. Artikel ini membahas masalah apa yang tersembunyi di balik setiap pendekatan dan cara menyelesaikannya.
Mengapa Pencarian Menyeluruh Mustahil

Kutukan Dimensionalitas
Pencarian menyeluruh (grid search) menguji setiap kombinasi nilai untuk setiap parameter. Untuk dua parameter dengan 9 nilai, itu adalah run — sangat layak. Untuk tiga: — masih bisa ditoleransi.
Namun untuk strategi nyata dengan 12 parameter:
Dua ratus delapan puluh dua miliar run. Bahkan jika satu backtest membutuhkan 1 detik (yang sudah optimis), pencarian menyeluruh akan memakan waktu:
Ini adalah pertumbuhan eksponensial: setiap parameter baru mengalikan ruang pencarian dengan 9. Tambahkan parameter ke-13 — dan alih-alih 9.000 tahun Anda butuh 80.000.
import math
def grid_search_cost(n_params: int, values_per_param: int, seconds_per_trial: float) -> dict:
"""Estimate the cost of exhaustive search."""
total_trials = values_per_param ** n_params
total_seconds = total_trials * seconds_per_trial
return {
"total_trials": total_trials,
"total_hours": total_seconds / 3600,
"total_years": total_seconds / (3600 * 24 * 365),
}
cost = grid_search_cost(12, 9, 1.0)
print(f"Trials: {cost['total_trials']:,.0f}") # 282,429,536,481
print(f"Years: {cost['total_years']:,.0f}") # 8,950
Bahkan dengan Pra-komputasi
Dalam artikel tentang cache Parquet kami menunjukkan bagaimana pra-komputasi timeframe dan indikator mempercepat satu backtest hingga ~1 detik. Namun bahkan pada 0,1 detik per run, pencarian menyeluruh 12 parameter membutuhkan 895 tahun. Pra-komputasi membantu, tetapi tidak menyelesaikan masalah mendasar pertumbuhan eksponensial.
Kita membutuhkan metode yang menjelajahi ruang parameter lebih cerdas daripada pencarian menyeluruh.
Coordinate Descent dan OAT: Cepat tapi Buta
Dua Varian dari Ide yang Sama
Ada dua pendekatan terkait — keduanya mengoptimalkan satu parameter sekaligus, tetapi berbeda dalam jumlah pass:
OAT (One-at-a-Time) sweep — satu pass melalui semua parameter. Iterasi melalui nilai-nilai parameter pertama, tetapkan yang terbaik, pindah ke yang kedua — dan seterusnya. Sekali saja. Cepat dan murah.
Coordinate Descent — multi-pass. Setelah mengoptimalkan parameter terakhir, kembali ke yang pertama dan periksa apakah optimum telah berubah (karena konteksnya berubah — nilai parameter lain sekarang berbeda). Ulangi putaran hingga konvergensi. Lebih mahal, tetapi lebih presisi — setiap putaran dapat menyempurnakan solusi.
Dalam praktiknya, untuk backtest OAT lebih sering digunakan: satu pass melalui 12 parameter — 96 run. Coordinate descent dengan 3-5 putaran — 300-500 run, yang sudah sebanding dengan Optuna, tetapi tanpa keunggulannya.
Untuk 12 parameter dengan ~8 nilai masing-masing:
Bandingkan dengan untuk grid search. OAT bersifat linier: alih-alih . Ini sekaligus merupakan keunggulan utama dan masalah utamanya.
def oat_sweep(
param_grid: dict[str, list],
run_backtest_fn,
initial_params: dict,
metric: str = "effective_score",
) -> dict:
"""
OAT sweep: single pass, optimizing one parameter at a time.
param_grid: {"htf_entry_sell": [0.0, 0.005, ..., 0.05], ...}
initial_params: starting values for all parameters
metric: metric to optimize (effective_score recommended —
PnL per active time extrapolated to a year)
"""
best_params = initial_params.copy()
best_score = run_backtest_fn(**best_params)[metric]
for param_name, values in param_grid.items():
param_best_val = best_params[param_name]
param_best_score = best_score
for val in values:
candidate = best_params.copy()
candidate[param_name] = val
result = run_backtest_fn(**candidate)
score = result[metric]
if score > param_best_score:
param_best_score = score
param_best_val = val
best_params[param_name] = param_best_val
best_score = param_best_score
print(f"{param_name}: best={param_best_val}, score={param_best_score:.4f}")
return best_params
Metrik mana yang dipilih untuk optimasi? Alih-alih PnL mentah atau PnL@MaxLev, disarankan menggunakan effective score — PnL per waktu aktif yang diekstrapolasi ke satu tahun. Metrik ini memperhitungkan waktu dalam posisi dan memungkinkan perbandingan yang benar antara strategi dengan frekuensi trading yang berbeda.
Titik Buta: Interaksi Parameter
OAT mengasumsikan bahwa efek setiap parameter bersifat aditif — yaitu, nilai optimal satu parameter tidak bergantung pada nilai parameter lainnya. Asumsi ini berlaku untuk beberapa parameter, tetapi gagal untuk parameter yang terkait.
Parameter Aditif vs Terkait
Sebelum mengoptimalkan — ada baiknya mengklasifikasikan parameter:
Aditif (independen) — nilai optimal satu tidak bergantung pada yang lain. Mereka dapat dioptimalkan satu per satu dengan murah:
htf_entry_selldanhtf_entry_buy— ambang entri untuk arah berbeda (jual/beli) pada timeframe yang sama. Ambang jual memfilter sinyal short, ambang beli — long. Mereka beroperasi pada subset trade yang tidak tumpang tindih.tp_targetdanbe_trigger— take-profit dan breakeven, jika tidak menciptakan kondisi exit yang bertentangan.
Terkait (interaktif) — nilai optimal satu bergantung pada yang lain. Optimasi bersama diperlukan:
htf_entry_selldanmtf_entry_sell— ambang untuk arah yang sama (jual) pada timeframe yang berbeda. HTF menentukan sinyal mana yang mencapai MTF, dan ambang MTF menentukan efektivitas filtering. Optimum HTF bergeser ketika MTF berubah.ltf_entry_sell,mtf_entry_sell,htf_entry_sell— seluruh rantai ambang untuk satu arah.partial_fracdantp_target— ukuran penutupan parsial bergantung pada level TP.
Pendekatan praktis: pertama optimalkan parameter aditif secara murah melalui OAT. Kemudian optimalkan grup terkait melalui Optuna. Ini mengurangi anggaran: alih-alih 12 parameter di Optuna, kita hanya mengirim 6-8 yang terkait, sementara sisanya sudah ditetapkan.
Contoh: Bagaimana OAT Melewatkan Interaksi
Pertimbangkan dua ambang terkait:
htf_entry_sell— ambang pada timeframe lebih tinggi (arah jual)mtf_entry_sell— ambang pada timeframe tengah (arah jual)
OAT menetapkan mtf_entry_sell = 0.01 (nilai awal) dan mengiterasi melalui htf_entry_sell. Menemukan nilai terbaik: htf_entry_sell = 0.02. Menetapkannya dan pindah ke parameter berikutnya — tidak pernah kembali.
Inilah yang dilewatkan OAT:
htf_entry_sell |
mtf_entry_sell |
PnL |
|---|---|---|
| 0.02 | 0.01 | +42% |
| 0.02 | 0.02 | +38% |
| 0.03 | 0.02 | +51% |
| 0.03 | 0.01 | +35% |
Kombinasi (0.03, 0.02) menghasilkan PnL +51%, tetapi OAT tidak akan pernah mempertimbangkannya karena dengan mtf_entry_sell = 0.01 yang tetap, nilai htf_entry_sell = 0.03 hanya menghasilkan +35%. OAT "terjebak" di optimum lokal (0.02, 0.01) dan tidak dapat melihat optimum global (0.03, 0.02).
Ini adalah masalah klasik: jika lanskap fungsi objektif mengandung punggung diagonal (ketika optimum satu parameter bergeser seiring perubahan parameter lain), OAT melewatkannya.
Memformalisasi Masalah
Misalkan adalah fungsi objektif (PnL). OAT menemukan titik di mana:
Namun ini adalah kondisi yang diperlukan, bukan kondisi yang cukup untuk optimum global. Jika matriks Hessian memiliki elemen off-diagonal yang signifikan — OAT tidak memperhitungkan turunan silang ketika .
Untuk parameter terkait (ambang arah yang sama di beberapa timeframe) — interaksi adalah aturan, bukan pengecualian. Ambang entri pada timeframe lebih tinggi menentukan sinyal mana yang mencapai timeframe tengah, dan ambang pada timeframe tengah menentukan efektivitas filtering pada timeframe lebih rendah. Untuk parameter aditif (arah berbeda, filter independen) turunan silang mendekati nol — dan OAT bekerja dengan baik.
Optimasi Bayesian: Pencarian Cerdas

Idenya
Alih-alih enumerasi buta atau pencarian serakah, optimasi Bayesian membangun model surrogate dari fungsi objektif dan pada setiap langkah memilih titik di mana peningkatan yang diharapkan maksimal.
Algoritma:
- Pilih beberapa titik acak, evaluasi fungsi objektif
- Bangun model surrogate (memperkirakan dari titik yang diamati)
- Temukan titik dengan peningkatan yang diharapkan maksimal (fungsi akuisisi)
- Evaluasi fungsi objektif di titik tersebut
- Perbarui model surrogate
- Ulangi langkah 3-5
Perbedaan utama dari OAT: optimasi Bayesian mempertimbangkan semua parameter secara bersamaan dan dapat menjelajahi punggung diagonal di ruang parameter.
TPE (Tree-structured Parzen Estimator)

TPE adalah sampler default di Optuna. Alih-alih memodelkan secara langsung, TPE memodelkan dua distribusi:
- — distribusi parameter di mana fungsi objektif lebih baik dari ambang
- — distribusi parameter di mana fungsi objektif lebih buruk dari ambang
Fungsi akuisisi TPE — rasio:
TPE memilih titik di mana besar (parameter mirip dengan yang "baik") dan kecil (parameter tidak mirip dengan yang "buruk").
Mengapa TPE cocok untuk backtest:
- Menangani dependensi kondisional antar parameter
- Tidak memerlukan kontinuitas fungsi objektif
- Efisien dengan anggaran sedang (100-1000 iterasi)
- Mendukung parameter kategorikal dan diskrit
Gaussian Process (GP)
Alternatif untuk TPE — Gaussian Process. GP memodelkan sebagai proses normal multivariat dan memberikan tidak hanya prediksi nilai, tetapi juga ketidakpastian di setiap titik.
di mana adalah rata-rata, adalah fungsi kovarians (kernel).
GP bekerja baik ketika:
- Ada sedikit parameter (hingga 10-15)
- Fungsi objektif mulus
- Setiap run mahal (menit, jam)
Untuk backtest dengan cache Parquet yang telah dihitung sebelumnya, di mana satu run membutuhkan ~1 detik, TPE biasanya lebih disukai: membangun model lebih cepat dan skala lebih baik ke 500+ iterasi.
Integrasi Praktis dengan Optuna
Contoh Kerja Lengkap
import optuna
from optuna.samplers import TPESampler
import numpy as np
def run_backtest(htf_pre, mtf_pre, ltf_pre, **params) -> dict:
"""
Runs a backtest with given parameters.
Returns a dict with metrics: pnl, max_dd, n_trades, trading_time, sharpe.
Uses precomputed Parquet cache — ~1 second per run.
"""
pass
def objective(trial: optuna.Trial) -> float:
"""Objective function for Optuna."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
study = optuna.create_study(
sampler=TPESampler(seed=42),
study_name="strategy_optimization",
direction="minimize",
)
study.optimize(objective, n_trials=500, show_progress_bar=True)
print(f"Best PnL: {-study.best_value:.2f}%")
print(f"Best params: {study.best_params}")
print(f"Total trials: {len(study.trials)}")
Pada ~1 detik per backtest (dengan cache yang telah dihitung sebelumnya):
Delapan menit versus 8.950 tahun pencarian menyeluruh. Dan TPE dalam 500 iterasi menemukan kombinasi yang dilewatkan OAT dalam 96, karena ia menjelajahi ruang parameter secara bersamaan alih-alih satu sumbu pada satu waktu.
Menyimpan dan Melanjutkan Study
import optuna
study = optuna.create_study(
storage="sqlite:///optuna_study.db",
study_name="strategy_v2",
sampler=TPESampler(seed=42),
direction="minimize",
load_if_exists=True, # continue if study already exists
)
study.optimize(objective, n_trials=300)
study.optimize(objective, n_trials=200)
Menambahkan Batasan
Tidak semua kombinasi parameter valid. Misalnya, ambang exit tidak boleh melebihi ambang entry:
def objective_with_constraints(trial: optuna.Trial) -> float:
htf_entry = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
htf_exit = trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005)
if htf_exit > htf_entry:
raise optuna.TrialPruned()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
Perbandingan Sampler
Optuna mendukung beberapa sampler. Masing-masing memiliki keunggulannya sendiri.
TPESampler (default)
sampler = optuna.samplers.TPESampler(
n_startup_trials=20, # random trials before modeling begins
seed=42,
)
- Prinsip: Tree-structured Parzen Estimator
- Keunggulan: baik untuk tipe parameter campuran, skala ke 1000+ iterasi
- Kelemahan: mungkin kurang efisien dengan interaksi parameter yang kuat
- Kapan digunakan: secara default, jika tidak ada alasan untuk memilih yang lain
CmaEsSampler
sampler = optuna.samplers.CmaEsSampler(seed=42)
- Prinsip: Covariance Matrix Adaptation Evolution Strategy — algoritma evolusioner yang mengadaptasi matriks kovarians
- Keunggulan: sangat baik dalam menemukan interaksi antara parameter kontinu, memperhitungkan korelasi
- Kelemahan: tidak mendukung parameter kategorikal, memerlukan lebih banyak iterasi untuk inisialisasi
- Kapan digunakan: jika semua parameter kontinu dan Anda mencurigai interaksi yang kuat
GPSampler
sampler = optuna.samplers.GPSampler(seed=42)
- Prinsip: Gaussian Process dengan fungsi akuisisi
- Keunggulan: efisiensi sampel terbaik (lebih sedikit iterasi untuk hasil yang baik), memberikan estimasi ketidakpastian
- Kelemahan: dalam jumlah iterasi — lambat ketika
- Kapan digunakan: jika satu backtest mahal (menit) dan anggaran terbatas hingga 100-200 iterasi
RandomSampler (baseline)
sampler = optuna.samplers.RandomSampler(seed=42)
- Prinsip: pengambilan sampel acak seragam
- Keunggulan: tidak terjebak di optimum lokal, cakupan ruang penuh
- Kelemahan: tidak menggunakan hasil sebelumnya
- Kapan digunakan: sebagai baseline untuk perbandingan, atau untuk analisis eksplorasi
QMCSampler
sampler = optuna.samplers.QMCSampler(seed=42)
- Prinsip: Quasi-Monte Carlo (urutan Sobol/Halton) — mengisi ruang lebih seragam daripada sampler acak
- Keunggulan: cakupan ruang lebih baik dari RandomSampler, reproduksibilitas
- Kelemahan: tidak beradaptasi dengan hasil
- Kapan digunakan: untuk 50-100 iterasi pertama sebelum beralih ke TPE
Tabel Ringkasan
| Sampler | Tipe | Interaksi | Kategorikal | Anggaran Terbaik |
|---|---|---|---|---|
| TPE | Bayesian | Parsial | Ya | 100-1000 |
| CmaEs | Evolusioner | Ya | Tidak | 200-2000 |
| GP | Bayesian | Ya | Terbatas | 50-200 |
| Random | Acak | Tidak | Ya | Semua (baseline) |
| QMC | Kuasi-acak | Tidak | Tidak | 50-500 |
Benchmark Praktis
import optuna
import time
def benchmark_sampler(sampler, n_trials=300):
"""Compare samplers on the same task."""
study = optuna.create_study(sampler=sampler, direction="minimize")
start = time.time()
study.optimize(objective, n_trials=n_trials, show_progress_bar=False)
elapsed = time.time() - start
return {
"best_value": -study.best_value,
"elapsed_sec": elapsed,
"best_trial": study.best_trial.number,
}
samplers = {
"TPE": optuna.samplers.TPESampler(seed=42),
"CmaEs": optuna.samplers.CmaEsSampler(seed=42),
"GP": optuna.samplers.GPSampler(seed=42),
"Random": optuna.samplers.RandomSampler(seed=42),
"QMC": optuna.samplers.QMCSampler(seed=42),
}
for name, sampler in samplers.items():
result = benchmark_sampler(sampler, n_trials=300)
print(f"{name:8s}: best PnL={result['best_value']:.2f}%, "
f"found at trial #{result['best_trial']}, "
f"time={result['elapsed_sec']:.1f}s")
Hasil tipikal untuk strategi dengan 12 parameter:
| Sampler | PnL Terbaik | Ditemukan pada Iterasi | Overhead Sampler |
|---|---|---|---|
| TPE | ~51% | ~180 | Rendah |
| CmaEs | ~49% | ~250 | Sedang |
| GP | ~48% | ~90 | Tinggi ketika |
| Random | ~42% | ~270 | Minimal |
| QMC | ~43% | ~200 | Minimal |
TPE dan CmaEs secara konsisten mengungguli pencarian acak sebesar 15-20% dalam PnL akhir. GP menemukan hasil yang baik lebih awal tetapi mencapai batas komputasi dengan jumlah iterasi yang besar.
Optimasi Multi-Objektif: PnL vs MaxDD
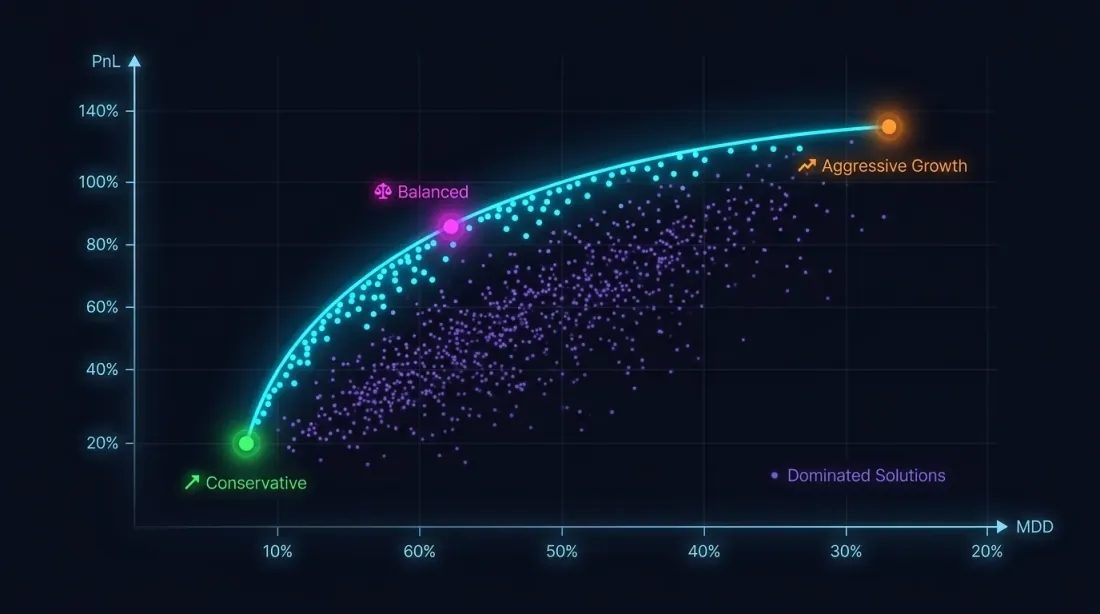
Mengapa Satu Kriteria Tidak Cukup
Memaksimalkan PnL tanpa batasan drawdown adalah jalan menuju bencana. Strategi dengan PnL +80% dan MaxDD -30% adalah, karena asimetri loss-profit, jauh lebih berisiko daripada strategi dengan PnL +50% dan MaxDD -5%.
Masalah optimasi sebenarnya bersifat multi-objektif:
Tujuan-tujuan ini bertentangan: parameter agresif meningkatkan PnL maupun drawdown. Solusinya bukan satu titik, melainkan Pareto front: sekumpulan solusi di mana Anda tidak dapat meningkatkan satu metrik tanpa memperburuk yang lain.
NSGA-II / NSGA-III di Optuna
import optuna
def multi_objective(trial: optuna.Trial) -> tuple[float, float]:
"""Multi-objective function: (PnL, MaxDD)."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
pnl = result["pnl"] # maximize
max_dd = result["max_dd"] # minimize (already a negative number)
return pnl, max_dd # Optuna: both directions are set in create_study
study = optuna.create_study(
directions=["maximize", "minimize"],
sampler=optuna.samplers.NSGAIIISampler(seed=42),
study_name="multi_objective_strategy",
)
study.optimize(multi_objective, n_trials=500)
pareto_trials = study.best_trials
print(f"Pareto front: {len(pareto_trials)} solutions")
for t in pareto_trials[:5]:
print(f" PnL={t.values[0]:.2f}%, MaxDD={t.values[1]:.2f}%")
Memilih Titik pada Pareto Front
Pareto front memberikan beberapa solusi. Bagaimana cara memilih satu?
def select_from_pareto(
pareto_trials: list,
max_dd_limit: float = -5.0,
min_pnl: float = 20.0,
) -> list:
"""
Filter the Pareto front by constraints.
max_dd_limit: maximum acceptable drawdown (e.g., -5%)
min_pnl: minimum acceptable PnL (%)
"""
filtered = []
for trial in pareto_trials:
pnl, max_dd = trial.values
if max_dd >= max_dd_limit and pnl >= min_pnl:
max_lev = min(50 / abs(max_dd), 100) if max_dd != 0 else 100
pnl_at_max_lev = pnl * max_lev
filtered.append({
"trial": trial,
"pnl": pnl,
"max_dd": max_dd,
"max_lev": max_lev,
"pnl_at_max_lev": pnl_at_max_lev,
})
filtered.sort(key=lambda x: x["pnl_at_max_lev"], reverse=True)
return filtered
Catatan: saat menghitung PnL pada leverage maksimum, Anda harus memperhitungkan funding rate, jika tidak leverage yang secara teoritis tinggi akan berubah menjadi kerugian di pasar nyata. Selain itu, PnL akhir adalah estimasi satu titik, dan untuk menilai stabilitas hasil Anda memerlukan bootstrap Monte Carlo.
Contoh: Tiga Strategi pada Pareto Front
| Strategi | PnL | MaxDD | MaxLev | PnL@MaxLev | Waktu trading |
|---|---|---|---|---|---|
| Strategi A | ~55% | ~0,9% | ~55x | ~3025% | ~15% |
| Strategi B | ~25% | ~0,75% | ~66x | ~1650% | ~5% |
| Strategi C | ~300% | ~17% | ~3x | ~900% | ~45% |
Strategi C dengan PnL yang mengesankan +300% ternyata paling tidak menarik berdasarkan PnL@MaxLev karena drawdown yang tinggi. Strategi A memimpin dalam return berleveraged bersih, tetapi dengan mempertimbangkan PnL per waktu aktif, Strategi B mungkin lebih disukai — 95% waktu bebas dapat diisi dengan strategi lain.
Contour Plot dan Pentingnya Parameter

Visualisasi Lanskap
Setelah optimasi — visualisasi. Optuna menyediakan alat bawaan:
import optuna.visualization as vis
fig_contour = vis.plot_contour(
study,
params=["htf_entry_sell", "mtf_entry_sell"],
)
fig_contour.show()
fig_importance = vis.plot_param_importances(study)
fig_importance.show()
fig_history = vis.plot_optimization_history(study)
fig_history.show()
fig_parallel = vis.plot_parallel_coordinate(
study,
params=["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell"],
)
fig_parallel.show()
fig_slice = vis.plot_slice(study)
fig_slice.show()
Contour Plot: Membaca Interaksi
Contour plot membangun penampang dua dimensi dari fungsi objektif untuk sepasang parameter. Jika isolines sejajar dengan salah satu sumbu — parameter tidak berinteraksi, dan OAT akan menemukan optimum yang sama. Jika isolines diagonal — ada interaksi, dan OAT akan melewatkannya.
key_params = ["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell",
"htf_entry_buy", "mtf_entry_buy", "ltf_entry_buy"]
for i, p1 in enumerate(key_params):
for p2 in key_params[i+1:]:
fig = vis.plot_contour(study, params=[p1, p2])
fig.write_image(f"contour_{p1}_vs_{p2}.png")
Jika contour plot menunjukkan plateau — wilayah di mana fungsi objektif berubah sedikit — ini adalah tanda yang baik. Plateau berarti hasilnya robust terhadap deviasi parameter kecil. Lebih lanjut tentang analisis plateau dan hubungannya dengan overfitting — dalam artikel mendatang Analisis plateau.
Pentingnya Parameter
importance = optuna.importance.get_param_importances(study)
for param, imp in importance.items():
print(f"{param:20s}: {imp:.4f}")
Output tipikal:
htf_entry_sell : 0.2841
mtf_entry_sell : 0.2103
ltf_entry_sell : 0.1567
trail_pct : 0.1204
htf_entry_buy : 0.0892
...
Parameter dengan kepentingan < 0,01 dapat ditetapkan pada nilai defaultnya — ini mengurangi dimensionalitas masalah dan mempercepat optimasi. Tetapi berhati-hatilah: kepentingan yang rendah mungkin juga berarti parameter tersebut penting hanya dalam interaksi dengan yang lain. Verifikasi melalui contour plot.
Cache yang Telah Dihitung Sebelumnya: Mengapa 1 Detik per Backtest Mengubah Segalanya
Kecepatan satu backtest menentukan metode optimasi mana yang dapat Anda gunakan.
| Waktu Backtest | 96 OAT | 500 TPE | 2000 CmaEs |
|---|---|---|---|
| 60 detik | 1,6 jam | 8,3 jam | 33 jam |
| 10 detik | 16 menit | 83 menit | 5,5 jam |
| 1 detik | 1,5 menit | 8 menit | 33 menit |
| 0,1 detik | 10 detik | 50 detik | 3,3 menit |
Pada 60 detik per backtest, 500 iterasi TPE membutuhkan 8 jam. Sudah bisa ditoleransi, tetapi melakukan iterasi (mengubah fungsi objektif, memulai ulang) itu mahal. Pada 1 detik — 8 menit, dan Anda dapat menjalankan puluhan eksperimen per hari.
Inilah tepatnya mengapa pra-komputasi ke cache Parquet bukan sekadar optimasi kecepatan, tetapi merupakan perluasan ruang metode yang tersedia. Tanpa cache Anda terbatas pada OAT atau 100 iterasi GP. Dengan cache — Anda dapat menggunakan 2000 iterasi CmaEs atau NSGA-III multi-objektif penuh.
import pyarrow.parquet as pq
import time
t0 = time.time()
htf_pre = pq.read_table("cache/htf_indicators.parquet").to_pandas()
mtf_pre = pq.read_table("cache/mtf_indicators.parquet").to_pandas()
ltf_pre = pq.read_table("cache/ltf_indicators.parquet").to_pandas()
print(f"Cache loaded in {time.time() - t0:.2f}s") # ~0.3s
t1 = time.time()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, htf_entry_sell=0.02, ...)
print(f"Backtest in {time.time() - t1:.2f}s") # ~1.0s
Rekomendasi Praktis
Kapan Menggunakan OAT
OAT dibenarkan dalam kasus-kasus berikut:
-
Analisis eksplorasi. Anda baru mulai menjelajahi strategi dan ingin memahami parameter mana yang memengaruhi hasil sama sekali. 96 run dalam 1,5 menit — titik awal yang sangat baik.
-
Parameter aditif. Untuk parameter yang beroperasi pada subset trade yang tidak tumpang tindih (arah jual vs beli, instrumen berbeda), OAT akan memberikan hasil yang benar lebih cepat.
-
Backtest yang sangat mahal. Jika satu run membutuhkan 10+ menit dan tidak bisa dipercepat, OAT dengan 96 run (16 jam) lebih disukai daripada 500 iterasi TPE (3,5 hari).
Kapan Menggunakan Optuna
Optuna lebih disukai dalam sebagian besar kasus:
-
Lebih dari 3 parameter. Interaksi hampir pasti ada — OAT akan melewatkan optimum.
-
Strategi multi-timeframe. Ambang di timeframe berbeda hampir selalu saling terkait.
-
Optimasi akhir. Ketika strategi telah melewati bootstrap Monte Carlo dan Anda yakin dengan robustnessnya — Optuna akan menemukan parameter terbaik.
-
Masalah multi-objektif. PnL vs MaxDD vs waktu trading — OAT tidak dapat menyelesaikan masalah ini pada prinsipnya.
Pendekatan Hibrida: OAT untuk Aditif + Optuna untuk Terkait
Anda tidak harus memilih antara OAT dan Optuna — lebih baik menggabungkannya:
-
Klasifikasikan parameter. Bagi menjadi aditif (independen) dan terkait (interaktif). Contoh untuk 12 parameter pemisah:
- Aditif:
htf_entry_sell<->htf_entry_buy,mtf_entry_sell<->mtf_entry_buy,ltf_entry_sell<->ltf_entry_buy(jual/beli — arah berbeda, beroperasi pada trade yang tidak tumpang tindih) - Grup terkait jual:
htf_entry_sell,mtf_entry_sell,ltf_entry_sell(rantai filtering: HTF -> MTF -> LTF untuk sinyal jual) - Grup terkait beli:
htf_entry_buy,mtf_entry_buy,ltf_entry_buy
- Aditif:
-
OAT untuk aditif. Optimalkan grup jual dan beli secara independen. Jika parameter jual tidak memengaruhi trade beli — OAT akan memberikan hasil yang benar dalam beberapa menit.
-
Optuna untuk terkait. Dalam setiap grup (jual: 6 parameter entry+exit) gunakan TPE. 6 parameter alih-alih 12 — anggaran dipotong setengah.
sell_params = oat_sweep(sell_param_grid, run_backtest, initial_params)
def objective_sell(trial):
params = sell_params.copy()
params["htf_entry_sell"] = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
params["mtf_entry_sell"] = trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005)
params["ltf_entry_sell"] = trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005)
params["htf_exit_sell"] = trial.suggest_float("htf_exit_sell", 0.0, 0.02, step=0.001)
params["mtf_exit_sell"] = trial.suggest_float("mtf_exit_sell", 0.0, 0.02, step=0.001)
params["ltf_exit_sell"] = trial.suggest_float("ltf_exit_sell", 0.0, 0.02, step=0.001)
return -run_backtest(**params)["effective_score"]
study = optuna.create_study(sampler=optuna.samplers.TPESampler())
study.optimize(objective_sell, n_trials=300) # 6 parameters → 300 is enough
Pipeline Optimasi Lengkap
1. Precompute Parquet cache (once)
2. Classify parameters: additive vs coupled
3. OAT for additive (~50 runs, ~1 min) → fix
4. Optuna TPE for coupled groups (300 iterations x 2 groups, ~10 min)
5. Optuna NSGA-III for meta-parameters (500 iterations, ~8 min) → Pareto front
6. Contour plots → visualize interactions
7. Monte Carlo bootstrap of best points → confidence intervals
8. Walk-Forward → out-of-sample validation
Langkah 8 — walk-forward optimization — sangat penting untuk perlindungan terhadap overfitting. Lebih lanjut tentang ini dalam artikel mendatang Walk-Forward.
Jebakan Optimasi
Overfitting. Semakin banyak parameter dan semakin tepat optimasi — semakin tinggi risiko menyesuaikan strategi dengan data historis. 500 iterasi Optuna dengan 12 parameter akan menemukan kombinasi yang bekerja sempurna pada set pelatihan, tetapi tidak berguna pada data baru.
Perlindungan:
- Bagi data menjadi train/test (70/30)
- Gunakan bootstrap Monte Carlo untuk menilai stabilitas
- Validasi melalui walk-forward
- Pilih solusi pada plateau (lebih lanjut tentang ini di Analisis plateau)
Masalah perbandingan berganda. Jika Anda menguji 500 kombinasi, probabilitas secara acak menemukan hasil "baik" meningkat. Koreksi Bonferroni atau kontrol FDR (False Discovery Rate) membantu, tetapi pendekatan yang lebih sederhana adalah validasi out-of-sample.
Anggaran tidak mencukupi. TPE dengan 50 iterasi untuk 12 parameter terlalu sedikit. 20 iterasi pertama bersifat acak (startup), menyisakan hanya 30 untuk pemodelan. Anggaran minimum: iterasi untuk 12 parameter, yang disarankan: .
Freqtrade: Cara Kerjanya dalam Framework Produksi

Freqtrade — salah satu framework algotrading yang populer — menggunakan Optuna di balik layar melalui modul Hyperopt. Pengalamannya mengkonfirmasi rekomendasi kita:
- Sampler: TPE (default), GP, CmaEs, NSGA-II, QMC — semua tersedia melalui konfigurasi
- Fungsi loss: 12 fungsi loss bawaan, termasuk ShortTradeDurHyperOptLoss, SharpeHyperOptLoss, MaxDrawDownHyperOptLoss
- Multi-objektif: dukungan untuk NSGA-II dan NSGA-III untuk optimasi simultan beberapa metrik
- Sampler kustom: kemampuan untuk menghubungkan sampler Optuna yang kompatibel
Pelajaran utama dari ekosistem Freqtrade: fungsi loss bawaan mencakup skenario tipikal, tetapi untuk optimasi serius Anda memerlukan fungsi objektif kustom yang memperhitungkan spesifik strategi Anda — waktu aktif, biaya funding, drill-down adaptif untuk simulasi fill yang akurat.
Kesimpulan

Coordinate descent (OAT) adalah metode yang cepat dan intuitif. Untuk 12 parameter hanya memerlukan 96 run dan selesai dalam satu setengah menit. Namun ia buta terhadap interaksi parameter — dan dalam strategi multi-timeframe, interaksi hampir selalu ada.
Optimasi Bayesian melalui Optuna (TPE, GP, CmaEs) menjelajahi ruang parameter secara keseluruhan. 500 iterasi dalam 8 menit — dengan cache Parquet yang telah dihitung sebelumnya — menemukan kombinasi yang tidak terlihat oleh OAT.
Optimasi multi-objektif (NSGA-III) mengubah masalah "maksimalkan PnL" menjadi masalah "bangun Pareto front PnL vs MaxDD" — dan memberikan sekumpulan solusi dengan tradeoff risk-return yang berbeda.
Namun optimasi hanyalah bagian dari pipeline. Parameter yang ditemukan perlu divalidasi melalui bootstrap Monte Carlo, dikoreksi untuk funding rate, dihitung ulang dengan mempertimbangkan waktu aktif, dan dijalankan melalui validasi walk-forward. Lebih lanjut tentang itu dalam artikel mendatang dari seri ini.
Tautan Berguna
- Optuna: A Next-generation Hyperparameter Optimization Framework (Akiba et al., 2019)
- Algorithms for Hyper-Parameter Optimization (Bergstra et al., 2011) — the original TPE paper
- Optuna Documentation — Samplers
- Optuna Visualization Module
- Hansen, N. — The CMA Evolution Strategy: A Tutorial
- Deb, K. et al. — NSGA-II: A Fast and Elitist Multiobjective Genetic Algorithm (2002)
- Snoek, J. et al. — Practical Bayesian Optimization of Machine Learning Algorithms (2012)
- Freqtrade Documentation — Hyperopt
- Marcos Lopez de Prado — Advances in Financial Machine Learning, Chapter 12
- Bergstra, J. & Bengio, Y. — Random Search for Hyper-Parameter Optimization (2012)
Kutipan
@article{soloviov2026optuna,
author = {Soloviov, Eugen},
title = {Coordinate Descent vs Bayesian Optimization: Which Finds Better Parameters},
year = {2026},
url = {https://marketmaker.cc/id/blog/post/optuna-vs-coordinate-descent},
description = {Mengapa pencarian menyeluruh mustahil untuk 12+ parameter, bagaimana coordinate descent melewatkan interaksi, dan bagaimana Optuna dengan sampler TPE menemukan dalam 500 iterasi apa yang OAT tidak bisa temukan dalam 96.}
}
Penulis

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Baca Selengkapnya

Drill-Down Adaptif: Backtest dengan Granularitas Bervariasi dari Menit hingga Trade Mentah

Cache Parquet Teragregasi: Cara Mempercepat Backtest Multi-Timeframe Ratusan Kali Lipat
