Coordinate Descent กับ Bayesian Optimization: วิธีไหนหาพารามิเตอร์ที่ดีกว่ากัน
นี่คือบทความที่ห้าในซีรีส์ "Backtests Without Illusions" ในบทความก่อนหน้าเราได้พูดถึง ความไม่สมมาตรของการขาดทุน-กำไร, Monte Carlo bootstrap, ผลกระทบของ funding rates, และ Parquet cache สำหรับ backtest ที่เร็วขึ้น ตอนนี้มาพูดถึงกระบวนการหาพารามิเตอร์ที่เหมาะสมของกลยุทธ์ — งานที่สัญชาตญาณมักล้มเหลวบ่อยที่สุด
คุณมีกลยุทธ์ที่มี 12 พารามิเตอร์ แต่ละพารามิเตอร์รับ ~9 ค่า คุณต้องการหาชุดค่าผสมที่ทำให้ PnL สูงสุดพร้อม drawdown ที่จำกัด จะทำอย่างไร?
ถ้าคำตอบของคุณคือ "ฉันลองทุกชุดค่าผสม" — คุณมีปัญหา ถ้าคำตอบของคุณคือ "ฉันเปลี่ยนพารามิเตอร์ทีละตัว" — คุณมีปัญหาต่างออกไป บทความนี้พูดถึงปัญหาที่ซ่อนอยู่ในแต่ละแนวทางและวิธีแก้ไข
ทำไมการค้นหาแบบครอบคลุมจึงเป็นไปไม่ได้

คำสาปของมิติ
การค้นหาแบบครอบคลุม (grid search) ทดสอบทุกชุดค่าผสมของค่าสำหรับทุกพารามิเตอร์ สำหรับพารามิเตอร์สองตัวที่มี 9 ค่า นั่นคือ รอบ — ทำได้สบาย สำหรับสามตัว: — พอรับได้
แต่สำหรับกลยุทธ์จริงที่มี 12 พารามิเตอร์:
สองแสนแปดหมื่นสองพันล้านรอบ แม้ backtest เพียงครั้งเดียวใช้เวลา 1 วินาที (ซึ่งถือว่าดีมากแล้ว) การค้นหาแบบครอบคลุมจะใช้เวลา:
นี่คือการเติบโตแบบเอกซ์โพเนนเชียล: พารามิเตอร์ใหม่แต่ละตัวคูณพื้นที่ค้นหาด้วย 9 เพิ่มพารามิเตอร์ตัวที่ 13 — และแทนที่จะใช้เวลา 9,000 ปีคุณต้องใช้ 80,000 ปี
import math
def grid_search_cost(n_params: int, values_per_param: int, seconds_per_trial: float) -> dict:
"""Estimate the cost of exhaustive search."""
total_trials = values_per_param ** n_params
total_seconds = total_trials * seconds_per_trial
return {
"total_trials": total_trials,
"total_hours": total_seconds / 3600,
"total_years": total_seconds / (3600 * 24 * 365),
}
cost = grid_search_cost(12, 9, 1.0)
print(f"Trials: {cost['total_trials']:,.0f}") # 282,429,536,481
print(f"Years: {cost['total_years']:,.0f}") # 8,950
แม้จะมีการคำนวณล่วงหน้า
ในบทความเกี่ยวกับ Parquet cache เราแสดงให้เห็นว่าการคำนวณ timeframe และ indicator ล่วงหน้าช่วยเร่ง backtest แต่ละครั้งให้เหลือ ~1 วินาที แต่แม้ที่ 0.1 วินาทีต่อรอบ การค้นหาแบบครอบคลุมของ 12 พารามิเตอร์ก็ยังต้องใช้เวลา 895 ปี การคำนวณล่วงหน้าช่วยได้ แต่ไม่ได้แก้ปัญหาพื้นฐานของการเติบโตแบบเอกซ์โพเนนเชียล
เราต้องการวิธีที่สำรวจพื้นที่พารามิเตอร์ อย่างชาญฉลาด กว่าการค้นหาแบบครอบคลุม
Coordinate Descent และ OAT: เร็วแต่ตาบอด
สองรูปแบบของแนวคิดเดียวกัน
มีสองแนวทางที่เกี่ยวข้องกัน — ทั้งคู่ปรับแต่งพารามิเตอร์ทีละตัว แต่แตกต่างกันในจำนวนรอบผ่าน:
OAT (One-at-a-Time) sweep — รอบผ่านเดียวผ่านพารามิเตอร์ทั้งหมด ลองค่าของพารามิเตอร์แรก, ตรึงค่าที่ดีที่สุด, ไปยังตัวที่สอง — และเช่นนั้นต่อไป ครั้งเดียว เร็วและประหยัด
Coordinate Descent — หลายรอบผ่าน หลังจากปรับแต่งพารามิเตอร์สุดท้ายแล้ว กลับไปที่ตัวแรกและตรวจสอบว่าค่าที่ดีที่สุดเปลี่ยนไปหรือไม่ (เนื่องจากบริบทเปลี่ยน — ค่าพารามิเตอร์อื่นๆ แตกต่างออกไปแล้ว) ทำซ้ำรอบจนกว่าจะลู่เข้า แพงกว่า แต่แม่นยำกว่า — แต่ละรอบสามารถปรับปรุงคำตอบได้
ในทางปฏิบัติ สำหรับ backtest จะใช้ OAT บ่อยกว่า: รอบผ่านเดียวผ่าน 12 พารามิเตอร์ — 96 รอบ Coordinate descent ที่ 3-5 รอบ — 300-500 รอบ ซึ่งเทียบได้กับ Optuna แล้ว แต่ไม่มีข้อได้เปรียบของมัน
สำหรับ 12 พารามิเตอร์ที่มี ~8 ค่าแต่ละตัว:
เทียบกับ สำหรับ grid search OAT เป็นแบบเชิงเส้น: แทนที่จะเป็น นี่คือทั้งข้อได้เปรียบหลักและปัญหาหลักของมัน
def oat_sweep(
param_grid: dict[str, list],
run_backtest_fn,
initial_params: dict,
metric: str = "effective_score",
) -> dict:
"""
OAT sweep: single pass, optimizing one parameter at a time.
param_grid: {"htf_entry_sell": [0.0, 0.005, ..., 0.05], ...}
initial_params: starting values for all parameters
metric: metric to optimize (effective_score recommended —
PnL per active time extrapolated to a year)
"""
best_params = initial_params.copy()
best_score = run_backtest_fn(**best_params)[metric]
for param_name, values in param_grid.items():
param_best_val = best_params[param_name]
param_best_score = best_score
for val in values:
candidate = best_params.copy()
candidate[param_name] = val
result = run_backtest_fn(**candidate)
score = result[metric]
if score > param_best_score:
param_best_score = score
param_best_val = val
best_params[param_name] = param_best_val
best_score = param_best_score
print(f"{param_name}: best={param_best_val}, score={param_best_score:.4f}")
return best_params
จะเลือก metric ไหนสำหรับการปรับแต่ง? แทนที่จะใช้ PnL ดิบหรือ PnL@MaxLev แนะนำให้ใช้ effective score — PnL ต่อเวลาที่ใช้งานจริง ที่ extrapolate เป็นรายปี metric นี้คำนึงถึงเวลาที่อยู่ในตำแหน่งและช่วยให้เปรียบเทียบกลยุทธ์ที่มีความถี่การซื้อขายต่างกันได้อย่างถูกต้อง
จุดอับ: ปฏิสัมพันธ์ระหว่างพารามิเตอร์
OAT สมมติว่าผลกระทบของแต่ละพารามิเตอร์เป็น แบบบวก — นั่นคือค่าที่เหมาะสมของพารามิเตอร์หนึ่งไม่ขึ้นอยู่กับค่าของพารามิเตอร์อื่น สมมติฐานนี้ใช้ได้กับพารามิเตอร์บางตัว แต่พังสำหรับพารามิเตอร์ที่มีความเชื่อมโยงกัน
พารามิเตอร์แบบบวก กับ แบบมีความเชื่อมโยง
ก่อนการปรับแต่ง — มีประโยชน์ที่จะจำแนกพารามิเตอร์:
แบบบวก (อิสระ) — ค่าที่เหมาะสมของหนึ่งไม่ขึ้นอยู่กับอีกตัว สามารถปรับแต่งทีละตัวได้อย่างประหยัด:
htf_entry_sellและhtf_entry_buy— threshold การเข้าสำหรับทิศทางต่างกัน (sell/buy) บน timeframe เดียวกัน threshold sell กรองสัญญาณ short, threshold buy — กรอง long ดำเนินการบนชุดย่อยของการซื้อขายที่ไม่ทับซ้อนกันtp_targetและbe_trigger— take-profit และ breakeven ถ้าไม่สร้างเงื่อนไขออกที่ขัดแย้งกัน
แบบมีความเชื่อมโยง (interactive) — ค่าที่เหมาะสมของหนึ่งขึ้นอยู่กับอีกตัว ต้องการการปรับแต่งร่วมกัน:
htf_entry_sellและmtf_entry_sell— threshold สำหรับทิศทางเดียวกัน (sell) บน timeframe ต่างกัน HTF กำหนดว่าสัญญาณใดถึง MTF และ MTF threshold กำหนดประสิทธิภาพของการกรอง ค่าที่เหมาะสมของ HTF เปลี่ยนเมื่อ MTF เปลี่ยนltf_entry_sell,mtf_entry_sell,htf_entry_sell— ห่วงโซ่ threshold ทั้งหมดสำหรับทิศทางเดียวpartial_fracและtp_target— ขนาดการปิดบางส่วนขึ้นอยู่กับระดับ TP
แนวทางปฏิบัติ: ก่อนปรับแต่งพารามิเตอร์แบบบวกด้วยราคาถูกผ่าน OAT จากนั้นปรับแต่งกลุ่มที่มีความเชื่อมโยงผ่าน Optuna สิ่งนี้ลดงบประมาณ: แทนที่จะส่ง 12 พารามิเตอร์ไปใน Optuna เราส่งเพียง 6-8 ตัวที่มีความเชื่อมโยง ส่วนที่เหลือถูกตรึงไว้แล้ว
ตัวอย่าง: OAT พลาดปฏิสัมพันธ์อย่างไร
พิจารณา threshold ที่ มีความเชื่อมโยง สองตัว:
htf_entry_sell— threshold บน timeframe ที่สูงกว่า (ทิศทาง sell)mtf_entry_sell— threshold บน timeframe ระดับกลาง (ทิศทาง sell)
OAT ตรึง mtf_entry_sell = 0.01 (ค่าเริ่มต้น) และลองค่าต่างๆ ของ htf_entry_sell พบค่าที่ดีที่สุด: htf_entry_sell = 0.02 ตรึงมันและไปยังพารามิเตอร์ถัดไป — ไม่เคยกลับมา
นี่คือสิ่งที่ OAT พลาด:
htf_entry_sell |
mtf_entry_sell |
PnL |
|---|---|---|
| 0.02 | 0.01 | +42% |
| 0.02 | 0.02 | +38% |
| 0.03 | 0.02 | +51% |
| 0.03 | 0.01 | +35% |
ชุดค่าผสม (0.03, 0.02) ให้ PnL +51% แต่ OAT จะไม่มีวันพิจารณามันเพราะเมื่อตรึง mtf_entry_sell = 0.01, ค่า htf_entry_sell = 0.03 ให้เพียง +35% OAT "ติดอยู่" ใน local optimum (0.02, 0.01) และไม่สามารถเห็น global optimum (0.03, 0.02) ได้
นี่คือปัญหาคลาสสิก: ถ้า ภูมิทัศน์ของฟังก์ชันเป้าหมายมีสันเขาแนวทแยง (เมื่อ optimum ของพารามิเตอร์หนึ่งเปลี่ยนเมื่ออีกตัวเปลี่ยน) OAT จะพลาด
การทำให้เป็นทางการของปัญหา
ให้ เป็นฟังก์ชันเป้าหมาย (PnL) OAT หาจุดที่:
แต่นี่เป็นเงื่อนไขที่จำเป็น ไม่ใช่เพียงพอสำหรับ global optimum ถ้า Hessian matrix มี off-diagonal element ที่มีนัยสำคัญ — OAT ไม่คำนึงถึง cross-derivative เมื่อ
สำหรับพารามิเตอร์ที่มีความเชื่อมโยง (threshold ในทิศทางเดียวกันข้ามหลาย timeframe) — ปฏิสัมพันธ์เป็นกฎ ไม่ใช่ข้อยกเว้น entry threshold บน timeframe ที่สูงกว่าจะกำหนดว่าสัญญาณใดถึงระดับกลาง และ threshold ระดับกลางจะกำหนดประสิทธิภาพการกรองบนระดับล่าง สำหรับพารามิเตอร์แบบบวก (ทิศทางต่างกัน, filter อิสระ) cross-derivative ใกล้ศูนย์ — และ OAT ทำงานได้ดี
Bayesian Optimization: การค้นหาที่ชาญฉลาด

แนวคิด
แทนที่จะทำการ enumerate แบบตาบอดหรือการค้นหาแบบ greedy Bayesian optimization สร้าง surrogate model ของฟังก์ชันเป้าหมายและในแต่ละขั้นตอนเลือกจุดที่ การปรับปรุงที่คาดหวังสูงสุด
อัลกอริทึม:
- เลือกจุดสุ่มหลายจุด, ประเมินฟังก์ชันเป้าหมาย
- สร้าง surrogate model (ประมาณ จากจุดที่สังเกต)
- หาจุดที่มีการปรับปรุงที่คาดหวังสูงสุด (acquisition function)
- ประเมินฟังก์ชันเป้าหมายที่จุดนั้น
- อัปเดต surrogate model
- ทำซ้ำขั้นตอน 3-5
ความแตกต่างหลักจาก OAT: Bayesian optimization พิจารณาพารามิเตอร์ทั้งหมดพร้อมกัน และสามารถสำรวจสันเขาแนวทแยงในพื้นที่พารามิเตอร์ได้
TPE (Tree-structured Parzen Estimator)

TPE คือ sampler เริ่มต้นใน Optuna แทนที่จะ model โดยตรง TPE จะ model การกระจายสองแบบ:
- — การกระจายของพารามิเตอร์ที่ฟังก์ชันเป้าหมายดีกว่า threshold
- — การกระจายของพารามิเตอร์ที่ฟังก์ชันเป้าหมายแย่กว่า threshold
acquisition function ของ TPE — อัตราส่วน:
TPE เลือกจุดที่ มีขนาดใหญ่ (พารามิเตอร์คล้ายกับตัว "ดี") และ มีขนาดเล็ก (พารามิเตอร์ไม่คล้ายกับตัว "ไม่ดี")
ทำไม TPE เหมาะสำหรับ backtest:
- รองรับการพึ่งพาตามเงื่อนไขระหว่างพารามิเตอร์
- ไม่ต้องการความต่อเนื่องของฟังก์ชันเป้าหมาย
- มีประสิทธิภาพด้วยงบประมาณปานกลาง (100-1000 รอบ)
- รองรับพารามิเตอร์แบบ categorical และ discrete
Gaussian Process (GP)
ทางเลือกสำหรับ TPE — Gaussian Process GP จะ model เป็น multivariate normal process และให้ไม่เพียงแค่การพยากรณ์ค่า แต่ยัง ความไม่แน่นอน ที่แต่ละจุด
โดยที่ คือค่าเฉลี่ย, คือฟังก์ชัน covariance (kernel)
GP ทำงานได้ดีเมื่อ:
- มีพารามิเตอร์จำนวนน้อย (สูงสุด 10-15 ตัว)
- ฟังก์ชันเป้าหมายมีความราบรื่น
- แต่ละรอบมีต้นทุนสูง (นาที, ชั่วโมง)
สำหรับ backtest ที่มี Parquet cache ที่คำนวณล่วงหน้า ซึ่งรอบเดียวใช้เวลา ~1 วินาที มักนิยม TPE มากกว่า: มัน build model ได้เร็วกว่าและ scale ได้ดีกว่าสำหรับ 500+ รอบ
การรวม Optuna เข้ากับการใช้งานจริง
ตัวอย่างการทำงานเต็มรูปแบบ
import optuna
from optuna.samplers import TPESampler
import numpy as np
def run_backtest(htf_pre, mtf_pre, ltf_pre, **params) -> dict:
"""
Runs a backtest with given parameters.
Returns a dict with metrics: pnl, max_dd, n_trades, trading_time, sharpe.
Uses precomputed Parquet cache — ~1 second per run.
"""
pass
def objective(trial: optuna.Trial) -> float:
"""Objective function for Optuna."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
study = optuna.create_study(
sampler=TPESampler(seed=42),
study_name="strategy_optimization",
direction="minimize",
)
study.optimize(objective, n_trials=500, show_progress_bar=True)
print(f"Best PnL: {-study.best_value:.2f}%")
print(f"Best params: {study.best_params}")
print(f"Total trials: {len(study.trials)}")
ที่ ~1 วินาทีต่อ backtest (ด้วย cache ที่คำนวณล่วงหน้า):
แปดนาทีเทียบกับ 8,950 ปีของการค้นหาแบบครอบคลุม และ TPE ใน 500 รอบหาชุดค่าผสมที่ OAT พลาดใน 96 รอบ เพราะมันสำรวจพื้นที่พารามิเตอร์ พร้อมกัน แทนที่จะทีละแกน
การบันทึกและดำเนินการต่อ Study
import optuna
study = optuna.create_study(
storage="sqlite:///optuna_study.db",
study_name="strategy_v2",
sampler=TPESampler(seed=42),
direction="minimize",
load_if_exists=True, # continue if study already exists
)
study.optimize(objective, n_trials=300)
study.optimize(objective, n_trials=200)
การเพิ่มข้อจำกัด
ไม่ใช่ทุกชุดค่าผสมของพารามิเตอร์จะถูกต้อง ตัวอย่างเช่น threshold การออกไม่ควรเกิน threshold การเข้า:
def objective_with_constraints(trial: optuna.Trial) -> float:
htf_entry = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
htf_exit = trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005)
if htf_exit > htf_entry:
raise optuna.TrialPruned()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
การเปรียบเทียบ Sampler
Optuna รองรับ sampler หลายตัว แต่ละตัวมีจุดแข็งของตัวเอง
TPESampler (ค่าเริ่มต้น)
sampler = optuna.samplers.TPESampler(
n_startup_trials=20, # random trials before modeling begins
seed=42,
)
- หลักการ: Tree-structured Parzen Estimator
- จุดแข็ง: ดีสำหรับพารามิเตอร์ประเภทผสม, scale ได้ถึง 1000+ รอบ
- จุดอ่อน: อาจมีประสิทธิภาพน้อยกว่าเมื่อมีปฏิสัมพันธ์ระหว่างพารามิเตอร์ที่แข็งแกร่ง
- เมื่อไรใช้: โดยค่าเริ่มต้น ถ้าไม่มีเหตุผลที่จะเลือกตัวอื่น
CmaEsSampler
sampler = optuna.samplers.CmaEsSampler(seed=42)
- หลักการ: Covariance Matrix Adaptation Evolution Strategy — อัลกอริทึมเชิงวิวัฒนาการที่ปรับ covariance matrix
- จุดแข็ง: ยอดเยี่ยมในการหาปฏิสัมพันธ์ระหว่างพารามิเตอร์ต่อเนื่อง, คำนึงถึง correlation
- จุดอ่อน: ไม่รองรับพารามิเตอร์ categorical, ต้องการรอบมากกว่าสำหรับการเริ่มต้น
- เมื่อไรใช้: ถ้าพารามิเตอร์ทั้งหมดเป็นแบบต่อเนื่องและคุณสงสัยว่ามีปฏิสัมพันธ์ที่แข็งแกร่ง
GPSampler
sampler = optuna.samplers.GPSampler(seed=42)
- หลักการ: Gaussian Process พร้อม acquisition function
- จุดแข็ง: ประสิทธิภาพ sample ที่ดีที่สุด (รอบน้อยกว่าสำหรับผลลัพธ์ที่ดี), ให้การประมาณความไม่แน่นอน
- จุดอ่อน: ตามจำนวนรอบ — ช้าเมื่อ
- เมื่อไรใช้: ถ้า backtest แต่ละครั้งมีต้นทุนสูง (นาที) และงบประมาณจำกัดอยู่ที่ 100-200 รอบ
RandomSampler (baseline)
sampler = optuna.samplers.RandomSampler(seed=42)
- หลักการ: การสุ่มแบบ uniform
- จุดแข็ง: ไม่ติดอยู่ใน local optima, ครอบคลุมพื้นที่ทั้งหมด
- จุดอ่อน: ไม่ใช้ผลลัพธ์ก่อนหน้า
- เมื่อไรใช้: เป็น baseline สำหรับการเปรียบเทียบ, หรือสำหรับการวิเคราะห์เชิงสำรวจ
QMCSampler
sampler = optuna.samplers.QMCSampler(seed=42)
- หลักการ: Quasi-Monte Carlo (ลำดับ Sobol/Halton) — เติมพื้นที่ได้สม่ำเสมอกว่า random sampler
- จุดแข็ง: ครอบคลุมพื้นที่ได้ดีกว่า RandomSampler, reproducibility
- จุดอ่อน: ไม่ปรับตัวตามผลลัพธ์
- เมื่อไรใช้: สำหรับรอบแรก 50-100 รอบก่อนสลับไปใช้ TPE
ตารางสรุป
| Sampler | ประเภท | ปฏิสัมพันธ์ | Categorical | งบประมาณที่ดีที่สุด |
|---|---|---|---|---|
| TPE | Bayesian | บางส่วน | ใช่ | 100-1000 |
| CmaEs | เชิงวิวัฒนาการ | ใช่ | ไม่ | 200-2000 |
| GP | Bayesian | ใช่ | จำกัด | 50-200 |
| Random | สุ่ม | ไม่ | ใช่ | ใดๆ (baseline) |
| QMC | Quasi-random | ไม่ | ไม่ | 50-500 |
Benchmark เชิงปฏิบัติ
import optuna
import time
def benchmark_sampler(sampler, n_trials=300):
"""Compare samplers on the same task."""
study = optuna.create_study(sampler=sampler, direction="minimize")
start = time.time()
study.optimize(objective, n_trials=n_trials, show_progress_bar=False)
elapsed = time.time() - start
return {
"best_value": -study.best_value,
"elapsed_sec": elapsed,
"best_trial": study.best_trial.number,
}
samplers = {
"TPE": optuna.samplers.TPESampler(seed=42),
"CmaEs": optuna.samplers.CmaEsSampler(seed=42),
"GP": optuna.samplers.GPSampler(seed=42),
"Random": optuna.samplers.RandomSampler(seed=42),
"QMC": optuna.samplers.QMCSampler(seed=42),
}
for name, sampler in samplers.items():
result = benchmark_sampler(sampler, n_trials=300)
print(f"{name:8s}: best PnL={result['best_value']:.2f}%, "
f"found at trial #{result['best_trial']}, "
f"time={result['elapsed_sec']:.1f}s")
ผลลัพธ์ทั่วไปสำหรับกลยุทธ์ที่มี 12 พารามิเตอร์:
| Sampler | PnL ที่ดีที่สุด | พบที่รอบ | Overhead ของ Sampler |
|---|---|---|---|
| TPE | ~51% | ~180 | ต่ำ |
| CmaEs | ~49% | ~250 | ปานกลาง |
| GP | ~48% | ~90 | สูงเมื่อ |
| Random | ~42% | ~270 | น้อยมาก |
| QMC | ~43% | ~200 | น้อยมาก |
TPE และ CmaEs ให้ผลลัพธ์ดีกว่า random search อย่างสม่ำเสมอ 15-20% ใน PnL สุดท้าย GP หาผลลัพธ์ที่ดีก่อนแต่ถึงเพดานการคำนวณเมื่อจำนวนรอบมาก
การปรับแต่งแบบหลายวัตถุประสงค์: PnL กับ MaxDD
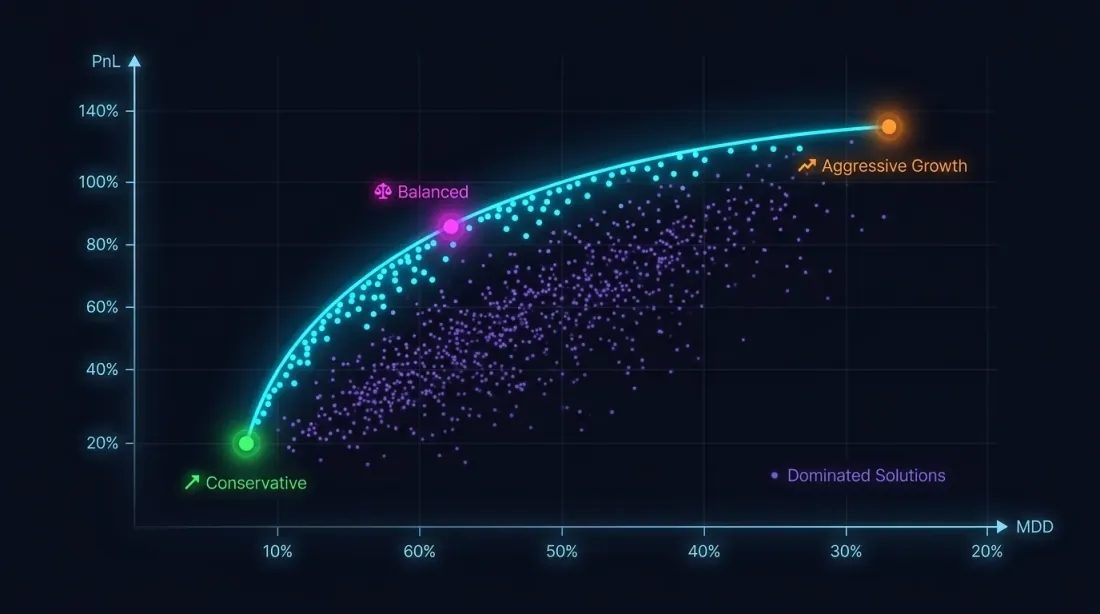
ทำไมเกณฑ์เดียวจึงไม่พอ
การ maximize PnL โดยไม่มีข้อจำกัด drawdown คือเส้นทางสู่หายนะ กลยุทธ์ที่มี PnL +80% และ MaxDD -30% นั้น เนื่องจาก ความไม่สมมาตรของการขาดทุน-กำไร มีความเสี่ยงสูงกว่ากลยุทธ์ที่มี PnL +50% และ MaxDD -5% อย่างมีนัยสำคัญ
ปัญหาการปรับแต่งจริงๆ แล้วเป็น แบบหลายวัตถุประสงค์:
เป้าหมายเหล่านี้ขัดแย้งกัน: พารามิเตอร์ที่ aggressive เพิ่มทั้ง PnL และ drawdown คำตอบไม่ใช่จุดเดียว แต่เป็น Pareto front: ชุดของคำตอบที่คุณไม่สามารถปรับปรุง metric หนึ่งได้โดยไม่ทำให้อีก metric แย่ลง
NSGA-II / NSGA-III ใน Optuna
import optuna
def multi_objective(trial: optuna.Trial) -> tuple[float, float]:
"""Multi-objective function: (PnL, MaxDD)."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
pnl = result["pnl"] # maximize
max_dd = result["max_dd"] # minimize (already a negative number)
return pnl, max_dd # Optuna: both directions are set in create_study
study = optuna.create_study(
directions=["maximize", "minimize"],
sampler=optuna.samplers.NSGAIIISampler(seed=42),
study_name="multi_objective_strategy",
)
study.optimize(multi_objective, n_trials=500)
pareto_trials = study.best_trials
print(f"Pareto front: {len(pareto_trials)} solutions")
for t in pareto_trials[:5]:
print(f" PnL={t.values[0]:.2f}%, MaxDD={t.values[1]:.2f}%")
การเลือกจุดบน Pareto Front
Pareto front ให้คำตอบหลายอัน จะเลือกอย่างไร?
def select_from_pareto(
pareto_trials: list,
max_dd_limit: float = -5.0,
min_pnl: float = 20.0,
) -> list:
"""
Filter the Pareto front by constraints.
max_dd_limit: maximum acceptable drawdown (e.g., -5%)
min_pnl: minimum acceptable PnL (%)
"""
filtered = []
for trial in pareto_trials:
pnl, max_dd = trial.values
if max_dd >= max_dd_limit and pnl >= min_pnl:
max_lev = min(50 / abs(max_dd), 100) if max_dd != 0 else 100
pnl_at_max_lev = pnl * max_lev
filtered.append({
"trial": trial,
"pnl": pnl,
"max_dd": max_dd,
"max_lev": max_lev,
"pnl_at_max_lev": pnl_at_max_lev,
})
filtered.sort(key=lambda x: x["pnl_at_max_lev"], reverse=True)
return filtered
หมายเหตุ: เมื่อคำนวณ PnL ที่ leverage สูงสุด ต้องคำนึงถึง funding rates ด้วย มิฉะนั้น leverage ที่สูงในทางทฤษฎีจะกลายเป็นการขาดทุนในตลาดจริง นอกจากนี้ PnL สุดท้ายเป็นการประมาณแบบ single-point และเพื่อประเมินความเสถียรของผลลัพธ์คุณต้องใช้ Monte Carlo bootstrap
ตัวอย่าง: สามกลยุทธ์บน Pareto Front
| กลยุทธ์ | PnL | MaxDD | MaxLev | PnL@MaxLev | เวลาซื้อขาย |
|---|---|---|---|---|---|
| กลยุทธ์ A | ~55% | ~0.9% | ~55x | ~3025% | ~15% |
| กลยุทธ์ B | ~25% | ~0.75% | ~66x | ~1650% | ~5% |
| กลยุทธ์ C | ~300% | ~17% | ~3x | ~900% | ~45% |
กลยุทธ์ C ที่มี PnL ที่น่าประทับใจ +300% กลายเป็นตัวที่น่าสนใจน้อยที่สุดตาม PnL@MaxLev เนื่องจาก drawdown สูง กลยุทธ์ A นำหน้าในผลตอบแทนที่ใช้ leverage สุทธิ แต่เมื่อคำนึงถึง PnL ต่อเวลาที่ใช้งานจริง กลยุทธ์ B อาจเป็นที่ต้องการมากกว่า — 95% ของเวลาว่างสามารถใช้กับกลยุทธ์อื่นได้
Contour Plots และความสำคัญของพารามิเตอร์

การ Visualize ภูมิทัศน์
หลังจากการปรับแต่ง — visualization Optuna มีเครื่องมือในตัว:
import optuna.visualization as vis
fig_contour = vis.plot_contour(
study,
params=["htf_entry_sell", "mtf_entry_sell"],
)
fig_contour.show()
fig_importance = vis.plot_param_importances(study)
fig_importance.show()
fig_history = vis.plot_optimization_history(study)
fig_history.show()
fig_parallel = vis.plot_parallel_coordinate(
study,
params=["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell"],
)
fig_parallel.show()
fig_slice = vis.plot_slice(study)
fig_slice.show()
Contour Plot: การอ่านปฏิสัมพันธ์
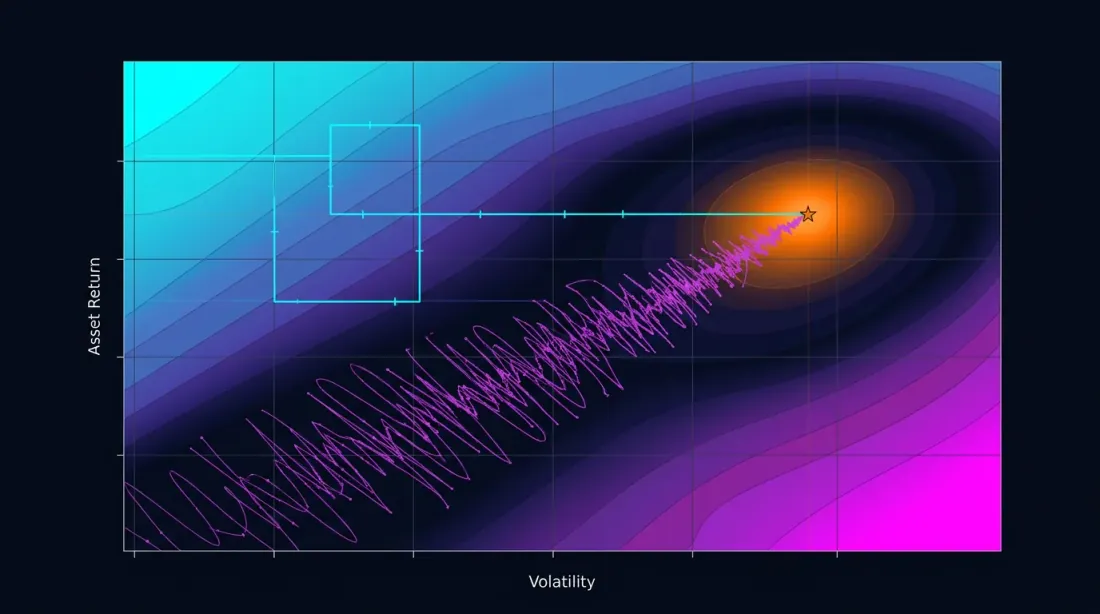
Contour plot สร้างภาพตัดขวางสองมิติของฟังก์ชันเป้าหมายสำหรับพารามิเตอร์คู่หนึ่ง ถ้า isoline ขนานกับหนึ่งในแกน — พารามิเตอร์ไม่มีปฏิสัมพันธ์กัน และ OAT จะหา optimum เดียวกันได้ ถ้า isoline เป็น แนวทแยง — มีปฏิสัมพันธ์ และ OAT จะพลาด
key_params = ["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell",
"htf_entry_buy", "mtf_entry_buy", "ltf_entry_buy"]
for i, p1 in enumerate(key_params):
for p2 in key_params[i+1:]:
fig = vis.plot_contour(study, params=[p1, p2])
fig.write_image(f"contour_{p1}_vs_{p2}.png")
ถ้า contour plot แสดง ที่ราบ — พื้นที่ที่ฟังก์ชันเป้าหมายเปลี่ยนแปลงน้อย — นี่คือสัญญาณที่ดี ที่ราบหมายความว่าผลลัพธ์มีความทนทานต่อการเบี่ยงเบนเล็กน้อยของพารามิเตอร์ ข้อมูลเพิ่มเติมเกี่ยวกับการวิเคราะห์ที่ราบและความสัมพันธ์กับ overfitting — ในบทความที่กำลังจะมา Plateau analysis
ความสำคัญของพารามิเตอร์
importance = optuna.importance.get_param_importances(study)
for param, imp in importance.items():
print(f"{param:20s}: {imp:.4f}")
ผลลัพธ์ทั่วไป:
htf_entry_sell : 0.2841
mtf_entry_sell : 0.2103
ltf_entry_sell : 0.1567
trail_pct : 0.1204
htf_entry_buy : 0.0892
...
พารามิเตอร์ที่มีความสำคัญ < 0.01 สามารถตรึงไว้ที่ค่าเริ่มต้น — สิ่งนี้ลด dimensionality ของปัญหาและเร่งการปรับแต่ง แต่ ระวัง: ความสำคัญต่ำอาจหมายความว่าพารามิเตอร์สำคัญเฉพาะในปฏิสัมพันธ์กับพารามิเตอร์อื่น ตรวจสอบผ่าน contour plot
Cache ที่คำนวณล่วงหน้า: ทำไม 1 วินาทีต่อ Backtest จึงเปลี่ยนแปลงทุกอย่าง
ความเร็วของ backtest แต่ละครั้งจะกำหนดว่าคุณสามารถใช้วิธีการปรับแต่งอะไรได้บ้าง
| เวลา Backtest | 96 OAT | 500 TPE | 2000 CmaEs |
|---|---|---|---|
| 60 วินาที | 1.6 ชั่วโมง | 8.3 ชั่วโมง | 33 ชั่วโมง |
| 10 วินาที | 16 นาที | 83 นาที | 5.5 ชั่วโมง |
| 1 วินาที | 1.5 นาที | 8 นาที | 33 นาที |
| 0.1 วินาที | 10 วินาที | 50 วินาที | 3.3 นาที |
ที่ 60 วินาทีต่อ backtest, 500 รอบ TPE ใช้เวลา 8 ชั่วโมง ยังพอรับได้ แต่การวนซ้ำ (เปลี่ยนฟังก์ชันเป้าหมาย, รีสตาร์ท) มีต้นทุนสูง ที่ 1 วินาที — 8 นาที และคุณสามารถรันการทดลองหลายสิบครั้งต่อวัน
นี่คือเหตุผลที่ การคำนวณล่วงหน้าไปยัง Parquet cache ไม่ใช่แค่การปรับความเร็ว แต่เป็น การขยายพื้นที่ของวิธีที่มีอยู่ หากไม่มี cache คุณถูกจำกัดอยู่กับ OAT หรือ 100 รอบ GP ด้วย cache — คุณสามารถ afford 2000 รอบ CmaEs หรือ multi-objective NSGA-III เต็มรูปแบบได้
import pyarrow.parquet as pq
import time
t0 = time.time()
htf_pre = pq.read_table("cache/htf_indicators.parquet").to_pandas()
mtf_pre = pq.read_table("cache/mtf_indicators.parquet").to_pandas()
ltf_pre = pq.read_table("cache/ltf_indicators.parquet").to_pandas()
print(f"Cache loaded in {time.time() - t0:.2f}s") # ~0.3s
t1 = time.time()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, htf_entry_sell=0.02, ...)
print(f"Backtest in {time.time() - t1:.2f}s") # ~1.0s
คำแนะนำเชิงปฏิบัติ
เมื่อไรควรใช้ OAT
OAT มีเหตุผลในกรณีต่อไปนี้:
-
การวิเคราะห์เชิงสำรวจ คุณเพิ่งเริ่มสำรวจกลยุทธ์และต้องการเข้าใจว่าพารามิเตอร์ใดส่งผลต่อผลลัพธ์ 96 รอบใน 1.5 นาที — จุดเริ่มต้นที่ยอดเยี่ยม
-
พารามิเตอร์แบบบวก สำหรับพารามิเตอร์ที่ดำเนินการบนชุดย่อยของการซื้อขายที่ไม่ทับซ้อนกัน (ทิศทาง sell กับ buy, เครื่องมือต่างกัน) OAT จะให้ผลลัพธ์ที่ถูกต้องได้เร็วกว่า
-
Backtest ที่มีต้นทุนสูงมาก ถ้ารอบเดียวใช้เวลา 10+ นาทีและไม่สามารถเร่งได้ OAT ที่ 96 รอบ (16 ชั่วโมง) ดีกว่า 500 รอบ TPE (3.5 วัน)
เมื่อไรควรใช้ Optuna
Optuna เป็นที่ต้องการในกรณีส่วนใหญ่:
-
มากกว่า 3 พารามิเตอร์ ปฏิสัมพันธ์มีอยู่จริงในทางปฏิบัติ — OAT จะพลาด optimum
-
กลยุทธ์หลาย timeframe Threshold ข้ามหลาย timeframe เชื่อมโยงกันเกือบเสมอ
-
การปรับแต่งขั้นสุดท้าย เมื่อกลยุทธ์ผ่าน Monte Carlo bootstrap และคุณมั่นใจในความเสถียรของมัน — Optuna จะหาพารามิเตอร์ที่ดีที่สุด
-
ปัญหาแบบหลายวัตถุประสงค์ PnL กับ MaxDD กับเวลาซื้อขาย — OAT ไม่สามารถแก้ปัญหานี้ได้โดยหลักการ
แนวทาง Hybrid: OAT สำหรับแบบบวก + Optuna สำหรับแบบมีความเชื่อมโยง
คุณไม่ต้องเลือกระหว่าง OAT และ Optuna — ดีกว่าที่จะรวมกัน:
-
จำแนกพารามิเตอร์ แบ่งเป็นแบบบวก (อิสระ) และแบบมีความเชื่อมโยง (interactive) ตัวอย่างสำหรับพารามิเตอร์การแยก 12 ตัว:
- แบบบวก:
htf_entry_sell<->htf_entry_buy,mtf_entry_sell<->mtf_entry_buy,ltf_entry_sell<->ltf_entry_buy(sell/buy — ทิศทางต่างกัน, ดำเนินการบนการซื้อขายที่ไม่ทับซ้อนกัน) - กลุ่มที่มีความเชื่อมโยง sell:
htf_entry_sell,mtf_entry_sell,ltf_entry_sell(ห่วงโซ่การกรอง: HTF -> MTF -> LTF สำหรับสัญญาณ sell) - กลุ่มที่มีความเชื่อมโยง buy:
htf_entry_buy,mtf_entry_buy,ltf_entry_buy
- แบบบวก:
-
OAT สำหรับแบบบวก ปรับแต่งกลุ่ม sell และ buy อย่างอิสระ ถ้าพารามิเตอร์ sell ไม่ส่งผลต่อการซื้อขาย buy — OAT จะให้ผลลัพธ์ที่ถูกต้องในไม่กี่นาที
-
Optuna สำหรับแบบมีความเชื่อมโยง ภายในแต่ละกลุ่ม (sell: 6 พารามิเตอร์ entry+exit) ใช้ TPE 6 พารามิเตอร์แทน 12 — งบประมาณลดลงครึ่งหนึ่ง
sell_params = oat_sweep(sell_param_grid, run_backtest, initial_params)
def objective_sell(trial):
params = sell_params.copy()
params["htf_entry_sell"] = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
params["mtf_entry_sell"] = trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005)
params["ltf_entry_sell"] = trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005)
params["htf_exit_sell"] = trial.suggest_float("htf_exit_sell", 0.0, 0.02, step=0.001)
params["mtf_exit_sell"] = trial.suggest_float("mtf_exit_sell", 0.0, 0.02, step=0.001)
params["ltf_exit_sell"] = trial.suggest_float("ltf_exit_sell", 0.0, 0.02, step=0.001)
return -run_backtest(**params)["effective_score"]
study = optuna.create_study(sampler=optuna.samplers.TPESampler())
study.optimize(objective_sell, n_trials=300) # 6 parameters → 300 is enough
Pipeline การปรับแต่งเต็มรูปแบบ
1. Precompute Parquet cache (once)
2. Classify parameters: additive vs coupled
3. OAT for additive (~50 runs, ~1 min) → fix
4. Optuna TPE for coupled groups (300 iterations x 2 groups, ~10 min)
5. Optuna NSGA-III for meta-parameters (500 iterations, ~8 min) → Pareto front
6. Contour plots → visualize interactions
7. Monte Carlo bootstrap of best points → confidence intervals
8. Walk-Forward → out-of-sample validation
ขั้นตอนที่ 8 — walk-forward optimization — มีความสำคัญอย่างยิ่งสำหรับการป้องกัน overfitting ข้อมูลเพิ่มเติมเกี่ยวกับเรื่องนี้ในบทความที่กำลังจะมา Walk-Forward
กับดักในการปรับแต่ง
Overfitting ยิ่งมีพารามิเตอร์มากและการปรับแต่งแม่นยำมากเท่าใด ความเสี่ยงของการ fit กลยุทธ์กับข้อมูลประวัติศาสตร์ก็สูงขึ้นเท่านั้น 500 รอบ Optuna ที่มี 12 พารามิเตอร์จะหาชุดค่าผสมที่ทำงานได้ดีอย่างสมบูรณ์บน training set แต่ไม่มีประโยชน์กับข้อมูลใหม่
การป้องกัน:
- แบ่งข้อมูลเป็น train/test (70/30)
- ใช้ Monte Carlo bootstrap เพื่อประเมินความเสถียร
- ตรวจสอบผ่าน walk-forward
- ต้องการคำตอบบนที่ราบ (ข้อมูลเพิ่มเติมใน Plateau analysis)
ปัญหาการเปรียบเทียบหลายรายการ ถ้าคุณทดสอบ 500 ชุดค่าผสม ความน่าจะเป็นของการพบผลลัพธ์ "ดี" แบบสุ่มเพิ่มขึ้น การแก้ไข Bonferroni หรือการควบคุม FDR (False Discovery Rate) ช่วยได้ แต่แนวทางที่ง่ายกว่าคือการตรวจสอบ out-of-sample
งบประมาณไม่เพียงพอ TPE ที่ 50 รอบสำหรับ 12 พารามิเตอร์น้อยเกินไป 20 รอบแรกเป็นแบบสุ่ม (startup) เหลือเพียง 30 รอบสำหรับการ modeling งบประมาณขั้นต่ำ: รอบสำหรับ 12 พารามิเตอร์, แนะนำ:
Freqtrade: วิธีการทำงานใน Production Framework

Freqtrade — หนึ่งใน framework algotrading ยอดนิยม — ใช้ Optuna ภายในผ่านโมดูล Hyperopt ประสบการณ์ของมันยืนยันคำแนะนำของเรา:
- Sampler: TPE (ค่าเริ่มต้น), GP, CmaEs, NSGA-II, QMC — ทั้งหมดพร้อมใช้งานผ่าน configuration
- Loss functions: 12 loss function ในตัว รวมถึง ShortTradeDurHyperOptLoss, SharpeHyperOptLoss, MaxDrawDownHyperOptLoss
- Multi-objective: รองรับ NSGA-II และ NSGA-III สำหรับการปรับแต่งหลาย metric พร้อมกัน
- Custom samplers: ความสามารถในการเสียบ Optuna-compatible sampler ใดก็ได้
บทเรียนสำคัญจาก ecosystem ของ Freqtrade: loss function ในตัวครอบคลุมสถานการณ์ทั่วไป แต่สำหรับการปรับแต่งอย่างจริงจังคุณต้องการ objective function แบบ custom ที่คำนึงถึงลักษณะเฉพาะของกลยุทธ์ของคุณ — เวลาที่ใช้งานจริง, ต้นทุน funding, adaptive drill-down สำหรับ การจำลองการ fill ที่แม่นยำ
บทสรุป

Coordinate descent (OAT) เป็นวิธีที่เร็วและใช้งานง่าย สำหรับ 12 พารามิเตอร์ต้องการเพียง 96 รอบและเสร็จในหนึ่งนาทีครึ่ง แต่มันตาบอดต่อปฏิสัมพันธ์ระหว่างพารามิเตอร์ — และในกลยุทธ์หลาย timeframe ปฏิสัมพันธ์เกือบจะมีอยู่เสมอ
Bayesian optimization ผ่าน Optuna (TPE, GP, CmaEs) สำรวจพื้นที่พารามิเตอร์โดยรวม 500 รอบใน 8 นาที — ด้วย Parquet cache ที่คำนวณล่วงหน้า — หาชุดค่าผสมที่ OAT มองไม่เห็น
Multi-objective optimization (NSGA-III) เปลี่ยนปัญหา "maximize PnL" เป็นปัญหา "build Pareto front ของ PnL กับ MaxDD" — และให้ชุดของคำตอบที่มีการแลกเปลี่ยนระหว่างความเสี่ยงและผลตอบแทนที่แตกต่างกัน
แต่การปรับแต่งเป็นเพียงส่วนหนึ่งของ pipeline พารามิเตอร์ที่พบจำเป็นต้องได้รับการตรวจสอบผ่าน Monte Carlo bootstrap, ปรับแก้สำหรับ funding rates, คำนวณใหม่โดยคำนึงถึง เวลาที่ใช้งานจริง, และผ่าน walk-forward validation ข้อมูลเพิ่มเติมจะอยู่ในบทความต่อๆ ไปของซีรีส์
ลิงก์ที่มีประโยชน์
- Optuna: A Next-generation Hyperparameter Optimization Framework (Akiba et al., 2019)
- Algorithms for Hyper-Parameter Optimization (Bergstra et al., 2011) — บทความ TPE ต้นฉบับ
- Optuna Documentation — Samplers
- Optuna Visualization Module
- Hansen, N. — The CMA Evolution Strategy: A Tutorial
- Deb, K. et al. — NSGA-II: A Fast and Elitist Multiobjective Genetic Algorithm (2002)
- Snoek, J. et al. — Practical Bayesian Optimization of Machine Learning Algorithms (2012)
- Freqtrade Documentation — Hyperopt
- Marcos Lopez de Prado — Advances in Financial Machine Learning, Chapter 12
- Bergstra, J. & Bengio, Y. — Random Search for Hyper-Parameter Optimization (2012)
การอ้างอิง
@article{soloviov2026optuna,
author = {Soloviov, Eugen},
title = {Coordinate Descent vs Bayesian Optimization: Which Finds Better Parameters},
year = {2026},
url = {https://marketmaker.cc/th/blog/post/optuna-vs-coordinate-descent},
description = {ทำไมการค้นหาแบบครอบคลุมจึงเป็นไปไม่ได้สำหรับพารามิเตอร์ 12+ ตัว, coordinate descent พลาดปฏิสัมพันธ์ระหว่างพารามิเตอร์อย่างไร, และ Optuna พร้อม TPE sampler หาได้ใน 500 รอบสิ่งที่ OAT ไม่สามารถหาได้ใน 96 รอบ}
}
ผู้เขียน

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
อ่านเพิ่มเติม

Adaptive Drill-Down: แบ็คเทสต์ด้วยความละเอียดข้อมูลแบบยืดหยุ่น ตั้งแต่นาทีจนถึงการเทรดดิบ

Aggregated Parquet Cache: วิธีเร่งความเร็วแบ็คเทสต์หลาย Timeframe ได้หลายร้อยเท่า
