Coordinate Descent vs Tối ưu hóa Bayesian: Phương pháp nào tìm tham số tốt hơn
Đây là bài viết thứ năm trong chuỗi "Backtest Không Ảo Tưởng". Trong các bài trước, chúng ta đã đề cập đến bất đối xứng lỗ-lãi, bootstrap Monte Carlo, tác động của funding rate và Parquet cache để tăng tốc backtest. Bây giờ hãy nói về quá trình tìm kiếm tham số tối ưu cho chiến lược — một nhiệm vụ mà trực giác thường thất bại nhất.
Bạn có một chiến lược với 12 tham số. Mỗi tham số nhận ~9 giá trị. Bạn muốn tìm tổ hợp tối đa hóa PnL với drawdown giới hạn. Làm thế nào?
Nếu câu trả lời của bạn là "Tôi duyệt qua tất cả các tổ hợp" — bạn đang gặp vấn đề. Nếu câu trả lời của bạn là "Tôi thay đổi từng tham số một" — bạn đang gặp vấn đề khác. Bài viết này nói về những vấn đề ẩn sau mỗi cách tiếp cận và cách giải quyết chúng.
Tại Sao Tìm Kiếm Toàn Bộ Không Thể Thực Hiện

Lời Nguyền Chiều Không Gian
Tìm kiếm toàn bộ (grid search) kiểm tra mọi tổ hợp giá trị cho mọi tham số. Với hai tham số có 9 giá trị, đó là lần chạy — hoàn toàn khả thi. Với ba tham số: — chấp nhận được.
Nhưng với một chiến lược thực tế có 12 tham số:
Hai trăm tám mươi hai tỷ lần chạy. Ngay cả khi một backtest mất 1 giây (điều này đã rất lạc quan), tìm kiếm toàn bộ sẽ mất:
Đây là tăng trưởng hàm mũ: mỗi tham số mới nhân không gian tìm kiếm lên 9. Thêm tham số thứ 13 — và thay vì 9.000 năm bạn cần 80.000.
import math
def grid_search_cost(n_params: int, values_per_param: int, seconds_per_trial: float) -> dict:
"""Estimate the cost of exhaustive search."""
total_trials = values_per_param ** n_params
total_seconds = total_trials * seconds_per_trial
return {
"total_trials": total_trials,
"total_hours": total_seconds / 3600,
"total_years": total_seconds / (3600 * 24 * 365),
}
cost = grid_search_cost(12, 9, 1.0)
print(f"Trials: {cost['total_trials']:,.0f}") # 282,429,536,481
print(f"Years: {cost['total_years']:,.0f}") # 8,950
Kể Cả Khi Có Tính Toán Trước
Trong bài viết về Parquet cache, chúng ta đã chỉ ra cách tính toán trước các khung thời gian và chỉ báo giúp tăng tốc một backtest đơn lẻ lên ~1 giây. Nhưng ngay cả ở mức 0,1 giây mỗi lần chạy, tìm kiếm toàn bộ với 12 tham số sẽ cần 895 năm. Tính toán trước giúp ích, nhưng không giải quyết vấn đề cơ bản của tăng trưởng hàm mũ.
Chúng ta cần các phương pháp khám phá không gian tham số thông minh hơn so với tìm kiếm toàn bộ.
Coordinate Descent và OAT: Nhanh nhưng Mù Quáng
Hai Biến Thể của Cùng Một Ý Tưởng
Có hai cách tiếp cận liên quan — cả hai đều tối ưu hóa từng tham số một, nhưng khác nhau về số lần duyệt:
OAT (One-at-a-Time) sweep — một lần duyệt qua tất cả các tham số. Lặp qua các giá trị của tham số đầu tiên, cố định giá trị tốt nhất, chuyển sang tham số thứ hai — và cứ thế. Một lần duy nhất. Nhanh và ít tốn kém.
Coordinate Descent — nhiều lần duyệt. Sau khi tối ưu hóa tham số cuối cùng, quay lại tham số đầu tiên và kiểm tra xem điểm tối ưu có thay đổi không (vì ngữ cảnh đã thay đổi — các giá trị tham số khác bây giờ khác). Lặp lại các vòng cho đến khi hội tụ. Tốn kém hơn, nhưng chính xác hơn — mỗi vòng có thể tinh chỉnh nghiệm.
Trong thực tế, với backtest OAT được dùng thường xuyên hơn: một lần duyệt qua 12 tham số — 96 lần chạy. Coordinate descent với 3-5 vòng — 300-500 lần chạy, đã tương đương với Optuna, nhưng không có ưu điểm của nó.
Với 12 tham số có ~8 giá trị mỗi tham số:
So sánh với của grid search. OAT là tuyến tính: thay vì . Đây vừa là ưu điểm chính vừa là vấn đề chính của nó.
def oat_sweep(
param_grid: dict[str, list],
run_backtest_fn,
initial_params: dict,
metric: str = "effective_score",
) -> dict:
"""
OAT sweep: single pass, optimizing one parameter at a time.
param_grid: {"htf_entry_sell": [0.0, 0.005, ..., 0.05], ...}
initial_params: starting values for all parameters
metric: metric to optimize (effective_score recommended —
PnL per active time extrapolated to a year)
"""
best_params = initial_params.copy()
best_score = run_backtest_fn(**best_params)[metric]
for param_name, values in param_grid.items():
param_best_val = best_params[param_name]
param_best_score = best_score
for val in values:
candidate = best_params.copy()
candidate[param_name] = val
result = run_backtest_fn(**candidate)
score = result[metric]
if score > param_best_score:
param_best_score = score
param_best_val = val
best_params[param_name] = param_best_val
best_score = param_best_score
print(f"{param_name}: best={param_best_val}, score={param_best_score:.4f}")
return best_params
Chọn chỉ số nào để tối ưu hóa? Thay vì PnL thô hoặc PnL@MaxLev, nên dùng effective score — PnL trên thời gian hoạt động ngoại suy theo năm. Chỉ số này tính đến thời gian trong vị thế và cho phép so sánh chính xác các chiến lược với tần suất giao dịch khác nhau.
Điểm Mù: Tương Tác Tham Số
OAT giả định rằng hiệu ứng của mỗi tham số là cộng tính — tức là giá trị tối ưu của một tham số không phụ thuộc vào giá trị của các tham số khác. Giả định này đúng với một số tham số, nhưng bị phá vỡ với các tham số có liên kết.
Tham Số Cộng Tính vs Tham Số Có Liên Kết
Trước khi tối ưu hóa — nên phân loại các tham số:
Cộng tính (độc lập) — giá trị tối ưu của cái này không phụ thuộc vào cái kia. Có thể tối ưu hóa từng cái một cách rẻ:
htf_entry_sellvàhtf_entry_buy— ngưỡng vào lệnh cho các hướng khác nhau (bán/mua) trên cùng một khung thời gian. Ngưỡng bán lọc tín hiệu short, ngưỡng mua — long. Chúng hoạt động trên các tập giao dịch không chồng lấp.tp_targetvàbe_trigger— take-profit và breakeven, nếu chúng không tạo điều kiện thoát lệnh mâu thuẫn.
Có liên kết (tương tác) — giá trị tối ưu của cái này phụ thuộc vào cái kia. Cần tối ưu hóa chung:
htf_entry_sellvàmtf_entry_sell— ngưỡng cho cùng hướng (bán) trên các khung thời gian khác nhau. HTF xác định tín hiệu nào đến được MTF, và ngưỡng MTF xác định hiệu quả lọc. Điểm tối ưu HTF thay đổi khi MTF thay đổi.ltf_entry_sell,mtf_entry_sell,htf_entry_sell— toàn bộ chuỗi ngưỡng cho một hướng.partial_fracvàtp_target— kích thước đóng một phần phụ thuộc vào mức TP.
Cách tiếp cận thực tế: trước tiên tối ưu hóa rẻ các tham số cộng tính qua OAT. Sau đó tối ưu hóa các nhóm có liên kết qua Optuna. Điều này giảm ngân sách: thay vì 12 tham số trong Optuna, chúng ta chỉ gửi 6-8 tham số có liên kết, trong khi phần còn lại đã được cố định.
Ví Dụ: OAT Bỏ Lỡ Tương Tác Như Thế Nào
Xét hai ngưỡng có liên kết:
htf_entry_sell— ngưỡng trên khung thời gian cao hơn (hướng bán)mtf_entry_sell— ngưỡng trên khung thời gian trung bình (hướng bán)
OAT cố định mtf_entry_sell = 0.01 (giá trị ban đầu) và lặp qua htf_entry_sell. Tìm giá trị tốt nhất: htf_entry_sell = 0.02. Cố định nó và chuyển sang tham số tiếp theo — không bao giờ quay lại.
Đây là những gì OAT đã bỏ lỡ:
htf_entry_sell |
mtf_entry_sell |
PnL |
|---|---|---|
| 0.02 | 0.01 | +42% |
| 0.02 | 0.02 | +38% |
| 0.03 | 0.02 | +51% |
| 0.03 | 0.01 | +35% |
Tổ hợp (0.03, 0.02) cho PnL +51%, nhưng OAT sẽ không bao giờ xét đến nó vì với mtf_entry_sell = 0.01 cố định, giá trị htf_entry_sell = 0.03 chỉ cho +35%. OAT bị "mắc kẹt" ở cực trị cục bộ (0.02, 0.01) và không thể nhìn thấy cực trị toàn cục (0.03, 0.02).
Đây là vấn đề cổ điển: nếu bề mặt hàm mục tiêu chứa các đỉnh chéo (khi điểm tối ưu của một tham số dịch chuyển khi tham số khác thay đổi), OAT sẽ bỏ lỡ chúng.
Hình Thức Hóa Vấn Đề
Cho là hàm mục tiêu (PnL). OAT tìm điểm mà:
Nhưng đây là điều kiện cần, không phải đủ cho cực trị toàn cục. Nếu ma trận Hessian có các phần tử ngoài đường chéo đáng kể — OAT không tính đến các đạo hàm chéo khi .
Với các tham số có liên kết (ngưỡng cùng hướng trên nhiều khung thời gian) — tương tác là quy tắc, không phải ngoại lệ. Ngưỡng vào lệnh trên khung thời gian cao hơn xác định tín hiệu nào đến được khung trung bình, và ngưỡng trên khung trung bình xác định hiệu quả lọc trên khung thấp hơn. Với các tham số cộng tính (hướng khác nhau, bộ lọc độc lập), các đạo hàm chéo gần bằng không — và OAT hoạt động tốt.
Tối Ưu Hóa Bayesian: Tìm Kiếm Thông Minh

Ý Tưởng
Thay vì liệt kê mù quáng hoặc tìm kiếm tham lam, tối ưu hóa Bayesian xây dựng mô hình thay thế của hàm mục tiêu và ở mỗi bước chọn điểm mà cải tiến kỳ vọng là tối đa.
Thuật toán:
- Chọn một số điểm ngẫu nhiên, đánh giá hàm mục tiêu
- Xây dựng mô hình thay thế (xấp xỉ từ các điểm đã quan sát)
- Tìm điểm với cải tiến kỳ vọng tối đa (hàm thu thập)
- Đánh giá hàm mục tiêu tại điểm đó
- Cập nhật mô hình thay thế
- Lặp lại bước 3-5
Sự khác biệt chính với OAT: tối ưu hóa Bayesian xét tất cả các tham số đồng thời và có thể khám phá các đỉnh chéo trong không gian tham số.
TPE (Tree-structured Parzen Estimator)

TPE là sampler mặc định trong Optuna. Thay vì mô hình hóa trực tiếp, TPE mô hình hóa hai phân phối:
- — phân phối các tham số mà hàm mục tiêu tốt hơn ngưỡng
- — phân phối các tham số mà hàm mục tiêu tệ hơn ngưỡng
Hàm thu thập của TPE — tỷ lệ:
TPE chọn các điểm mà lớn (tham số tương tự "tốt") và nhỏ (tham số không tương tự "xấu").
Tại sao TPE phù hợp với backtest:
- Xử lý được các phụ thuộc có điều kiện giữa các tham số
- Không yêu cầu tính liên tục của hàm mục tiêu
- Hiệu quả với ngân sách vừa phải (100-1000 vòng lặp)
- Hỗ trợ tham số phân loại và rời rạc
Gaussian Process (GP)
Một lựa chọn thay thế cho TPE — Gaussian Process. GP mô hình hóa như một quá trình chuẩn đa biến và cung cấp không chỉ dự báo giá trị, mà còn độ không chắc chắn tại mỗi điểm.
trong đó là trung bình, là hàm hiệp phương sai (kernel).
GP hoạt động tốt khi:
- Số tham số ít (đến 10-15)
- Hàm mục tiêu trơn
- Mỗi lần chạy tốn kém (phút, giờ)
Với backtest sử dụng Parquet cache đã tính toán trước, mà một lần chạy mất ~1 giây, TPE thường được ưa chuộng hơn: nó xây dựng mô hình nhanh hơn và mở rộng tốt hơn lên 500+ vòng lặp.
Tích Hợp Thực Tế với Optuna
Ví Dụ Đầy Đủ Hoạt Động
import optuna
from optuna.samplers import TPESampler
import numpy as np
def run_backtest(htf_pre, mtf_pre, ltf_pre, **params) -> dict:
"""
Runs a backtest with given parameters.
Returns a dict with metrics: pnl, max_dd, n_trades, trading_time, sharpe.
Uses precomputed Parquet cache — ~1 second per run.
"""
pass
def objective(trial: optuna.Trial) -> float:
"""Objective function for Optuna."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
study = optuna.create_study(
sampler=TPESampler(seed=42),
study_name="strategy_optimization",
direction="minimize",
)
study.optimize(objective, n_trials=500, show_progress_bar=True)
print(f"Best PnL: {-study.best_value:.2f}%")
print(f"Best params: {study.best_params}")
print(f"Total trials: {len(study.trials)}")
Với ~1 giây mỗi backtest (với cache đã tính toán trước):
Tám phút so với 8.950 năm của tìm kiếm toàn bộ. Và TPE trong 500 vòng lặp tìm được các tổ hợp mà OAT bỏ lỡ trong 96, vì nó khám phá không gian tham số đồng thời thay vì từng trục một.
Lưu và Tiếp Tục Nghiên Cứu
import optuna
study = optuna.create_study(
storage="sqlite:///optuna_study.db",
study_name="strategy_v2",
sampler=TPESampler(seed=42),
direction="minimize",
load_if_exists=True, # continue if study already exists
)
study.optimize(objective, n_trials=300)
study.optimize(objective, n_trials=200)
Thêm Ràng Buộc
Không phải mọi tổ hợp tham số đều hợp lệ. Ví dụ, ngưỡng thoát lệnh không được vượt quá ngưỡng vào lệnh:
def objective_with_constraints(trial: optuna.Trial) -> float:
htf_entry = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
htf_exit = trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005)
if htf_exit > htf_entry:
raise optuna.TrialPruned()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
So Sánh Sampler
Optuna hỗ trợ nhiều sampler. Mỗi cái có ưu điểm riêng.
TPESampler (mặc định)
sampler = optuna.samplers.TPESampler(
n_startup_trials=20, # random trials before modeling begins
seed=42,
)
- Nguyên lý: Tree-structured Parzen Estimator
- Ưu điểm: tốt cho các loại tham số hỗn hợp, mở rộng đến 1000+ vòng lặp
- Nhược điểm: có thể kém hiệu quả hơn với tương tác tham số mạnh
- Khi dùng: theo mặc định, nếu không có lý do để chọn cái khác
CmaEsSampler
sampler = optuna.samplers.CmaEsSampler(seed=42)
- Nguyên lý: Covariance Matrix Adaptation Evolution Strategy — thuật toán tiến hóa thích nghi ma trận hiệp phương sai
- Ưu điểm: xuất sắc trong tìm kiếm tương tác giữa các tham số liên tục, tính đến tương quan
- Nhược điểm: không hỗ trợ tham số phân loại, cần nhiều vòng lặp hơn để khởi tạo
- Khi dùng: nếu tất cả tham số là liên tục và bạn nghi ngờ có tương tác mạnh
GPSampler
sampler = optuna.samplers.GPSampler(seed=42)
- Nguyên lý: Gaussian Process với hàm thu thập
- Ưu điểm: hiệu quả mẫu tốt nhất (ít vòng lặp hơn cho kết quả tốt), cung cấp ước tính độ không chắc chắn
- Nhược điểm: theo số vòng lặp — chậm khi
- Khi dùng: nếu một backtest tốn kém (phút) và ngân sách giới hạn ở 100-200 vòng lặp
RandomSampler (baseline)
sampler = optuna.samplers.RandomSampler(seed=42)
- Nguyên lý: lấy mẫu ngẫu nhiên đồng đều
- Ưu điểm: không bị mắc kẹt ở cực trị cục bộ, bao phủ toàn bộ không gian
- Nhược điểm: không sử dụng kết quả trước đó
- Khi dùng: làm baseline để so sánh, hoặc cho phân tích khám phá
QMCSampler
sampler = optuna.samplers.QMCSampler(seed=42)
- Nguyên lý: Quasi-Monte Carlo (dãy Sobol/Halton) — lấp đầy không gian đồng đều hơn so với sampler ngẫu nhiên
- Ưu điểm: bao phủ không gian tốt hơn RandomSampler, khả năng tái tạo
- Nhược điểm: không thích nghi với kết quả
- Khi dùng: cho 50-100 vòng lặp đầu tiên trước khi chuyển sang TPE
Bảng Tóm Tắt
| Sampler | Loại | Tương tác | Phân loại | Ngân sách tốt nhất |
|---|---|---|---|---|
| TPE | Bayesian | Một phần | Có | 100-1000 |
| CmaEs | Tiến hóa | Có | Không | 200-2000 |
| GP | Bayesian | Có | Giới hạn | 50-200 |
| Random | Ngẫu nhiên | Không | Có | Bất kỳ (baseline) |
| QMC | Bán ngẫu nhiên | Không | Không | 50-500 |
Benchmark Thực Tế
import optuna
import time
def benchmark_sampler(sampler, n_trials=300):
"""Compare samplers on the same task."""
study = optuna.create_study(sampler=sampler, direction="minimize")
start = time.time()
study.optimize(objective, n_trials=n_trials, show_progress_bar=False)
elapsed = time.time() - start
return {
"best_value": -study.best_value,
"elapsed_sec": elapsed,
"best_trial": study.best_trial.number,
}
samplers = {
"TPE": optuna.samplers.TPESampler(seed=42),
"CmaEs": optuna.samplers.CmaEsSampler(seed=42),
"GP": optuna.samplers.GPSampler(seed=42),
"Random": optuna.samplers.RandomSampler(seed=42),
"QMC": optuna.samplers.QMCSampler(seed=42),
}
for name, sampler in samplers.items():
result = benchmark_sampler(sampler, n_trials=300)
print(f"{name:8s}: best PnL={result['best_value']:.2f}%, "
f"found at trial #{result['best_trial']}, "
f"time={result['elapsed_sec']:.1f}s")
Kết quả điển hình cho chiến lược với 12 tham số:
| Sampler | PnL tốt nhất | Tìm thấy ở vòng lặp | Chi phí sampler |
|---|---|---|---|
| TPE | ~51% | ~180 | Thấp |
| CmaEs | ~49% | ~250 | Trung bình |
| GP | ~48% | ~90 | Cao khi |
| Random | ~42% | ~270 | Tối thiểu |
| QMC | ~43% | ~200 | Tối thiểu |
TPE và CmaEs liên tục vượt trội so với tìm kiếm ngẫu nhiên 15-20% trong PnL cuối. GP tìm kết quả tốt sớm hơn nhưng đạt giới hạn tính toán với số lượng lớn vòng lặp.
Tối Ưu Hóa Đa Mục Tiêu: PnL vs MaxDD
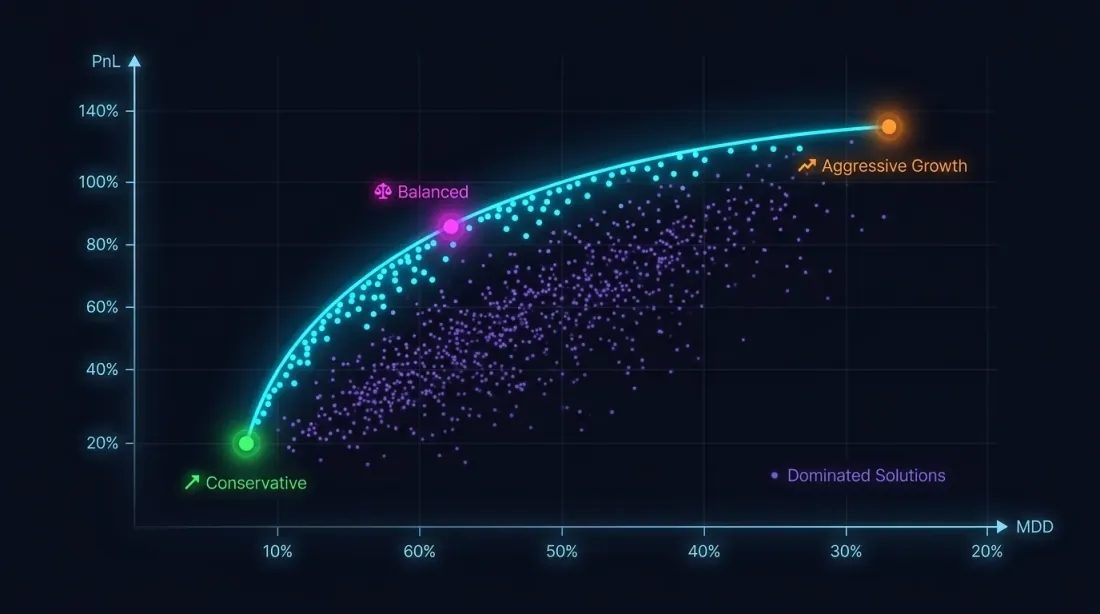
Tại Sao Một Tiêu Chí Không Đủ
Tối đa hóa PnL mà không có ràng buộc drawdown là con đường dẫn đến thảm họa. Chiến lược với PnL +80% và MaxDD -30% do bất đối xứng lỗ-lãi có rủi ro đáng kể cao hơn chiến lược với PnL +50% và MaxDD -5%.
Bài toán tối ưu hóa thực sự là đa mục tiêu:
Các mục tiêu này mâu thuẫn: tham số hung hăng tăng cả PnL lẫn drawdown. Giải pháp không phải là một điểm đơn, mà là mặt trận Pareto: tập các nghiệm mà bạn không thể cải thiện một chỉ số mà không làm xấu cái khác.
NSGA-II / NSGA-III trong Optuna
import optuna
def multi_objective(trial: optuna.Trial) -> tuple[float, float]:
"""Multi-objective function: (PnL, MaxDD)."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
pnl = result["pnl"] # maximize
max_dd = result["max_dd"] # minimize (already a negative number)
return pnl, max_dd # Optuna: both directions are set in create_study
study = optuna.create_study(
directions=["maximize", "minimize"],
sampler=optuna.samplers.NSGAIIISampler(seed=42),
study_name="multi_objective_strategy",
)
study.optimize(multi_objective, n_trials=500)
pareto_trials = study.best_trials
print(f"Pareto front: {len(pareto_trials)} solutions")
for t in pareto_trials[:5]:
print(f" PnL={t.values[0]:.2f}%, MaxDD={t.values[1]:.2f}%")
Chọn Điểm Trên Mặt Trận Pareto
Mặt trận Pareto cung cấp nhiều nghiệm. Làm thế nào để chọn một?
def select_from_pareto(
pareto_trials: list,
max_dd_limit: float = -5.0,
min_pnl: float = 20.0,
) -> list:
"""
Filter the Pareto front by constraints.
max_dd_limit: maximum acceptable drawdown (e.g., -5%)
min_pnl: minimum acceptable PnL (%)
"""
filtered = []
for trial in pareto_trials:
pnl, max_dd = trial.values
if max_dd >= max_dd_limit and pnl >= min_pnl:
max_lev = min(50 / abs(max_dd), 100) if max_dd != 0 else 100
pnl_at_max_lev = pnl * max_lev
filtered.append({
"trial": trial,
"pnl": pnl,
"max_dd": max_dd,
"max_lev": max_lev,
"pnl_at_max_lev": pnl_at_max_lev,
})
filtered.sort(key=lambda x: x["pnl_at_max_lev"], reverse=True)
return filtered
Lưu ý: khi tính PnL ở đòn bẩy tối đa, bạn phải tính đến funding rate, nếu không đòn bẩy cao về lý thuyết sẽ biến thành thua lỗ trên thị trường thực. Ngoài ra, PnL cuối cùng là ước tính một điểm, và để đánh giá tính ổn định của kết quả bạn cần bootstrap Monte Carlo.
Ví Dụ: Ba Chiến Lược Trên Mặt Trận Pareto
| Chiến lược | PnL | MaxDD | MaxLev | PnL@MaxLev | Thời gian giao dịch |
|---|---|---|---|---|---|
| Chiến lược A | ~55% | ~0.9% | ~55x | ~3025% | ~15% |
| Chiến lược B | ~25% | ~0.75% | ~66x | ~1650% | ~5% |
| Chiến lược C | ~300% | ~17% | ~3x | ~900% | ~45% |
Chiến lược C với PnL ấn tượng +300% hóa ra là kém hấp dẫn nhất theo PnL@MaxLev do drawdown cao. Chiến lược A dẫn đầu về lợi nhuận đòn bẩy thuần, nhưng khi tính đến PnL trên thời gian hoạt động, Chiến lược B có thể được ưa chuộng hơn — 95% thời gian rảnh có thể lấp đầy bằng các chiến lược khác.
Biểu Đồ Contour và Tầm Quan Trọng Tham Số

Trực Quan Hóa Bề Mặt
Sau tối ưu hóa — trực quan hóa. Optuna cung cấp các công cụ tích hợp:
import optuna.visualization as vis
fig_contour = vis.plot_contour(
study,
params=["htf_entry_sell", "mtf_entry_sell"],
)
fig_contour.show()
fig_importance = vis.plot_param_importances(study)
fig_importance.show()
fig_history = vis.plot_optimization_history(study)
fig_history.show()
fig_parallel = vis.plot_parallel_coordinate(
study,
params=["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell"],
)
fig_parallel.show()
fig_slice = vis.plot_slice(study)
fig_slice.show()
Biểu Đồ Contour: Đọc Tương Tác
Biểu đồ contour xây dựng mặt cắt hai chiều của hàm mục tiêu cho một cặp tham số. Nếu các đường đồng mức song song với một trong các trục — các tham số không tương tác, và OAT sẽ tìm thấy cùng điểm tối ưu. Nếu các đường đồng mức chéo — có tương tác, và OAT sẽ bỏ lỡ.
key_params = ["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell",
"htf_entry_buy", "mtf_entry_buy", "ltf_entry_buy"]
for i, p1 in enumerate(key_params):
for p2 in key_params[i+1:]:
fig = vis.plot_contour(study, params=[p1, p2])
fig.write_image(f"contour_{p1}_vs_{p2}.png")
Nếu biểu đồ contour cho thấy vùng bình ổn — một vùng mà hàm mục tiêu thay đổi ít — đây là dấu hiệu tốt. Vùng bình ổn có nghĩa là kết quả mạnh mẽ trước các sai lệch tham số nhỏ. Thêm về phân tích vùng bình ổn và mối quan hệ của nó với overfitting — trong bài viết sắp tới Phân tích vùng bình ổn.
Tầm Quan Trọng Tham Số
importance = optuna.importance.get_param_importances(study)
for param, imp in importance.items():
print(f"{param:20s}: {imp:.4f}")
Đầu ra điển hình:
htf_entry_sell : 0.2841
mtf_entry_sell : 0.2103
ltf_entry_sell : 0.1567
trail_pct : 0.1204
htf_entry_buy : 0.0892
...
Các tham số có tầm quan trọng < 0.01 có thể cố định ở giá trị mặc định — điều này giảm chiều của bài toán và tăng tốc tối ưu hóa. Nhưng cẩn thận: tầm quan trọng thấp cũng có thể có nghĩa là tham số chỉ quan trọng trong tương tác với các tham số khác. Xác minh qua biểu đồ contour.
Cache Đã Tính Toán Trước: Tại Sao 1 Giây Mỗi Backtest Thay Đổi Mọi Thứ
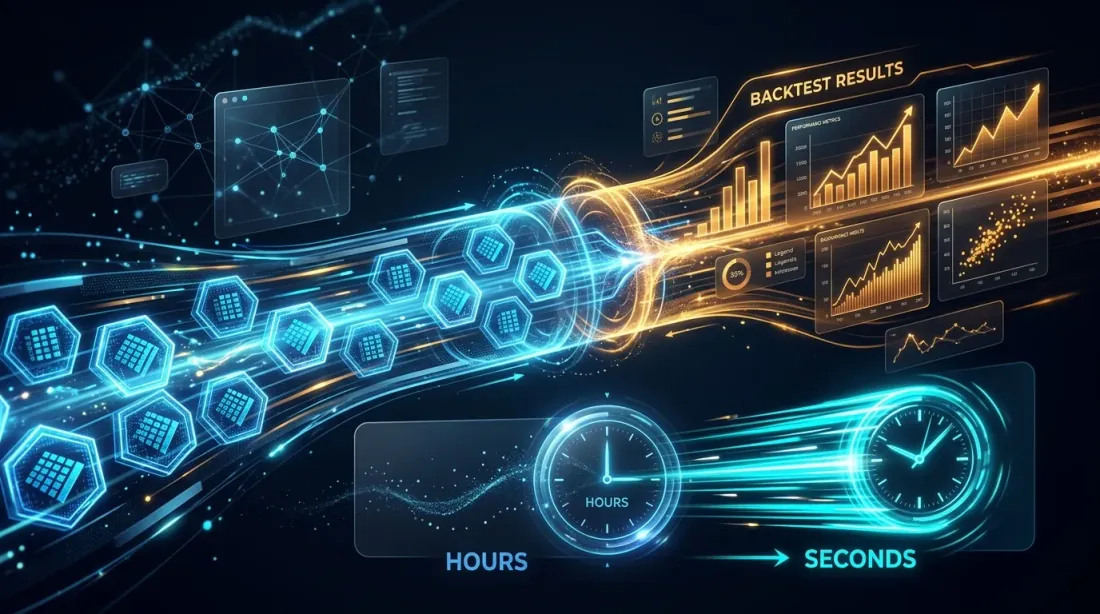
Tốc độ của một backtest đơn lẻ xác định phương pháp tối ưu hóa bạn có thể sử dụng.
| Thời gian Backtest | 96 OAT | 500 TPE | 2000 CmaEs |
|---|---|---|---|
| 60 giây | 1.6 giờ | 8.3 giờ | 33 giờ |
| 10 giây | 16 phút | 83 phút | 5.5 giờ |
| 1 giây | 1.5 phút | 8 phút | 33 phút |
| 0.1 giây | 10 giây | 50 giây | 3.3 phút |
Ở 60 giây mỗi backtest, 500 vòng lặp TPE mất 8 giờ. Chấp nhận được, nhưng lặp đi lặp lại (thay đổi hàm mục tiêu, khởi động lại) tốn kém. Ở 1 giây — 8 phút, và bạn có thể chạy hàng chục thử nghiệm mỗi ngày.
Đây chính xác là lý do tại sao tính toán trước vào Parquet cache không chỉ là tối ưu hóa tốc độ, mà là mở rộng không gian các phương pháp có thể dùng. Không có cache bạn bị giới hạn ở OAT hoặc 100 vòng lặp GP. Với cache — bạn có thể đủ khả năng 2000 vòng lặp CmaEs hoặc NSGA-III đa mục tiêu đầy đủ.
import pyarrow.parquet as pq
import time
t0 = time.time()
htf_pre = pq.read_table("cache/htf_indicators.parquet").to_pandas()
mtf_pre = pq.read_table("cache/mtf_indicators.parquet").to_pandas()
ltf_pre = pq.read_table("cache/ltf_indicators.parquet").to_pandas()
print(f"Cache loaded in {time.time() - t0:.2f}s") # ~0.3s
t1 = time.time()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, htf_entry_sell=0.02, ...)
print(f"Backtest in {time.time() - t1:.2f}s") # ~1.0s
Khuyến Nghị Thực Tế
Khi Nào Dùng OAT
OAT hợp lý trong các trường hợp sau:
-
Phân tích khám phá. Bạn mới bắt đầu khám phá một chiến lược và muốn hiểu tham số nào ảnh hưởng đến kết quả. 96 lần chạy trong 1.5 phút — điểm khởi đầu xuất sắc.
-
Tham số cộng tính. Với các tham số hoạt động trên các tập giao dịch không chồng lấp (hướng bán vs mua, các công cụ khác nhau), OAT sẽ cho kết quả chính xác nhanh hơn.
-
Backtest rất tốn kém. Nếu một lần chạy mất 10+ phút và không thể tăng tốc, OAT với 96 lần chạy (16 giờ) được ưa chuộng hơn 500 vòng lặp TPE (3.5 ngày).
Khi Nào Dùng Optuna
Optuna được ưa chuộng trong hầu hết các trường hợp:
-
Nhiều hơn 3 tham số. Tương tác hầu như được đảm bảo — OAT sẽ bỏ lỡ điểm tối ưu.
-
Chiến lược đa khung thời gian. Ngưỡng trên các khung thời gian khác nhau hầu như luôn có liên kết với nhau.
-
Tối ưu hóa cuối cùng. Khi chiến lược đã qua bootstrap Monte Carlo và bạn tự tin về tính mạnh mẽ của nó — Optuna sẽ tìm các tham số tốt nhất.
-
Bài toán đa mục tiêu. PnL vs MaxDD vs thời gian giao dịch — OAT về nguyên tắc không thể giải quyết bài toán này.
Cách Tiếp Cận Lai: OAT cho Cộng Tính + Optuna cho Có Liên Kết
Bạn không phải chọn giữa OAT và Optuna — tốt hơn là kết hợp chúng:
-
Phân loại tham số. Chia thành cộng tính (độc lập) và có liên kết (tương tác). Ví dụ với 12 tham số phân tách:
- Cộng tính:
htf_entry_sell<->htf_entry_buy,mtf_entry_sell<->mtf_entry_buy,ltf_entry_sell<->ltf_entry_buy(bán/mua — hướng khác nhau, hoạt động trên các giao dịch không chồng lấp) - Nhóm liên kết bán:
htf_entry_sell,mtf_entry_sell,ltf_entry_sell(chuỗi lọc: HTF -> MTF -> LTF cho tín hiệu bán) - Nhóm liên kết mua:
htf_entry_buy,mtf_entry_buy,ltf_entry_buy
- Cộng tính:
-
OAT cho cộng tính. Tối ưu hóa nhóm bán và mua độc lập. Nếu tham số bán không ảnh hưởng đến giao dịch mua — OAT sẽ cho kết quả chính xác trong vài phút.
-
Optuna cho liên kết. Trong mỗi nhóm (bán: 6 tham số vào+ra) dùng TPE. 6 tham số thay vì 12 — ngân sách giảm một nửa.
sell_params = oat_sweep(sell_param_grid, run_backtest, initial_params)
def objective_sell(trial):
params = sell_params.copy()
params["htf_entry_sell"] = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
params["mtf_entry_sell"] = trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005)
params["ltf_entry_sell"] = trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005)
params["htf_exit_sell"] = trial.suggest_float("htf_exit_sell", 0.0, 0.02, step=0.001)
params["mtf_exit_sell"] = trial.suggest_float("mtf_exit_sell", 0.0, 0.02, step=0.001)
params["ltf_exit_sell"] = trial.suggest_float("ltf_exit_sell", 0.0, 0.02, step=0.001)
return -run_backtest(**params)["effective_score"]
study = optuna.create_study(sampler=optuna.samplers.TPESampler())
study.optimize(objective_sell, n_trials=300) # 6 parameters → 300 is enough
Pipeline Tối Ưu Hóa Đầy Đủ
1. Precompute Parquet cache (once)
2. Classify parameters: additive vs coupled
3. OAT for additive (~50 runs, ~1 min) → fix
4. Optuna TPE for coupled groups (300 iterations x 2 groups, ~10 min)
5. Optuna NSGA-III for meta-parameters (500 iterations, ~8 min) → Pareto front
6. Contour plots → visualize interactions
7. Monte Carlo bootstrap of best points → confidence intervals
8. Walk-Forward → out-of-sample validation
Bước 8 — tối ưu hóa walk-forward — cực kỳ quan trọng để bảo vệ khỏi overfitting. Thêm về điều này trong bài viết sắp tới Walk-Forward.
Những Cạm Bẫy Của Tối Ưu Hóa
Overfitting. Càng nhiều tham số và càng chính xác tối ưu hóa — rủi ro fitting chiến lược vào dữ liệu lịch sử càng cao. 500 vòng lặp Optuna với 12 tham số sẽ tìm tổ hợp hoạt động hoàn hảo trên tập huấn luyện, nhưng vô dụng trên dữ liệu mới.
Biện pháp bảo vệ:
- Chia dữ liệu thành train/test (70/30)
- Dùng bootstrap Monte Carlo để đánh giá tính ổn định
- Xác thực qua walk-forward
- Ưu tiên các nghiệm trên vùng bình ổn (thêm về điều này trong Phân tích vùng bình ổn)
Vấn đề so sánh nhiều lần. Nếu bạn kiểm tra 500 tổ hợp, xác suất ngẫu nhiên tìm thấy kết quả "tốt" tăng lên. Hiệu chỉnh Bonferroni hoặc kiểm soát FDR (False Discovery Rate) giúp ích, nhưng cách đơn giản hơn là xác thực ngoài mẫu.
Ngân sách không đủ. TPE với 50 vòng lặp cho 12 tham số là quá ít. 20 vòng lặp đầu là ngẫu nhiên (khởi động), chỉ còn 30 cho mô hình hóa. Ngân sách tối thiểu: vòng lặp cho 12 tham số, khuyến nghị: .
Freqtrade: Cách Nó Hoạt Động Trong Framework Sản Xuất

Freqtrade — một trong những framework algotrading phổ biến — sử dụng Optuna ẩn bên dưới thông qua module Hyperopt. Kinh nghiệm của nó xác nhận các khuyến nghị của chúng ta:
- Sampler: TPE (mặc định), GP, CmaEs, NSGA-II, QMC — tất cả có thể qua cấu hình
- Hàm mất: 12 hàm mất tích hợp, bao gồm ShortTradeDurHyperOptLoss, SharpeHyperOptLoss, MaxDrawDownHyperOptLoss
- Đa mục tiêu: hỗ trợ NSGA-II và NSGA-III để tối ưu hóa đồng thời nhiều chỉ số
- Sampler tùy chỉnh: khả năng tích hợp bất kỳ sampler tương thích Optuna nào
Bài học quan trọng từ hệ sinh thái Freqtrade: các hàm mất tích hợp bao phủ các tình huống điển hình, nhưng để tối ưu hóa nghiêm túc bạn cần hàm mục tiêu tùy chỉnh tính đến đặc thù của chiến lược — thời gian hoạt động, chi phí funding, drill-down thích nghi cho mô phỏng khớp lệnh chính xác.
Kết Luận

Coordinate descent (OAT) là phương pháp nhanh và trực quan. Với 12 tham số nó chỉ cần 96 lần chạy và hoàn thành trong một phút rưỡi. Nhưng nó mù quáng với các tương tác tham số — và trong các chiến lược đa khung thời gian, tương tác hầu như luôn hiện diện.
Tối ưu hóa Bayesian qua Optuna (TPE, GP, CmaEs) khám phá không gian tham số như một tổng thể. 500 vòng lặp trong 8 phút — với Parquet cache đã tính toán trước — tìm ra các tổ hợp không nhìn thấy được với OAT.
Tối ưu hóa đa mục tiêu (NSGA-III) biến bài toán "tối đa hóa PnL" thành bài toán "xây dựng mặt trận Pareto PnL vs MaxDD" — và cung cấp một tập nghiệm với các đánh đổi rủi ro-lợi nhuận khác nhau.
Nhưng tối ưu hóa chỉ là một phần của pipeline. Các tham số tìm được cần xác thực qua bootstrap Monte Carlo, hiệu chỉnh cho funding rate, tính toán lại theo thời gian hoạt động, và chạy qua xác thực walk-forward. Thêm về điều đó trong các bài viết tiếp theo của chuỗi.
Liên Kết Hữu Ích
- Optuna: A Next-generation Hyperparameter Optimization Framework (Akiba et al., 2019)
- Algorithms for Hyper-Parameter Optimization (Bergstra et al., 2011) — bài báo gốc về TPE
- Optuna Documentation — Samplers
- Optuna Visualization Module
- Hansen, N. — The CMA Evolution Strategy: A Tutorial
- Deb, K. et al. — NSGA-II: A Fast and Elitist Multiobjective Genetic Algorithm (2002)
- Snoek, J. et al. — Practical Bayesian Optimization of Machine Learning Algorithms (2012)
- Freqtrade Documentation — Hyperopt
- Marcos Lopez de Prado — Advances in Financial Machine Learning, Chapter 12
- Bergstra, J. & Bengio, Y. — Random Search for Hyper-Parameter Optimization (2012)
Trích Dẫn
@article{soloviov2026optuna,
author = {Soloviov, Eugen},
title = {Coordinate Descent vs Bayesian Optimization: Which Finds Better Parameters},
year = {2026},
url = {https://marketmaker.cc/vi/blog/post/optuna-vs-coordinate-descent},
description = {Tại sao tìm kiếm toàn bộ không thể thực hiện với 12+ tham số, cách coordinate descent bỏ lỡ các tương tác, và cách Optuna với TPE sampler tìm ra trong 500 vòng lặp những gì OAT không thể tìm trong 96.}
}
Tác Giả

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Đọc Thêm

Adaptive Drill-Down: Backtest với Độ Phân Giải Biến Đổi từ Phút đến Giao Dịch Thô

Bộ nhớ đệm Parquet tổng hợp: Cách tăng tốc backtest đa khung thời gian lên hàng trăm lần
