Coordinate Descent vs Pengoptimuman Bayesian: Yang Mana Mencari Parameter Lebih Baik
Ini adalah artikel kelima dalam siri "Backtest Tanpa Ilusi". Dalam artikel sebelumnya kami membincangkan asimetri kerugian-untung, bootstrap Monte Carlo, kesan kadar pembiayaan, dan cache Parquet untuk backtest lebih pantas. Kini mari kita bincangkan proses mencari parameter strategi yang optimum — satu tugas di mana intuisi paling kerap gagal.
Anda mempunyai strategi dengan 12 parameter. Setiap parameter mengambil ~9 nilai. Anda ingin mencari kombinasi yang memaksimumkan PnL dengan drawdown yang terhad. Bagaimana anda melakukannya?
Jika jawapan anda ialah "saya lelari melalui semua kombinasi" — anda mempunyai masalah. Jika jawapan anda ialah "saya tukar satu parameter pada satu masa" — anda mempunyai masalah yang berbeza. Artikel ini membincangkan masalah apa yang tersembunyi di sebalik setiap pendekatan dan cara menyelesaikannya.
Mengapa Carian Menyeluruh Adalah Mustahil

Laknat Dimensi
Carian menyeluruh (grid search) menguji setiap kombinasi nilai untuk setiap parameter. Untuk dua parameter dengan 9 nilai, itu ialah jalankan — sangat boleh dilaksanakan. Untuk tiga: — boleh ditanggung.
Tetapi untuk strategi sebenar dengan 12 parameter:
Dua ratus lapan puluh dua bilion jalankan. Walaupun satu backtest mengambil masa 1 saat (yang sudah pun optimistik), carian menyeluruh akan mengambil masa:
Ini adalah pertumbuhan eksponen: setiap parameter baru mendarabkan ruang carian dengan 9. Tambah parameter ke-13 — dan bukannya 9,000 tahun anda memerlukan 80,000.
import math
def grid_search_cost(n_params: int, values_per_param: int, seconds_per_trial: float) -> dict:
"""Estimate the cost of exhaustive search."""
total_trials = values_per_param ** n_params
total_seconds = total_trials * seconds_per_trial
return {
"total_trials": total_trials,
"total_hours": total_seconds / 3600,
"total_years": total_seconds / (3600 * 24 * 365),
}
cost = grid_search_cost(12, 9, 1.0)
print(f"Trials: {cost['total_trials']:,.0f}") # 282,429,536,481
print(f"Years: {cost['total_years']:,.0f}") # 8,950
Walaupun dengan Pra-pengiraan
Dalam artikel mengenai cache Parquet kami menunjukkan bagaimana pra-pengiraan timeframe dan penunjuk mempercepatkan satu backtest kepada ~1 saat. Tetapi walaupun pada 0.1 saat setiap jalankan, carian menyeluruh 12 parameter memerlukan 895 tahun. Pra-pengiraan membantu, tetapi tidak menyelesaikan masalah asas pertumbuhan eksponen.
Kita memerlukan kaedah yang meneroka ruang parameter lebih bijak daripada carian menyeluruh.
Coordinate Descent dan OAT: Pantas tetapi Buta
Dua Varian Idea Yang Sama
Terdapat dua pendekatan berkaitan — kedua-duanya mengoptimumkan satu parameter pada satu masa, tetapi berbeza dalam bilangan lintasan:
OAT (One-at-a-Time) sweep — satu lintasan melalui semua parameter. Lelari melalui nilai parameter pertama, tetapkan yang terbaik, beralih ke yang kedua — dan seterusnya. Sekali sahaja. Pantas dan murah.
Coordinate Descent — pelbagai lintasan. Selepas mengoptimumkan parameter terakhir, kembali ke yang pertama dan semak sama ada optimum telah berubah (kerana konteks telah berubah — nilai parameter lain kini berbeza). Ulang pusingan sehingga penumpuan. Lebih mahal, tetapi lebih tepat — setiap pusingan boleh memperhalusi penyelesaian.
Dalam amalan, untuk backtest OAT lebih kerap digunakan: satu lintasan melalui 12 parameter — 96 jalankan. Coordinate descent dengan 3-5 pusingan — 300-500 jalankan, yang sudah setanding dengan Optuna, tetapi tanpa kelebihannya.
Untuk 12 parameter dengan ~8 nilai masing-masing:
Bandingkan dengan untuk grid search. OAT adalah linear: bukannya . Ini adalah kelebihan utama dan masalah utamanya sekaligus.
def oat_sweep(
param_grid: dict[str, list],
run_backtest_fn,
initial_params: dict,
metric: str = "effective_score",
) -> dict:
"""
OAT sweep: single pass, optimizing one parameter at a time.
param_grid: {"htf_entry_sell": [0.0, 0.005, ..., 0.05], ...}
initial_params: starting values for all parameters
metric: metric to optimize (effective_score recommended —
PnL per active time extrapolated to a year)
"""
best_params = initial_params.copy()
best_score = run_backtest_fn(**best_params)[metric]
for param_name, values in param_grid.items():
param_best_val = best_params[param_name]
param_best_score = best_score
for val in values:
candidate = best_params.copy()
candidate[param_name] = val
result = run_backtest_fn(**candidate)
score = result[metric]
if score > param_best_score:
param_best_score = score
param_best_val = val
best_params[param_name] = param_best_val
best_score = param_best_score
print(f"{param_name}: best={param_best_val}, score={param_best_score:.4f}")
return best_params
Metrik mana yang hendak dipilih untuk pengoptimuman? Daripada PnL mentah atau PnL@MaxLev, adalah disyorkan untuk menggunakan effective score — PnL per masa aktif yang diekstrapolasi kepada setahun. Metrik ini mengambil kira masa dalam posisi dan membolehkan perbandingan yang betul bagi strategi dengan frekuensi perdagangan yang berbeza.
Titik Buta: Interaksi Parameter
OAT mengandaikan bahawa kesan setiap parameter adalah additif — iaitu, nilai optimum satu parameter tidak bergantung kepada nilai parameter lain. Andaian ini berlaku untuk sesetengah parameter, tetapi rosak untuk parameter yang berganding.
Parameter Additif vs Berganding
Sebelum mengoptimumkan — adalah berguna untuk mengklasifikasikan parameter:
Additif (bebas) — nilai optimum satu tidak bergantung kepada yang lain. Ia boleh dioptimumkan satu persatu dengan murah:
htf_entry_selldanhtf_entry_buy— ambang masuk untuk arah berbeza (jual/beli) pada timeframe yang sama. Ambang jual menapis isyarat pendek, ambang beli — panjang. Mereka beroperasi pada subset dagangan yang tidak bertindih.tp_targetdanbe_trigger— ambil untung dan breakeven, jika mereka tidak mewujudkan syarat keluar yang bercanggah.
Berganding (interaktif) — nilai optimum satu bergantung kepada yang lain. Pengoptimuman bersama diperlukan:
htf_entry_selldanmtf_entry_sell— ambang untuk arah yang sama (jual) pada timeframe berbeza. HTF menentukan isyarat mana yang mencapai MTF, dan ambang MTF menentukan keberkesanan penapisan. Optimum HTF beranjak apabila MTF berubah.ltf_entry_sell,mtf_entry_sell,htf_entry_sell— keseluruhan rantai ambang untuk satu arah.partial_fracdantp_target— saiz tutup separa bergantung pada tahap TP.
Pendekatan praktikal: pertama optimumkan parameter additif dengan murah melalui OAT. Kemudian optimumkan kumpulan berganding melalui Optuna. Ini mengurangkan bajet: daripada 12 parameter dalam Optuna, kami hanya menghantar 6-8 yang berganding, manakala yang lain sudah ditetapkan.
Contoh: Bagaimana OAT Terlepas Interaksi
Pertimbangkan dua ambang berganding:
htf_entry_sell— ambang pada timeframe lebih tinggi (arah jual)mtf_entry_sell— ambang pada timeframe tengah (arah jual)
OAT menetapkan mtf_entry_sell = 0.01 (nilai awal) dan lelari melalui htf_entry_sell. Menjumpai nilai terbaik: htf_entry_sell = 0.02. Menetapkannya dan beralih ke parameter seterusnya — tidak pernah kembali.
Inilah yang OAT terlepas:
htf_entry_sell |
mtf_entry_sell |
PnL |
|---|---|---|
| 0.02 | 0.01 | +42% |
| 0.02 | 0.02 | +38% |
| 0.03 | 0.02 | +51% |
| 0.03 | 0.01 | +35% |
Kombinasi (0.03, 0.02) menghasilkan PnL +51%, tetapi OAT tidak akan pernah mempertimbangkannya kerana dengan mtf_entry_sell = 0.01 yang ditetapkan, nilai htf_entry_sell = 0.03 hanya menghasilkan +35%. OAT "terperangkap" dalam optimum tempatan (0.02, 0.01) dan tidak dapat melihat optimum global (0.03, 0.02).
Ini adalah masalah klasik: jika landskap fungsi objektif mengandungi rabung pepenjuru (apabila optimum satu parameter beranjak apabila parameter lain berubah), OAT akan terlepasnya.
Memformalkan Masalah
Biarkan ialah fungsi objektif (PnL). OAT mencari titik di mana:
Tetapi ini adalah syarat perlu, bukan syarat mencukupi untuk optimum global. Jika matriks Hessian mempunyai elemen luar pepenjuru yang ketara — OAT tidak mengambil kira terbitan silang apabila .
Untuk parameter berganding (ambang arah yang sama merentasi pelbagai timeframe) — interaksi adalah peraturan, bukan pengecualian. Ambang masuk pada timeframe lebih tinggi menentukan isyarat mana yang mencapai yang tengah, dan ambang pada yang tengah menentukan keberkesanan penapisan pada yang lebih rendah. Untuk parameter additif (arah berbeza, penapis bebas) terbitan silang menghampiri sifar — dan OAT berfungsi dengan baik.
Pengoptimuman Bayesian: Carian Bijak

Idea
Daripada penghitungan buta atau carian tamak, pengoptimuman Bayesian membina model surrogat fungsi objektif dan pada setiap langkah memilih titik di mana peningkatan jangkaan adalah maksimum.
Algoritma:
- Pilih beberapa titik rawak, nilai fungsi objektif
- Bina model surrogat (menganggar dari titik yang diperhatikan)
- Cari titik dengan peningkatan jangkaan maksimum (fungsi pemerolehan)
- Nilai fungsi objektif di titik itu
- Kemas kini model surrogat
- Ulang langkah 3-5
Perbezaan utama dari OAT: pengoptimuman Bayesian mempertimbangkan semua parameter serentak dan boleh meneroka rabung pepenjuru dalam ruang parameter.
TPE (Tree-structured Parzen Estimator)

TPE adalah sampler lalai dalam Optuna. Daripada memodelkan secara langsung, TPE memodelkan dua taburan:
- — taburan parameter di mana fungsi objektif lebih baik daripada ambang
- — taburan parameter di mana fungsi objektif lebih buruk daripada ambang
Fungsi pemerolehan TPE — nisbah:
TPE memilih titik di mana adalah besar (parameter serupa dengan yang "baik") dan adalah kecil (parameter tidak serupa dengan yang "buruk").
Mengapa TPE sesuai untuk backtest:
- Mengendalikan kebergantungan bersyarat antara parameter
- Tidak memerlukan kesinambungan fungsi objektif
- Cekap dengan bajet sederhana (100-1000 lelaran)
- Menyokong parameter kategorikal dan diskret
Proses Gaussian (GP)
Alternatif kepada TPE — Proses Gaussian. GP memodelkan sebagai proses normal multivariat dan menyediakan bukan sahaja ramalan nilai, tetapi juga ketidakpastian di setiap titik.
di mana ialah min, ialah fungsi kovarians (kernel).
GP berfungsi dengan baik apabila:
- Terdapat sedikit parameter (hingga 10-15)
- Fungsi objektif adalah lancar
- Setiap jalankan adalah mahal (minit, jam)
Untuk backtest dengan cache Parquet yang telah dipra-kirakan, di mana satu jalankan mengambil ~1 saat, TPE biasanya lebih disukai: ia membina model lebih pantas dan berskala lebih baik kepada 500+ lelaran.
Integrasi Praktikal dengan Optuna
Contoh Kerja Penuh
import optuna
from optuna.samplers import TPESampler
import numpy as np
def run_backtest(htf_pre, mtf_pre, ltf_pre, **params) -> dict:
"""
Runs a backtest with given parameters.
Returns a dict with metrics: pnl, max_dd, n_trades, trading_time, sharpe.
Uses precomputed Parquet cache — ~1 second per run.
"""
pass
def objective(trial: optuna.Trial) -> float:
"""Objective function for Optuna."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
study = optuna.create_study(
sampler=TPESampler(seed=42),
study_name="strategy_optimization",
direction="minimize",
)
study.optimize(objective, n_trials=500, show_progress_bar=True)
print(f"Best PnL: {-study.best_value:.2f}%")
print(f"Best params: {study.best_params}")
print(f"Total trials: {len(study.trials)}")
Pada ~1 saat setiap backtest (dengan cache yang telah dipra-kirakan):
Lapan minit berbanding 8,950 tahun carian menyeluruh. Dan TPE dalam 500 lelaran menemui kombinasi yang OAT terlepas dalam 96, kerana ia meneroka ruang parameter serentak dan bukannya satu paksi pada satu masa.
Menyimpan dan Menyambung Semula Kajian
import optuna
study = optuna.create_study(
storage="sqlite:///optuna_study.db",
study_name="strategy_v2",
sampler=TPESampler(seed=42),
direction="minimize",
load_if_exists=True, # continue if study already exists
)
study.optimize(objective, n_trials=300)
study.optimize(objective, n_trials=200)
Menambah Kekangan
Tidak semua kombinasi parameter adalah sah. Sebagai contoh, ambang keluar tidak seharusnya melebihi ambang masuk:
def objective_with_constraints(trial: optuna.Trial) -> float:
htf_entry = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
htf_exit = trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005)
if htf_exit > htf_entry:
raise optuna.TrialPruned()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
Perbandingan Sampler
Optuna menyokong beberapa sampler. Setiap satu mempunyai kekuatannya sendiri.
TPESampler (lalai)
sampler = optuna.samplers.TPESampler(
n_startup_trials=20, # random trials before modeling begins
seed=42,
)
- Prinsip: Tree-structured Parzen Estimator
- Kekuatan: baik untuk jenis parameter campuran, berskala kepada 1000+ lelaran
- Kelemahan: mungkin kurang cekap dengan interaksi parameter yang kuat
- Bila digunakan: secara lalai, jika tiada sebab untuk memilih yang lain
CmaEsSampler
sampler = optuna.samplers.CmaEsSampler(seed=42)
- Prinsip: Covariance Matrix Adaptation Evolution Strategy — algoritma evolusi yang menyesuaikan matriks kovarians
- Kekuatan: cemerlang dalam mencari interaksi antara parameter berterusan, mengambil kira korelasi
- Kelemahan: tidak menyokong parameter kategorikal, memerlukan lebih banyak lelaran untuk permulaan
- Bila digunakan: jika semua parameter adalah berterusan dan anda mengesyaki interaksi yang kuat
GPSampler
sampler = optuna.samplers.GPSampler(seed=42)
- Prinsip: Proses Gaussian dengan fungsi pemerolehan
- Kekuatan: kecekapan sampel terbaik (lebih sedikit lelaran untuk hasil yang baik), menyediakan anggaran ketidakpastian
- Kelemahan: dalam kiraan lelaran — perlahan apabila
- Bila digunakan: jika satu backtest adalah mahal (minit) dan bajet terhad kepada 100-200 lelaran
RandomSampler (garis dasar)
sampler = optuna.samplers.RandomSampler(seed=42)
- Prinsip: pensampelan rawak seragam
- Kekuatan: tidak terperangkap dalam optimum tempatan, liputan ruang penuh
- Kelemahan: tidak menggunakan keputusan sebelumnya
- Bila digunakan: sebagai garis dasar untuk perbandingan, atau untuk analisis penerokaan
QMCSampler
sampler = optuna.samplers.QMCSampler(seed=42)
- Prinsip: Quasi-Monte Carlo (urutan Sobol/Halton) — mengisi ruang lebih seragam daripada sampler rawak
- Kekuatan: liputan ruang lebih baik daripada RandomSampler, kebolehulangan
- Kelemahan: tidak menyesuaikan diri dengan keputusan
- Bila digunakan: untuk 50-100 lelaran pertama sebelum beralih kepada TPE
Jadual Ringkasan
| Sampler | Jenis | Interaksi | Kategorikal | Bajet Terbaik |
|---|---|---|---|---|
| TPE | Bayesian | Separa | Ya | 100-1000 |
| CmaEs | Evolusi | Ya | Tidak | 200-2000 |
| GP | Bayesian | Ya | Terhad | 50-200 |
| Random | Rawak | Tidak | Ya | Mana-mana (garis dasar) |
| QMC | Kuasi-rawak | Tidak | Tidak | 50-500 |
Penanda Aras Praktikal
import optuna
import time
def benchmark_sampler(sampler, n_trials=300):
"""Compare samplers on the same task."""
study = optuna.create_study(sampler=sampler, direction="minimize")
start = time.time()
study.optimize(objective, n_trials=n_trials, show_progress_bar=False)
elapsed = time.time() - start
return {
"best_value": -study.best_value,
"elapsed_sec": elapsed,
"best_trial": study.best_trial.number,
}
samplers = {
"TPE": optuna.samplers.TPESampler(seed=42),
"CmaEs": optuna.samplers.CmaEsSampler(seed=42),
"GP": optuna.samplers.GPSampler(seed=42),
"Random": optuna.samplers.RandomSampler(seed=42),
"QMC": optuna.samplers.QMCSampler(seed=42),
}
for name, sampler in samplers.items():
result = benchmark_sampler(sampler, n_trials=300)
print(f"{name:8s}: best PnL={result['best_value']:.2f}%, "
f"found at trial #{result['best_trial']}, "
f"time={result['elapsed_sec']:.1f}s")
Keputusan tipikal untuk strategi dengan 12 parameter:
| Sampler | PnL Terbaik | Dijumpai pada Lelaran | Overhed Sampler |
|---|---|---|---|
| TPE | ~51% | ~180 | Rendah |
| CmaEs | ~49% | ~250 | Sederhana |
| GP | ~48% | ~90 | Tinggi apabila |
| Random | ~42% | ~270 | Minimum |
| QMC | ~43% | ~200 | Minimum |
TPE dan CmaEs secara konsisten mengatasi carian rawak sebanyak 15-20% dalam PnL akhir. GP menemui keputusan yang baik lebih awal tetapi mencapai had pengiraan dengan bilangan lelaran yang besar.
Pengoptimuman Pelbagai Objektif: PnL vs MaxDD
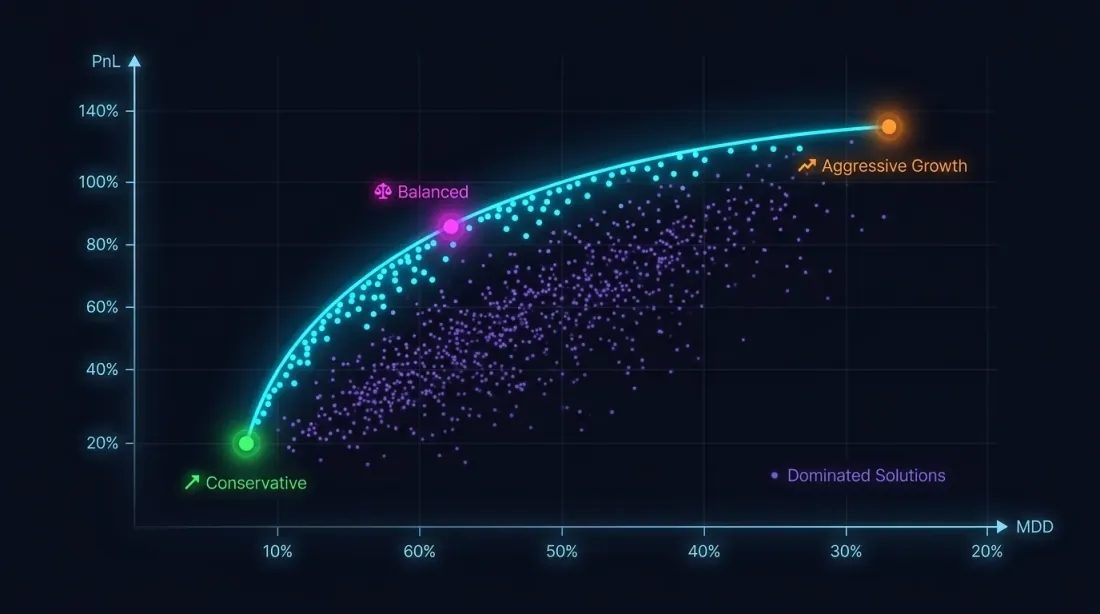
Mengapa Satu Kriteria Tidak Mencukupi
Memaksimumkan PnL tanpa kekangan drawdown adalah jalan menuju bencana. Strategi dengan PnL +80% dan MaxDD -30% adalah, disebabkan asimetri kerugian-untung, jauh lebih berisiko daripada strategi dengan PnL +50% dan MaxDD -5%.
Masalah pengoptimuman sebenarnya adalah pelbagai objektif:
Matlamat-matlamat ini bercanggah: parameter agresif meningkatkan kedua-dua PnL dan drawdown. Penyelesaiannya bukan satu titik, tetapi hadapan Pareto: set penyelesaian di mana anda tidak boleh memperbaiki satu metrik tanpa memburukkan yang lain.
NSGA-II / NSGA-III dalam Optuna
import optuna
def multi_objective(trial: optuna.Trial) -> tuple[float, float]:
"""Multi-objective function: (PnL, MaxDD)."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
pnl = result["pnl"] # maximize
max_dd = result["max_dd"] # minimize (already a negative number)
return pnl, max_dd # Optuna: both directions are set in create_study
study = optuna.create_study(
directions=["maximize", "minimize"],
sampler=optuna.samplers.NSGAIIISampler(seed=42),
study_name="multi_objective_strategy",
)
study.optimize(multi_objective, n_trials=500)
pareto_trials = study.best_trials
print(f"Pareto front: {len(pareto_trials)} solutions")
for t in pareto_trials[:5]:
print(f" PnL={t.values[0]:.2f}%, MaxDD={t.values[1]:.2f}%")
Memilih Titik pada Hadapan Pareto
Hadapan Pareto memberikan pelbagai penyelesaian. Bagaimana untuk memilih satu?
def select_from_pareto(
pareto_trials: list,
max_dd_limit: float = -5.0,
min_pnl: float = 20.0,
) -> list:
"""
Filter the Pareto front by constraints.
max_dd_limit: maximum acceptable drawdown (e.g., -5%)
min_pnl: minimum acceptable PnL (%)
"""
filtered = []
for trial in pareto_trials:
pnl, max_dd = trial.values
if max_dd >= max_dd_limit and pnl >= min_pnl:
max_lev = min(50 / abs(max_dd), 100) if max_dd != 0 else 100
pnl_at_max_lev = pnl * max_lev
filtered.append({
"trial": trial,
"pnl": pnl,
"max_dd": max_dd,
"max_lev": max_lev,
"pnl_at_max_lev": pnl_at_max_lev,
})
filtered.sort(key=lambda x: x["pnl_at_max_lev"], reverse=True)
return filtered
Nota: apabila mengira PnL pada leverage maksimum, anda mesti mengambil kira kadar pembiayaan, jika tidak leverage yang tinggi secara teori akan bertukar menjadi kerugian di pasaran sebenar. Tambahan pula, PnL akhir adalah anggaran satu titik, dan untuk menilai kestabilan keputusan anda memerlukan bootstrap Monte Carlo.
Contoh: Tiga Strategi pada Hadapan Pareto
| Strategi | PnL | MaxDD | MaxLev | PnL@MaxLev | Masa perdagangan |
|---|---|---|---|---|---|
| Strategi A | ~55% | ~0.9% | ~55x | ~3025% | ~15% |
| Strategi B | ~25% | ~0.75% | ~66x | ~1650% | ~5% |
| Strategi C | ~300% | ~17% | ~3x | ~900% | ~45% |
Strategi C dengan PnL yang mengesankan +300% ternyata paling kurang menarik dari segi PnL@MaxLev disebabkan drawdown yang tinggi. Strategi A mengetuai dalam pulangan berleveraj bersih, tetapi apabila mengambil kira PnL per masa aktif, Strategi B mungkin lebih disukai — 95% masa bebas boleh diisi dengan strategi lain.
Plot Kontur dan Kepentingan Parameter

Visualisasi Landskap
Selepas pengoptimuman — visualisasi. Optuna menyediakan alat terbina dalam:
import optuna.visualization as vis
fig_contour = vis.plot_contour(
study,
params=["htf_entry_sell", "mtf_entry_sell"],
)
fig_contour.show()
fig_importance = vis.plot_param_importances(study)
fig_importance.show()
fig_history = vis.plot_optimization_history(study)
fig_history.show()
fig_parallel = vis.plot_parallel_coordinate(
study,
params=["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell"],
)
fig_parallel.show()
fig_slice = vis.plot_slice(study)
fig_slice.show()
Plot Kontur: Membaca Interaksi
Plot kontur membina keratan rentas dua dimensi fungsi objektif untuk sepasang parameter. Jika garis iso adalah selari dengan salah satu paksi — parameter tidak berinteraksi, dan OAT akan menemui optimum yang sama. Jika garis iso adalah pepenjuru — terdapat interaksi, dan OAT akan terlepasnya.
key_params = ["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell",
"htf_entry_buy", "mtf_entry_buy", "ltf_entry_buy"]
for i, p1 in enumerate(key_params):
for p2 in key_params[i+1:]:
fig = vis.plot_contour(study, params=[p1, p2])
fig.write_image(f"contour_{p1}_vs_{p2}.png")
Jika plot kontur menunjukkan platau — kawasan di mana fungsi objektif berubah sedikit — ini adalah tanda yang baik. Platau bermakna keputusan adalah teguh terhadap penyelewengan parameter kecil. Lebih lanjut mengenai analisis platau dan hubungannya dengan overfitting — dalam artikel akan datang Analisis platau.
Kepentingan Parameter
importance = optuna.importance.get_param_importances(study)
for param, imp in importance.items():
print(f"{param:20s}: {imp:.4f}")
Output tipikal:
htf_entry_sell : 0.2841
mtf_entry_sell : 0.2103
ltf_entry_sell : 0.1567
trail_pct : 0.1204
htf_entry_buy : 0.0892
...
Parameter dengan kepentingan < 0.01 boleh ditetapkan pada nilai lalainya — ini mengurangkan dimensi masalah dan mempercepatkan pengoptimuman. Tetapi berhati-hati: kepentingan yang rendah mungkin juga bermakna parameter itu penting hanya dalam interaksi dengan yang lain. Sahkan melalui plot kontur.
Cache Pra-dikira: Mengapa 1 Saat per Backtest Mengubah Segalanya
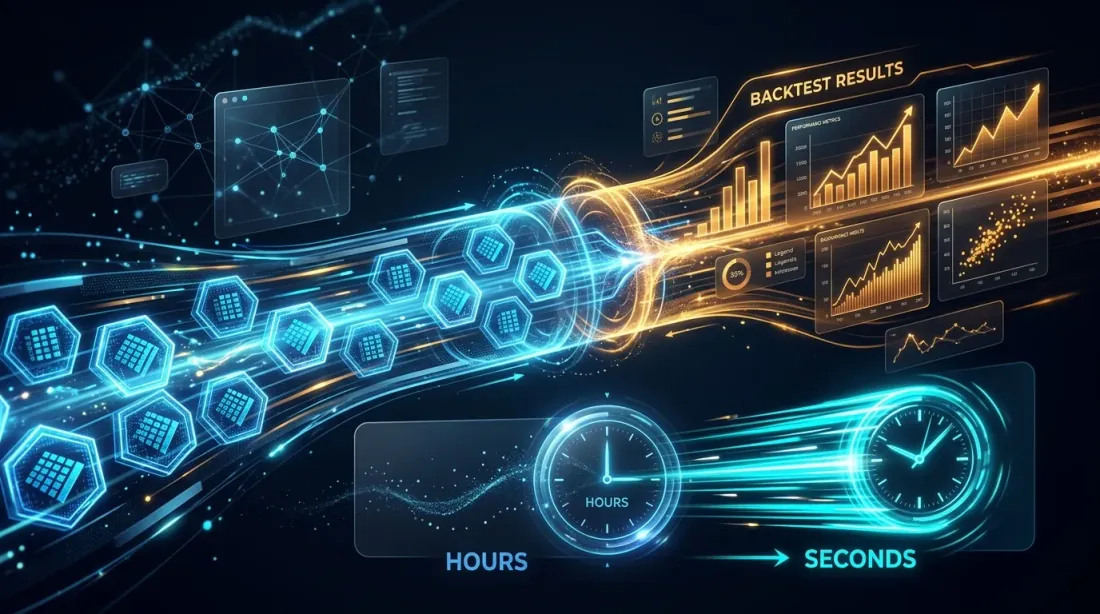
Kelajuan satu backtest menentukan kaedah pengoptimuman yang boleh anda tanggung.
| Masa Backtest | 96 OAT | 500 TPE | 2000 CmaEs |
|---|---|---|---|
| 60 saat | 1.6 jam | 8.3 jam | 33 jam |
| 10 saat | 16 minit | 83 minit | 5.5 jam |
| 1 saat | 1.5 minit | 8 minit | 33 minit |
| 0.1 saat | 10 saat | 50 saat | 3.3 minit |
Pada 60 saat setiap backtest, 500 lelaran TPE mengambil masa 8 jam. Sudah boleh ditanggung, tetapi berulang (menukar fungsi objektif, memulakan semula) adalah mahal. Pada 1 saat — 8 minit, dan anda boleh menjalankan berpuluh-puluh eksperimen sehari.
Inilah sebabnya tepat mengapa pra-pengiraan ke dalam cache Parquet bukan sahaja pengoptimuman kelajuan, tetapi pengembangan ruang kaedah yang tersedia. Tanpa cache anda terhad kepada OAT atau 100 lelaran GP. Dengan cache — anda boleh menanggung 2000 lelaran CmaEs atau NSGA-III pelbagai objektif penuh.
import pyarrow.parquet as pq
import time
t0 = time.time()
htf_pre = pq.read_table("cache/htf_indicators.parquet").to_pandas()
mtf_pre = pq.read_table("cache/mtf_indicators.parquet").to_pandas()
ltf_pre = pq.read_table("cache/ltf_indicators.parquet").to_pandas()
print(f"Cache loaded in {time.time() - t0:.2f}s") # ~0.3s
t1 = time.time()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, htf_entry_sell=0.02, ...)
print(f"Backtest in {time.time() - t1:.2f}s") # ~1.0s
Cadangan Praktikal
Bila Menggunakan OAT
OAT adalah wajar dalam kes-kes berikut:
-
Analisis penerokaan. Anda baru mula meneroka strategi dan ingin memahami parameter mana yang mempengaruhi keputusan sama sekali. 96 jalankan dalam 1.5 minit — titik permulaan yang cemerlang.
-
Parameter additif. Untuk parameter yang beroperasi pada subset dagangan yang tidak bertindih (arah jual vs beli, instrumen berbeza), OAT akan memberikan keputusan yang betul dengan lebih pantas.
-
Backtest yang sangat mahal. Jika satu jalankan mengambil masa 10+ minit dan tidak dapat dipercepatkan, OAT dengan 96 jalankan (16 jam) lebih disukai daripada 500 lelaran TPE (3.5 hari).
Bila Menggunakan Optuna
Optuna lebih disukai dalam kebanyakan kes:
-
Lebih daripada 3 parameter. Interaksi hampir dijamin — OAT akan terlepas optimum.
-
Strategi pelbagai-timeframe. Ambang merentasi timeframe berbeza hampir selalu saling berkaitan.
-
Pengoptimuman akhir. Apabila strategi telah lulus bootstrap Monte Carlo dan anda yakin dengan ketegarannya — Optuna akan menemui parameter terbaik.
-
Masalah pelbagai objektif. PnL vs MaxDD vs masa perdagangan — OAT tidak dapat menyelesaikan masalah ini pada dasarnya.
Pendekatan Hibrid: OAT untuk Additif + Optuna untuk Berganding
Anda tidak perlu memilih antara OAT dan Optuna — adalah lebih baik untuk menggabungkannya:
-
Klasifikasikan parameter. Bahagikan kepada additif (bebas) dan berganding (interaktif). Contoh untuk 12 parameter pemisahan:
- Additif:
htf_entry_sell<->htf_entry_buy,mtf_entry_sell<->mtf_entry_buy,ltf_entry_sell<->ltf_entry_buy(jual/beli — arah berbeza, beroperasi pada dagangan yang tidak bertindih) - Kumpulan berganding jual:
htf_entry_sell,mtf_entry_sell,ltf_entry_sell(rantai penapisan: HTF -> MTF -> LTF untuk isyarat jual) - Kumpulan berganding beli:
htf_entry_buy,mtf_entry_buy,ltf_entry_buy
- Additif:
-
OAT untuk additif. Optimumkan kumpulan jual dan beli secara bebas. Jika parameter jual tidak mempengaruhi dagangan beli — OAT akan memberikan keputusan yang betul dalam beberapa minit.
-
Optuna untuk berganding. Dalam setiap kumpulan (jual: 6 parameter masuk+keluar) gunakan TPE. 6 parameter dan bukannya 12 — bajet dikurangkan separuh.
sell_params = oat_sweep(sell_param_grid, run_backtest, initial_params)
def objective_sell(trial):
params = sell_params.copy()
params["htf_entry_sell"] = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
params["mtf_entry_sell"] = trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005)
params["ltf_entry_sell"] = trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005)
params["htf_exit_sell"] = trial.suggest_float("htf_exit_sell", 0.0, 0.02, step=0.001)
params["mtf_exit_sell"] = trial.suggest_float("mtf_exit_sell", 0.0, 0.02, step=0.001)
params["ltf_exit_sell"] = trial.suggest_float("ltf_exit_sell", 0.0, 0.02, step=0.001)
return -run_backtest(**params)["effective_score"]
study = optuna.create_study(sampler=optuna.samplers.TPESampler())
study.optimize(objective_sell, n_trials=300) # 6 parameters → 300 is enough
Saluran Paip Pengoptimuman Penuh
1. Precompute Parquet cache (once)
2. Classify parameters: additive vs coupled
3. OAT for additive (~50 runs, ~1 min) → fix
4. Optuna TPE for coupled groups (300 iterations x 2 groups, ~10 min)
5. Optuna NSGA-III for meta-parameters (500 iterations, ~8 min) → Pareto front
6. Contour plots → visualize interactions
7. Monte Carlo bootstrap of best points → confidence intervals
8. Walk-Forward → out-of-sample validation
Langkah 8 — pengoptimuman walk-forward — adalah kritikal penting untuk perlindungan terhadap overfitting. Lebih lanjut mengenai ini dalam artikel akan datang Walk-Forward.
Perangkap Pengoptimuman
Overfitting. Semakin banyak parameter dan semakin tepat pengoptimuman — semakin tinggi risiko memasang strategi kepada data sejarah. 500 lelaran Optuna dengan 12 parameter akan menemui kombinasi yang berfungsi dengan sempurna pada set latihan, tetapi tidak berguna pada data baru.
Perlindungan:
- Bahagikan data kepada latihan/ujian (70/30)
- Gunakan bootstrap Monte Carlo untuk menilai kestabilan
- Sahkan melalui walk-forward
- Utamakan penyelesaian pada platau (lebih lanjut mengenai ini dalam Analisis platau)
Masalah perbandingan berganda. Jika anda menguji 500 kombinasi, kemungkinan secara rawak menemui keputusan "baik" meningkat. Pembetulan Bonferroni atau kawalan FDR (False Discovery Rate) membantu, tetapi pendekatan yang lebih mudah adalah pengesahan luar sampel.
Bajet tidak mencukupi. TPE dengan 50 lelaran untuk 12 parameter adalah terlalu sedikit. 20 lelaran pertama adalah rawak (permulaan), hanya meninggalkan 30 untuk pemodelan. Bajet minimum: lelaran untuk 12 parameter, disyorkan: .
Freqtrade: Bagaimana Ia Berfungsi dalam Rangka Kerja Pengeluaran

Freqtrade — salah satu rangka kerja algotrading yang popular — menggunakan Optuna di bawahnya melalui modul Hyperopt. Pengalamannya mengesahkan cadangan kami:
- Sampler: TPE (lalai), GP, CmaEs, NSGA-II, QMC — semua tersedia melalui konfigurasi
- Fungsi kerugian: 12 fungsi kerugian terbina dalam, termasuk ShortTradeDurHyperOptLoss, SharpeHyperOptLoss, MaxDrawDownHyperOptLoss
- Pelbagai objektif: sokongan untuk NSGA-II dan NSGA-III untuk pengoptimuman serentak pelbagai metrik
- Sampler tersuai: keupayaan untuk menyambungkan mana-mana sampler yang serasi dengan Optuna
Pelajaran utama dari ekosistem Freqtrade: fungsi kerugian terbina dalam meliputi senario tipikal, tetapi untuk pengoptimuman serius anda memerlukan fungsi objektif tersuai yang mengambil kira kekhususan strategi anda — masa aktif, kos pembiayaan, penggerudi adaptif untuk simulasi pelaksanaan yang tepat.
Kesimpulan

Coordinate descent (OAT) adalah kaedah yang pantas dan intuitif. Untuk 12 parameter ia hanya memerlukan 96 jalankan dan selesai dalam satu setengah minit. Tetapi ia buta terhadap interaksi parameter — dan dalam strategi pelbagai-timeframe, interaksi hampir selalu hadir.
Pengoptimuman Bayesian melalui Optuna (TPE, GP, CmaEs) meneroka ruang parameter secara keseluruhan. 500 lelaran dalam 8 minit — dengan cache Parquet yang telah dipra-kirakan — menemui kombinasi yang tidak kelihatan oleh OAT.
Pengoptimuman pelbagai objektif (NSGA-III) mengubah masalah "maksimumkan PnL" kepada masalah "bina hadapan Pareto PnL vs MaxDD" — dan menyediakan set penyelesaian dengan pertukaran risiko-pulangan yang berbeza.
Tetapi pengoptimuman hanyalah sebahagian daripada saluran paip. Parameter yang ditemui perlu disahkan melalui bootstrap Monte Carlo, dibetulkan untuk kadar pembiayaan, dikira semula dengan mengambil kira masa aktif, dan dijalankan melalui pengesahan walk-forward. Lebih lanjut mengenai itu dalam artikel akan datang siri ini.
Pautan Berguna
- Optuna: A Next-generation Hyperparameter Optimization Framework (Akiba et al., 2019)
- Algorithms for Hyper-Parameter Optimization (Bergstra et al., 2011) — the original TPE paper
- Optuna Documentation — Samplers
- Optuna Visualization Module
- Hansen, N. — The CMA Evolution Strategy: A Tutorial
- Deb, K. et al. — NSGA-II: A Fast and Elitist Multiobjective Genetic Algorithm (2002)
- Snoek, J. et al. — Practical Bayesian Optimization of Machine Learning Algorithms (2012)
- Freqtrade Documentation — Hyperopt
- Marcos Lopez de Prado — Advances in Financial Machine Learning, Chapter 12
- Bergstra, J. & Bengio, Y. — Random Search for Hyper-Parameter Optimization (2012)
Petikan
@article{soloviov2026optuna,
author = {Soloviov, Eugen},
title = {Coordinate Descent vs Bayesian Optimization: Which Finds Better Parameters},
year = {2026},
url = {https://marketmaker.cc/ms/blog/post/optuna-vs-coordinate-descent},
description = {Mengapa carian menyeluruh mustahil untuk 12+ parameter, bagaimana coordinate descent terlepas interaksi, dan bagaimana Optuna dengan TPE sampler menemui dalam 500 lelaran apa yang OAT tidak dapat temui dalam 96.}
}
Pengarang

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Baca Lagi

Adaptive Drill-Down: Backtest dengan Granulariti Pemboleh ubah dari Minit hingga Dagangan Mentah

Cache Parquet Teragregat: Cara Mempercepatkan Backtest Pelbagai Jangka Masa Ratusan Kali
